Chapter 7 - thread pool of shared model
Thread pool (key)
There are many pooling technologies, such as thread pool, database connection pool, HTTP connection pool and so on. The idea of pooling technology is mainly to reduce the consumption of resources and improve the utilization of resources.
Thread pools provide a way to limit and manage resources (including performing a task). Each thread pool also maintains some basic statistics, such as the number of tasks completed.
Here, the benefits of using thread pool are mentioned in the art of Java Concurrent Programming:
- Reduce resource consumption. Reduce the consumption caused by thread creation and destruction by reusing the created threads. (the created thread actually needs to be mapped with the thread of the operating system, which consumes resources)
- Improve response speed. When the task arrives, the task can be executed immediately without waiting for the thread to be created.
- Improve thread manageability. Threads are scarce resources. If they are created without restrictions, they will not only consume system resources, but also reduce the stability of the system. Using thread pool can carry out unified allocation, tuning and monitoring.
Custom thread pool
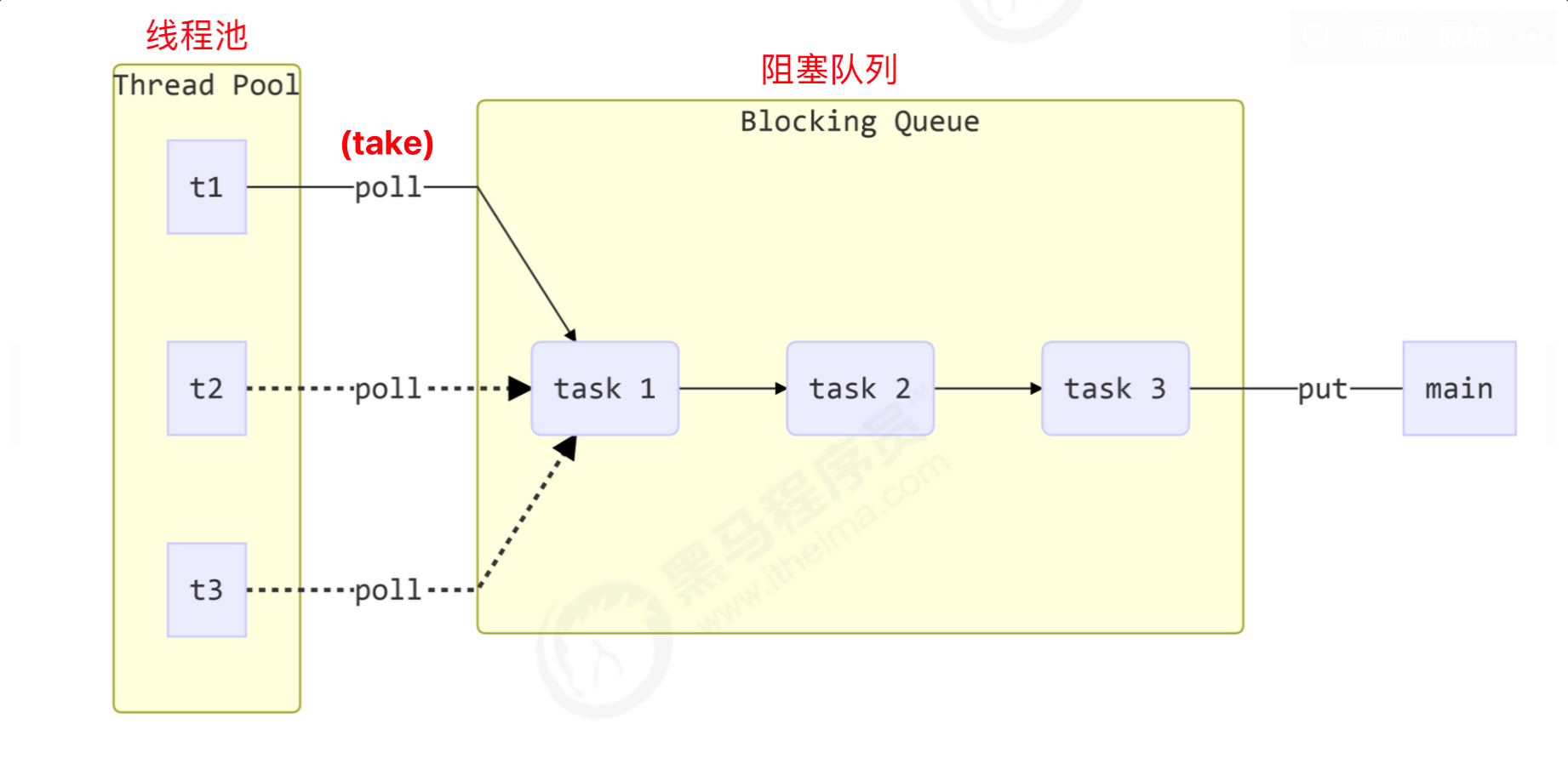
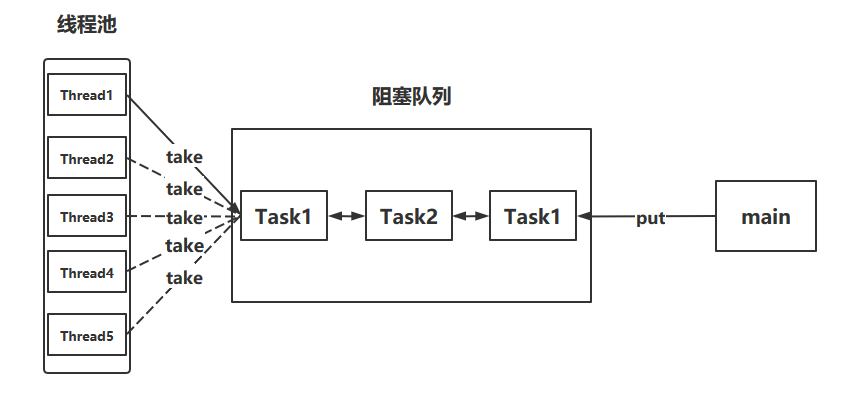
- The blocking queue maintains the tasks generated by the main thread (or other threads)
- The main thread is similar to the producer, generating tasks and putting them into the blocking queue
- The thread pool is similar to the consumer, which gets the existing tasks in the blocking queue and executes them
Implementation steps of custom thread pool:
- Step 1: customize the rejection policy interface
- Step 2: customize the task blocking queue
- Step 3: Customize thread pool
- Step 4: Test
/**
* Description: Customize a simple thread pool
*
* @author xiexu
* @create 2022-02-08 8:06 PM
*/
@Slf4j(topic = "c.TestPool")
public class TestPool {
public static void main(String[] args) {
/**
* First parameter: maximum number of threads
* Second parameter: timeout
* Third parameter: time unit
* Fourth parameter: queue capacity
*/
ThreadPool threadPool = new ThreadPool(1, 1000, TimeUnit.MILLISECONDS, 1, new RejectPolicy<Runnable>() {
@Override
public void reject(BlockingQueue<Runnable> queue, Runnable task) {
// Reject strategy
// 1. Die waiting
//queue.put(task);
// 2. Wait with timeout
queue.offer(task, 500, TimeUnit.MILLISECONDS);
// 3. Let the caller abandon the task execution
// log.debug("give up -{}", task);
// 4. Let the caller discard the exception
// throw new RuntimeException("task execution failed" + task);
// 5. Let the caller perform the task himself
// task.run();
}
});
// Create 5 tasks
for (int i = 0; i < 3; i++) {
int j = i;
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("{}", j);
}
});
}
}
}
@FunctionalInterface // Reject strategy
interface RejectPolicy<T> {
void reject(BlockingQueue<T> queue, T task);
}
/**
* Thread pool
*/
@Slf4j(topic = "c.ThreadPool")
class ThreadPool {
// Blocking task queue
private BlockingQueue<Runnable> taskQueue;
// Thread collection
private HashSet<Worker> workers = new HashSet<>();
// Number of core threads
private int coreSize;
// Gets the timeout of the task
private long timeout;
private TimeUnit timeUnit;
// Reject strategy
private RejectPolicy<Runnable> rejectPolicy;
public ThreadPool(int coreSize, long timeout, TimeUnit timeUnit, int queueCapacity, RejectPolicy<Runnable> rejectPolicy) {
this.coreSize = coreSize;
this.timeout = timeout;
this.timeUnit = timeUnit;
this.taskQueue = new BlockingQueue<>(queueCapacity);
this.rejectPolicy = rejectPolicy;
}
// Perform tasks
public void execute(Runnable task) {
synchronized (workers) {
// When the number of tasks does not exceed the number of threads, it means that the current worker thread can consume these tasks without adding them to the blocking queue
if (workers.size() < coreSize) {
Worker worker = new Worker(task);
log.debug("newly added worker {}, {}", worker, task);
// Add a newly created thread to the thread collection
workers.add(worker);
worker.start();
} else { // When the number of tasks exceeds the number of threads, they are added to the task queue for temporary storage
// taskQueue.put(task); // Only one dead wait can be set, so we can use the reject policy
// Reject strategy
// 1. Die waiting
// 2. Wait with timeout
// 3. Let the caller abandon the task execution
// 4. Let the caller discard the exception
// 5. Let the caller perform the task himself
taskQueue.tryPut(rejectPolicy, task);
}
}
}
// Thread class
class Worker extends Thread {
private Runnable task;
public Worker(Runnable task) {
this.task = task;
}
@Override
public void run() {
// Perform tasks
// 1) : when the task is not empty, execute the task
// 2) : when the task is completed, then get the task from the blocking queue and execute it
//while (task != null || (task = taskQueue.take()) != null) {
while (task != null || (task = taskQueue.poll(timeout, timeUnit)) != null) {
try {
log.debug("Executing...{}", task);
task.run();
} catch (Exception e) {
e.printStackTrace();
} finally {
// Set the executed task to null
task = null;
}
}
// Removes the current thread from the thread collection
synchronized (workers) {
log.debug("current worker Removed {}", this);
workers.remove(this);
}
}
}
}
/**
* Blocking queue for storing tasks
*
* @param <T> Runnable, The task is abstracted as Runnable
*/
@Slf4j(topic = "c.BlockingQueue")
class BlockingQueue<T> {
// 1. Task queue
private Deque<T> queue = new ArrayDeque<>();
// 2. Lock
private ReentrantLock lock = new ReentrantLock();
// 3. Producer's condition variable (when the blocking queue is full of tasks and there is no space, enter the condition variable and wait)
private Condition fullWaitSet = lock.newCondition();
// 4. Condition variable of the consumer (enter the condition variable and wait when there is no task to consume)
private Condition emptyWaitSet = lock.newCondition();
// 5. Capacity of blocking queue
private int capacity;
public BlockingQueue(int capacity) {
this.capacity = capacity;
}
// Get the task from the blocking queue. If there is no task, it will wait for the specified time
public T poll(long timeout, TimeUnit unit) {
lock.lock();
try {
// Uniformly convert timeout to nanosecond
long nanos = unit.toNanos(timeout);
while (queue.isEmpty()) {
try {
// Indicates timeout, no need to wait, and directly returns null
if (nanos <= 0) {
return null;
}
// Time of return value (the remaining time is returned) = waiting time - elapsed time, so there is no false wake-up (it refers to waking up before waiting enough, and then waiting for the same time again)
