1, Introduction
1.1 INTRODUCTION
ClickHouse is a column storage database (DBMS) open source by Yandex of Russia in 2016. It is written in C + + language and is mainly used for online analysis and query processing (OLAP). It can generate analysis data reports in real time using SQL queries.
- characteristic
- Distributed columnar storage: faster statistical operation and easier data compression;
- Diversification engine: plug in the table level storage engine. Different storage engines can be set according to different requirements of the table. At present, there are more than 20 engines including merge tree, log, interface and other four categories.
- High throughput and write capability: ClickHouse adopts a structure similar to LSM tree, and compares data in the background regularly after data is written. Through the structure similar to LSM tree, ClickHouse is written in sequence by append during data import. After writing, the data segments cannot be changed. During background compaction, multiple segments are written back to disk after merge sort.
- Data partitioning and thread level parallelism: ClickHouse divides the data into multiple partitions, and each partition is further divided into multiple index granularity, and then processes some of them through multiple CPU cores to realize parallel data processing. Under this design, a single Query can use all CPUs of the whole machine.
- Usage scenario
ClickHouse has the advantage of aggregate query analysis of single wide table of large order of magnitude.
- Most requests are for read access, not single point access, but range query or full table scan;
- The data needs to be updated in large batches (greater than 1000 rows) rather than single lines; or there is no update operation;
- When reading data, a large number of rows will be extracted from the database, but only a small number of columns will be used;
- The table is "wide", that is, the table contains a large number of columns;
- The query frequency is relatively low (usually hundreds or less queries per second per server);
- For simple queries, a delay of about 50 milliseconds is allowed;
- The value of the column is a relatively small value or short string (for example, only 60 bytes per URL);
- High throughput is required when processing a single query (up to billions of rows per second per server);
- No transaction is required;
- Low data consistency requirements;
- Each query will only query one large table, and the rest are small tables;
- The query result is significantly smaller than the data source, that is, the data is filtered or aggregated, and the returned result does not exceed the memory size of a single server.
1.2 single machine deployment
reference resources: https://clickhouse.tech/docs/en/getting-started/install/#from-rpm-packages
A single machine can meet most learning scenarios, and high availability or distributed clusters need to be deployed for production (because it will add operational trouble).
sudo yum install yum-utils sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64 sudo yum install clickhouse-server clickhouse-client sudo systemctl start clickhouse-server.service clickhouse-client
[root@cloud-mn01 ~]# clickhouse-client ClickHouse client version 21.7.5.29 (official build). Connecting to localhost:9000 as user default. Connected to ClickHouse server version 21.7.5 revision 54449. cloud-mn01 :) show databases; SHOW DATABASES Query id: 7efd3129-2076-4eff-8bac-2a314abf7b78 ┌─name────┐ │ default │ │ system │ └─────────┘ 2 rows in set. Elapsed: 0.002 sec. cloud-mn01 :) Bye. [root@cloud-mn01 ~]# clickhouse-client --query "show databases" default system [root@cloud-mn01 ~]#
1.3 high availability cluster
- Copy write process
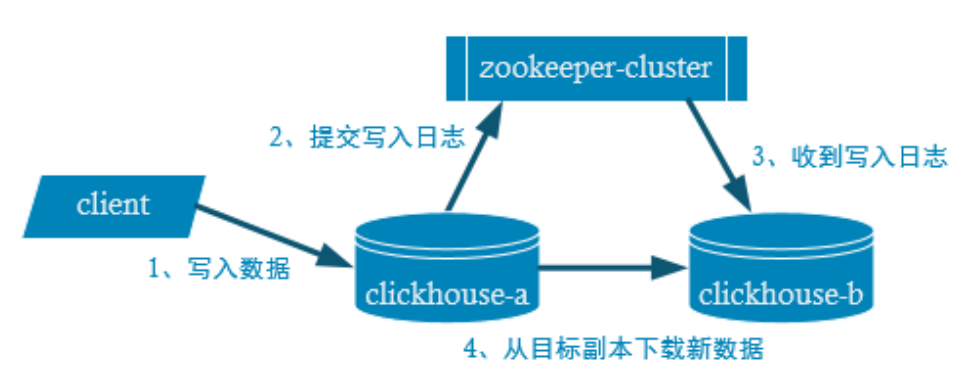
- configuration file
/etc/clickhouse-server/config.xml
<zookeeper>
<node index="1">
<host>hadoop102</host>
<port>2181</port>
</node>
<node index="2">
<host>hadoop103</host>
<port>2181</port>
</node>
<node index="3">
<host>hadoop104</host>
<port>2181</port>
</node>
</zookeeper>
- Build table
Replicas can only synchronize data, not table structures, so we need to manually create tables on each machine.
In ReplicatedMergeTree, the first parameter is the ZK of fragmentation_ Path is generally written in the format of: / clickhouse/table/{shard}/{table_name}. If there is only one partition, write 01. The second parameter is the replica name. The same fragment replica name cannot be the same.
CREATE TABLE t_order_rep2
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` Datetime
)
ENGINE = ReplicatedMergeTree('/clickhouse/table/01/t_order_rep', 'rep_101')
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id)
CREATE TABLE t_order_rep2
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` Datetime
)
ENGINE = ReplicatedMergeTree('/clickhouse/table/01/t_order_rep', 'rep_102')
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id)
1.4 distributed cluster
- Cluster write process

- Cluster read process

- configuration file
/etc/clickhouse-server/config.xml
<remote_servers>
<gmall_cluster> <!-- Cluster name-->
<shard> <!--The first slice of the cluster-->
<internal_replication>true</internal_replication>
<!--The first copy of the tile-->
<replica>
<host>hadoop101</host>
<port>9000</port>
</replica>
<!--The second copy of the tile-->
<replica>
<host>hadoop102</host>
<port>9000</port>
</replica>
</shard>
<shard> <!--The second slice of the cluster-->
<internal_replication>true</internal_replication>
<replica> <!--The first copy of the tile-->
<host>hadoop103</host>
<port>9000</port>
</replica>
<replica> <!--The second copy of the tile-->
<host>hadoop104</host>
<port>9000</port>
</replica>
</shard>
<shard> <!--The third slice of the cluster-->
<internal_replication>true</internal_replication>
<replica> <!--The first copy of the tile-->
<host>hadoop105</host>
<port>9000</port>
</replica>
<replica> <!--The second copy of the tile-->
<host>hadoop106</host>
<port>9000</port>
</replica>
</shard>
</gmall_cluster>
</remote_servers>
<zookeeper>
<node index="1">
<host>hadoop102</host>
<port>2181</port>
</node>
<node index="2">
<host>hadoop103</host>
<port>2181</port>
</node>
<node index="3">
<host>hadoop104</host>
<port>2181</port>
</node>
</zookeeper>
<macros>
<shard>01</shard> <!--Different machines put different pieces-->
<replica>rep_1_1</replica> <!--The number of copies placed on different machines is different-->
</macros>
- Create table statement
- data sheet
Only the data in its slice can be found in this table
CREATE TABLE st_order_mt ON CLUSTER gmall_cluster
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` Datetime
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt', '{replica}')
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id)
- Distributed table
All data can be found in this table
CREATE TABLE st_order_mt_all2 ON CLUSTER gmall_cluster
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` Datetime
)
ENGINE = Distributed(gmall_cluster, default, st_order_mt, hiveHash(sku_id))
1.5 data type
Full data type documentation reference: https://clickhouse.tech/docs/en/sql-reference/data-types/#data_types
- integer
| type | Range |
|---|---|
| Int8 | [-128 : 127] |
| Int16 | [-32768 : 32767] |
| Int32 | [-2147483648 : 2147483647] |
| Int64 | [-9223372036854775808 : 9223372036854775807] |
| UInt8 | [0 : 255] |
| UInt16 | [0 : 65535] |
| UInt32 | [0 : 4294967295] |
| UInt64 | [0 : 18446744073709551615] |
- float
| type | explain |
|---|---|
| Float32 | float |
| Float64 | double |
It is recommended to store data as integers as much as possible, because floating-point calculations may cause rounding errors.
cloud-mn01 :) select 1.0 - 0.9; SELECT 1. - 0.9 Query id: ec6a31cf-42df-418e-bcd5-63b3732ecb44 ┌──────minus(1., 0.9)─┐ │ 0.09999999999999998 │ └─────────────────────┘ 1 rows in set. Elapsed: 0.003 sec. cloud-mn01 :)
- Boolean
There is no separate type to store Boolean values. UInt8 type can be used, and the value is limited to 0 or 1.
- Decimal type
A signed floating-point number that maintains precision during addition, subtraction, and multiplication. For division, the least significant number is discarded (not rounded).
| type | explain |
|---|---|
| Decimal32(s) | It is equivalent to Decimal(9-s,s), and the significant digits are 1 ~ 9 (s indicates the decimal digits) |
| Decimal64(s) | It is equivalent to Decimal(18-s,s), and the significant digits are 1 ~ 18 |
| Decimal128(s) | It is equivalent to Decimal(38-s,s), and the significant digits are 1 ~ 38 |
- character string
- String
Strings can be of any length. It can contain any byte set, including empty bytes.
- FixedString(N)
For a string of fixed length N, n must be a strictly positive natural number. When the server reads a string with a length less than N, the length of N bytes is reached by adding empty bytes at the end of the string. When the server reads a string with a length greater than N, an error message will be returned.
- Enumeration type
Includes Enum8 and Enum16 types. Enum saves the correspondence of 'string' = integer.
# Use the - m option to support line breaks
[root@cloud-mn01 ~]# clickhouse-client -m
ClickHouse client version 21.7.5.29 (official build).
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 21.7.5 revision 54449.
# establish
cloud-mn01 :) CREATE TABLE t_enum
:-] (
:-] x Enum8('hello' = 1, 'world' = 2)
:-] )
:-] ENGINE = TinyLog;
CREATE TABLE t_enum
(
`x` Enum8('hello' = 1, 'world' = 2)
)
ENGINE = TinyLog
Query id: b1bdb268-0cd1-4d1a-ad5a-59fc767bb85d
Ok.
0 rows in set. Elapsed: 0.008 sec.
# insert
cloud-mn01 :) INSERT INTO t_enum VALUES ('hello'), ('world'), ('hello');
INSERT INTO t_enum VALUES
Query id: 16a4ae7c-20a8-4a2c-a4f3-0201823740ca
Ok.
