- reference:
preface
- As we all know, Map is a very classic data structure, which is often used to store data in memory;
- This article mainly wants to discuss concurrent HashMap, a concurrent container. However, before discussing, I think it is necessary to understand its origin and its so-called predecessor "HashMap". Understanding its development will help us to have a deeper understanding and master concurrent HashMap;
- If you don't know about HashMap, you can learn HashMap first;
- HashMap:
- The bottom layer is based on array + linked list;
- In fact, the implementation mode in different JDK versions does not change very much, especially jdk1 From 8 to 16, there is basically no change, while jdk1 7 has not changed much before, so our main focus is jdk1 seven ➡➡ jdk1.8. Optimization of one aspect of HashMap;
- Concurrent scenario: jdk1 There are three major problems with HashMap in 7: ☪☪☪
- Duplicate data;
- Dead cycle:
- See other blogs for details: This one has a diagram of the dead cycle. It feels good
- Data loss: when a put operation is performed in a multi-threaded environment, executing addEntry(hash, key, value, i) may cause hash conflicts and data loss;
- jdk1. HashMap in 8 solves two major problems:
- Solved jdk1 The HashMap in 7 causes the problem of dead loop in concurrent scenarios;
- Solved jdk1 Low efficiency of HashMap query in 7 (through red black tree);
- Of course, you can use HashTable or collections Synchronized map is used to solve the concurrency problem, but the efficiency is not high, so today's protagonist appears!!!
Introduction to the ConcurrentHashMap class
- ConcurrentHashMap is jdk1 5 version of JUC introduces a synchronization collection tool class, which is a thread safe HashMap;
- [note]: different versions of ConcurrentHashMap have different internal implementation mechanisms. All discussions in this section are based on jdk1 8;
- Let's first take a look at the inheritance relationship of ConcurrentHashMap (the first reference blog Figure):
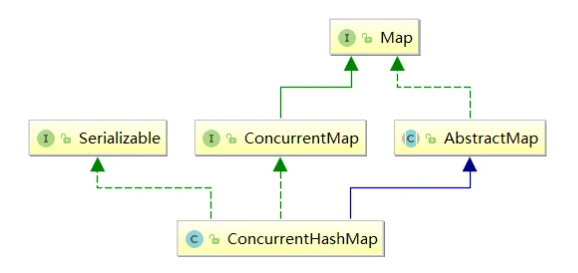
- We can see that it inherits two interfaces and an abstract class:
- AbstractMap: This is a Java The abstract class under util package provides the main method implementation of Map interface to minimize the workload required to implement data structures such as Map;
- Generally speaking, if you need to build wheels repeatedly - to implement a Map yourself, it is generally to inherit AbstractMap;
- Serializable interface: in fact, it has no special meaning for a class or interface, that is, it is serialized to facilitate storage or transmission. If you are interested, you can have a look Serializable related introduction;
- ConcurrentMap interface: in jdk1 At 5:00, with the introduction of J.U.C package, this interface actually provides some atomic operations for Map:
- Let's see what methods it implements:
- AbstractMap: This is a Java The abstract class under util package provides the main method implementation of Map interface to minimize the workload required to implement data structures such as Map;
package java.util.concurrent;
import java.util.Map;
import java.util.Objects;
import java.util.function.BiConsumer;
import java.util.function.BiFunction;
import java.util.function.Function;
public interface ConcurrentMap<K,V> extends Map<K,V> {
//Returns the value corresponding to the specified key; If the key does not exist in the Map, defaultValue is returned 💦💦
default V getOrDefault(Object key, V defaultValue) { ...}
//Traverse all entries of the Map and perform the specified aciton operation on them 💦💦
default void forEach(BiConsumer<? super K, ? super V> action) {...}
//If the specified key does not exist in the Map, insert < K, V >; Otherwise, the value corresponding to the key is returned directly 💦💦
V putIfAbsent(K key, V value);
//Delete entries that exactly match < key, value >, and return true; Otherwise, false is returned 💦💦