nanos = emptyWaitSet.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.removeFirst();
fullWaitSet.signal(); // Wake up the producer for production. At this time, the blocking queue is not full
return t;
} finally {
lock.unlock();
}
}
// Get the task from the blocking queue. If there is no task, it will wait all the time
public T take() {
lock.lock();
try {
// Whether the blocking queue is empty
while (queue.isEmpty()) {
// Enter the condition variable of the consumer and wait. At this time, there is no task for consumption
try {
emptyWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// The blocking queue is not empty. Get the queue header task
T t = queue.removeFirst();
fullWaitSet.signal(); // Wake up the producer for production. At this time, the blocking queue is not full
return t;
} finally {
lock.unlock(); // Release lock
}
}
// Add task to blocking queue
public void put(T task) {
lock.lock();
try {
// Determine whether the blocking queue is full
while (queue.size() == capacity) {
try {
log.debug("Waiting to join the blocking queue...");
// Enter the condition variable of the producer and wait. At this time, there is no capacity for production
fullWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// Add a new task to the queue
queue.addLast(task);
log.debug("Join task blocking queue {}", task);
emptyWaitSet.signal(); // At this time, there are tasks in the blocking queue. Wake up the consumer for consumption tasks
} finally {
lock.unlock();
}
}
// Add task to blocking queue (with timeout)
public boolean offer(T task, long timeout, TimeUnit timeUnit) {
lock.lock();
try {
long nanos = timeUnit.toNanos(timeout);
while (queue.size() == capacity) {
try {
if (nanos <= 0) {
return false;
}
log.debug("Waiting to enter the blocking queue {}...", task);
nanos = fullWaitSet.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.debug("Join task blocking queue {}", task);
queue.addLast(task);
emptyWaitSet.signal(); // At this time, there are tasks in the blocking queue. Wake up the consumer for consumption tasks
return true;
} finally {
lock.unlock();
}
}
// Get queue size
public int size() {
lock.lock();
try {
return queue.size();
} finally {
lock.unlock();
}
}
public void tryPut(RejectPolicy<T> rejectPolicy, T task) {
lock.lock();
try {
// Determine whether the queue is full
if (queue.size() == capacity) {
rejectPolicy.reject(this, task);
} else {
// Free
log.debug("Join task queue {}", task);
queue.addLast(task);
emptyWaitSet.signal(); // At this time, there are tasks in the blocking queue. Wake up the consumer for consumption tasks
}
} finally {
lock.unlock();
}
}
}
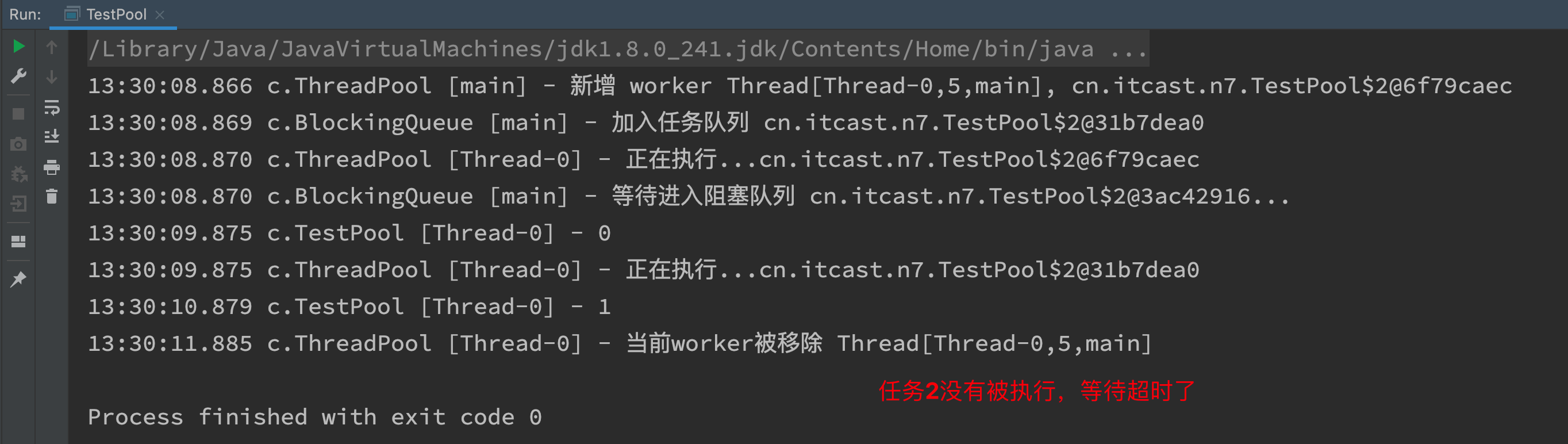
- Blocking queue BlockingQueue is used to temporarily stage tasks that are too late to be executed by threads
- It can also be said to balance the difference in execution speed between producers and consumers
- The acquisition task and put task use the producer consumer model
- The Thread is encapsulated again in the Thread pool for Worker
- When calling the run method of the task object (Runnable, Callable), the thread will execute the task. After execution, it will get a new task from the blocking queue for execution
- The main method of executing tasks in the thread pool is the execute method
- When executing, judge whether the number of executing threads is greater than the thread pool capacity
ThreadPoolExecutor
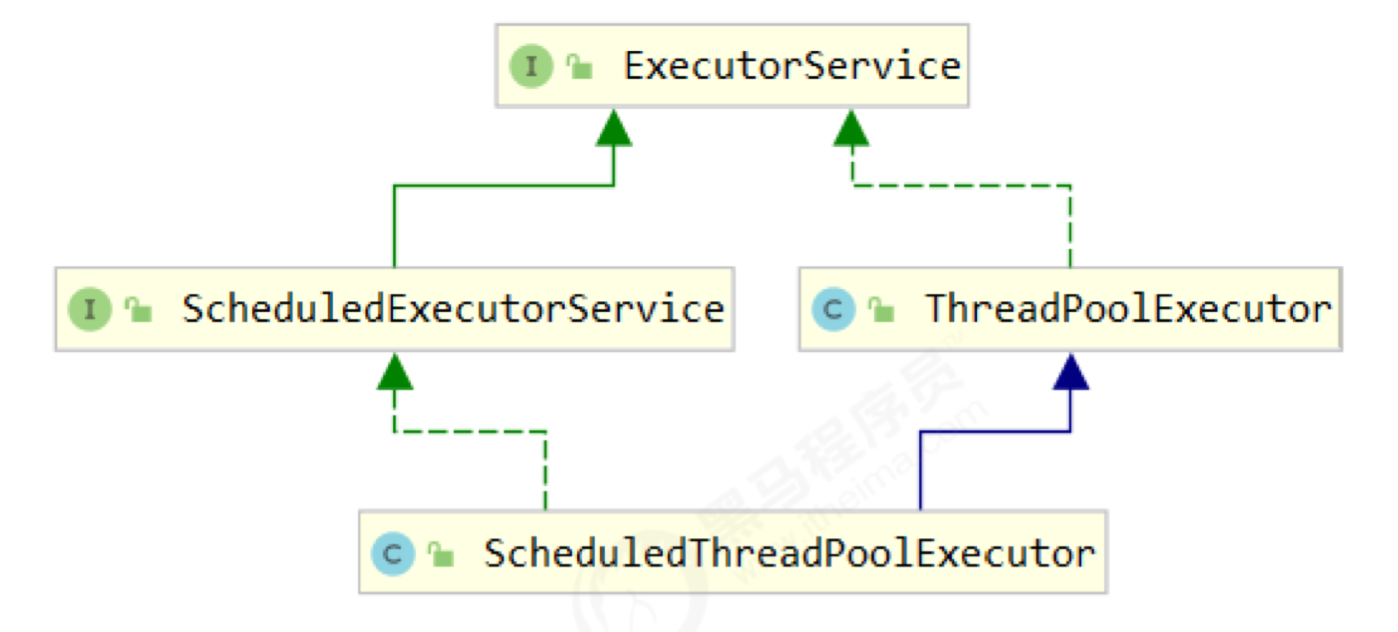
Thread pool state
ThreadPoolExecutor uses the upper 3 bits of int to indicate the thread pool status and the lower 29 bits to indicate the number of threads
// Thread pool status // runState is stored in the high-order bits // The upper 3 bits of RUNNING are 111 private static final int RUNNING = -1 << COUNT_BITS; // The upper 3 bits of SHUTDOWN are 000 private static final int SHUTDOWN = 0 << COUNT_BITS; // High 3 digit 001 private static final int STOP = 1 << COUNT_BITS; // High 3 digits 010 private static final int TIDYING = 2 << COUNT_BITS; // High 3 digits 011 private static final int TERMINATED = 3 << COUNT_BITS;
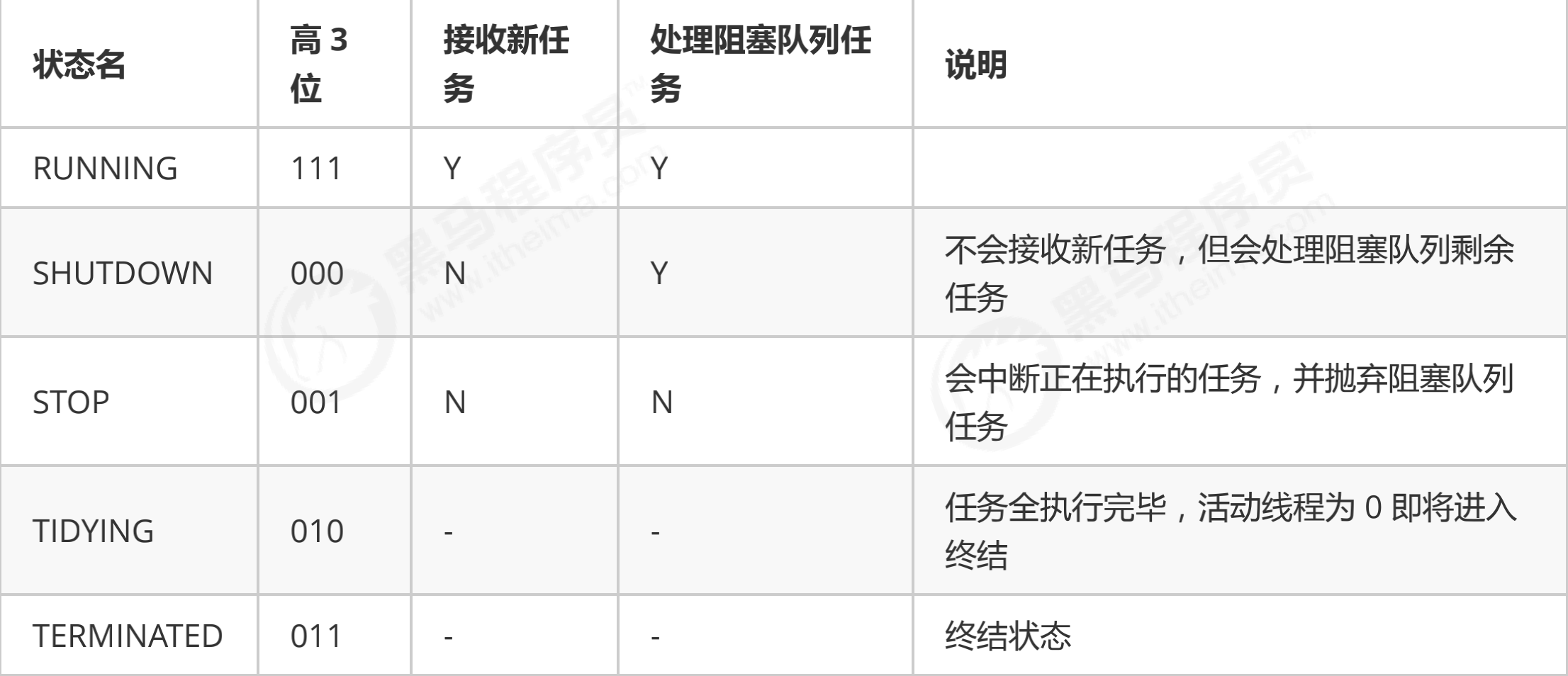
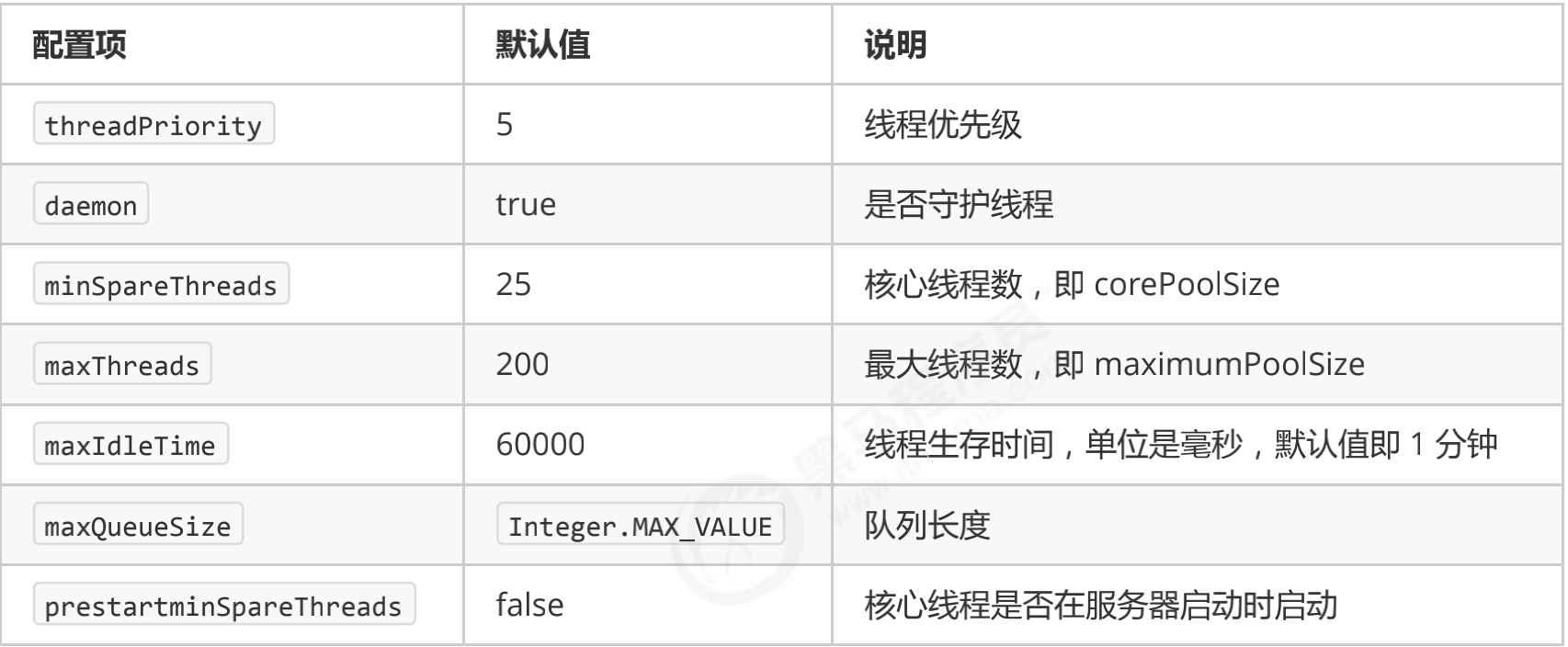
| Status name | Value of the upper 3 bits | describe |
|---|---|---|
| RUNNING | 111 | Receive new tasks and process tasks in the task queue at the same time |
| SHUTDOWN | 000 | Do not accept new tasks, but process tasks in the task queue |
| STOP | 001 | Interrupt the task in progress and discard the task in the blocking queue |
| TIDYING | 010 | When the task is completed and the active thread is 0, it will enter the termination stage |
| TERMINATED | 011 | End state |
- Numerically, terminated > tidying > stop > shutdown > running
The thread pool status and the number of threads in the thread pool are represented by an atomic integer ctl
- The main reason for using a number to represent two values is that the values of two attributes can be changed at the same time through a CAS
// Atomic integer. The first three bits store the state of the thread pool, and the remaining bits store the number of threads private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); // Not all platforms have 32-bit int s. // Remove the first three bits to save the thread status, and the rest is used to save the number of threads // The upper 3 digits are 0, and the remaining digits are all 1 private static final int COUNT_BITS = Integer.SIZE - 3; // 2^COUNT_BITS power, indicating the maximum number of threads that can be saved // The upper 3 bits of capability are 0 private static final int CAPACITY = (1 << COUNT_BITS) - 1;
- Get the thread pool status, the number of threads, and the operation of merging the two values
// Packing and unpacking ctl
// Get running status
// This operation will change all numbers except the upper 3 bits to 0
private static int runStateOf(int c) { return c & ~CAPACITY; }
// Get the number of running threads
// This operation causes the upper 3 bits to be 0
private static int workerCountOf(int c) { return c & CAPACITY; }
// Calculate new ctl value
private static int ctlOf(int rs, int wc) { return rs | wc; }
- This information is stored in an atomic variable ctl. The purpose is to combine the thread pool state and the number of threads into one, so that it can be assigned with a CAS atomic operation
// c is the old value and ctlOf returns the new value
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))));
// rs is the upper 3 bits representing the thread pool status, wc is the lower 29 bits representing the number of threads, and ctl is to merge them
private static int ctlOf(int rs, int wc) { return rs | wc; }
Properties of thread pool
// Worker Thread, internally encapsulated Thread
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable {
...
