Catalog
- I. Multiple Processes of Concurrent Programming
-
2. Multithreading of Concurrent Programming
- 1. Introduction to threading module
- 2. Two Ways to Open Threads
- 3. Code comparison of thread vs process
- 4. Other methods of threading
- 5. Usage in join threads
- 6. Daemon threads
- 7. Mutex Lock
- 8. Deadlock Phenomenon and Recursive Lock
- 9. Signals
- 10.Python GIL
- 11. The Difference between GIL and lock Locks
- 12. Verify the efficiency of compute-intensive IO-intensive
- 13. Multithread socket Communication
- 14. process pool, thread pool
- 15. Blocking, non-blocking, synchronous, asynchronous
- 16. Synchronized call, asynchronous call
- 17. Asynchronous call + callback function
- 18. Thread queue queque
- 19. event events
- 20. Co-operation
I. Multiple Processes of Concurrent Programming
1. Introduction of multiprocessing module
Multithreading in Python can't take advantage of multicore. If you want to make full use of the resources of multicore CPU (os.cpu_count() to view), in most cases in python, you need to use multiprocesses. Python provides multiprocessing.
multiprocessing module is used to start sub-processes and perform customized tasks (such as functions) in sub-processes, which are similar to threading's programming interface.
multiprocessing module has many functions: supporting sub-processes, communicating and sharing data, performing different forms of synchronization, providing Process, Queue, Pipe, Lock and other components.
Unlike threads, processes do not have any shared state, and processes modify data only within the process.
2. Introduction of Process Class
Create process classes
Process([group [, target [, name [, args [, kwargs]]]]]), an object instantiated by this class, represents a task in a subprocess (not yet started) Emphasize: 1. You need to use keywords to specify parameters 2. The position parameter assigned by args to the target function is a tuple and must have a comma.
Introduction of parameters
The group parameter is not used and the value is always None
target represents the calling object, the task to be performed by the child process
Args denotes the location parameter tuple of the calling object, args=(1,2,'egon',)
Kwargs denotes the dictionary of the calling object, kwargs={'name':'egon','age':18}
Name is the name of the child processMethod Introduction
p.start(): Start the process and call p.run() in the subprocess. p.run(): The way a process runs at startup is when it calls the function specified by target. This method must be implemented in the class of our custom class. p.terminate(): Force the termination of process p without any cleanup. If p creates a subprocess, the subprocess becomes a botnet process, which requires special care. If p also saves a lock, it will not be released, leading to a deadlock. p.is_alive(): If p is still running, return to True p.join([timeout]): The main thread waits for p to terminate (emphasizing that the main thread is in the state of waiting, while p is in the state of running). Timout is an optional timeout. It should be emphasized that p. join can only live in processes opened by start, not processes opened by run.
Introduction to attributes
p.daemon: The default value is False. If it is set to True, it represents the daemon running in the background. When the parent process of P terminates, P terminates, and when it is set to True, P cannot create its own new process. It must be set before p.start(). p.name: The name of the process p.pid: PID of process p.exitcode: The process is None at runtime, and if it is'- N', it is terminated by signal N. p.authkey: Process authentication key, default is a 32-character string randomly generated by os.urandom(). The purpose of this key is to provide security for underlying inter-process communications involving network connections, which can only succeed if they have the same authentication key.
3. Use of Process Class
Note: In windows, Process() must be placed under # if name =='main':
Since Windows does not have fork, the multiprocessing module starts a new Python process and imports the calling module. If Process () is invoked at import, it will start an infinitely inherited new process (or until the machine runs out of resources). This is the original hidden internal call to Process (), using if__name_=="_main_", the statement in this if statement will not be invoked when imported.
