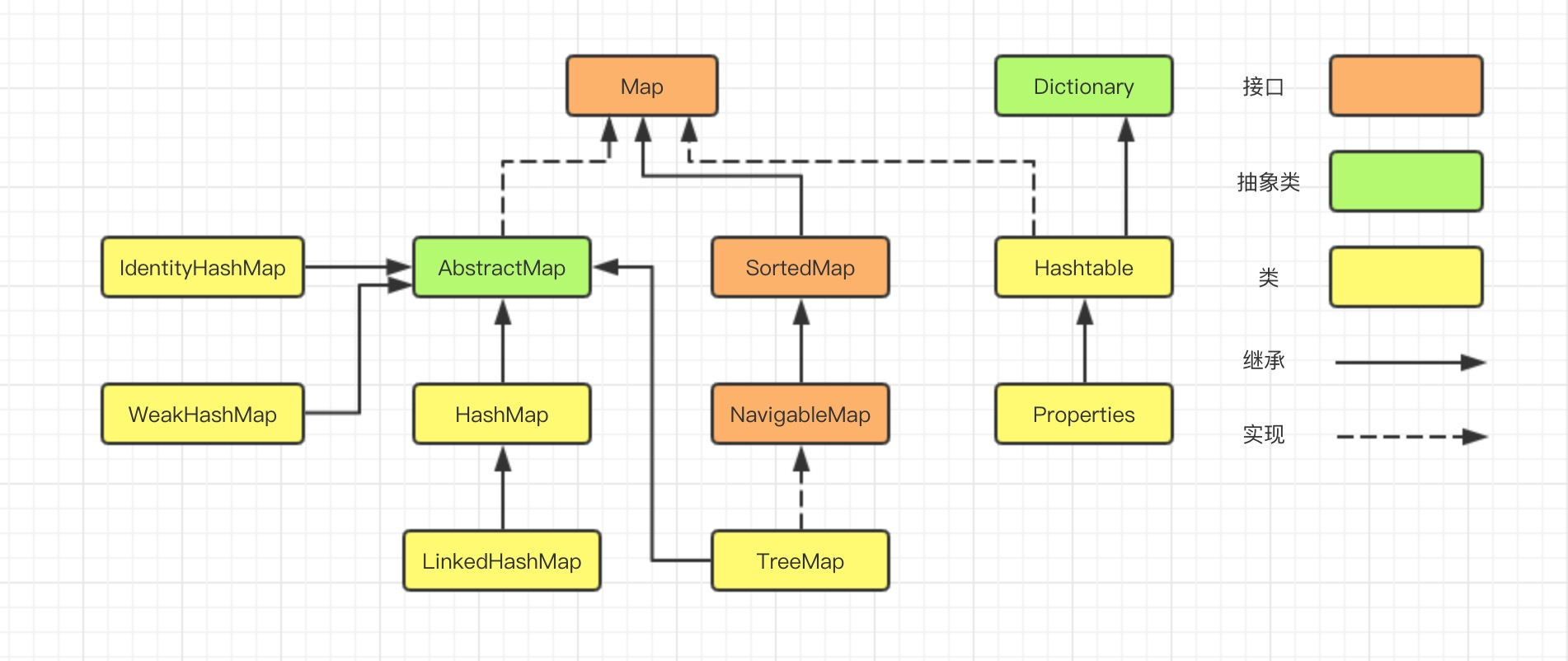
1. Summary
In the first chapter of the collection series, we learned that the implementation classes of Map are HashMap, LinkedHashMap, TreeMap, IdentityHashMap, WeakHashMap, Hashtable, Properties, and so on.
This paper mainly discusses the implementation of LinkedHashMap from the data structure and algorithm level.
2. Introduction
LinkedHashMap can be thought of as HashMap+LinkedList, which uses both HashMap to manipulate the data structure and LinkedList to maintain the order in which elements are inserted, linking all elements internally as a double-linked list.
LinkedHashMap inherits HashMap, allowing elements with null key and null value to be inserted.The name suggests that the container is a mixture of LinkedList and HashMap, that is, it satisfies some of the features of both HashMap and LinkedList, and LinkedHashMap can be thought of as a HashMap enhanced with Linked list.
