preface
The experimental course content of compiling principle course experiment - constructing top-down grammar analysis program. Through this experiment, we can skillfully master the construction method of LL(1) analysis table.
1.1 experimental purpose
(1) Master the construction method of LL(1) analysis table.
(2) Master the design, compilation and debugging of typical grammar analysis programs, and further master the common grammar analysis methods.
1.2 experimental tasks
Write a grammar analysis program according to LL(1) analysis method, with unlimited language and grammar.
1.3 experimental contents
1.3.1 test requirements
Your program should be universal, be able to identify whether the lexical unit sequence obtained by lexical analysis is the correct sentence (program) of a given grammar, and be able to output the analysis process and recognition results.
1.3.2 input format
Enter a line of source code and complete the syntax analysis through one scan.
1.3.3 output format
The experiment requires that the running results of the program (including First set, Follow set and LL(1) analysis table) be printed through standard output. In addition, the LL(1) analysis table can be saved. Your program needs to output the parsing process and the corresponding analysis results (that is, whether the string is a sentence in LL(1) grammar).
1.3.4 example
Input example 1:

Output example 1:
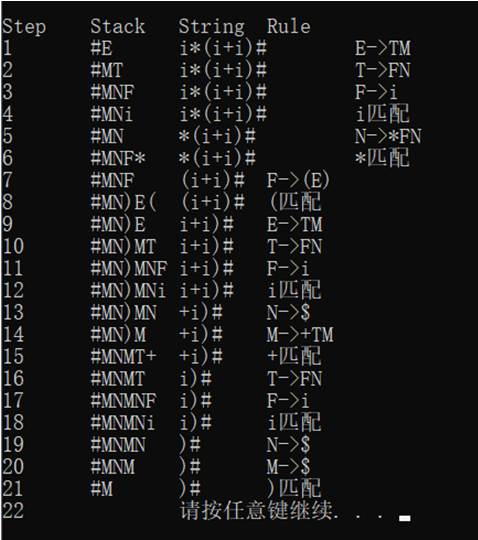
Input example 2:

Output example 2:
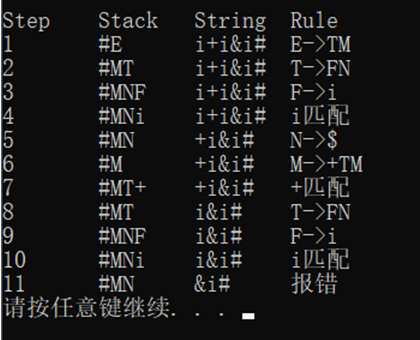
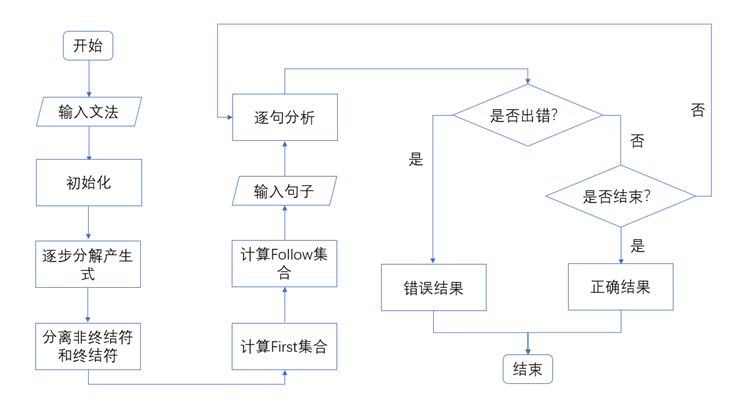
1.4 procedure
1.4.1 procedure flow chart
1.4.2 algorithm description
This LL (1) grammar analysis program only aims at the general LL (1) grammar, and can not convert a very complex non LL (1) grammar into LL (1) grammar. Because it is too complex and time is not enough, I can't realize it at present, so I can't analyze the C-language grammar. Here, I only analyze the grammar with capital letters representing non terminators. In addition, Visual Studio cannot print normally ε This represents an empty character, so another set of standards is adopted here: that is, $represents an empty string and # represents an empty character.
