Take Linux snapshots for Hadoop 102, 103 and 104, and then restore the snapshots.
2.1 configuration case of core parameters of yarn production environment
- Demand: count the number of occurrences of each word from 1G data. 3 servers, each configured with 4G memory and 4 cores
CPU, 4 threads. - Demand analysis:
1G / 128m = 8 maptasks; 1 ReduceTask; 1 mrAppMaster
On average, each node runs 10 / 3 sets ≈ 3 tasks (4 ≈ 3 ≈ 3) - Modify Yard site XML configuration parameters are as follows:
<!-- Select scheduler, default capacity --> <property> <description>The class to use as the resource scheduler.</description> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> </property> <!-- ResourceManager Number of threads processing scheduler requests,Default 50; If the number of tasks submitted is greater than 50, this value can be increased, but it cannot exceed 3 * 4 thread = 12 Threads (excluding other applications, it can't actually exceed 8) --> <property> <description>Number of threads to handle scheduler interface.</description> <name>yarn.resourcemanager.scheduler.client.thread-count</name> <value>8</value> </property> <!-- Whether to let yarn Configure the automatic detection hardware. The default is false,If the node has many other applications, manual configuration is recommended. If the node does not have other applications, you can use automatic --> <property> <description>Enable auto-detection of node capabilities such as memory and CPU.</description> <name>yarn.nodemanager.resource.detect-hardware-capabilities</name> <value>false</value> </property> <!-- Whether to treat virtual cores as CPU The default value is false,Adopt physics CPU Kernel number --> <property> <description>Flag to determine if logical processors(such as hyperthreads) should be counted as cores. Only applicable on Linux when yarn.nodemanager.resource.cpu-vcores is set to -1 and yarn.nodemanager.resource.detect-hardware-capabilities is true.</description> <name>yarn.nodemanager.resource.count-logical-processors-as-cores</name> <value>false</value> </property> <!-- Virtual core and physical core multiplier. The default value is 1.0 --> <property> <description>Multiplier to determine how to convert phyiscal cores to vcores. This value is used if yarn.nodemanager.resource.cpu-vcores is set to -1(which implies auto-calculate vcores) and yarn.nodemanager.resource.detect-hardware-capabilities is set to true.The number of vcores will be calculated as number of CPUs * multiplier.</description> <name>yarn.nodemanager.resource.pcores-vcores-multiplier</name> <value>1.0</value> </property> <!-- NodeManager Number of memory used, 8 by default G,Change to 4 G Memory --> <property> <description>Amount of physical memory, in MB, that can be allocated for containers. If set to -1 and yarn.nodemanager.resource.detect-hardware-capabilities is true, it is automatically calculated(in case of Windows and Linux).In other cases, the default is 8192MB.</description> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <!-- nodemanager of CPU When the number of cores is not automatically set according to the hardware environment, it is 8 by default and modified to 4 --> <property> <description>Number of vcores that can be allocated for containers. This is used by the RM scheduler when allocating resources for containers. This is not used to limit the number of CPUs used by YARN containers. If it is set to -1 and yarn.nodemanager.resource.detect-hardware-capabilities is true, it is automatically determined from the hardware in case of Windows and Linux. In other cases, number of vcores is 8 by default.</description> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>4</value> </property> <!-- Container minimum memory, default 1 G --> <property> <description>The minimum allocation for every container request at theRM in MBs. Memory requests lower than this will be set to the value of this property. Additionally, a node manager that is configured to have less memory than this value will be shut down by the resource manager.</description> <name>yarn.scheduler.minimum-allocation-mb</name> <value>1024</value> </property> <!-- Container maximum memory, default 8 G,Change to 2 G --> <property> <description>The maximum allocation for every container request at the RM in MBs. Memory requests higher than this will throw an InvalidResourceRequestException.</description> <name>yarn.scheduler.maximum-allocation-mb</name> <value>2048</value> </property> <!-- Minimum container CPU Number of cores, 1 by default --> <property> <description>The minimum allocation for every container request at the RM in terms of virtual CPU cores. Requests lower than this will be set to the value of this property. Additionally, a node manager that is configured to have fewer virtual cores than this value will be shut down by the resource manager.</description> <name>yarn.scheduler.minimum-allocation-vcores</name> <value>1</value> </property> <!-- Container Max CPU The number of cores is 4 by default and modified to 2 --> <property> <description>The maximum allocation for every container request at the RM in terms of virtual CPU cores. Requests higher than this will throw an InvalidResourceRequestException.</description> <name>yarn.scheduler.maximum-allocation-vcores</name> <value>2</value> </property> <!-- Virtual memory check is on by default and changed to off --> <property> <description>Whether virtual memory limits will be enforced for containers.</description> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- Virtual memory and physical memory setting ratio,Default 2.1 --> <property> <description>Ratio between virtual memory to physical memory when setting memory limits for containers. Container allocations are expressed in terms of physical memory, and virtual memory usage is allowed to exceed this allocation by this ratio.</description> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property>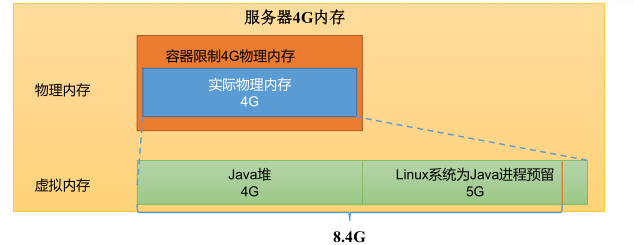
