Hello, I'm Conard Li. Is there a front-end architecture? This may be the confusion of many people, because in actual business development, we rarely design standard code architecture for the front end, and may pay more attention to engineering, directory level and business code implementation.
Today, let's look at a model of front-end architecture. The original author called it "Clean Architecture". The article is very long and detailed. I spent a long time reading it. It's very rewarding. I translated it to you. The article also integrates a lot of my own thinking. I recommend you to read it.
- https://dev.to/bespoyasov/clean-architecture-on-frontend-4311
- The source code of the example in this article: https://github.com/bespoyasov/frontend-clean-architecture/
First, we will briefly introduce what is a Clean architecture, such as the concepts of domain, use case and application layer. Then there is how to apply the Clean architecture to the front end and whether it is worth it.
Next, we will use the principle of clean architecture to design a store application, and implement it from scratch to see if it can run.
This application will use React as its UI framework, just to show that this development method can be used with React. You can also choose any other UI library to implement it.
Some typescripts will be used in the code, just to show how to use types and interfaces to describe entities. In fact, all code can be implemented without TypeScript, but the code will not look so expressive.
Architecture and design
The essence of design is to take things apart in a way that can put them back together... To split things into things that can be recombined, which is design Rich Hickey, design, refactoring and performance
System design is actually the splitting of the system. The most important thing is that we can reassemble them without spending too much time.
I agree with the above view, but I think another main goal of the system architecture is the scalability of the system. The requirements of our applications are constantly changing. We hope that our program can be easily updated and modified to meet the new needs of continuous change. A clean architecture can help us achieve this goal.
What is a clean architecture?
A way to split an application's domain based on the degree of cleanliness of the domain's functions.
Domain is a program model abstracted from the real world. It can reflect the mapping of data in the real world and programs. For example, if we update the name of a product and replace the old name with a new name, it is domain transformation.
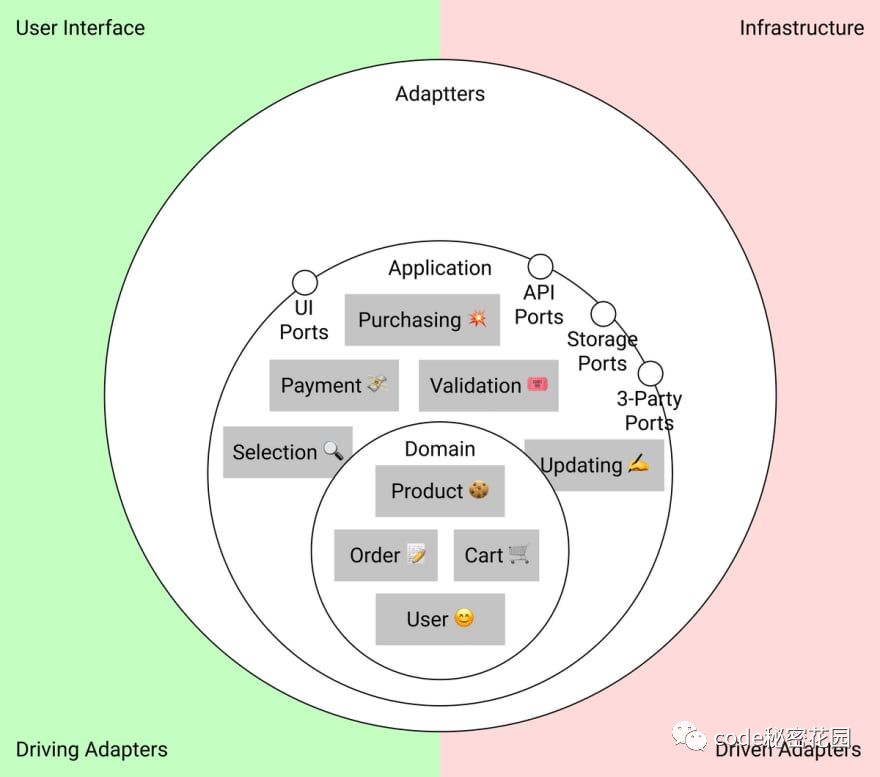
The functions of clean architecture are usually divided into three layers. We can see the following figure:
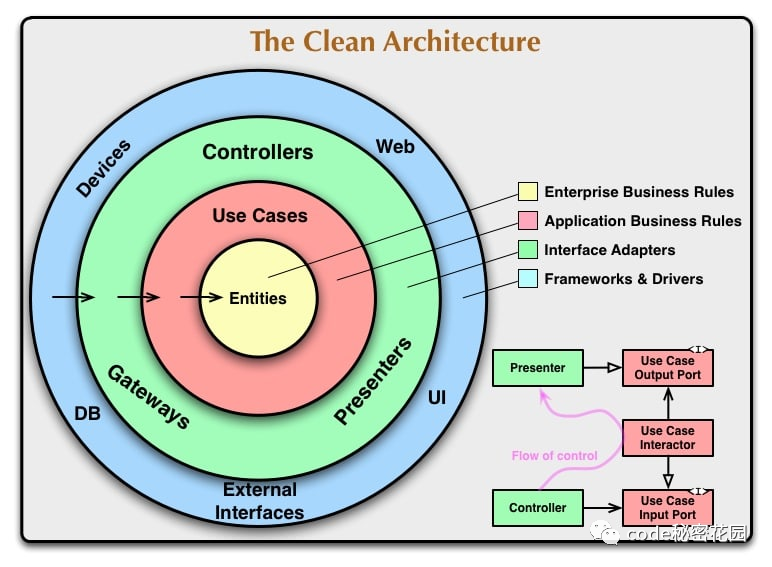
Domain layer
At the center is the domain layer, which describes the entities and data of the application subject area, as well as the code to convert the data. Domain is the core of distinguishing different programs.
You can understand the domain as the part that will not change when we migrate from React to Angular or change some use cases. In the store application, the domain is products, orders, users, shopping carts and methods to update these data.