boolean remove(Object key, Object value);
//If there is a key and the value is consistent with oldValue, it will be updated to newValue and return true; Otherwise, false is returned 💦💦
boolean replace(K key, V oldValue, V newValue);
//If there is a key, it will be updated to value and the old value will be returned; Otherwise, null is returned 💦💦
V replace(K key, V value);
//Traverse all entries of the Map and perform the specified fusion operation on them 💦💦
default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {...}
//If the specified key does not exist in the Map, calculate the value through the mappingFunction and insert it 💦💦
default V computeIfAbsent(K key , Function<? super K, ? extends V> mappingFunction{...}
//If the specified key exists in the Map, calculate the value through the mappingFunction and replace the old value 💦💦
default V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) {...}
//Find value according to the specified key; Then recalculate the new value and replace the old value according to the obtained value and remappingFunction 💦💦
default V compute(K key , BiFunction<? super K, ? super V, ? extends V> remappingFunction) {...}
//If the key does not exist, insert value; Otherwise, the new value is calculated according to the value corresponding to the key and the remappingFunction, and the old value is replaced 💦💦
default V merge(K key, V value , BiFunction<? super V, ? super V, ? extends V> remappingFunction) {...}
ConcurrentHashMap basic data structure
- Let's take a look at jdk1 8's internal data structure of ConcurrentHashMap (as shown in the first blog, the big God is too strong):
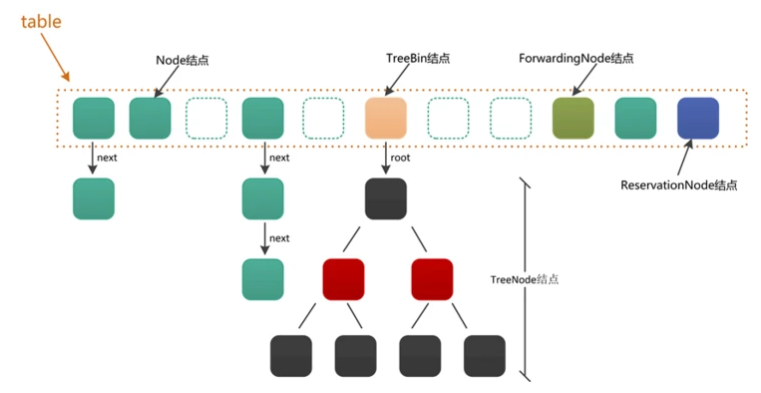
- ConcurrentHashMap internally maintains an array of Node type: table
- table contains four different types of buckets. Different buckets are represented by different colors. This is jdk1 8. Features of the version;
- [note]: the TreeBin Node is connected to a red black tree. The nodes of the red black tree are represented by TreeNode, so there are actually five different types of Node nodes in the ConcurrentHashMap;
- Here we think about a question, why can't we use TreeNode directly?
- This is mainly because the operations of red black tree are complex, including construction, left rotation, right rotation, deletion, balance and other operations. Using a proxy node TreeBin to contain these complex operations is actually an idea of "separation of responsibilities". In addition, TreeBin also contains some add / unlock operations.
- Each position table[i] of the array represents a bucket. When a key value pair is inserted, it will be mapped to different bucket positions according to the hash value of the key;
- [note]:
- In jdk1 Before 8, ConcurrentHashMap adopted the design idea of segmented [Segment] lock to reduce the conflict of hotspot domain. There is still an internal class Segment in jdk16 for serialization and compatibility with previous JDK versions;
- jdk1.8. Instead of continuing, lock each bucket directly, and use the "red black tree" to link the conflict nodes (see if you are interested) Explanation of red black tree);
Node definition of ConcurrentHashMap class
- In the previous part, we talked about the data structure of ConcurrentHashMap. We know that it actually includes five kinds of nodes. Let's take a look at:
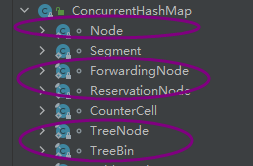
one ️⃣ Node:- Node is the parent class of the other four types of nodes;
- It is linked to table[i] by default, that is, the Node on the bucket is the Node node;
- In case of hash conflict, the Node node will first link to the table in the form of a linked list:
- When the number of nodes exceeds a certain number, the linked list will be transformed into a red black tree;
- [note]: because the time complexity of linked list search is O(n), while the red black tree is a balanced binary tree, and its average time complexity is O(logn), which improves the efficiency.
