I process
Process is a running activity of a computer program on a data set. It is the basic unit for resource allocation and scheduling of the system and the basis of the structure of the operating system. In the early computer structure of process oriented design, process is the basic executive entity of program; In the contemporary computer architecture of thread oriented design, process is the container of thread. Program is the description of instructions, data and their organizational form, and process is the entity of program.
- Program: a pile of code (dead)
- Process: running program (Live)
Note: if the same program is executed twice, two processes will appear in the operating system, so we can run a software at the same time and do different things separately without confusion.
Process scheduling
In order to run multiple processes alternately, the operating system must schedule these processes. This scheduling is not carried out immediately, but needs to follow certain rules, so there is a process scheduling algorithm.
First come first serve (FCFS) scheduling algorithm
First come, first served( FCFS)Scheduling algorithm is the simplest scheduling algorithm, which can be used for job scheduling and process scheduling. FCFS Algorithm comparison is beneficial to long jobs (processes), but not to short jobs (processes). It can be seen that this algorithm is suitable for CPU Busy operation, not conducive to I/O Busy jobs (processes).
Short job first scheduling algorithm
Short job (process) priority scheduling algorithm( SJ/PF)It refers to the priority scheduling algorithm for short jobs or short processes. The algorithm can be used for both job scheduling and process scheduling. However, it is unfavorable to long-term operation; Cannot ensure that urgent operations (processes) are handled in time; The length of the assignment is only estimated.
time-slice Round-robin method
Time slice rotation(Round Robin,RR)The basic idea of the method is to make the waiting time of each process in the ready queue proportional to the time of enjoying the service. In the time slice rotation method, you need to CPU The processing time is divided into fixed size time slices, for example, tens of milliseconds to hundreds of milliseconds. If a process runs out of the time slice specified by the system after being selected by the scheduler, but fails to complete the required task, it will release its own time slice CPU And wait for the next scheduling at the end of the ready queue. At the same time, the process scheduler schedules the first process in the current ready queue.
Obviously, the rotation method can only be used to schedule and allocate some resources that can be preempted. These resources that can be preempted can be deprived at any time, and they can be redistributed to other processes. CPU It is a kind of preemptive resources. However, resources such as printers cannot be preempted. Because job scheduling is right except CPU The allocation of all system hardware resources, including non preemptible resources, so the job scheduling does not use the rotation method.
In the rotation method, the selection of time slice length is very important. Firstly, the choice of time slice length will directly affect the system overhead and response time. If the time slice length is too short, the number of times the scheduler preempts the processor increases. This will greatly increase the number of process context switching, thus increasing the system overhead. Conversely, if the time slice length is too long, for example, a time slice can ensure that the process with the longest execution time in the ready queue can be completed, the rotation method becomes the first come first serve method. The selection of time slice length is determined according to the system's response time requirements and the maximum number of processes allowed in the ready queue.
In the rotation method, there are three situations for processes added to the ready queue:
One is that the time slice allocated to it runs out, but the process has not been completed. It returns to the end of the ready queue and waits for the next scheduling to continue execution.
Another situation is that the time slice allocated to the process is not used up, just because of the request I/O Or blocked due to mutual exclusion and synchronization of processes. When the blocking is released, it returns to the ready queue.
The third case is that the newly created process enters the ready queue.
If these processes are treated differently and given different priorities and time slices, intuitively, the service quality and efficiency of the system can be further improved. For example, we can divide the ready queue into different ready queues according to the type of process arriving at the ready queue and the blocking reason when the process is blocked FCFS In principle, the processes in each queue enjoy different priorities, but the priorities in the same queue are the same. In this way, when a process is awakened from sleep and created after executing its time slice, it will enter a different ready queue.