Data structures and their transformation are isolated from the outside world. External event calls trigger domain transformations, but do not determine how they operate.
For example, the function of adding goods to the shopping cart does not care about the way goods are added to the shopping cart:
- Users can add by clicking the "buy" button
- The user used the coupon to add automatically.
In both cases, an updated shopping cart object is returned.
application layer
Outside the domain is the application layer, which describes use cases.
For example, the "add to shopping cart" scenario is a use case. It describes the specific actions to be performed after clicking a button, such as a "coordinator":
- Send a request to the server;
- Perform domain conversion;
- Update the UI with the data of the response.
In addition, there are ports in the application layer - which describes how the application layer communicates with the outside world. Usually, a port is an interface and a behavior contract.
Ports can also be considered a "buffer" between the real world and applications. The input port will tell us how to accept external input. Similarly, the output port will explain how to prepare for external communication.
Adapter layer
The outermost layer contains the adapter of the external service. We use the adapter to convert the incompatible API of the external service.
Adapters can reduce the coupling between our code and external third-party services. Adapters are generally divided into:
- Driven - send messages to our applications;
- Passive - accept messages sent by our application.
Generally, users interact with the driver adapter most often. For example, handling the click event sent by the UI framework is a driver adapter. Together with the browser API, it converts events into signals that our application can understand.
Driven will interact with our infrastructure. In the front end, most of the infrastructure is the back-end server, but sometimes we may interact directly with other services, such as search engines.
Note that the farther away from the center, the more "service-oriented" the function of the code is, and the farther away from the application field. This is very important when we want to decide which layer a module is.
Dependency rule
The three-tier architecture has a dependency rule: only the outer layer can rely on the inner layer. This means:
- The field must be independent
- The application layer can depend on the domain
- The outermost layer can depend on anything
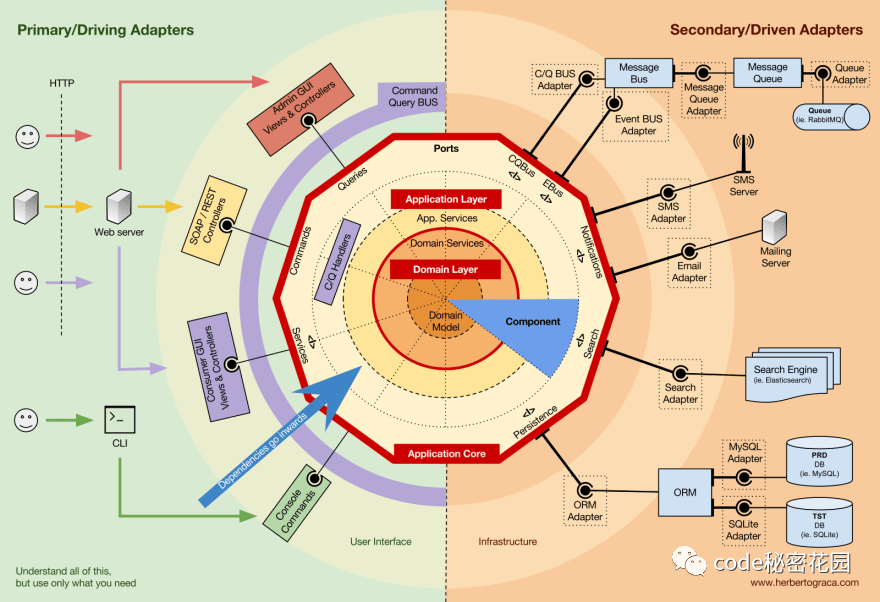
Of course, some special circumstances may violate this rule, but it's best not to abuse it. For example, some third-party libraries may be used in the field, even if such dependencies should not exist. There will be such an example when looking at the code below.
Code that does not control the direction of dependencies can become very complex and difficult to maintain. For example:
- Cyclic dependency, module A depends on B, B depends on C, and C depends on A.
- The testability is poor. Even if a small function is tested, the whole system has to be simulated.
- The coupling is too high, so the interaction between modules will be very fragile.
Advantages of clean architecture
Independent field
The core functions of all applications are split and maintained in one place - domain
The functionality in the domain is independent, which means it is easier to test. The less dependent modules are, the less infrastructure is required for testing.
Independent domains are also easier to test according to business expectations. This helps make it easier for novices to understand. In addition, separate domains also make it easier to eliminate errors from requirements to code implementation.
Independent use case
Application scenarios and use cases are described independently. It determines what third-party services we need. We make external services more suitable for our needs, which gives us more space to choose appropriate third-party services. For example, now that the price of the payment system we call has increased, we can quickly replace it.
The code of the use case is also flat, easy to test and highly extensible. We will see this in the following examples.
Alternative third party services
Adapters make it easier to replace external third-party services. As long as we don't change the interface, it doesn't matter which third-party service implements this interface.
In this way, if others change the code, it will not directly affect us. Adapters also reduce the propagation of application runtime errors.
Cost of achieving a clean architecture
Architecture is first and foremost a tool. Like any other tool, a clean architecture brings additional costs in addition to benefits.
Need more time
The first is time. Both design and implementation need more time, because it is always easier to call the third-party service directly than to write the adapter.
It is difficult for us to think clearly about all the interactions and requirements of the module at the beginning. When we design, we need to pay attention to what may change, so we should consider more scalability.
Sometimes it seems superfluous
Generally speaking, clean architecture is not applicable to all scenarios, and sometimes even harmful. If it is a very small project, you have to design according to the clean architecture, which will greatly increase the threshold for getting started.
It's more difficult to get started
Designing and implementing completely according to the clean architecture will make it more difficult for a novice to get started, because he must first understand how the application works.
Increase in code volume
This is a unique problem of the front end. A clean architecture will increase the volume of the final packaged product. The larger the product, the longer the browser takes to download and interpret, so the amount of code must be controlled and the code should be deleted appropriately:
- Describe the use case more simply;
- Interact directly from the adapter and domain, bypassing the use case;
- Code splitting
How to reduce these costs
You can reduce some implementation time and code by cutting corners and sacrificing the "cleanliness" of the architecture. If I give up some things, I will get greater benefits, and I will do it without hesitation.
