background
Last week, I saw an article entitled "multi thread concurrent parsing of a single large file, 18 million data, 8 threads and 5 minutes storage" in the blog park. Although the content is all code, the full text analysis has yielded some results. The idea of recursively splitting large files and submitting them to multi thread parsing is worth studying in detail.
"How to quickly parse and store 1GB CSV files?" This is a good topic. I remember that in the past, in order to view a large log file, I downloaded Logviewer software to barely see it. How can I parse files that ordinary file editing software can't view?
Inspired by this article, let's explore this problem.
Problems in reading large files with normal IO
1. Write a tool class BigFileGenerator that generates files of a specified size. Run it to get a 2G CSV file. Each line in the file represents a web request access information. It is found that Java writes files very quickly. The operation results are as follows:
total line:22808227 cost :46(s)
2. Create a tool class BigFileReader and write a method readByBlock that uses FileInputStream, reads by block and reads 64MB data each time. It is read-only and does not process. It takes a total of 8.6 minutes:

3. Write a line by line reading method readByLine using BufferedReader. It reads only data and does not parse. The operation takes half a time:
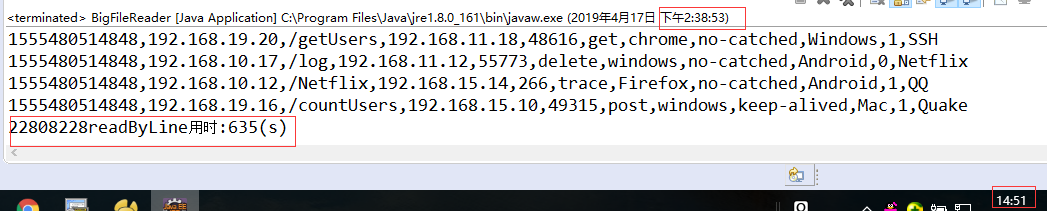
4. Write a method readByLineAndParse that uses BufferedReader to read line by line and parse the receipt. Use "MySQL database + InnoDB engine + self incrementing primary key" to insert 2000 SQL in batches each time. The total time is not measured, and the execution is stopped halfway:
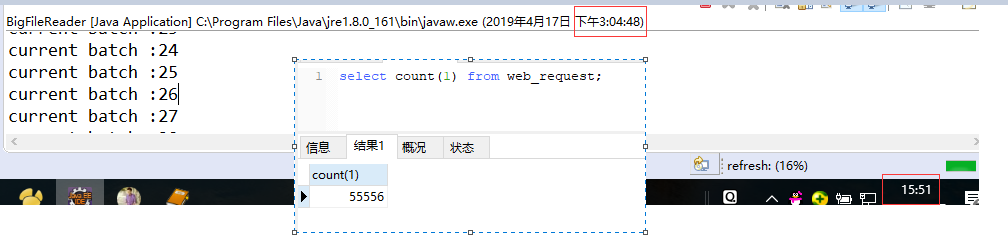
It took 47 minutes to execute, and only 550000 records were put into storage, with a total amount of more than 20 million. At this speed, it took about 188 minutes, which was quite slow.
According to the test results, there are several problems in "single thread + ordinary IO" parsing large files:
First, the problem of efficiency, without any processing, only reading operation is quite time-consuming;
Second, the efficiency of fixed length reading is a little higher than that of row by row reading, but the continuity of data cannot be guaranteed. 64MB data blocks are read each time, but the last item of data read in this time cannot be guaranteed to be completed, which is not conducive to data analysis. In addition, due to the memory configuration of the JVM, you cannot read too much data into memory at one time, otherwise OOM exceptions will occur.
Third, when I haven't completely tested the efficiency of memory mapped reading, my understanding of ordinary IO reading files is biased. From the later test results, the efficiency of line by line reading using BufferedReader is not very low.
Generally speaking, I think the bottleneck of large file parsing lies in the database and OS resources. In the multi-threaded parsing scheme, it is possible to use ordinary IO and memory mapping technology for file reading.
The basic idea of parsing large files with Java multithreading
1. Multithreading improves parsing efficiency: the large file is divided into N small blocks, and each block is parsed by a thread until all blocks are parsed. This involves file segmentation algorithm and multi-threaded cooperative control, which will be discussed in detail later.