Multilevel feedback queue
The various algorithms used for process scheduling described above have certain limitations. For example, the short process first scheduling algorithm only takes care of the short process and ignores the long process. If the length of the process is not specified, the short process first and the preemptive scheduling algorithm based on the process length will not be used. The multi-level feedback queue scheduling algorithm does not need to know the execution time of various processes in advance, and can also meet the needs of various types of processes. Therefore, it is recognized as a better process scheduling algorithm. In the system using multi-level feedback queue scheduling algorithm, the implementation process of the scheduling algorithm is as follows. (1) Multiple ready queues shall be set and each queue shall be given different priority. The priority of the first queue is the highest, followed by the second queue, and the priority of other queues is reduced one by one. The size of the execution time slice given by the algorithm to the processes in each queue is also different. In the queue with higher priority, the smaller the execution time slice specified for each process. For example, the time slice of the second queue is twice as long as that of the first queue i+1 The time slice of the first queue is longer than that of the second queue i The time slice of a queue is twice as long. (2) When a new process enters memory, first put it at the end of the first queue and press FCFS In principle, queue for scheduling. When it is the turn of the process to execute, if it can be completed within the time slice, it can be ready to evacuate the system; If it does not complete at the end of a time slice, the scheduler moves the process to the end of the second queue and press the same FCFS In principle, wait for dispatching execution; If it does not complete after running a time slice in the second queue, it will be put into the third queue in turn,... If this goes on, it will be a long job(process)From the first queue to the second queue n After the queue, on the n The queue is rotated by time slice. (3) Only when the first queue is idle, the scheduler schedules the process in the second queue to run; Only if the first~(i-1)When all queues are empty, the second queue will be scheduled i Processes in the queue are running. If the processor is in session i When a process is served in the queue, a new process enters the queue with higher priority(first~(i-1)Any queue in),At this time, the new process will preempt the processor of the running process, that is, the scheduler will put the running process back to the second processor i At the end of the queue, the processor is assigned to the newly arrived high priority process.
Parallelism and concurrency of processes
Parallel: parallel refers to the simultaneous execution of both. For example, in a race, two people are running forward continuously; (sufficient resources, such as three threads and four core CPU)
Concurrency: concurrency means that when resources are limited, the two use resources alternately. For example, only one person can pass through a section of Road (single core CPU resources). After a goes for a section, a gives it to B, and B continues to use it to A. The purpose is to improve efficiency.
difference:
Parallelism is from the micro level, that is, in a precise moment of time, there are different programs executing, which requires multiple processors.
From a macro perspective, concurrency is executed at the same time in a time period. For example, a server processes multiple session s at the same time.
Synchronous asynchronous blocking non blocking
Status introduction
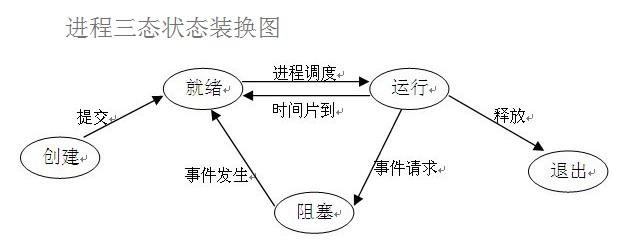
Before we understand other concepts, we first need to understand several states of the process. In the process of program running, due to the control of the scheduling algorithm of the operating system, the program will enter several states: ready, running and blocking.
(1) ready status
When the process has allocated all necessary resources except CPU, it can be executed immediately as long as the processor is obtained. The process state at this time is called ready state.
(2) execution / Running state when the process has obtained the processor and its program is executing on the processor, the process state at this time is called execution state.
(3) in the blocked state, when the executing process is unable to execute due to waiting for an event, it abandons the processor and is in the blocked state. There can be many kinds of events that cause process blocking, such as waiting for I/O to complete, the application buffer cannot be satisfied, waiting for a letter (signal), etc.

Synchronous and asynchronous
Describes how a task is submitted
Synchronization means that when the completion of a task depends on another task, the dependent task can be completed only after the dependent task is completed. This is a reliable task sequence. Either success or failure, and the states of the two tasks can be consistent.
The so-called asynchrony does not need to wait for the dependent task to be completed. It just notifies the dependent task of what work to complete, and the dependent task will be executed immediately. As long as you complete the whole task, it will be completed. As for whether the dependent task is actually completed in the end, the task that depends on it cannot be determined, so it is an unreliable task sequence
example:
For example, when I go to the bank to handle business, there may be two ways: The first one: queue up; Second: choose to take a small note with my number on it. When I get to my number, the person at the counter will inform me that it's my turn to handle business; First: the former(queue up)That is to wait for message notification synchronously, that is, I have to wait for the bank to handle business all the time; Second: the latter(Wait for someone else to inform)Is to wait for message notification asynchronously. In asynchronous message processing, waiting for a message notifier(In this case, it is the person waiting for business)A callback mechanism is often registered and triggered when the waiting event is triggered(Here is the man at the counter)Through some mechanism(Here is the number written on the small note. Shout)Find the person waiting for the event.
