Please click here View the basic usage of this environment
Please click here for more detailed instructions.
Project Name: clothing generation
(mainly in the field of semantic generation, GAN)
Today, I solemnly launched my clothes generation project. Let's applaud.
Based on the thesis semantically multi modal image synthesis, I have explained this thesis in detail in my This project Described in great detail.
Then the project is reproduced with the above paper, and reasonable modifications are made based on the specific task, and then give yourself a slap.
Finally, I also provide the test code, you can have a look.
Past and present life of the project
Here I'd like to introduce the past and present life of this project. First of all, when I got the task of clothing generation project, I actually had a preliminary idea to empower the design industry and better help designers to have a reasonable control over the final design in the design process, When I visited station B and saw the display effect of SPADE, the feeling of Ma Liang's brush immediately made me feel very friendly. Yes, this is my pursuit. Wang Ba looked at mung beans and looked at each other's eyes. He described me as very friendly at this time, so he said to do it. I directly found SPADE's paper first, read it first, and refer to its pytorch code, Then I wrote a pad directly.
During this process, I also saw the Spade reappearance of FutureSI boss. His personal understanding of gan's development is indeed a very good learning for me, but at this time, I encountered the first problem, data set. I finally chose kaggle, a data set of the competition (introduced when introducing the data set).
The second problem is to find that the training is very slow, and 1 batch takes dozens of seconds. At this time, I am thinking. Because the size of the picture I run is only 256 * 256, it is unlikely that it is the problem of forward propagation of the calculation amount of tensor. At this time, the problem comes to data processing. At this time, I am lazy and make do with my training. It was found that the spade effect was not good, and there may be too few iterations. At this time, I found that the paper semantic multi modal image synthesis, which is the main basis of this project, uses the deep fashion data set and the effect is very good, and then it is also based on spade, so it is actually very simple for me to modify based on spade, so I have the prototype of this project, In this process, I began to try offline resize for the first time, and found that it was much faster. Here is the guidance of GT, which made me firm this idea, and then it was really easy to use. In addition, when offline resize saves semantic segmentation information, I just saved too sparse [256256, class_num], which takes up a lot of memory. However, because a pixel actually has only one label, I finally saved it as [256256,1], which is also thanks to GT for pointing out my little white error.
IN addition, I use spade and IN. Following the suggestions of FutureSI here can improve the effect a little.
First, in two words, show:
It's show time.
From left to right are the model generation effect, ground truth (which can be understood as the model reference answer), and the semantic segmentation and visualization of model input




Detailed description of task requirements
- First of all, let's introduce the task requirements. I have to explain to you what I want to do. What I want to do is the clothing generation task.
- However, one of the differences between the clothes generation task and other tasks is that only one clean clothes is required to be output, which is equivalent to not having a fancy background, that is, the generator is required to focus on the clothes rather than the whole picture generated.
Data introduction and processing process:
- The data I selected is Data of FGVC6 in a game of Kaggle Here, I would like to express my gratitude for the competition provided by the data. This data provides accurate division and marking areas of various parts of clothes. You can directly see the GT and semantic segmentation effect visualization shown above. These are the two parts of data input into the model during training.
- During the test, the model input does not need this GT, but only needs the semantic segmentation information. The specific details of this part will be described later.
- The semantic segmentation Tensor input to the model is in the format of [batch_size,class_num,H,W], specifically [4,46256256], 46 is 46 label s, and then batch during training_ Size is 4.
- In addition, I will consider the mask of clothes when I calculate the loss.
- Because the data format I input is required to be 256 * 256, I need to resize the image and semantic segmentation information so that both H and W are 256. The original image of the original game is too large, and both H and W are thousands. Therefore, this resize operation is actually very time-consuming. At this time, someone will ask, why don't big guys use crop? Here are some reasons:
- Because our application is clothes generation, the best consideration of the model is the whole of clothes. We should give as little local information as possible to prevent peeping into the leopard and make the model have a pattern.