3.1 Two ways to create sub-processes
Mode I
from multiprocessing import Process
import time
def task(name):
print(f"{name} is running")
time.sleep(2)
print(f"{name} is gone")
if __name__ == '__main__':
#In windos, the opening process must be under _name_=='_main_'.
p = Process(target=task,args=("zbb",)) #Create a process object
p.start()
#Just send a signal to the operating system to start a subprocess, and then execute the next line
# When the signal operating system receives it, it opens up a sub-process space from memory.
# Then all data copy of the main process is loaded into the sub-process, and then the cpu is called to execute.
# Opening up subprocesses is expensive.
print("==Main Start")
time.sleep(3)
print("Main End")
# == Main Start
# zbb is running
# zbb is gone
# Main EndMode 2 (Understanding is not often used)
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self,name):
super().__init__()
self.name = name
def run(self): #Must be run or the parent class will be executed, but the parent class is None
print(f"{self.name} is running")
time.sleep(2)
print(f"{self.name} is gone ")
if __name__ == '__main__':
p = MyProcess("zbb")
p.start()
print("==main")
# = = main
# zbb is running
# zbb is gone 3.2 Getting process pid
pid is the unique identifier of a process in memory
For example, kill pid in linux
Code acquisition
from multiprocessing import Process
import os
def task(name):
print(f'Subprocesses:{os.getpid()}')
print(f'Main process:{os.getppid()}')
if __name__ == '__main__':
p = Process(target=task,args=('zbb',)) # Create a process object
p.start()
print(f'====main{os.getpid()}')
# ==== Lord 13548
# Subprocesses: 1832
# Main process: 13548win command line to get pid
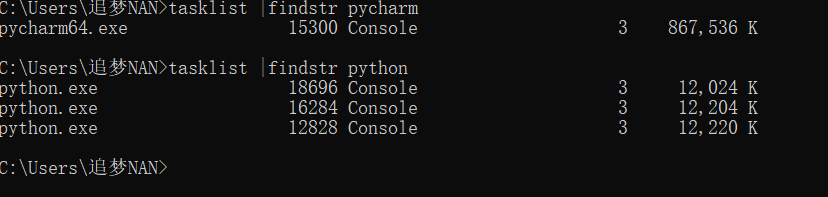
Getting in linux
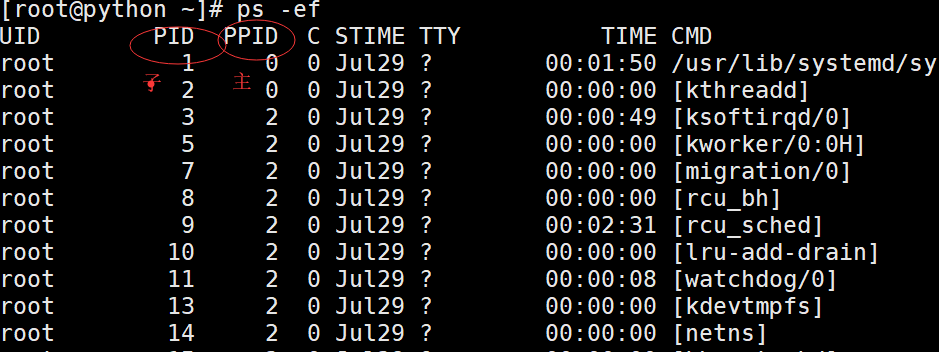
3.3 Spatial isolation between validation processes
Subprocesses and main processes are in different spaces
from multiprocessing import Process
import time
name = 'Pursue dreams NAN'
def task():
global name
name = 'zbb'
print(f'Subprocesses{name}')
if __name__ == '__main__':
p = Process(target=task) # Create a process object
p.start()
# print('== main start')
time.sleep(3)
print(f'main:{name}')
# Subprocess zbb
# Lord: Dreaming NAN3.4 join Method for Process Objects
join lets the main process wait for the child process to finish and execute the main process.