Blocking and non blocking
Used to describe the execution status of a task
The concepts of blocking and non blocking are related to the state of a program (thread) waiting for a message notification (not synchronous or asynchronous). In other words, blocking and non blocking are mainly from the perspective of the state of the program (thread) waiting for message notification
example:
Continue with the above example, whether queuing or using a number to wait for notification, if in the process of waiting, the waiting person can't do anything other than waiting for message notification, then the mechanism is blocked and manifested in the program,That is, the program has been blocked in the function call and cannot continue to execute. On the contrary, some people like to wait while making phone calls and sending text messages when the bank handles these businesses. This state is non blocking because it is not blocked(Waiting person)Instead of blocking this message, I waited while doing my own thing. Note: the synchronous non blocking form is actually inefficient. Imagine you need to look up while you are on the phone to see if you are in line. If calling and observing the queue position are regarded as two operations of the program, the program needs to switch back and forth between these two different behaviors, and the efficiency can be imagined to be low; The asynchronous non blocking form does not have such a problem, because it is you who make the call(Waiting person)It's the counter that informs you(Message trigger mechanism)The program does not switch back and forth between two different operations.
Create process
multiprocess module
In detail, multiprocess is not a module, but a package for operating and managing processes in python. The reason why it is called multi is the meaning of multi-function from multiple. This package contains almost all sub modules related to the process. Due to the large number of sub modules provided, in order to facilitate your classification and memory, I roughly divide this part into four parts: creating process part, process synchronization part, process pool part and data sharing between processes.
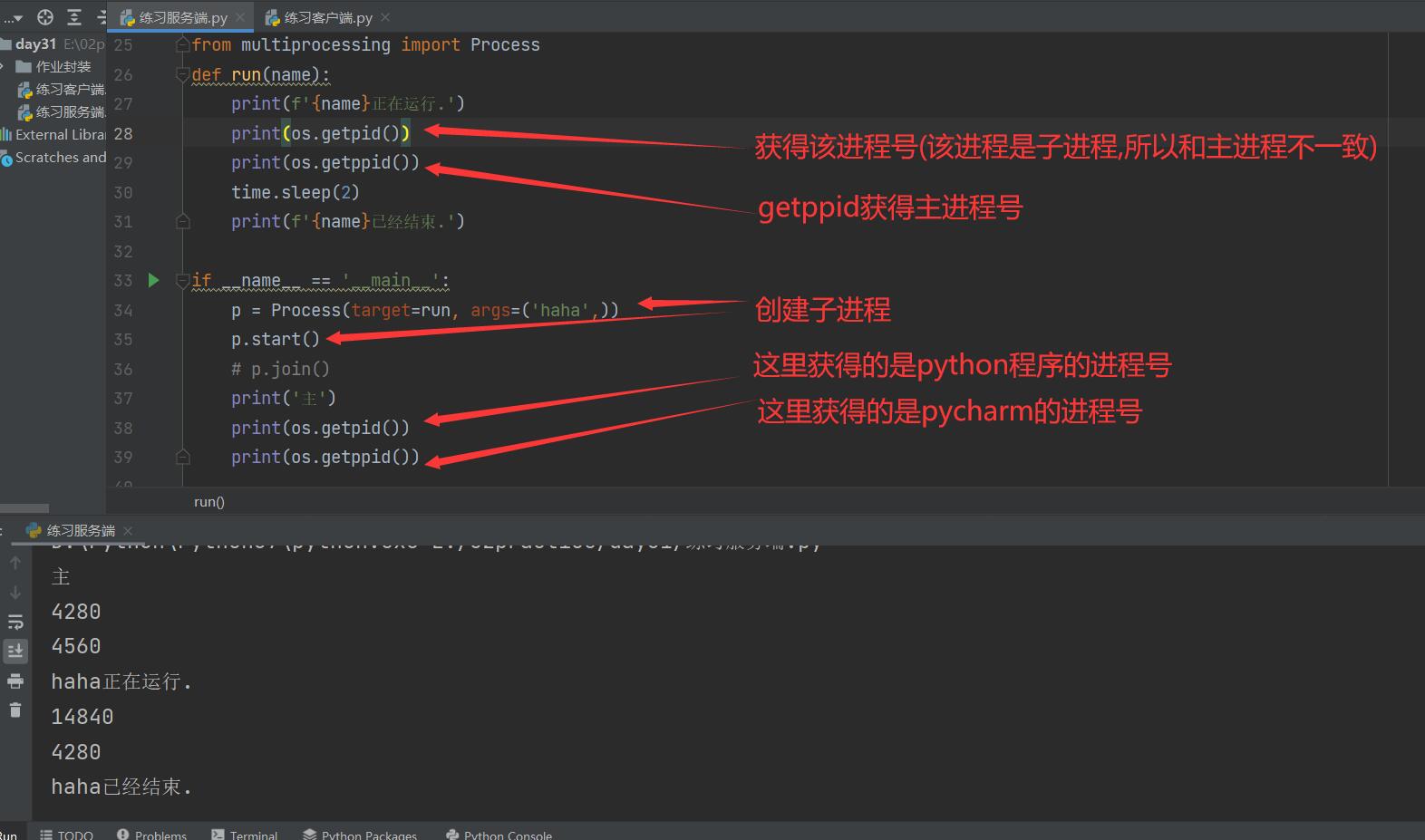
from multiprocessing import Process
def run(name):
print(f'{name}Running.')