- Because the position of clothes in a real picture is not so large and the position is not fixed, there is a high probability that you can cut a 256 * 256 area on 2500 * 2500. The probability is all black and no information is provided.
- Moreover, such data processing can easily lead to low visibility probability of some label models, such as shoes, because the proportion of shoes is very small.
- At this time, I use online resize. In fact, the training is very slow, and the data preprocessing takes a lot of time. Then I use the skill of offline resize and save it as npy, which means that the training will be full power. However, the npy I saved is [256256,46], which is very sparse and takes up more memory, so I only saved about 1000 groups, so I saved the vector saved by npy as [256256,1], which is much better. Finally, it is about 10000 groups.
import paddle import os import paddle.nn as nn import numpy as np import pandas as pd
## This is the data loader used for online resize. It is found that it is not easy to use, so please keep this code block dusty # from build_dataloader_clothes import Get_paired_dataset # data_loader = Get_paired_dataset(1)#Read data directly from the original dataset
If it's just to test the effect, there's no need to make a data set. I've provided several groups of data for the experiment. Just run the last code block directly
# # Data set storage address during resize: the first step of offline resize is to decompress the original data set. The decompression time is a little long
# if not os.path.isdir("./data/d"):
# os.mkdir("./data/d")
# ! unzip data/data125914/imaterialist-fashion-2019-FGVC6.zip -d ./data/d
# # The second step is to make your own offline resize npy and save the code. Well, it's done offline. It's recommended to simply save 10000 groups of training,
# from build_dataloader_clothes import pair_data
# dataset = pair_data()
# i = 0
# import paddle
# import numpy as np
# from tqdm import tqdm
# for input_img,mask in tqdm(dataset):
# # print(input_img.shape,mask.shape)
# mask = paddle.sum(paddle.arange(1,47).unsqueeze(0).unsqueeze(0) *paddle.ones([256,256,46])*paddle.to_tensor(mask),axis =2,keepdim =True).numpy()
# # print(mask)
# np.save("./all_dataset/imgs/"+str(i)+".npy",input_img)
# np.save("./all_dataset/masks/"+str(i)+".npy",mask)
# i += 1
# # break
#When testing VGG19, output a and b, a is the last layer of feature map, and b is the list, which is equivalent to outputting the middle feature map, including the last layer of feature map. For details, please refer to my public project CV GAN model for common use and easy application from VGG_Model import VGG19 import numpy as np import paddle m = np.random.random([1, 3,256,256]) real_image = paddle.to_tensor(m,dtype="float32") VGG19()(real_image)
Next, something like this! python -u ENCODER.py is unit testing, better for debug ging
# !python -u ENCODER.py
# !python -u SPADEResBlock.py
# !python -u MODEL.py
Next, let's explain some of my folders and their file contents.
- VGG_MODEL.py is VGg to facilitate the calculation of perceived loss, and the VGg folder is to save the parameter files required by VGG19.
- ENCODER.py is the encoder required for model training, and Generator is the model body decoder. Then the model decoder calls SPADEResBlock Py, and then SPADEResBlock calls spade Py's spade
- Normal.py is mainly for spectral normalization.
- GANLOSS.py provides lsgan anti loss structure, but I don't. I use STgan, which is invented by myself. The overall idea is that the discriminator learns the standard answer, and the generator learns from the discriminator.