3 rows in set. Elapsed: 0.002 sec.
# View the number corresponding to the enum value
cloud-mn01 :) SELECT CAST(x, 'Int8') FROM t_enum;
SELECT CAST(x, 'Int8')
FROM t_enum
Query id: f9a69904-c5ef-4157-940b-bd171c040063
┌─CAST(x, 'Int8')─┐
│ 1 │
│ 2 │
│ 1 │
└─────────────────┘
3 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :)
- Time type
| type | explain |
|---|---|
| Date | Accept the string of year month day, such as' December 16, 2019 ' |
| Datetime | Accept the string of year month day hour: minute: second, such as' 2019-12-16 20:50:10 ' |
| Datetime64 | Accept year month day hour: minute: second Sub second string, such as' 2019-12-16 20:50:10.66 ' |
- array
Array(T): an array of elements of type T.
# Create array mode 1, using the array function
cloud-mn01 :) SELECT array(1, 2) AS x, toTypeName(x);
SELECT
[1, 2] AS x,
toTypeName(x)
Query id: 30ac6d4c-854e-49b2-bc19-ed1529aa0dde
┌─x─────┬─toTypeName(array(1, 2))─┐
│ [1,2] │ Array(UInt8) │
└───────┴─────────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
# How to create an array 2: use square brackets
cloud-mn01 :) SELECT [1, 2] AS x, toTypeName(x);
SELECT
[1, 2] AS x,
toTypeName(x)
Query id: 9a6701df-9622-46a3-9a91-a0ad968f6f0a
┌─x─────┬─toTypeName([1, 2])─┐
│ [1,2] │ Array(UInt8) │
└───────┴────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :)
- Null value
In order to distinguish between null values, clickhouse needs to store additional masks files, which will consume more space than normal values. Try to avoid the use of null values. You can store meaningless values on the business side, such as - 1 to identify null values.
2, Table engine
For a complete list of table engines, see: https://clickhouse.tech/docs/en/engines/table-engines/#table_engines
- brief introduction
The table engine is a feature of ClickHouse. It can be said that the table engine determines how to store the data of the table.
- Storage mode and location of data, where to write and where to read data.
- Which queries are supported and how.
- Concurrent data access.
- Use of indexes, if any.
- Whether multithreaded requests can be executed.
- Data replication parameters.
2.1 Log
- TinyLog
It is saved on disk in the form of column file, does not support indexing, and has no concurrency control. Generally, small tables that store a small amount of data play a limited role in the production environment. It can be used for practice and test at ordinary times.
cloud-mn01 :) show create table t_tinylog;
SHOW CREATE TABLE t_tinylog
Query id: 9f444ef0-6b2d-4cc7-af79-32e885db9c7a
┌─statement─────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE default.t_tinylog
(
`id` String,
`name` String
)
ENGINE = TinyLog │
└───────────────────────────────────────────────────────────────────────────────────┘
1 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :)
2.2 Integration
- MySQL
The MySQL engine allows you to perform SELECT and INSERT queries on data that is stored on a remote MySQL server.
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
) ENGINE = MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause'])
SETTINGS
[connection_pool_size=16, ]
[connection_max_tries=3, ]
[connection_auto_close=true ]
;
cloud-mn01 :) SHOW CREATE TABLE mysql;
SHOW CREATE TABLE mysql
Query id: 1d8f5ea0-0f46-4ad8-8033-aa96b8cdb2b1
┌─statement───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE default.mysql
(
`name` String,
`age` Int8
)
ENGINE = MySQL('127.0.0.1:3306', 'clickhouse', 'person', 'root', '')
SETTINGS connection_pool_size = 16, connection_max_tries = 3, connection_auto_close = 1 │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :) SELECT * FROM mysql;
SELECT *
FROM mysql
Query id: 724bea04-d126-474b-b814-ab9162f41822
┌─name────┬─age─┐
│ rayslee │ 18 │
└─────────┴─────┘
1 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :) INSERT INTO mysql VALUES('lily', 19);
INSERT INTO mysql VALUES
Query id: 27d72eaa-4c10-461f-ace4-ffab589493a4
Ok.
1 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :)
2.3 Special
- Memory
- In the memory engine, the data is directly saved in the memory in the original uncompressed form, and the data will disappear when the server restarts.
- Read and write operations will not block each other, and indexes are not supported. Very, very high performance under simple query (more than 10G/s).
- Generally, it is not used in many places. In addition to testing, it is used in scenarios where very high performance is required and the amount of data is not too large (the upper limit is about 100 million lines).
2.4 MergeTree
2.4.1 MergeTree
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr
[DELETE|TO DISK 'xxx'|TO VOLUME 'xxx' [, ...] ]
[WHERE conditions]
[GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ] ]
[SETTINGS name=value, ...]
cloud-mn01 :) SHOW CREATE TABLE t_order_mt;
SHOW CREATE TABLE t_order_mt
Query id: e8257846-ed21-40b8-854f-e91ecb6f5a02
┌─statement──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE default.t_order_mt
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` DateTime
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id)
SETTINGS index_granularity = 8192 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
1 rows in set. Elapsed: 0.004 sec.
cloud-mn01 :)
- PARTITION BY
- The main purpose of partitioning is to reduce the scanning range and optimize the query speed;
- After partitioning, ClickHouse will process query statistics involving cross partitions in parallel.
- Data writing and partition merging: data writing in any batch will generate a temporary partition and will not be included in any existing partition. write in
ClickHouse will automatically perform the merge operation at a certain time (about 10-15 minutes later);
cloud-mn01 :) insert into t_order_mt values :-] (101,'sku_001',1000.00,'2020-06-01 12:00:00') , :-] (102,'sku_002',2000.00,'2020-06-01 11:00:00'), :-] (102,'sku_004',2500.00,'2020-06-01 12:00:00'), :-] (102,'sku_002',2000.00,'2020-06-01 13:00:00'), :-] (102,'sku_002',12000.00,'2020-06-01 13:00:00'), :-] (102,'sku_002',600.00,'2020-06-02 12:00:00'); INSERT INTO t_order_mt VALUES Query id: 60cdb8e5-3f91-4a42-9d2c-14d93698b23e Ok. 6 rows in set. Elapsed: 0.002 sec. cloud-mn01 :) select * from t_order_mt; SELECT * FROM t_order_mt Query id: 96fb5d88-18a8-4bf5-89df-3e87cfaa301f ┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 102 │ sku_002 │ 600.00 │ 2020-06-02 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘ ┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 101 │ sku_001 │ 1000.00 │ 2020-06-01 12:00:00 │ │ 102 │ sku_002 │ 2000.00 │ 2020-06-01 11:00:00 │ │ 102 │ sku_002 │ 2000.00 │ 2020-06-01 13:00:00 │ │ 102 │ sku_002 │ 12000.00 │ 2020-06-01 13:00:00 │ │ 102 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘ 6 rows in set. Elapsed: 0.002 sec. cloud-mn01 :) insert into t_order_mt values :-] (101,'sku_001',1000.00,'2020-06-01 12:00:00') , :-] (102,'sku_002',2000.00,'2020-06-01 11:00:00'), :-] (102,'sku_004',2500.00,'2020-06-01 12:00:00'), :-] (102,'sku_002',2000.00,'2020-06-01 13:00:00'), :-] (102,'sku_002',12000.00,'2020-06-01 13:00:00'), :-] (102,'sku_002',600.00,'2020-06-02 12:00:00'); INSERT INTO t_order_mt VALUES Query id: e58fb4bf-2d69-40e6-857e-d91b049a974d Ok. 6 rows in set. Elapsed: 0.003 sec. cloud-mn01 :) select * from t_order_mt; SELECT * FROM t_order_mt Query id: 98b097f3-489c-4cc7-81ff-d1fe77e21a50 ┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 102 │ sku_002 │ 600.00 │ 2020-06-02 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘ ┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 102 │ sku_002 │ 600.00 │ 2020-06-02 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘ ┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 101 │ sku_001 │ 1000.00 │ 2020-06-01 12:00:00 │ │ 102 │ sku_002 │ 2000.00 │ 2020-06-01 11:00:00 │ │ 102 │ sku_002 │ 2000.00 │ 2020-06-01 13:00:00 │ │ 102 │ sku_002 │ 12000.00 │ 2020-06-01 13:00:00 │ │ 102 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘ ┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 101 │ sku_001 │ 1000.00 │ 2020-06-01 12:00:00 │ │ 102 │ sku_002 │ 2000.00 │ 2020-06-01 11:00:00 │ │ 102 │ sku_002 │ 2000.00 │ 2020-06-01 13:00:00 │ │ 102 │ sku_002 │ 12000.00 │ 2020-06-01 13:00:00 │ │ 102 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘ 12 rows in set. Elapsed: 0.004 sec. cloud-mn01 :) optimize table t_order_mt final; OPTIMIZE TABLE t_order_mt FINAL Query id: 6c242f60-e096-4293-b936-9df17763ffb1 Ok. 0 rows in set. Elapsed: 0.005 sec. cloud-mn01 :) select * from t_order_mt; SELECT * FROM t_order_mt Query id: 670d8871-bec7-43d4-9141-1347602ed24a ┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 102 │ sku_002 │ 600.00 │ 2020-06-02 12:00:00 │ │ 102 │ sku_002 │ 600.00 │ 2020-06-02 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘ ┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 101 │ sku_001 │ 1000.00 │ 2020-06-01 12:00:00 │ │ 101 │ sku_001 │ 1000.00 │ 2020-06-01 12:00:00 │ │ 102 │ sku_002 │ 2000.00 │ 2020-06-01 11:00:00 │ │ 102 │ sku_002 │ 2000.00 │ 2020-06-01 13:00:00 │ │ 102 │ sku_002 │ 12000.00 │ 2020-06-01 13:00:00 │ │ 102 │ sku_002 │ 2000.00 │ 2020-06-01 11:00:00 │ │ 102 │ sku_002 │ 2000.00 │ 2020-06-01 13:00:00 │ │ 102 │ sku_002 │ 12000.00 │ 2020-06-01 13:00:00 │ │ 102 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │ │ 102 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘ 12 rows in set. Elapsed: 0.003 sec. cloud-mn01 :)
# Example 20200602_2_4_1 = PartitionId_MinBlockNum_MaxBlockNum_Level # =>PartitionId # Partition value # =>MinBlockNum # Minimum partition block number, self increasing type, starting from 1 and increasing upward. Each new directory partition is incremented by a number. # =>MaxBlockNum # The maximum partition block number. The newly created partition MinBlockNum is equal to the number of MaxBlockNum. # =>Level # The level of consolidation and the number of times to be consolidated. The more merging times, the higher the level value. [root@cloud-mn01 t_order_mt]# pwd /var/lib/clickhouse/data/default/t_order_mt [root@cloud-mn01 t_order_mt]# ll total 4 drwxr-x--- 2 clickhouse clickhouse 203 Aug 1 12:32 20200601_1_1_0 drwxr-x--- 2 clickhouse clickhouse 203 Aug 1 12:34 20200601_1_3_1 drwxr-x--- 2 clickhouse clickhouse 203 Aug 1 12:33 20200601_3_3_0 drwxr-x--- 2 clickhouse clickhouse 203 Aug 1 12:32 20200602_2_2_0 drwxr-x--- 2 clickhouse clickhouse 203 Aug 1 12:34 20200602_2_4_1 drwxr-x--- 2 clickhouse clickhouse 203 Aug 1 12:33 20200602_4_4_0 drwxr-x--- 2 clickhouse clickhouse 6 Aug 1 12:29 detached -rw-r----- 1 clickhouse clickhouse 1 Aug 1 12:29 format_version.txt [root@cloud-mn01 t_order_mt]#
- PRIMARY KEY
The primary key in ClickHouse is different from other databases. It only provides the primary index of data, but it is not the only constraint. This means that data with the same primary key can exist.