2. Use RandomAccessFile class to segment a file: its seek method can jump to any position for data reading. During file segmentation, calculate the end position of the block, and then find the file pointer position that appears for the first time after \ r\n, taking it as the real end position of the block to ensure data integrity.
3. RandomAccessFile provides memory file mapping API, which can speed up the processing efficiency of large files.
"Memory file mapping" refers to the file located in the hard disk as the physical memory corresponding to an area in the program address space. The data of the file is the corresponding data in the memory of this area. Reading and writing the data in the file can directly operate on the address of this area, thereby reducing the link of memory replication.
Memory mapping technology and multithreading concurrent parsing of large files
Function implementation class diagram
The implementation of this simple function probably involves several classes. The class diagram is drawn as follows:
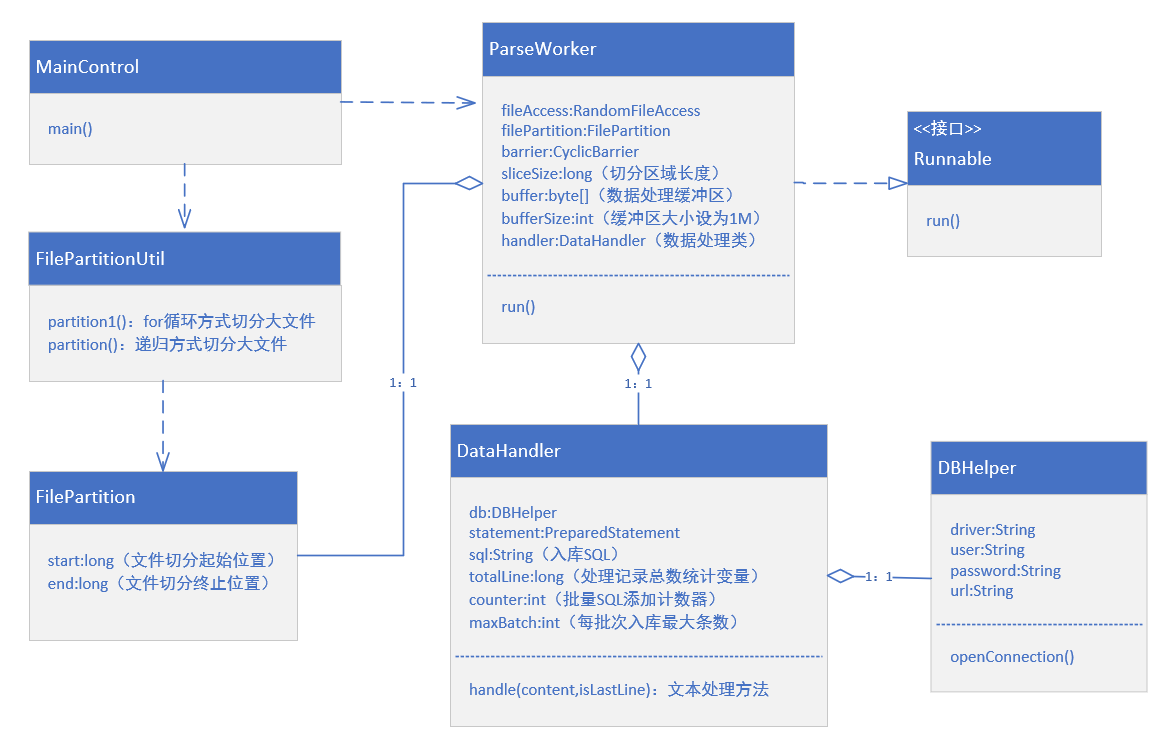
Execution process of main method in MainControl:
- Call the partition1 method of FilePartitionUtil to segment a large file to obtain N FilePartition objects;
- Each filepart is submitted to a ParseWorker task;
- ParseWorker circularly reads the contents in the FilePartition area, finds the records contained in \ r\n each row, and hands them to the DataHandler object for processing;
- DataHandler divides each line of text information with commas and maps it to the corresponding fields of the database, and then calls DBHelper to obtain the database connection, and then batch warehousing.
####Preparatory work
1. Using the tool class written above, a 2G CSV file is generated. The first line is the title, with a length of 95 bytes, and the total number of effective records in the file is more than 20 million lines.
