Depth residual network
Innovation of deep residual network?
- Based on the ultra deep network structure, the Residule structure is proposed
- Batch Normalization is used to make our batch feature map the same dimension,
It meets the distribution law with mean value of 0 and variance of 1.. - 1X1 dimension lifting structure is added to the residual block to greatly reduce the ultra deep network parameters. inception structure.
Degradation problem: with the deepening of network depth, gradient disappearance and gradient explosion will occur
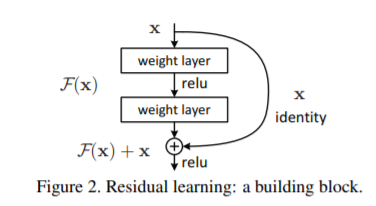
The structure of residual network is shown in the figure
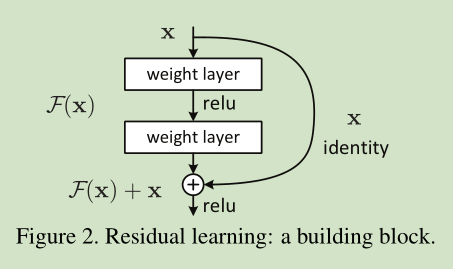
Different from the previous network structure, a fast channel is added to sum the input and output (original). The network layer relationship mapping is H(x), and the residual network fits another mapping, F(x):= H(x)-x, then the original mapping is F(x)+x. Optimizing the residual mapping F(x) is easier than optimizing the original mapping H(x). It is equivalent to eliminating redundant features and leaving unique features, so as to better realize classification.
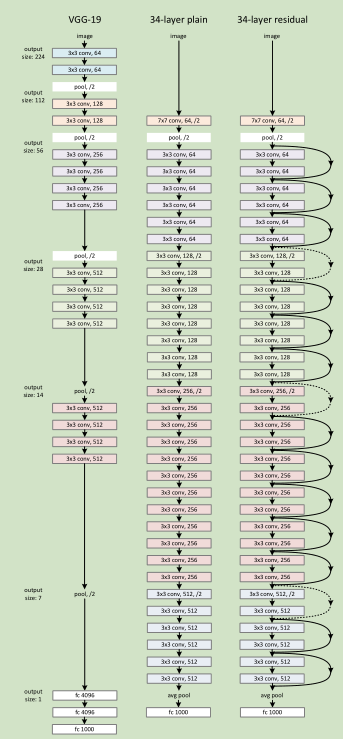
Example: overall structure diagram of 34th floor:
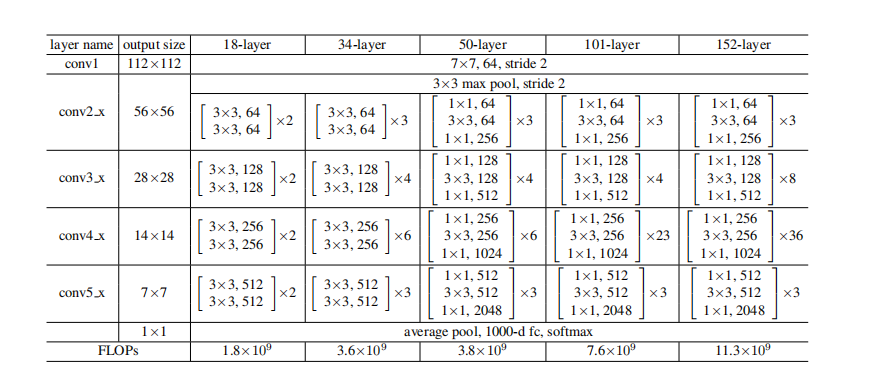
Small components in residual network
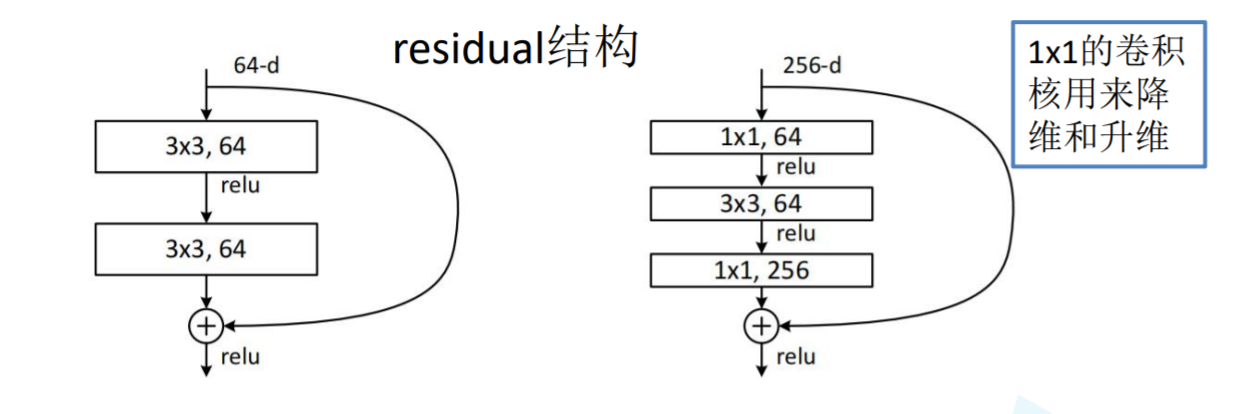
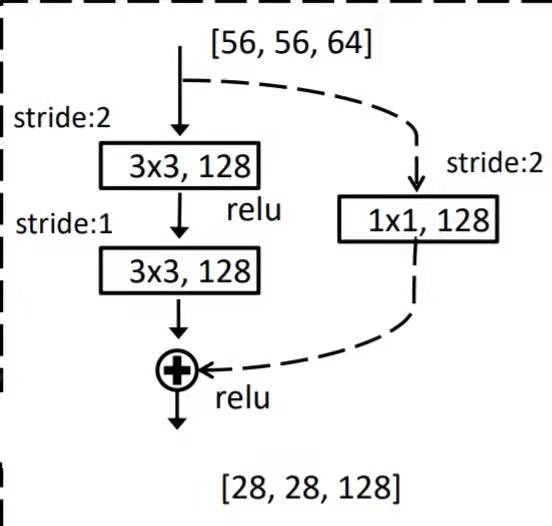
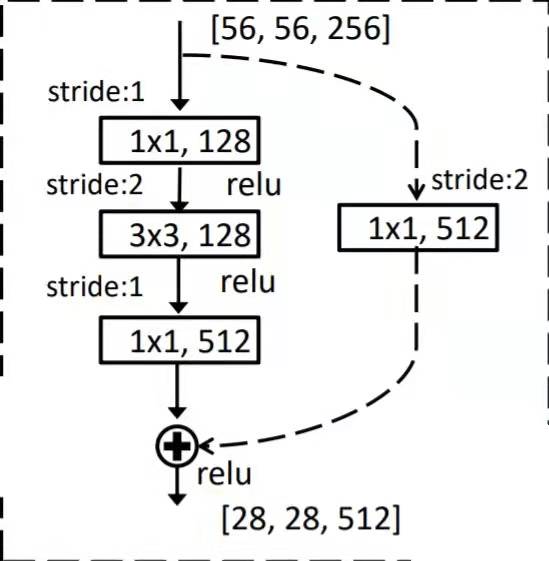
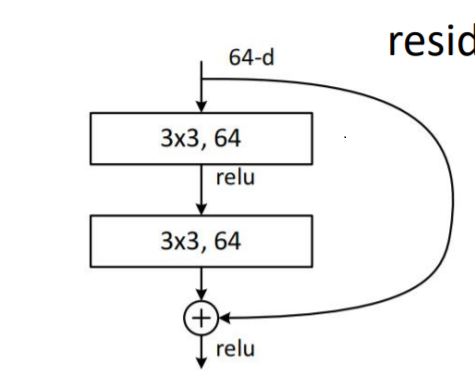
The structure is relatively simple, and the code can be stacked.
