preface
Circular dependency in Spring has always been a very important topic in Spring. On the one hand, it is because the source code has done a lot of processing to solve circular dependency. On the other hand, if you ask a higher-level question in Spring during the interview, circular dependency must not escape. If you answer well, then this is your must kill skill. Anyway, it is the interviewer's must kill skill, which is also the reason for taking this title. Of course, the purpose of this article is to let you have one more must kill skill in all subsequent interviews, which is specially used to kill the interviewer!
The core idea of this paper is,
When the interviewer asks:
"Please talk about circular dependency in Spring." When I was young,
How on earth should we answer?
The main points are as follows
- What is circular dependency?
- Under what circumstances can circular dependencies be handled?
- How does Spring solve circular dependency?
At the same time, this paper hopes to correct several wrong statements about circular dependency that often appear in the industry
- The circular dependency can only be solved if it is injected in setter mode (error)
- The purpose of L3 cache is to improve efficiency (error)
OK, the groundwork has been done. Let's start the text
What is circular dependency?
Literally, A depends on B, and B also depends on A, as shown below
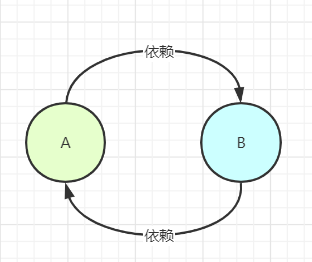 image-20200705175322521
image-20200705175322521
This is what it looks like at the code level
@Component
public class A {
// B is injected into A
@Autowired
private B b;
}
@Component
public class B {
// A is also injected into B
@Autowired
private A a;
}
Of course, this is the most common kind of circular dependency, and there are some special ones
// Rely on yourself
@Component
public class A {
// A is injected into a
@Autowired
private A a;
}
Although the forms are different, they are actually the same problem - > circular dependency
Under what circumstances can circular dependencies be handled?
Before answering this question, it should be clear that Spring has preconditions to solve circular dependency
- The Bean with cyclic dependency must be a singleton
- Dependency injection cannot be all constructor injection (many blogs say that it can only solve the circular dependency of setter methods, which is wrong)
The first point should be well understood. The second point: what does it mean not to be all constructor injection? Let's still talk in code
@Component
public class A {
// @Autowired
// private B b;
public A(B b) {
}
}
@Component
public class B {
// @Autowired
// private A a;
public B(A a){
}
}
In the above example, the method of injecting B into A is through the constructor, and the method of injecting A into B is also through the constructor. At this time, the circular dependency cannot be solved. If there are two such interdependent beans in your project, the following error will be reported during startup:
Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'a': Requested bean is currently in creation: Is there an unresolvable circular reference?
In order to test the relationship between the solution of circular dependency and the injection method, we do the following four tests
| Dependency | Dependency injection mode | Are circular dependencies resolved |
|---|---|---|
| AB interdependence (cyclic dependency) | setter method is used for injection | yes |
| AB interdependence (cyclic dependency) | All are injected by constructor | no |
| AB interdependence (cyclic dependency) | The method of injecting B into A is setter method, and the method of injecting A into B is constructor | yes |
| AB interdependence (cyclic dependency) | The method of injecting A into B is setter method, and the method of injecting B into A is constructor | no |
The specific test code is very simple, so I won't let go. From the above test results, we can see that the circular dependency can not be solved only when the setter method is injected. Even in the scenario of constructor injection, the circular dependency can still be handled normally.
So why? How does Spring deal with circular dependencies? Don't worry, let's keep looking down
How does Spring solve circular dependency?
The solution of circular dependency should be discussed in two cases
- Simple circular dependency (no AOP)
- Combined with the cyclic dependency of AOP
Simple circular dependency (no AOP)
Let's first analyze the simplest example, the demo mentioned above
@Component
public class A {
// B is injected into A
@Autowired
private B b;
}
@Component
public class B {
// A is also injected into B
@Autowired
private A a;
}
We know from the above that the circular dependency can be solved in this case. What is the specific process? We analyze it step by step
First of all, we need to know that Spring creates beans according to natural sorting by default, so in the first step, Spring will create A.