}
// Blocking queue is used to store tasks that are too late to be executed by the core thread
private final BlockingQueue<Runnable> workQueue;
// lock
private final ReentrantLock mainLock = new ReentrantLock();
// The container used to store the core thread. The element (core thread) can be obtained only when the lock is held
private final HashSet<Worker> workers = new HashSet<Worker>();
Construction method (key)
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
- corePoolSize: number of core threads
- maximumPoolSize: maximum number of threads
- maximumPoolSize - corePoolSize = number of emergency threads
- Note: the emergency thread only uses the emergency thread when there is no idle core thread and the task queue is full
- keepAliveTime: the maximum survival time when the emergency thread is idle (the core thread can run all the time)
- Unit: time unit (for emergency thread)
- workQueue: blocking queue (storing tasks)
- Bounded blocking queue ArrayBlockingQueue
- Unbounded blocking queue LinkedBlockingQueue
- SynchronousQueue with at most one synchronization element
- Priority BlockingQueue
- threadFactory: thread factory (name the thread)
- handler: reject policy
operation mode
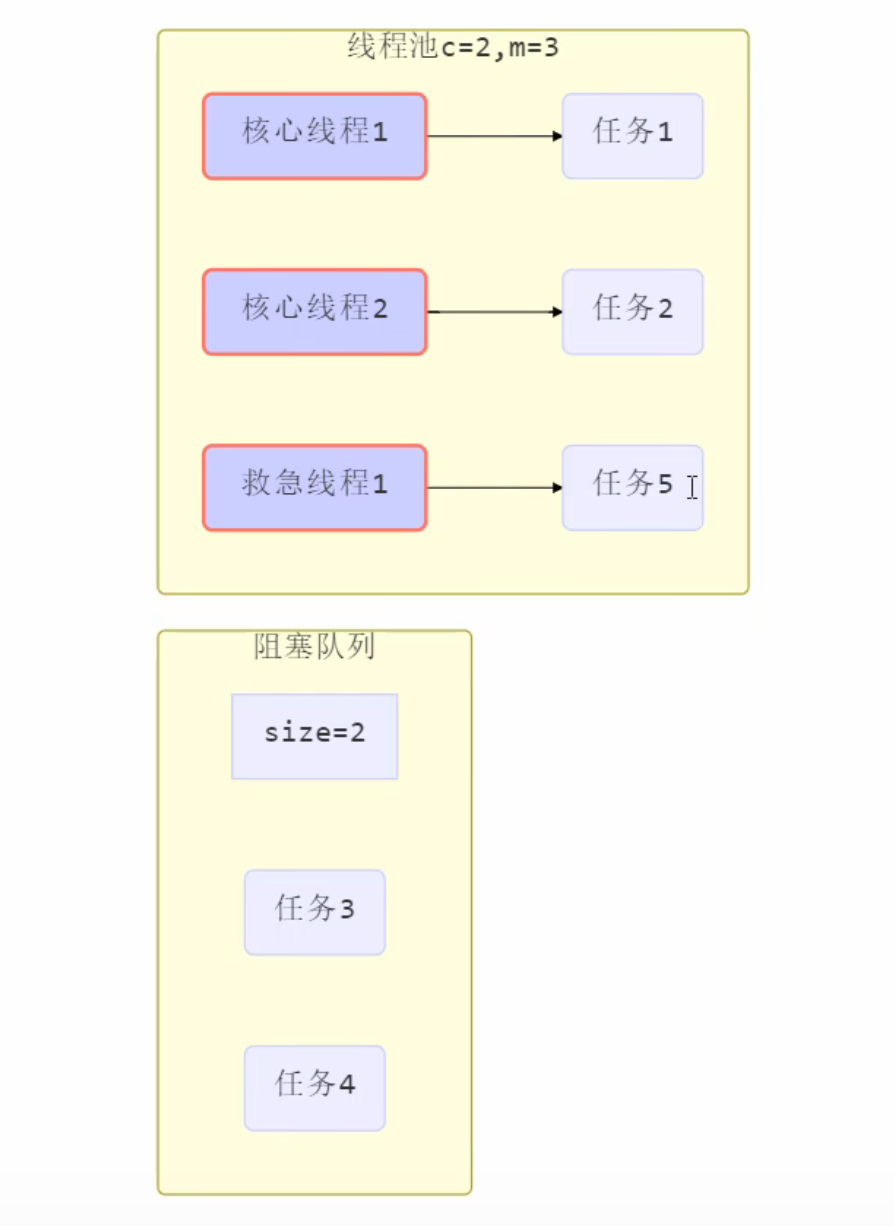
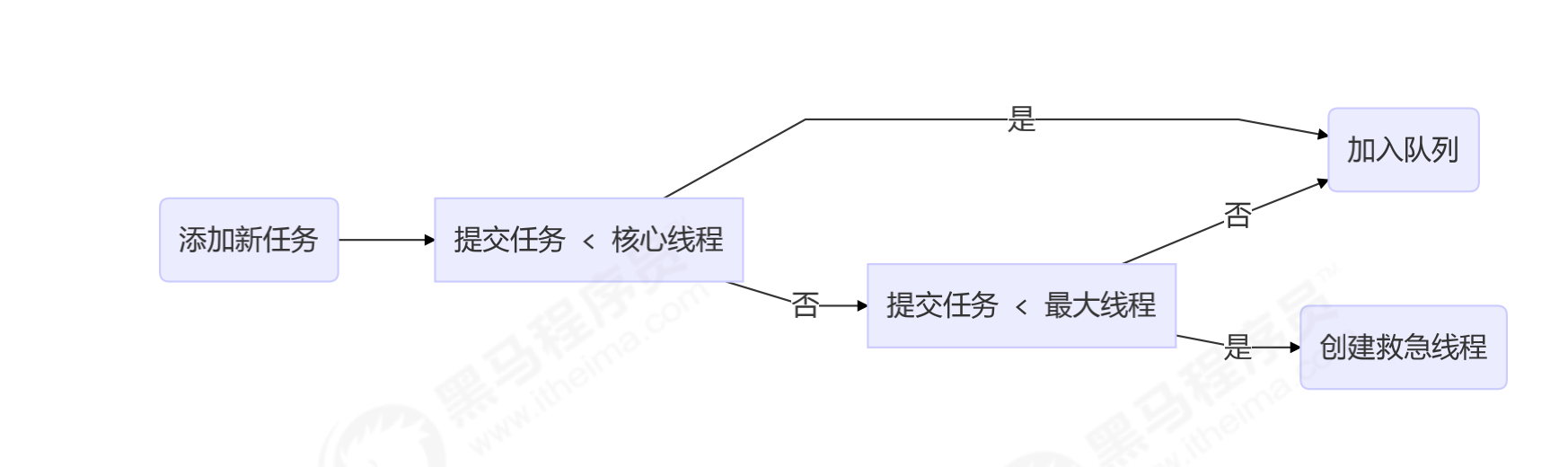
- There are no threads in the thread pool at first. When a task is submitted to the thread pool, the thread pool will create a new thread to execute the task.
- When the number of threads reaches the corePoolSize (number of core threads) and no threads are idle, if a task is added at this time, the newly added task will be added to the workQueue (blocking queue) until there are idle threads.
- If a bounded queue is selected for the queue, when the task exceeds the queue size, threads with a maximum poolsize - corepoolsize (maximum threads - core threads) number will be created for emergency rescue.
- If the number of threads reaches the maximum poolsize and there are still new tasks, the reject policy will be executed. The denial policy jdk provides four implementations, and other well-known frameworks also provide implementations
- AbortPolicy allows the caller to throw a RejectedExecutionException exception, which is the default policy
- CallerRunsPolicy lets the caller run the task
- Discard policy abandons this task
- DiscardOldestPolicy discards the earliest task in the queue and replaces it with this task
- The implementation of Dubbo will record the log and dump the thread stack information before throwing the RejectedExecutionException exception, which is convenient to locate the problem
- Netty's implementation is to create a new thread to perform tasks
- The implementation of ActiveMQ, with timeout waiting (60s), tries to put into the queue, which is similar to our previously customized rejection policy
- The implementation of PinPoint, which uses a rejection policy chain, will try each rejection policy in the policy chain one by one
- When the peak is over, the emergency threads exceeding the number of core threads need to end to save resources if they have no tasks to do for a period of time. This time is controlled by keepAliveTime and unit.

- According to this construction method, the JDK Executors class provides many factory methods to create thread pools for various purposes
operation mode
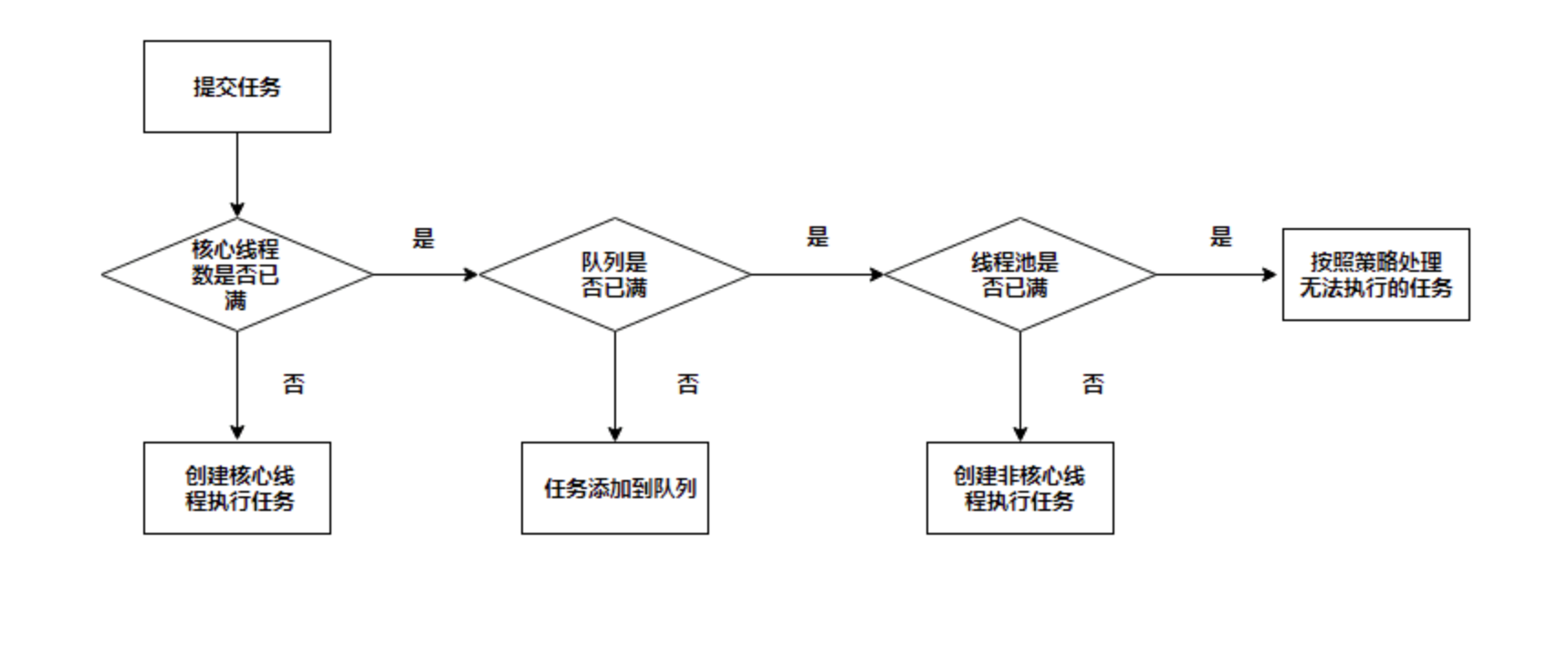
- After a task is transferred to the thread pool, there may be the following possibilities
- Assign tasks to a core thread to execute
- The core threads are executing tasks. They put the tasks into the blocking queue workQueue and wait for them to be executed
- When the blocking queue is full, use the emergency thread to execute the task
- After the emergency thread is used up, it will be released after the keepAliveTime
- When the total number of tasks is greater than the maximum number of threads (maximumPoolSize) and the maximum capacity of the blocking queue (workQueue.capacity), the reject policy is used
Reject strategy
- If the number of threads reaches the maximum poolsize and there are still new tasks, the reject policy will be executed. The denial policy jdk provides four implementations

- Pithy formula: refuse to lose the old tune
- (thread pool rejection policy: abort policy, discard policy, discard policy, caller run policy)
- Simple answer:
- Abort strategy: no special scenarios.
- Discard strategy: unimportant tasks (blog reading).
- Abandon the old strategy: release news.
- Caller running strategy: no failure scenario is allowed (low performance requirements and low concurrency).
AbortPolicy abort policy: discard the task and throw RejectedExecutionException. This is the default policy
- This is the default rejection policy of the thread pool. When the task can no longer be submitted, throw an exception and feed back the running state of the program in time. If it is a key business, it is recommended to use this rejection strategy, so that when the subsystem cannot bear a larger amount of concurrency, it can find exceptions in time.
- Function: when the reject policy is triggered, the exception of reject execution will be thrown directly. The meaning of aborting the policy is to interrupt the current execution process
- Usage scenario: there is no special scenario, but one thing is to correctly handle the exceptions thrown. The default policy in ThreadPoolExecutor is AbortPolicy. This is the default policy for ThreadPoolExecutor series of ExecutorService interface because there is no set rejection policy displayed. However, please note that the thread pool instance queue in ExecutorService is unbounded, that is, exploding the memory will not trigger the rejection policy. When you customize the thread pool instance, when using this strategy, you must deal with the exception thrown when triggering the policy, because it will interrupt the current execution process.
Discard policy: discard the task without throwing an exception. If the thread queue is full, subsequent submitted tasks will be discarded silently.
- Using this strategy may prevent us from discovering the abnormal state of the system. The suggestion is that some unimportant businesses adopt this strategy. For example, this rejection strategy is used by my blog website to count the reading volume.
- Function: directly and quietly discard this task without triggering any action.
- Usage scenario: if the task you submit is irrelevant, you can use it. Because it is an empty realization, it will quietly devour your task. So this strategy is basically not used.
Discard oldest policy: discard the task at the top of the queue and resubmit the rejected task.
- This rejection strategy is a rejection strategy that likes the new and hates the old. Whether to adopt this rejection strategy must be carefully measured according to whether the actual business allows the abandonment of old tasks.
- Function: if the thread pool is not closed, pop up the element at the head of the queue, and then try to execute
- Usage scenario: this strategy will still discard tasks, and there is no sound when discarding, but it is characterized by discarding old unexecuted tasks and tasks with high priority to be executed. Based on this feature, the thought scenario is to publish messages and modify messages. After the messages are published, they have not been executed. At this time, the updated messages come again. At this time, the version of the unexecuted messages is lower than that of the submitted messages, and they can be discarded. Because there may be messages with lower message versions in the queue that will be queued for execution, it is necessary to compare the versions of messages when actually processing messages.
CallerRunsPolicy caller run policy: this task is handled by the calling thread.
- Function: when the reject policy is triggered, as long as the thread pool is not closed, it will be processed by the current thread submitting the task.
- Usage scenario: it is generally used in scenarios where failure is not allowed, performance requirements are not high and concurrency is small, because the thread pool will not be closed in general, that is, the submitted task will be run. However, because it is executed by the caller thread itself, when the task is submitted many times, the execution of subsequent tasks will be blocked, and the performance and efficiency will naturally be slow.
newFixedThreadPool
Construction method of internal call
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
- characteristic
- Number of core threads = maximum number of threads (no emergency threads were created), so there is no timeout
- The blocking queue is unbounded and can hold any number of tasks
- It is applicable to tasks with known amount of tasks and relatively time-consuming
This is the factory method provided by executors class to create thread pool! Executors is a tool class of the Executor framework!
/**
* @author xiexu
* @create 2022-02-09 4:09 PM
*/
@Slf4j(topic = "c.TestThreadPoolExecutors")
public class TestThreadPoolExecutors {
public static void main(String[] args) {
// Create a thread pool with 2 core threads
// ThreadFactory allows you to add a name to a thread
ExecutorService pool = Executors.newFixedThreadPool(2, new ThreadFactory() {
private AtomicInteger t = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "mypool_t" + t.getAndIncrement());
}
});
pool.execute(() -> {
log.debug("1");
});
pool.execute(() -> {
log.debug("2");
});
pool.execute(() -> {
log.debug("3");
});
}
}
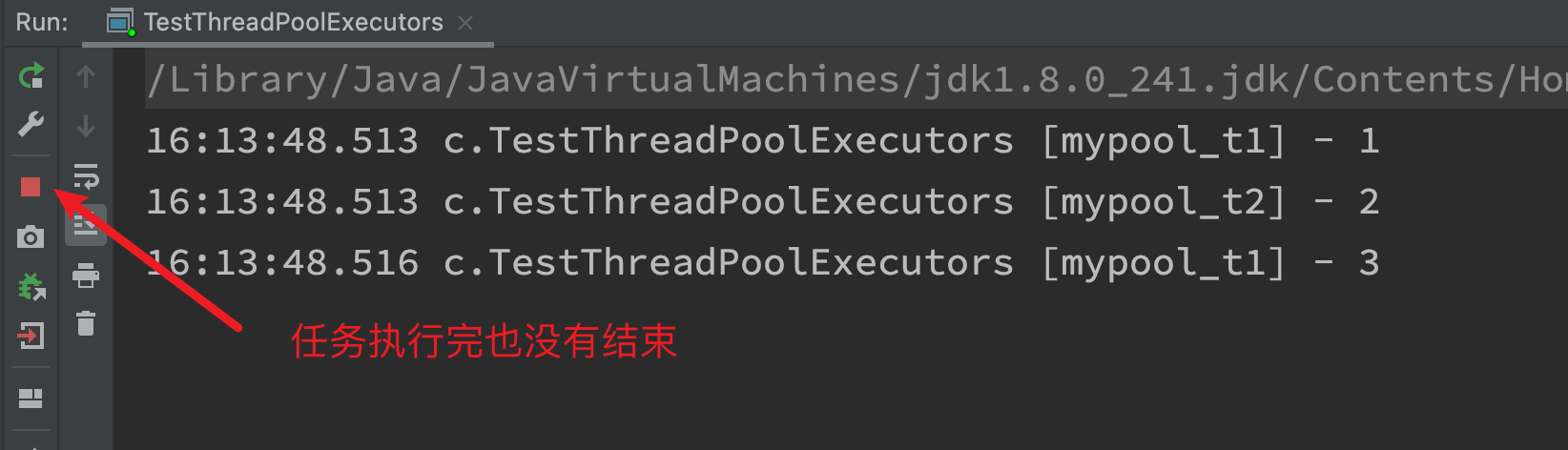
- The thread pool size is 2 and 3 tasks. After t1 thread executes 1, it executes 3
- The created threads are all non daemon threads by default, and the main thread does not end after execution
newCachedThreadPool
Internal construction method
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
- There is no core thread, and the maximum number of threads is integer MAX_ Value, all created threads are emergency threads (can be created indefinitely), and the idle survival time is 60 seconds
- The blocking queue uses synchronous queue
- Synchronous queue is a special kind of queue
- There is no capacity and no thread to pick it up. You can't put it in (hand in money and hand in delivery)
- Only when a thread fetches a task will it put the task into the blocking queue
- Synchronous queue is a special kind of queue
- The whole thread pool shows that the number of threads will increase continuously according to the number of tasks, and there is no upper limit. When the task is completed, the threads will be released after being idle for 1 minute.