- index_granularity
- Index granularity refers to the interval between two adjacent indexes in a sparse index.
- MergeTree in ClickHouse defaults to 8192. Officials do not recommend modifying this value unless there are a large number of duplicate values in this column. For example, tens of thousands of rows in a partition have different data.
- The advantage of sparse index is that it can locate more data with less index data. The cost is that it can only locate the first row of index granularity, and then scan a little.
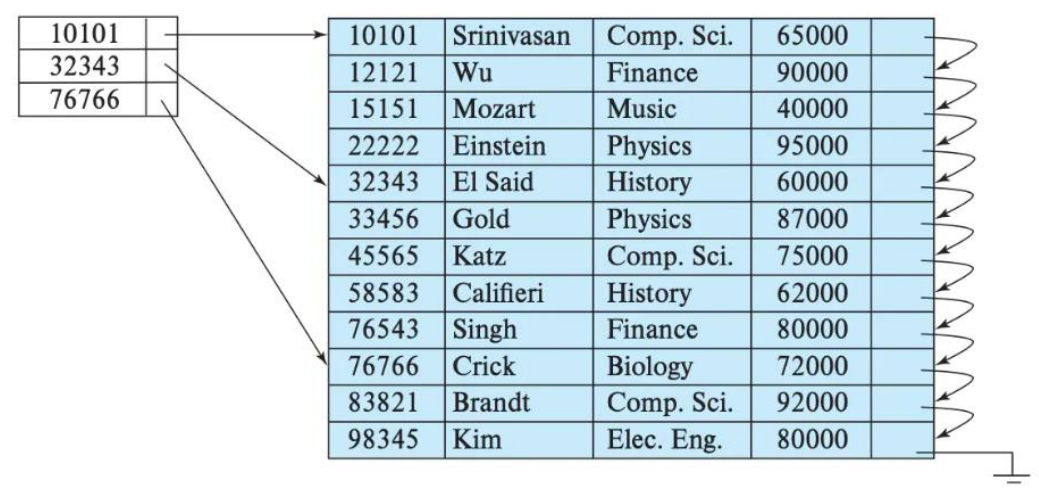
- ORDER BY
- order by sets the order in which the data in the partition is saved in order.
- Order by is the only required item in MergeTree, which is even more important than the primary key, because when the user does not set the primary key, many processes will be processed according to the field of order by.
- The primary key must be a prefix field to the order by field. For example, if the order by field is (id,sku_id), the primary key must be ID or (id,sku_id).
- Secondary index
Secondary indexes can work for queries with non primary key fields.
GRANULARITY N is the granularity of the secondary index to the primary index, that is, n * index_ The granularity row generates an index.
cloud-mn01 :) SHOW CREATE TABLE t_order_mt2;
SHOW CREATE TABLE t_order_mt2
Query id: d23601cf-3f9a-44f6-bde1-51735d7c31a4
┌─statement──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE default.t_order_mt2
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` DateTime,
INDEX a total_amount TYPE minmax GRANULARITY 5
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id)
SETTINGS index_granularity = 8192 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :)
- TTL
TTL is Time To Live. MergeTree provides the function of managing the life cycle of data tables or columns.
- Column level
# Specify when creating
CREATE TABLE example_table
(
d DateTime,
a Int TTL d + INTERVAL 1 MONTH,
b Int TTL d + INTERVAL 1 MONTH,
c String
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d;
# Specify after creation
ALTER TABLE example_table
MODIFY COLUMN
c String TTL d + INTERVAL 1 DAY;
- Table level
# Specify when creating
CREATE TABLE example_table
(
d DateTime,
a Int
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d
TTL d + INTERVAL 1 MONTH [DELETE],
d + INTERVAL 1 WEEK TO VOLUME 'aaa',
d + INTERVAL 2 WEEK TO DISK 'bbb';
# Specify after creation
ALTER TABLE example_table
MODIFY TTL d + INTERVAL 1 DAY;
2.4.2 ReplacingMergeTree
- brief introduction
- Replaceingmergetree is a variant of MergeTree. Its storage features fully inherit from MergeTree, but it has an additional partition de duplication function.
- Data De duplication only occurs during the first batch insertion and partition consolidation. The merger will take place in the background at an unknown time, so you can't plan in advance.
- If the table has been partitioned, de duplication will only be performed within the partition, and cross partition de duplication cannot be performed.
- use
create table t_order_rmt( id UInt32, sku_id String, total_amount Decimal(16,2) , create_time Datetime ) engine =ReplacingMergeTree(create_time) partition by toYYYYMMDD(create_time) primary key (id) order by (id, sku_id);
- The parameter filled in by replaceingmergetree() is the version field, and the maximum value of the duplicate data retention version field.
- If you do not fill in the version field, the last one is reserved by default according to the insertion order.
- Use the order by field as the unique key.
2.4.3 SummingMergeTree
SummingMergeTree, engine for partition "pre aggregation"
create table t_order_smt( id UInt32, sku_id String, total_amount Decimal(16,2) , create_time Datetime ) engine =SummingMergeTree(total_amount) partition by toYYYYMMDD(create_time) primary key (id) order by (id,sku_id );
- Take the column specified in SummingMergeTree() as the summary data column
- You can fill in multiple columns, which must be numeric columns. If not, all fields that are non dimension columns and numeric columns are summarized data columns
- The column of order by shall prevail as the dimension column
- The other columns retain the first row in the insertion order
- Data not in a partition will not be aggregated
- Aggregation occurs only when the same batch is inserted (new version) or piecemeal merged
3, SQL operation
- DDL data definition language
- DCL data control language
- DML data manipulation language
- DQL data query language
3.1 DML
- brief introduction
- ClickHouse provides the ability of Delete and Update. This kind of operation is called Mutation query, which can be regarded as a kind of Alter.
- Although modification and deletion can be realized, unlike ordinary OLTP databases, the Mutation statement is a very "heavy" operation and does not support transactions.
- The main reason for "duplicate" is that each modification or deletion will result in abandoning the original partition of the target data and rebuilding a new partition. Therefore, try to make batch changes instead of frequent small data operations.
- Because the operation is "heavy", the Mutation statement is executed in two steps. The part of synchronous execution is actually to add data, add partitions and mark the old partitions with logical invalidation marks. The old data will not be deleted until the partition merge is triggered to free up disk space.
- delete
alter table t_order_smt delete where sku_id ='sku_001';
- to update
alter table t_order_smt update total_amount=toDecimal32(2000.00,2) where id = 102;
3.2 DQL
- Group By
GROUP BY adds with rollup\with cube\with total to calculate subtotals and totals.
