Article catalog
catalogue
3. Get praise, coin and other information
4. Get the url through bv, and then get the oid parameter
preface
I'm a freshman who just started typing code. A studio in the school arranged some examinations, and then suggested that we write a blog. This is also my first blog. I think it's very meaningful to record my learning process. I have a shallow understanding of many things. If there are mistakes, please give me more advice.
1, Climbing results:

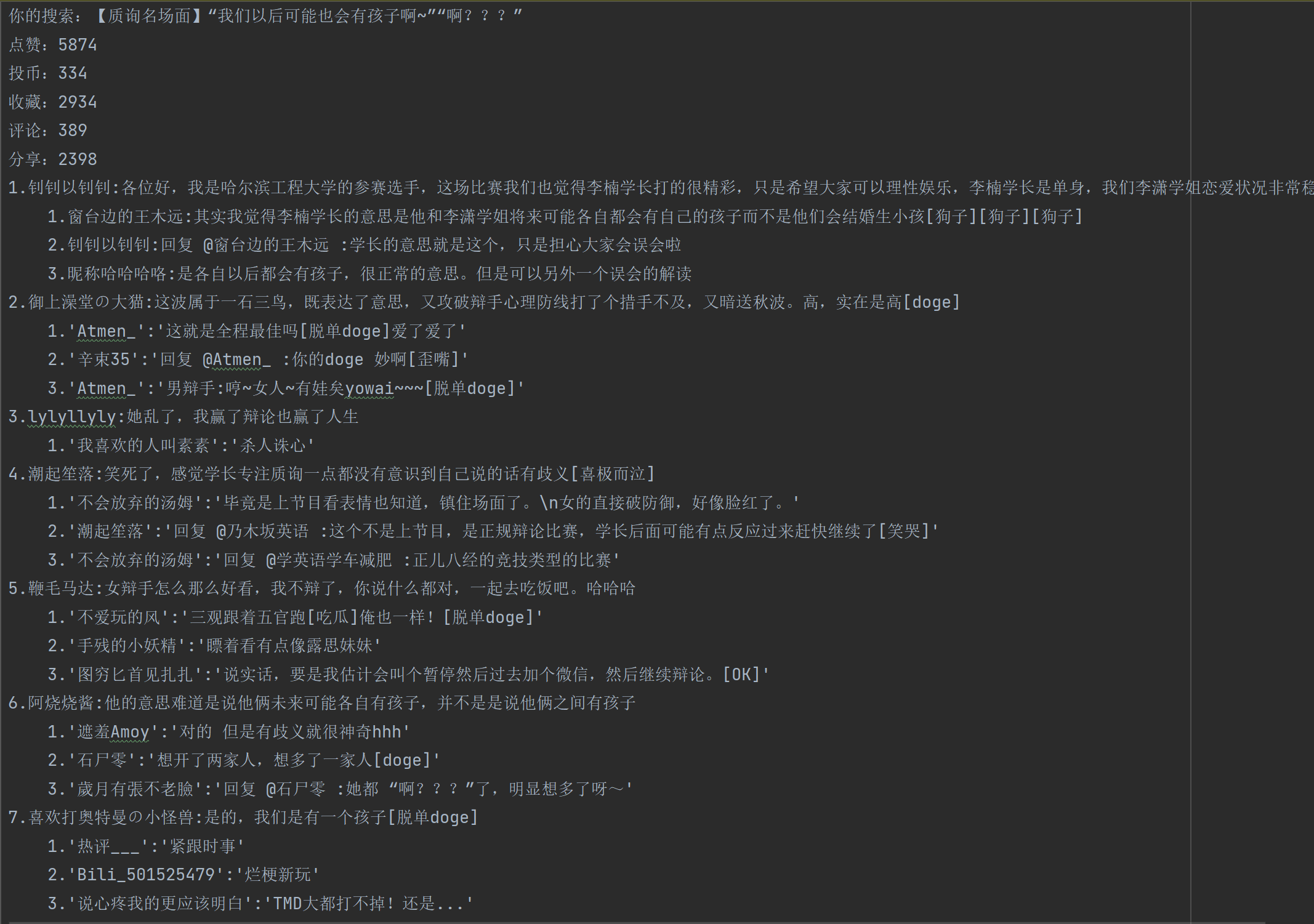
2, Train of thought
Functions realized:
By searching the video name, you can get the information such as the number of likes and coins of the video, as well as the comments of the video
General steps:
1. We can search and open the search video page through selenium, and get the bv number of the video
2. Through the bv number, we can get the url of the video, and use regular expressions to get likes, coins and other information
3. Through the packet capture tool, we can know the comment interface. Each video has different id parameters, which can be obtained through the web page source code
4. Then there is the link of capturing comments. At this time, you still need to judge whether there are top comments
3, Operation
1. Import and storage
import re import requests import json from selenium.webdriver import Chrome from selenium.webdriver.common.keys import Keys
2. Obtain bv number
def getbv(search):
browser=Chrome()
browser.get('https://Www.bilibilili. COM / '# open bilibilili
browser.maximize_window()
browser.find_element_by_tag_name('input').send_keys(f'{search}',Keys.ENTER) #Enter search and press enter
windows=browser.window_handles
browser.switch_to.window(windows[-1]) #Switch to new window
browser.find_element_by_xpath('//*[@ id = "all list"] / div [1] / div [2] / UL / Li / a '). Click() # click the first video on the page
windows = browser.window_handles
browser.switch_to.window(windows[-1]) #Switch to new window
obj=re.compile(r'video/(?P<bv>.*?)\?') #Matching bv numbers with regular expressions
bv=obj.search(browser.current_url).group('bv')
browser.close()
print('bv The number is:'+bv) #Let's see that the program got the bv number
return bv3. Get praise, coin and other information
def info(bv,search):
url="https://www.bilibili.com/video/"+bv
headers={
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"
}
resp=requests.get(url,headers=headers)
#Regular matching is used to match the like coin and other information in the source code
obj=re.compile(r'"reply":(?P<comment>.*?),"favorite":(?P<collect>.*?),"coin":(?P<coin>.*?),"share":(?P<share>.*?),"now_rank".*?"like":(?P<goods>.*?),"dislike"',re.S)
result=obj.search(resp.text)
with open('b Station comments.txt', mode='w', encoding='utf-8') as f: #Write the obtained information into the file
f.write('Your search:'+search+'\n')
f.write('give the thumbs-up:')
f.write(str(result.group('goods').strip()))
f.write('\n coin-operated:')
f.write(str(result.group('coin').strip()))
f.write('\n Collection:')
f.write(str(result.group('collect').strip()))
f.write('\n Comments:')
f.write(str(result.group('comment').strip()))
