Background and objectives
Optical character recognition (OCR) is a process of converting handwritten or printed text in an image into machine coded text to obtain text and layout information in the image. Its purpose is to recognize the words in the picture for further word processing.
The earliest OCR technology can be traced back to 1914. Emanuel Goldberg developed a hand-held scanner. When this scanner scans printed documents, it will produce corresponding specific characters; In the 1930s, the traditional template matching algorithm was applied to the recognition of English letters and numbers; So far, OCR technology has made great progress, new OCR algorithms emerge in endlessly, and gradually transition from traditional algorithms to deep learning algorithms. With the emergence of smart phones, OCR technology is widely used in various occasions, such as identification of passport documents, invoices, bank cards, ID cards, business cards and business licenses. At present, OCR technology is a hot research field of pattern recognition, artificial intelligence and computer vision.
ID card information extraction is an important application in the field of OCR. With the development of digital finance, online payment and online financial services are booming. OCR technology can accurately and quickly extract gender, birthplace, date of birth, ID number and other information from user ID card pictures, so as to facilitate user authentication and authentication. It effectively solves the problem of ID card information entry, can process data quickly and efficiently, and greatly improves the efficiency.
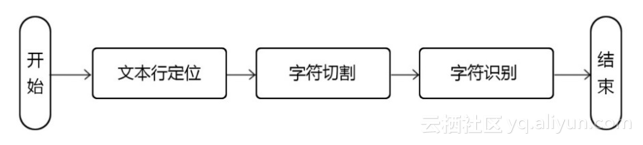
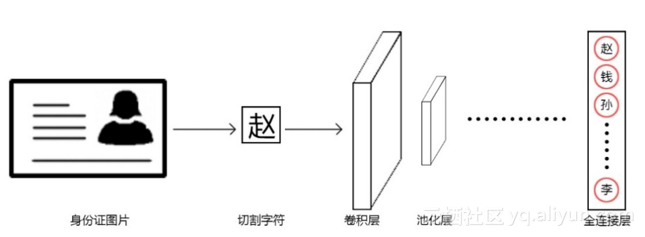
ID card OCR identification process
In the design of this system, OCR recognition of ID card mainly goes through three processes: text line positioning, character cutting and character recognition (see the figure below). Because the background of the ID card picture is relatively single, and the ID card text is black characters, which is quite different from the background, good results can be obtained by using traditional methods in text line positioning and character cutting.
At present, most character recognition algorithms recognize individual characters. According to rough statistics, the number of Chinese characters commonly used in ID cards is about 6500. It is very difficult to use traditional methods to recognize such a large number of pictures and obtain high accuracy. In recent years, deep learning technology has been widely used and made a breakthrough in the field of image recognition.
In the 2012 ImageNet competition, the convolutional neural network (CNN) used by Alex achieved a recognition accuracy of 84%, much higher than the 74% accuracy in the previous two years. Since then, with its excellent performance in the field of image recognition, CNN has developed into one of the most effective methods in image recognition technology.
In the implementation of ID card OCR, the image processing part uses the computer vision library OpenCV for corresponding image processing, and the CNN network for character recognition uses Keras with Tensorflow as the back end for construction and training.
Text line positioning
It is very important for the uneven illumination and uneven texture of the text, as well as how to quickly locate the blurred image. In this system, the location of text lines can be divided into 3 steps: first, locate the ID number row according to the horizontal projection, secondly remove the ID photo area according to the vertical projection, and finally locate the ID card text information row according to the horizontal projection.

By observing the ID card image, we can find that there is a clear interval between the ID number and the personal information and photos above. Therefore, using this interval can easily separate the ID number. First, in order to reduce the interference of background to location, the gray image is normalized and the projection is used to project the image. The principle of the algorithm is to analyze the pixel distribution histogram of the image. The projection peak is the ID number area from the bottom to the first obvious peak area. The specific codes are as follows:
#Import the required libraries. import cv2 import numpy as np #Read the picture from the file path. file_path = '/path to your image' img = cv2.imread(file_path, 1) #Grayscale the image. img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #Then standardize the picture and unify the values of the picture array to a certain range. Parameters of function #The sequence is: input array, output array, minimum value, maximum value and standardization mode. cv2.normalize(img, img, 0, 255, cv2.NORM_MINMAX) #Use the projection algorithm to project the image. horizontal_map = np.mean(img, axis=1)
When the user uses the mobile phone to shoot, the obtained image may have some problems such as rotation angle and uneven illumination. In order to reduce the impact of such problems on positioning and recognition, it is necessary to use CLAHE algorithm for illumination correction, Canny algorithm for edge detection, and Radon transform to obtain the rotation angle, Then perform rotation correction according to the rotation angle obtained in the previous step. The implementation code of Radon transform is as follows:
#Import the required libraries.