/*
* An ordinary Entry node is used only when it is saved in the form of a linked list to store actual data
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next; //Linked list pointer 💛
Node(int hash, K key, V val) {
this.hash = hash;
this.key = key;
this.val = val;
}
Node(int hash, K key, V val, Node<K,V> next) {
this(hash, key, val);
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString() { return Helpers.mapEntryToString(key, val); }
public final V setValue(V value) { throw new UnsupportedOperationException(); }
public final boolean equals(Object o) {
Object k, v, u; Map.Entry<?,?> e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry<?,?>)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
//For linked list lookup, different types of nodes have different find() methods 🧡
Node<K,V> find(int h, Object k) {...}
two ️⃣ TreeNode node:
- TreeNode is the node of the red black tree. TreeNode is not directly linked to the bucket, but is linked by TreeBin, which will point to the root node of the red black tree;
// The red black tree node stores the actual data
static final class TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent; // Red black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
/* needed to unlink next upon deletion ,prev The pointer is for easy deletion,
When deleting a non head node of a linked list, you need to know its predecessor node to delete it, so you directly provide a prev pointer
*/
TreeNode<K,V> prev;
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next , TreeNode<K,V> parent) {
super(hash, key, val, next);
this.parent = parent;
}
Node<K,V> find(int h, Object k) {
return findTreeNode(h, k, null);
}
//Take the current node (this) as the root node and start traversing to find the specified key
final TreeNode<K,V> findTreeNode(int h, Object k, Class<?> kc) {...}
three ️⃣ TreeBin node:
- TreeBin is equivalent to the proxy node of TreeNode; TreeBin will be directly linked to * * table[i] *. This node provides a series of red black tree related operations, as well as locking and unlocking operations:
/*
TreeNode Proxy node (equivalent to a container encapsulating TreeNode, which provides conversion operations and lock control for red black trees)
hash The value is fixed to - 3
*/
static final class TreeBin<K,V> extends Node<K,V> {
TreeNode<K,V> root; // Root node of red black tree structure
volatile TreeNode<K,V> first; // Head node of linked list structure
volatile Thread waiter; // The most recent thread to set the WAITER ID bit
volatile int lockState; // Overall lock status identification bit
// values for lockState
static final int WRITER = 1; // Binary 001, write lock status of red black tree
static final int WAITER = 2; // Binary 010, waiting for red black tree to obtain write lock status
// Binary 100 is the read lock state of the red black tree. Reads can be concurrent. For each additional read thread, a READER value is added to the lockState
static final int READER = 4;
/**
* Use this method to determine the size when hashcodes are equal and not of Comparable type
*/
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ? -1 : 1);
return d;
}
// Convert the linked list with b as the head node into a red black tree
TreeBin(TreeNode<K,V> b) {...}
// Add a write lock to the root node of the red black tree
private final void lockRoot() {
if (!U.compareAndSetInt(this, LOCKSTATE, 0, WRITER))
contendedLock(); // offload to separate method
}
//Release write lock
private final void unlockRoot() {
lockState = 0;
}
/**
* Possibly blocks awaiting root lock.
