Write in front
Recently, I was working on model compression. After training a network with good recognition rate, I began to try to compress the model smaller in different ways to facilitate deployment on different platforms. The large model has higher precision and can be deployed on servers with GPU. The precision of the small model is a little poor, but the model is smaller, less parameters and fast, It is easy to deploy at the edge or mobile devices.
At present, several different model compression schemes have been tried:
- Use a mobile type network instead of the backbone (mobileNet V3, GhsotNet, etc.);
- Combined with knowledge distillation, the large model is used to train the small model;
- Channel clipping technology;
- Quantitative training (not attempted).
At the beginning, I tried to use mobilenetv3 and GhsotNet as the trunk of CRNN for direct training. The effect is not ideal. The accuracy is far from meeting the requirements, so I gave up. I began to analyze the reasons and felt that the ability of small models was still limited. Can I combine knowledge distillation to train a small model? I'm sure I can. After using ResNet34 (a large model in CRNN) as the backbone to train a model with high accuracy, I took it as the teacher model, Using knowledge distillation technology to drive a mobile TV 3 trunk model for training, although the accuracy is improved by one or two points, the effect is still not enough! (it may be that the opening method is wrong, and there will be time to analyze the reasons later). Finally, I thought of using channel clipping to compress the model, and found that the effect is still very excellent. With almost no loss of accuracy, the model size is reduced by 75%. This article records the process of using channel clipping technology to compress the CRNN model size from 41M to 7.5M.
The model cutting technology used in this paper is based on the paper Learning Efficient Convolutional Networks Through Network Slimming (ICCV 2017) The principle is based on the bn layer gamma coefficient for channel pruning. Those interested can search Baidu for the principle. There are many articles to explain it. Due to the limited space, it will not be described too much in this paper. Code implementation based on PytorchOCR Code warehouse, a very easy-to-use ocr warehouse, based on the pytorch implementation of paddleocr, strong Amway.
1, Pruning work
Before that, sort out the process of model pruning:
- Basic training, i.e. normal training;
- Sparse training, applying a sparse factor to BN layer for training;
- Model pruning;
- Fine tune training.
Before basic training, select a well tailored network for basic training. VGG13 is directly used here (because CRNN itself is a small network, there is no need to build too large a model and increase the training cost) as the backbone. The network structure is as follows:
class VGG(nn.Module):
def __init__(self, init_weights=True, deploy=False):
super(VGG, self).__init__()
cfg = [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512]
cls_ch_squeeze = cfg[-1]
self.feature = self.make_layers(cfg, True)
self.out_channels = cls_ch_squeeze
if init_weights:
self._initialize_weights()
def make_layers(self, cfg, batch_norm=False):
layers = []
in_channels = 3
for i , v in enumerate(cfg):
if v == 'M':
if i == 2 or i == 5:
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif i == 8:
layers += [nn.MaxPool2d(kernel_size=2, stride=(2,1),padding=(0,1))]
else:
layers += [nn.MaxPool2d(kernel_size=2, stride=(2, 1))]
else:
if i == 13:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, stride=(2, 1), padding=1, bias=False)
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1, bias=False)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
def forward(self, x):
out = self.feature(x)
return out
During training, the tensorboard is used to record the BN distribution in the training process. The BN distribution changes in the whole training process are as follows:
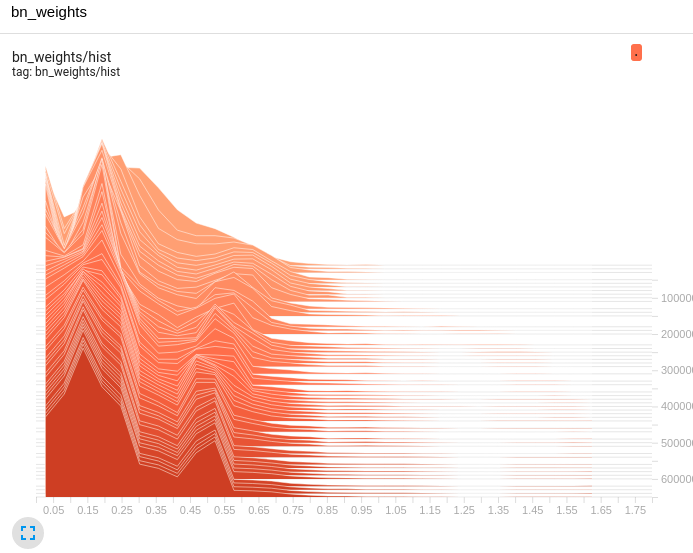
Because it is uncompressed and generally distributed, the accuracy of the model will be greatly affected by cutting at this time. Therefore, the model should be sparsely trained to approximate the distribution of BN to 0.
