Character encoding and file manipulation
1. Character coding

1.1 what is character encoding
The information stored in the computer is represented by binary numbers; The English and Chinese characters we see on the screen are the result of binary number conversion. Generally speaking, according to what rules characters are stored in the computer, such as what is represented by 'a', which is called "coding"; On the contrary, the binary number stored in the computer is parsed and displayed, which is called "decoding".
1.2 development history of character coding
1.2.1 ASCII code
Modern computers originated in the United States, so at that time, the United States invented a coding method only suitable for them, namely ASCII code.
ASCII encoding: a rule that converts an ASCII character set to a number in a number system acceptable to the computer. ASCII is designed with only 128 characters. In order to represent more common European characters, ASCII is extended. The ASCII extended character set uses 8 bits to represent one character, a total of 256 characters.

The biggest disadvantage of ASCII is that it can only display 26 Basic Latin letters, Arabic numerals and British punctuation marks. Therefore, it can only be used to display modern American English and cannot support the languages of other countries.
1.2.2 country codes
After the emergence of computers for a long time, they were only used in the United States and some western developed countries. ASCII can well meet the needs of users. However, after the computer enters China, in order to display Chinese, a set of coding rules must be designed to convert Chinese characters into numbers acceptable to the computer.
Domestic experts cancelled those strange symbols after the 127 (i.e. EASCII) and stipulated that a character less than 127 has the same meaning as the original, but when two characters greater than 127 are connected together, it means a Chinese character. In this way, we can combine more than 7000 simplified Chinese characters (actually only 6763 Chinese characters). In these codes, mathematical symbols, Roman and Greek letters and Japanese pseudonyms are also coded in. Even the original numbers, punctuation and letters in ASCII are re coded with two byte long codes, which are often called "full angle" characters, while those below No. 127 are called "half angle" characters. This is GB2312.
Chinese characters Chinese characters are basically met by the appearance of GB2312. The Chinese characters it has collected has covered 99.75% of the frequency of use in Chinese mainland. GB2312 can't handle the rare words in people's names and ancient Chinese, which led to the emergence of GBK and GB 18030 Chinese character sets.
GB 18030, full name: the national standard GB 18030-2005 Chinese coded character set for information technology is the latest internal code character set of the people's Republic of China and the revised version of GB 18030-2000 basic set of Chinese coded character set for information technology and information exchange. It is fully compatible with GB 2312-1980 and basically compatible with GBK. It supports all unified Chinese characters of GB 13000 and Unicode, including 70244 Chinese characters.
The current version was issued by the State Administration of quality supervision, inspection and the National Standardization Administration of China on November 8, 2005 and implemented on May 1, 2006. This specification is mandatory for all software products in China.
When the computer is transmitted to all countries in the world, in order to adapt to the local language and characters, design and implement a set of codes similar to GB232/GBK. There is no problem in local use. Once it appears in the network, due to incompatibility, there will be random codes when accessing each other. In order to solve this problem, Unicode appeared
1.2.3 Unicode
Unicode (unified code, universal code, single code, standard universal code) is a standard in the industry. The Unicode encoding system is designed to express any character in any language. It uses 4-byte numbers to express each letter, symbol, or ideograph. Each number represents a unique symbol used in at least one language.
It enables computers to embody the system of dozens of words in the world. Unicode is developed based on the standard of Universal Character Set and published in the form of books. So far, Unicode has contained more than 100000 characters. The Unicode Consortium is operated by a non-profit organization and leads the follow-up development of Unicode, Its goal is to replace the existing character coding scheme with Unicode coding scheme. Especially, the existing schemes have only limited space and incompatibility in multilingual environment.
Unicode character encoding scheme: UTF-32, UTF-16, UTF-8
-
UTF-32
Use 4-byte numbers to express each letter, symbol, or ideograph. Each number represents a unique coding scheme of symbols used in at least one language. Use 4 bytes for each character. In terms of space, it is very inefficient. That is, it occupies 4 bytes.
-
UTF-16
The most obvious advantage of UTF-16 coding is that it is twice as space efficient as UTF-32, because each character only needs 2 bytes to store, rather than 4 bytes in UTF-32. Although its UTF-16 is spatially efficient, it will expand the storage capacity of four bytes beyond two bytes. However, each character occupies two bytes, and some space will be wasted when the certificate of deposit is one byte.
-
UTF-8
UTF-8 (8-bit Unicode Transformation Format) is a variable length character encoding (fixed length code) for Unicode and a prefix code. It can be used to represent any character in the Unicode standard, and the first byte in its encoding is still compatible with ASCII, which makes the original software dealing with ASCII characters continue to use without or with only a few modifications. Therefore, it has gradually become the preferred coding in e-mail, web pages and other applications for storing or transmitting text. The Internet Engineering Task Force (IETF) requires that all Internet protocols must support UTF-8 coding.