Therefore, it is not necessary to follow the design criteria of clean architecture in all aspects, and just follow the core criteria.
Abstract domain
Domain abstraction can help us understand the overall design and how they work. At the same time, it will make it easier for other developers to understand programs, entities and the relationship between them.
Even if we skip other layers directly, the abstract domain is easier to refactor. Because their code is centrally encapsulated in one place, other layers can be easily added when needed.
Compliance with dependency rules
The second rule is that they should not rely on or give up the rule. External services need to adapt to the internal, not the opposite direction.
If you try to call an external API directly, there is a problem. It is best to write an adapter before there is a problem.
Design of store application
Having finished the theory, we can start to practice. Let's actually design a store application.
The store will sell different kinds of biscuits. Users can choose the biscuits they want to buy and pay through the tripartite payment service.
Users can see all cookies on the home page, but they can only buy them after logging in. Click the login button to jump to the login page.
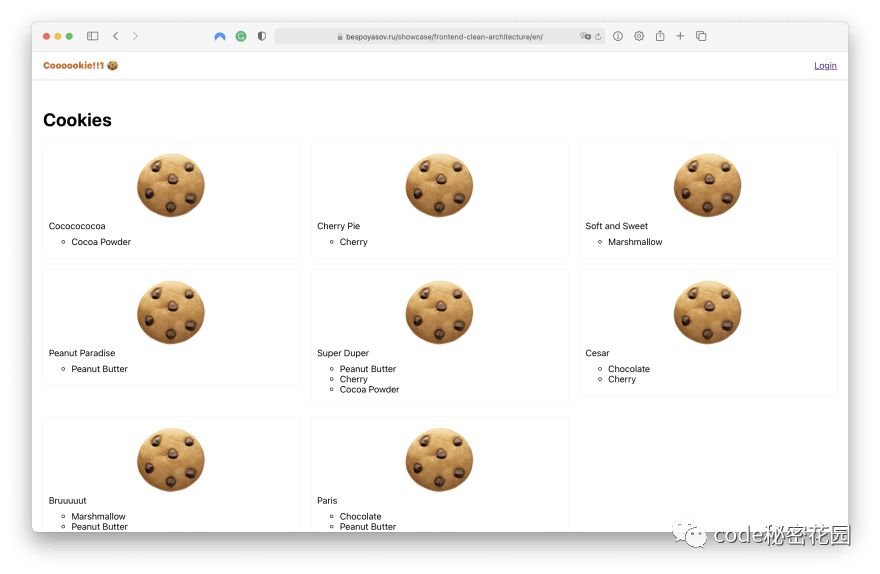
After successful login, users can add cookies to the shopping cart.

After adding cookies to the shopping cart, users can pay. After payment, the shopping cart is emptied and a new order is generated.
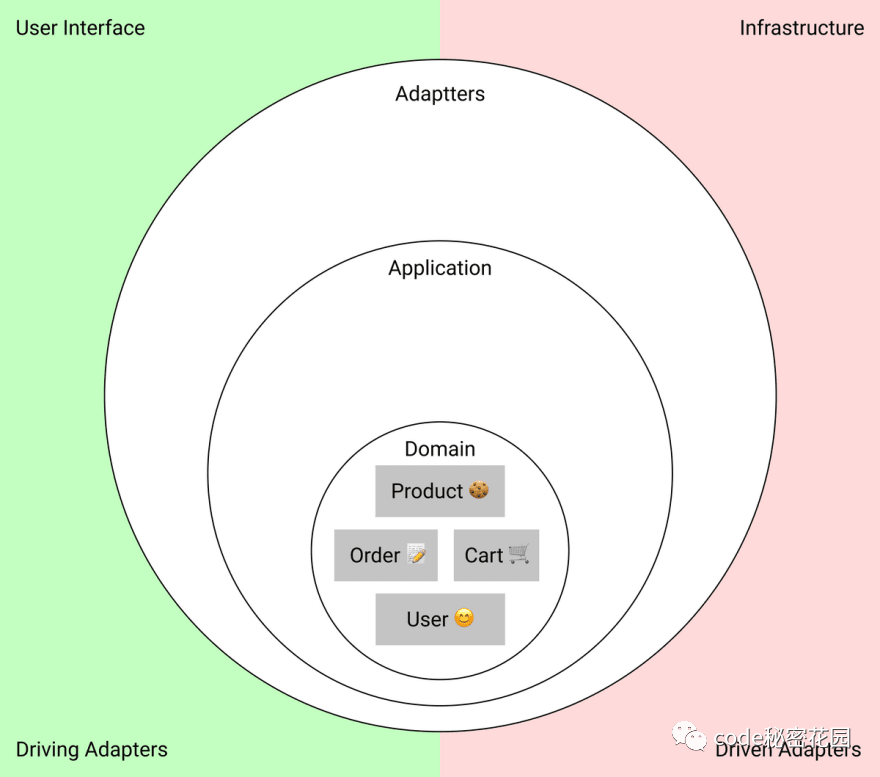
First, let's define entities, use cases, and functions and layer them.
Design field
The most important thing in programming is domain design, which represents the transformation from entity to data.
Areas of the store may include:
- Data type of each entity: user, biscuit, shopping cart and order;
- If you implement it with OOP (object-oriented thinking), you should also design factories and classes to generate entities;
- Function of data conversion.
The transformation method in the domain should only rely on the rules of the domain and not on anything else. For example, the method should be as follows:
- Method of calculating total price
- Method for detecting user taste
- Method for detecting whether goods are in shopping cart
Design application layer
The application layer contains use cases, one of which contains an actor, an action and a result.
