Search: (Searching) is to determine a data element (or record) whose keyword is equal to the given value in the lookup table according to a given value.
A Search Table is a collection of data elements (or records) of the same type.
A key is the value of a data item in a data element.
Static Search Table: a lookup table that is used only for lookup operations.
1. Query whether a "specific" data element is in the lookup table.
2. Retrieve a "specific" data element and various attributes.
Dynamic Search Table: a lookup table that is used only for lookup operations.
1. Insert data elements when searching.
2. Delete data elements on lookup.
Sequential table lookup
Sequential Search, also known as linear search, is the most basic search technology. Its search process is: starting from the first (or last) record in the table, compare the keyword of the record with the given value one by one. If the keyword of a record is equal to the given value, the search is successful and the searched record is found; If the keyword and given value of the last (or first) record are not equal until the comparison, there is no record in the table and the search is unsuccessful.
/* Search without sentry sequence. a is the array, n is the number of arrays to be searched, and key is the keyword to be searched */
int Sequential_Search(int *a,int n,int key)
{
int i;
for(i=1;i<=n;i++)
{
if (a[i]==key)
return i;
}
return 0;
}
/* There are sentinels to search in sequence */
int Sequential_Search2(int *a,int n,int key)
{
int i;
a[0]=key;
i=n;
while(a[i]!=key)
{
i--;
}
return i;
}Ordered table lookup
Binary Search technology, also known as Binary Search. Its premise is that the records in the linear table must be in order of key codes (usually sorted from small to large), and the linear table must be stored in order. The basic idea of half search: in the ordered table, take the intermediate record as the comparison object. If the given value is equal to the keyword of the intermediate record, the search is successful; If the given value is less than the keyword of the intermediate record, continue to search in the left half of the intermediate record; If the given value is greater than the keyword of the intermediate record, search in the right half of the intermediate record. Repeat the above mistakes until the search is successful, or there is no record in all search areas and the search fails.
/* Half search */
int Binary_Search(int *a,int n,int key)
{
int low,high,mid;
low=1; /* Define the lowest subscript as the first record */
high=n; /* Define the highest subscript as the last bit of the record */
while(low<=high)
{
mid=(low+high)/2; /* Halve */
if (key<a[mid]) /* If the search value is smaller than the median */
high=mid-1; /* The highest subscript is adjusted to the middle subscript, and the subscript is one digit lower */
else if (key>a[mid])/* If the search value is larger than the median value */
low=mid+1; /* The lowest subscript is adjusted to the middle subscript, and the subscript is one higher */
else
{
return mid; /* If they are equal, it means that mid is the location found */
}
}
return 0;
}Interpolation Search is a search method based on the comparison between the keyword key to be searched and the keyword of the largest and smallest record in the search table. Its core lies in the calculation formula of interpolation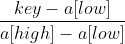 .
.

Fibonacci search:
/* fibonacci search */
int Fibonacci_Search(int *a,int n,int key)
{
int low,high,mid,i,k=0;
low=1; /* Define the lowest subscript as the first record */
high=n; /* Define the highest subscript as the last bit of the record */
while(n>F[k]-1)
k++;
for (i=n;i<F[k]-1;i++)
a[i]=a[n];
while(low<=high)
{
mid=low+F[k-1]-1;
if (key<a[mid])
{
high=mid-1;
k=k-1;
}
else if (key>a[mid])
{
low=mid+1;
k=k-2;
}
else
{
if (mid<=n)
return mid; /* If they are equal, it means that mid is the location found */
else
return n;
}
}
return 0;
}The core of Fibonacci search algorithm:
1. When key=a[mid], the search is successful;
2. When key < a[mid], the new range is from low to mid-1. At this time, the number of ranges is F[k-1]-1;
3. When key > a[mid], the new range is from m+1 to high, and the number of ranges is F[]k-2]-1;
Linear index lookup
Index: index is the process of associating a keyword with its corresponding record.
The so-called linear index is to organize the set of index items into a linear structure, also known as the index table.