from multiprocessing import Process
import time
def task(name):
print(f'{name} is running')
time.sleep(2)
print(f'{name} is gone')
if __name__ == '__main__':
p = Process(target=task,args=('zbb',)) # Create a process object
p.start()
p.join() #
print('==Main Start')Multiple subprocesses use join
Verification 1
from multiprocessing import Process
import time
def task(name,sec):
print(f'{name}is running')
time.sleep(sec)
print(f'{name} is gone')
if __name__ == '__main__':
start_time = time.time()
p1 = Process(target=task,args=('1',1))
p2 = Process(target=task,args=('2',2))
p3 = Process(target=task,args=('3',3))
p1.start()
p2.start()
p3.start()
p1.join() # Join is only for the main process, and if the join is joined several times below, it is not blocked.
p2.join()
p3.join()
print(f'==main{time.time()-start_time}')
# 1is running
# 2is running
# 3is running
# 1 is gone
# 2 is gone
# 3 is gone
# == Lord 3.186117172241211Verification 2
# Multiple subprocesses use join
from multiprocessing import Process
import time
def task(name,sec):
print(f'{name}is running')
time.sleep(sec)
print(f'{name} is gone')
if __name__ == '__main__':
start_time = time.time()
p1 = Process(target=task,args=('1',3))
p2 = Process(target=task,args=('2',2))
p3 = Process(target=task,args=('3',1))
p1.start()
p2.start()
p3.start()
p1.join() #p1 is a blockage that does not take place until a week later.
print(f'==Main 1-{time.time() - start_time}')
p2.join()
print(f'==Main 2-{time.time() - start_time}')
p3.join()
print(f'==Main 3-{time.time()-start_time}')
# 1is running
# 2is running
# 3is running
# 3 is gone
# 2 is gone
# 1 is gone
# == Main 1-3.152977705001831
# == Main 2-3.152977705001831
# == Main 3-3.152977705001831Optimize the above code
from multiprocessing import Process
import time
def task(name,sec):
print(f'{name}is running')
time.sleep(sec)
print(f'{name} is gone')
if __name__ == '__main__':
start_time = time.time()
l1 = []
for i in range(1,4):
p=Process(target=task,args=("zbb",1))
l1.append(p)
p.start()
for i in l1:
i.join()
print(f'==main{time.time() - start_time}')
print(l1)
# zbbis running
# zbbis running
# zbbis running
# zbb is gone
# zbb is gone
# zbb is gone
# == Main 1.1665570735931396
# [<Process(Process-1, stopped)>, <Process(Process-2, stopped)>, <Process(Process-3, stopped)>]Join is blocking. The main process has join. The code under the main process is not executed until the process has finished executing.
3.5 Other Properties of Process Objects (Understanding)
from multiprocessing import Process
import time
def task(name):
print(f'{name} is running')
time.sleep(2)
print(f'{name} is gone')
if __name__ == '__main__':
p = Process(target=task,args=('cc',),name='aaa') # Create a process object
print(p.name) #Name the child process
p.start()
# time.sleep(1)
p.terminate() #Kill the child process
time.sleep(0.5) #Sleep for a while or you'll be alive.
print(p.is_alive())#Judging whether a child process is alive or not
# p.name = 'sb' #Name of the subprocess
print('==Main Start')3.6 Zombie and Orphan Processes (Understanding)
unix-based environment (linux,macOS)
Normal: The main process needs to wait for the child process to finish before the main process ends.
The main process monitors the running status of the sub-process at all times. When the sub-process is finished, the sub-process is recovered within a period of time.
Why doesn't the main process reclaim the child process immediately after it's finished?
1. The main process and the child process are asynchronous. The main process cannot immediately capture when the child process ends. 2. If the resource is released in memory immediately after the end of the child process, the main process will not be able to monitor the status of the child process.
unix provides a mechanism for solving the above problems.
After all the sub-processes are finished, the operation links of files and most of the data in memory will be released immediately, but some contents will be retained: process number, end time, running status, waiting for the main process to monitor and reclaim.
After all the sub-processes are finished, they will enter the zombie state before they are reclaimed by the main process.
First: Zombie Process (Harmful) Botnet process: A process uses fork to create a child process. If the child process exits and the parent process does not call wait or waitpid to get the status information of the child process, then the process descriptor of the child process is still stored in the system. This process is called a deadlock process.