import torch.nn as nn
import torch
#This structure is a residual structure without dotted lines,
class BasicBlock(nn.Module):
expansion=1
#This module is a 34 layer and 18 layer network, which does not involve 1x1 dimensionality reduction and elevation, but only the convolution of 3x3 convolution kernel layer
18th and 34th floors
super(BasicBlock,self).__init__()
self.conv1=nn.Conv2d(in_channels=in_channel,out_channels=out_channel,kernel_size=3,stride=stride,padding=1,bias=False)
#The structure is that the input and output remain the same size
self.bn1=nn.BatchNorm2d(out_channel)
self.relu=nn.ReLU()
self.conv2=nn.Conv2d(in_channels=out_channel,out_channels=out_channel,kernel_size=3,stride=1,padding=1,bias=False)
#The structure is that the input and output remain the same size
self.bn2=nn.BatchNorm2d(out_channel)
self.downsampel=downsample
def forward(self,x):
identity=x
if self.downsample is not None:
identity=self.downsample(x)
out=self.conv1(x)
out=self.bn1(out)
out=self.relu(out)
out=self.con2(out)
out=self.bn2(out)
out+=identity
out=self.relu(out)
return out
class Bottleneck(nn.Module):
#Dashed residual branch
expansion=4
def__init__(self,in_channel,out_channel,stride=1,downsample=None,group=1,width_per_group=64):
super(Bottleneck,self)__init__()
width=int(out_channel*(width_per_group/64.))*groups
self.conv1=nn.Conv2d(in_channels=in_channel,out_channels=width,kernel_size=1,stride=1,bias=False)
self.bn1=nn.BatchNorm2d(width)
self.conv2=nn.Conv2d(in_channels=width,out_channels=width,groups=groups,kernel_size=3,stride=stride,bias=False,padding=1)
self.bn2=nn.BatchNorm2d(width)
self.conv3=nn.Conv2d(in_channels=width,out_channels_out_channel*self.expansion,kernel_size=1,stride=1,bias=False)
self.bn3=nn.BatchNorm2d(out_channel*self.expansion)
self.relu=nn.ReLU(inplace=True)
self.downsample=downsample
def forward(self,x):
identity=x
if self.downsample is not None:
identity=self.downsample(X)
#This structure is a fast track, with an added dimension of 1 * 1. It is not available in the 34th floor, and others are available
out=self.conv1(x)
out=self.bn1(out)
out=self.relu(out)
out=self.conv2(out)
out=self.bn2(out)
out=self.relu(out)
out=self.conv3(out)
out=self.bn3(out)
out+=identity
out=self.relu(out)
return out
class ResNet(nn.Module):
def__init__(self,block,block_num,num_classes=1000,include_top=True,group=1,width_per_group=64):
super(ResNet,self).__init__()
self.include_top=include_top
self.in_channel=64
self.groups=groups
self.width_per_group=width_per_group
self.conv1=nn.Conv2d(3,self.in_channel,kernel_size=7,stride=2,padding=3,bias=False)
self.bn1=nn.BatchNorm2d(self.in_channel)
self.relu=nn.ReLU(inplace=True)
self.maxpool=nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
self.layer1=self._make_layer(block,64,block_num[0])
self.layer2=self._make_layer(block,128,blocks_num[1],stride=2)
self.layer3=self._make_layer(block,256,blocks_num[2],stride=2)
self.layer4=self._make_layer(block,512,block_num[3],stride=2)
if self.include_top:
self.avgpool=nn.AdaptiveAvgPool2d((1,1))
self.fc=nn.Linear(512*block.expansion,num_classes)
for m in self.module():
if isinstance(m,nn.Conv2d):
nn.init.kaimin_normal_(m.weight,mode='fan_out',nonlinearity='relu')
def _mak_layer(self,block,channel,block_num,stride=1):
downsample=None
if stride1=1 or self.in_channel!=channel*block.expansion:
downsample=nn.Sequential(
nn.Conv2d(self.in_channel,channel*block.expansion,kernel_size=1,stride=stride,bias=False),
nn.BatchNorm2d(channel*block.expansion)
layers=[]
layers.append(block(self.in_channel,channel,
downsample=downsample,
stride=stride,
groups=slef.groups
width_per_group=self.width_per_group))
self.in_channel=channel*block.expansion
#Personally, I think layer 34 is OK, but layer 50 input channel and output channel are not reasonable
for _ in range(1,block_num):
layers.append(block(self.in_channel,channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self,x):
x=self.conv1(x)
x=self.bn1(x)
x=self.relu(x)
x=self.maxpool(x)
x=self.layer1(x)
x=self.layer2(x)
x=self.layer3(X)
x=self.layer4(x)
if self.include_top:
x=self.avgpool(x)
x=torch.flatten(x,1)
x=self.fc(x)
return x
def resnet34(num_classes=1000,include_top=True):
return ResNet(BasicBlock,[3,4,6,3],num_classes=num_classes,include_top=include_top)
def resnet50(num_classes=1000,include_top=True):
return ResNet(Bottleneck,[3,4,6,3],num_classes=num_classes,include_top=include_top)
def resnet101(num_classes=1000,include_top=True):
return ResNet(Bottleneck,[3,4,23,3],num_classes=num_classes,include_top=include_top)
def resnext50_32x4d(num_classes=1000,include_top=True):
groups=32
width_per_group=4
return ResNet(Bottleneck,[3,4,6,3],
num_classes=num_classes,
include_top=include_top,
group=group,
width_per_group=width_per_group)
def resnext101_32x8d(num_classes=1000,include_top=True):
groups=32
width_per_group=8
return ResNet(Bottleneck,[3,4,23,3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
Training model
Basic process of code training:
-
Import package
1.1 basic torch, torch nn,torch.optim some related layers, optimizer.