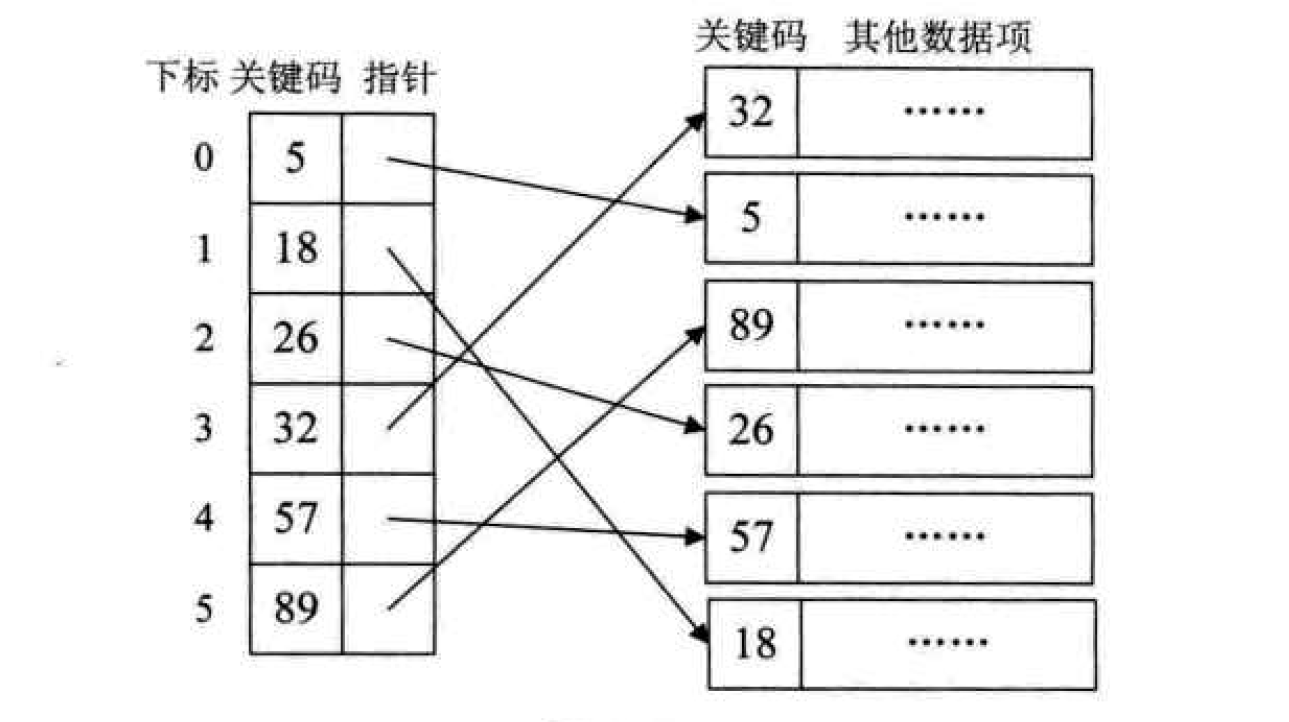
1. Dense index: refers to a linear index in which each record in the dataset corresponds to an index item. For the dense index table, the index entries must be arranged in order according to the key.