In the overall design idea of the program, several functions are used to calculate and output the first set, calculate and output the follow set, save and output the LL(1) analysis table, and finally use the analysis table to find the analysis process of a given input string.
First, let's talk about the method of finding the first set. The general idea is to start with the first grammar symbol on the right. If it is a terminator, it is directly added to the first set and ends. If it is a non terminator, take the non terminator as a new parameter and call the function of finding the first recursively until it meets the terminator.
For the follow set, first look at whether the symbol is followed by a terminator or a non terminator or at the end. For the terminator, directly set it as a follow set. If it is a non terminator, you need to find the first of the non terminator. If it is the end, you need to use the follow set of the left non terminator, and call the follow set function repeatedly for several times, To find the complete follow set (that is, when the follow set is no longer increased).
For the process of calculating the analysis table by inputting the symbol string, we can establish a two-dimensional array and store it in the LL (1) analysis table. Then, in the analysis process, for the symbols pointed by the pointer, according to the stack top information of the analysis stack, judge whether to move into the grammar or perform matching operation through rows and columns in the analysis table, and output the whole analysis process at the same time.
This program uses direct input to the analysis table M constructed according to the known grammar.
1.4.3 program source code
#include<iostream>
#include<cstring>
#include<cstdio>
#include<algorithm>
#include<stack>
#include<set>
#include<map>
#include <Windows.h>
#include <fstream>
#include<string>
using namespace std;
//Table array (the grammar used is the sample grammar without left recursion on page P93 of the textbook)
// i + * ( ) #
char LL1[50][50][100] = { {"->TM","null" ,"null","->TM" ,"null","null" }, //A string with a capacity of 100 characters, a total of 50 rows and 50 columns
{"null","->+TM" ,"null","null" ,"->$", "->$"},
{"->FN","null" ,"null" ,"->FN","null","null" },
{"null","->$" ,"->*FN" ,"null" ,"->$","->$" },
{"->i" ,"null","null","->(E)" ,"null","null" } };
char H[200] = "EMTNF";
char L[200] = "i+*()#";
stack<char>cmp;
int findH(char a)
{
for (int i = 0; i < 5; i++) //The corresponding non terminator was found
{
if (a == H[i])
{
return i;
}
}
return -1;
}
int findL(char b)
{
for (int i = 0; i < 6; i++) //Find the corresponding terminator
{
if (b == L[i])
{
return i;
}
}
return -1;
}
int error(int i, int cnt, int len, char p[], char str[])
{
printf("%d\t%s\t", cnt, p);
for (int q = i; q < len; q++)
{
cout << str[q];
}
printf("\t report errors\n");
return len;
}
void analyze(char str[], int len)
{
int cnt = 1; //Output Step only
int i = 0;
char p[200] = "#E "; / / special for output stack, i.e. output analysis stack
int pindex = 2;
printf("Step\tStack\tString\tRule\n");
while (i < len)
{
int x, y;
char ch = cmp.top(); //cmp is the analysis state stack and ch is the top symbol of the stack
if (ch >= 'A'&&ch <= 'Z')
{
cmp.pop(); //Out of stack
x = findH(ch); //x is the corresponding non terminator position
y = findL(str[i]); //y is the corresponding terminator position
if (x != -1 && y != -1)
{
int len2 = strlen(LL1[x][y]); //Record the length of this string
if (strcmp(LL1[x][y], "null") == 0)
{
i = error(i, cnt, len, p, str);