- Discriminator.py provides multi size discriminator
- all_ The dataset folder has two folders to store npy of mask and img respectively
- Save pictures in KL during training_ Result folder
- The model in model is the encapsulation of encoder and generator, which can be used directly during training
- During training, MODEL forward sets z = paddle Randn ([1,46 * 8,8,8]) is commented out. Canceling the comment during the test means losing the encoder
# This is the dataset constructed using the offline npy file
import paddle
import numpy as np
import os
class Dataset(paddle.io.Dataset):
def __init__(self):
self.root = "/home/aistudio/all_dataset"
self.imgs_ori = os.path.join(self.root, "imgs")
self.masks_ori = os.path.join(self.root, "masks")
self.imgs_path_ori = Dataset.data_maker(self.imgs_ori)
self.masks_path_ori = Dataset.data_maker(self.masks_ori)
self.size = len(self.imgs_path_ori)
@staticmethod
def data_maker(dir):
dir_list = []
assert os.path.isdir(dir), '%s is not a valid directory' % dir
for root, _, fnames in sorted(os.walk(dir)):
for fname in fnames:
if Dataset.is_npy_file(fname):
path = os.path.join(root, fname)
dir_list.append(path)
return sorted(dir_list)
@staticmethod
def is_npy_file(filename):
return any(filename.endswith(extension) for extension in ["npy"])
def __getitem__(self, index):
input_img = np.load(self.imgs_path_ori[index])
masks = np.load(self.masks_path_ori[index])
masks = paddle.nn.functional.one_hot(paddle.to_tensor(masks).squeeze(2),47, name=None)[:,:,1:].numpy()#From [256256,1] to [256256, class_num], the key is one_hot function
return (input_img,masks)
def __len__(self):
return self.size
batch_size = 4
datas = Dataset()
data_loader = paddle.io.DataLoader(datas,batch_size=batch_size,shuffle =True)
for input_img,masks in data_loader:
print(input_img.shape,masks.shape)
break
## It mainly tests the time consumed by online resize for data preprocessing.
# import time
# j = 0
# t = time.clock( )
# # for i in data_loader:
# # print(j, "this round takes {: 2f}s".format(time.clock()-t))
# # t = time.clock()
# # j+=1
# # break
from ENCODER import ConvEncoder from Generator import SPADEGenerator
import paddle import paddle.nn as nn
KLDLoss mainly realizes this: see the loss of VAE for derivation
Encoder E produces a potential code Z, which should follow a Gaussian distribution N (0,1) in the training process. During the test, encoder E is discarded. The coding of random sampling from Gaussian distribution replaces Z. In order to enable this technique, we can re use the [26] loss function in the training process. Specifically, the encoder predicts an average vector and a variance vector through two fully connected layers to represent the distribution of coding. The gap between coded z-Distribution and Gaussian distribution can be minimized by applying kl divergence loss.
class KLDLoss(nn.Layer):
def forward(self, mu, logvar):
return -0.5 * paddle.sum(1 + logvar - mu.pow(2) - logvar.exp())
KLD_Loss = KLDLoss()
l1loss = nn.L1Loss()
# !python -u build_dataloader_clothes.py
from VGG_Model import VGG19 VGG = VGG19()
import paddle
import cv2
from tqdm import tqdm
import numpy as np
import os
from GANloss import GANLoss
from visualdl import LogWriter
from MODEL import Model
import math
log_writer = LogWriter("./log/gnet")
mse_loss = paddle.nn.MSELoss()
l1loss = paddle.nn.L1Loss()
# !python -u Discriminator.py
'''
This code block represents an example of a multiscale discriminator
'''
from Discriminator import build_m_discriminator
import numpy as np
discriminator = build_m_discriminator()
input_nc = 3
x = np.random.uniform(-1, 1, [4, 3, 256, 256]).astype('float32')
x = paddle.to_tensor(x)
print("input tensor x.shape",x.shape)\
y = discriminator(x)
for i in range(len(y)):
for j in range(len(y[i])):
print(i, j, y[i][j].shape)
print('--------------------------------------')
encoder = ConvEncoder() generator = SPADEGenerator() model = Model() #model and discriminator parameter file import # M_path ='model_params/Mmodel_state2.pdparams' # layer_state_dictm = paddle.load(M_path) # model.set_state_dict(layer_state_dictm) # D_path ='discriminator_params/Dmodel_state2.pdparams' # layer_state_dictD = paddle.load(D_path) # discriminator.set_state_dict(layer_state_dictD)