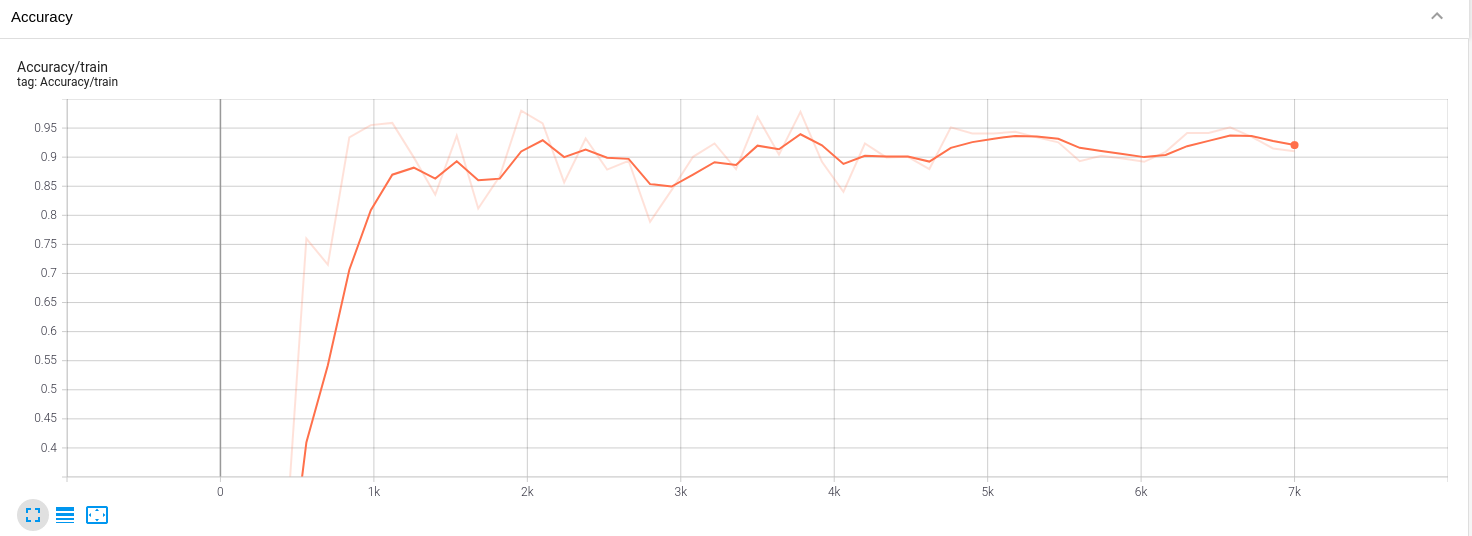
Let's look at the accuracy that basic training can achieve:
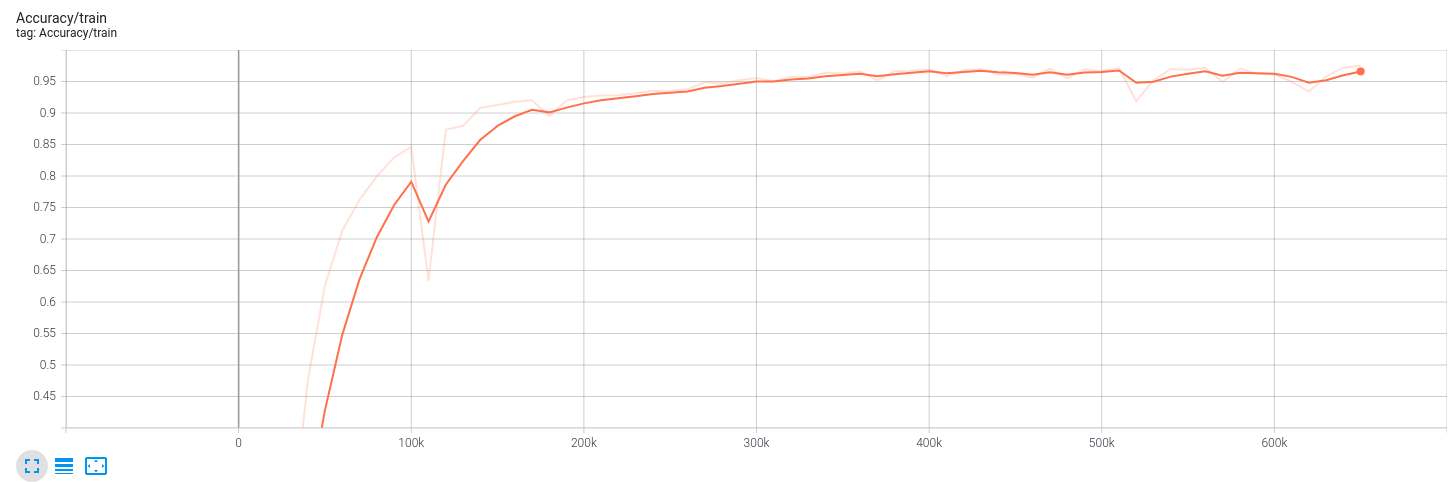
It seems that it's not bad. In the past, the following code is used to train the model sparsity, and S is the sparsity factor.
def updateBN(model,s): # Extract BN layer
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
m.weight.grad.data.add_(s*torch.sign(m.weight.data)) # L1