If the parent process does not wait/wait pid the botnet process, a large number of Botnet processes will be generated, which will occupy memory and process pid number.
How to solve the zombie process???
The parent process produces a large number of child processes, but does not recycle, so a large number of zombie processes will be formed. The solution is to kill the parent process directly, turn all zombie processes into orphan processes, and recycle them by init.
II: Orphan process (harmless) Orphan processes: When a parent process exits and one or more of its children are still running, those children will become orphan processes. The orphan processes will be adopted by the init process (process number is 1), and the init process will collect their status.
4. Daemon process
The sub-process guards the main process, and as long as the main process ends, the sub-process ends.
from multiprocessing import Process
import time
def task(name):
print(f'{name} is running')
time.sleep(2)
print(f'{name} is gone')
if __name__ == '__main__':
# In windows environment, the opening process must be under _name_=='_main_'.
p = Process(target=task,args=('Chang Xin',)) # Create a process object
p.daemon = True # Set the p subprocess to a daemon, and the daemon will end as soon as the main process is finished.
p.start()
time.sleep(1)
print('===main')5. Mutex Lock (Process Synchronization Control)
When multiple users grab a resource, the first user grabs it first, adds a lock, and then uses it for the second user.
problem
Three colleagues print content with one printer at the same time.
Three processes simulate three colleagues, and the output platform simulates the printer.
#Version 1:
#Concurrent is efficiency first, but at present our demand is order first.
#When multiple processes strengthen a resource together, the priority should be guaranteed: serial, one by one.
from multiprocessing import Process
import time
import random
import os
def task1(p):
print(f'{p}It's starting to print.')
time.sleep(random.randint(1,3))
print(f'{p}Printing is over')
def task2(p):
print(f'{p}It's starting to print.')
time.sleep(random.randint(1,3))
print(f'{p}Printing is over')
if __name__ == '__main__':
p1 = Process(target=task1,args=('p1',))
p2 = Process(target=task2,args=('p2',))
p2.start()
p2.join()
p1.start()
p1.join()
#We use join to solve the serial problem and ensure that the order is first, but the first one is fixed.
#This is unreasonable. When you are competing for the same resource, you should first come, first served and ensure fairness.from multiprocessing import Process
from multiprocessing import Lock
import time
import random
import os
def task1(p,lock):
'''
//A lock cannot be locked twice in a row
'''
lock.acquire()
print(f'{p}It's starting to print.')
time.sleep(random.randint(1,3))
print(f'{p}Printing is over')
lock.release()
def task2(p,lock):
lock.acquire()
print(f'{p}It's starting to print.')
time.sleep(random.randint(1,3))
print(f'{p}Printing is over')
lock.release()
if __name__ == '__main__':
mutex = Lock()
p1 = Process(target=task1,args=('p1',mutex))
p2 = Process(target=task2,args=('p2',mutex))
p2.start()
p1.start()The difference between lock and join.
Common point: It can turn concurrency into serialization, which guarantees the order. Differences: join artificially sets the order, lock lets it contend for the order, guarantees fairness.
6. Communication between processes
1. File-based Communication
# Ticket snatching system.
# First you can check the tickets. Query the number of remaining tickets. Concurrent
# Purchase, send requests to the server, the server receives requests, in the back end the number of tickets - 1, back to the front end. Serial.