In the store app, we can distinguish it as follows:
- A product purchase scenario;
- Payment, call the third-party payment system;
- Interaction with products and orders: update and query;
- Access different pages according to roles.
We usually describe use cases with subject areas. For example, "purchase" includes the following steps:
- Query the goods from the shopping cart and create a new order;
- Create payment order;
- Notify the user when payment fails;
- After successful payment, empty the shopping cart and display the order.
The use case method is the code that describes this scenario.
In addition, there are ports in the application layer - the interface used to communicate with the outside world.
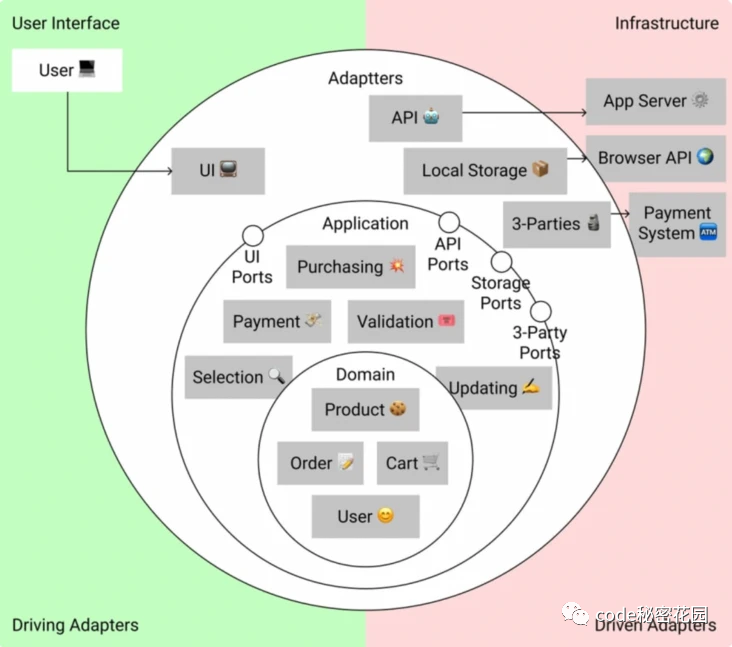
Design adapter layer
At the adapter layer, we declare adapters for external services. The adapter can be compatible with various incompatible external services for our system.
At the front end, the adapter is generally a UI framework and an API request module to the back end. For example, it will be used in our store program:
- User interface;
- API request module;
- Adapter for local storage;
- The API returns to the adapter of the application layer.
Compare MVC architecture
Sometimes it is difficult for us to judge which layer some data belongs to. Here we can make a small comparison with MVC Architecture:
- Model s are generally domain entities
- The Controller is generally related to the transformation or application layer
- View is the driver adapter
Although these concepts are different in detail, they are very similar.
Implementation details - domain
Once we have determined which entities we need, we can begin to define their behavior. Here is the directory structure of our project:
src/ |_domain/ |_user.ts |_product.ts |_order.ts |_cart.ts |_application/ |_addToCart.ts |_authenticate.ts |_orderProducts.ts |_ports.ts |_services/ |_authAdapter.ts |_notificationAdapter.ts |_paymentAdapter.ts |_storageAdapter.ts |_api.ts |_store.tsx |_lib/ |_ui/
Domains are defined in the domain directory, application layers are defined in the application directory, and adapters are defined in the service directory. Finally, we will discuss whether there are other alternatives to the directory structure.
Create domain entity
We have four entities in the field:
- product
- user
- order
- Cart (shopping cart)
The most important one is user. In the reply, we will save the user information, so we design a user type separately in the field. The user type includes the following data:
// domain/user.ts
export type UserName = string;
export type User = {
id: UniqueId;
name: UserName;
email: Email;
preferences: Ingredient[];
allergies: Ingredient[];
};
Users can put biscuits into the shopping cart, and we also add types to the shopping cart and biscuits.
// domain/product.ts
export type ProductTitle = string;
export type Product = {
id: UniqueId;
title: ProductTitle;
price: PriceCents;
toppings: Ingredient[];
};
// domain/cart.ts
import { Product } from "./product";
export type Cart = {
products: Product[];
};
After successful payment, a new order will be created, and we will add another order entity type.
// domain/order.ts — ConardLi
export type OrderStatus = "new" | "delivery" | "completed";
export type Order = {
user: UniqueId;
cart: Cart;
created: DateTimeString;
status: OrderStatus;
total: PriceCents;
};
Understand the relationship between entities
The advantage of designing entity types in this way is that we can check whether their diagrams are consistent with the actual situation:
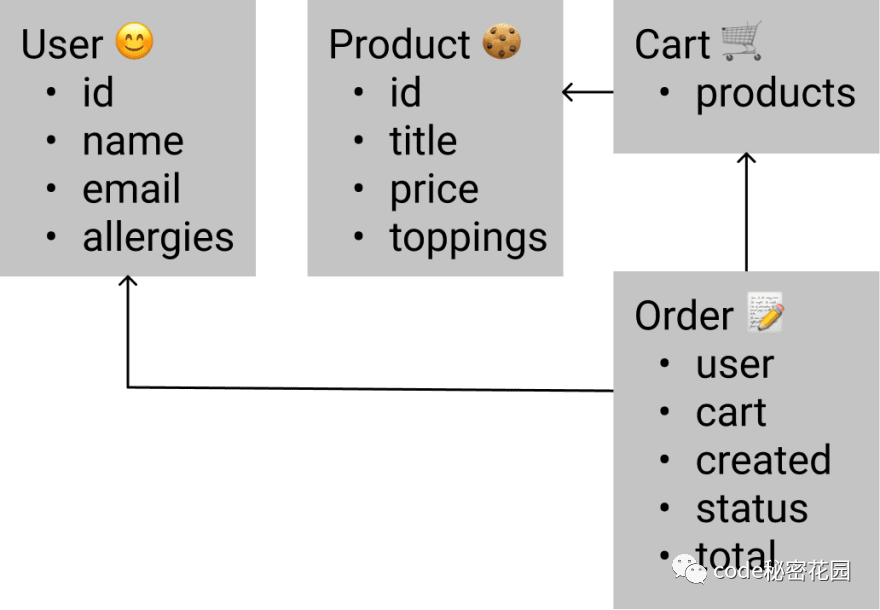
We can check the following points:
- Is the participant a user
- Is there enough information in the order
- Do some entities need to be extended
- Is there enough scalability in the future
In addition, at this stage, types can help identify compatibility between entities and errors in call direction.