Retrain and look at the results of sparse training. First, the distribution of BN layer:
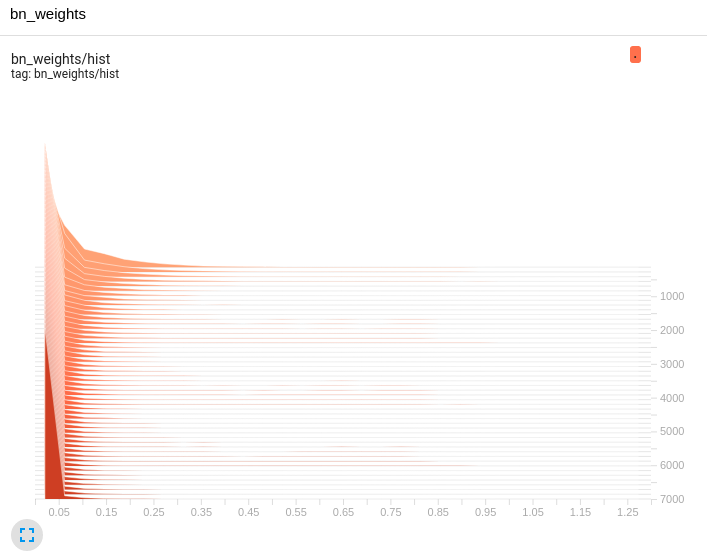
It can be seen that the compression of BN is good, and the whole tends to 0. At this time, it can be considered that the more layers tend to 0, the smaller the impact on the network after cutting, that is, this part can be cut off to see the accuracy.