At the same time, we should know that Spring has three steps in the process of creating beans
- Instantiation, corresponding method: createBeanInstance method in AbstractAutowireCapableBeanFactory
- Attribute injection, corresponding method: populateBean method of AbstractAutowireCapableBeanFactory
- Initialization, corresponding method: initializeBean of AbstractAutowireCapableBeanFactory
These methods have been explained in detail in previous articles on source code analysis. If you haven't read my article before, you just need to know
- Instantiation is simply understood as new creating an object
- Property injection: fill in properties for the new object in the instantiation
- Initialize, execute the method in the aware interface, initialize the method, and complete the AOP agent
Based on the above knowledge, we begin to interpret the whole process of circular dependency processing. The whole process should start with the creation of A. as mentioned earlier, the first step is to create a!
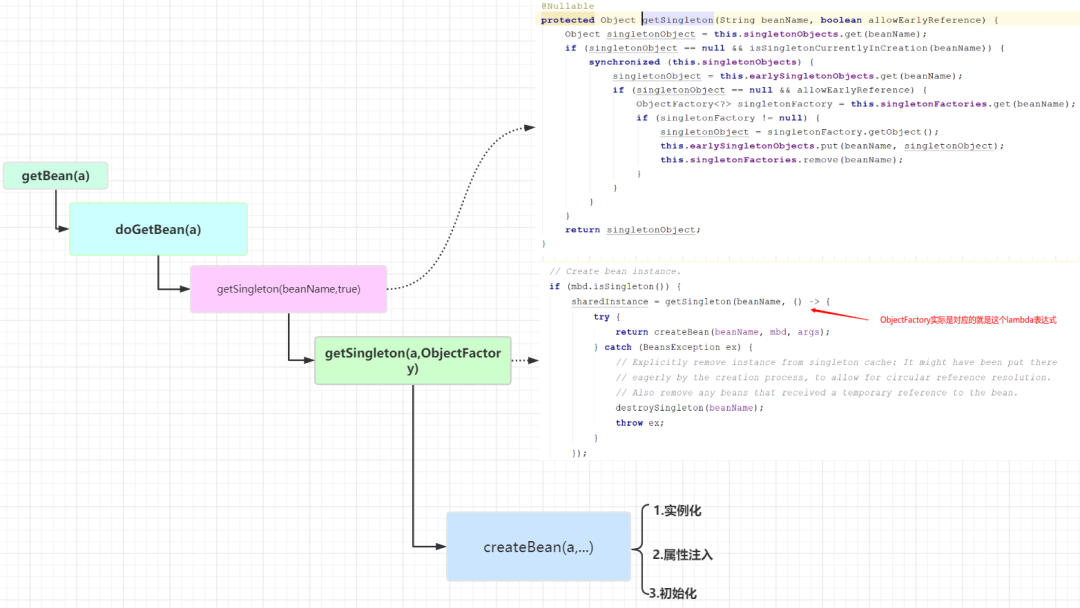
The process of creating A is actually to call the getBean method, which has two meanings
- Create a new Bean
- Get the created object from the cache
We are now analyzing the first layer of meaning, because there is no A in the cache at this time!
Call getSingleton(beanName)
First, call the getSingleton(a) method, which will call getSingleton(beanName, true). I omitted this step in the figure above
public Object getSingleton(String beanName) {
return getSingleton(beanName, true);
}
getSingleton(beanName, true) is actually trying to get beans from the cache. The whole cache is divided into three levels
- singletonObjects, the first level cache, stores all the created singleton beans
- earlySingletonObjects, objects that have been instantiated but have not yet been injected and initialized
- Singleton factories, a singleton factory exposed in advance, stores the objects obtained from this factory in the L2 cache
Because A is created for the first time, it must not be in any cache. Therefore, it will enter another overloaded method getSingleton(beanName, singletonFactory) of getSingleton.
Call getSingleton(beanName, singletonFactory)
This method is used to create beans. Its source code is as follows:
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "Bean name must not be null");
synchronized (this.singletonObjects) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// ....
// Omit exception handling and logging
// ....
// Make a mark before creating a singleton object
// Put beanName into the singletonsCurrentlyInCreation collection
// This indicates that the singleton Bean is being created
// If the same singleton Bean is created multiple times, an exception will be thrown here
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<>();
}
try {
// The lambda passed in from the upstream will be executed here. Call the createBean method to create a Bean and return
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
// ...
// Omit catch exception handling
// ...
finally {
if (recordSuppressedExceptions) {
this.suppressedExceptions = null;
}
// After creation, remove the corresponding beanName from singletonsCurrentlyInCreation
afterSingletonCreation(beanName);
}
if (newSingleton) {
// Add to singletonObjects in L1 cache
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}
In the above code, we mainly catch one point. The Bean returned through the createBean method is finally put into the first level cache, that is, the singleton pool.