Opening the LinkedHashMap source code reveals three main core properties:
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>{
/**Head Node of Bidirectional Chain List*/
transient LinkedHashMap.Entry<K,V> head;
/**End Node of Bidirectional Chain List*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* 1,If accessOrder is true, the elements visited are placed behind the list in the order in which they were visited
* 2,If accessOrder is false, traverse in insertion order
*/
final boolean accessOrder;
}LinkedHashMap is traversed in the initialization phase by default in the insertion order
public LinkedHashMap() {
super();
accessOrder = false;
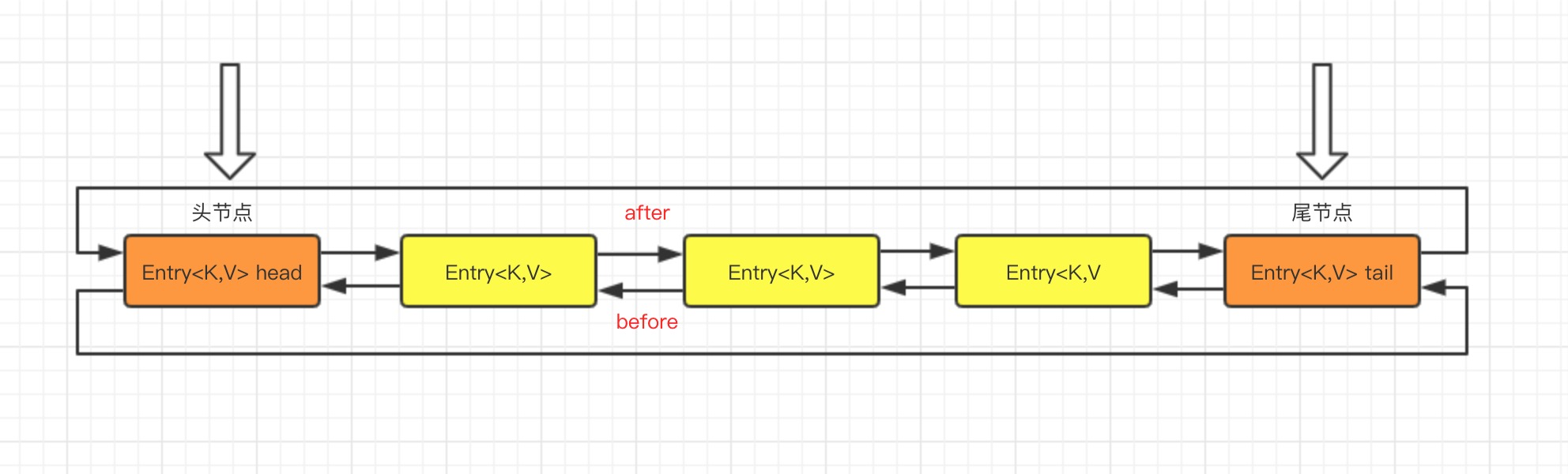
}LinkedHashMap uses the same Hash algorithm as HashMap, except that it redefines the element Entry stored in the array, which not only saves references to the current object, but also saves references to the previous element before and the next element after, thus forming a two-way link list based on a hash table.
The source code is as follows:
static class Entry<K,V> extends HashMap.Node<K,V> {
//before refers to the precursor node of a list of chains, after refers to the precursor node of a list of chains
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}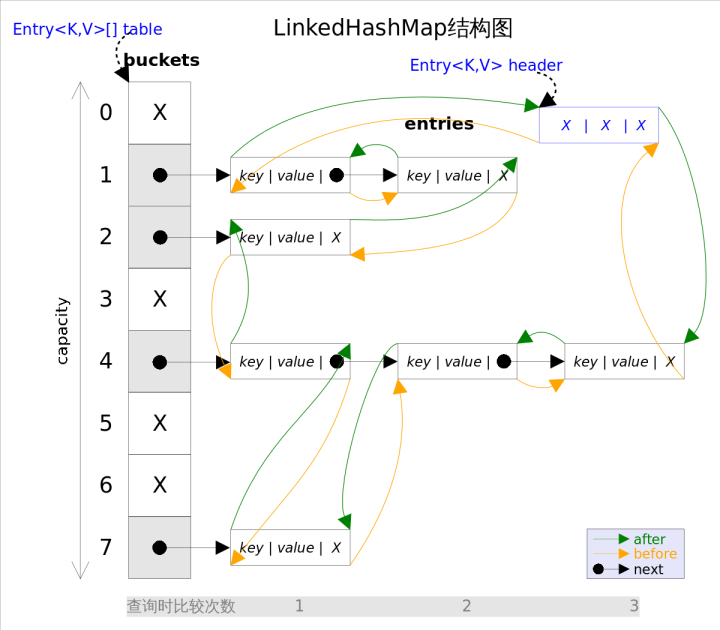
It is intuitive to see that the data inserted into the head of a two-way chain table is the entry to the chain table, and the iterator traversal direction is from the head of the chain table to the end of the chain table.