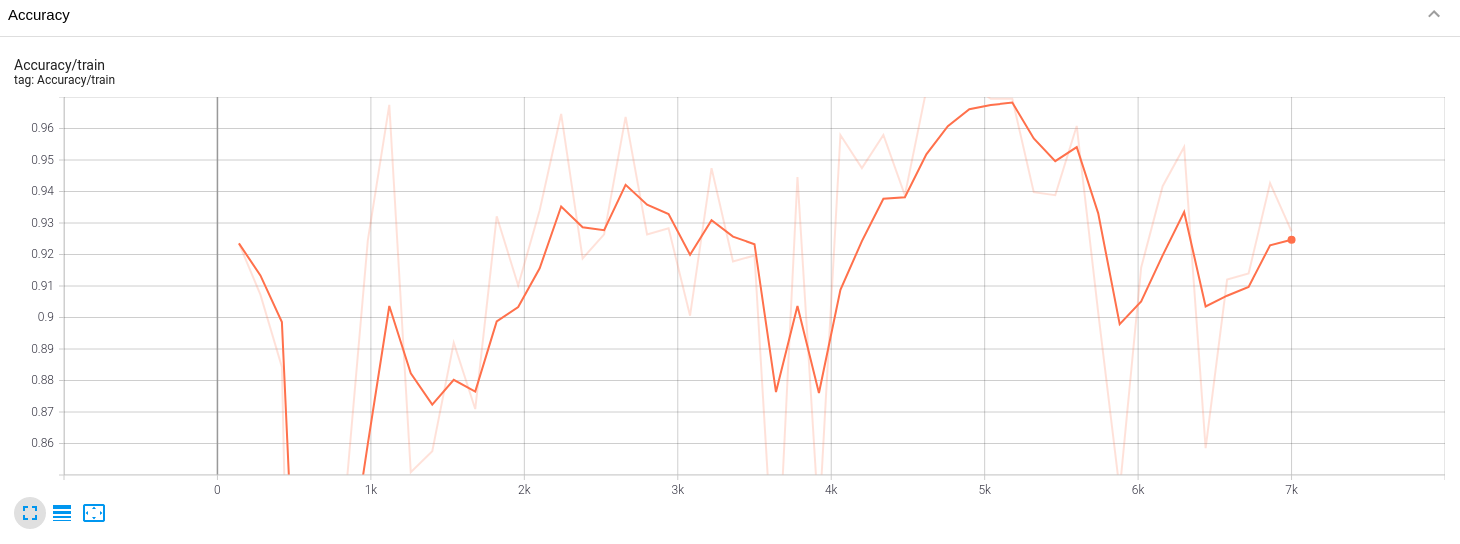
It can be seen that at the beginning of sparsity, the accuracy fluctuation is relatively large, but it doesn't matter. From the distribution of BN layer, the overall compression is good.
The next step is to prune the model. First, you need to put the parameter clone s of all BN layers in the network into the list, sort them by using the sorting function, and then set a pruning ratio, such as 0.8, and then find the BN parameter size at the position of 0.8 as the threshold value. Those less than this threshold value are cut off, and those greater than this threshold value are retained, Note that the output of the previous layer is used as the input of the next layer, which should be aligned.
Finally, fine tune the model after pruning, and the accuracy recovers quickly, although there is a little loss:
Finally, compare the parameters before and after the model. Before pruning:
================================================================= Layer (type:depth-idx) Param # ================================================================= ├─VGG: 1-1 -- | └─Sequential: 2-1 -- | | └─Conv2d: 3-1 1,728 | | └─BatchNorm2d: 3-2 128 | | └─ReLU: 3-3 -- | | └─Conv2d: 3-4 36,864 | | └─BatchNorm2d: 3-5 128 | | └─ReLU: 3-6 -- | | └─MaxPool2d: 3-7 -- | | └─Conv2d: 3-8 73,728 | | └─BatchNorm2d: 3-9 256 | | └─ReLU: 3-10 -- | | └─Conv2d: 3-11 147,456 | | └─BatchNorm2d: 3-12 256 | | └─ReLU: 3-13 -- | | └─MaxPool2d: 3-14 -- | | └─Conv2d: 3-15 294,912 | | └─BatchNorm2d: 3-16 512 | | └─ReLU: 3-17 -- | | └─Conv2d: 3-18 589,824 | | └─BatchNorm2d: 3-19 512 | | └─ReLU: 3-20 -- | | └─MaxPool2d: 3-21 -- | | └─Conv2d: 3-22 1,179,648 | | └─BatchNorm2d: 3-23 1,024 | | └─ReLU: 3-24 -- | | └─Conv2d: 3-25 2,359,296 | | └─BatchNorm2d: 3-26 1,024 | | └─ReLU: 3-27 -- | | └─MaxPool2d: 3-28 -- | | └─Conv2d: 3-29 2,359,296 | | └─BatchNorm2d: 3-30 1,024 | | └─ReLU: 3-31 -- | | └─Conv2d: 3-32 2,359,296 | | └─BatchNorm2d: 3-33 1,024 | | └─ReLU: 3-34 -- ├─SequenceEncoder: 1-2 -- | └─Im2Seq: 2-2 -- | └─EncoderWithRNN: 2-3 -- | | └─LSTM: 3-35 271,872 ├─CTC: 1-3 -- | └─Linear: 2-4 578,411 ================================================================= Total params: 10,258,219 Trainable params: 10,258,219 Non-trainable params: 0 =================================================================