cloud-mn01 :) select * from t_order_mt; SELECT * FROM t_order_mt Query id: be6ba693-9ad0-45e9-9b05-9cb0aeba1213 ┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 105 │ sku_003 │ 600.00 │ 2020-06-02 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘ ┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 101 │ sku_001 │ 1000.00 │ 2020-06-01 12:00:00 │ │ 101 │ sku_002 │ 2000.00 │ 2020-06-01 12:00:00 │ │ 103 │ sku_004 │ 2500.00 │ 2020-06-01 12:00:00 │ │ 104 │ sku_002 │ 2000.00 │ 2020-06-01 12:00:00 │ │ 110 │ sku_003 │ 600.00 │ 2020-06-01 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘ ┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐ │ 106 │ sku_001 │ 1000.00 │ 2020-06-04 12:00:00 │ │ 107 │ sku_002 │ 2000.00 │ 2020-06-04 12:00:00 │ │ 108 │ sku_004 │ 2500.00 │ 2020-06-04 12:00:00 │ │ 109 │ sku_002 │ 2000.00 │ 2020-06-04 12:00:00 │ └─────┴─────────┴──────────────┴─────────────────────┘ 10 rows in set. Elapsed: 0.002 sec. cloud-mn01 :)
- with rollup: remove dimensions from right to left for subtotal
cloud-mn01 :) select id , sku_id,sum(total_amount) from t_order_mt group by
:-] id,sku_id with rollup;
SELECT
id,
sku_id,
sum(total_amount)
FROM t_order_mt
GROUP BY
id,
sku_id
WITH ROLLUP
Query id: a43fba98-5bcf-4bf2-96d1-cf2a41b2891d
┌──id─┬─sku_id──┬─sum(total_amount)─┐
│ 110 │ sku_003 │ 600.00 │
│ 109 │ sku_002 │ 2000.00 │
│ 107 │ sku_002 │ 2000.00 │
│ 106 │ sku_001 │ 1000.00 │
│ 104 │ sku_002 │ 2000.00 │
│ 101 │ sku_002 │ 2000.00 │
│ 103 │ sku_004 │ 2500.00 │
│ 108 │ sku_004 │ 2500.00 │
│ 105 │ sku_003 │ 600.00 │
│ 101 │ sku_001 │ 1000.00 │
└─────┴─────────┴───────────────────┘
┌──id─┬─sku_id─┬─sum(total_amount)─┐
│ 110 │ │ 600.00 │
│ 106 │ │ 1000.00 │
│ 105 │ │ 600.00 │
│ 109 │ │ 2000.00 │
│ 107 │ │ 2000.00 │
│ 104 │ │ 2000.00 │
│ 103 │ │ 2500.00 │
│ 108 │ │ 2500.00 │
│ 101 │ │ 3000.00 │
└─────┴────────┴───────────────────┘
┌─id─┬─sku_id─┬─sum(total_amount)─┐
│ 0 │ │ 16200.00 │
└────┴────────┴───────────────────┘
20 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :)
- with cube: remove the dimension from right to left for subtotal, and then remove the dimension from left to right for subtotal
cloud-mn01 :) select id , sku_id,sum(total_amount) from t_order_mt group by
:-] id,sku_id with cube;
SELECT
id,
sku_id,
sum(total_amount)
FROM t_order_mt
GROUP BY
id,
sku_id
WITH CUBE
Query id: df7b72c9-5e06-4ddf-a8f1-5ad1e3e195ad
┌──id─┬─sku_id──┬─sum(total_amount)─┐
│ 110 │ sku_003 │ 600.00 │
│ 109 │ sku_002 │ 2000.00 │
│ 107 │ sku_002 │ 2000.00 │
│ 106 │ sku_001 │ 1000.00 │
│ 104 │ sku_002 │ 2000.00 │
│ 101 │ sku_002 │ 2000.00 │
│ 103 │ sku_004 │ 2500.00 │
│ 108 │ sku_004 │ 2500.00 │
│ 105 │ sku_003 │ 600.00 │
│ 101 │ sku_001 │ 1000.00 │
└─────┴─────────┴───────────────────┘
┌──id─┬─sku_id─┬─sum(total_amount)─┐
│ 110 │ │ 600.00 │
│ 106 │ │ 1000.00 │
│ 105 │ │ 600.00 │
│ 109 │ │ 2000.00 │
│ 107 │ │ 2000.00 │
│ 104 │ │ 2000.00 │
│ 103 │ │ 2500.00 │
│ 108 │ │ 2500.00 │
│ 101 │ │ 3000.00 │
└─────┴────────┴───────────────────┘
┌─id─┬─sku_id──┬─sum(total_amount)─┐
│ 0 │ sku_003 │ 1200.00 │
│ 0 │ sku_004 │ 5000.00 │
│ 0 │ sku_001 │ 2000.00 │
│ 0 │ sku_002 │ 8000.00 │
└────┴─────────┴───────────────────┘
┌─id─┬─sku_id─┬─sum(total_amount)─┐
│ 0 │ │ 16200.00 │
└────┴────────┴───────────────────┘
24 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :)
- with totals: calculate totals only
cloud-mn01 :) select id , sku_id,sum(total_amount) from t_order_mt group by
:-] id,sku_id with totals;
SELECT
id,
sku_id,
sum(total_amount)
FROM t_order_mt
GROUP BY
id,
sku_id
WITH TOTALS
Query id: 0e5d8a29-253e-4f5d-90a1-73c81122837f
┌──id─┬─sku_id──┬─sum(total_amount)─┐
│ 110 │ sku_003 │ 600.00 │
│ 109 │ sku_002 │ 2000.00 │
│ 107 │ sku_002 │ 2000.00 │
│ 106 │ sku_001 │ 1000.00 │
│ 104 │ sku_002 │ 2000.00 │
│ 101 │ sku_002 │ 2000.00 │
│ 103 │ sku_004 │ 2500.00 │
│ 108 │ sku_004 │ 2500.00 │
│ 105 │ sku_003 │ 600.00 │
│ 101 │ sku_001 │ 1000.00 │
└─────┴─────────┴───────────────────┘
Totals:
┌─id─┬─sku_id─┬─sum(total_amount)─┐
│ 0 │ │ 16200.00 │
└────┴────────┴───────────────────┘
10 rows in set. Elapsed: 0.002 sec.
cloud-mn01 :)
- Data export
clickhouse-client --query "select * from t_order_mt where create_time='2020-06-01 12:00:00'" --format CSVWithNames> /opt/module/data/rs1.csv
3.3 DDL
- New field
alter table tableName add column newcolname String after col1;
- Modify field
alter table tableName modify column newcolname String;
- Delete field
alter table tableName drop column newcolname;
4, Optimize
4.1 table creation optimization
4.1. 1 data type
- Time field
- When creating a table, do not use strings for fields that can be represented by numeric type or date time type;
- Although the ClickHouse underlying layer stores DateTime as the timestamp Long type, it is not recommended to store the Long type;
- DateTime does not need function conversion, with high execution efficiency and good readability.
CREATE TABLE t_type2
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` Int32
)
ENGINE = ReplacingMergeTree(create_time)
PARTITION BY toYYYYMMDD(toDate(create_time)) --It needs to be converted once, otherwise an error will be reported
PRIMARY KEY id
ORDER BY (id, sku_id)
- Null value
- Nullable types almost always drag performance, because when storing nullable columns, an additional file needs to be created to store NULL tags, and nullable columns cannot be indexed;
- Unless it is very special, you should directly use the default value of the field to indicate null, or specify a value that is meaningless in the business;
CREATE TABLE t_null
(
`x` Int8,
`y` Nullable(Int8)
)
ENGINE = TinyLog
[root@cloud-mn01 t_null]# pwd
/var/lib/clickhouse/data/default/t_null
[root@cloud-mn01 t_null]#
[root@cloud-mn01 t_null]# ll
total 16
-rw-r----- 1 clickhouse clickhouse 91 Aug 10 09:21 sizes.json
-rw-r----- 1 clickhouse clickhouse 28 Aug 10 09:21 x.bin
-rw-r----- 1 clickhouse clickhouse 28 Aug 10 09:21 y.bin
-rw-r----- 1 clickhouse clickhouse 28 Aug 10 09:21 y.null.bin
[root@cloud-mn01 t_null]#
4.1. 2 partitions and indexes
- The partition granularity is determined according to the business characteristics and should not be too coarse or too fine. Generally, it is divided by day, or it can be specified as Tuple(). Taking 100 million data in a single table as an example, it is best to control the partition size at 10-30;
- The index column must be specified. The index column in ClickHouse is the row sequence. It is specified by order by. Generally, the attributes often used as filter criteria in query criteria are included;
- It can be a single dimension or an index of combined dimensions; Generally, it is required to meet the principle of high-level column first and high query frequency first;
- In addition, those with a large base are not suitable for index columns, such as the userid field of the user table; Generally, it is the best if the filtered data is within one million.
-- official hits_v1 PARTITION BY toYYYYMM(EventDate) ORDER BY (CounterID, EventDate, intHash32(UserID)) -- official visits_v1 PARTITION BY toYYYYMM(EventDate) ORDER BY (CounterID, EventDate, intHash32(UserID))
4.1. Table 3 parameters
- Index_granularity is used to control the index granularity. The default value is 8192. Adjustment is not recommended unless necessary.
- If it is not necessary to keep the full amount of historical data in the table, it is recommended to specify TTL (survival time value);
4.1. 4 write and delete
- principle
- Try not to perform single or small batch deletion and insertion operations, which will produce small partition files and bring great pressure to the background Merge task;
- Do not write too many partitions at a time, or write data too fast. Too fast data writing will cause the Merge speed to fail to keep up and report an error;
- It is generally recommended to initiate 2-3 write operations every second, and write 2w~5w pieces of data each time (depending on the server performance).
- Write too fast
-- use WAL Pre write log to improve write performance( in_memory_parts_enable_wal Default to true). 1. Code: 252, e.displayText() = DB::Exception: Too many parts(304). Merges are processing significantly slower than inserts -- When the server memory is abundant, the memory quota is increased through max_memory_usage To achieve -- When the server memory is insufficient, it is recommended to allocate the excess content to the system hard disk, but the execution speed will be reduced. Generally, it is through -- max_bytes_before_external_group_by,max_bytes_before_external_sort Parameters. 2. Code: 241, e.displayText() = DB::Exception: Memory limit (for query) exceeded:would use 9.37 GiB (attempt to allocate chunk of 301989888 bytes), maximum: 9.31 GiB
4.1. 5 common configurations
| to configure | describe |
|---|---|
| background_pool_size | The size of the background thread pool. Merge threads are executed in this thread pool. This thread pool is not only used for merge threads. The default value is 16. If allowed, it is recommended to change it to twice the number of CPUs (number of threads). |
| background_schedule_pool_size | The number of threads executing background tasks (replication table, Kafka stream, DNS cache update). The default is 128. It is recommended to change it to twice the number of CPUs (number of threads). |
| background_distributed_schedule_pool_size | It is set as the number of threads for distributed sending and executing background tasks. The default is 16. It is recommended to change it to twice the number of CPUs (threads). |
| max_concurrent_queries | The maximum number of concurrent requests (including select,insert, etc.), the default value is 100, and it is recommended to add 150 ~ 300. |
| max_threads | Set the maximum number of CPUs that can be used by a single query. The default is the number of cpu cores |
| max_memory_usage | This parameter is in users In XML, it indicates the maximum memory occupied by a single Query. This value can be set to be large, which can increase the upper limit of cluster Query. Reserve a bit for the OS, such as a machine with 128G memory, and set it to 100GB. |
| max_bytes_before_external_group_by | Generally according to Max_ memory_ Half of usage sets the memory. When the memory used by the group exceeds the threshold, it will be refreshed to the disk for processing. Because clickhouse aggregation is divided into two stages: querying and creating intermediate data and merging intermediate data. Combined with the previous item, 50GB is recommended. |
| max_bytes_before_external_sort | When order by has used max_bytes_before_external_sort memory overflows the disk (based on disk sorting). If this value is not set, errors will be thrown directly when there is not enough memory. If this value is set, order by can be completed normally, but the speed must be slow compared with the memory (the measured speed is very slow and unacceptable). |
| max_table_size_to_drop | This parameter is in config XML, which is used when tables or partitions need to be deleted. The default is 50GB, which means that deleting partitioned tables above 50GB will fail. It is recommended to change it to 0, so that no matter how large the partition table is, it can be deleted. |
4.2 syntax optimization
4.2.1 EXPLAIN
- EXPLAIN
EXPLAIN [AST | SYNTAX | PLAN | PIPELINE] [setting = value, ...] SELECT ... [FORMAT ...]
- PLAN: used to view the execution PLAN. The default value is.