UTF-8 uses one to four bytes to encode each character (ASCII compatible):
ASCII characters require only one byte encoding
Latin, Greek, Cyrillic, Armenian, Hebrew, Arabic, Syrian and other alphabets with additional symbols require two byte encoding
Characters in other basic multilingual planes (BMP s), which contain most common words, are encoded in three bytes
Other rarely used Unicode auxiliary plane characters use four byte encoding.
It is very effective in dealing with ASCII characters that are often used. It is also no worse than UTF-16 in dealing with the extended Latin character set. For Chinese characters, it is better than UTF-32.
Now the default encoding is utf8
Note that the software is stored on the hard disk, and running the software is to load the software into the memory. In the face of various traditional coded software stored in the hard disk, if we want our computer to run them normally without garbled code, there must be a universal compatible code in the memory, and the code needs to have a corresponding mapping / conversion relationship with other codes.
1.3 character coding exercise
How to solve the problem of file scrambling: the file was encoded in what format and decoded in what format when it was opened.
In the Python interpreter, the encoding method of python2 version is ACSII code by default, and the encoding method of python3 version is UTF8 by default
UTF-8 is used in the python 2 version
[root@hans ~]#cat py2.py str1 = "Hello" print(str1) [root@hans ~]# python --version Python 2.7.5 [root@hans ~]# python py2.py File "py2.py", line 1 SyntaxError: Non-ASCII character '\xe4' in file py2.py on line 1, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details # An error will be reported when using the python 2 version. resolvent: [root@hans ~]#cat py2.py #coding:utf8 #Write the line at the beginning and tell the interpreter to use utf8 for the following encoding str1 = u"Hello" #A small u should be added in front of the definition string to tell the interpreter that this is a unicode print(str1)
1.4 encoding and decoding
What is encoding?
Convert the characters we can read into 0 and 1 that can be recognized by the computer according to the corresponding coding type.
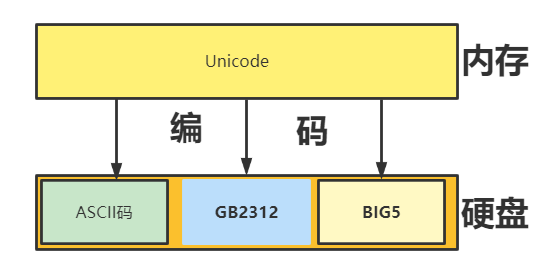
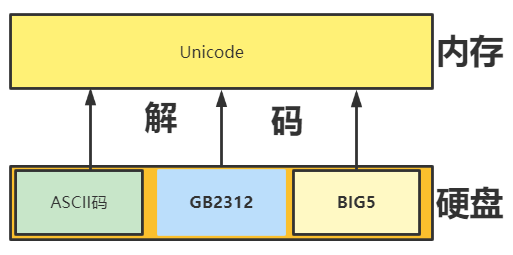
What is decoding?
Convert 0 and 1 into characters that we can understand according to the corresponding decoding type
Example:
#code
str1 = "study hard and make progress every day"
enstr = str1.encode('utf8') #Encode string as utf8
print(enstr)
Print results:
b'\xe5\xa5\xbd\xe5\xa5\xbd\xe5\xad\xa6\xe4\xb9\xa0 \xe5\xa4\xa9\xe5\xa4\xa9\xe5\x90\x91\xe4\xb8\x8a'
#decode:
destr = enstr.decode("utf8")
print(destr)
#Print results:
study hard and make progress every day
#Full script:
[root@hans_tencent_centos82 ~]# cat deencode.py
str1 = "study hard and make progress every day"
enstr = str1.encode('utf8')
print(enstr)
destr = enstr.decode("utf8")
print(destr)
#Execution results:
[root@hans_tencent_centos82 ~]# python3 deencode.py
b'\xe5\xa5\xbd\xe5\xa5\xbd\xe5\xad\xa6\xe4\xb9\xa0 \xe5\xa4\xa9\xe5\xa4\xa9\xe5\x90\x91\xe4\xb8\x8a'
study hard and make progress every day
2. File operation
There are three main steps to use python to manipulate files:
- Open file
- Operation file
- Close file
Method 1 of operating files with python:
2.1 usage of open():
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
Parameter Description:
- File: required, file path (relative or absolute path).
- Mode: optional, file open mode
- Buffering: setting buffering
- encoding: utf8 is generally used
- errors: error level
- newline: distinguish line breaks
- closefd: type of file parameter passed in
- Opener: set a custom opener. The return value of the opener must be an open file descriptor.