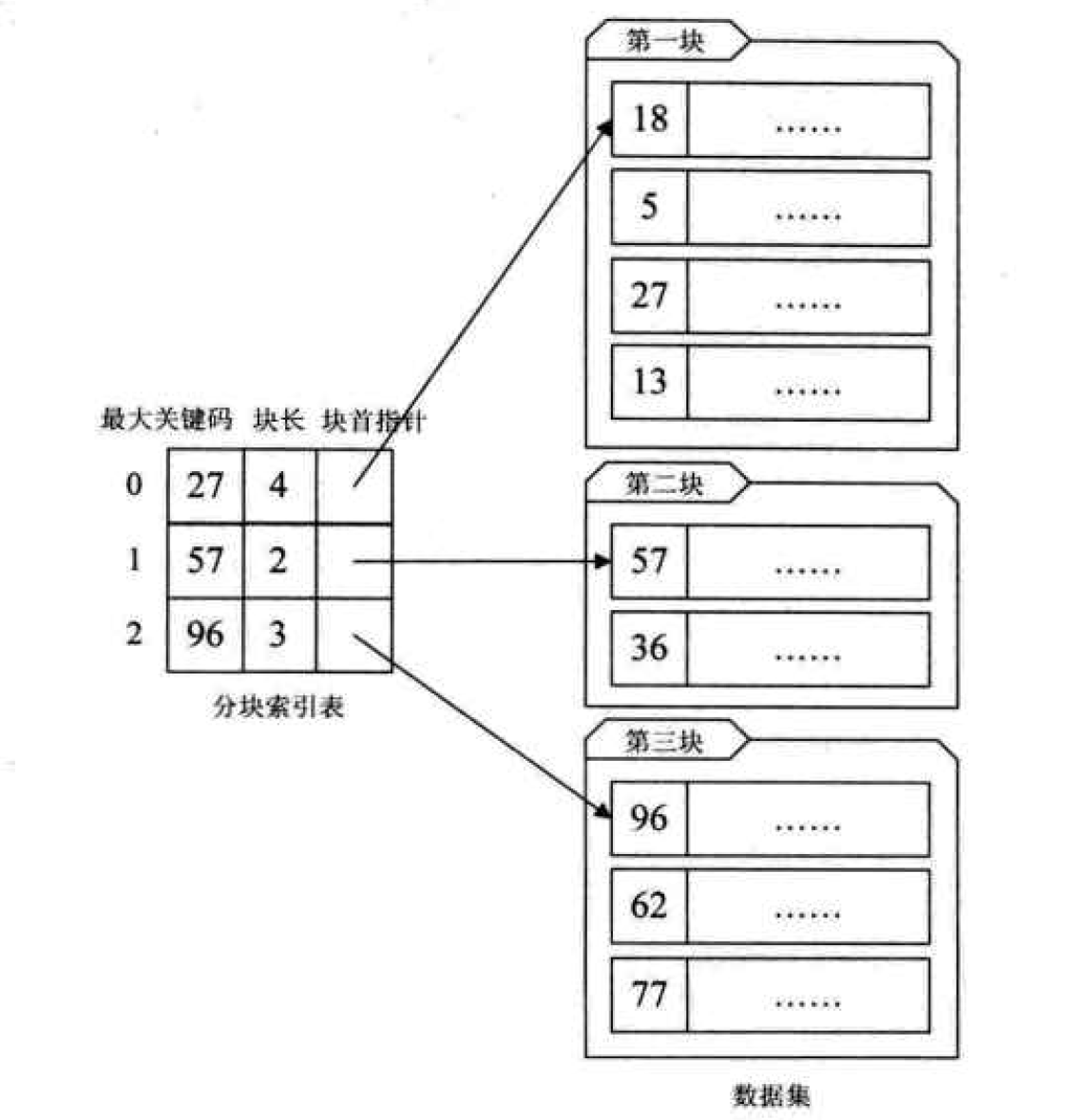
2. Block index: it is to divide the records of the data set into several blocks, and these blocks need to meet two conditions:
1. Disorder in the block, that is, the records in each block are not required to be orderly.
2. Order between blocks
The index item structure of the block index defined by us is divided into three data items:
1. Maximum key, which stores the largest keyword in each block. The advantage is that the smallest keyword in the next block after it can be larger than the largest keyword in this block.
2. The number of records in the block is stored for circulation.
3. The pointer used to point to the data element at the beginning of the block to facilitate the traversal of the records in this block.
Binary sort tree
Binary Sort Tree, also known as binary search tree. It is either an empty tree or a binary tree with the following properties.
1. If its left subtree is not empty, the value of all nodes on the left subtree is less than the value of its root structure.