================================================================= Layer (type:depth-idx) Param # ================================================================= ├─VGG: 1-1 -- | └─Sequential: 2-1 -- | | └─Conv2d: 3-1 972 | | └─BatchNorm2d: 3-2 72 | | └─ReLU: 3-3 -- | | └─Conv2d: 3-4 16,200 | | └─BatchNorm2d: 3-5 100 | | └─ReLU: 3-6 -- | | └─MaxPool2d: 3-7 -- | | └─Conv2d: 3-8 32,850 | | └─BatchNorm2d: 3-9 146 | | └─ReLU: 3-10 -- | | └─Conv2d: 3-11 60,444 | | └─BatchNorm2d: 3-12 184 | | └─ReLU: 3-13 -- | | └─MaxPool2d: 3-14 -- | | └─Conv2d: 3-15 74,520 | | └─BatchNorm2d: 3-16 180 | | └─ReLU: 3-17 -- | | └─Conv2d: 3-18 96,390 | | └─BatchNorm2d: 3-19 238 | | └─ReLU: 3-20 -- | | └─MaxPool2d: 3-21 -- | | └─Conv2d: 3-22 100,674 | | └─BatchNorm2d: 3-23 188 | | └─ReLU: 3-24 -- | | └─Conv2d: 3-25 113,364 | | └─BatchNorm2d: 3-26 268 | | └─ReLU: 3-27 -- | | └─MaxPool2d: 3-28 -- | | └─Conv2d: 3-29 305,118 | | └─BatchNorm2d: 3-30 506 | | └─ReLU: 3-31 -- | | └─Conv2d: 3-32 403,029 | | └─BatchNorm2d: 3-33 354 | | └─ReLU: 3-34 -- ├─SequenceEncoder: 1-2 -- | └─Im2Seq: 2-2 -- | └─EncoderWithRNN: 2-3 -- | | └─LSTM: 3-35 143,232 ├─CTC: 1-3 -- | └─Linear: 2-4 578,411 ================================================================= Total params: 1,927,440 Trainable params: 1,927,440 Non-trainable params: 0 =================================================================
When I set the pruning ratio to 0.62, the number of parameters is reduced by about 80%, because I only cut the CNN layer, and the LSTM layer in CRNN also accounts for the parameters. This part is not handled. The maximum limit I have tried is to cut the ratio of 0.87, and the CNN parameters are reduced by more than 95%. Why can you cut so much? In fact, it has something to do with the quality of thinning. When your thinning is not ideal, the distribution proportion of BN close to 0 is relatively small. At this time, it is impossible to cut too high proportion. Here, we must emphasize the importance of thinning.
The final result is that when the model accuracy drops one or two points, the model size is reduced to 20% of the original, and the reasoning speed is 5-10 times faster.
2, Digression
In terms of improving the accuracy of model recognition, I found a surprise. Using repvgg-A0 (the smallest model) as the backbone, the accuracy can reach 99.9. After converting the training model into the deployment model, the reasoning speed can reach the single digit millisecond level on the 1050Ti GPU, which can not be achieved by resnet18 and mobilenet series as the backbone, At the same time, reasoning on the cpu can reach more than ten milliseconds. It's really nice. It's really a combination of precision and speed. It's super strong!! The only disadvantage is that the model is a little larger. As the backbone, the size of the whole CRNN model is close to 50M... Well, it's OK to use it on the server, but it's a little big at the edge. Then I tried to cut it, but I found that the pit is so big... I'll talk about it next time.
what? Code? No, Share ideas, work is not easy, refuse white whoring. Gu Debai ~