The mode parameters are:
| pattern | describe |
|---|---|
| r | Open the file as read-only. The pointer to the file will be placed at the beginning of the file. This is the default mode. |
| w | Open a file for writing only. If the file already exists, open the file and edit it from the beginning, that is, the original content will be deleted. If the file does not exist, create a new file. |
| a | Open a file for append. If the file already exists, the file pointer will be placed at the end of the file. That is, the new content will be written after the existing content. If the file does not exist, create a new file for writing |
Example:
# a.txt file content
There's a fire starting in my heart
Reaching a fever pitch and it's bringing me out the dark
Finally I can see you crystal clear
Go ahead and sell me out and I'll lay your ship bare
See how I leave with every piece of you
Don't underestimate the things that I will do
There's a fire starting in my heart
# Script: mod:r read only mode
[root@hans_tencent_centos82 tmp]# cat test.py
#!/usr/bin/env python3
file1 = 'a.txt'
res = open(file1, 'r', encoding='utf8')
print(res.read())
res.close()
#In the computer, some symbols with letters have special meanings, such as \ a or \ n. if they are written directly into the script, it may cause ambiguity. You can use r to cancel
file1 = r'D:\pycharm\codestudy\n.txt'
r Just deal with what you write as it is.
# Execute script
[root@hans_tencent_centos82 tmp]# python3 test.py
There's a fire starting in my heart
Reaching a fever pitch and it's bringing me out the dark
Finally I can see you crystal clear
Go ahead and sell me out and I'll lay your ship bare
See how I leave with every piece of you
Don't underestimate the things that I will do
There's a fire starting in my heart
# If the file does not exist, an error will be reported:
[root@hans_tencent_centos82 tmp]# python3 test.py
Traceback (most recent call last):
File "test.py", line 5, in <module>
res = open(file1, 'r', encoding='utf8')
FileNotFoundError: [Errno 2] No such file or directory: 'b.txt'
# Script: mod:w write only mode
# If the file exists:
[root@hans_tencent_centos82 tmp]# cat test.py
#!/usr/bin/env python3
file1 = 'a.txt'
res = open(file1, 'w', encoding='utf8')
res.write("Hello world!\n")
res.close()
[root@hans_tencent_centos82 tmp]# python3 test.py
[root@hans_tencent_centos82 tmp]# cat a.txt
Hello world!
# It is found that the contents before the a.txt file are gone, only the last line written.
# If the file exists, empty the file content first, and then perform the write operation.
# If the file does not exist:
[root@hans_tencent_centos82 tmp]# ls -lrt b.txt # file does not exist
ls: cannot access 'b.txt': No such file or directory
[root@hans_tencent_centos82 tmp]# cat test.py
#!/usr/bin/env python3
file1 = 'b.txt'
res = open(file1, 'w', encoding='utf8')
res.write("Hi!\n")
res.close()
[root@hans_tencent_centos82 tmp]# python3 test.py
[root@hans_tencent_centos82 tmp]# cat b.txt
Hi!
# If the file does not exist, it is created automatically
When you use the open() function to process files, you sometimes forget to close the file. You can use with instead.
2.2 context management (with)
The context manager is an object that defines the with The runtime context to be established when the statement. The context manager handles the runtime context required to enter and exit to execute code blocks. with statements are usually used, but they can also be used by calling their methods directly.
Typical uses of context manager include saving and restoring various global states, locking and unlocking resources, closing open files, and so on.
Example:
# Read:
file1 = 'a.txt'
with open(file1,'r',encoding='utf8') as f:
print(f.read())
result:
Hello world!
# Write:
file1 = 'a.txt'
with open(file1,'w',encoding='utf8') as f:
f.write('Hi\n')
#result:
Hi
#It will still empty and rebuild the previous.
2.3 add mode
The contents demonstrated above are read-only and cannot be written. Those that can be written cannot retain the previous contents. If you want to retain the previous contents when writing, you can use mode a.
Example:
# Current a.txt file content:
Hello world!
#Add content:
If you miss the train I'm on
You will know that I am gone
You can hear the whistle blow a hundred miles
A hundred miles, a hundred miles
# script:
[root@hans_tencent_centos82 tmp]# cat test.py
#!/usr/bin/env python3
file1 = 'a.txt'
with open(file1,'a',encoding='utf8') as f:
f.write("If you miss the train I'm on\n")
f.write("You will know that I am gone\n")
f.write("You can hear the whistle blow a hundred miles\n")
f.write("A hundred miles, a hundred miles\n")
# Execution results:
[root@hans_tencent_centos82 tmp]# cat a.txt
Hello world!
If you miss the train I'm on
You will know that I am gone
You can hear the whistle blow a hundred miles
A hundred miles, a hundred miles
with syntax is recommended
In some operations, you can only register the syntax structure without any operations:
pass or