# When multiple processes strengthen a single data, if data security is to be guaranteed, it must be serialized.
# If we want to serialize the purchase process, we must lock it.
from multiprocessing import Process
from multiprocessing import Lock
import json
import time
import os
import random
def search():
time.sleep(random.randint(1,3)) # Analog Network Delay (Query Link)
with open('ticket.json',encoding='utf-8') as f1:
dic = json.load(f1)
print(f'{os.getpid()} Check the number of tickets,Surplus{dic["count"]}')
def paid():
with open('ticket.json', encoding='utf-8') as f1:
dic = json.load(f1)
if dic['count'] > 0:
dic['count'] -= 1
time.sleep(random.randint(1,3)) # Analog network latency (purchase link)
with open('ticket.json', encoding='utf-8',mode='w') as f1:
json.dump(dic,f1)
print(f'{os.getpid()} Successful Purchase')
def task(lock):
search()
lock.acquire()
paid()
lock.release()
if __name__ == '__main__':
mutex = Lock()
for i in range(6):
p = Process(target=task,args=(mutex,))
p.start()
# When many processes have a single resource (data), you need to ensure that the sequence (data security) must be serial.
# Mutual exclusion lock: guarantees the order of fairness and the security of data.
# Communication between file-based processes:
# Low efficiency.
# Self-locking is troublesome and deadlock prone.2. Queue-based communication
Processes are isolated from each other. To achieve interprocess communication (IPC), the multiprocessing module supports two forms: queue and pipeline, both of which use messaging.
Queue: Understand the queue as a container that can hold some data.
Queue characteristics: FIFO always keeps this data.
.
Classes that create queues (the underlying implementation is pipeline and locking):
1 Queue([maxsize]): Create shared process queues. Queue is a multi-process secure queue that can be used to transfer data between multiple processes.
Introduction of parameters:
1 maxsize is the maximum number of permissible items in the queue, and ellipsis has no size limitation.
Main methods:
The q.put method is used to insert data into the queue, and the put method has two optional parameters: blocked and timeout. If blocked is True (default value) and timeout is positive, this method blocks the time specified by timeout until the queue has space left. If timeout occurs, a Queue.Full exception is thrown. If the blocked is False, but the Queue is full, the Queue.Full exception is thrown immediately.
The q.get method can read from the queue and delete an element. Similarly, the get method has two optional parameters: blocked and timeout. If blocked is True (default value) and timeout is positive, then no element is fetched during the waiting time, and a Queue.Empty exception is thrown. If blocked is False, there are two situations. If a value of Queue is available, the value is returned immediately. Otherwise, if the queue is empty, the Queue.Empty exception is thrown immediately.
q.get_nowait():with q.get(False) q.put_nowait():with q.put(False)
q.empty(): If q is empty when this method is called, it returns True, which is unreliable, for example, if an item is added to the queue in the process of returning True. q.full(): When this method is called, q returns to True when it is full. This result is unreliable, for example, if the item in the queue is removed during the process of returning to True. 9 q.qsize(): The correct number of items in the return queue is unreliable for the same reason as q.empty() and q.full().
Other methods (understanding):
q.cancel_join_thread(): The background thread is not automatically connected when the process exits. Prevent the join_thread() method from blocking q.close(): Close the queue to prevent more data from being added to the queue. Calling this method, the background thread will continue to write data that has been queued but has not yet been written, but will close as soon as this method completes. If q is garbage collected, this method is called. Closing the queue does not produce any type of end-of-data signal or exception in the queue user. For example, if a user is blocking a get() operation, closing the queue in the producer will not cause the get() method to return an error. q.join_thread(): The background thread that connects the queue. This method is used to wait for all queue items to be consumed after calling the q.close() method. By default, this method is called by all processes that are not the original creators of Q. Calling the q.cancel_join_thread method can prohibit this behavior
from multiprocessing import Queue
q = Queue(3) # maxsize
q.put(1)
q.put('alex')
q.put([1,2,3])
# q.put(5555,block=False) # When the queue is full, put data is blocked in the process.
#
print(q.get())
print(q.get())
print(q.get())
print(q.get(timeout=3)) # Blocked for 3 seconds and then blocked for direct error reporting.
# print(q.get(block=False)) # When the data is fetched, the process get data will also be blocked until a process put data.
# block=False will report an error whenever it encounters a blocking.3. Pipeline-based
Pipeline is a problem. Pipeline can cause data insecurity. The official explanation is that pipeline may cause data damage.