import imutils
import numpy as np
#Define Radon transform function, detection range - 90 to 90, interval 0.5:
def radon_angle(img, angle_split=0.5):
angles_list = list(np.arange(-90., 90. + angle_split,
angle_split))
#Create a list of angles_map_max, which stores the maximum integral of the projection in each direction
#Value. We calculate each rotation angle to obtain the projection of the image at each angle,
#Then calculate the maximum value of the integral of the currently specified angle projection value. Angle corresponding to the maximum integral value
#Is the deflection angle.
angles_map_max = []
for current_angle in angles_list:
rotated_img = imutils.rotate_bound(img, current_angle)
current_map = np.sum(rotated_img, axis=1)
angles_map_max.append(np.max(current_map))
adjust_angle = angles_list[np.argmax(angles_map_max)]
return adjust_angle
After the rotation correction, the same image is projected after the ID number is separated. Here, the projection value in the corresponding direction of the image is obtained by calculating the pixel mean in the vertical direction. The first peak area from right to left in the projection peak is the position of the column where the ID card photo is located. The following figure is the schematic diagram of projection cutting:
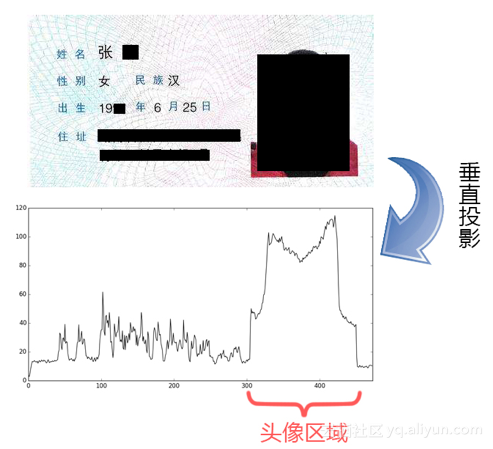
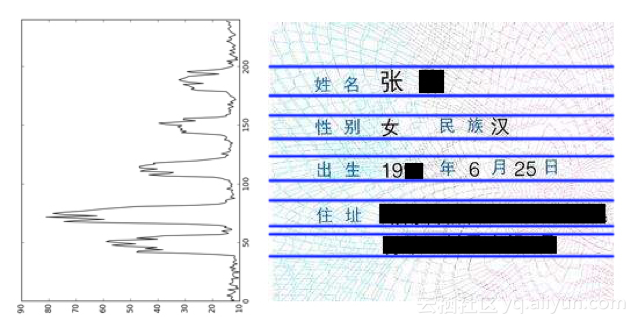
After removing the ID card photo, the remaining part is the required ID text information. Since the specification of the ID card is uniform, we can remove the blank part around the text and further reduce the area of the text image part. Through the observation of the character arrangement on the ID card, it can be seen that there are more black pixels on the lines with text information, and there is an obvious gap between the lines of characters. When the image is horizontally projected, the lines with text information will form obvious peaks, and the gap between lines will form obvious peaks and valleys. This determines the approximate position of the horizontal area where each line of text is located.
Character cutting
After obtaining the text line, it is necessary to cut a single character. After cutting each character, it is convenient for subsequent character recognition. The simplest method of character segmentation is to use continuous equally spaced frames as templates for segmentation. However, for the actual ID card image, the ID card address information often contains numbers and Chinese characters, and the number of characters can not be determined. Therefore, using equally spaced templates to segment single characters can not get ideal results, Therefore, the vertical projection cutting algorithm is adopted for the cutting of a single character in this system, and the local maximum method is used to obtain the best cutting position. However, characters with left-right structure or left middle right structure often appear in Chinese characters, such as "North", "Sichuan" and "small". In projection cutting, these characters are often wrongly cut into two or three characters.