- It is suitable for the situation that the number of tasks is relatively intensive, but the execution time of each task is short
SynchronousQueue demo
@Slf4j(topic = "c.TestSynchronousQueue")
public class TestSynchronousQueue {
public static void main(String[] args) {
SynchronousQueue<Integer> integers = new SynchronousQueue<>();
new Thread(() -> {
try {
log.debug("putting {} ", 1);
integers.put(1);
log.debug("{} putted...", 1);
log.debug("putting...{} ", 2);
integers.put(2);
log.debug("{} putted...", 2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t1").start();
sleep(1);
new Thread(() -> {
try {
log.debug("taking {}", 1);
integers.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t2").start();
sleep(1);
new Thread(() -> {
try {
log.debug("taking {}", 2);
integers.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t3").start();
}
}
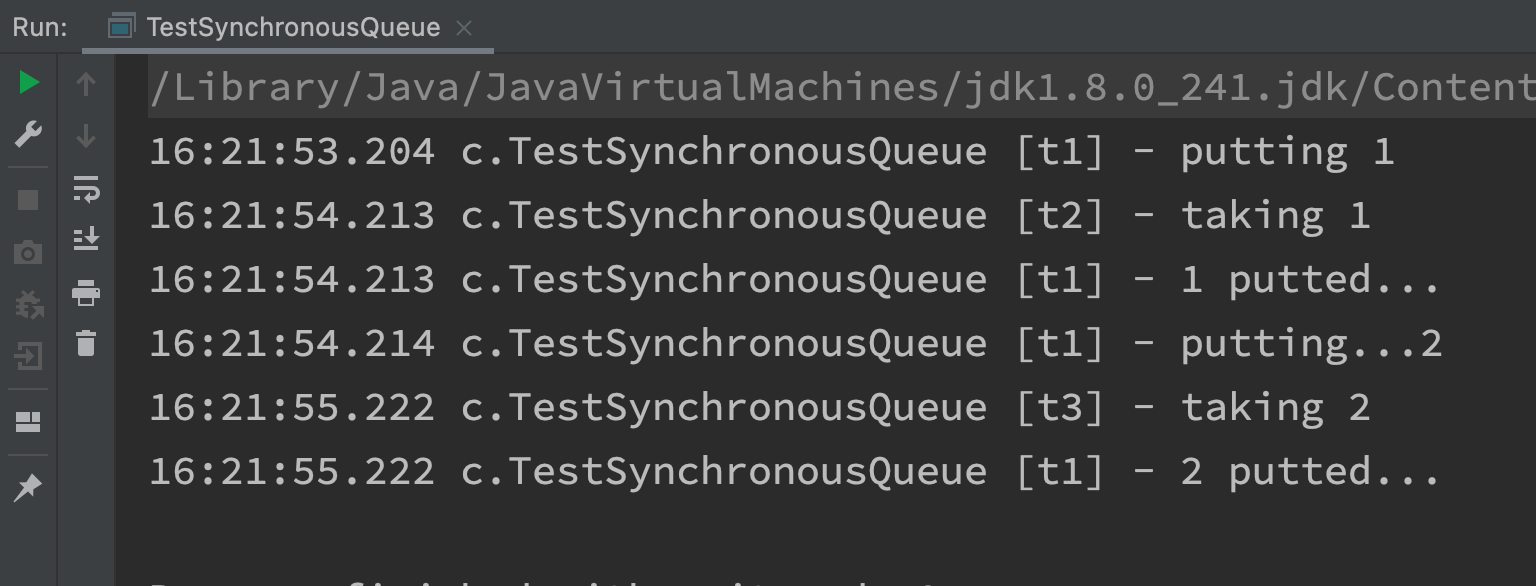
- The thread pool is created with newCachedThreadPool(), and the implementation of its blocking queue is synchronous queue.
- The initial maximum number of threads in the thread pool is the maximum value of Integer, but all are emergency threads, and threads are lazy initialization (that is, not all threads will be created at the beginning, but so many threads can be created when used)
- Then, the capacity of the blocking queue is empty. If there is no thread to get it, it can not be stored in it. It plays a buffer role and there is no need to block at all, because the emergency thread has no upper limit, so it can get your task away soon.
- When the thread task in the thread pool is completed, the emergency thread created before will be released after being idle for 1 minute.
newSingleThreadExecutor
Internal construction method
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
Usage scenario:
- Multiple tasks are expected to be queued. The number of threads is fixed to 1; When the number of tasks is more than 1, it will be put into an unbounded queue. When the task is completed, the only thread will not be released.
difference:
- Create a single thread serial execution task by yourself. If the task fails to execute and terminates, there is no remedy. The newSingleThreadExecutor thread pool will also create a new thread to ensure the normal operation of the pool
- Executors. The number of threads of newsinglethreadexecutor() is always 1 and cannot be modified
- FinalizableDelegatedExecutorService applies the decorator mode, which only exposes the ExecutorService interface, so it cannot call the unique methods in ThreadPoolExecutor
- Executors.newFixedThreadPool(1) is initially 1 and can be modified later
- External exposure is ThreadPoolExecutor object, which can be changed by calling setCorePoolSize and other methods.
Code example
public static void test2() {
ExecutorService pool = Executors.newSingleThreadExecutor();
pool.execute(() -> {
log.debug("1");
int i = 1 / 0;
});
pool.execute(() -> {
log.debug("2");
});
pool.execute(() -> {
log.debug("3");
});
}
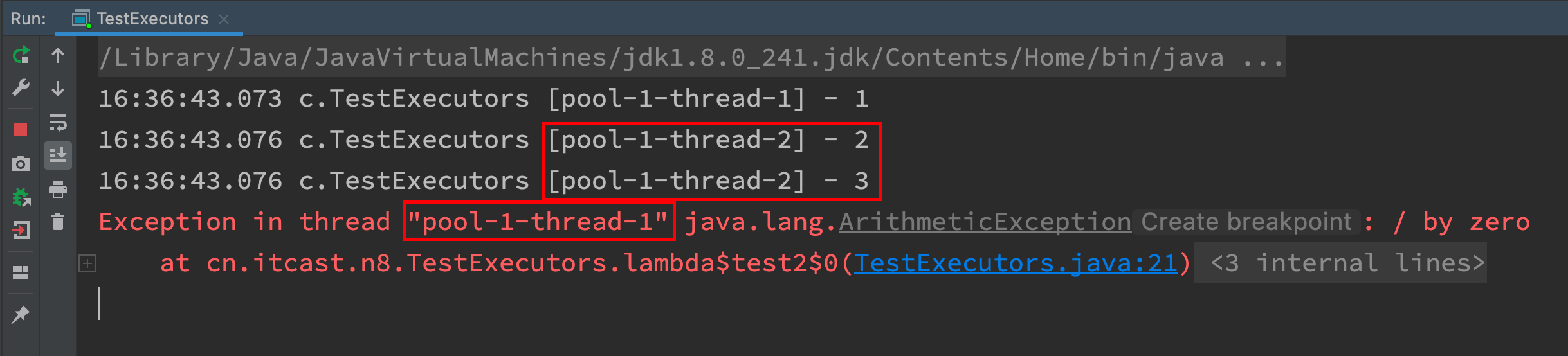
- After thread 1 hangs up, a new thread 2 is created to perform tasks, and always ensure that there is an available thread in the thread pool.
The disadvantages of Executors returning thread pool objects are as follows (key points)
Note: the disadvantages of Executors returning thread pool objects are as follows:
- FixedThreadPool and singlethreadexecution: the queue length allowed for requests is integer MAX_ Value (unbounded blocking queue), which may accumulate a large number of requests, resulting in OOM.
- CachedThreadPool and ScheduledThreadPool: number of threads allowed to be created integer MAX_ Value, a large number of threads may be created, resulting in OOM.
- It is recommended to use ThreadPoolExecutor to create threads
Avoid the above measures: use bounded queues to control the number of threads created.
execute/submit task
// Perform tasks void execute(Runnable command); // Submit the task and use the return value Future to obtain the task execution result. The principle of Future is to accept the returned result by using the protective pause mode we mentioned earlier. The main thread can execute futuretask Get () method to wait for the task execution to complete <T> Future<T> submit(Callable<T> task); // Submit all tasks in tasks <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException; // Submit all tasks in tasks with timeout <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit) throws InterruptedException; // Submit all tasks in the tasks. Which task is successfully executed first will return the execution result of this task, and other tasks will be cancelled <T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException; // Submit all tasks in the tasks. Which task is successfully executed first will return the execution result of this task. Other tasks will be cancelled with timeout <T> T invokeAny(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
execute() method
execute(Runnable command)
- Pass in a Runnable object and execute the run method in it
- Source code analysis
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
// Get ctl
int c = ctl.get();
// Judge whether the number of currently enabled threads is less than the number of core threads
if (workerCountOf(c) < corePoolSize) {
// Assign a thread to the task
if (addWorker(command, true))
// Return if the allocation is successful
return;
// Failed to allocate. Get ctl again
c = ctl.get();
}
// After allocation and information thread failure
// If the pool status is RUNNING and the insertion into the task queue is successful
if (isRunning(c) && workQueue.offer(command)) {
// Double detection. The thread pool status may change to non RUNNING after adding
int recheck = ctl.get();
// If the pool status is non RUNNING, the new task will not be executed
// Remove the task from the blocking queue
if (! isRunning(recheck) && remove(command))
// Call the reject policy to reject the execution of the task
reject(command);
// If there are no running threads
else if (workerCountOf(recheck) == 0)
// A new thread is created to perform the task
addWorker(null, false);
}
// If the addition fails (the task queue is full), the reject policy is invoked
else if (!addWorker(command, false))
reject(command);
}
- The **addWoker() * method is called. Let's take a look at this method.
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
// If the pool state is non RUNNING, the thread pool is SHUTDOWN and the task is empty, or there are tasks in the blocking queue
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
// Failed to create new thread
return false;
for (;;) {
// Gets the current number of worker threads
int wc = workerCountOf(c);
// core in parameter is true
// Capability is 1 < < count_ Bits-1, generally not more than
// If the number of worker threads is greater than the number of core threads, the creation fails
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// Change the value of c through CAS operation
if (compareAndIncrementWorkerCount(c))
// If the change is successful, it will jump out of multiple loops and no longer run the loop
break retry;
// Failed to change, get ctl value again
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
// Jump out of multiple loops and re-enter the loop
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
// Used to mark whether the task in work is successfully executed
boolean workerStarted = false;
// Used to mark whether the worker has successfully joined the thread pool
boolean workerAdded = false;
Worker w = null;
try {
// Create a new thread to perform the task
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
// Lock
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
// Detect again while locking
// Avoid calling shut down before releasing the lock.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
// Add thread to thread pool
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
// Add success flag bit becomes true
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// If the worker successfully joins the thread pool, it will execute the tasks in it
if (workerAdded) {
t.start();
// Start successful
workerStarted = true;
}
}
} finally {
// If execution fails
if (! workerStarted)
// Call the function that failed to add
addWorkerFailed(w);
}
return workerStarted;
}
submit() method
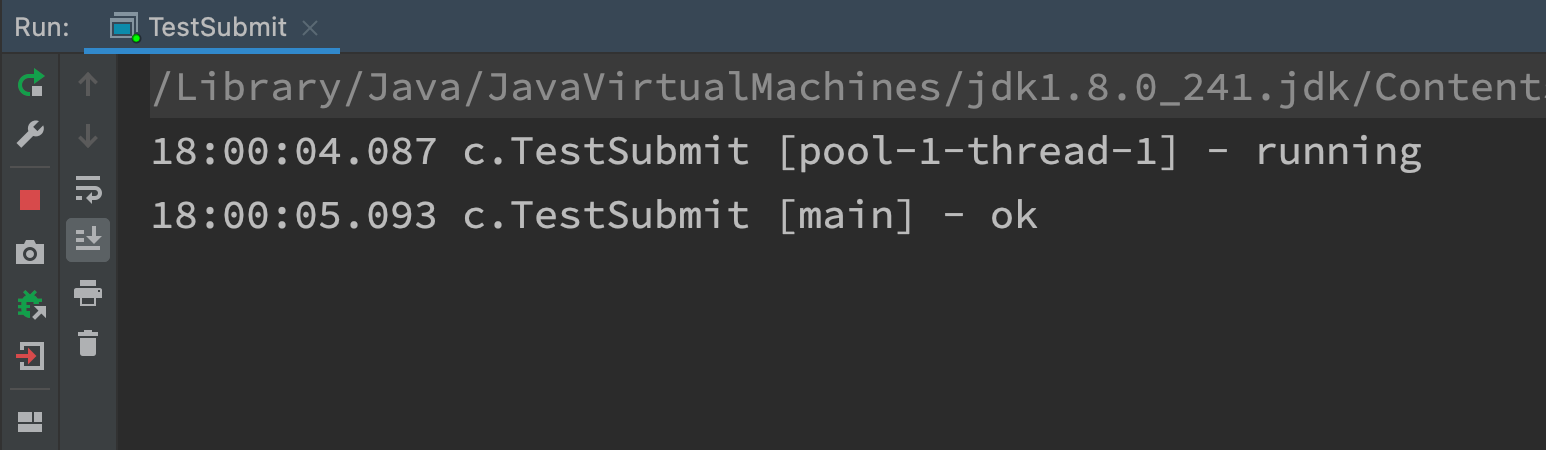