1.1 header print the head description of each step in the plan. It is off by default and 0 by default;
1.2 description print the description of each step in the plan. It is on by default, and the default value is 1;
1.3 actions print the details of each step in the plan. It is off by default and 0 by default. - AST: used to view the syntax tree;
- SYNTAX: used to optimize SYNTAX;
- PIPELINE: used to view PIPELINE plan.
4.1 header print the head description of each step in the plan. It is closed by default;
4.2 the graph describes the pipeline diagram in DOT graphic language. It is closed by default. Relevant graphics need to be viewed in cooperation with graphviz;
4.3 actions if graph is enabled, compact printing is enabled by default.
EXPLAIN SELECT number FROM system.numbers LIMIT 10 Query id: bbc68c47-0848-4219-ae39-ba0a744df1dd ┌─explain───────────────────────────────────────────────────────────────────┐ │ Expression ((Projection + Before ORDER BY)) │ │ SettingQuotaAndLimits (Set limits and quota after reading from storage) │ │ Limit (preliminary LIMIT) │ │ ReadFromStorage (SystemNumbers) │ └───────────────────────────────────────────────────────────────────────────┘
EXPLAIN header = 1, actions = 1, description = 1 SELECT number FROM system.numbers LIMIT 10 Query id: 4d53ac26-5d3e-4217-9ee2-bd798413c1f6 ┌─explain───────────────────────────────────────────────────────────────────┐ │ Expression ((Projection + Before ORDER BY)) │ │ Header: number UInt64 │ │ Actions: INPUT :: 0 -> number UInt64 : 0 │ │ Positions: 0 │ │ SettingQuotaAndLimits (Set limits and quota after reading from storage) │ │ Header: number UInt64 │ │ Limit (preliminary LIMIT) │ │ Header: number UInt64 │ │ Limit 10 │ │ Offset 0 │ │ ReadFromStorage (SystemNumbers) │ │ Header: number UInt64 │ └───────────────────────────────────────────────────────────────────────────┘
- SYNTAX syntax optimization
-- Ternary operator optimization needs to be turned on SET optimize_if_chain_to_multiif = 1; EXPLAIN SYNTAX SELECT if(number = 1, 'hello', if(number = 2, 'world', 'atguigu')) FROM numbers(10) Query id: d4bd3df8-6a70-4831-8c19-cdfc0ed9da25 ┌─explain─────────────────────────────────────────────────────────────┐ │ SELECT multiIf(number = 1, 'hello', number = 2, 'world', 'atguigu') │ │ FROM numbers(10) │ └─────────────────────────────────────────────────────────────────────┘
4.2. 2 optimization rules
- Prepare test data
[root@cloud-mn01 ~]# ll total 1792572 -rw-r--r-- 1 root root 1271623680 Aug 10 09:58 hits_v1.tar -rw-r--r-- 1 root root 563968000 Aug 10 09:58 visits_v1.tar [root@cloud-mn01 ~]# tar -xf hits_v1.tar -C /var/lib/clickhouse # hits_ The V1 table has more than 130 fields and more than 8.8 million pieces of data [root@cloud-mn01 ~]# tar -xf visits_v1.tar -C /var/lib/clickhouse # visits_ The V1 table has more than 180 fields and more than 1.6 million pieces of data [root@cloud-mn01 ~]# systemctl restart clickhouse-server.service [root@cloud-mn01 ~]#
- COUNT optimization
When you call the count function, if you use count() or count(*) and there is no where condition, you will directly use system Total of tables_ rows
cloud-mn01 :) EXPLAIN SELECT count()FROM datasets.hits_v1; EXPLAIN SELECT count() FROM datasets.hits_v1 Query id: 6ac410cd-81f1-4d96-bd35-2d45bbfb276d ┌─explain──────────────────────────────────────────────┐ │ Expression ((Projection + Before ORDER BY)) │ │ MergingAggregated │ │ ReadFromPreparedSource (Optimized trivial count) │ └──────────────────────────────────────────────────────┘ 3 rows in set. Elapsed: 0.002 sec. cloud-mn01 :)
If count is a specific column field, this optimization will not be used
cloud-mn01 :) EXPLAIN SELECT count(CounterID)FROM datasets.hits_v1; EXPLAIN SELECT count(CounterID) FROM datasets.hits_v1 Query id: be5182bb-4808-4e8f-a395-1fedd1bdd0be ┌─explain───────────────────────────────────────────────────────────────────────┐ │ Expression ((Projection + Before ORDER BY)) │ │ Aggregating │ │ Expression (Before GROUP BY) │ │ SettingQuotaAndLimits (Set limits and quota after reading from storage) │ │ ReadFromMergeTree │ └───────────────────────────────────────────────────────────────────────────────┘ 5 rows in set. Elapsed: 0.002 sec. cloud-mn01 :)
- Predicate push down
When group by has a having clause but is not modified with cube, with rollback or with totals, the having filter will be pushed down to where to filter in advance.
EXPLAIN SYNTAX SELECT UserID FROM datasets.hits_v1 GROUP BY UserID HAVING UserID = '8585742290196126178' Query id: 1ecd2b6b-6a0d-400a-aca1-3e9eac0b7874 ┌─explain──────────────────────────────┐ │ SELECT UserID │ │ FROM datasets.hits_v1 │ │ WHERE UserID = '8585742290196126178' │ │ GROUP BY UserID │ └──────────────────────────────────────┘
Subqueries also support predicate push down
EXPLAIN SYNTAX
SELECT *
FROM
(
SELECT UserID
FROM datasets.visits_v1
)
WHERE UserID = '8585742290196126178'
Query id: 4cece210-36f7-45c3-95a3-acb75a72ad09
┌─explain──────────────────────────────────┐
│ SELECT UserID │
│ FROM │
│ ( │
│ SELECT UserID │
│ FROM datasets.visits_v1 │
│ WHERE UserID = '8585742290196126178' │
│ ) │
│ WHERE UserID = '8585742290196126178' │
└──────────────────────────────────────────┘
- Aggregate calculation extrapolation
EXPLAIN SYNTAX SELECT sum(UserID * 2) FROM datasets.visits_v1 Query id: bf6d9094-9c2a-4c70-acc4-574dee713e9a ┌─explain─────────────────┐ │ SELECT sum(UserID) * 2 │ │ FROM datasets.visits_v1 │ └─────────────────────────┘
- Aggregate function elimination
If min, max and any aggregate functions are used for the aggregate key, that is, group by key, the function is eliminated
EXPLAIN SYNTAX
SELECT
sum(UserID * 2),
max(VisitID),
max(UserID)
FROM visits_v1
GROUP BY UserID
Query id: 88dc8579-e110-433b-bc52-46d90078b187
┌─explain──────────────┐
│ SELECT │
│ sum(UserID) * 2, │
│ max(VisitID), │
│ UserID │
│ FROM visits_v1 │
│ GROUP BY UserID │
└──────────────────────┘
- scalar replacement
If the subquery returns only one row of data, it is replaced with scalar when referenced
EXPLAIN SYNTAX
WITH (
SELECT sum(bytes)
FROM system.parts
WHERE active
) AS total_disk_usage
SELECT
(sum(bytes) / total_disk_usage) * 100 AS table_disk_usage,
table
FROM system.parts
GROUP BY table
ORDER BY table_disk_usage DESC
LIMIT 10
Query id: dd48033c-d21b-41f2-87f0-78f3c529dc6b
┌─explain─────────────────────────────────────────────────────────────────────────┐
│ WITH identity(CAST(0, 'UInt64')) AS total_disk_usage │
│ SELECT │
│ (sum(bytes_on_disk AS bytes) / total_disk_usage) * 100 AS table_disk_usage, │
│ table │
│ FROM system.parts │
│ GROUP BY table │
│ ORDER BY table_disk_usage DESC │
│ LIMIT 10 │
└─────────────────────────────────────────────────────────────────────────────────┘
- Ternary operation optimization
If optimize is on_ if_ chain_ to_ For the multiIf parameter, the ternary operator will be replaced by the multiIf function
EXPLAIN SYNTAX SELECT if(number = 1, 'hello', if(number = 2, 'world', 'atguigu')) FROM numbers(10) SETTINGS optimize_if_chain_to_multiif = 1 Query id: e1cb685f-a2b9-4121-bd8e-374b0c76d735 ┌─explain─────────────────────────────────────────────────────────────┐ │ SELECT multiIf(number = 1, 'hello', number = 2, 'world', 'atguigu') │ │ FROM numbers(10) │ │ SETTINGS optimize_if_chain_to_multiif = 1 │ └─────────────────────────────────────────────────────────────────────┘
4.3 query optimization
4.3. 1 single table
- PreWhere
- The function of the where statement is the same as that of the where statement, which is used to filter data.
- The difference is that where only supports the tables of * MergeTree family engines. First, it will read the specified column data to judge the data filtering. After the data filtering, it will read the column field declared by select to complete the other attributes.
- When the query columns are significantly more than the filter columns, the query performance can be improved ten times by using prewhere. Prewhere will automatically optimize the data reading method in the filtering stage and reduce io operations.
- In some scenarios, you need to specify the where manually
4.1 using constant expressions
4.2 use fields of alias type by default
4.3 query including arrayJOIN, globalIn, globalNotIn or indexHint
4.4 the column field of select query is the same as the predicate of where
4.5 primary key field is used
- sampling
The sampling modifier is valid only in the MergeTree engine table, and the sampling policy needs to be specified when creating the table.
CREATE TABLE datasets.hits_v1
(
`WatchID` UInt64,
`JavaEnable` UInt8,
...
`RequestTry` UInt8
)
ENGINE = MergeTree
...
SAMPLE BY intHash32(UserID)
...