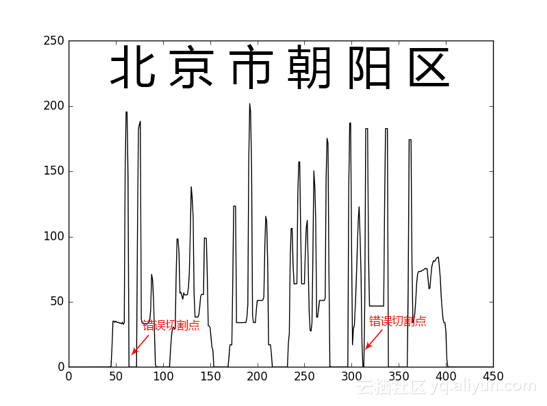
In order to solve this problem, we statistically analyze the width of a single character, take the character width as the judgment standard, and merge the cut characters through the character recognition model, so as to solve the problem of cutting characters from the middle.
character recognition
Character picture preprocessing
After obtaining a single character, in order to obtain the best recognition effect, before using CNN convolutional neural network for training and recognition, we need to carry out certain preprocessing steps for the image, including image enhancement, truncation thresholding, image edge resection and image resolution unification.
- image enhancement
Image enhancement is mainly to highlight the information needed in the image, weaken or remove the unnecessary information, weaken the interference and noise, so as to strengthen the useful information and facilitate the distinction or interpretation. There are many methods of image enhancement. In this paper, histogram equalization technology is mainly used.
Histogram equalization technology is to transform the original image, redistribute the image pixel value, and transform the gray histogram of the original image from a gray interval in the comparison set to a form of uniform distribution in all gray ranges, so as to change the histogram of the original image into a uniformly distributed histogram, so as to enhance the overall contrast of the image.
- Truncation thresholding
The threshold type is as follows:
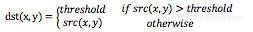
Firstly, a threshold is selected, and the image is processed as follows according to the threshold: the pixels greater than the threshold in the image are set as the threshold, and those less than the threshold remain unchanged.
- Image edge excision
The purpose of this step is to remove the redundant white space up, down, left and right of a single character. The specific method is to cut off the image edge by finding the upper, lower, left and right edge positions of black pixels on each row and column of the image. - Uniform image resolution
Finally, we need to uniformly scale the resolution of all single character images to the size of 32 * 32, which is convenient for input into the neural network.
#Firstly, histogram equalization is performed.
enhance_img = cv2.equalizeHist(img)
#The parameters of the function are: input array, set threshold, maximum pixel value and threshold type.
ret, binary_img = cv2.threshold(enhance_img, 127, 255,
cv2.THRESH_TRUNC)
#Image edge cutting processing.
width_val = np.min(binary_img, axis=0)
height_val = np.min(binary_img, axis=1)
left_point = np.min(indices(width_val, lambda
x:x<cutThreahold))
right_point = np.max(indices(width_val, lambda
x:x<cutThreahold))
up_point = np.max(indices(height_val, lambda
x:x<cutThreahold))
down_point = np.min(indices(height_val, lambda
x:x<cutThreahold))
prepare_img = binary_img[down_point:up_point+1,
left_point:right_point+1]
#Unify the resolution of the image.
img_rows, img_cols = prepare_img.shape[:2]
standard_img = np.ones((32, 32), dtype='uint8') * 127
resize_scale = np.max(prepare_img.shape[:2])
resized_img = cv2.resize(prepare_img, (int(img_cols * 32 /
resize_scale), int(img_rows * 32 /
resize_scale)))
img_rows, img_cols = resized_img.shape[:2]
offset_rows = (32 - img_rows) // 2
offset_cols = (32 - img_cols) // 2
for x in range(img_rows):
for y in range(img_cols):
newimg[x +offset_height, y +offset_width] =
img_resize[x, y]model training
After preprocessing a single character, we get a sample set composed of many single characters. The project uses about 50000 ID card pictures and 750000 single character samples for actual training, covering 6935 kinds of numbers, Chinese characters and English letters, which can cover more than 99.9% of the common characters of ID card. After the above preprocessing, we get a gray image with the size of 32 * 32 pixels and the number of channels of 1 for each single character sample. Therefore, each graph can be regarded as 32 * 32 * 1 = 1024 features as the input of convolutional neural network. The output of the neural network is the probability that the current input sample belongs to each character. If the neural network thinks that the more the input is like a character, the closer the output probability value is to 1. The character with the highest probability is selected through comparison and sorting, so as to achieve the purpose of recognition.