continue;
}
printf("%d\t%s\t", cnt, p); //Output status stack information
if (p[pindex - 1] != '#')
{
p[pindex] = '\0'; //End of string flag
pindex--;
}
if (LL1[x][y][2] != '$') //If the grammar is not empty
{
for (int q = len2 - 1; q > 1; q--)
{
p[pindex++] = LL1[x][y][q]; //Load the candidate production backward into the analysis stack
cmp.push(LL1[x][y][q]); //Load analysis stack
}
}
else
{
p[pindex] = '\0'; //Eliminate current non Terminator
pindex--;
}
for (int q = i; q < len; q++)
{
cout << str[q]; //Output remaining input string
}
printf("\t%c%s\n", ch, LL1[x][y]); //Output the production or match used
}
else
{
i = error(i, cnt, len, p, str);
continue;
///If not found, an error is reported
}
}
else //Is the terminator
{
if (ch == str[i])
{
cmp.pop(); //Direct bomb stack
printf("%d\t%s\t", cnt, p); //Output the terminator
if (ch == '#'&&str[i] == '#'/ / directly accept and return
{
printf("#\t accept \ n "");
return;
}
for (int q = i; q < len; q++) //Output the information of the remaining input string
{
cout << str[q];
}
printf("\t%c matching\n", ch);
pindex--;
p[pindex] = '\0';
i++;
}
else
{
i = error(i, cnt, len, p, str);
continue;
///Error reporting
}
}
cnt++;
}
}
//Output follow and first sets
class FF {
public:
string fileName = "productions.txt"; //Text file containing grammar rules
set<string> productions; //Production set, set will automatically sort from small to large according to the ASCII code of the initial letter
map<string, set<string>> split_productions; //Decomposed production set
set<string> Vt; //Terminator set
set<string> Vn; //Non terminator set
map<string, set<string>> first; //First set
map<string, set<string>> follow; //Follow set
void init(); //Read production from file
void splitProductions(); //Decomposition production
void findVtAndVn(); //Get terminator and non Terminator
bool isVn(string s);
bool isVt(string s);
set<string> getOneFirst(string s); //Gets the first set of a single non terminator
void getFirst(); //Gets the first set of all non terminators
void getFollow(); //Get all non terminator follow sets
void get_follow_again(); //Step 3 of finding the follow set (mainly the non terminator at the end of the grammar)
};
void FF::init() {
string line;
ifstream in(fileName);
if (in) {
//The follow ing set of grammar start symbols is put into$
getline(in, line);
productions.insert(line); //Add the production set to the first row
follow[line.substr(0, 1)].insert("$");
cout << line << endl;
while (getline(in, line)) {
productions.insert(line);
cout << line << endl;
}
}
}
void FF::splitProductions() { //Split production
int position = 0;
for (set<string>::iterator it = productions.begin(); it != productions.end(); it++) {
string temp = *it;
for (int i = 0; i < temp.length(); i++) {
position = temp.find("->"); //Find - >
string s = temp.substr(0, position); //Intercept - > previous
string ss = temp.substr(position + 2); //Intercepted - > after
set<string>sss;
string t;
for (int j = 0; j < ss.length(); j++) {
if (ss[j] == '|') { //If ss[j] = '|', there is a new production
sss.insert(t);
t = "";
}
else
{
t.append(ss.substr(j, 1));
}
}
sss.insert(t);
split_productions.insert(pair<string, set<string>>(s, sss)); //All grammars corresponding to a non terminator inserted
}
}
//Output the split elements
for (map<string, set<string>>::iterator it = split_productions.begin(); it != split_productions.end(); it++) {
cout << it->first << " ";
for (set<string>::iterator ii = it->second.begin(); ii != it->second.end(); ii++) {
cout << *ii << " ";
}
cout << endl;
}
}