1.2 training data preprocessing in torchvision transforms
1.3 training dataset processing datasets image reading and processing ImageFolder.
1.3 import model package from model import resnet34
1.4 read address and file import os import json -
Get training equipment
device=torch.device("cuda:0" if cuda.is_available() else "cpu") -
Training data and validation data preprocessing transforms compose
train
3.1 normalization, transforms Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
3.2 cutting, transforms RandomResizedCrop(224)
3.3 horizontal inversion, transformations RandomHorizontalFlip()
3.4 totensor ,transforms.ToTensor()
test
3.1 readjustment, transformations Resize(224)
3.2 central shear, transforms CenterCrop()
3.3 normalization, transforms Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
3.4 transforms ToTensor()
data_transform={
"train":transforms.Compose([transfoms.RandomResizedCrop(224),
transforms.RandomHorizontalFilp(),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
])
"val":transforms.Compose([transforms.Resize(),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
])
} -
Read picture datasets The imagefolder parameters are root and transforms
train_dataset=datasets.ImageFolder(root=os.path.join(image_path,"train"),transforms= data_transforms["train"]) -
According to the read train_data, to become a dataloader, is to become batch data
train_loader=torch.util.data.DataLoader(train_data,bach_size=bach_size,shuffle=True,num_workers=nw)
After the training data is acquired and processed, it is loaded into the network for training -
net=resnet34()
-
Load weights, use migration learning
model_weight_path="./resnet34.pth"
net.load_state_dict(torch.load(model_weight_path,map_location=device)) -
Define loss function
loss_function=nn.CrossEntropyLoss() -
The optimizer passes in the parameters to be optimized
params=[p for p in net.parameters() if p.requires_grad]
optimizer=optim.Adam(param,lr=0.001) -
Start training, number of training rounds, excellent weight maintenance address, verify each training batch
Tqdm is a fast and extensible Python progress bar. You can add a progress prompt in the python long loop. Users only need to encapsulate any iterator tqdm(iterator).
net.train()
Optimizer zeroing
optimizer.zero_grad() -
Forward propagation
logits=net(image.to(device)) -
Calculation loss error
loss=loss_function(logits,labels.to(device)) -
Back propagation
loss.backward() -
Parameter update
optimizer.step() -
data validation
net.eval() -
According to the obtained results, the accuracy is calculated
predict_y=torch.max(outputs,dim=1)[1]
acc+=torch.eq(predict_y,val_labels.to(device)).sum().item() -
Save excellent weights
if val_accurate>best_acc:
best_accurate=best_acc
torch.save(net.state_dict(),save_path)
Complete the test
Batch prediction is performed according to the weight saved in the previous step. Batch prediction is batch forward propagation
import os
import json
import torch
from PIL import Image
from torchvision import transforms
from model import resnet34
def main():
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform=transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
])
imgs_root="/.data/imgs"
#Batch folder
assert os.path.exists(imgs_root),f"file:'{imgs_root}'dose not exist."
img_path_list=[os.path.json(imgs_root,i) for i in os.listdir(imgs_root) if i.endswith(".jpg")]
json_path='./class_indices.json'
assert os.path.exists(json_path).f"file:'{json_path}' dose not exist."
json_file=open(json_path,"r")
class_indict=json.load(json_file)
model=resnet34(num_classes=5).to(device)
weights_path="./resnet34.pth"
assert os.path.exists(weight_path).f"file:'{weight_path}'dose not exist."
model.loade_state_dict(torch.load(weights_paht,map_location=device))
model.eval()
batch_size=8
with torch.no_grad():
for ids in range(0,len(image_path_list)//bath_size):
img_list=[]
for img_path in img_path_list[ids*batch_size:(ids+1)*batch_size]:
assert os.path.exists(img_path),f"file":'{img_path}'dose not exist."
img=Image.ipen(img_path)
img=data_transform(img)
img_list.append(img)
batch_img=torch.stack(img_list,dim=0)#pack
output=model(batch_img.to(device)).cpu()
predict=torch.softmax(output,dim=1)
probs,classes=torch.max(predict,dim=1)
Accuracy
for idx,(pro,cla) in enumerate(zip(probs,classes)):
print('image:{} class:{} prob:{:.3}'.format(img_path_list[ids *batch_size+idex],class_indict[str(cla.numpy())],pro.numpy())
if __name__=='__main__':
main()