time.sleep(3)
print(f'{name}It's already over..')
if __name__ == '__main__':
p = Process(target=run, args=('jason',))
p.start() # Build child process
p.join()
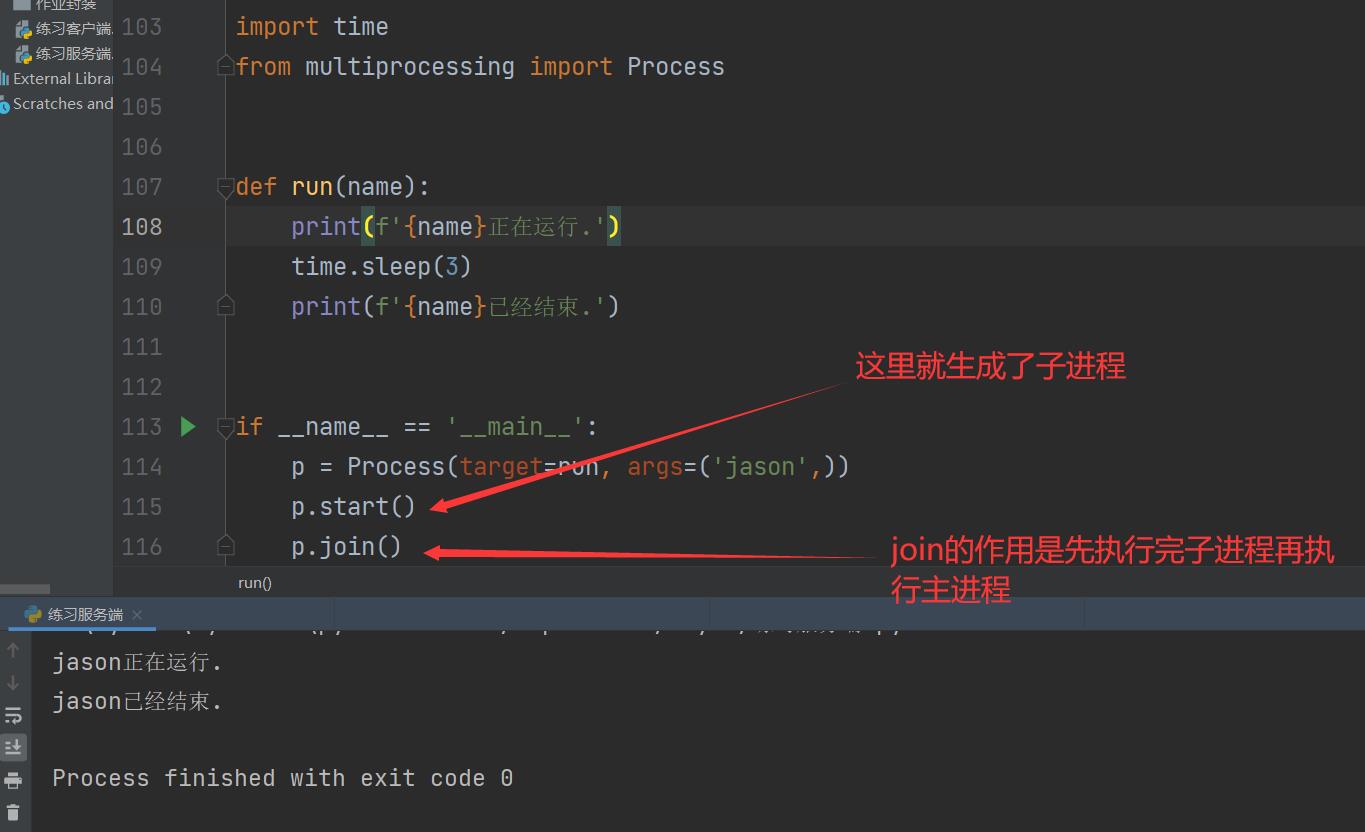
join method