If everything meets our expectations, we can start the transformation of the design field.
Create data conversion
All kinds of things will happen to these types of data we just designed. We can add items to the shopping cart, empty the shopping cart, update items and user names, etc. Let's create corresponding functions for these data transformations:
For example, to determine whether a user likes or dislikes a taste, we can create two functions:
// domain/user.ts
export function hasAllergy(user: User, ingredient: Ingredient): boolean {
return user.allergies.includes(ingredient);
}
export function hasPreference(user: User, ingredient: Ingredient): boolean {
return user.preferences.includes(ingredient);
}
Add an item to the cart and check if the item is in the cart:
// domain/cart.ts — ConardLi
export function addProduct(cart: Cart, product: Product): Cart {
return { ...cart, products: [...cart.products, product] };
}
export function contains(cart: Cart, product: Product): boolean {
return cart.products.some(({ id }) => id === product.id);
}
Here is the total price calculation (if necessary, we can design more functions, such as discount, coupon and other scenarios):
// domain/product.ts
export function totalPrice(products: Product[]): PriceCents {
return products.reduce((total, { price }) => total + price, 0);
}
Create a new order and associate it with the corresponding user and his shopping cart.
// domain/order.ts
export function createOrder(user: User, cart: Cart): Order {
return {
user: user.id,
cart,
created: new Date().toISOString(),
status: "new",
total: totalPrice(products),
};
}
Detailed design - shared kernel
You may have noticed some of the types we use when describing domain types. For example, Email, UniqueId or DateTimeString. These are actually type aliases:
// shared-kernel.d.ts type Email = string; type UniqueId = string; type DateTimeString = string; type PriceCents = number;
I use DateTimeString instead of string to more clearly indicate what this string is used for. The closer these types are to reality, the easier it is to troubleshoot problems.
These types are defined in the shared kernel d. In the TS file. Shared kernel refers to some code and data, and the dependence on them will not increase the coupling between modules.
In practice, the shared kernel can be explained as follows: we use TypeScript and its standard type library, but we don't think of them as a dependency. This is because the modules that use them do not affect each other and can remain decoupled.
Not all code can be regarded as a shared kernel. The main principle is that such code must be compatible with the system everywhere. If one part of the program is written in TypeScript and the other part is written in another language, the shared core can only contain parts that can work in both languages.
In our example, the entire application is written in TypeScript, so the alias of the built-in type can be used as part of the shared kernel. This globally available type does not increase the coupling between modules, and can be used in any part of the program.
Implementation details - application layer
We have completed the design of the domain. Now we can design the application layer.
This layer will include specific use case design. For example, a use case is the complete process of adding goods to the shopping cart and paying.
The example will involve the interaction between applications and external services, and the interaction with external services is a side effect. We all know that it is easier to call or debug methods without side effects, so most domain functions are implemented as pure functions.
In order to combine pure functions without side effects and interactions with side effects, we can use the application layer as a non pure context with side effects.
Non context only data conversion
A non pure context and pure data transformation with side effects is such a code organization:
- First, perform a side effect to obtain some data;
- Then execute pure functions to process the data;
- Finally, perform a side effect to store or pass the result.
For example, the use case of "putting goods into shopping cart":
- First, get the status of the shopping cart from the database;
- Then the shopping cart update function is invoked to transfer the commodity information to be added.
- Finally, save the updated shopping cart to the database.
This process is like a "sandwich": side effects, pure functions, side effects. All the main logic processing is to call pure functions for data conversion, and all external communication is isolated in an imperative shell.

Design use case
We choose the checkout scenario for use case design, which is more representative because it is asynchronous and interacts with many third-party services.
We can think about what we want to express through the whole use case. There are some biscuits in the user's shopping cart. When the user clicks the buy button:
- To create a new order;
- Payment in the third-party payment system;
- If the payment fails, notify the user;
- If the payment is successful, save the order on the server;
- Store and save the order data locally and display it on the page;
When designing the function, we will take the user and shopping cart as parameters, and then let this method complete the whole process.
type OrderProducts = (user: User, cart: Cart) => Promise<void>;
Of course, ideally, the use case should not receive two separate parameters, but an encapsulated object. In order to simplify the code, let's deal with it first.
Write the interface of application layer
Let's take a closer look at the steps of the use case: order creation itself is a domain function, and we have to call external services for all other operations.
We should keep in mind that external methods should always adapt to our needs. Therefore, in the application layer, we should not only describe the use case itself, but also define the communication mode of calling external services - port.
Think about the services we might use:
- Third party payment services;
- Service for notifying users of events and errors;
- A service that saves data to local storage.

Note that we are now discussing the interface s of these services, not their specific implementations. At this stage, it is important for us to describe the necessary behavior, because this is the behavior we rely on in the application layer when describing the scenario.
How to implement it is not the focus now. We can consider which external services to call at the end, so that the code can ensure low coupling as much as possible.
Also note that we split the interface by function. Everything related to payment is in the same module, and everything related to storage is in another module. This makes it easier to ensure that the functions of different services and third-party services are not mixed up.
Payment system interface
Our store app is just a small Demo, so the payment system will be very simple. It will have a tryPay method, which will accept the amount to be paid, and then return a Boolean value to indicate the result of the payment.
// application/ports.ts — ConardLi
export interface PaymentService {
tryPay(amount: PriceCents): Promise<boolean>;
}
Generally speaking, payment is processed on the server side. But we're just a simple demonstration, so we'll deal with it directly at the front end. Later, we will also call some simple API s instead of communicating directly with the payment system.