In addition to maintaining the iteration order, this structure has one advantage: instead of traversing the entire table as HashMap does when iterating over LinkedHashMap, it simply traverses the two-way chain table pointed to by the header directly, which means that the iteration time of LinkedHashMap is only related to the number of entries, not to the size of the table.
3. Introduction of Common Methods
3.1. get method
The get method returns the corresponding value based on the specified key value.This method works almost exactly like the HashMap.get() method, traversing in the insertion order by default.
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}If accessOrder is true, the elements visited are placed behind the list in the order in which they are accessed
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}Test cases:
public static void main(String[] args) {
//accessOrder defaults to false
Map<String, String> accessOrderFalse = new LinkedHashMap<>();
accessOrderFalse.put("1","1");
accessOrderFalse.put("2","2");
accessOrderFalse.put("3","3");
accessOrderFalse.put("4","4");
System.out.println("acessOrderFalse: "+accessOrderFalse.toString());
//accessOrder set to true
Map<String, String> accessOrderTrue = new LinkedHashMap<>(16, 0.75f, true);
accessOrderTrue.put("1","1");
accessOrderTrue.put("2","2");
accessOrderTrue.put("3","3");
accessOrderTrue.put("4","4");
accessOrderTrue.get("2");//Get Key 2
accessOrderTrue.get("3");//Get Key 3