SELECT
Title,
count(*) AS PageViews
FROM hits_v1
SAMPLE 0.1 -- Representative sampling 10%Data,It can also be a specific number
WHERE CounterID = 57
GROUP BY Title
ORDER BY PageViews DESC
LIMIT 1000
Query id: 269e0b6b-4e78-4282-8e35-f5bdc73c69c3
┌─Title────────────────────────────────────────────────────────────────┬─PageViews─┐
│ │ 77 │
│ Фильмы онлайн на сегодня │ 6 │
│ Сбербанка «Работа, мебель обувь бензор.НЕТ « Новости, аксессионально │ 6 │
└──────────────────────────────────────────────────────────────────────┴───────────┘
- duplicate removal
- uniqCombined replaces distinct, and its performance can be improved by more than 10 times;
- The underlying layer of uniqCombined is implemented by hyperlog algorithm, which has a data error of about 2%. This de duplication method can be directly used to improve the query performance;
- Count(distinct) will use uniqExact for accurate de duplication;
- It is not recommended to perform distinct de duplication query on tens of millions of different data, but to perform approximate de duplication uniqCombined instead.
cloud-mn01 :) select count(distinct rand()) from hits_v1; SELECT countDistinct(rand()) FROM hits_v1 Query id: 4c17ea01-14f6-4c83-9990-450bb30a2f59 ┌─uniqExact(rand())─┐ │ 8864520 │ └───────────────────┘ 1 rows in set. Elapsed: 0.483 sec. Processed 8.87 million rows, 80.31 MB (18.37 million rows/s., 166.26 MB/s.) cloud-mn01 :) SELECT uniqCombined(rand()) from datasets.hits_v1 ; SELECT uniqCombined(rand()) FROM datasets.hits_v1 Query id: 63912054-e9ed-47d1-a4db-1923a5c8f9c1 ┌─uniqCombined(rand())─┐ │ 8878876 │ └──────────────────────┘ 1 rows in set. Elapsed: 0.102 sec. Processed 8.87 million rows, 80.31 MB (86.86 million rows/s., 786.11 MB/s.) cloud-mn01 :)
- matters needing attention
- Query fusing: in order to avoid the service avalanche caused by individual slow queries, in addition to setting timeout for a single query, cycle fusing can also be configured. In a query cycle, if users frequently perform slow query operations, they will not be able to continue query operations after exceeding the specified threshold.
- Turn off virtual memory: the data exchange between physical memory and virtual memory will slow down the query. If resources allow, turn off virtual memory.
- Configure join_use_nulls: add a join for each account_ use_ Nulls configuration, a record in the left table does not exist in the right table, and the corresponding field in the right table will return the default value of the corresponding data type of the field instead of the Null value in standard SQL.
- Sort before batch writing: when batch writing data, the number of partitions involved in each batch of data must be controlled. It is best to sort the data to be imported before writing. Disordered data or too many partitions will cause ClickHouse to fail to merge the newly imported data in time, thus affecting the query performance.
- Pay attention to cpu: generally, query fluctuations will occur when the cpu is about 50%, and a wide range of query timeout will occur when it reaches 70%. cpu is the most critical indicator, so we should pay close attention to it.
4.3. 2 multi meter
- Use IN instead of JOIN: when multiple tables are associated queried and the queried data is only from one table, consider using IN instead of JOIN;
- Size table join: when joining multiple tables, the principle of small tables on the right should be met. When the right table is associated, it is loaded into memory and compared with the left table;
- Note that predicate push down: ClickHouse will not actively initiate predicate push down during join query, and each sub query needs to complete the filtering operation in advance;
- Distributed tables use GLOBAL: the IN and JOIN of two distributed tables must be preceded by the GLOBAL keyword. The right table will only be queried once at the node receiving the query request and distributed to other nodes. If the GLOBAL keyword is not added, each node will initiate a separate query on the right table, and the right table is a distributed table, resulting IN a total of N queries on the right table ² Times (n is the number of slices of the distributed table), which is query amplification, which will bring great overhead.
5, Advanced
5.1 data consistency
Replaceingmergetree and SummingMergeTree only guarantee the final consistency. There will be short-term data inconsistency after updating the table data.
- Environmental preparation
-- user_id Is the identification of data De duplication update;
-- create_time Is the version number field in each group of data create_time The largest row represents the latest data;
-- deleted Is a self-defined flag bit. For example, 0 means not deleted and 1 means deleted data.
CREATE TABLE test_a
(
`user_id` UInt64,
`score` String,
`deleted` UInt8 DEFAULT 0,
`create_time` DateTime DEFAULT toDateTime(0)
)
ENGINE = ReplacingMergeTree(create_time)
ORDER BY user_id
INSERT INTO test_a (user_id, score) WITH (
SELECT ['A', 'B', 'C', 'D', 'E', 'F', 'G']
) AS dict
SELECT
number AS user_id,
dict[(number % 7) + 1]
FROM numbers(100000)
- De duplication through FINAL
Add the FINAL modifier after the query statement, so that the special logic of Merge (such as data De duplication, pre aggregation, etc.) will be executed during the query.
-- Update data
INSERT INTO test_a (user_id, score, create_time) WITH (
SELECT ['AA', 'BB', 'CC', 'DD', 'EE', 'FF', 'GG']
) AS dict
SELECT
number AS user_id,
dict[(number % 7) + 1],
now() AS create_time
FROM numbers(5000)
-- General query
SELECT COUNT()
FROM test_a
WHERE user_id < 5000
┌─count()─┐
│ 10000 │
└─────────┘
-- adopt FINAL query
SELECT COUNT()
FROM test_a
FINAL
WHERE user_id < 5000
┌─count()─┐
│ 5000 │
└─────────┘
- De duplication through GROUP BY
-- argMax(field1,field2):according to field2 The maximum value of is taken as field1 Value of.
-- When we update the data, we will write a new row of data. For example, in the above statement, we can query the largest data create_time Modified score Field value.
SELECT
user_id ,
argMax(score, create_time) AS score,
argMax(deleted, create_time) AS deleted,
max(create_time) AS ctime
FROM test_a
GROUP BY user_id
HAVING deleted = 0;
-- Create views to facilitate testing
CREATE VIEW view_test_a AS
SELECT
user_id,
argMax(score, create_time) AS score,
argMax(deleted, create_time) AS deleted,
max(create_time) AS ctime
FROM test_a
GROUP BY user_id
HAVING deleted = 0
-- Update data
INSERT INTO test_a (user_id, score, create_time) VALUES
-- Query view, de duplication
SELECT *
FROM view_test_a
WHERE user_id = 0
Query id: a11e2648-cba4-4fde-9e95-3a6896f0adca
┌─user_id─┬─score─┬─deleted─┬───────────────ctime─┐
│ 0 │ AAAA │ 0 │ 2021-08-10 11:17:49 │
└─────────┴───────┴─────────┴─────────────────────┘
-- Query the original table, and all records are in the
SELECT *
FROM test_a
WHERE user_id = 0
Query id: 55af213a-f8b7-4238-8456-bc5df1b62562
┌─user_id─┬─score─┬─deleted─┬─────────create_time─┐
│ 0 │ AAAA │ 0 │ 2021-08-10 11:17:49 │
└─────────┴───────┴─────────┴─────────────────────┘
┌─user_id─┬─score─┬─deleted─┬─────────create_time─┐
│ 0 │ A │ 0 │ 1970-01-01 08:00:00 │
└─────────┴───────┴─────────┴─────────────────────┘
-- Delete data
INSERT INTO test_a (user_id, score, deleted, create_time) VALUES
-- Query the view and the record disappears
SELECT *
FROM view_test_a
WHERE user_id = 0
Query id: c6157128-84ac-4e86-92a9-68aad99b539d
Ok.
0 rows in set. Elapsed: 0.006 sec. Processed 8.19 thousand rows, 188.47 KB (1.47 million rows/s., 33.80 MB/s.)
-- Query the original table, and the data is in the
SELECT *
FROM test_a
WHERE user_id = 0
Query id: 482cbcdb-f2d1-45b4-ba05-7153c0e0a6ef
┌─user_id─┬─score─┬─deleted─┬─────────create_time─┐
│ 0 │ AAAA │ 0 │ 2021-08-10 11:17:49 │
└─────────┴───────┴─────────┴─────────────────────┘
┌─user_id─┬─score─┬─deleted─┬─────────create_time─┐
│ 0 │ AAAA │ 1 │ 2021-08-10 11:19:10 │
└─────────┴───────┴─────────┴─────────────────────┘
┌─user_id─┬─score─┬─deleted─┬─────────create_time─┐
│ 0 │ A │ 0 │ 1970-01-01 08:00:00 │
└─────────┴───────┴─────────┴─────────────────────┘
5.2 materialized view
- brief introduction
- The normal view does not save data, but only query statements, while the materialized view of ClickHouse is a kind of persistence of query results;
- The user's query is no different from the table. It is a table, and it is also like a table that is being pre calculated at all times;
- Advantages: fast query speed;
- Disadvantages: its essence is a usage scenario of streaming data. It is a cumulative technology, which is not suitable for de reanalysis of historical data; If many materialized views are added to a table, many machine resources will be consumed when writing this table.
- grammar
It is also the create syntax, which creates a hidden target table TO save the view data. You can also save the TO table name TO
An explicit table. No TO table name is added. The table name defaults TO inner. Materialized view name
CREATE [MATERIALIZED] VIEW [IF NOT EXISTS] [db.]table_name [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT ...
- The engine of materialized view must be specified for data storage;
- TO [db]. When using [table] syntax, you cannot use popup;
- The popup keyword determines the update strategy of materialized view: + query historical data, - only apply to newly inserted data;
- The materialized view does not support synchronous deletion. If the data of the source table does not exist (deleted), the data of the materialized view will still be retained.
- demonstration
-- Create original table
CREATE TABLE hits_test
(
`EventDate` Date,
`CounterID` UInt32,
`UserID` UInt64,
`URL` String,
`Income` UInt8
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
SETTINGS index_granularity = 8192
-- insert data
INSERT INTO hits_test SELECT
EventDate,
CounterID,
UserID,
URL,
Income
FROM datasets.hits_v1
LIMIT 10000
-- Create materialized view
CREATE MATERIALIZED VIEW hits_mv
ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(EventDate)
ORDER BY (EventDate, intHash32(UserID)) AS
SELECT
UserID,
EventDate,
count(URL) AS ClickCount,
sum(Income) AS IncomeSum
FROM hits_test
WHERE EventDate >= '2014-03-20'
GROUP BY
UserID,
EventDate
-- View generated inner surface
SHOW TABLES
┌─name───────────────────────────────────────────┐
│ .inner_id.069f7d89-bd86-4ae6-869f-7d89bd86fae6 │
│ hits_mv │
│ hits_test │
└────────────────────────────────────────────────┘
-- Import incremental data
INSERT INTO hits_test SELECT
EventDate,
CounterID,
UserID,
URL,
Income
FROM datasets.hits_v1
WHERE EventDate >= '2014-03-23'
LIMIT 10
-- Query materialized view
SELECT *
FROM hits_mv
Query id: 9af4d8b2-7e9d-48d1-b950-a923e95a047c
┌──────────────UserID─┬──EventDate─┬─ClickCount─┬─IncomeSum─┐
│ 8585742290196126178 │ 2014-03-23 │ 8 │ 16 │
│ 1095363898647626948 │ 2014-03-23 │ 2 │ 0 │
└─────────────────────┴────────────┴────────────┴───────────┘
2 rows in set. Elapsed: 0.002 sec.