Notification service interface
If there are some problems, we must notify the user.
We can notify users in various ways. For example, using the UI, sending email, and even making the user's mobile phone vibrate.
Generally speaking, the notification service should also be abstracted, so we don't need to consider the implementation now.
Send a notification to the user:
// application/ports.ts
export interface NotificationService {
notify(message: string): void;
}
Local storage interface
We will save the new order in the local repository.
This storage can be anything: Redux, MobX, any storage. The repository can be split on different entities, or the data of the whole application can be maintained together. But it doesn't matter now, because these are the implementation details.
My usual practice is to create a separate storage interface for each entity: a separate interface to store user data, a shopping cart and an order:
// application/ports.ts — ConardLi
export interface OrdersStorageService {
orders: Order[];
updateOrders(orders: Order[]): void;
}
Use case method
Let's see if we can build a use case with the existing domain methods and the newly built interface. The script will include the following steps:
- Validation data;
- Create order;
- Payment order;
- Notify the problem;
- Save the results.
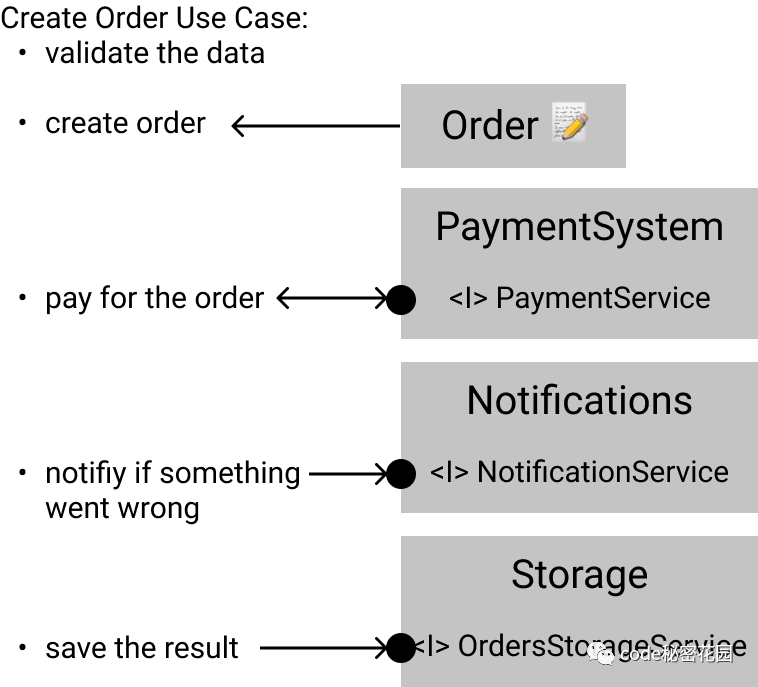
First, we declare the module of the service we want to call. TypeScript will prompt us that we haven't given the implementation of the interface. Don't worry about it first.
// application/orderProducts.ts — ConardLi
const payment: PaymentService = {};
const notifier: NotificationService = {};
const orderStorage: OrdersStorageService = {};
Now we can use these modules as if we were using real services. We can access their fields and call their methods. This is very useful when converting use cases into code.
Now let's create a method called orderProducts to create an order:
// application/orderProducts.ts — ConardLi
//...
async function orderProducts(user: User, cart: Cart) {
const order = createOrder(user, cart);
}
Here, we regard the interface as a convention of behavior. In other words, the module example will really perform the operation we expect:
// application/orderProducts.ts — ConardLi
//...
async function orderProducts(user: User, cart: Cart) {
const order = createOrder(user, cart);
// Try to pay for the order;
// Notify the user if something is wrong:
const paid = await payment.tryPay(order.total);
if (!paid) return notifier.notify("Oops! 🤷");
// Save the result and clear the cart:
const { orders } = orderStorage;
orderStorage.updateOrders([...orders, order]);
cartStorage.emptyCart();
}
Note that use cases do not directly invoke third-party services. It depends on the behavior described in the interface, so as long as the interface remains unchanged, we don't need to care about which module to implement it and how to implement it. Such a module is replaceable.
Implementation details - adapter layer
We have "translated" the use case into TypeScript. Now let's check whether the reality meets our needs.
Usually, it won't, so we need to encapsulate the adapter to call the third-party service.
Add UI and use cases
First, the first adapter is a UI framework. It connects the browser API to our application. In the scenario of order creation, it is the processing method of "checkout" button and click event. The functions of specific use cases will be called here.
// ui/components/Buy.tsx — ConardLi
export function Buy() {
// Get access to the use case in the component:
const { orderProducts } = useOrderProducts();
async function handleSubmit(e: React.FormEvent) {
setLoading(true);
e.preventDefault();
// Call the use case function:
await orderProducts(user!, cart);
setLoading(false);
}
return (
<section>
<h2>Checkout</h2>
<form onSubmit={handleSubmit}>{/* ... */}</form>
</section>
);
}
We can use a Hook to encapsulate the use case. It is suggested to encapsulate all services in it and finally return the use case:
// application/orderProducts.ts — ConardLi
export function useOrderProducts() {
const notifier = useNotifier();
const payment = usePayment();
const orderStorage = useOrdersStorage();
async function orderProducts(user: User, cookies: Cookie[]) {
// ...
}
return { orderProducts };
}
We use hook as a dependency injection. First, we use useNotifier, usePayment and useOrdersStorage to get service instances. Then we use the function useOrderProducts to create a closure so that they can be called in the orderProducts function.
In addition, it needs to be more friendly to test cases and other functions.
Payment service implementation
The use case uses the PaymentService interface. Let's implement it first.