System.out.println("accessOrderTrue: "+accessOrderTrue.toString());
}Output results:
acessOrderFalse: {1=1, 2=2, 3=3, 4=4}
accessOrderTrue: {1=1, 4=4, 2=2, 3=3}3.2, put method
The put(K key, V value) method adds the specified key, value pair to the map.This method first calls HashMap's insert method, and also does a lookup on the map to see if it contains the element, returns directly if it already contains it, and the lookup process is similar to the get() method; if it is not found, inserts the element into the collection.
/**HashMap Medium implementation*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}Override methods in LinkedHashMap
// Override in LinkedHashMap
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// Join Entry at the end of a two-way Chain List
linkNodeLast(p);
return p;
}
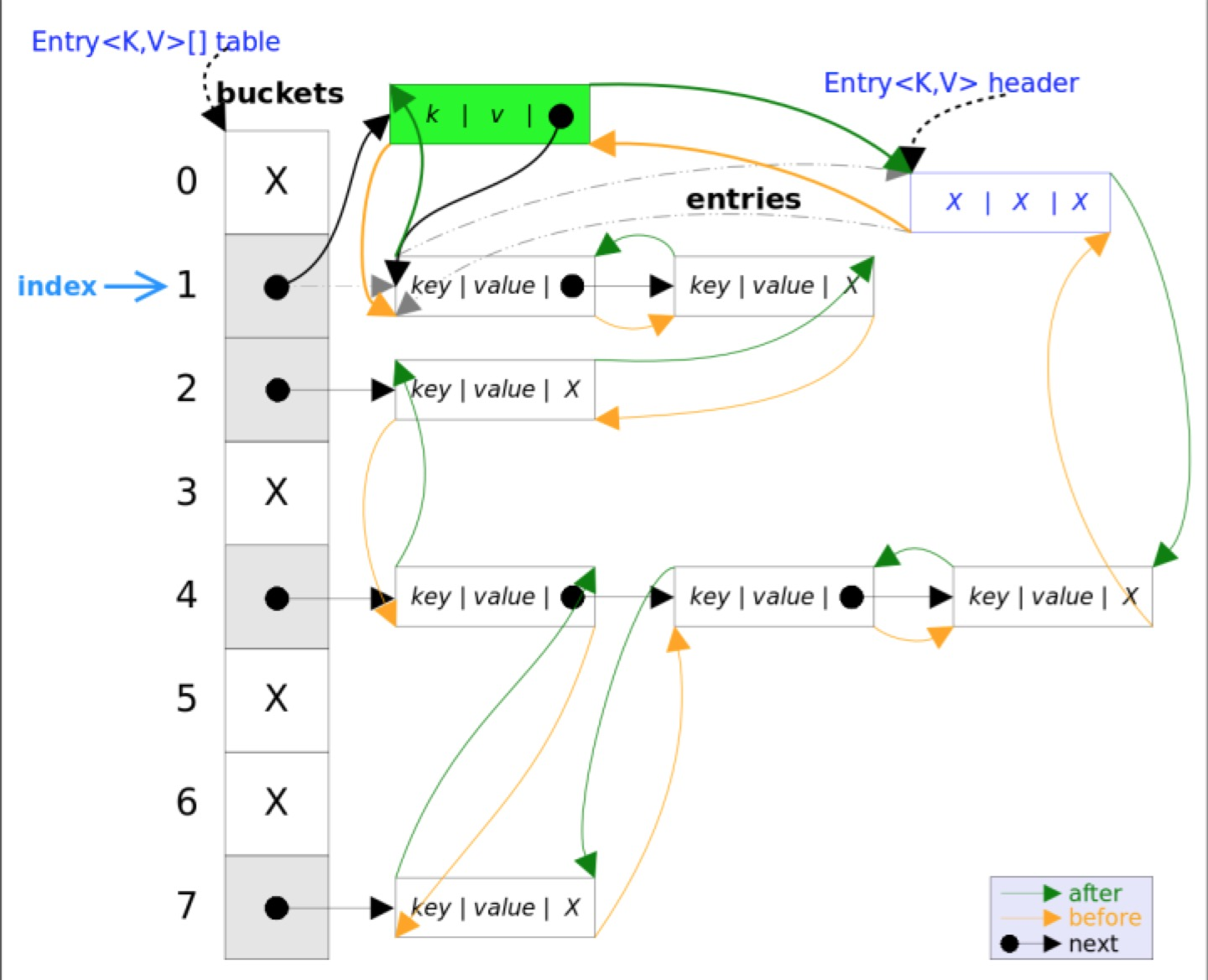
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
// last is null, indicating that the chain list has not been established
if (last == null)
head = p;
else {
// Join new node p at the end of the list
p.before = last;
last.after = p;
}
}
3.3. remove method
The purpose of remove(Object key) is to delete the entry corresponding to the key value. This method mainly implements HashMap. First, find the entry corresponding to the key value, then delete the entry (modify the corresponding reference of the chain table), the search process is similar to get() method, and then call the overridden method in LinkedHashMap to delete it!