So here we can draw a conclusion: the first level cache stores the fully created singleton Bean
Call the addSingletonFactory method
As shown in the figure below:
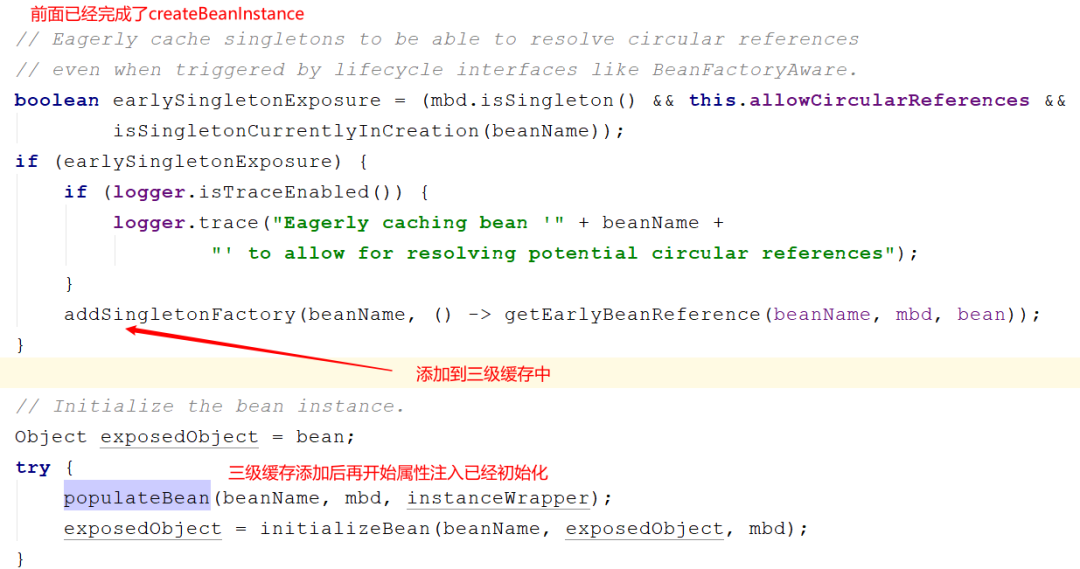
After the instantiation of the Bean and before the attribute injection, Spring wraps the Bean into a factory and adds it to the L3 cache. The corresponding source code is as follows:
// The parameter passed in here is also a lambda expression, () - > getearlybeanreference (beanname, MBD, bean)
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
// Add to L3 cache
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
A factory is just added here. An object can be obtained through the getObject method of the factory (ObjectFactory), and the object is actually created through the getEarlyBeanReference method. Then, when will the getObject method of the factory be called? At this time, it is time to create the process of B.
After a completes the instantiation and adds it to the L3 cache, it is necessary to start property injection for A. It is found that a depends on B during injection. At this time, Spring will go to getBean(b), and then call the setter method to complete property injection.