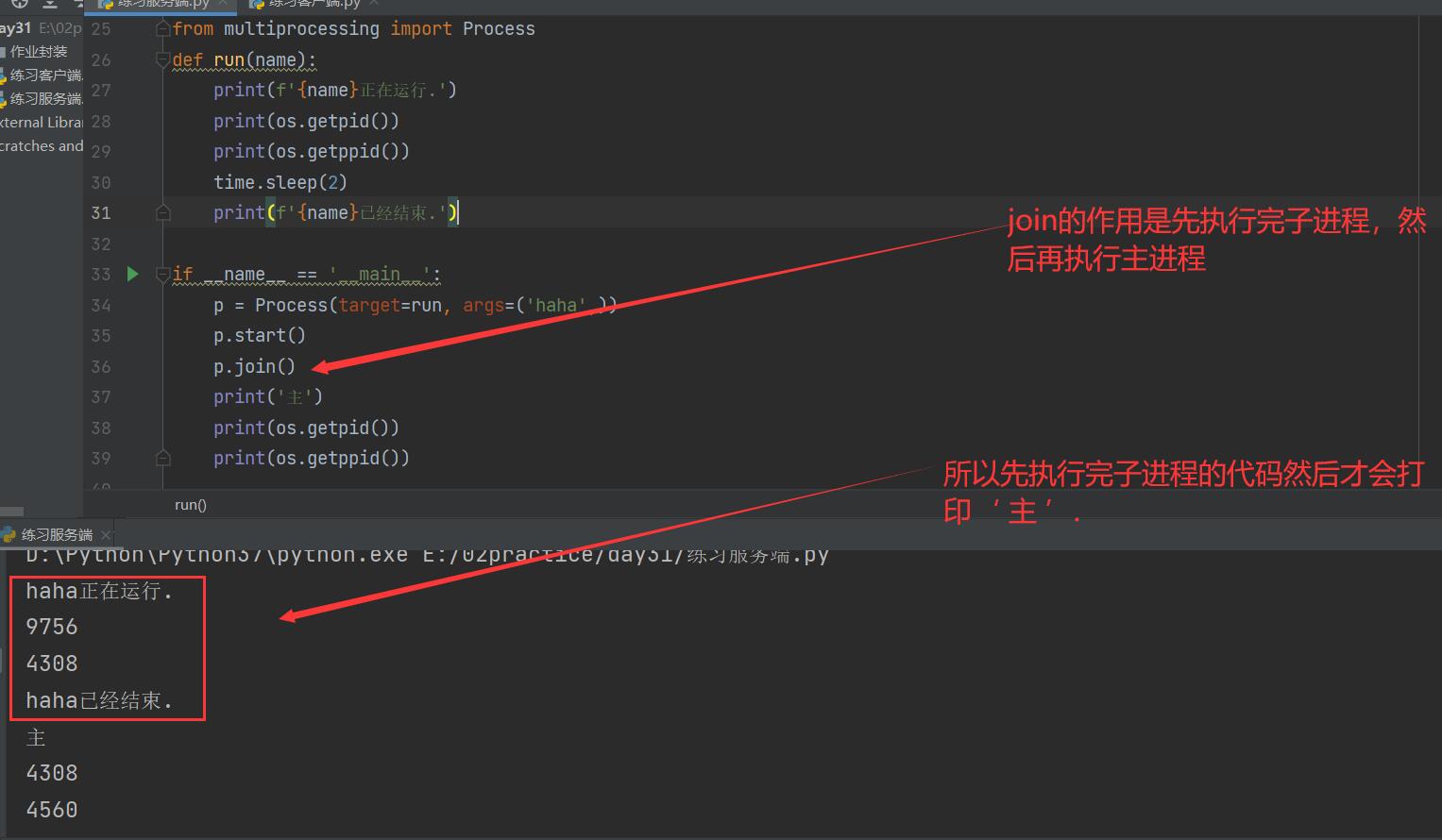
Get process number
Asynchronous understanding
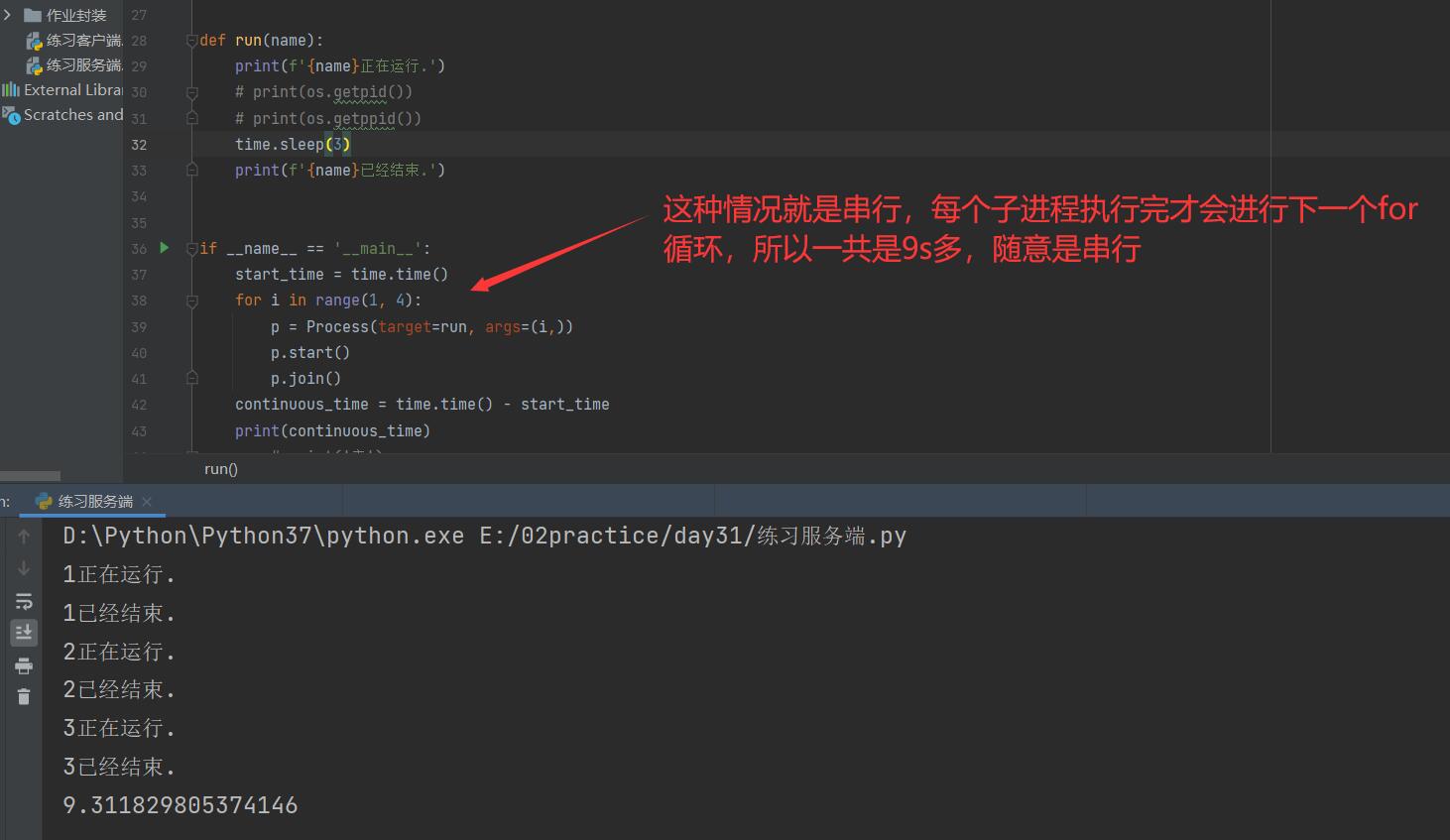
import time
from multiprocessing import Process
def run(name):
print(f'{name}Running.')
