Because the interview big factory was hanged, I finally made up my mind to make up for it
jdk1.7 is a segment lock implementation of segment lock, and 1.8 does not have segment lock
Let's talk about the process of putValue:
-
Throw a null pointer if the key is not empty
-
Get table array
-
Judge whether the table is empty. If it is empty, expand the capacity
-
Judge whether the table subscript corresponding to the hash value of the key is empty. If it is empty, create a node through cas operation, put it into the table, and then exit directly.
-
If the bucket bit is empty, judge whether the return value of the current header node is - 1. If so, the current thread is required to help expand the capacity, obtain the expanded bucket, and then restart the cycle.
-
If the bucket is empty and is not expanding, and there are other node s on the table. Declaring an empty value will be assigned and returned.
-
Add a synchronization lock to the node found to prevent concurrency problems, and other threads will block when they enter.
-
Again, use cas to confirm that the table on the index is our node. If not, the node will be modified and released directly into the next cycle.
-
If the first hash value of the target table is greater than or equal to 0, it is judged that it is a chain structure, otherwise it is a red black tree
-
The ID bincount is 1, because at least one node on the table will enter the linked list
-
Cycle linked list
-
If the hash value of the traversal element is the same as the hash value of the target key to be inserted (the same comparison method as hashmap), and the value is also the same, a duplicate key is inserted.
-
Judge whether onlyIfAbsent is false to replace the value, otherwise it will not be modified and jump out of the current cycle.
-
If there is no same key at the end of the loop, the tail interpolation will be performed directly, and the current loop will also jump out
-
If it is a red black tree, perform operations related to the red black tree
-
When the binCount of the linked list length is greater than 8, the red black tree is transformed,
-
Return old value
-
addCount(1L, binCount); Conduct capacity expansion judgment.
Variable name meaning
bincount table Number of elements in the target index linked list
f table The head node of the linked list corresponding to the target index in the
n table Length of
i Target index
fh Head node f Hash value of
tab table Copy of array
final V putVal(K key, V value, boolean onlyIfAbsent) {
//1. Determine whether the key is empty
if (key == null || value == null) throw new NullPointerException();
//2. Calculate hash value
int hash = spread(key.hashCode());
int binCount = 0;
//3. Get an array of table s
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//4. If the table array is empty, initialize the table
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//5. If there is no node at the corresponding table array subscript position on the hash value of the corresponding key, create a node through cas operation, put it into the table, and then putval out of the stack
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//6. If the table is being expanded, get the expanded table, and then restart a cycle
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
//7. Here it is explained that the corresponding table after the key hash is found, and there are other node s on the table
V oldVal = null;
//8. Add a synchronization lock to the found node to prevent concurrency problems. If other keys are put in, the corresponding tab will be blocked here
synchronized (f) {
//9. Use cas again to confirm that the table on index i is the node we found. If not, the node will be modified, and the lock will be released directly to the next cycle
if (tabAt(tab, i) == f) {
//10. If the hash value of the first node of the target table is greater than or equal to 0, it is a chain structure. Go through the linked list for search, and on the contrary, go through the red and black tree for search
if (fh >= 0) {
//11. The flag bincount is 1 because there is at least one node node on the table
binCount = 1;
//12. Circular linked list
for (Node<K,V> e = f;; ++binCount) {
K ek;
//13. If the hash value of the traversal element is the same as the hash value of the target key to be inserted, and the value is the same, the element of the duplicate key is inserted
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
//14. If onlyIfAbsent is false, it will be replaced with a new value, otherwise it will not be modified (generally false)
if (!onlyIfAbsent)
e.val = value;
//15.break cycle
break;
}
//16. Cycle until the key of the last node is not the key we want to insert
Node<K,V> pred = e;
if ((e = e.next) == null) {
//Add a new node at the end to break the loop
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//17. This node belongs to the child node of the red black tree and performs tree operation
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//18. If the node node is not 0
if (binCount != 0) {
//19. If node is greater than or equal to 8, it will be converted to red black tree
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
//20. Return the old value corresponding to the original key
if (oldVal != null)
return oldVal;
break;
}
}
}
//20. Capacity expansion judgment
addCount(1L, binCount);
return null;
}
Can the load factor of ConcurrentHashmap be specified?