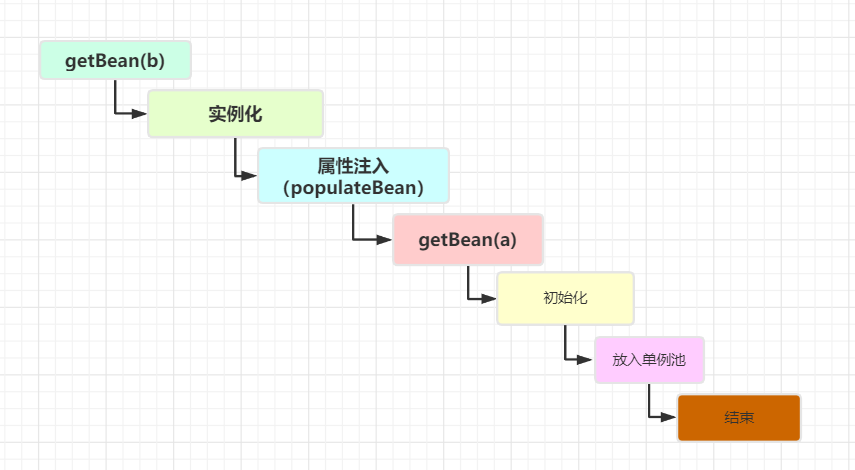
Because B needs to inject A, when creating B, it will call getBean(a). At this time, it will return to the previous process. However, the difference is that the previous getBean is to create A Bean. At this time, the call to getBean is not to create, but to get it from the cache, because A has put it into the singletonFactories of the three-level cache after instantiation, So this is the process of getBean(a)
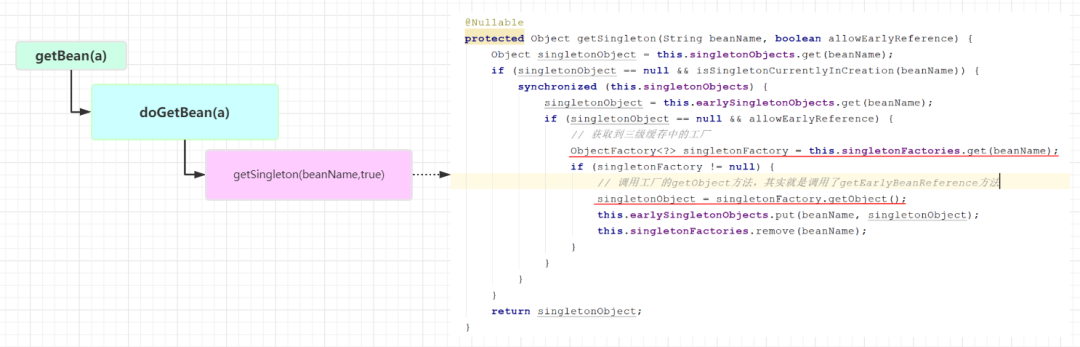
From here, we can see that A injected into B is an object exposed in advance through the getEarlyBeanReference method. It is not A complete Bean. What has getEarlyBeanReference done? Let's take A look at its source code
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
It actually calls the getEarlyBeanReference of the post processor, and there is only one post processor that really implements this method, that is, the AnnotationAwareAspectJAutoProxyCreator imported through the @ EnableAspectJAutoProxy annotation. That is, without considering AOP, the above code is equivalent to:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
return exposedObject;
}
In other words, the factory did nothing and directly returned the objects created in the instantiation stage! So is L3 caching useful without considering AOP? It's reasonable. It's really useless. Don't I have no problem putting this object directly into the L2 cache? If you say it improves efficiency, tell me where it improves efficiency?

So what is the role of L3 caching? Don't worry. Let's finish the whole process first. You can experience the role of level 3 cache when analyzing circular dependency in combination with AOP below!
I don't know if my friends will have any questions here. Will there be no problem if an uninitialized type A object is injected into B in advance?
A: No
At this time, we need to finish the whole process of creating A Bean, as shown in the following figure:
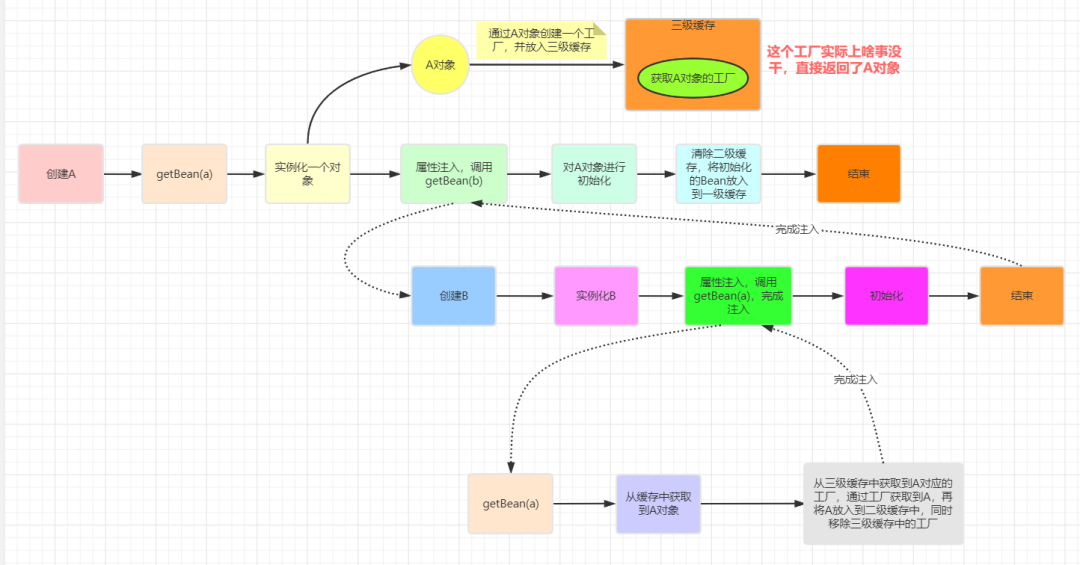
We can see from the above figure that although an uninitialized A object is injected into B in advance when creating B, the reference of the A object injected into B is always used in the process of creating A, and then A will be initialized according to this reference, so there is no problem.