/**HashMap Medium implementation*/
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode) {...}
else {
// Traverse the single-chain list, find the node to delete, and assign it to the node variable
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode) {...}
// Remove the node to be deleted from the single-chain list
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node); // Call the delete callback method for subsequent action
return node;
}
}
return null;
}The afterNodeRemoval method overridden in LinkedHashMap
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// Empty the precursor and subsequent references of a p-node
p.before = p.after = null;
// b is null, indicating p is the head node
if (b == null)
head = a;
else
b.after = a;
// a is null, indicating p is the tail node
if (a == null)
tail = b;
else
a.before = b;
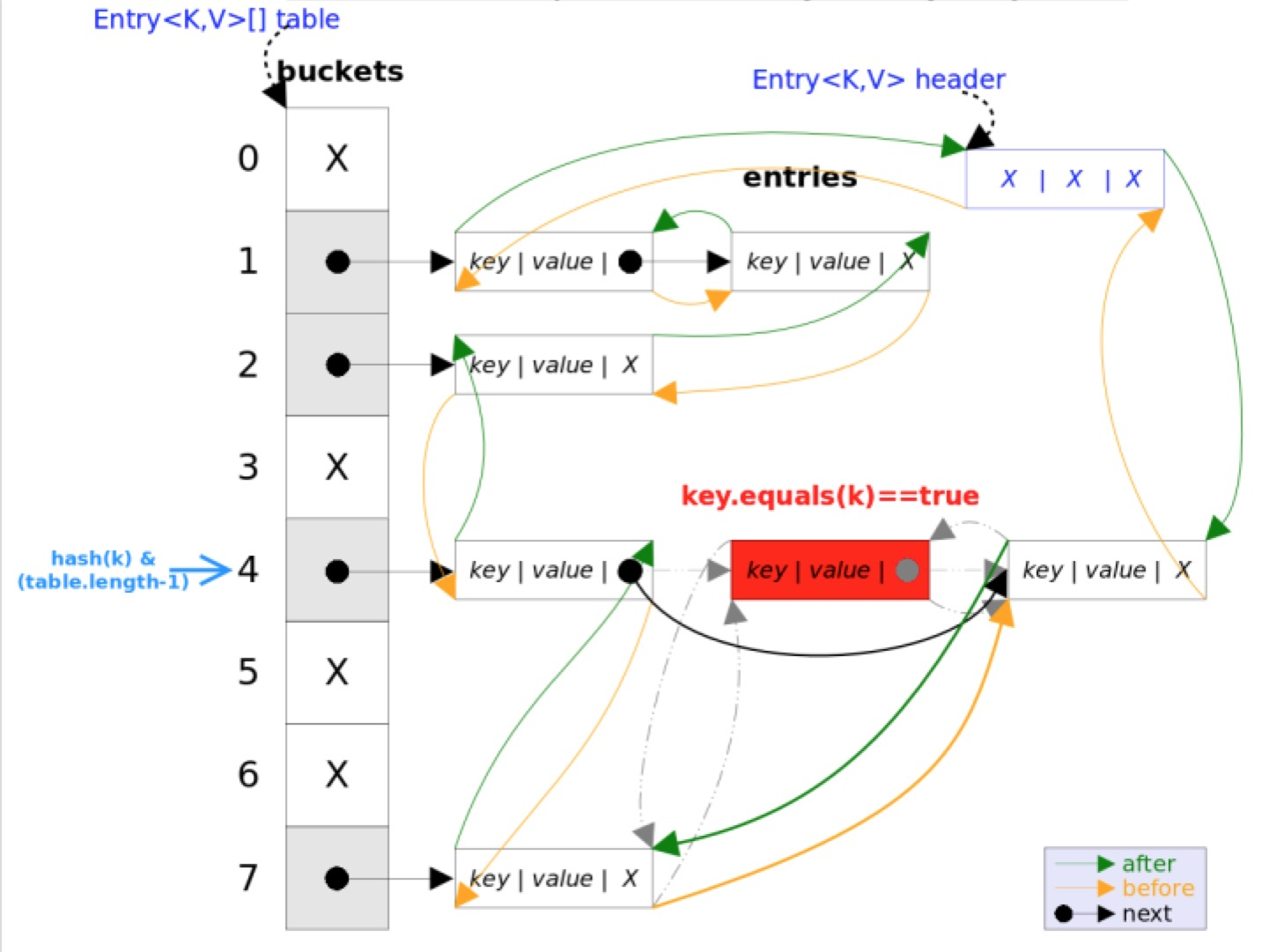
}
4. Summary
LinkedHashMap inherits from HashMap, and most of its functionality is basically the same. The only difference between them is that LinkedHashMap joins all entries in a doubly-linked list based on HashMap, so as to ensure that elements iterate in the same order as they are inserted.
The body part is exactly the same as HashMap, with more header s pointing to the head of the two-way chain table and tails pointing to the tail of the two-way Chain table. The default iteration order of the two-way chain table is the insertion order of entry.
5. Reference
1. JDK1.7&JDK1.8 Source
2,Blog Park - CarpenterLee - Java Collection Framework Source Profiling LinkedHashMap
Author: Fried Chicken Coke
Source: www.pzblog.cn