void FF::findVtAndVn() {
for (set<string>::iterator it = productions.begin(); it != productions.end(); it++) {
string temp = *it;
for (int i = 0; i < temp.length(); i++) {
if (temp[i] == '-' || temp[i] == '>' || temp[i] == '|')
continue;
//Is a capital letter
if (temp[i] >= 'A' && temp[i] <= 'Z') {
//'followed by'
if (temp[i + 1] == '\'') { //This step is actually useless. I changed E 'to M and T' to N
Vn.insert(temp.substr(i, 2));
i++;
}
else {
Vn.insert(temp.substr(i, 1));
}
}
//Is the terminator
else
{
Vt.insert(temp.substr(i, 1)); //Terminator direct insertion
}
}
}
cout << "Non Terminator" << endl;
for (set<string>::iterator it = Vn.begin(); it != Vn.end(); it++) {
cout << *it << endl;
}
cout << endl;
cout << "Terminator" << endl;
for (set<string>::iterator it = Vt.begin(); it != Vt.end(); it++) {
cout << *it << endl;
}
}
bool FF::isVn(string s) {
if (Vn.find(s) != Vn.end()) {
return true;
}
return false;
}
bool FF::isVt(string s) {
if (Vt.find(s) != Vt.end()) {
return true;
}
return false;
}
set<string> FF::getOneFirst(string s) { //The algorithm is based on the recursive search idea defined by the First set
if (split_productions.count(s) > 0) {
set<string>temp = split_productions[s];
for (set<string>::iterator it = temp.begin(); it != temp.end(); it++) {
string stemp = *it;
if (stemp == "#") {
first[s].insert("#");
}
else {
int flagAll = 0; //The first set of all non terminators has #;
for (int i = 0; i < stemp.length(); i++) {
int flag = 0; //The first set of the current non terminator has #;
if (stemp[i + 1] == '\'') {//Non terminator with '
set<string>t1 = getOneFirst(stemp.substr(i, 2));
for (set<string>::iterator ii = t1.begin(); ii != t1.end(); ii++) {
if (*ii == "#") {/ / empty string cannot be inserted at this time
flag = 1;
}
else {
first[s].insert(*ii);
}
}
i++;
}
else if (isVn(stemp.substr(i, 1)))//Single non Terminator
{
set<string>t2 = getOneFirst(stemp.substr(i, 1)); //For the derivation of the first character or non terminator, recursion continues according to the non terminator
for (set<string>::iterator ii = t2.begin(); ii != t2.end(); ii++) {
if (*ii == "#") {/ / empty string cannot be inserted at this time
flag = 1;
}
else {
first[s].insert(*ii);
}
}
}
else {//Terminator
first[s].insert(stemp.substr(i, 1));
}
if (i == stemp.length() - 1 && flag == 1) {
flagAll = 1;
}
if (flag == 0)
break;
}
if (flagAll == 1) {
first[s].insert("#");
}
}
}
}
return first[s];
}
void FF::getFirst() { //Output first set contents in order
for (map<string, set<string>>::iterator it = split_productions.begin(); it != split_productions.end(); it++) {
getOneFirst(it->first);
}
cout << "First collection" << endl;
for (map<string, set<string>>::iterator it = first.begin(); it != first.end(); it++) {
cout << it->first << ": ";
for (set<string>::iterator ii = it->second.begin(); ii != it->second.end(); ii++)
{
cout << *ii << " ";
}
cout << endl;
}
}
void FF::getFollow() {
for (map<string, set<string>>::iterator it = split_productions.begin(); it != split_productions.end(); it++) {
string left = it->first;
set<string>right = it->second;
for (set<string>::iterator ii = right.begin(); ii != right.end(); ii++) {
string temp = *ii;
for (int i = 0; i < temp.length(); i++) {
if (isVt(temp.substr(i, 1))) { //Terminator has no follow set, skipping
continue;
}
else if (i + 1 < temp.length() && temp[i + 1] == '\'') {//Non terminator with '
if (isVt(temp.substr(i + 2, 1))) {//Non terminator followed by Terminator
follow[temp.substr(i, 2)].insert(temp.substr(i + 2, 1));
i++;
}
else {//Non terminator followed by non terminator s