Future<T> submit(Callable<T> task)
- Pass in a Callable object and use Future to capture the return value
private static void method1(ExecutorService pool) throws InterruptedException, ExecutionException {
// Execute the call method in Callable through submit
// Capture the return value through Future
Future<String> future = pool.submit(new Callable<String>() {
@Override
public String call() throws Exception {
log.debug("running");
Thread.sleep(1000);
return "ok";
}
});
log.debug("{}", future.get());
}
invokeAll
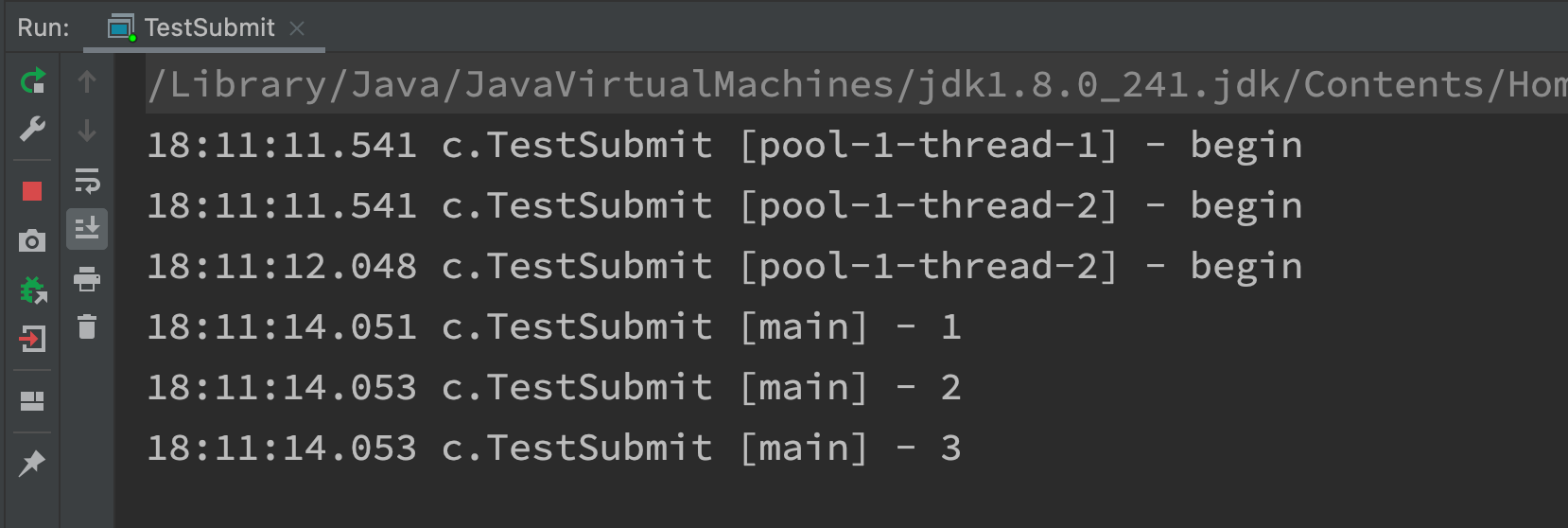
private static void method2(ExecutorService pool) throws InterruptedException {
List<Future<String>> futures = pool.invokeAll(Arrays.asList(() -> {
log.debug("begin");
Thread.sleep(1000);
return "1";
}, () -> {
log.debug("begin");
Thread.sleep(500);
return "2";
}, () -> {
log.debug("begin");
Thread.sleep(2000);
return "3";
}));
futures.forEach(f -> {
try {
log.debug("{}", f.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
}
invokeAny
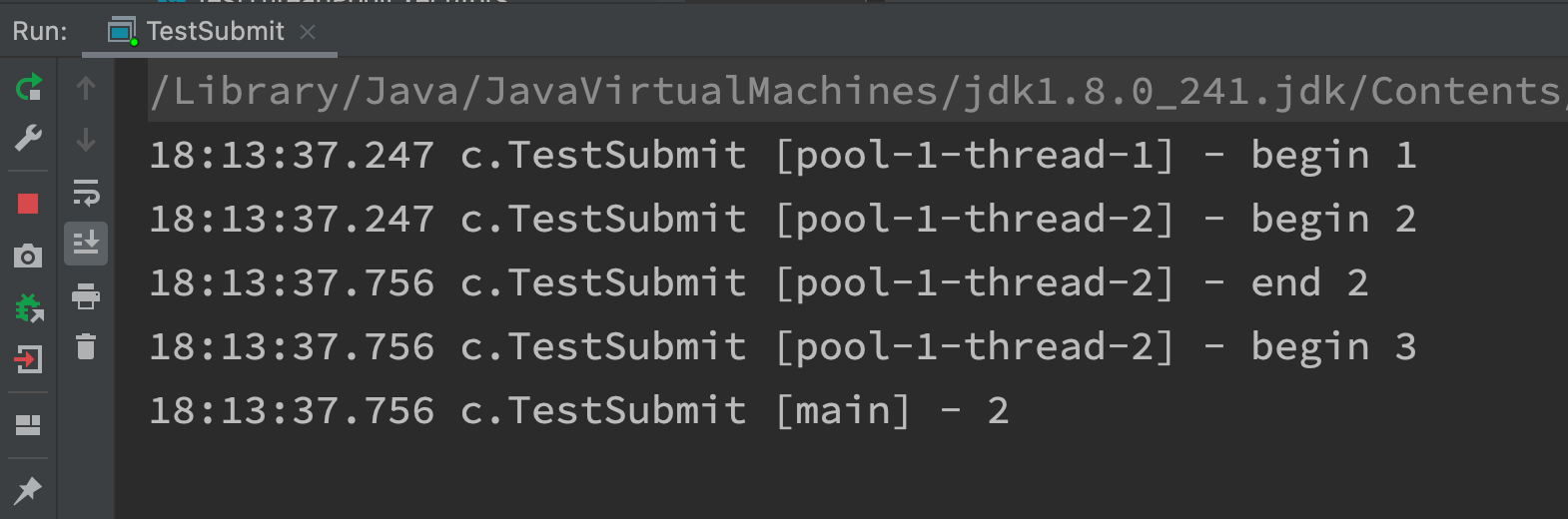
private static void method3(ExecutorService pool) throws InterruptedException, ExecutionException {
String result = pool.invokeAny(Arrays.asList(() -> {
log.debug("begin 1");
Thread.sleep(1000);
log.debug("end 1");
return "1";
}, () -> {
log.debug("begin 2");
Thread.sleep(500);
log.debug("end 2");
return "2";
}, () -> {
log.debug("begin 3");
Thread.sleep(2000);
log.debug("end 3");
return "3";
}));
log.debug("{}", result);
}
Close thread pool shutdown()
shutdown( )
- Change the status of the thread pool to SHUTDOWN
- No new tasks will be accepted, but the tasks in the blocking queue will be completed
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// Modify thread pool status
advanceRunState(SHUTDOWN);
// Only idle threads are interrupted
interruptIdleWorkers();
// Extension point ScheduledThreadPoolExecutor
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
// Try to terminate (threads that are not running can be terminated immediately, and if there are still running threads, they will not wait)
tryTerminate();
}
shutdownNow( )
- Change the status of the thread pool to STOP
- No new tasks will be accepted, and no tasks in the blocking queue will be executed
- The unexecuted tasks in the blocking queue are returned to the caller
- And interrupt the executing task in the way of interrupt
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// The modification status is STOP and no tasks are performed
advanceRunState(STOP);
// Interrupt all threads
interruptWorkers();
// The unexecuted task is removed from the queue and returned to the caller
tasks = drainQueue();
} finally {
mainLock.unlock();
}
// The attempt to terminate is sure to succeed because the blocking queue is empty
tryTerminate();
return tasks;
}
Other methods
// If the thread pool is not in the RUNNING state, this method returns true boolean isShutdown(); // Is the thread pool status TERMINATED boolean isTerminated(); // After the shutdown is called, because the method of calling to end the thread is asynchronous, it will not return after all tasks are completed, // Therefore, if it wants to do something else after the process pool is TERMINATED, it can use this method to wait boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
Code example
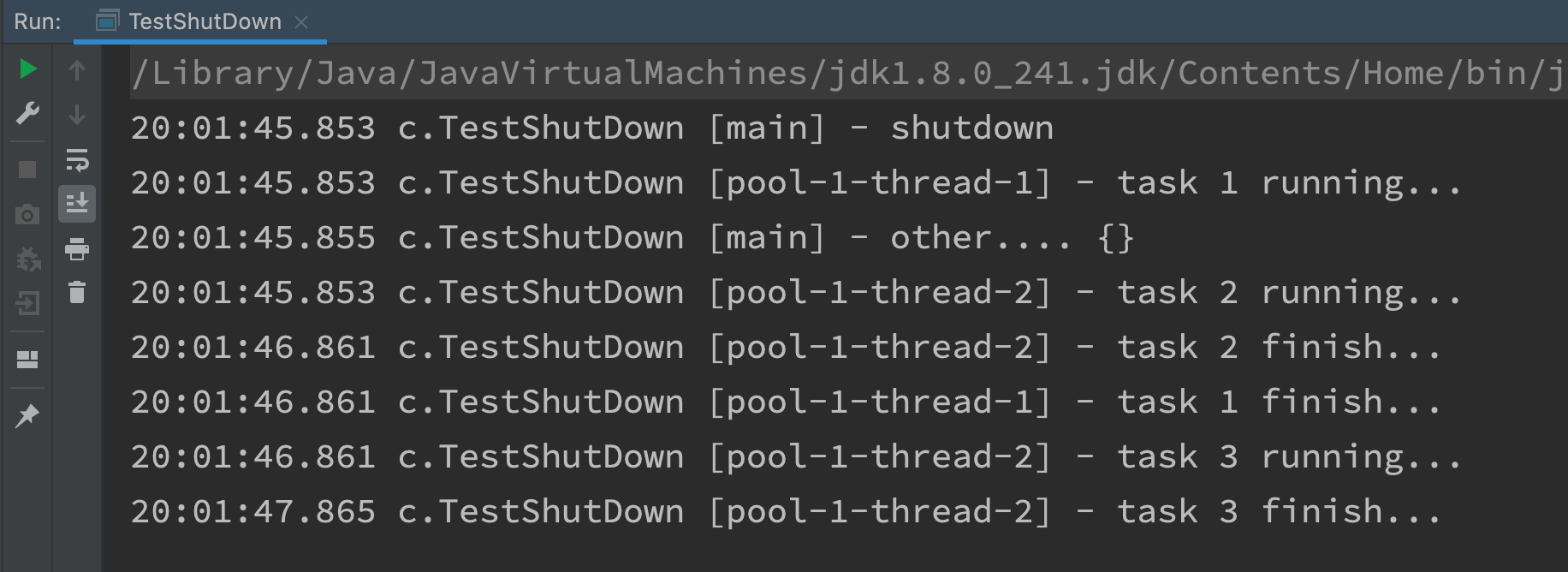
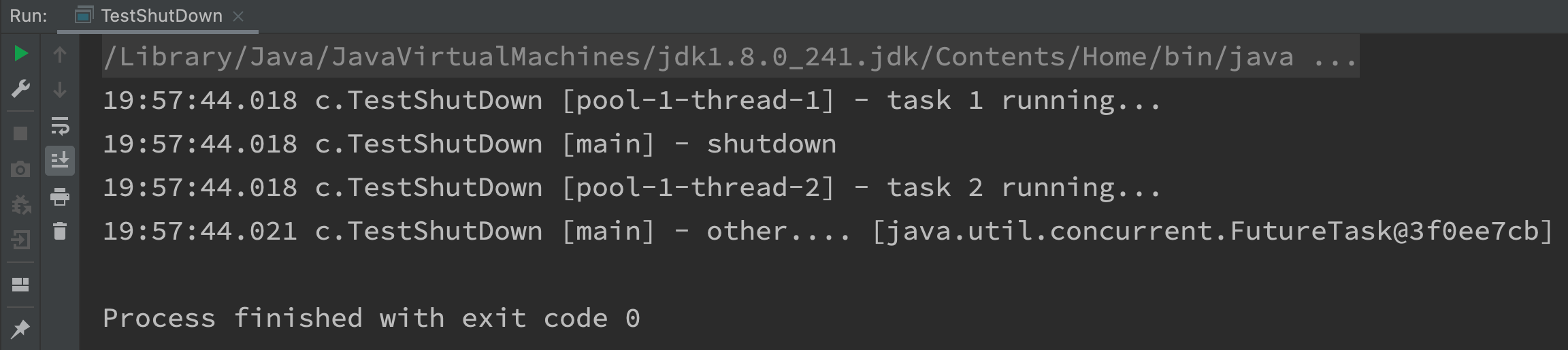
@Slf4j(topic = "c.TestShutDown")
public class TestShutDown {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService pool = Executors.newFixedThreadPool(2);
Future<Integer> result1 = pool.submit(() -> {
log.debug("task 1 running...");
Thread.sleep(1000);
log.debug("task 1 finish...");
return 1;
});
Future<Integer> result2 = pool.submit(() -> {
log.debug("task 2 running...");
Thread.sleep(1000);
log.debug("task 2 finish...");
return 2;
});
Future<Integer> result3 = pool.submit(() -> {
log.debug("task 3 running...");
Thread.sleep(1000);
log.debug("task 3 finish...");
return 3;
});
log.debug("shutdown");
// pool.shutdown();
// pool.awaitTermination(3, TimeUnit.SECONDS);
List<Runnable> runnables = pool.shutdownNow();
log.debug("other.... {}", runnables);
}
}
shutdown output
shotdownNow output
Asynchronous mode worker thread
definition
- Let a limited number of worker threads take turns to handle an unlimited number of tasks asynchronously. It can also be classified as division of labor mode. Its typical implementation is thread pool, which also reflects the sharing mode in the classical design mode.
- For example, the waiter (thread) of Haidilao handles each guest's order (task) in turn. If each guest is equipped with a dedicated waiter, the cost is too high (compared with another multi-threaded design mode: thread per message)
- Note that different task types should use different thread pools, which can avoid hunger and improve efficiency
- For example, if a restaurant worker has to greet guests (task type A) and cook in the back kitchen (task type B), it is obviously inefficient. It is more reasonable to divide into waiter (thread pool a) and chef (thread pool B). Of course, you can think of a more detailed division of labor
hunger
Fixed size thread pool will be hungry
- Two workers are two threads in the same thread pool
- What they have to do is: order for the guests and cook in the back kitchen, which are two stages of work
- Guests' ordering: they must finish ordering first, wait for the dishes to be ready and serve. During this period, the workers handling the ordering must wait
- Kitchen cooking: nothing to say, just do it
- For example, worker A handled the order task, and then he had to wait for worker B to finish the dishes and serve them. They also cooperated very well
- At this time, the worker A and the guest B are hungry, but it's time for them to cook at the same time, but both of them don't come
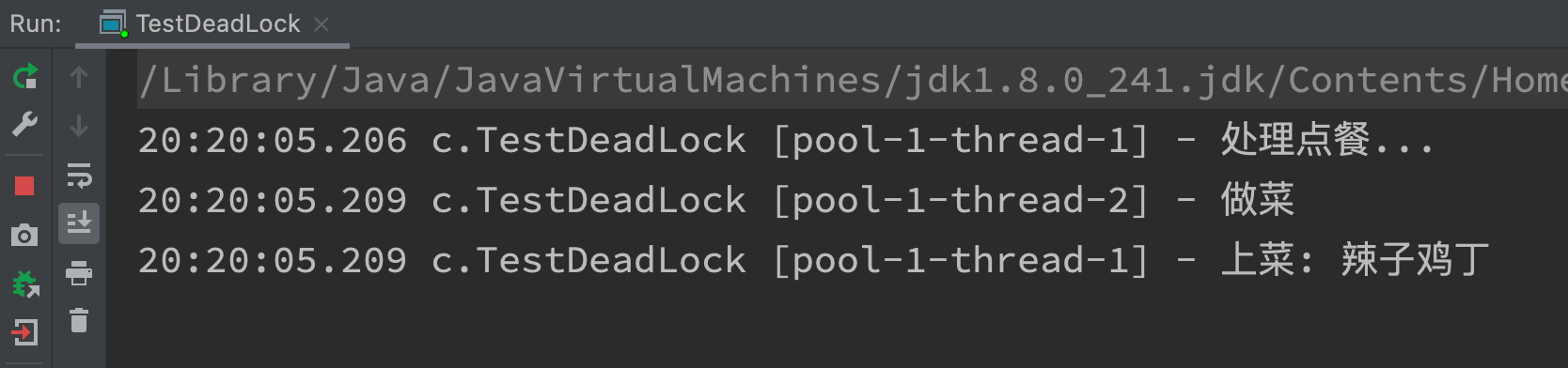
Hunger example
@Slf4j(topic = "c.TestDeadLock")
public class TestDeadLock {
static final List<String> MENU = Arrays.asList("Sauteed Potato, Green Pepper and Eggplant", "Kung Pao Chicken", "Sauteed Chicken Dices with Chili Peppers", "Roast chicken wings");
static Random RANDOM = new Random();
static String cooking() {
return MENU.get(RANDOM.nextInt(MENU.size()));
}
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(2);
pool.execute(() -> {
log.debug("Process order...");
Future<String> future = pool.submit(() -> {
log.debug("cook a dish");
return cooking();
});
try {
log.debug("Serve: {}", future.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
// pool.execute(() -> {
// log.debug("process order...);
// Future<String> future = pool.submit(() -> {
// log.debug("cooking");
// return cooking();
// });
// try {
// log.debug("serving: {}", future.get());
// } catch (InterruptedException | ExecutionException e) {
// e.printStackTrace();
// }
// });
}
}
There is only one guest, thread 1 is responsible for ordering and serving, and thread 2 is responsible for cooking
When the comment is cancelled, it is equivalent to two guests, thread 1 and thread 2, go to order, and no one is cooking. At this time, hunger occurs

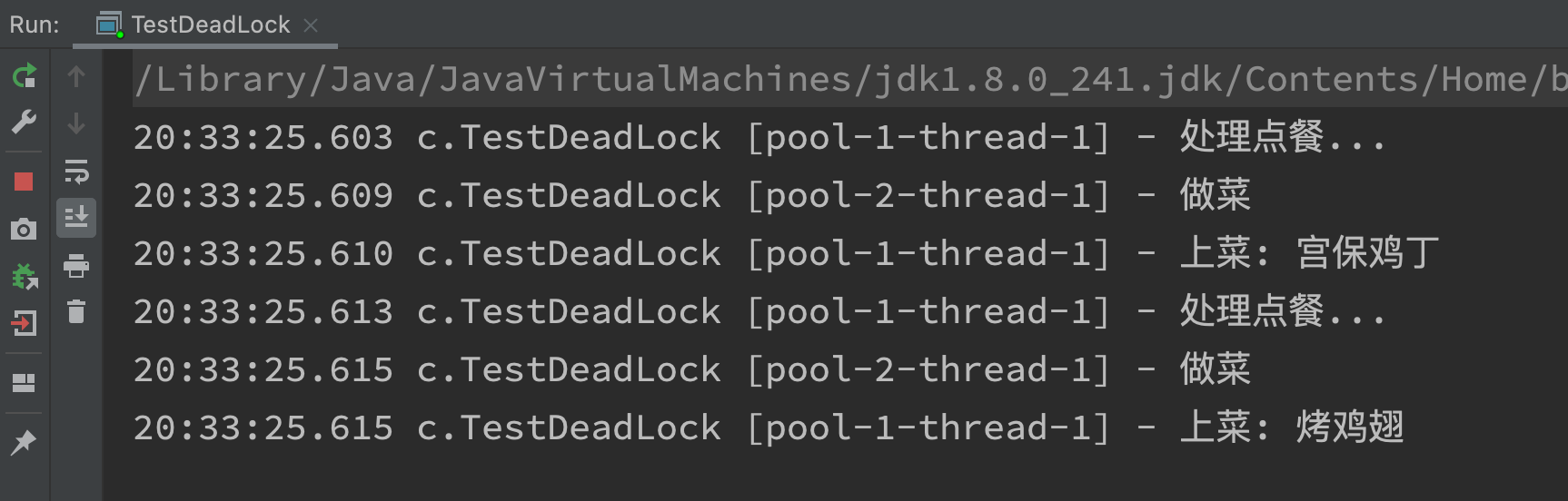
Hunger resolution
The solution is to increase the size of the thread pool, but it is not the fundamental solution. As mentioned earlier, different thread pools are used for different task types
@Slf4j(topic = "c.TestDeadLock")
public class TestDeadLock {
static final List<String> MENU = Arrays.asList("Sauteed Potato, Green Pepper and Eggplant", "Kung Pao Chicken", "Sauteed Chicken Dices with Chili Peppers", "Roast chicken wings");
static Random RANDOM = new Random();
static String cooking() {
return MENU.get(RANDOM.nextInt(MENU.size()));
}
public static void main(String[] args) {
ExecutorService waiterPool = Executors.newFixedThreadPool(1);
ExecutorService cookPool = Executors.newFixedThreadPool(1);
waiterPool.execute(() -> {
log.debug("Process order...");
Future<String> future = cookPool.submit(() -> {
log.debug("cook a dish");
return cooking();
});
try {
log.debug("Serve: {}", future.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
waiterPool.execute(() -> {
log.debug("Process order...");
Future<String> future = cookPool.submit(() -> {
log.debug("cook a dish");
return cooking();
});
try {
log.debug("Serve: {}", future.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
}
}
How many threads should be set in the thread pool?