5.3 materialized MySQL engine
- brief introduction
- The database engine of materialize MySQL can map to a database in MySQL and automatically create the corresponding replaceingmergetree in ClickHouse;
- As a MySQL copy, ClickHouse service reads Binlog and executes DDL and DML requests, realizing the real-time synchronization function of business database based on MySQL Binlog mechanism;
- Materialized MySQL supports both full and incremental synchronization. At the beginning of database creation, tables and data in MySQL will be fully synchronized, and then incremental synchronization will be carried out through binlog;
- The materialized MySQL database automatically adds a new value for each replaceingmergetree it creates_ sign and_ version field;
- The ClickHouse database table automatically converts MySQL primary keys and index clauses into ORDER BY tuples.
- _sign + _version
_ Version is used as a version parameter. Whenever insert, update and delete events are heard, it will be automatically incremented globally in databse; And_ sign is used to mark whether it is deleted. The value is 1 or - 1.
- MYSQL_WRITE_ROWS_EVENT: _sign = 1,_version ++
- MYSQL_DELETE_ROWS_EVENT: _sign = -1,_version ++
- MYSQL_UPDATE_ROWS_EVENT: new data_ sign = 1,_ version ++
- MYSQL_QUERY_EVENT: supports CREATE TABLE, DROP TABLE, RENAME TABLE, etc.
- MySQL configuration
The binlog and GTID modes need to be enabled
[root@cloud-dn02 ~]# cat /etc/my.cnf [mysqld] user=root basedir=/opt/module/mysql datadir=/opt/module/mysql/data socket=/tmp/mysql.sock port=3306 # Make sure that MySQL has the binlog function enabled and the format is ROW server_id=6 log-bin=mysql-bin binlog_format=ROW # Turn on GTID mode, which can ensure the consistency of data synchronization in mysql master-slave mode (during master-slave switching). gtid-mode=on enforce-gtid-consistency=1 log-slave-updates=1 # the MaterializeMySQL engine requires default_authentication_plugin='mysql_native_password'. default_authentication_plugin=mysql_native_password [mysql] socket=/tmp/mysql.sock [root@cloud-dn02 ~]#
- Exhibition
- Create MySQL tables and insert data
CREATE DATABASE testck; CREATE TABLE `testck`.`t_organization` ( `id` int(11) NOT NULL AUTO_INCREMENT, `code` int NOT NULL, `name` text DEFAULT NULL, `updatetime` datetime DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY (`code`) ) ENGINE=InnoDB; INSERT INTO testck.t_organization (code, name,updatetime) VALUES(1000,'Realinsight',NOW()); INSERT INTO testck.t_organization (code, name,updatetime) VALUES(1001, 'Realindex',NOW()); INSERT INTO testck.t_organization (code, name,updatetime) VALUES(1002,'EDT',NOW()); CREATE TABLE `testck`.`t_user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `code` int, PRIMARY KEY (`id`) ) ENGINE=InnoDB; INSERT INTO testck.t_user (code) VALUES(1);
- Create ClickHouse synchronization database
SET allow_experimental_database_materialize_mysql = 1
CREATE DATABASE test_binlog
ENGINE = MaterializeMySQL('cloud-dn02:3306', 'testck', 'rayslee', 'abcd1234..')
# Note that there may be an unknown error when using root: Code: 100 DB::Exception: Received from localhost:9000. DB::Exception: Access denied for user root.
cloud-mn01 :) show tables;
SHOW TABLES
Query id: 95891aee-ffbc-4b0c-abc1-881266785c86
┌─name───────────┐
│ t_organization │
│ t_user │
└────────────────┘