scheduler_G = paddle.optimizer.lr.StepDecay(learning_rate=1e-4, step_size=3, gamma=0.8, verbose=True) scheduler_D = paddle.optimizer.lr.StepDecay(learning_rate=4e-4, step_size=3, gamma=0.8, verbose=True) optimizer_G = paddle.optimizer.Adam(learning_rate=scheduler_G,parameters=model.parameters(),beta1=0.,beta2 =0.9) optimizer_D = paddle.optimizer.Adam(learning_rate=scheduler_D,parameters=discriminator.parameters(),beta1=0.,beta2 =0.9)
EPOCHEES = 100 i = 0
#Four folders for saving design parameter files save_dir_generator = "generator_params" save_dir_encoder = "encoder_params" save_dir_model = "model_params" save_dir_Discriminator = "discriminator_params"
class Train_OPT():
'''
opt format
'''
def __init__(self):
super(Train_OPT, self).__init__()
self.no_vgg_loss = False
self.batchSize = 4
self.lambda_feat = 10.0
self.lambda_vgg = 2
opt = Train_OPT()
#Simply as an indicator, the actual style_loss does not participate in back propagation
def gram(x):
b, c, h, w = x.shape
x_tmp = x.reshape((b, c, (h * w)))
gram = paddle.matmul(x_tmp, x_tmp, transpose_y=True)
return gram / (c * h * w)
def style_loss(style, fake):
mean_loss = paddle.sqrt(paddle.abs(paddle.square(paddle.mean(style))-paddle.square(paddle.mean(fake))))*0.5
std_loss = paddle.sqrt(paddle.abs(paddle.square(paddle.std(style))-paddle.square(paddle.std(fake))))*0.5
gram_loss = nn.L1Loss()(gram(style), gram(fake))
return gram_loss
# return gram_loss
trans_img is to realize the special input of Encoder, [b, 3 * 46256256]. See my project for specific reasons This paper interprets a paper on semantic generation (it is required to control separate semantic generation) Detailed explanation of Enooder in.
def trans_img(input_semantics, real_image):
images = None
seg_range = input_semantics.shape[1]
for i in range(input_semantics.shape[0]):
resize_image = None
for n in range(0, seg_range):
seg_image = real_image[i] * input_semantics[i][n]
seg_image = seg_image.unsqueeze(axis=0)#[1,3,h,w]
# resize_image = torch.cat((resize_image, seg_image), dim=0)
if resize_image is None:
resize_image = seg_image
else:
resize_image = paddle.concat((resize_image, seg_image), axis=1)
if images is None:
images = resize_image
else:
images = paddle.concat((images, resize_image), axis=0)
return images
Here's a brief introduction to the personal improvement of my model:
- The discriminator has three tasks. It needs to distinguish that GT is True, the image generated by the discriminator generator is False, and the discrimination semantic segmentation is visualized as False. This is my improvement. This is to help the discriminator generator generate more complex and real textures.
- In order to focus slightly on the area with clothes, the featloss of the final generator only considers the part with clothes mask.
- Then I put spade NN in py Conv2d (46128) becomes an ordinary convolution without using packet convolution. Because 46 cannot be divided_ num = 4
All G involved in back propagation_ Loss part:
g_loss = g_ganloss + g_vggloss +g_featloss +kldloss
Once again:
During training, MODEL forward sets z = paddle Randn ([1,46 * 8,8,8]) is commented out. Canceling the comment during the test means losing the encoder
# Training code
step =0
for epoch in range(EPOCHEES):
# if(step >1000):
# break
for input_img,mask in tqdm(data_loader):
try:
# if(step >1000):
# break
# print(input_img.shape,mask.shape)
input_img =paddle.transpose(x=input_img.astype("float32")/127.5-1,perm=[0,3,1,2])
mask = paddle.transpose(x=mask,perm=[0,3,1,2]).astype("float32")
seg_mask = (paddle.sum(paddle.arange(1,47).unsqueeze(0).unsqueeze(-1).unsqueeze(-1)*paddle.ones([opt.batchSize,46,256,256])*mask,axis =1,keepdim =True).astype("float32")*3+50)/255-1
seg_mask = paddle.concat([seg_mask,seg_mask,seg_mask],axis =1)
b,c,h,w = input_img.shape
model_input = trans_img(mask,input_img)
img_fake,_,_ = model(model_input,mask)
img_fake = img_fake.detach()
# kld_loss = KLD_Loss(mu,logvar)
# print(img_fake.shape)
fake_and_real_data = paddle.concat((img_fake, input_img,seg_mask), 0).detach()
pred = discriminator(fake_and_real_data)
df_ganloss = 0.