# print(os.getpid())
# print(os.getppid())
time.sleep(3)
print(f'{name}It's already over..')
if __name__ == '__main__':
start_time = time.time()
for i in range(1, 4):
p = Process(target=run, args=(i,))
p.start()
p.join()
continuous_time = time.time() - start_time
print(continuous_time)
import time
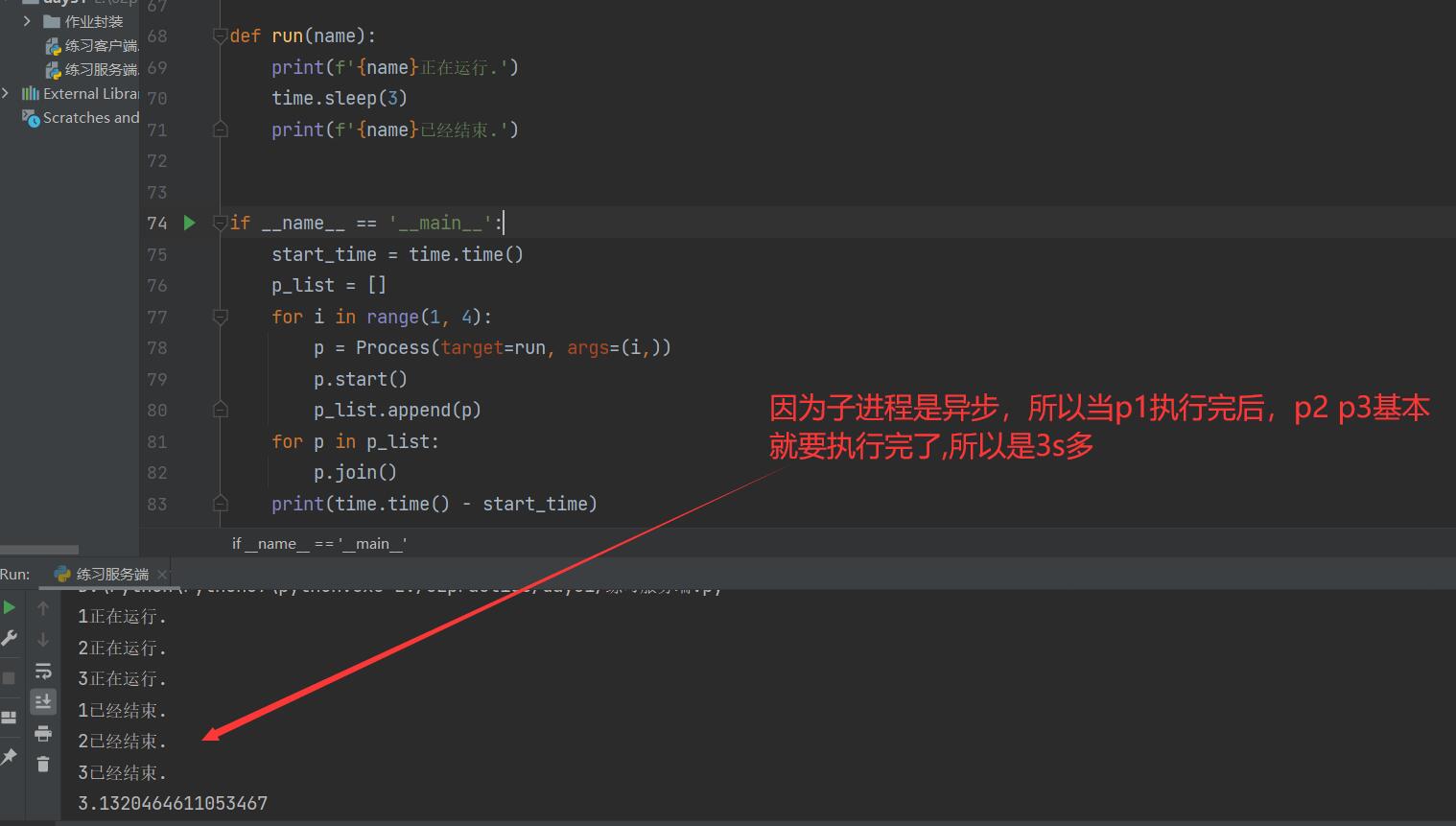
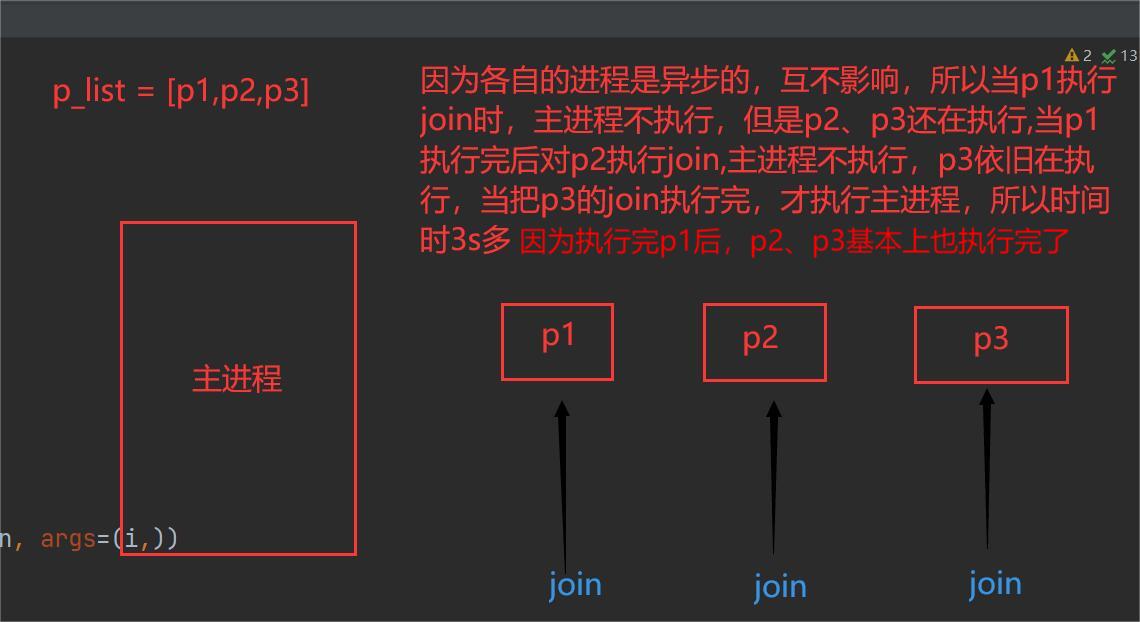
from multiprocessing import Process
def run(name):
print(f'{name}Running.')