Combined with the cyclic dependency of AOP
As we have said before, in the case of ordinary circular dependency, L3 cache has no effect. The L3 cache is actually related to AOP in Spring. Let's take another look at the code of getEarlyBeanReference:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
If AOP is enabled, call the getEarlyBeanReference method of AnnotationAwareAspectJAutoProxyCreator. The corresponding source code is as follows:
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
// If you need a proxy, return a proxy object. If you don't need a proxy, directly return the currently passed in bean object
return wrapIfNecessary(bean, beanName, cacheKey);
}
Returning to the above example, if we AOP proxy a, then getEarlyBeanReference will return an object after proxy instead of the object created in the instantiation stage, which means that a injected in B will be a proxy object instead of the object created in the instantiation stage of A.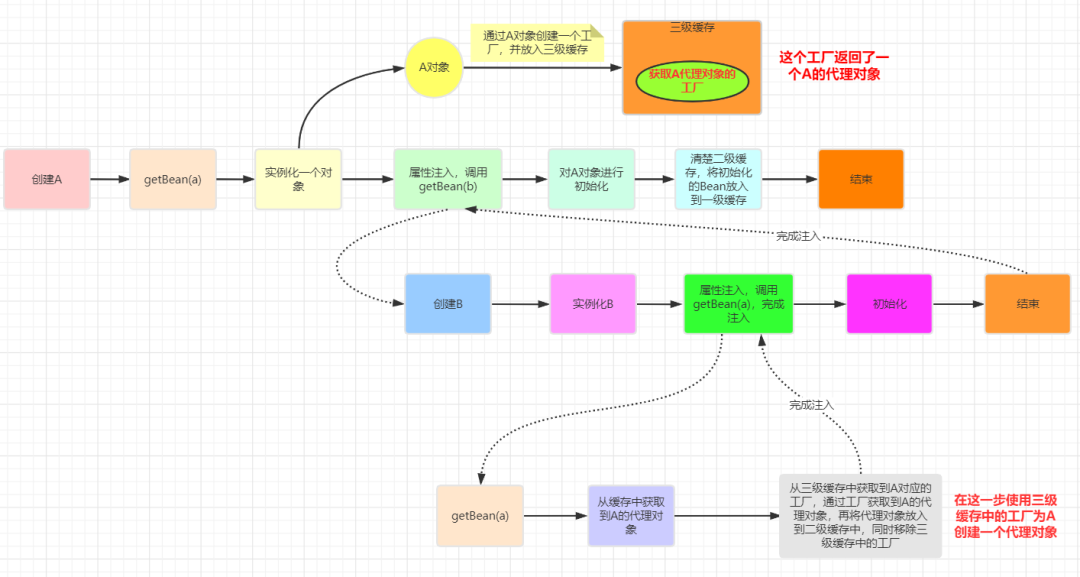
See this picture, you may have the following questions
- Why inject a proxy object when injecting B?
A: when we AOP proxy a, it means that what we want to get from the container is the object after a proxy, not a itself. Therefore, when we inject a as a dependency, we should also inject its proxy object
- It is A object at the time of initialization, so where does Spring put the proxy object into the container?