7. Producers and consumers
Using producer and consumer patterns in concurrent programming can solve most concurrent problems. This model improves the overall data processing speed of the program by balancing the workability of the production line and the consuming threads.
1. Why use the producer-consumer model
In the threaded world, producers are threads of production data and consumers are threads of consumption data. In multi-threaded development, if the producer processes quickly and the consumer processes slowly, then the producer must wait for the consumer to finish processing before continuing to produce data. In the same way, if the consumer's processing power is greater than that of the producer, then the consumer must wait for the producer. In order to solve this problem, producer and consumer models are introduced.
2. What is the producer-consumer model?
The producer-consumer model solves the strong coupling problem between producer and consumer through a container. Producers and consumers do not communicate directly with each other, but through blocking queues to communicate, so producers do not have to wait for consumers to process the data after production, and throw it directly to the blocking queue. Consumers do not look for producers to ask for data, but directly from the blocking queue, blocking queue is equivalent to a buffer. It balances the processing power of producers and consumers.
It serves as a buffer, balances productivity and consumption, and decouples them.
from multiprocessing import Process
from multiprocessing import Queue
import time
import random
def producer(q,name):
for i in range(1,6):
time.sleep(random.randint(1,2))
res = f'{i}Steamed bun'
q.put(res)
print(f'Producer{name} Produced{res}')
def consumer(q,name):
while 1:
try:
food = q.get(timeout=3)
time.sleep(random.randint(1, 3))
print(f'\033[31;0m Consumer{name} Ate{food}\033[0m')
except Exception:
return
if __name__ == '__main__':
q = Queue()
p1 = Process(target=producer,args=(q,'Passerby A'))
p2 = Process(target=consumer,args=(q,'Passerby B'))
p1.start()
p2.start()2. Multithreading of Concurrent Programming
1. Introduction to threading module
Multiprocessing module imitates the interface of threading module completely. They are similar in use level, so they are not introduced in detail.
Official explanation https://docs.python.org/3/library/threading.html?highlight=threading#
2. Two Ways to Open Threads
from threading import Thread
import time
def task(name):
print(f"{name} is runing!")
time.sleep(2)
print(f"{name} is stop")
t1 =Thread(target=task,args=("mysql",))
t1.start()
print('===Main thread') # Threads are not primary or secondary (for good memory)The second kind of understanding is OK (not often used)
from threading import Thread
import time
class MyThread(Thread):
def __init__(self,name):
super().__init__()
self.name = name
def run(self):
print(f'{self.name} is running!')
time.sleep(1)
print(f'{self.name} is stop')
t1 = MyThread("mysql")
t1.start()
print('main')
3. Code comparison of thread vs process
1. The Difference of Opening Speed between Multithread and Multiprocess
Multiprocess
Execute the main process first
from multiprocessing import Process
def work():
print('hello')
if __name__ == '__main__':
#Open threads under the main process
t=Process(target=work)
t.start()
print('Main thread/Main process') Multithreading
Execute subthreads first
from threading import Thread
import time
def task(name):
print(f'{name} is running')
time.sleep(1)
print(f'{name} is gone')
if __name__ == '__main__':
t1 = Thread(target=task,args=('A',))
t1.start()
print('===Main thread')2. Contrast pid
process
from multiprocessing import Process
import time
import os
def task(name):
print(f'Subprocesses: {os.getpid()}')
print(f'Main process: {os.getppid()}')
if __name__ == '__main__':
p1 = Process(target=task,args=('A',)) # Create a process object
p2 = Process(target=task,args=('B',)) # Create a process object
p1.start()
p2.start()
print(f'==main{os.getpid()}')
# == Lord 17444
# Subprocess: 8636
# Main process: 17444
# Subprocess: 14200
# Main process: 17444thread
resource sharing
from threading import Thread
import os
def task():
print(os.getpid())
if __name__ == '__main__':
t1 = Thread(target=task)
t2 = Thread(target=task)
t1.start()
t2.start()
print(f'===Main thread{os.getpid()}')
# 18712
# 18712
# === Main thread 18712 3. Threads in the same process share internal data
from threading import Thread
import os
x = 3
def task():
global x
x = 100
if __name__ == '__main__':
t1 = Thread(target=task)
t1.start()
# t1.join()
print(f'===Main thread{x}')
# Resource data in the same process is shared among multiple threads of the process.4. Other methods of threading
Method of Thread Instance Object
# isAlive(): Returns whether the thread is active. # getName(): Returns the thread name. # setName(): Set the thread name. Some methods provided by threading module: # threading.currentThread(): Returns the current thread variable. # threading.enumerate(): Returns a list of running threads. Running refers to threads that start and end, excluding threads that start and terminate. # threading.activeCount(): Returns the number of threads running with the same results as len(threading.enumerate()).