2. If its right subtree is not empty, the value of all nodes on the right subtree is greater than the value of its root structure.
3. Its left and right subtrees are also binary sort trees.
/* Definition of binary linked list node structure of binary tree */
typedef struct BiTNode /* Node structure */
{
int data; /* Node data */
struct BiTNode *lchild, *rchild; /* Left and right child pointers */
} BiTNode, *BiTree;Search of binary sort tree:
/* Recursively find out whether there is a key in the binary sort tree T, */
/* Pointer f points to the parent of T and its initial call value is NULL */
/* If the search is successful, the pointer p points to the data element node and returns TRUE */
/* Otherwise, the pointer p points to the last node accessed on the lookup path and returns FALSE */
Status SearchBST(BiTree T, int key, BiTree f, BiTree *p)
{
if (!T) /* The search was unsuccessful */
{
*p = f;
return FALSE;
}
else if (key==T->data) /* Search succeeded */
{
*p = T;
return TRUE;
}
else if (key<T->data)
return SearchBST(T->lchild, key, T, p); /* Continue searching in the left subtree */
else
return SearchBST(T->rchild, key, T, p); /* Continue searching in the right subtree */
}Binary sort tree insertion:
/* When there is no data element with keyword equal to key in binary sort tree T, */
/* Insert the key and return TRUE, otherwise return FALSE */
Status InsertBST(BiTree *T, int key)
{
BiTree p,s;
if (!SearchBST(*T, key, NULL, &p)) /* The search was unsuccessful */
{
s = (BiTree)malloc(sizeof(BiTNode));
s->data = key;
s->lchild = s->rchild = NULL;
if (!p)
*T = s; /* Insert s as the new root node */
else if (key<p->data)
p->lchild = s; /* Insert s as left child */
else
p->rchild = s; /* Insert s as right child */
return TRUE;
}
else
return FALSE; /* A node with the same keyword already exists in the tree and will not be inserted */
}Balanced binary tree (AVL tree)
Self balancing binary search tree is a sort of binary tree, in which the height difference between the left subtree and the right subtree of each node is at most equal to 1. We subtract the depth of the right subtree from the depth of the left subtree of the node on the binary tree as the balance factor BF(Balance Factor)