- Too small will lead to the program can not make full use of system resources, easy to lead to hunger
- Too large will lead to more thread context switching and occupy more memory
CPU intensive computing
Usually * * CPU cores + 1 * * can be used to achieve the optimal CPU utilization, + 1 is to ensure that when the thread is suspended due to page loss fault (operating system) or other reasons, the additional thread can be pushed up to ensure that the CPU clock cycle is not wasted
I/O intensive operation
The CPU is not always busy. For example, when you perform business computing, CPU resources will be used, but when you perform I/O operations, remote RPC calls, including database operations, the CPU will be idle. You can use multithreading to improve its utilization.
The empirical formula is as follows
Number of threads = Kernel number * expect CPU Utilization rate * Total time(CPU computing time+waiting time) / CPU computing time
- For example, the calculation time of 4-core CPU is 50%, and the other waiting time is 50%. It is expected that the CPU will be 100% utilized. Apply the formula
4 * 100% * 100% / 50% = 8
- For example, the calculation time of 4-core CPU is 10%, and the other waiting time is 90%. It is expected that the CPU will be 100% utilized. Apply the formula
4 * 100% * 100% / 10% = 40
Task scheduling thread pool
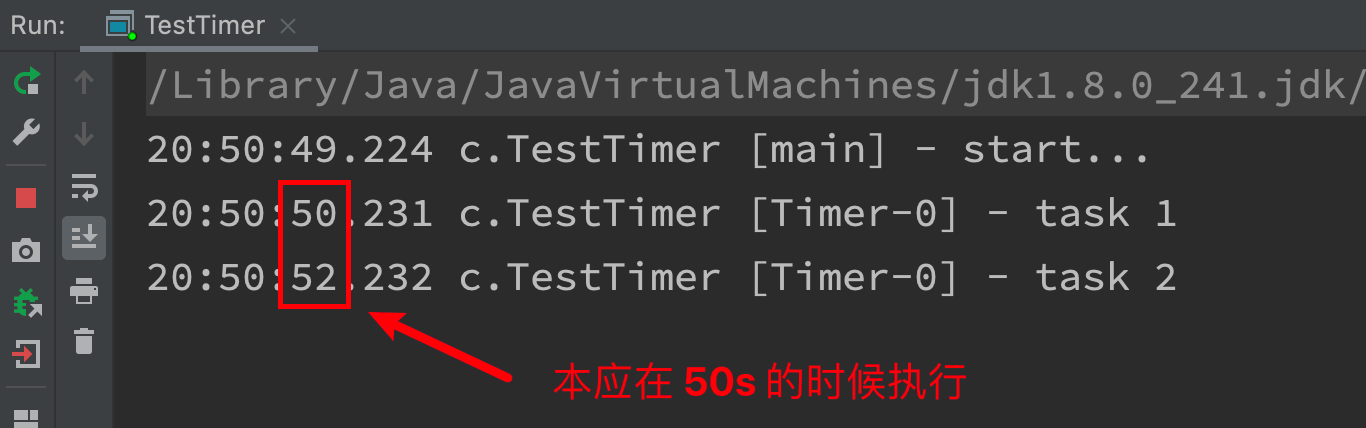
- Before the "task scheduling thread pool" function is added, you can use Java util. Timer is used to realize the timing function. The advantage of timer is that it is simple and easy to use. However, since all tasks are scheduled by the same thread, all tasks are executed in series. Only one task can be executed at the same time, and the delay or exception of the previous task will affect the subsequent tasks.
@Slf4j(topic = "c.TestTimer")
public class TestTimer {
public static void main(String[] args) {
Timer timer = new Timer();
TimerTask task1 = new TimerTask() {
@Override
public void run() {
log.debug("task 1");
Sleeper.sleep(2);
}
};
TimerTask task2 = new TimerTask() {
@Override
public void run() {
log.debug("task 2");
}
};
log.debug("start...");
// Use timer to add two tasks. I hope they will be executed in 1s
// However, since there is only one thread in the timer to execute the tasks in the queue in sequence, the delay of "task 1" affects the execution of "task 2"
timer.schedule(task1, 1000);
timer.schedule(task2, 1000);
}
}
ScheduledExecutorService (key)
Use of schedule method in ScheduledExecutorService
public static void method2() {
ScheduledExecutorService pool = Executors.newScheduledThreadPool(2);
// Add two tasks and expect them to be executed in 1s
pool.schedule(() -> {
System.out.println("Task 1, execution time:" + new Date());
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
}
}, 1, TimeUnit.SECONDS);
pool.schedule(() -> {
System.out.println("Task 2, execution time:" + new Date());
}, 1, TimeUnit.SECONDS);
}
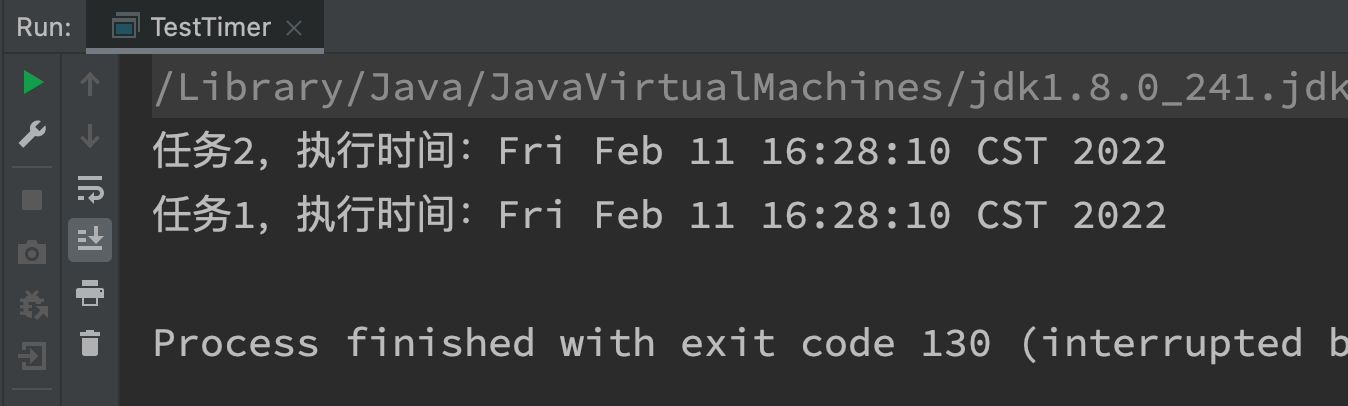
- The execution of two threads does not interfere with each other
- Of course, if the thread pool size is 1, tasks are still executed serially
Use of scheduleAtFixedRate method in ScheduledExecutorService
public static void method3() {
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
log.debug("start...");
// After a delay of 1s, print running at the rate of 1s
pool.scheduleAtFixedRate(() -> {
log.debug("running...");
}, 1, 1, TimeUnit.SECONDS);
}
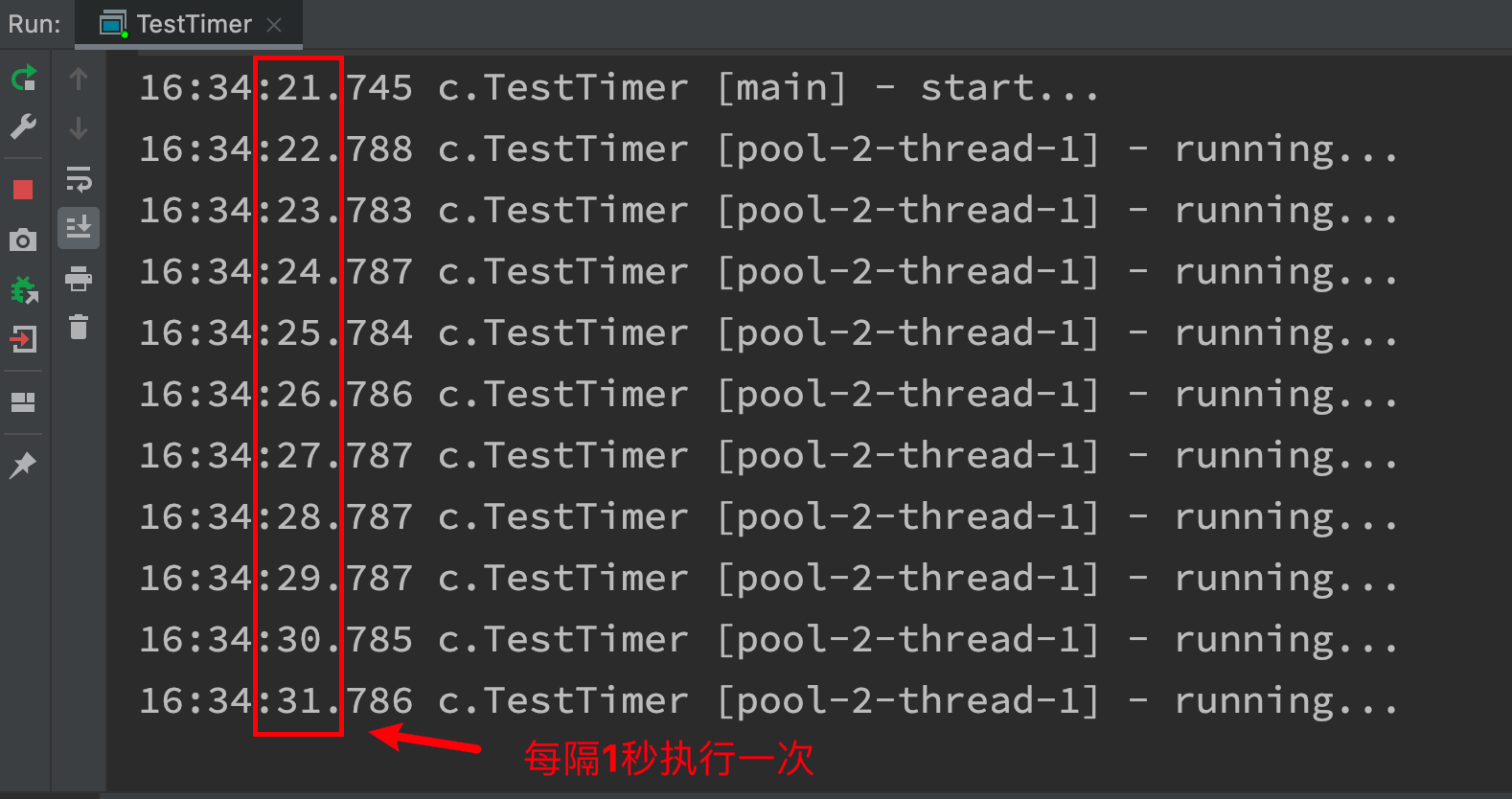
If the task execution time exceeds the interval
public static void method3() {
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
log.debug("start...");
// After a delay of 1s, print running at the rate of 1s
pool.scheduleAtFixedRate(() -> {
log.debug("running...");
Sleeper.sleep(2);
}, 1, 1, TimeUnit.SECONDS);
}
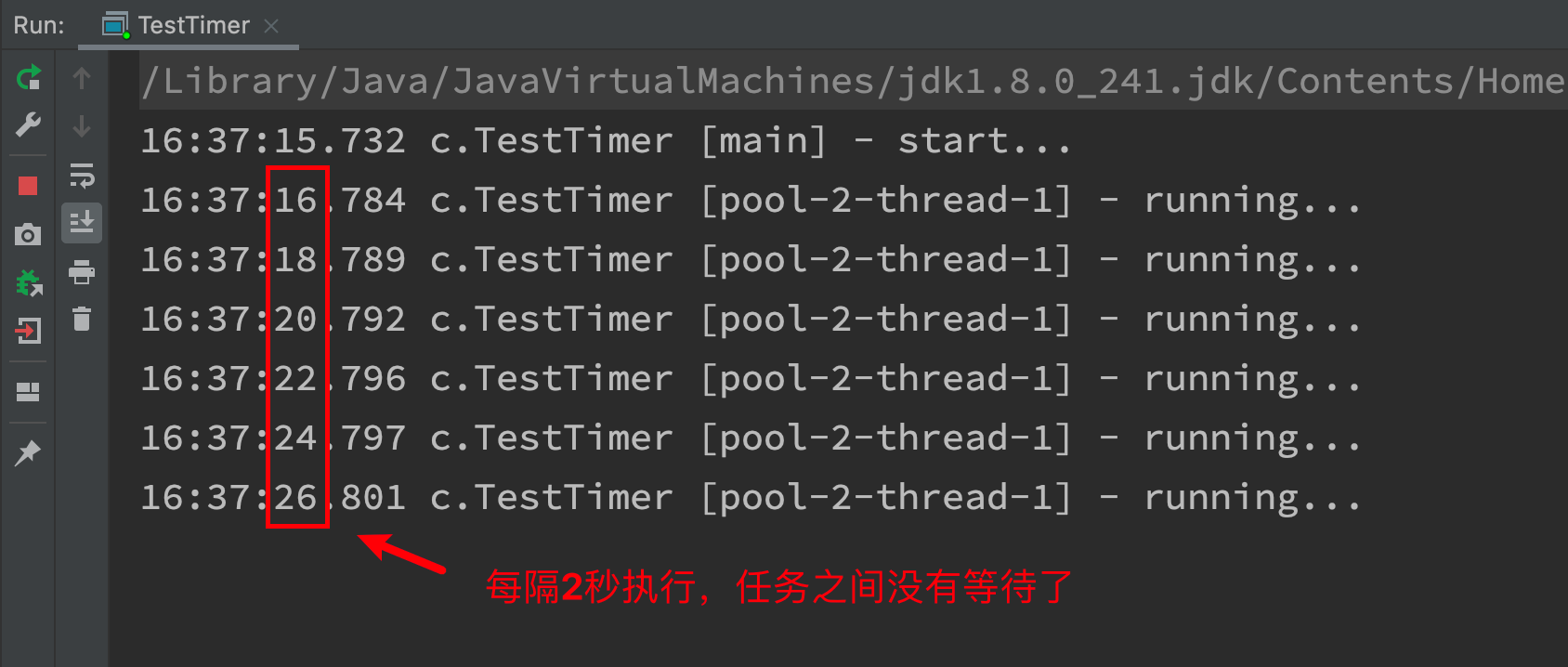
- Since the "analysis interval" is more than 2s, the execution time is delayed to 1s
Use of scheduleWithFixedDelay method in ScheduledExecutorService
public static void method4() {
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
log.debug("start...");
pool.scheduleWithFixedDelay(() -> {
log.debug("running...");
sleep(2);
}, 1, 1, TimeUnit.SECONDS);
}
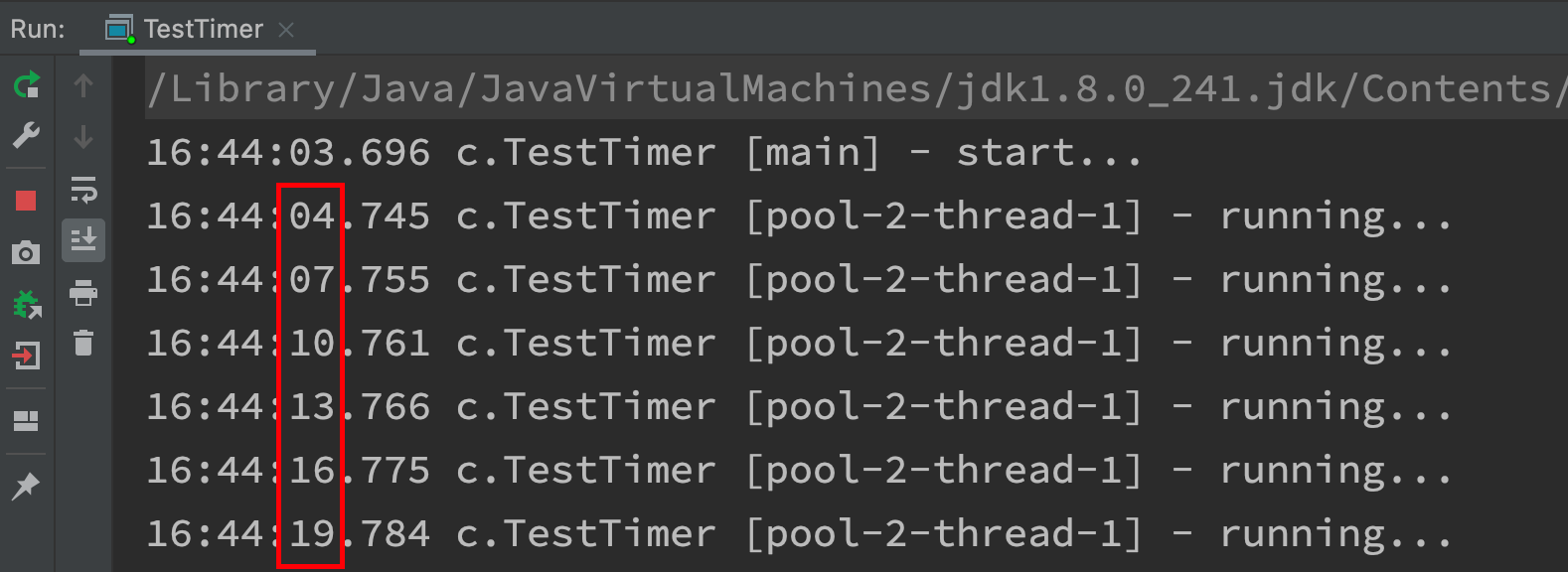
- Output analysis: at the beginning, the delay is 1s. The interval of scheduleWithFixedDelay is the end of the previous task + delay = the start of the next task, so the interval is 3s