time.sleep(3)
print(f'{name}It's already over..')
if __name__ == '__main__':
start_time = time.time()
p_list = []
for i in range(1, 4):
p = Process(target=run, args=(i,))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print(time.time() - start_time)
Other methods
""" 1.current_process View process number 2.os.getpid() View process number os.getppid() View parent process number 3.The name of the process, p.name There is a direct default, or it can be passed in the form of keywords when instantiating the process object name='' 3.p.terminate() Kill child process 4.p.is_alive() Determine whether the process is alive 3,4 No results can be seen in combination, because the operating system needs reaction time. Main process 0.1 You can see the effect """
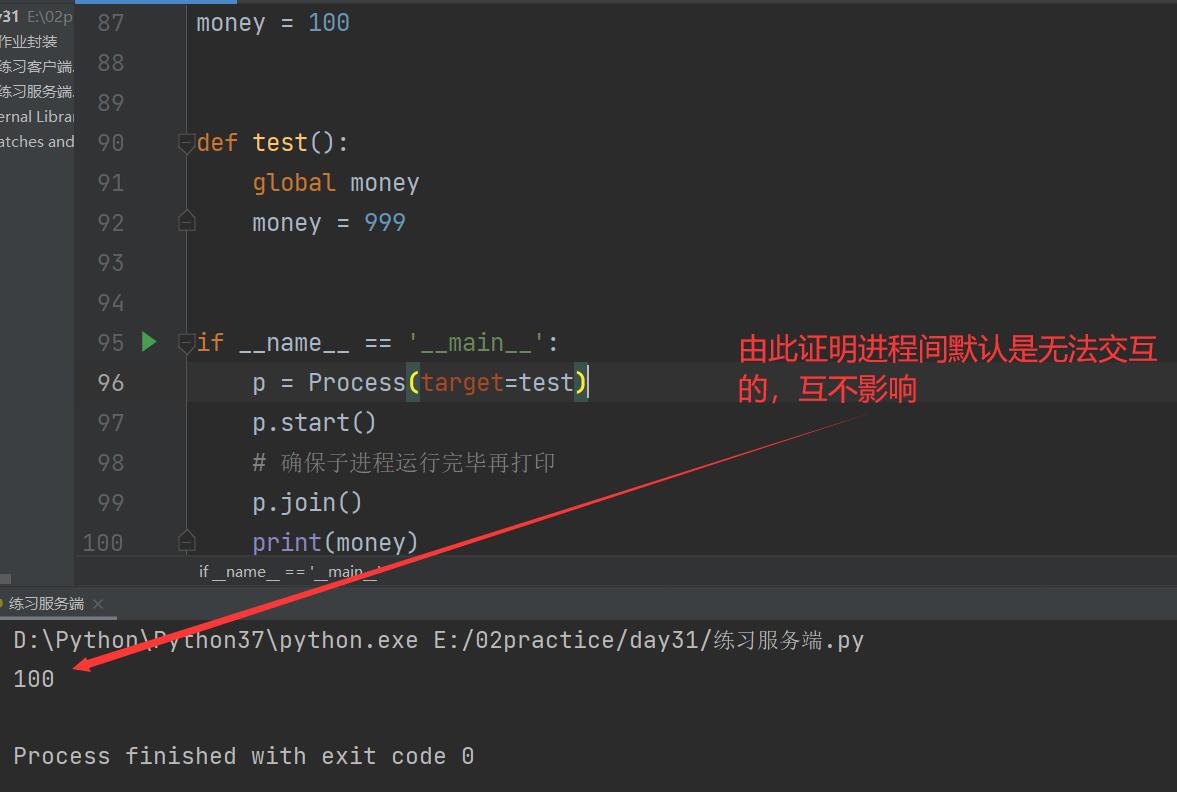
No interaction between processes by default
from multiprocessing import Process
money = 100
def test():
global money
money = 999
if __name__ == '__main__':
p = Process(target=test)
p.start()
# Ensure that the subprocess is running before printing
p.join()
print(money)