for i in range(len(pred)):
pred_i = pred[i][-1][:opt.batchSize]
# new_loss = -paddle.minimum(-pred_i - 1, paddle.zeros_like(pred_i)).mean() # hingle loss pred_i<-1
new_loss = (300 * 1.2 *GANLoss()(pred_i, False))/4
df_ganloss += new_loss
df_ganloss /= len(pred)
df_ganloss*=0.35
dr_ganloss = 0.
for i in range(len(pred)):
pred_i = pred[i][-1][opt.batchSize:opt.batchSize*2]
# new_loss = -paddle.minimum(pred_i - 1, paddle.zeros_like(pred_i)).mean() # hingle loss pred_i>1
new_loss = (300 * 1.2 *GANLoss()(pred_i, True))/4
dr_ganloss += new_loss
dr_ganloss /= len(pred)
dr_ganloss*=0.35
dseg_ganloss = 0.
for i in range(len(pred)):
pred_i = pred[i][-1][opt.batchSize*2:]
# new_loss = -paddle.minimum(pred_i - 1, paddle.zeros_like(pred_i)).mean() # hingle loss pred_i>1
new_loss = (300 * 1.2 *GANLoss()(pred_i, False))/4
dseg_ganloss += new_loss
dseg_ganloss /= len(pred)
dseg_ganloss*=0.35
d_loss = df_ganloss + dr_ganloss + dseg_ganloss
d_loss.backward()
optimizer_D.step()
optimizer_D.clear_grad()
discriminator.eval()
# encoder.eval()
# set_requires_grad(discriminator,False)
# mu, logvar = encoder(input_img)
# kld_loss = KLD_Loss(mu,logvar)
# z = reparameterize(mu, logvar)
# img_fake = generator(mask,z)
# print(img_fake.shape)
img_fake,mu,logvar = model(model_input,mask)
kldloss = KLD_Loss(mu,logvar)/20
loss_mask = paddle.sum(mask,axis = 1,keepdim = True).astype("bool").astype("float32").detach()
g_vggloss = paddle.to_tensor(0.)
g_styleloss= paddle.to_tensor(0.)
if not opt.no_vgg_loss:
rates = [1.0 / 32, 1.0 / 16, 1.0 / 8, 1.0 / 4, 1.0]
# _, fake_features = VGG( paddle.multiply (img_fake,loss_mask))
# _, real_features = VGG(paddle.multiply (input_img,loss_mask))
_, fake_features = VGG(img_fake)
_, real_features = VGG(input_img)
for i in range(len(fake_features)):
a,b = fake_features[i], real_features[i]
# if i ==len(fake_features)-1:
# a = paddle.multiply( a,F.interpolate(loss_mask,a.shape[-2:]))
# b = paddle.multiply( b,F.interpolate(loss_mask,b.shape[-2:]))
g_vggloss += rates[i] * l1loss(a,b)
# print(a.shape,b.shape)
# g_vggloss += paddle.mean(rates[i] *paddle.square(a-b))
if i ==len(fake_features)-1:
style_a,style_b = fake_features[i], real_features[i]
style_a = paddle.multiply( style_a,F.interpolate(loss_mask,style_a.shape[-2:]))
style_b = paddle.multiply( style_b,F.interpolate(loss_mask,style_b.shape[-2:]))
g_styleloss += rates[i] * style_loss(style_b,style_a)
g_vggloss *= opt.lambda_vgg
g_vggloss /=30
g_styleloss/=50
loss_mask8 = paddle.concat([loss_mask,loss_mask],axis=0)
fake_and_real_data = paddle.concat((img_fake, input_img), 0)
# fake_and_real_data = paddle.multiply (fake_and_real_data,loss_mask8)
pred = discriminator(fake_and_real_data)
# Turn off gradient calculation of true picture tensor
for i in range(len(pred)):
for j in range(len(pred[i])):
pred[i][j][opt.batchSize:].stop_gradient = True
g_ganloss = paddle.to_tensor(0.)