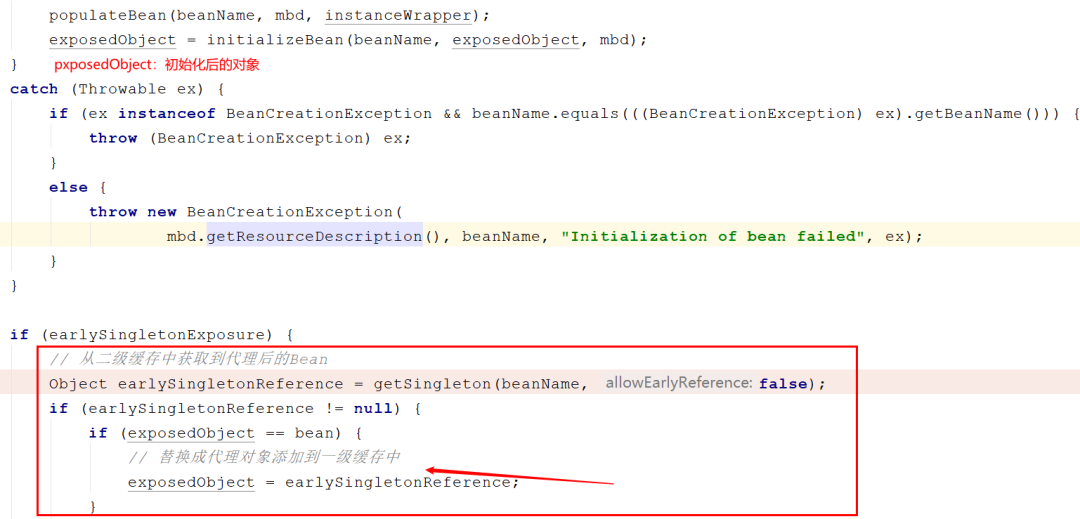
After initialization, Spring calls the getSingleton method again. The parameters passed in this time are different. false can be understood as disabling the L3 cache. As mentioned in the previous figure, when injecting A into B, the factory in the L3 cache has been taken out, and an object obtained from the factory has been put into the L2 cache, Therefore, the time for the getSingleton method here is to obtain the A object after the proxy from the L2 cache. exposedObject == bean can be considered to be valid unless you have to replace the Bean in the normal process in the post processor in the initialization stage, such as adding A post processor:
@Component
public class MyPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (beanName.equals("a")) {
return new A();
}
return bean;
}
}
However, please don't do this coquettish operation, which will only increase your troubles!
- During initialization, the A object itself is initialized, and the proxy objects in the container and injected into B are proxy objects. Won't there be A problem?
A: No, this is because no matter the proxy class generated by cglib proxy or jdk dynamic proxy, it holds a reference to the target class. When calling the method of the proxy object, it will actually call the method of the target object. A completes the initialization, which is equivalent to that of the proxy object itself
- Why should L3 cache use factories instead of direct references? In other words, why do you need this L3 cache? Can't you expose a reference directly through the L2 cache?
A: the purpose of this factory is to delay the proxy of the object generated in the instantiation stage. The proxy object is generated in advance only when the circular dependency really occurs. Otherwise, only a factory will be created and put into the L3 cache, but the object will not be created through this factory
Let's consider A simple case. Take creating A separately as an example. Suppose there is no dependency between AB, but A is proxy. At this time, when A completes instantiation, it will still enter the following code:
// A is singleton, MBD Issingleton() condition satisfied
// allowCircularReferences: this variable represents whether circular dependencies are allowed. It is on by default and the conditions are met
// Issingletoncurrentyincreation: A is being created, which is also satisfied
// So earlySingletonExposure=true
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
// Or will it enter this code
if (earlySingletonExposure) {
// Or will a factory object be exposed in advance through the L3 cache
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
See, even if there is no circular dependency, it will be added to the L3 cache, and it has to be added to the L3 cache, because so far, Spring is not sure whether this Bean has circular dependency with other beans.
Assuming that we directly use L2 cache here, it means that all beans must complete AOP proxy in this step. Is this necessary?
It is not only unnecessary, but also contrary to the design of Spring's life cycle of combining AOP and Bean! The life cycle of Spring combining AOP with Bean is completed through the post processor AnnotationAwareAspectJAutoProxyCreator. In the post-processing postProcessAfterInitialization method, AOP proxy is completed for the initialized Bean. If there is a circular dependency, there is no way. We can only create an agent for the Bean first, but if there is no circular dependency, the beginning of design is to let the Bean complete the agent at the last step of the life cycle, rather than immediately complete the agent after instantiation.
Does L3 caching really improve efficiency?