The load factor of hashmap can be specified (although it is also final modified, it modifies the pointing content of the load factor), and the concurrent map cannot be specified because it is final modified and private.
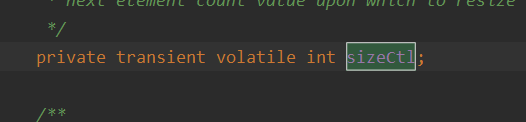
sizeCtl
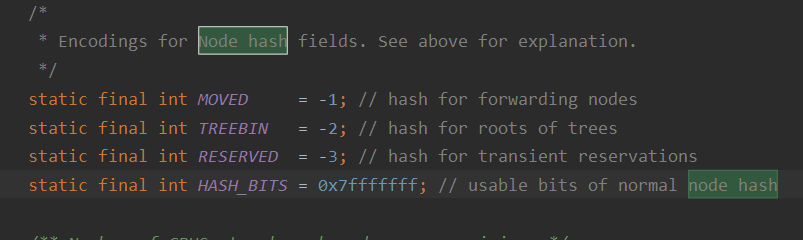
Generally, the Node.hash field must be > = 0
Because the negative number has a special meaning, the ForwardingNode node is - 1. When the hash table is expanded, a data migration process will be triggered. After the old hash table migrates a bucket, there is a marker point whose ForwardingNode value is - 1
There is also a case of a red black tree. The red black tree is represented by a special Node, which is a TreeBin structure. It itself is also an inherited Node, and its hash value is - 2
ReservationNode is a reserved node, which is a placeholder. It will not save the actual data. Normally, it will not appear. The default hash value is - 3
sizeCtl:
There are the following situations:
A value of - 1 indicates that array initialization is in progress
A value of 0 indicates that the array is uninitialized and the initial capacity of the array is 16
The value is a positive number: if the array is not initialized, record the initial capacity of the array; if initialized, record the capacity expansion threshold of the array
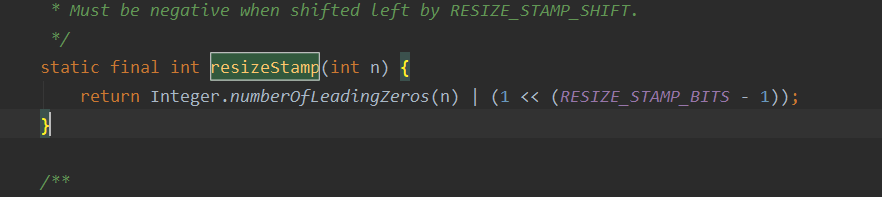
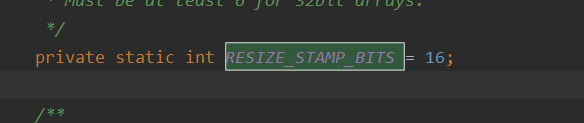
Less than 0 but not - 1 indicates that the array is being expanded. A capacity expansion status. The high 16 bits indicate the capacity expansion identification stamp, the low 16 bits indicate the number of threads + 1, and (1+n) indicates that n threads are jointly completing the capacity expansion operation. That is, the lower 16 bits minus 1 equals the number of threads being expanded.
Capacity expansion identification stamp: the capacity expansion identification stamp calculated by each thread must be consistent before concurrent capacity expansion. This stamp is related to the table size before capacity expansion.
How does concurrehahmap ensure the security of writing data?
The thread safety is guaranteed by internal spin lock + CAS + suncronized + segment lock.
-
First judge whether the scattered list has been initialized. If not, initialize the scattered list before writing

-
To add data to the bucket, first judge whether the bucket is empty. If it is empty, add the new data to the bucket through cas algorithm. If the write fails, it indicates that other threads have written data in the current bucket. The current thread fails to compete and returns to the spin position to wait.