for i in range(len(pred)):
pred_i_f = pred[i][-1][:opt.batchSize]
loss_mask0 = F.interpolate(loss_mask,pred_i_f.shape[-2:])
# pred_i_f = paddle.multiply(pred_i_f,loss_mask0)
pred_i_r = pred[i][-1][opt.batchSize:].detach()
# pred_i_r = paddle.multiply(pred_i_r,loss_mask0)
_,c,h,w = pred_i_f.shape
# new_loss = -1*pred_i_f.mean() # hinge loss
new_loss = paddle.sum(paddle.square(pred_i_r -pred_i_f))/math.sqrt(c*h*w)
g_ganloss += new_loss
g_ganloss /= len(pred)
# g_ganloss*=20
g_featloss = paddle.to_tensor(0.)
for i in range(len(pred)):
for j in range(len(pred[i]) - 1): # Remove the middle layer feature map of the last layer
pred_i_f = pred[i][j][:opt.batchSize]
loss_mask0 = F.interpolate(loss_mask,pred_i_f.shape[-2:])
pred_i_f = paddle.multiply(pred_i_f,loss_mask0)
pred_i_r = pred[i][j][opt.batchSize:].detach()
pred_i_r = paddle.multiply(pred_i_r,loss_mask0)
unweighted_loss = (pred_i_r -pred_i_f).abs().mean() # L1 loss
g_featloss += unweighted_loss * opt.lambda_feat / len(pred)
g_featloss*=3
g_loss = g_ganloss + g_vggloss +g_featloss +kldloss
# g_loss = g_vggloss+g_styleloss
g_loss.backward()
optimizer_G.step()
optimizer_G.clear_grad()
# optimizer_E.step()
# optimizer_E.clear_grad()
discriminator.train()
if step%2==0:
log_writer.add_scalar(tag='train/d_real_loss', step=step, value=dr_ganloss.numpy()[0])
log_writer.add_scalar(tag='train/d_fake_loss', step=step, value=df_ganloss.numpy()[0])
dseg_ganloss
log_writer.add_scalar(tag='train/dseg_ganloss', step=step, value=dseg_ganloss.numpy()[0])
log_writer.add_scalar(tag='train/d_all_loss', step=step, value=d_loss.numpy()[0])
log_writer.add_scalar(tag='train/g_ganloss', step=step, value=g_ganloss.numpy()[0])
log_writer.add_scalar(tag='train/g_featloss', step=step, value=g_featloss.numpy()[0])
log_writer.add_scalar(tag='train/g_vggloss', step=step, value=g_vggloss.numpy()[0])
log_writer.add_scalar(tag='train/g_loss', step=step, value=g_loss.numpy()[0])
log_writer.add_scalar(tag='train/g_styleloss', step=step, value=g_styleloss.numpy()[0])