- The whole thread pool shows that when the number of threads is fixed and the number of tasks is more than the number of threads, it will be put into an unbounded queue. After the task is executed, these threads will not be released. Used to perform tasks that are delayed or repeated.
eg: how to make every Thursday 18:00:00 scheduled to perform tasks?
public class TestSchedule {
// How to make every Thursday 18:00:00 scheduled to perform tasks?
public static void main(String[] args) {
// Get current time
LocalDateTime now = LocalDateTime.now();
System.out.println(now);
// Get Thursday time
LocalDateTime time = now.withHour(18).withMinute(0).withSecond(0).withNano(0).with(DayOfWeek.THURSDAY);
// If the current time is > Thursday of this week, you must find Thursday of next week
if (now.compareTo(time) > 0) {
time = time.plusWeeks(1); // Plus one week
}
System.out.println(time);
// initailDelay represents the time difference between the current time and Thursday
long initailDelay = Duration.between(now, time).toMillis();
// period interval of one week
long period = 1000 * 60 * 60 * 24 * 7;
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
pool.scheduleAtFixedRate(() -> {
System.out.println("running...");
}, initailDelay, period, TimeUnit.MILLISECONDS);
}
}
Correctly handle the exception of executing task
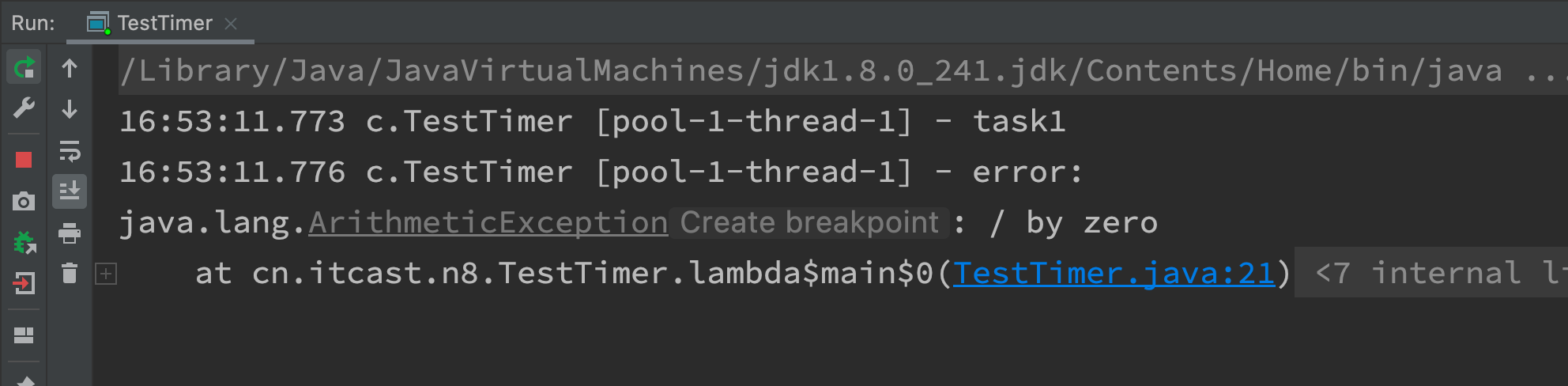
Method 1: actively catch exceptions
ExecutorService pool = Executors.newFixedThreadPool(1);
pool.submit(() -> {
try {
log.debug("task1");
int i = 1 / 0;
} catch (Exception e) {
log.error("error:", e);
}
});
Method 2: use Future
ExecutorService pool = Executors.newFixedThreadPool(1);
Future<Boolean> future = pool.submit(() -> {
log.debug("task1");
int i = 1 / 0;
return true;
});
log.debug("result:{}", future.get());
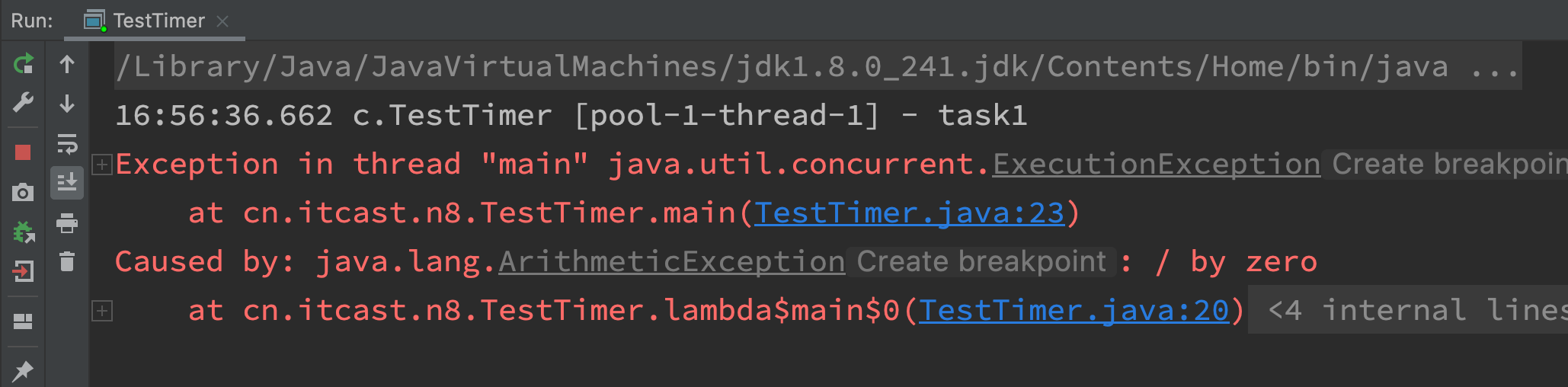
- Use Future to receive the return value. If it is normal, receive the return value of the Callable interface
- If there is an exception, it will catch the exception
Tomcat thread pool
Where does Tomcat use thread pools?
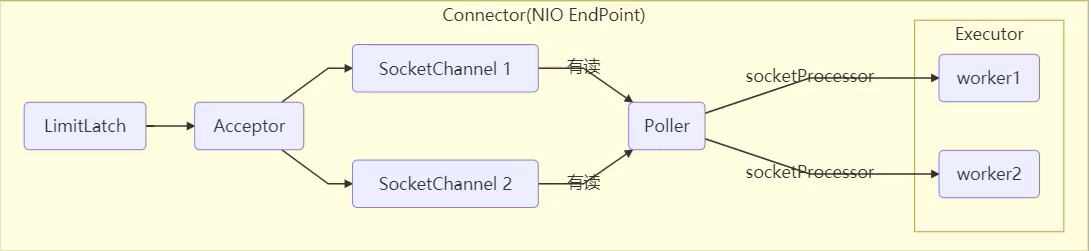
- LimitLatch is used to limit current and control the maximum number of connections, similar to Semaphore in J.U.C, which will be discussed later
- Acceptor is only responsible for [receiving new socket connection]
- Poller is only responsible for monitoring whether the socket channel has [readable I/O events]
- Once readable, encapsulate a task object (socket processor) and submit it to the Executor thread pool for processing
- The worker thread in the Executor thread pool is ultimately responsible for [processing requests]
It reflects that different thread pools do different work
Tomcat thread pool extends ThreadPoolExecutor with slightly different behavior
- If the total number of threads reaches maximumPoolSize
- RejectedExecutionException exception will not be thrown immediately at this time
- Instead, try to put the task in the queue again. If it still fails, throw the RejectedExecutionException exception
Source code tomcat-7.0.42
public void execute(Runnable command, long timeout, TimeUnit unit) {
submittedCount.incrementAndGet();
try {
super.execute(command);
} catch (RejectedExecutionException rx) {
if (super.getQueue() instanceof TaskQueue) {
final TaskQueue queue = (TaskQueue)super.getQueue();
try {
// Re entering the task into the blocking queue
if (!queue.force(command, timeout, unit)) {
submittedCount.decrementAndGet();
throw new RejectedExecutionException("Queue capacity is full.");
}
} catch (InterruptedException x) {
submittedCount.decrementAndGet();
Thread.interrupted();
throw new RejectedExecutionException(x);
}
} else {
submittedCount.decrementAndGet();
throw rx;
}
}
}
- TaskQueue.java
public boolean force(Runnable o, long timeout, TimeUnit unit) throws InterruptedException {
if ( parent.isShutdown() )
throw new RejectedExecutionException(
"Executor not running, can't force a command into the queue"
);
return super.offer(o,timeout,unit); //forces the item onto the queue, to be used if the task is rejected
}
- Connector configuration
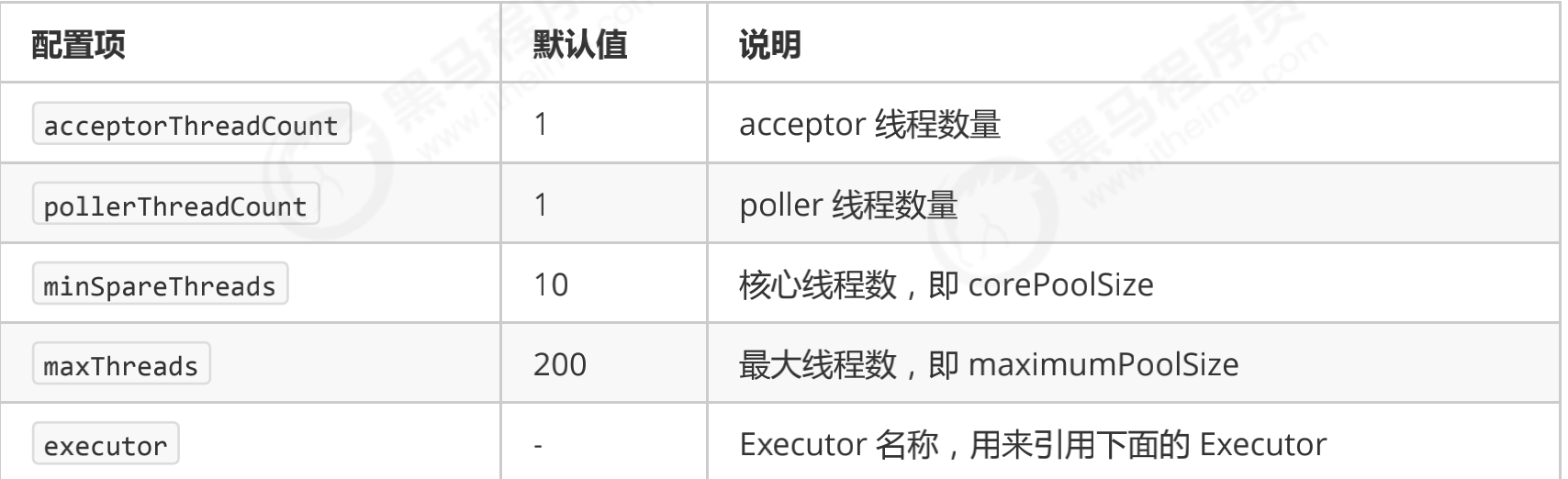
- Executor thread configuration
Daemon thread means that the thread will end with the end of the main thread
- There is something wrong in the figure below. The submitted task < core thread should be directly handed over to the core thread for execution.