-
If the bucket is not empty, you need to judge the type of the head node in the current bucket: if the value of the head node in the bucket is - 1, it means that the head node of the current bucket is fed node. At present, the scattered list is in the capacity expansion state. At this time, the current thread needs to assist in capacity expansion.

If the conditions in 2.3 are not met, it means that the current bucket location may be stored in a scattered list or the proxy object TreeBin of the red black tree. In this case, synchronized will be used to lock the head node in the bucket to ensure that the write operation in the bucket is thread safe.


Addressing algorithm
(length-1) & hash is not different from hashMap. The basic algorithm is to XOR the high 16 bits with the low 16 bits, but force the sign bit to 0 to make the value positive. Because length must be to the power of 2, the conversion of length-1 to binary must be in the form of 111.. when this number is bitwise and calculated with any number, it must be able to obtain a number greater than or equal to 0 and less than.
What is the size field of int type in a concurrent map when counting the current hash data in a hashMap?
In fact, it is a LongAdder (jdk8 new feature), but the name in the map does not directly import the LongAdder, but takes the source code,
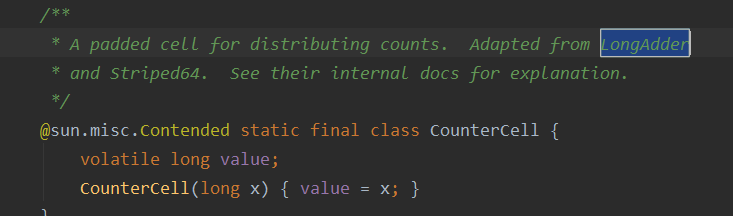

Why not use AtomicLong
AtomicLong is based on CAS spin update; LongAdder divides the value into several cells. When the concurrency is low, CAS updates the value directly, and the success ends. In the case of high concurrency, CAS updates a cell value and expands the cell data when necessary, and ends successfully; Update failed to update cell value. When the value is taken, the sum() method is called to accumulate each cell.
AtomicLong contains atomic read and write APIs; LongAdder has no atomic read-write api, which can ensure the final consistency of the results. The performance of AtomicLong and LongAdder in low concurrency scenario is similar, and the performance of LongAdder in high concurrency scenario is better than AtomicLong. It is mainly a performance consideration.
Note: in a scenario, we let AtomicLong self increment with 100 threads. cas first compares the expected value in a formal way. The replacement operation is carried out only when the expected value is consistent with the actual value. cas reflects that the kernel layer is the cmpxchg instruction. During execution, it will check whether the current platform is a multi-core platform. If it is a multi-core platform, Cmpxchg will lock the total threads to ensure that there is only one cpu to execute at the same time. These 100 threads still pass serially on the platform. The expected value obtained by the following thread has expired data. If it is inconsistent with the actual value, it will fail. After the failure, read the latest value in memory as the expected value, and then try to modify it until it succeeds. There can only be one success at a time, so the cpu memory occupied by other threads is too large.
LongAdder splits values into several, which is a segmented lock. It is a practice of exchanging space for time.
What additional things do threads that trigger expansion conditions need to do?
1. When the sizecl is less than 0 - 1, it indicates that the thread is initializing or expanding. Since this expansion thread is triggered, the current thread must modify sizecl.
2 this thread will create a new table twice the size of the old one. And tell the reference address of the new table to the map.nextTable field (you need to ask subsequent threads to assist in capacity expansion until the data of the old table is migrated),
3 save the length of the old table to the map.transferIndex field and record the migration progress of the old table. The migration progress starts from the high-level bucket to the bucket with subscript 0.
How to mark after migration?
During migration, a ForwardingNode object will be created to indicate that the specified Slot has been migrated.

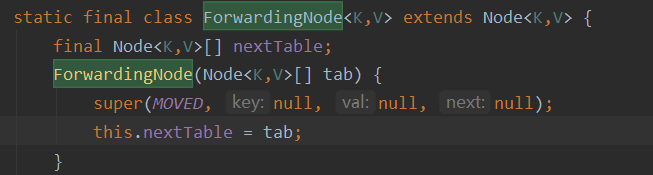
A find () method is provided to query the target data in the new scattered list
There is a pointer to the new table, nextTable
The hash table is being expanded. How should I handle the write request?