//Add the first set ff of the following non terminator to the follow set
string s;
if (i + 3 < temp.length() && temp[i + 3] == '\'') {
s = temp.substr(i + 2, 2);
}
else {
s = temp.substr(i + 2, 1);
}
set<string> ff = first[s];
for (set<string>::iterator nn = ff.begin(); nn != ff.end(); nn++) {
if (*nn != "#")
follow[temp.substr(i, 2)].insert(*nn);
}
}
}
else {//Non terminator without '
if (i + 1 < temp.length() && isVt(temp.substr(i + 1, 1))) { //Non terminator followed by Terminator
follow[temp.substr(i, 1)].insert(temp.substr(i + 1, 1));
i++;
}
else {//Non terminator followed by non terminator s
//Add the first set ff of the following non terminator to the follow set
string s;
if (i + 2 < temp.length() && temp[i + 2] == '\'') {
s = temp.substr(i + 1, 2);
}
else {
s = temp.substr(i + 1, 1); //The following non terminator was found
}
set<string> ff = first[s]; //Add the follow set of the non terminator
for (set<string>::iterator nn = ff.begin(); nn != ff.end(); nn++) {
if (*nn != "#")
follow[temp.substr(i, 1)].insert(*nn);
}
}
}
}
}
}
//This one needs to be carried out several times, because follow is growing
get_follow_again();
get_follow_again();
cout << "Follow collection" << endl;
for (map<string, set<string>>::iterator it = follow.begin(); it != follow.end(); it++) {
cout << it->first << ": ";
for (set<string>::iterator ii = it->second.begin(); ii != it->second.end(); ii++)
{
cout << *ii << " ";
}
cout << endl;
}
}
void FF::get_follow_again() {
for (map<string, set<string>>::iterator it = split_productions.begin(); it != split_productions.end(); it++) {
string left = it->first;
set<string>right = it->second;
for (set<string>::iterator ii = right.begin(); ii != right.end(); ii++) {
string temp = *ii;
for (int j = temp.length() - 1; j > 0; j--) { //Check upside down
string now;
if (temp[j] == '\'') {
now = temp.substr(j - 1, 2);
j--;
}
else now = temp.substr(j, 1);
if (isVt(now)) {//The production ends with a terminator
break;
}
else {//The production ends with a non terminator
set<string>aa = follow[left]; //Finally, the non terminator. You need to put the part of the left non terminator here.
for (set<string>::iterator pp = aa.begin(); pp != aa.end(); pp++) {
follow[now].insert(*pp);
}
}
if (first[now].find("#") == first[now].end())
break;
}
}
}
}
int main()
{
//cout<<H[0]<<H[4]<<endl;
//cout<<L[0]<<L[5]<<endl;
/*for(int i = 0; i < 5; i++)
{
for(int j = 0 ; j < 6; j++)
printf("%5s",LL1[i][j]);
cout<<endl;
}*/
FF ff;
ff.init();
ff.splitProductions();
cout << endl;
ff.findVtAndVn();
cout << endl;
ff.getFirst();
cout << endl;
ff.getFollow();
cout << endl;
cout << "Please enter the sentence to be analyzed:" << endl;
char str[200];
cin >> str;
cout << endl;
//Output analysis table (since this program adopts the form of direct input of known analysis table, it only needs to output analysis table directly)
cout << "LL(1)Analysis table:" << endl;
ifstream infile("LL(1).txt");
string ans;
while (infile.good())
{
getline(infile, ans);
cout << ans << endl;
}
infile.close();
cout << endl;
int len = strlen(str);
cmp.push('#');
cmp.push('E');
analyze(str, len + 1);
return 0;
}
1.5 summary
Among them, the most difficult problem I encountered was the basic data structure construction and the solution algorithm of the first set, because the first set needed to be solved by recursion (recursion is really painful forever). Although the idea was about, I didn't knock out the running algorithm for a long time. Finally, I realized this function by relying on the algorithm of the boss on csdn.