*/
private final void contendedLock() { ... }
// Traverse the search from the root node, return the "equal" node if it is found, and return null if it is not found. When there is a write lock, search in the form of linked list
final Node<K,V> find(int h, Object k) {
if (k != null) {
for (Node<K,V> e = first; e != null; ) {
int s; K ek;
/*
There are two cases: searching by linked list:
1,A thread is holding a write lock, which does not block the read thread
2,A thread is waiting to acquire a write lock and will no longer add a read lock, which is equivalent to the "write first" mode
*/
if (((s = lockState) & (WAITER|WRITER)) != 0) {
if (e.hash == h && ((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
e = e.next;
}
else if (U.compareAndSetInt(this, LOCKSTATE, s , s + READER)) {
TreeNode<K,V> r, p;
try {
p = ((r = root) == null ? null :
r.findTreeNode(h, k, null));
} finally {
Thread w;
if (U.getAndAddInt(this, LOCKSTATE, -READER) ==
(READER|WAITER) && (w = waiter) != null)
LockSupport.unpark(w);
}
return p;
}
}
}
return null;
}
/**
* Find the node corresponding to the specified key. If it is not found, insert it
* @return null will be returned if the insertion is successful. Otherwise, the node found will be returned
*/
final TreeNode<K,V> putTreeVal(int h, K k, V v) {...}
/*
Delete the node of red black tree:
1. If the size of the red black tree is too small, return true, and then convert the tree - > linked list;
2. When the red black tree is large enough, it does not need to be transformed into a linked list, but it needs to add a write lock when deleting nodes;
*/
final boolean removeTreeNode(TreeNode<K,V> p) {...}
// The following is the classic operation method of red black tree, adapted from introduction to algorithm 💦💦💦💦
static <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root , TreeNode<K,V> p) { ...}
static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root , TreeNode<K,V> p) {...}
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root , TreeNode<K,V> x) {...}
static <K,V> TreeNode<K,V> balanceDeletion(TreeNode<K,V> root, TreeNode<K,V> x) { ... }
static <K,V> boolean checkInvariants(TreeNode<K,V> t) {...} //Recursively check the correctness of red black tree
private static final long LOCKSTATE= U.objectFieldOffset(TreeBin.class, "lockState");
}
four ️⃣ ForwardingNode node:
- The forwardingnode node is only used during capacity expansion
/**
* ForwardingNode It is a temporary node that only appears during capacity expansion. The hash value is fixed to - 1 and does not store actual data.
* If all nodes in a hash bucket of the old table array are migrated to the new table, a ForwardingNode is placed in this bucket.
* When the read operation encounters the ForwardingNode, the operation is forwarded to the new table array after capacity expansion for execution; When the write operation encounters it, it tries to help expand the capacity.
*/
static final class ForwardingNode<K, V> extends Node<K, V> {
final Node<K, V>[] nextTable;
ForwardingNode(Node<K, V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
// Find on the new array nextTable
Node<K, V> find(int h, Object k) {...}
five ️⃣ ReservationNode node
/**
* Keep nodes
* hash The value is fixed to - 3, and the actual data is not saved
* It is only used as a placeholder for locking in the two functional API s of computeIfAbsent and compute
*/
static final class ReservationNode<K, V> extends Node<K, V> {
ReservationNode() {
super(RESERVED, null, null, null);
}
Node<K, V> find(int h, Object k) {
return null;
}
}
Constructor of ConcurrentHashMap class
- ConcurrentHashMap provides five constructors:
- The five constructors only calculate the initial capacity of the following table at most, and do not actually create a table array:
- At this time, there is a question: when to create a table array?