When performing a write operation, if the access to the bucket is not a fwd node, the write operation is performed directly.
If it is a fwd node, it means that the data in the current bucket has been migrated, which also means that the scattered list is being expanded. At this time, the current thread needs to join (helpTransfer(tab, f);) to minimize the time spent in capacity expansion. After the current thread is added, ConcurrentHashMap will allocate the migration work according to the global transferIndex field (work refers to the bucket interval responsible for migrating the old scattered list). For example, it is responsible for transferring bucket data of [0-5] to a new scattered list.
If the thread is not assigned to the task responsible for migration, exit assistance. That is, after the expansion, the current thread can continue to write.
During capacity expansion, how does the capacity expansion worker thread maintain the lower 16 bits of sizeCtl
As mentioned earlier, the number of threads is reduced by one in the lower 16 bits of sizeCtl. If a thread is added to the expansion, the lower 16 bits will be + 1.
Each thread executing the capacity expansion operation will be assigned to a migration work interval. If the task interval migration of the current thread is completed, the current thread can exit to assist in capacity expansion. At this time, update the low 16 bit of sizeCtl to - 1, indicating that a thread has exited to assist in capacity expansion.
If the value of sizeCtl after the lower 16 bits - 1 is 1, it indicates that the current thread is the last thread to exit concurrent capacity expansion.
Before the last thread exits, it will also traverse the old table to see if there is any omission of migration. The judgment condition is whether the value of slot is a fwd node, and save the new reference to map.table(); Field, and then calculate the threshold according to the length of the new table and save it to the sizeCtl field.
When the linked list in the bucket is upgraded to a red black tree and a read thread is accessing the current red black tree, what should be done if a new write thread request comes again?
The writing thread will be blocked because when the red black tree writes data, the red black tree will trigger self balancing, left-handed and right-handed, which will lead to changes in the tree structure and will certainly affect the reading results of the reading thread.
static final class TreeBin<K,V> extends Node<K,V> {
// Red black tree root node
TreeNode<K,V> root;
// Head node of linked list
volatile TreeNode<K,V> first;
// Waiting thread (current lockState is read lock state)
volatile Thread waiter;
/**
* 1. Write lock status is exclusive. From the hash table, there is only one write thread entering TreeBin at the same time. one
* 2. Read lock status read lock is shared. Multiple threads can enter the TreeBin object to obtain data at the same time. Each thread will give lockStat + 4
* 3. Wait state (the write thread is waiting). When a read thread in TreeBin is currently reading data and the write thread cannot modify the data, set the lowest 2 bits of lockState to 0b 10
*/
volatile int lockState;
// values for lockState
static final int WRITER = 1; // set while holding write lock
static final int WAITER = 2; // set when waiting for write lock
static final int READER = 4; // increment value for setting read lock
Reading data and writing data on the red black tree are mutually exclusive
There is a lockState field in treeBin. When a thread reads data, it will use CAS to + 4 (indicating that a read lock is added). After reading, it will use CAS to satte-4.
When writing, first check whether the state value is equal to 0. If it is 0, it means that no thread is retrieving. At this time, data can be written. The writing thread will also set the state field to 1 through CAS, indicating that a write lock (exclusive lock) is added.
If the state is not 0, park() will be used to suspend the current thread. The write thread will first set the second bit of state to bit 1, which is 2, indicating that there are write threads waiting to be awakened. When the read thread ends, it will -4 check whether the state is 2. If so, the read thread will use the unpark () interface to wait for the write thread to wake up
When a write thread is executing a write operation on the red black tree, what if there is a new read thread request?
A linked list structure is reserved inside the TreeBin object, which is designed for this situation. At this time, the new reader thread will access the data on the linked list without going through the red black tree. first is the reserved linked list structure, which is specially designed for this situation. It can directly retrieve data without entering the red black tree.