log_writer.add_scalar(tag='train/kldloss', step=step, value=kldloss.numpy()[0])
step+=1
# print(i)
if step%300 == 3:
print(step,"g_ganloss",g_ganloss.numpy()[0],"g_featloss",g_featloss.numpy()[0],"g_vggloss",g_vggloss.numpy()[0],"g_styleloss",g_styleloss.numpy()[0],"kldloss",kldloss.numpy()[0],"g_loss",g_loss.numpy()[0])
print(step,"dreal_loss",dr_ganloss.numpy()[0],"dfake_loss",df_ganloss.numpy()[0],"dseg_ganloss",dseg_ganloss.numpy()[0],"d_all_loss",d_loss.numpy()[0])
# img_fake = paddle.multiply (img_fake,loss_mask)
input_img = paddle.multiply (input_img,loss_mask)
g_output = paddle.concat([img_fake,input_img,seg_mask],axis = 3).detach().numpy() # tensor -> numpy
g_output = g_output.transpose(0, 2, 3, 1)[0] # NCHW -> NHWC
g_output = (g_output+1) *127.5 # Inverse normalization
g_output = g_output.astype(np.uint8)
cv2.imwrite(os.path.join("./kl_result", 'epoch'+str(step).zfill(3)+'.png'),cv2.cvtColor(g_output,cv2.COLOR_RGB2BGR))
# generator.train()
if step%100 == 3:
save_param_path_g = os.path.join(save_dir_generator, 'Gmodel_state'+str(3)+'.pdparams')
paddle.save(model.generator.state_dict(), save_param_path_g)
save_param_path_d = os.path.join(save_dir_Discriminator, 'Dmodel_state'+str(3)+'.pdparams')
paddle.save(discriminator.state_dict(), save_param_path_d)
# save_param_path_e = os.path.join(save_dir_encoder, 'Emodel_state'+str(1)+'.pdparams')
# paddle.save(model.encoder.state_dict(), save_param_path_e)
save_param_path_m = os.path.join(save_dir_model, 'Mmodel_state'+str(3)+'.pdparams')
paddle.save(model.state_dict(), save_param_path_m)
# break
except:
pass
# break
scheduler_G.step()
scheduler_D.step()
loss visualization
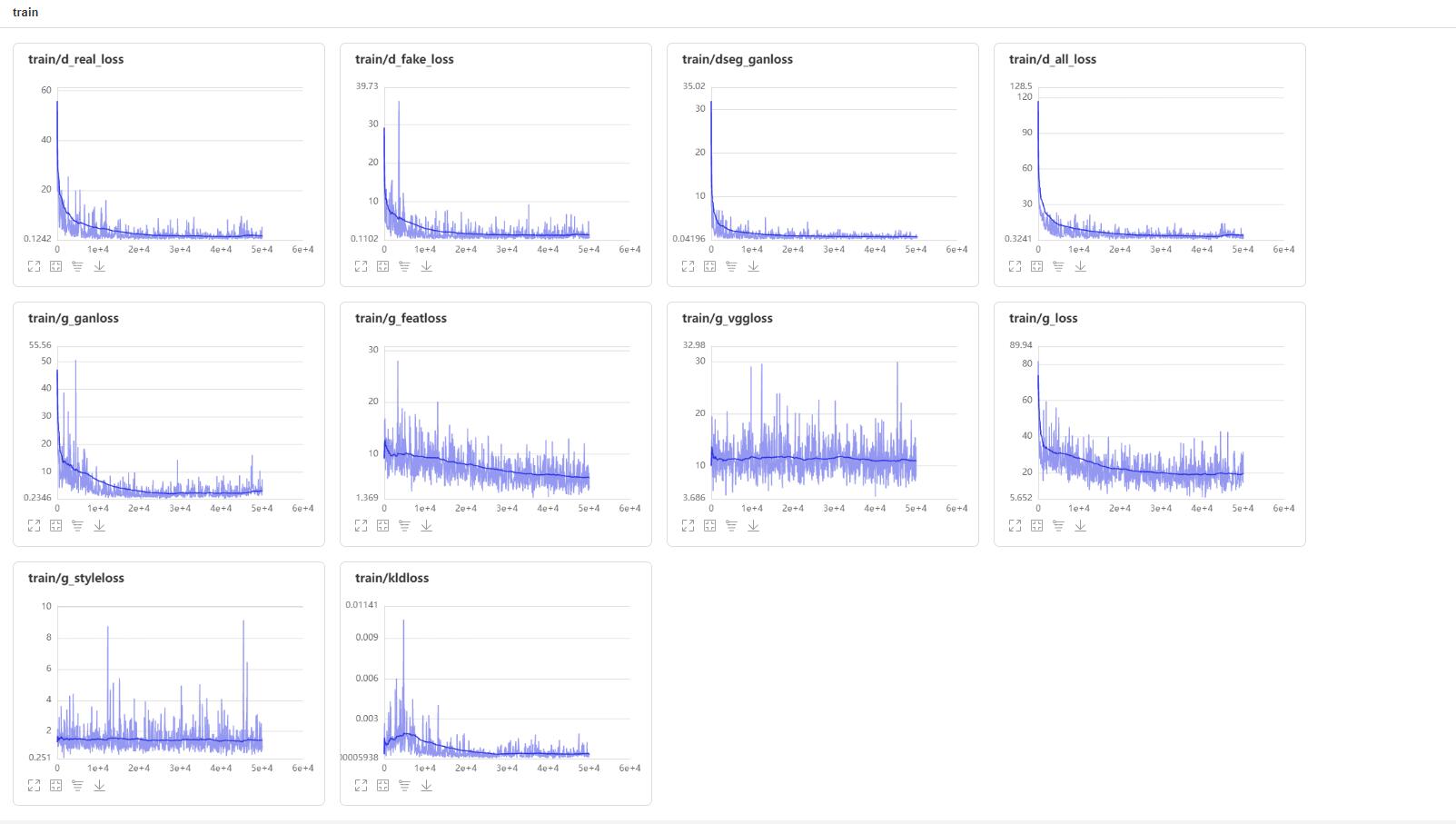
#Save test code effect to test file
from MODEL import Model
import paddle
import numpy as np
import cv2
import os
def trans_img(input_semantics, real_image):
images = None
seg_range = input_semantics.shape[1]
for i in range(input_semantics.shape[0]):
resize_image = None
for n in range(0, seg_range):
seg_image = real_image[i] * input_semantics[i][n]
seg_image = seg_image.unsqueeze(axis=0)#[1,3,h,w]