We use Keras to build convolutional neural network and train character recognition model. We will build a convolutional neural network with five layers, which is composed of three convolution layers, a full connection layer and an output layer. Among them, the first convolution layer plays the role of input layer, parameter input_shape represents the data shape of the input neural network. Here is the shape of our preprocessed image array (32, 32, 1).
Depending on the hardware of the computer, our neural network training process may take several minutes to hours. After getting the model, we need to test and observe the accuracy of the model on the validation set. In this project, the recognition accuracy of our character recognition model for a single character has reached 99.5%, the recognition accuracy of ID card name is 99.0%, the recognition accuracy of address is 75.5%, and the recognition accuracy of issuing agency is 82.5%. The figure shows the structure of CNN:
#Import Keras related libraries.
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D,
MaxPooling2D
#Model initialization.
model = Sequential()
#Create the first volume layer.
model.add(Convolution2D(16, 3, 3, border_mode='valid',
input_shape=(32, 32, 1)))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#Create a second volume layer.
model.add(Convolution2D(32, 3, 3, border_mode='valid'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#Create a third volume layer.
model.add(Convolution2D(32, 3, 3, border_mode='valid'))
model.add(Activation('tanh'))
#Create a full connectivity layer.
model.add(Flatten())
model.add(Dense(128, init= 'he_normal'))
model.add(Activation('tanh'))
#Create an output layer and use the Softmax function to output the probability values belonging to each character.
model.add(Dense(output_dim=nb_classes, init= 'he_normal'))
model.add(Activation('softmax'))
#Set the loss function and optimization algorithm in neural network.
model.compile(loss='poisson', optimizer='adam',
metrics=['accuracy'])
#Start training and set the batch size and number of steps.
model.fit(data,label_matrix,batch_size=2500,nb_epoch=50,
shuffle=True, verbose=1)Summary
The task of this chapter is to identify the text information in the ID card photo. In practical application scenarios, the quality of ID card photos collected is often uneven, and there are various problems, such as oblique shooting angle and poor lighting conditions, which greatly interfere with the subsequent neural network training and recognition tasks. Fortunately, through some professional processing methods in the image field, we can reduce the impact of image quality to a certain extent. These methods can help us get more regular single number and Chinese character pictures, so as to form our training samples.
With the training samples, we create a deep convolutional neural network CNN to train the character recognition model. Convolutional neural network is composed of multi-layer network structure, which is especially suitable for tasks such as image recognition, but it needs a very large number of training data sets. For each input, the neural network model will output the probability that it belongs to all character categories. We believe that the character category with the largest probability value is the actual prediction result. Finally, our model achieves a recognition accuracy of 99.5% for a single character.
In addition, an unavoidable problem in the process of training character recognition model is the imbalance of training samples. For example, it is difficult or even impossible to obtain sufficient real training samples for some rare Chinese characters, which will greatly affect the recognition accuracy of such characters. Our solution is to generate more samples by program through some image processing means, such as adding noise to a small number of existing real samples, changing illumination, changing angle, etc., and mixing real samples with artificial samples for training, which has also achieved good results.
This article is excerpted from the Python machine learning practice written by the author and colleagues. The author of this article is curly
Share:
Recommended concerns:
·BAT factory engineers must be Ansible. Haven't you come to learn yet?·"Java developer interview book" is being downloaded for free!·Look at him! Take you from basic to advanced play with the database·Participate in the essay solicitation of my Java strange play diary and win Beats headphones
Copyright notice: the content of this article is spontaneously contributed by Alibaba cloud real name registered users. The copyright belongs to the original author. Alibaba cloud developer community does not own its copyright or bear corresponding legal liabilities. Please check the specific rules< Alicloud developer community user service agreement >And< Alibaba cloud developer community intellectual property protection guidelines >. If you find any content suspected of plagiarism in this community, please fill in Infringement complaint form Report, once verified, the community will immediately delete the suspected infringement content.