- Distribution configuration
Note: if the hardware resources of the cluster are inconsistent, each NodeManager should be configured separatelycd /opt/module/hadoop-3.1.3/ cd /etc/hadoop/ vim yarn-site.xml xsync yarn-site.xml
- Restart the cluster: myhadoop SH start, or
sbin/stop-yarn.sh sbin/start-yarn.sh
- Execute WordCount program
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
- Observe the Yarn task execution page: http://hadoop103:8088/cluster/apps , or jpsall to view the status
2.2 capacity scheduler multi queue submission cases
- How do I create queues in a production environment?
- The scheduler has a default queue by default, which cannot meet the production requirements.
- According to the framework: hive /spark/ flink, the tasks of each framework are put into the specified queue
- According to the business module: login registration, shopping cart, order, business department 1, business department 2
- What are the benefits of creating multiple queues?
- Worry about writing recursive dead loop code and exhausting all resources.
- Realize the degraded use of tasks, and ensure sufficient resources for important task queues in special periods. 11.11 6.18 business department 1 (important) = "business department 2 (more important) =" order placement (general) = "shopping cart (general) =" login registration (secondary)
2.2.1 requirements
Requirement 1: the default queue accounts for 40% of the total memory, the maximum resource capacity accounts for 60% of the total resources, and the hive queue accounts for 60% of the total memory
60%, and the maximum resource capacity accounts for 80% of the total resources.
Requirement 2: configure queue priority
2.2.2 configure multi queue capacity scheduler
- Enter the cd /etc/hadoop / path and download the file locally for modification: SZ capacity scheduler XML, in capacity scheduler XML is configured as follows:
- Modify the following configuration:
<!-- Specify multiple queues and add hive queue --> <property> <name>yarn.scheduler.capacity.root.queues</name> <value>default,hive</value> <description>The queues at the this level (root is the root queue).</description> </property> <!-- reduce default The rated capacity of queue resources is 40%,Default 100% --> <property> <name>yarn.scheduler.capacity.root.default.capacity</name> <value>40</value> </property> <!-- reduce default The maximum capacity of queue resources is 60%,Default 100% --> <property> <name>yarn.scheduler.capacity.root.default.maximum-capacity</name> <value>60</value> </property> - Add the necessary attributes for the newly added queue:
<!-- appoint hive Rated resource capacity of the queue --> <property> <name>yarn.scheduler.capacity.root.hive.capacity</name> <value>60</value> </property> <!-- The maximum number of resources users can use in the queue. 1 indicates how many resources in the queue can be exhausted. The configuration range is 0.0 To 1.0--> <property> <name>yarn.scheduler.capacity.root.hive.user-limit-factor</name> <value>1</value> </property> <!-- appoint hive Maximum resource capacity of the queue --> <property> <name>yarn.scheduler.capacity.root.hive.maximum-capacity</name> <value>80</value> </property> <!-- start-up hive queue --> <property> <name>yarn.scheduler.capacity.root.hive.state</name> <value>RUNNING</value> </property> <!-- Which users have the right to submit jobs to the queue,*Represents all users --> <property> <name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name> <value>*</value> </property> <!-- Which users have permission to operate the queue, administrator permission (view)/Kill) --> <property> <name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name> <value>*</value> </property> <!-- Which users have the right to configure the priority of submitting tasks --> <property> <name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</name> <value>*</value> </property> <!-- Task timeout setting: yarn application -appId appId -updateLifetime Timeout reference material: https://blog.cloudera.com/enforcing-application-lifetime-slas-yarn/ --> <!-- If application If a timeout is specified, the number of requests submitted to the queue application The maximum timeout that can be specified cannot exceed this value.--> <property> <name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime</name> <value>-1</value> </property> <!-- If application If no timeout is specified, use default-application-lifetime As default --> <property> <name>yarn.scheduler.capacity.root.hive.default-application-lifetime</name> <value>-1</value> </property>
- Distribution profile: XSync capacity scheduler xml
- Restart Yarn or execute yarn rmadmin -refreshQueues to refresh the queue, and you can see two queues
- Run task, - D MapReduce job. Queuename = hive specifies the queue, which means that the parameter value is changed at run time
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -D mapreduce.job.queuename=hive /input /output
2.2.3 submit tasks to hive queue
- hadoop jar mode, as described in the previous section
- jar packaging method
public class WcDrvier { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); conf.set("mapreduce.job.queuename","hive"); //1. Get a Job instance Job job = Job.getInstance(conf); . . . . . . //6. Submit Job boolean b = job.waitForCompletion(true); System.exit(b ? 0 : 1); } }
2.2.4 task priority
The capacity scheduler supports the configuration of task priority. When resources are tight, tasks with high priority will get resources first.