For payment operations, we still use a fake API. Similarly, we still don't need to write all the services now. We can implement them later. The most important thing now is to implement the specified behavior:
// services/paymentAdapter.ts — ConardLi
import { fakeApi } from "./api";
import { PaymentService } from "../application/ports";
export function usePayment(): PaymentService {
return {
tryPay(amount: PriceCents) {
return fakeApi(true);
},
};
}
The function fakeApi will trigger a timeout after 450 milliseconds, simulate the delayed response from the server, and return the parameters we passed in.
// services/api.ts — ConardLi
export function fakeApi<TResponse>(response: TResponse): Promise<TResponse> {
return new Promise((res) => setTimeout(() => res(response), 450));
}
Notification service implementation
We simply use alert to implement notification, because the code is decoupled, and it is not a problem to rewrite the service later.
// services/notificationAdapter.ts — ConardLi
import { NotificationService } from "../application/ports";
export function useNotifier(): NotificationService {
return {
notify: (message: string) => window.alert(message),
};
}
Local storage implementation
We'll pass react Context and Hooks to realize local storage.
We create a new context, then pass it to the provider, and then export it so that other modules can use it through Hooks.
// store.tsx — ConardLi
const StoreContext = React.createContext<any>({});
export const useStore = () => useContext(StoreContext);
export const Provider: React.FC = ({ children }) => {
// ...Other entities...
const [orders, setOrders] = useState([]);
const value = {
// ...
orders,
updateOrders: setOrders,
};
return (
<StoreContext.Provider value={value}>{children}</StoreContext.Provider>
);
};
We can implement a Hook for each function point. In this way, we will not destroy the service interface and storage. At least from the perspective of interface, they are separated.
// services/storageAdapter.ts
export function useOrdersStorage(): OrdersStorageService {
return useStore();
}
In addition, this approach allows us to customize additional optimizations for each store: create selectors, caches, and so on.
Validation data flow chart
Now let's verify how the user communicates with the application.
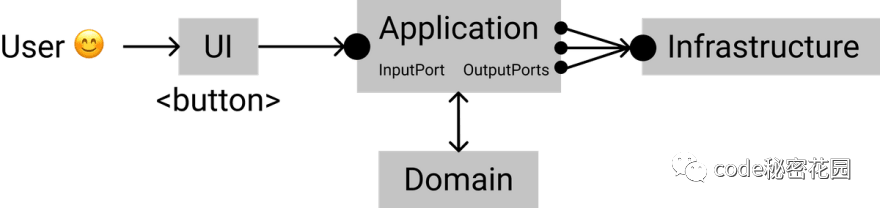
The user interacts with the UI layer, but the UI can only access the service interface through the port. That is, we can replace the UI at any time.
Use cases are handled in the application layer, which can accurately tell us what external services are needed. All the main logic and data are encapsulated in the domain.
All external services are hidden in the infrastructure and comply with our specifications. If we need to change the sending service, we only need to modify the adapter of the sending service.
Such a scheme makes the code easier to replace, easier to test and more scalable to meet the changing needs.
What can be improved
The above introduction can let you start and have a preliminary understanding of the clean architecture, but I want to point out some Jerry built things I did above to make the example simpler.
After reading the following content, you can understand what the clean architecture of "no cutting corners" looks like.
Use objects instead of numbers to represent prices
You may have noticed that I use a number to describe the price, which is not a good habit.
// shared-kernel.d.ts type PriceCents = number;
Numbers can only represent quantity, not currency. The price without currency is meaningless. Ideally, price should be an object with two fields: value and currency.
type Currency = "RUB" | "USD" | "EUR" | "SEK";
type AmountCents = number;
type Price = {
value: AmountCents;
currency: Currency;
};
In this way, the problem of storing money can be solved, and a lot of energy of storing and processing money can be saved. I didn't do this in the example to make it as simple as possible. In the real situation, the structural definition of price will be closer to the above description.
In addition, it is worth mentioning that the unit of price, for example, the smallest unit of US dollar is cents. Displaying prices in this way allows me to avoid thinking about floating-point calculations.
Split code by function, not by layer
Code can be split into folders "by function" instead of "by layer". A function is part of the pie chart below.
This structure is clearer because it allows you to deploy different function points:
Pay attention to cross component use
If we are discussing splitting the system into components, we have to consider the use of cross component code. Let's take another look at the code for creating the order:
import { Product, totalPrice } from "./product";
export function createOrder(user: User, cart: Cart): Order {
return {
user: user.id,
cart,
created: new Date().toISOString(),
status: "new",
total: totalPrice(products),
};
}
This function uses the totalPrice method introduced from another Product module. There is no problem in using it in this way, but if we want to consider splitting the code into independent functions, we can't directly access the code of other modules.
Use TS brand instead of type alias
In writing the shared kernel, I used type aliases. They are easy to implement, but the disadvantage is that TypeScript does not have a mechanism to monitor and enforce them.
This doesn't seem to be a problem: if you use string type instead of DateTimeString, it won't matter. The code will still compile successfully. However, this will make the code fragile and poor readability, because you can use any string, which will increase the possibility of errors.
There is a way for TypeScript to understand that we want a specific type - TS brand( https://github.com/kourge/ts-brand ). It can accurately track the use of types, but it will make the code more complex.
Pay attention to possible dependencies in the domain
The next problem is that we created a date in the domain of the createOrder function:
import { Product, totalPrice } from "./product";
export function createOrder(user: User, cart: Cart): Order {
return {
user: user.id,
cart,
// Вот эта строка:
created: new Date().toISOString(),
status: "new",
total: totalPrice(products),
};
}
new Date(). Functions such as tostring() may be called repeatedly many times. We can encapsulate them in a hleper:
// lib/datetime.ts — ConardLi
export function currentDatetime(): DateTimeString {
return new Date().toISOString();
}
Then call it in the field:
// domain/order.ts
import { currentDatetime } from "../lib/datetime";
import { Product, totalPrice } from "./product";
export function createOrder(user: User, cart: Cart): Order {
return {
user: user.id,
cart,
created: currentDatetime(),
status: "new",
total: totalPrice(products),
};
}
However, the principle of the domain is that you can't rely on anything else, so it's best for the createOrder function to transfer all data from the outside, and the date can be used as the last parameter:
// domain/order.ts — ConardLi
export function createOrder(
user: User,
cart: Cart,
created: DateTimeString
): Order {
return {
user: user.id,
products,
created,
status: "new",
total: totalPrice(products),
};
}
In this way, we will not break the dependency rules. Even if the creation date depends on the third-party library:
function someUserCase() {
// Use the `dateTimeSource` adapter,
// to get the current date in the desired format:
const createdOn = dateTimeSource.currentDatetime();
// Pass already created date to the domain function:
createOrder(user, cart, createdOn);
}
This will keep the domain independent and make testing easier.