2. Create a test database and data table with the following statements:
CREATE DATABASE bigfile; use bigfile; DROP TABLE IF EXISTS `web_request_multiple`; CREATE TABLE `web_request_multiple` ( `time` bigint(20) DEFAULT NULL, `src_ip` varchar(15) DEFAULT NULL, `request_url` varchar(255) DEFAULT NULL, `dest_ip` varchar(15) DEFAULT NULL, `dest_port` int(11) DEFAULT NULL, `method` varchar(32) DEFAULT NULL, `user_agent` varchar(22) DEFAULT NULL, `connection` varchar(32) DEFAULT NULL, `server` varchar(32) DEFAULT NULL, `status` varchar(20) DEFAULT NULL, `protocol` varchar(32) DEFAULT NULL ) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4;
Note: in order to improve the warehousing efficiency, the table does not have a primary key, and the database engine selects MyISAM. At first, the self incrementing primary key was designed for the table and the InnoDB engine was used. As a result, the multi-threaded warehousing was not completed in one day. The efficiency of multi-threaded parsing was as low as that of single thread parsing, and the database became a new bottleneck.
After adjusting the test direction, multi-threaded parsing of 2G, more than 20 million recorded files finally took more than 20 minutes, and multi-threaded parsing of large files can finally show its advantages.
####The first step is to segment large files
1. Two information needs to be determined: the total number of bytes of the file and the number of Shards. Divide them to get the average length of each shard area; Initialize the information of N segmentation regions.
2. Each row of data in the CSV file generated by the program contains \ r\n complete records, so the start and end position information of the segmentation area needs to be corrected one by one.
3. Correction logic: for the end information of each segmentation area, move the file pointer backward until the first character is encountered. At this time, the end information of the segmentation is actually "initial end + moved position + 2 (\ r\n two characters)"; the position of the next segmentation is "end + 1 of the previous segmentation".
The segmentation algorithms referenced on the Internet are implemented recursively. I don't think the recursive algorithm is easy to understand, so it is implemented according to my own ideas. Two for loops are used, the first initialization and the second correction. The specific code is:
/**
* Two for loops complete the segmentation of large files
* @param start File segmentation start position
* @param splitCount Number of pieces to be segmented
* @param totalSize Total file length
* @param randomAccessFile Large file access class
* @return
* @throws IOException
*/
public static List<FilePartition> partition1(long start, int splitCount, long totalSize, RandomAccessFile randomAccessFile) throws IOException{
if(splitCount<2) {
throw new IllegalArgumentException("Shard cannot be less than 2 ");
}
//Return result: all segmented area information
List<FilePartition> result = new ArrayList<FilePartition>(splitCount);
//Total length of each segmentation area
long length = totalSize/splitCount;
//Initialize segmentation block information
for(int i=0;i<splitCount;i++) {
//Create a record
FilePartition partition = new FilePartition();
//Start and end position of each area during average segmentation: similar to the algorithm for calculating the start and end position of pages by paging
long currentStart = start+length*i;
//The position starts from 0, so you need to subtract 1
long currentEnd = currentStart+length-1;
partition.setStart(currentStart);
partition.setEnd(currentEnd<totalSize?currentEnd:totalSize-1);
result.add(partition);
}
//Starting from the second segmentation block, correct the start and end positions: ensure that the end position of each block is a \ R \ nline break
long index = result.get(0).getEnd();
for(int i=1;i<splitCount;i++) {
//Locate the end of the previous slice and look for the newline symbol later
randomAccessFile.seek(index);
byte oneByte = randomAccessFile.readByte();
//Judge whether it is a newline symbol. If it is not a newline character, read it until the newline character
while(oneByte != '\n' && oneByte != '\r') {
randomAccessFile.seek(index++);
oneByte = randomAccessFile.readByte();
}
FilePartition previous = result.get(i-1);
FilePartition current = result.get(i);
//At the end of the loop, index is now in the \ r position
//At this time, there is still a \ n symbol to correct the end of the previous slice and the start of the current slice
previous.setEnd(index+1);
current.setStart(index+2);
//Set the next search position to the end of the current slice
index = current.getEnd();
}
return result;
}
The key point of the algorithm is that when the end is corrected to the position of the newline symbol, the position of the file pointer at the end of the loop is a \ r character, and each line of the file we generate has \ r\n, so an additional \ n character length is added during the correction here.
####The second step is to design the analysis task