By default, Yarn limits the priority of all tasks to 0. If you want to use the priority function of tasks, you must open this limit. 5 has the highest priority.
- Modify Yard site XML file, add the following parameters
<property> <name>yarn.cluster.max-application-priority</name> <value>5</value> </property> - Distribute the configuration and restart the Yarn, XSync Yarn site xml,sbin/stop-yarn.sh,sbin/start-yarn.sh
- Simulate the resource tight environment, and submit the following tasks continuously until the newly submitted task fails to apply for resources. Hadoop jar / opt / module / hadoop-3.1.3 / share / Hadoop / MapReduce / Hadoop MapReduce examples 3.1.3 jar pi 5 2000000
- Resubmit the high priority task again, Hadoop jar / opt / module / hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3 jar pi -D mapreduce. job. priority=5 5 2000000
- You can also modify the priority of the task being executed through the following commands: yarn application - appid < applicationid > - updatepriority priority. For example: yarn application -appID application_1611133087930_0009 -updatePriority 5
2.3 fair dispatching cases
2.3.1 requirements
Create two queues, test and atguigu (named after the group to which the user belongs). It is expected to achieve the following effects: if the user specifies a queue when submitting a task, the task will be submitted to the specified queue for operation; If no queue is specified, the task submitted by the test user will be sent to root group. The test queue runs, and the task submitted by atguigu is sent to root group. The atguigu queue runs (Note: group refers to the group to which the user belongs).
The configuration of the fair scheduler involves two files, one of which is yen site XML, and the other is fair scheduler queue allocation file fair scheduler XML (the file name can be customized).
(1) Configuration file reference official website:
https://hadoop.apache.org/docs/r3.1.3/hadoop-yarn/hadoop-yarn-site/FairScheduler.html
(2) Task queue placement rule reference:
https://blog.cloudera.com/untangling-apache-hadoop-yarn-part-4-fair-scheduler-queue-
basics/
2.3.2 configuring a fair scheduler with multiple queues
- Modify Yard site XML file, add the following parameters
<property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> <description>Configure fair scheduler</description> </property> <property> <name>yarn.scheduler.fair.allocation.file</name> <value>/opt/module/hadoop-3.1.3/etc/hadoop/fair-scheduler.xml</value> <description>Indicates the fair scheduler queue allocation profile</description> </property> <property> <name>yarn.scheduler.fair.preemption</name> <value>false</value> <description>Prohibit inter queue resource preemption</description> </property> - Configure fair scheduler xml
<?xml version="1.0"?> <allocations> <!-- In a single queue Application Master Maximum proportion of resources occupied,Value 0-1 ,Enterprise general configuration 0.1--> <queueMaxAMShareDefault>0.5</queueMaxAMShareDefault> <!-- Default value for maximum resources of a single queue test atguigu default --> <queueMaxResourcesDefault>4096mb,4vcores</queueMaxResourcesDefault> <!-- Add a queue test --> <queue name="test"> <!-- Queue minimum resource --> <minResources>2048mb,2vcores</minResources> <!-- Queue maximum resources --> <maxResources>4096mb,4vcores</maxResources> <!-- The maximum number of applications running simultaneously in the queue is 50 by default, which is configured according to the number of threads --> <maxRunningApps>4</maxRunningApps> <!-- In queue Application Master Maximum proportion of resources occupied --> <maxAMShare>0.5</maxAMShare> <!-- The queue resource weight,The default value is 1.0 --> <weight>1.0</weight> <!-- Resource allocation policy within the queue --> <schedulingPolicy>fair</schedulingPolicy> </queue> <!-- Add a queue atguigu --> <queue name="atguigu" type="parent"> <!-- Queue minimum resource --> <minResources>2048mb,2vcores</minResources> <!-- Queue maximum resources --> <maxResources>4096mb,4vcores</maxResources> <!-- The maximum number of applications running simultaneously in the queue is 50 by default, which is configured according to the number of threads --> <maxRunningApps>4</maxRunningApps> <!-- In queue Application Master Maximum proportion of resources occupied --> <maxAMShare>0.5</maxAMShare> <!-- The queue resource weight,The default value is 1.0 --> <weight>1.0</weight> <!-- Resource allocation policy within the queue --> <schedulingPolicy>fair</schedulingPolicy> </queue> <!