In the previous example, I didn't do this for two reasons: it will distract our focus. If it only uses the characteristics of the language itself, I don't think there's any problem relying on your own Helper. They can be considered as helpers, because they can only reduce the degree of code sharing.
Pay attention to the relationship between shopping cart and order
For example, Cart will only include the following items in the shopping Cart:
export type Cart = {
products: Product[];
};
export type Order = {
user: UniqueId;
cart: Cart;
created: DateTimeString;
status: OrderStatus;
total: PriceCents;
};
If the shopping cart has other attributes that are not associated with the order, there may be problems, so it is more reasonable to use ProductList directly:
type ProductList = Product[];
type Cart = {
products: ProductList;
};
type Order = {
user: UniqueId;
products: ProductList;
created: DateTimeString;
status: OrderStatus;
total: PriceCents;
};
Make use cases easier to test
Use cases also have a lot to discuss. For example, the orderProducts function is difficult to test independently of React, which is not good. Ideally, testing should not cost too much.
The root cause of the problem is that we use Hooks to implement the use case:
// application/orderProducts.ts — ConardLi
export function useOrderProducts() {
const notifier = useNotifier();
const payment = usePayment();
const orderStorage = useOrdersStorage();
const cartStorage = useCartStorage();
async function orderProducts(user: User, cart: Cart) {
const order = createOrder(user, cart);
const paid = await payment.tryPay(order.total);
if (!paid) return notifier.notify("Oops! 🤷");
const { orders } = orderStorage;
orderStorage.updateOrders([...orders, order]);
cartStorage.emptyCart();
}
return { orderProducts };
}
In the implementation of the specification, the use case method can be placed outside the Hooks, and the service passes in the use case through parameters or dependency injection:
type Dependencies = {
notifier?: NotificationService;
payment?: PaymentService;
orderStorage?: OrderStorageService;
};
async function orderProducts(
user: User,
cart: Cart,
dependencies: Dependencies = defaultDependencies
) {
const { notifier, payment, orderStorage } = dependencies;
// ...
}
Then Hooks' code can be used as an adapter, and only the examples will remain in the application layer. The orderProdeucts method can be easily tested.
function useOrderProducts() {
const notifier = useNotifier();
const payment = usePayment();
const orderStorage = useOrdersStorage();
return (user: User, cart: Cart) =>
orderProducts(user, cart, {
notifier,
payment,
orderStorage,
});
}
Configure automatic dependency injection
In the application layer, we manually inject dependency into the service:
export function useOrderProducts() {
// Here we use hooks to get the instances of each service,
// which will be used inside the orderProducts use case:
const notifier = useNotifier();
const payment = usePayment();
const orderStorage = useOrdersStorage();
const cartStorage = useCartStorage();
async function orderProducts(user: User, cart: Cart) {
// ...Inside the use case we use those services.
}
return { orderProducts };
}
Of course, there is a better way. Dependency injection can be completed automatically. We have implemented the simplest injection version through the last parameter. You can further configure automatic dependency injection.
In this particular application, I don't think setting up dependency injection makes much sense. It will distract us and make the code too complex. When React and hooks are used, we can use them as "containers" to return the implementation of the specified interface. Yes, although it is still implemented manually, it will not increase the threshold of getting started, and it is faster for novice developers to read.
The situation in the actual project may be more complex
The examples in the article are streamlined and the requirements are relatively simple. Obviously, our actual development is much more complex than this example. So I also want to talk about the common problems that may occur when using clean architecture in actual development.
Branch business logic
The most important problem is that our research on the actual scenario of requirements is not deep enough. Imagine a store with a product, a discounted product, and a cancelled product. How do we accurately describe these entities?
Should there be an extensible "base" entity? How should this entity be extended? Should there be additional fields? Should these entities be mutually exclusive?
There may be too many questions and too many answers. If it's just a hypothesis, we can't consider all the situations.
The specific solution depends on the specific situation. I can only recommend a few of my experience.
Inheritance is not recommended, even if it looks "extensible".
Copy and paste code is not necessarily bad, and sometimes it can even play a greater role. Create two nearly identical entities and observe their behavior in reality. In some cases, their behavior may be very different, and sometimes there may be only one or two fields. Merging two very similar entities is much easier than writing a lot of checks.
If you have to expand something..
Remember covariance, inversion and invariance, so you won't have some more unexpected work.
Choose between different entities and extensibility. It is recommended to use concepts similar to blocks and modifiers in BEM to help you think. If I consider it in the context of BEM, it can help me determine whether I have a "modifier extension" of a separate entity or code.

BEM - block element modifier is a very useful method, which can help you create reusable front-end components and front-end code.
Interdependent use cases
The second problem is related to use cases. The event of one use case triggers another use case.
The only way I know and can help me deal with this problem is to decompose use cases into smaller atomic use cases. They will be easier to put together.
Often, this problem is the result of another big problem in programming. This is the combination of entities.
last
In this article, we introduce the "clean architecture" of the front end.
This is not a gold standard, but a summary of experience accumulated in many projects, specifications and languages.
I find it a very convenient solution to help you decouple your code. Make layers, modules and services as independent as possible. It can not only publish and deploy independently, but also make it easier for you to migrate from one project to another.
What is your ideal front-end architecture?