f.write('\n Share:')
f.write(str(result.group('share').strip())+'\n')
print('information get!!!') #Tell us the program has got this information
resp.close()4. Get the url through bv, and then get the oid parameter
def getoid(bv):
resp=requests.get("https://www.bilibili.com/video/"+bv)
obj=re.compile(f'"aid":(?P<id>.*?),"bvid":"{bv}"') #You can find the id in the web page source code and get it with regular
oid=obj.search(resp.text).group('id')
print('oid yes'+oid) #Tell us that the parameter oid has been obtained when the program runs
return oid5. Judge + get top comments
def gettopcomment(oid):
try: #You need to judge whether there are top comments. The return value of the function is the main comment count
#If yes, the subsequent comments are counted from 2, and 2 is returned
#If not, the subsequent comments are counted from 1, and 1 is returned
param={
"jsonp": "jsonp",
"type":1,
"oid":oid, #The oid parameter is obtained in the previous step
"next":0
}
url="https://api.bilibili.com/x/v2/reply/main"
resp=requests.get(url,params=param)
# pprint.pprint(resp.json()) #!!!!! From here, we can find information such as comments and commentators layer by layer
data=json.loads(resp.text)['data']
f=open('b Station comments.txt',mode='a',encoding='utf-8')
f.write('1.'+data['top']['upper']['member']['uname']+':'+data['top']['upper']['content']['message']+'\n')
soncount=1
if data['top']['upper']['replies']!=None:
for i in data['top']['upper']['replies']:
f.write('\t'+f'{soncount}.'+i['member']['uname']+':'+i['content']['message']+'\n')
soncount+=1
print('Top Comment get!!!!!')
return 2
except:
print('Don't comment at the top!!')
return 16. Get non top comments
def getcomment(oid,count):
try:
f=open('b Station comments.txt',mode='a',encoding='utf-8')
page = 0
while True:
parameters={
"jsonp": "jsonp",
"type":1,
"oid":oid,
"next":page #Flip parameters
}
url="https://api.bilibili.com/x/v2/reply/main"
resp=requests.get(url,params=parameters)
data=json.loads(resp.text)['data']
#The regular constructed here is a bit tricky, that is, convert the dictionary into a string, and then match it with the regular
obj=re.compile("'uname': (?P<info>.*?), 'sex':.*?'message': (?P<content>.*?), 'plat'",re.S)
for i in data['replies']:
#Here, the main comment is obtained in the same way as the top comment
f.write(f'{count}.'+i['member']['uname']+":"+i['content']['message']+'\n')
count+=1
if i['replies'] == None:continue
#There is the behavior of converting a dictionary into a string
ret=obj.finditer(str(i['replies']))
soncount=1 #This thing is a sub comment count
for j in ret:
f.write('\t'+f'{soncount}.'+j.group('info')+":"+j.group('content')+'\n')
soncount+=1
page+=1 #In the above parameter table, there are parameters for turning
except:
print('comment get!!!!')
resp.close()7. Final operation
if __name__=='__main__':
search=input('Please enter what you want get The name of the video')
bv = getbv(search)
info(bv,search)
oid = getoid(bv)
count=gettopcomment(oid)
getcomment(oid,count)Summary:
Maybe that's it. My knowledge is scarce. It's hard to explain clearly. Let's sort it out.
Please give us your advice.