-- Task queue allocation policy,Configurable multi tier rules,Match from the first rule,Until the match is successful --> <queuePlacementPolicy> <!-- Specify queue when submitting task,If no submission queue is specified,Then continue to match the next rule; false Indicates: if the specified queue does not exist,Automatic creation is not allowed--> <rule name="specified" create="false"/> <!-- Submit to root.group.username queue,if root.group non-existent,Automatic creation is not allowed; if root.group.user non-existent,Allow automatic creation --> <rule name="nestedUserQueue" create="true"> <rule name="primaryGroup" create="false"/> </rule> <!-- The last rule must be reject perhaps default. Reject Indicates that the creation submission was rejected and failed, default Indicates that the task is submitted to default queue --> <rule name="reject" /> </queuePlacementPolicy> </allocations> - Distribute the configuration and restart Yan, XSync Yan site xml,xsync fair-scheduler.xml,sbin/stop-yarn.sh,sbin/start-yarn.sh
2.3.3 Test submission task
- When submitting a task, specify the queue. According to the configuration rules, the task will be sent to the specified root Test queue. hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi -Dmapreduce.job.queuename=root.test 1 1
- The queue is not specified when submitting the task. According to the configuration rules, the task will be sent to the root atguigu. Atguigu queue. hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 1 1
2.4 Yarn Tool interface case
- Requirements: the jar program written by yourself executes, - D setting parameters, which is mistaken for parameter transmission, resulting in an error in the running task. Therefore, it is hoped that the jar program written by yourself can also support dynamic parameter modification. Therefore, write Yan's Tool interface.
- Specific steps:
- New Maven project YarnDemo, pom as follows:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.atguigu</groupId> <artifactId>YarnDemo</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.1.3</version> </dependency> </dependencies> </project> - New com atguigu. Yarn package name
- Create a WordCount class and implement the Tool interface:
package com.atguigu.yarn; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import java.io.IOException; public class WordCount implements Tool { private Configuration conf; //Core driver (conf needs to be passed in) @Override public int run(String[] args) throws Exception { Job job = Job.getInstance(conf); job.setJarByClass(WordCountDriver.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); return job.waitForCompletion(true) ? 0 : 1; } @Override public void setConf(Configuration conf) { this.conf = conf; } @Override public Configuration getConf() { return conf; } //mapper public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private Text outK = new Text(); private IntWritable outV = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] words = line.split(" "); for (String word : words) { outK.set(word); context.write(outK, outV); } } } //reducer public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable outV = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); } outV.set(sum); context.write(key, outV); } } } - New WordCountDriver
package com.atguigu.yarn; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.util.Arrays; public class WordCountDriver { private static Tool tool; public static void main(String[] args) throws Exception { // 1. Create a profile Configuration conf = new Configuration(); // 2. Judge whether there is a tool interface switch (args[0]){ case "wordcount": tool = new WordCount(); break; default: throw new RuntimeException(" No such tool: "+ args[0] ); // 3. Execute the program with Tool // Arrays.copyOfRange puts the elements of the old array into the new array int run = ToolRunner.run(conf, tool, Arrays.copyOfRange(args, 1, args.length)); System.exit(run); } } }
- Prepare the input file on HDFS, assuming the / input directory, and submit the Jar package to the cluster. yarn jar YarnDemo.jar com.atguigu.yarn.WordCountDriver wordcount /input /output. Note the three parameters submitted at this time. The first one is used to generate a specific Tool, and the second and third are input and output directories. At this time, if we want to add setting parameters, we can add parameters after wordcount, for example: yarn Jar yarndemo Jar com. atguigu. yarn. WordCountDriver wordcount -Dmapreduce. job. queuename=root. test /input /output1