2 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :) select * from t_user;
SELECT *
FROM t_user
Query id: 9fa08f8a-4cd3-4c85-a71d-e3a92237caa8
┌─id─┬─code─┐
│ 1 │ 1 │
└────┴──────┘
1 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :) select * from t_organization;
SELECT *
FROM t_organization
Query id: eb1662db-101e-4132-aa7c-0326099ed084
┌─id─┬─code─┬─name────────┬──────────updatetime─┐
│ 1 │ 1000 │ Realinsight │ 2021-08-11 11:22:34 │
│ 2 │ 1001 │ Realindex │ 2021-08-11 11:22:34 │
│ 3 │ 1002 │ EDT │ 2021-08-11 11:22:34 │
└────┴──────┴─────────────┴─────────────────────┘
3 rows in set. Elapsed: 0.003 sec.
cloud-mn01 :)
5.4 cluster monitoring
- Installation monitoring
- Install prometheus
[root@cloud-mn01 ~]# tar -zxf /opt/soft/prometheus-2.26.0.linux-amd64.tar.gz -C /opt/module/
[root@cloud-mn01 ~]# ln -s /opt/module/prometheus-2.26.0.linux-amd64 /opt/module/prometheus
[root@cloud-mn01 ~]# vi /opt/module/prometheus/prometheus.yml
[root@cloud-mn01 ~]# tail /opt/module/prometheus/prometheus.yml
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
# Add clickhouse monitoring
- job_name: 'clickhouse'
static_configs:
- targets: ['cloud-mn01:9363']
[root@cloud-mn01 ~]# nohup /opt/module/prometheus/prometheus --config.file=/opt/module/prometheus/prometheus.yml &>> /var/log/prometheus.log &
[1] 1683
[root@cloud-mn01 ~]#
http://192.168.1.101:9090/targets
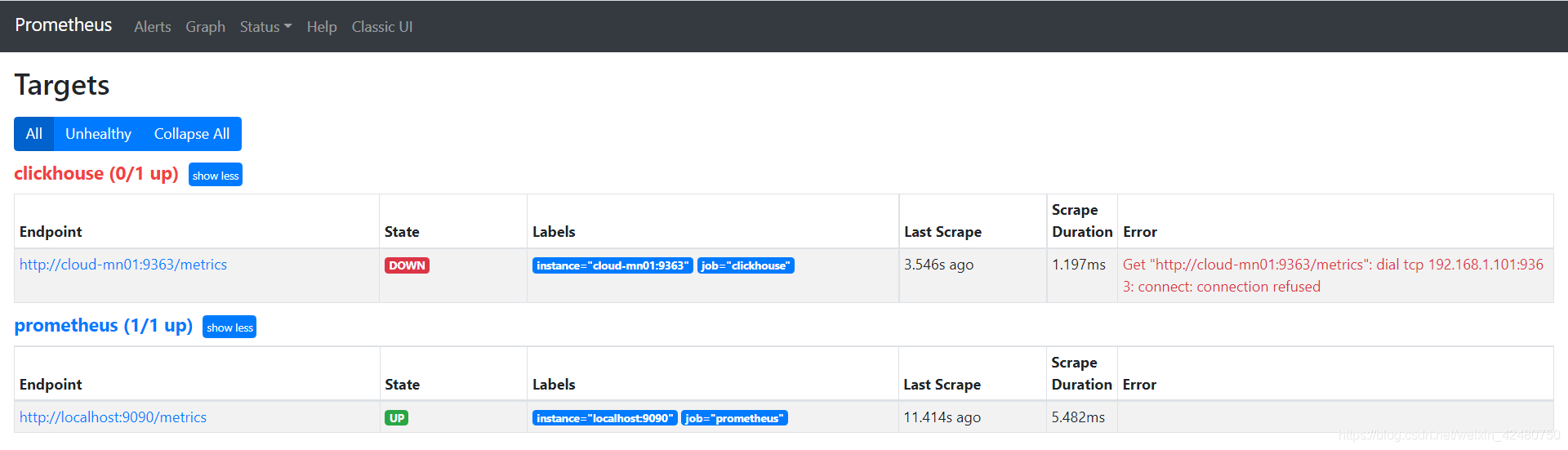
- Installing grafana
[root@cloud-mn01 ~]# tar -zxf /opt/soft/grafana-7.5.2.linux-amd64.tar.gz -C /opt/module/ [root@cloud-mn01 ~]# ln -s /opt/module/grafana-7.5.2 /opt/module/grafana [root@cloud-mn01 ~]# cd /opt/module/grafana # Note: you must enter the Grafana home directory for execution [root@cloud-mn01 grafana]# nohup ./bin/grafana-server web &>> /var/log/grafana-server.log & [2] 1748 [root@cloud-mn01 grafana]#
http://192.168.1.101:3000/ Default username and password admin/admin
- Clickhouse adaptation
[root@cloud-mn01 ~]# vim /etc/clickhouse-server/config.xml
# Open external access
<listen_host>::</listen_host>
# Open monitoring indicator
<prometheus>
<endpoint>/metrics</endpoint>
<port>9363</port>
<metrics>true</metrics>
<events>true</events>
<asynchronous_metrics>true</asynchronous_metrics>
<status_info>true</status_info>
</prometheus>
[root@cloud-mn01 ~]# systemctl restart clickhouse-server.service
[root@cloud-mn01 ~]#
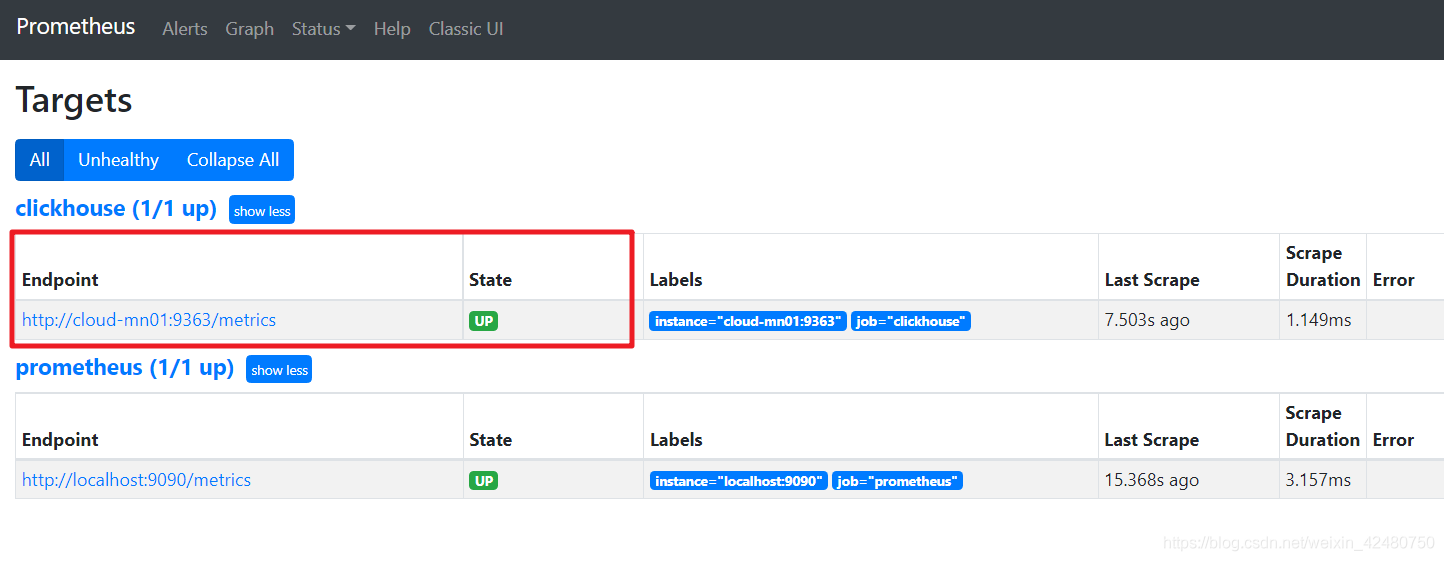
- Add monitoring
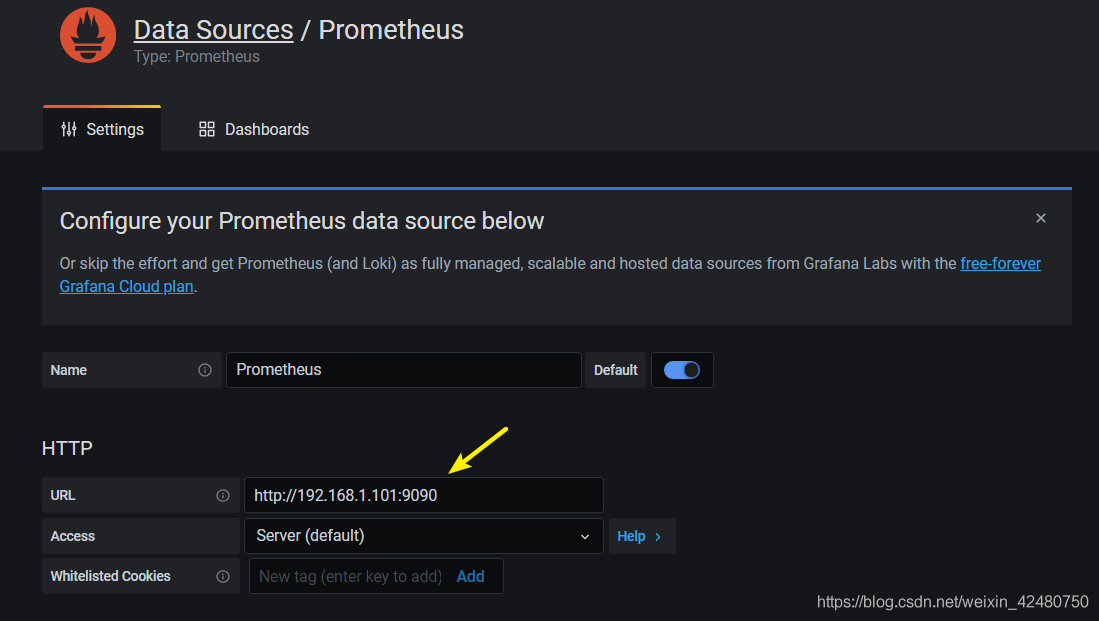
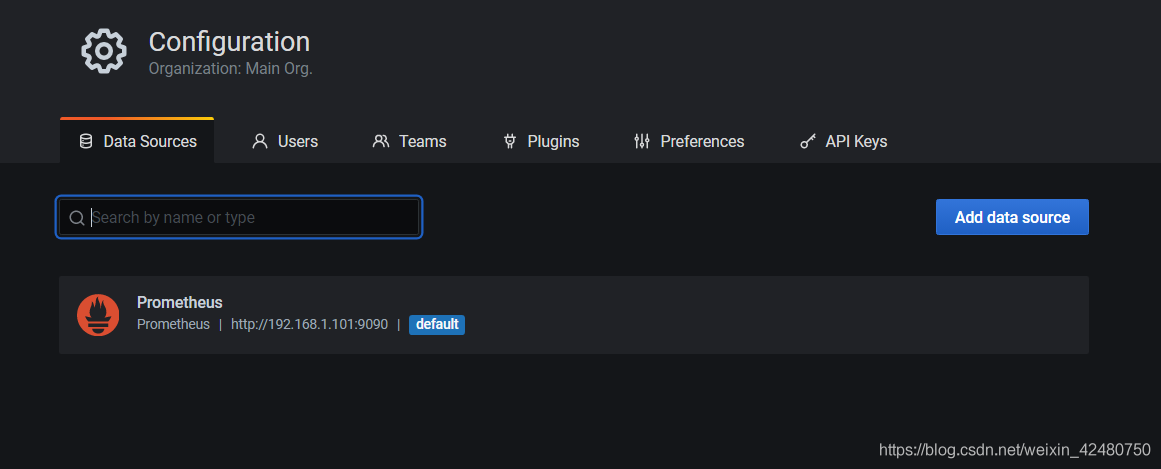
- add data source
- Select monitoring indicator template
https://grafana.com/grafana/dashboards/14432
- Import template
'+' => Import

- View monitoring effect
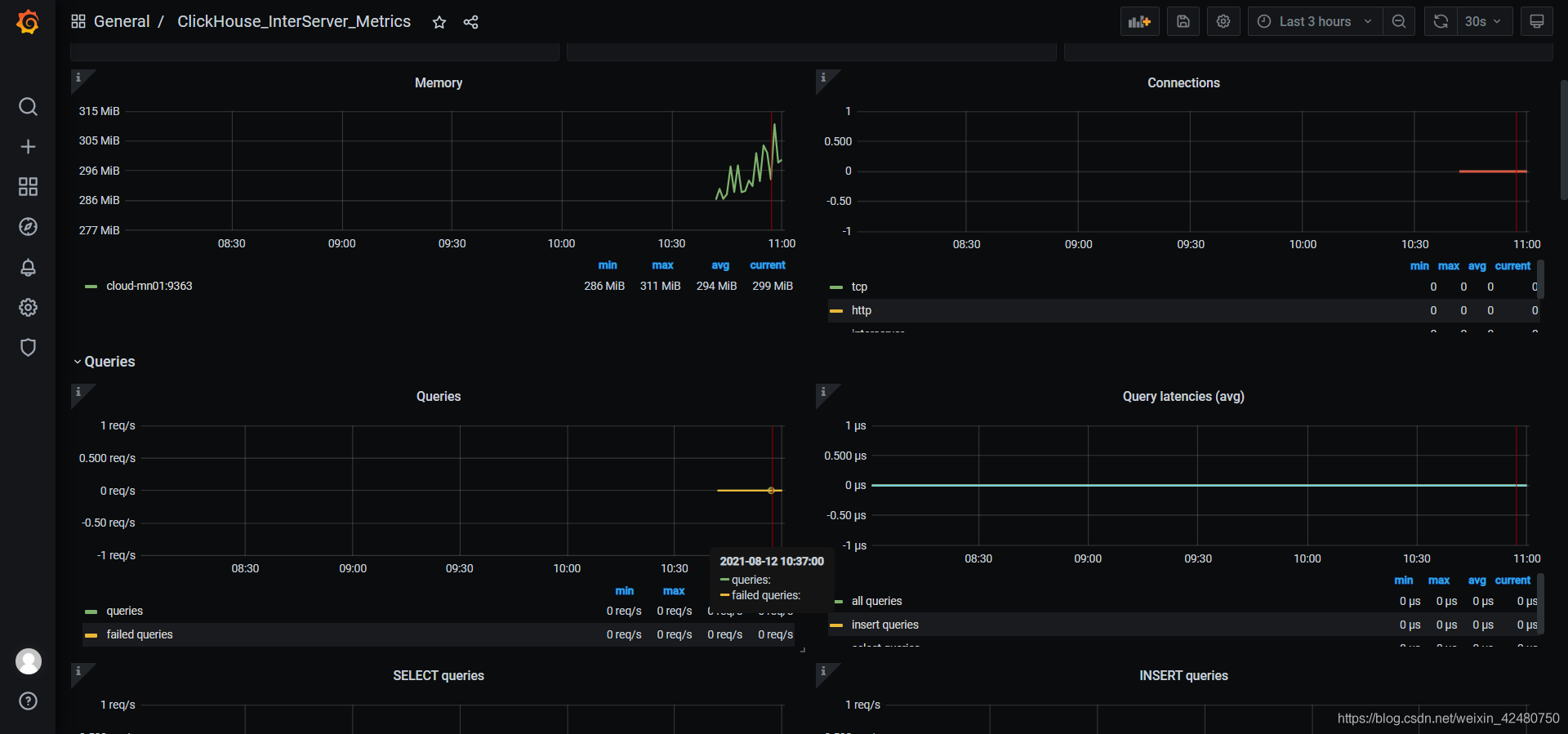
5.5 backup and recovery
https://github.com/AlexAkulov/clickhouse-backup/releases/tag/v1.0.0
## The tool has a version compatibility problem temporarily (the latest version of clickhouse was released in July and the latest version of the tool was released in June) [root@cloud-mn01 soft]# rpm -ivh clickhouse-backup-1.0.0-1.x86_64.rpm Preparing... ################################# [100%] Updating / installing... 1:clickhouse-backup-1.0.0-1 ################################# [100%] [root@cloud-mn01 soft]# cd /etc/clickhouse-backup/ [root@cloud-mn01 clickhouse-backup]# ll total 4 -rw-r--r-- 1 root root 1682 Jun 17 00:49 config.yml.example [root@cloud-mn01 clickhouse-backup]#