from threading import Thread
from threading import currentThread
from threading import enumerate
from threading import activeCount
import os
import time
x = 3
def task():
# print(currentThread())
time.sleep(1)
print('666')
print(123)
if __name__ == '__main__':
t1 = Thread(target=task,name='Thread 1')
t2 = Thread(target=task,name='Thread 2')
# name Sets Thread name
t1.start()
t2.start()
# time.sleep(2)
print(t1.isAlive()) # Determine whether threads are alive
print(t1.getName()) # Get the thread name
t1.setName('Child Thread-1')
print(t1.name) # Get the thread name***
# threading method
print(currentThread()) # Get the object of the current thread
print(enumerate()) # Returns a list of all threaded objects
print(activeCount()) # *** Returns the number of threads running.
print(f'===Main thread{os.getpid()}')
5. Usage in join threads
join: Blocking tells the main thread to wait until my sub-thread has finished executing before executing the main thread
from threading import Thread
import time
def task(name):
print(f'{name} is running')
time.sleep(1)
print(f'{name} is gone')
if __name__ == '__main__':
start_time = time.time()
t1 = Thread(target=task,args=('A',))
t2 = Thread(target=task,args=('B',))
t1.start()
t1.join()
t2.start()
t2.join()
print(f'===Main thread{time.time() - start_time}')6. Daemon threads
It should be emphasized that running out is not terminating
# 1. For the main process, run-through refers to run-out of the main process code. # 2. For the main thread, run-through means that all non-daemon threads in the process where the main thread is running-out, and the main thread is running-out.
If the lifetime of the daemon thread is smaller than that of other threads, then it must end first, or wait for the other non-daemon threads and the main thread to end.
Explain in detail:
# 1 The main process runs out after its code has finished (the daemon is reclaimed at this time), and then the main process will wait until all the non-daemon sub-processes have run out to reclaim the resources of the sub-process (otherwise a zombie process will occur) before it ends. # 2 The main thread runs only after the other non-daemon threads have finished running (daemon threads are reclaimed at this time). Because the end of the main thread means the end of the process, the whole resource of the process will be recycled, and the process must ensure that all non-daemon threads run before it can end.
from threading import Thread
import time
def sayhi(name):
print('You roll!')
time.sleep(2)
print('%s say hello' %name) #The main thread ends without execution
if __name__ == '__main__':
t = Thread(target=sayhi,args=('A',))
# t.setDaemon(True) #You must set it before t.start()
t.daemon = True
t.start() # Threads start much faster than processes
print('Main thread')
# Get out of here!
# Main threadWhen does the main thread end???
The daemon thread waits for the non-daemon sub-thread and the main thread to finish.
from threading import Thread
import time
def foo():
print(123) # 1
time.sleep(3)
print("end123") #The wait time is too long, the child process has been executed, and the daemon has been suspended.
def bar():
print(456) # 2
time.sleep(1)
print("end456") # 4
t1=Thread(target=foo)
t2=Thread(target=bar)
t1.daemon=True
t1.start()
t2.start()
print("main-------") # 3
# 123
# 456
# main-------
# end4567. Mutex Lock
Multi-threaded synchronization lock and multi-process synchronization lock is a truth, that is, when multiple threads preempt the same data (resources), we need to ensure the security of data, reasonable order.