Now we know the real function of L3 cache, but this answer may not convince you, so let's finally summarize and analyze the wave. Has L3 cache really improved efficiency? The discussion is divided into two points:
- Circular dependency between beans without AOP
As can be seen from the above analysis, the L3 cache is useless in this case! So there won't be any argument to improve efficiency
- The cyclic dependency between AOP beans is carried out
Take A and B on our as an example, where A is represented by AOP. First, we analyze the creation process of A and B when the three-level cache is used
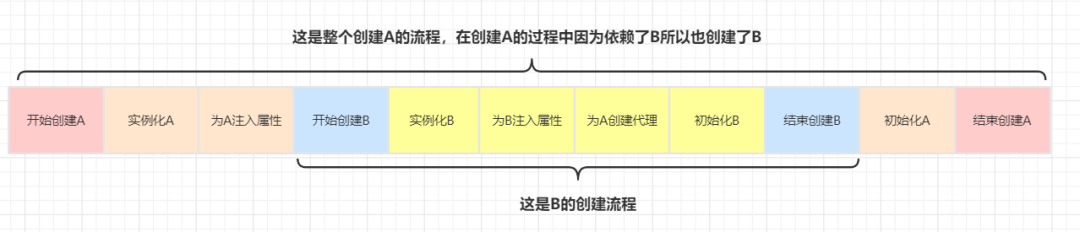
It is assumed that the L3 cache is not used and is directly stored in the L2 cache
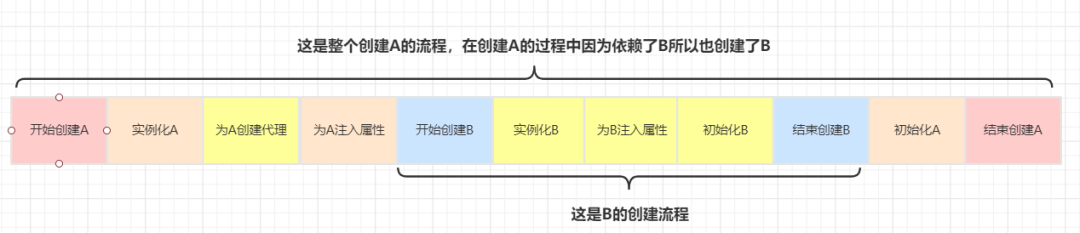
The only difference between the above two processes is that the time to create an agent for A object is different. When the L3 cache is used, the time to create an agent for A is when A needs to be injected into B. if the L3 cache is not used, the agent for A needs to be created immediately after A is instantiated and then put into the L2 cache. For the whole creation process of A and B, the time consumed is the same
To sum up, in either case, the statement that L3 cache improves efficiency is wrong!
summary
Interviewer: "how does Spring solve circular dependency? “
A: Spring solves circular dependency through three-level cache, The first level cache is singleton objects, the second level cache is earlySingletonObjects, and the third level cache is earlySingletonObjects (singletonFactories). When two classes a and B are circularly referenced, after a completes instantiation, it uses the instantiated object to create an object factory and add it to the three-level cache. If a is represented by AOP, the object after a is obtained through this factory. If a is not represented by AOP, the object obtained by this factory is the pair instantiated by A Elephant. When a performs attribute injection, it will create B, and B depends on A. therefore, when creating B, it will call getBean(a) to obtain the required dependencies. At this time, getBean(a) will be obtained from the cache. The first step is to obtain the factory in the L3 cache first; The second step is to call the getObject method of the object factory to obtain the corresponding object. After obtaining the object, inject it into B. Then B will complete its life cycle process, including initialization, post processor, etc. When B is created, B will be re injected into a, and a will complete its whole life cycle. At this point, the circular dependency ends!
Interviewer: "why use L3 cache? Can L2 cache solve circular dependency? “
A: if the L2 cache is used to solve the circular dependency, it means that all beans must complete the AOP proxy after instantiation, which is contrary to the principle of Spring design. At the beginning of design, Spring uses the post processor AnnotationAwareAspectJAutoProxyCreator to complete the AOP proxy at the last step of the Bean life cycle, Instead of AOP proxy immediately after instantiation.
A thinking problem
Why can the cyclic dependency of the third case in the following table be solved, while the fourth case cannot be solved?
Tip: Spring will create beans according to natural order by default when creating beans, so A will create beans before B
| Dependency | Dependency injection mode | Are circular dependencies resolved |
|---|---|---|
| AB interdependence (cyclic dependency) | setter method is used for injection | yes |
| AB interdependence (cyclic dependency) | All are injected by constructor | no |
| AB interdependence (cyclic dependency) | The method of injecting B into A is setter method, and the method of injecting A into B is constructor | yes |
| AB interdependence (cyclic dependency) | The method of injecting A into B is setter method, and the method of injecting B into A is constructor | no |