Balanced binary tree implementation algorithm:
/* Definition of binary linked list node structure of binary tree */
typedef struct BiTNode /* Node structure */
{
int data; /* Node data */
int bf; /* Equilibrium factor of node */
struct BiTNode *lchild, *rchild; /* Left and right child pointers */
} BiTNode, *BiTree;
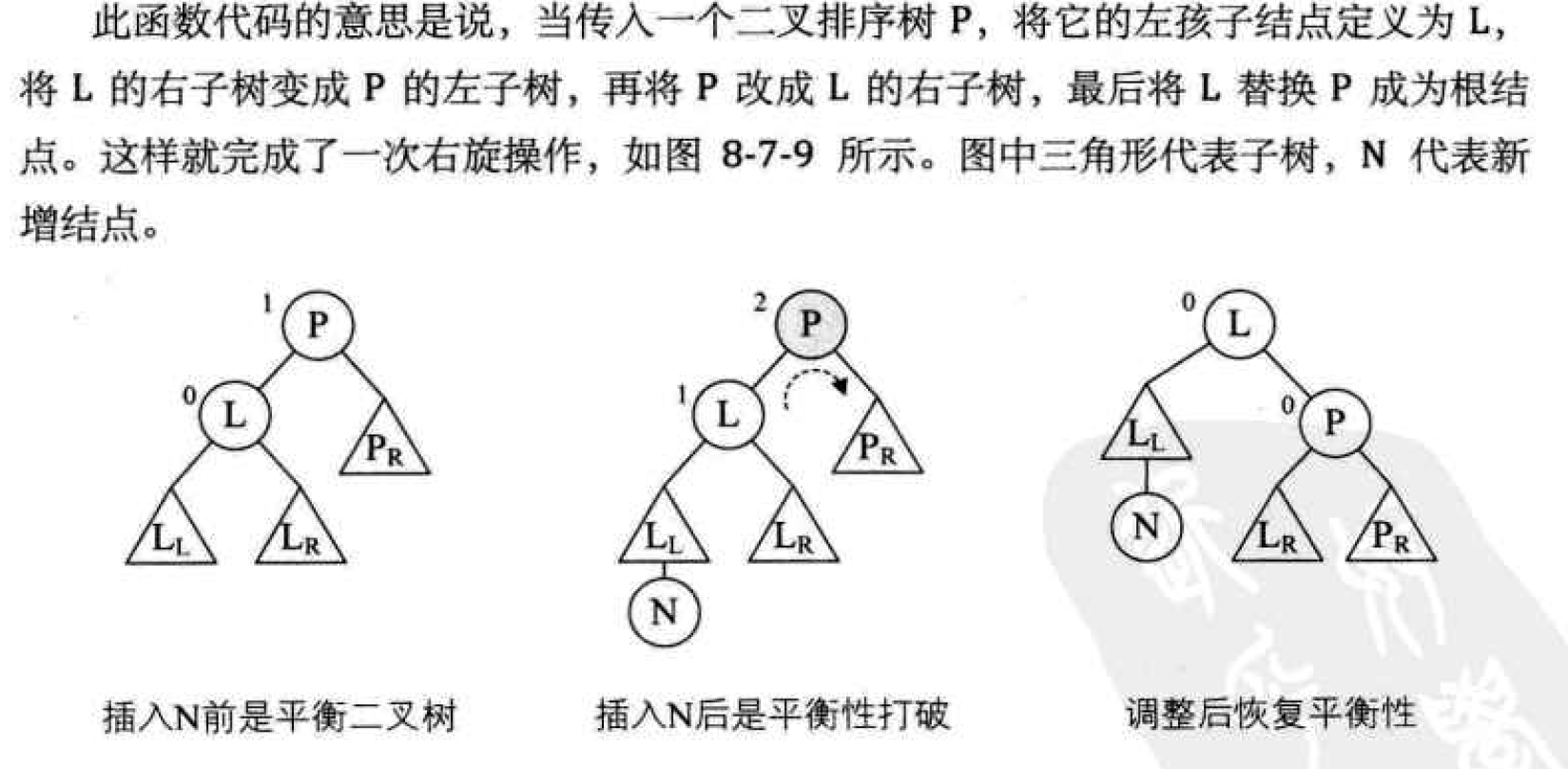
Then, for right-handed operation, our code:
/* The binary sort tree with p as the root is right rotated, */
/* After processing, p points to the new tree root node, that is, the root node of the left subtree before rotation processing */
void R_Rotate(BiTree *P)
{
BiTree L;
L=(*P)->lchild; /* L Point to the root node of the left subtree of P */
(*P)->lchild=L->rchild; /* L The right subtree of is connected to the left subtree of P */
L->rchild=(*P);
*P=L; /* P Point to the new root node */
}
Left hand operation code:
/* The binary sort tree with P as the root is processed by left rotation, */
/* After processing, P points to the new tree root node, that is, the root node 0 of the right subtree before rotation processing */
void L_Rotate(BiTree *P)
{
BiTree R;
R=(*P)->rchild; /* R Point to the root node of the right subtree of P */
(*P)->rchild=R->lchild; /* R The left subtree of is connected to the right subtree of P */
R->lchild=(*P);
*P=R; /* P Point to the new root node */
}Multiple lookup tree (B-tree)
The number of children in each node of a multiple way search tree can be more than two, and multiple elements can be stored at each node.



Hash table lookup
Hash technology is to establish a certain corresponding relationship f between the storage location of the record and its keywords, so that each keyword key corresponds to a storage location f (key). We call this correspondence f a hash function, also known as a hash function. Hash technology is used to store records in a continuous storage space, which is called hash table or hash table.