- ConcurrentHashMap adopts a "lazy loading" mode. Only when the key value pair is inserted for the first time will it really initialize the table array;
- Next, let's take a look at the five constructors:
//💕 Empty constructor 💕:
public ConcurrentHashMap() {}
//💕💕 Constructor that specifies the initial capacity of the table 💕💕
/**
* Constructor that specifies the initial capacity of the table
* tableSizeFor It will return a value greater than the minimum 2nd power of the input parameter (initialCapacity + (initialCapacity > > > 1) + 1)
*/
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
//💕💕💕 Construct according to the existing Map 💕💕💕
/**
* Construct ConcurrentHashMap according to the existing Map
*/
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
//💕💕💕💕 Constructor that specifies the initial capacity and load factor of the table 💕💕💕💕
/**
* Constructor that specifies the initial capacity and load factor of the table
*/
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
//💕💕💕💕💕 Constructor that specifies the initial capacity, load factor, and concurrency level of the table 💕💕💕💕💕
/**
* Constructor that specifies the initial capacity, load factor, and concurrency level of the table
* <p>
* Note: concurrencyLevel is only for compatibility with jdk1 The versions before 8 are not the actual concurrency level, and the loadFactor is not the actual load factor
* Both of them lose their original meaning and only control the initial capacity
*/
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel)
initialCapacity = concurrencyLevel;
long size = (long) (1.0 + (long) initialCapacity / loadFactor);
int cap = (size >= (long) MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int) size);
this.sizeCtl = cap;
}
Properties of the ConcurrentHashMap class
- Constant:
//Maximum capacity private static final int MAXIMUM_CAPACITY = 1 << 30; //Default initial capacity private static final int DEFAULT_CAPACITY = 16; static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; //Load factor, in order to be compatible with jdk1 8, jdk1 The load factor of ConcurrentHashMap in 8 is constant at 0.75 private static final float LOAD_FACTOR = 0.75f; //The threshold value of linked list to tree, that is, when the number of links is greater than 8, the linked list is converted to tree static final int TREEIFY_THRESHOLD = 8; //The threshold of tree to linked list, that is, when the tree node tree is less than 6, the tree is converted to linked list static final int UNTREEIFY_THRESHOLD = 6; /** * Before the linked list is transformed into a tree, there will be another judgment: * That is, only the number of key value pairs is greater than min_ TREEIFY_ Capability before conversion occurs. * This is to avoid unnecessary conversion caused by multiple key value pairs being put into the same linked list at the initial stage of Table creation. */ static final int MIN_TREEIFY_CAPACITY = 64; /** * Before the tree is transformed into a linked list, there will be another judgment: * That is, only the number of key value pairs is less than min_ TRANSFER_ The conversion will take place only after stride */ private static final int MIN_TRANSFER_STRIDE = 16; //Used to generate unique random numbers during capacity expansion private static int RESIZE_STAMP_BITS = 16; //The maximum number of threads that can be expanded at the same time private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1; /** * The bit shift for recording size stamp in sizeCtl. */ private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS; static final int MOVED = -1; // Identify the ForwardingNode node (it only appears during capacity expansion and does not store actual data) static final int TREEBIN = -2; // Identifies the root node of the red black tree static final int RESERVED = -3; // Identifies the ReservationNode node () static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash //Number of CPU cores, used during capacity expansion static final int NCPU = Runtime.getRuntime().availableProcessors();
- Field:
//Node array, which identifies the entire Map. It is created when the element is first inserted. The size is always a power of 2 transient volatile Node<K, V>[] table; //The new Node array after capacity expansion is not empty only during capacity expansion private transient volatile Node<K, V>[] nextTable; /** * Control the initialization and expansion of table * 0 : Initial default * -1 : A thread is initializing table * >0 : table The capacity used during initialization, or the threshold after initialization / expansion * -(1 + nThreads) : Record the number of threads performing the capacity expansion task */ private transient volatile int sizeCtl; //A subscript variable needed for capacity expansion private transient volatile int transferIndex; //Count base value. When there is no thread competition, the count will be added to the variable. Base variable similar to LongAdder private transient volatile long baseCount; //Count array, used in case of concurrency conflict. Cell array similar to LongAdder private transient volatile CounterCell[] counterCells; // Spin identification bit, used for counter cell [] capacity expansion. cellsBusy variable similar to LongAdder private transient volatile int cellsBusy; // View related fields private transient KeySetView<K, V> keySet; private transient ValuesView<K, V> values; private transient EntrySetView<K, V> entrySet;