Fork/Join (familiar)
concept
- Fork/Join is a new thread pool implementation added to JDK 1.7. It embodies a divide and conquer idea and is suitable for cpu intensive operations that can split tasks
- The so-called task splitting is to split a large task into small tasks with the same algorithm until it cannot be split and can be solved directly. Some calculations related to recursion, such as merge sorting and Fibonacci sequence, can be solved by divide and conquer
- Fork/Join adds multithreading on the basis of divide and conquer, which can divide and merge each task to different threads, further improving the operation efficiency
- Fork/Join creates a thread pool with the same size as the number of cpu cores by default
use
- The task submitted to the Fork/Join thread pool needs to inherit the RecursiveTask (with return value) or RecursiveAction (without return value). For example, the following defines a task for summing integers between 1 and n
@Slf4j(topic = "c.TestForkJoin2")
public class TestForkJoin2 {
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool(4);
System.out.println(pool.invoke(new MyTask(5)));
// new MyTask(5) 5+ new MyTask(4) 4 + new MyTask(3) 3 + new MyTask(2) 2 + new MyTask(1)
}
}
// Sum of integers between 1 and n
@Slf4j(topic = "c.MyTask")
class MyTask extends RecursiveTask<Integer> {
private int n;
public MyTask(int n) {
this.n = n;
}
@Override
public String toString() {
return "{" + n + '}';
}
@Override
protected Integer compute() {
// If n is already 1, the result can be obtained
if (n == 1) {
log.debug("join() {}", n);
return n;
}
// Fork a task
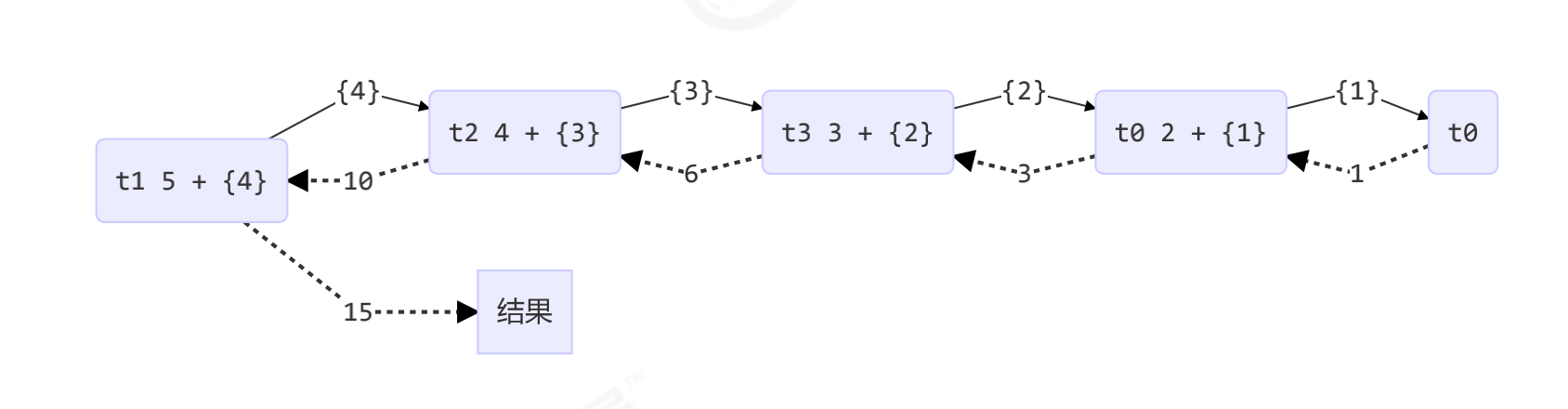
AddTask1 t1 = new AddTask1(n - 1);
t1.fork(); // Let a thread perform this task
log.debug("fork() {} + {}", n, t1);
// Join results
int result = n + t1.join(); // Get task results
log.debug("join() {} + {} = {}", n, t1, result);
return result;
}
}
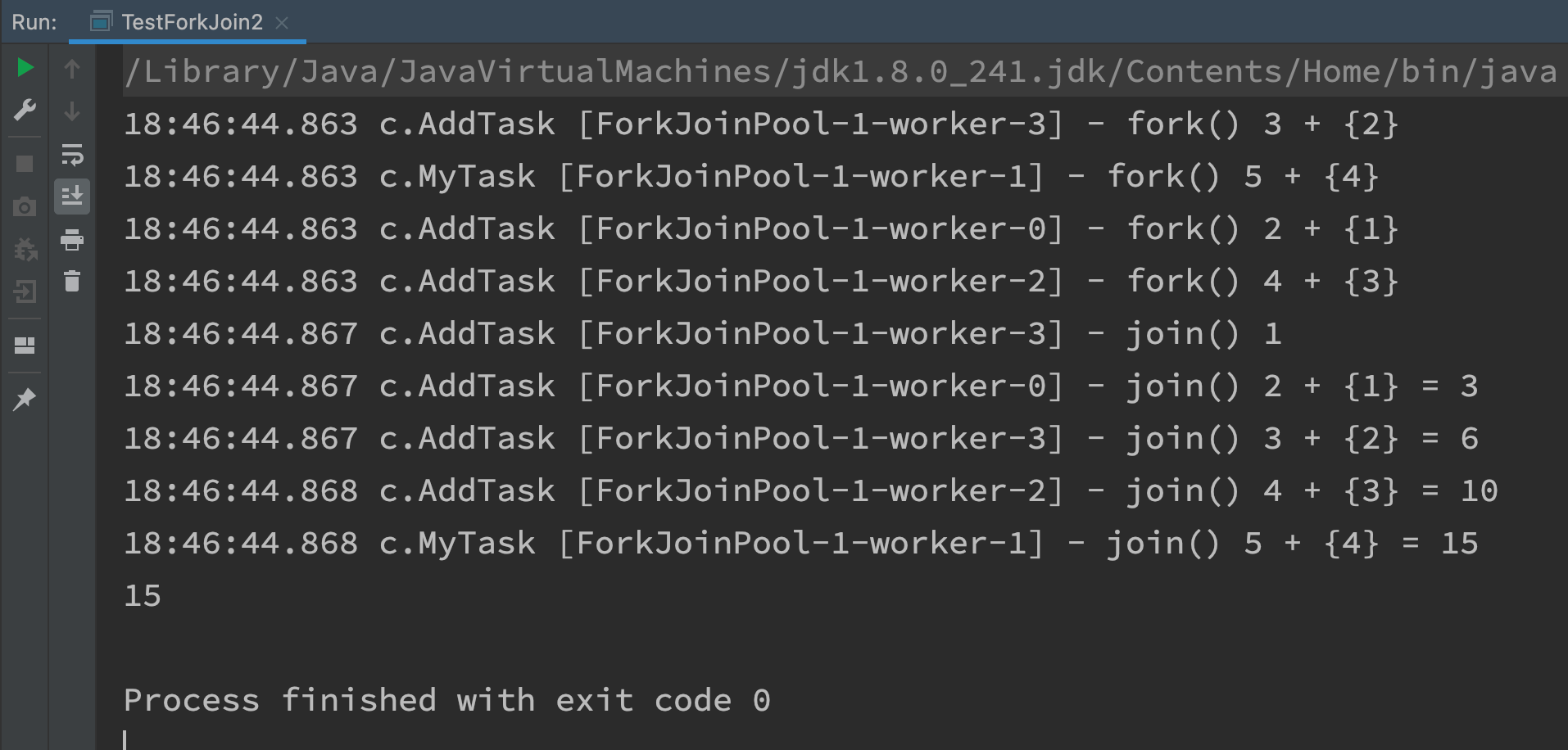
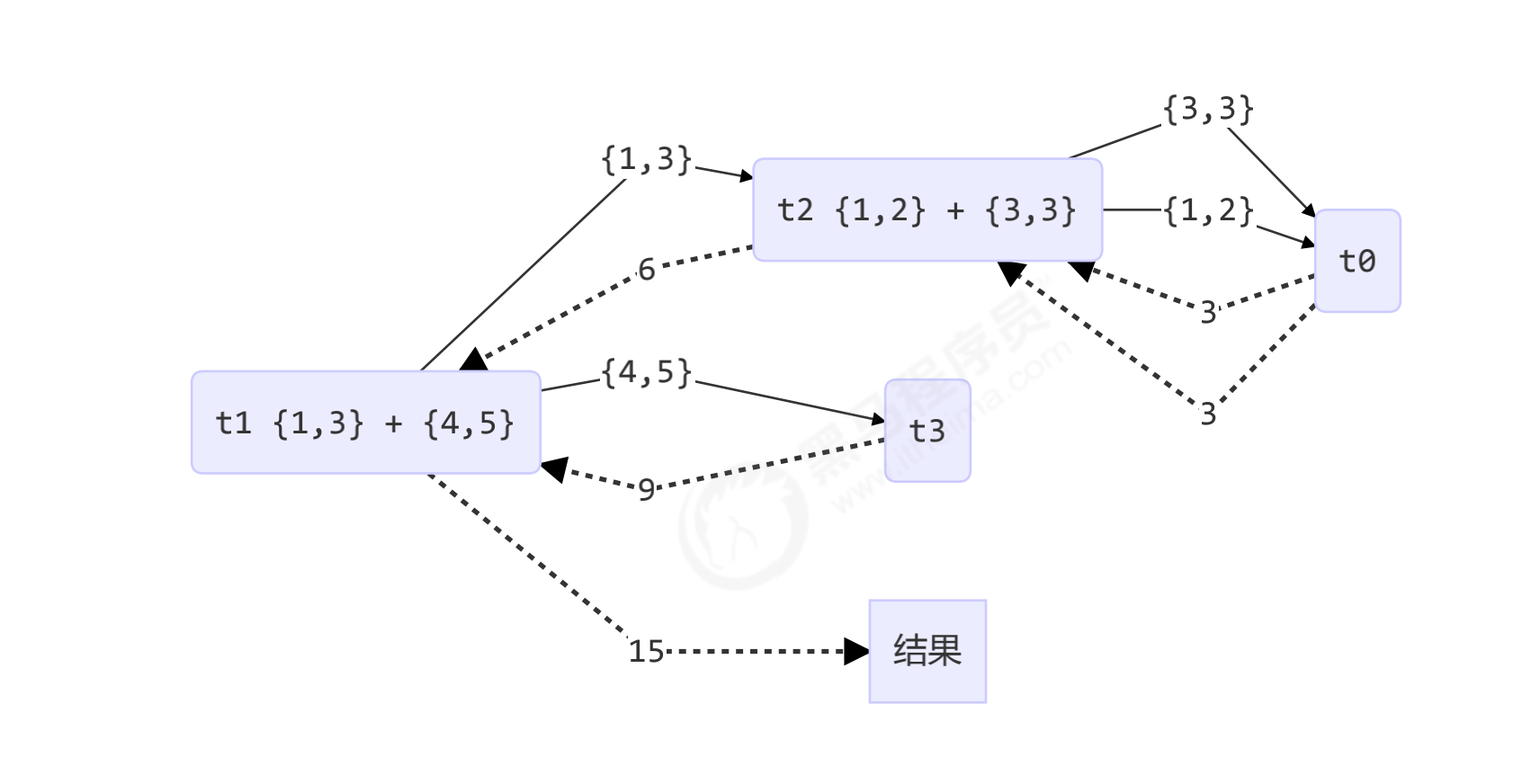
Graphic effect
improvement
@Slf4j(topic = "c.AddTaskTest")
public class AddTaskTest {
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool(4);
System.out.println(pool.invoke(new AddTask3(1, 5)));
}
}
@Slf4j(topic = "c.AddTask3")
class AddTask3 extends RecursiveTask<Integer> {
int begin;
int end;
public AddTask3(int begin, int end) {
this.begin = begin;
this.end = end;
}
@Override
public String toString() {
return "{" + begin + "," + end + '}';
}
@Override
protected Integer compute() {
if (begin == end) {
log.debug("join() {}", begin);
return begin;
}
if (end - begin == 1) {
log.debug("join() {} + {} = {}", begin, end, end + begin);
return end + begin;
}
int mid = (end + begin) / 2;
AddTask3 t1 = new AddTask3(begin, mid);
t1.fork();
AddTask3 t2 = new AddTask3(mid + 1, end);
t2.fork();
log.debug("fork() {} + {} = ?", t1, t2);
int result = t1.join() + t2.join();
log.debug("join() {} + {} = {}", t1, t2, result);
return result;
}
}
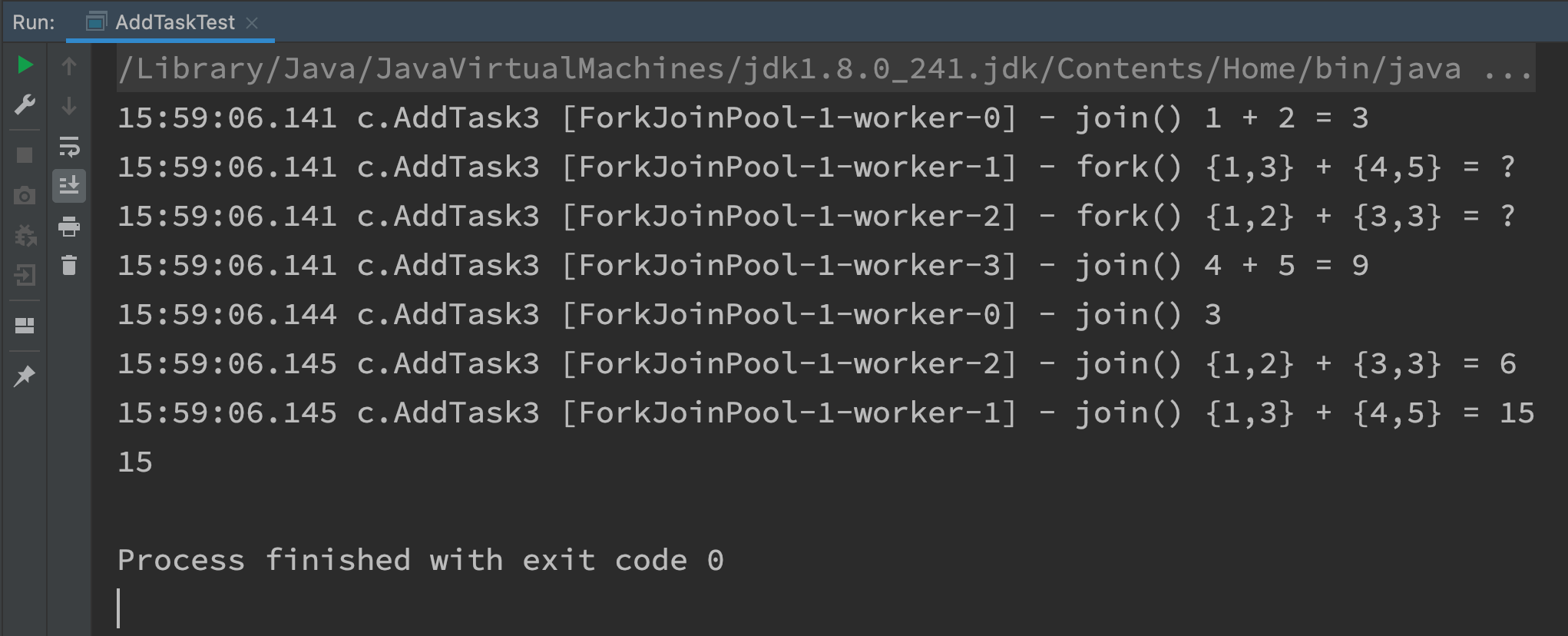
Graphical results