# resize_image = torch.cat((resize_image, seg_image), dim=0)
if resize_image is None:
resize_image = seg_image
else:
resize_image = paddle.concat((resize_image, seg_image), axis=1)
if images is None:
images = resize_image
else:
images = paddle.concat((images, resize_image), axis=0)
return images
model = Model(1)
M_path ='Mmodel_state3 (1).pdparams'
layer_state_dictm = paddle.load(M_path)
model.set_state_dict(layer_state_dictm)
input_img =paddle.to_tensor( np.load("all_dataset/imgs/1.npy")).astype("float32").unsqueeze(0)
# print(input_img.shape)
mask = np.load("all_dataset/masks/1.npy")
mask = paddle.nn.functional.one_hot(paddle.to_tensor(mask).squeeze(2),47, name=None)[:,:,1:].astype("float32").unsqueeze(0)
input_img =paddle.transpose(x=input_img.astype("float32")/127.5-1,perm=[0,3,1,2])
mask = paddle.transpose(x=mask,perm=[0,3,1,2]).astype("float32")
loss_mask = paddle.sum(mask,axis = 1,keepdim = True).astype("bool").astype("float32").detach()
seg_mask = paddle.sum(paddle.arange(1,47).unsqueeze(0).unsqueeze(-1).unsqueeze(-1)*paddle.ones([1,46,256,256])*mask,axis =1,keepdim =True).astype("float32")*5/255-1
seg_mask = paddle.concat([seg_mask,seg_mask,seg_mask],axis =1)
model_input = trans_img(mask,input_img)
img_fake,_,_ = model(model_input,mask)
print('img_fake',img_fake.shape)
input_img = paddle.multiply (input_img,loss_mask)
print(img_fake.shape,input_img.shape,seg_mask.shape)
g_output = paddle.concat([img_fake,input_img,seg_mask],axis = 3).detach().numpy() # tensor -> numpy
g_output = g_output.transpose(0, 2, 3, 1)[0] # NCHW -> NHWC
g_output = (g_output+1) *127.5 # Inverse normalization
g_output = g_output.astype(np.uint8)
cv2.imwrite(os.path.join("./test", str(1008)+'.png'), cv2.cvtColor(g_output,cv2.COLOR_RGB2BGR))
Parts worthy of improvement:
- Provide more delicate feature control
- Improve the diversity of generated models. Now I'm looking at the paper "Diverse Semantic Image Synthesis via Probability Distribution Modeling"
- It is hoped that the input control of texture can be carried out directly