Multiple tasks grab one data,The purpose of ensuring data security,Make it serial
from threading import Thread
from threading import Lock
import time
import random
x = 100
def task(lock):
lock.acquire()
# time.sleep(random.randint(1,2))
global x
temp = x
time.sleep(0.01)
temp = temp - 1
x = temp
lock.release()
if __name__ == '__main__':
mutex = Lock()
l1 = []
for i in range(100):
t = Thread(target=task,args=(mutex,))
l1.append(t)
t.start()
time.sleep(3)
print(f'Main thread{x}')8. Deadlock Phenomenon and Recursive Lock
Processes also have deadlocks and recursive locks. Process deadlocks and recursive locks are the same as thread deadlocks.

from threading import Thread
from threading import Lock
import time
lock_A = Lock()
lock_B = Lock()
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
lock_A.acquire()
print(f'{self.name}I got it. A lock')
lock_B.acquire()
print(f'{self.name}I got it. B lock')
lock_B.release()
lock_A.release()
def f2(self):
lock_B.acquire()
print(f'{self.name}I got it. B lock')
time.sleep(0.1)
lock_A.acquire()
print(f'{self.name}I got it. A lock')
lock_A.release()
lock_B.release()
if __name__ == '__main__':
for i in range(3):
t = MyThread()
t.start()Recursive lock has a counting function, the original number is 0, the last lock, count + 1, release a lock, count - 1
As long as the number above the recursive lock is not zero, other threads cannot lock.
#Recursive locks can solve deadlock problem. When business needs multiple locks, recursive locks should be considered first.
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
lock_A.acquire()
print(f'{self.name}I got it. A lock')
lock_B.acquire()
print(f'{self.name}I got it. B lock')
lock_B.release()
lock_A.release()
def f2(self):
lock_B.acquire()
print(f'{self.name}I got it. B lock')
lock_A.acquire()
print(f'{self.name}I got it. A lock')
lock_A.release()
lock_B.release()
if __name__ == '__main__':
for i in range(3):
t = MyThread()
t.start()9. Signals
It's also a lock that controls the number of concurrencies
The same as the process
Semaphore manages a built-in counter.
Built-in counter-1 whenever acquire() is called;
Built-in counter + 1 when release() is called;
The counter must not be less than 0; when the counter is 0, acquire() blocks the thread until release() is called by other threads.
Example: (At the same time, only five threads can obtain semaphore, which can limit the maximum number of connections to 5):
from threading import Thread, Semaphore, current_thread
import time
import random
sem = Semaphore(5) #The toilet has only five five places out of which one enters the other.
def task():
sem.acquire()
print(f'{current_thread().name} Toilet')
time.sleep(random.randint(1,3))
sem.release()
if __name__ == '__main__':
for i in range(20):
t = Thread(target=task,)
t.start()
10.Python GIL
GIL Global Interpreter Lock
Many self-proclaimed gods say that the GIL lock is python's fatal flaw, Python can not be multi-core, concurrent, etc..
This article gives a thorough analysis of the impact of GIL on python multithreading.
It is strongly recommended to take a look at: http://www.dabeaz.com/python/UnderstandingGIL.pdf
Why lock?
At that time, it was a single-core era, and the price of cpu was very expensive.
-
If there is no global interpreter lock, the programmer who develops Cpython interpreter will actively lock, unlock, troublesome, deadlock phenomena and so on in the source code. In order to save time, he directly enters the interpreter and adds a lock to the thread.
Advantages: It guarantees the security of data resources of Cpython interpreter.
Disadvantage: Multi-threading of a single process can't take advantage of multi-core.
Jpython has no GIL lock.
pypy also does not have GIL locks.
Now in the multi-core era, can I remove Cpython's GIL lock?
Because all the business logic of the Cpython interpreter is implemented around a single thread, it is almost impossible to remove the GIL lock.
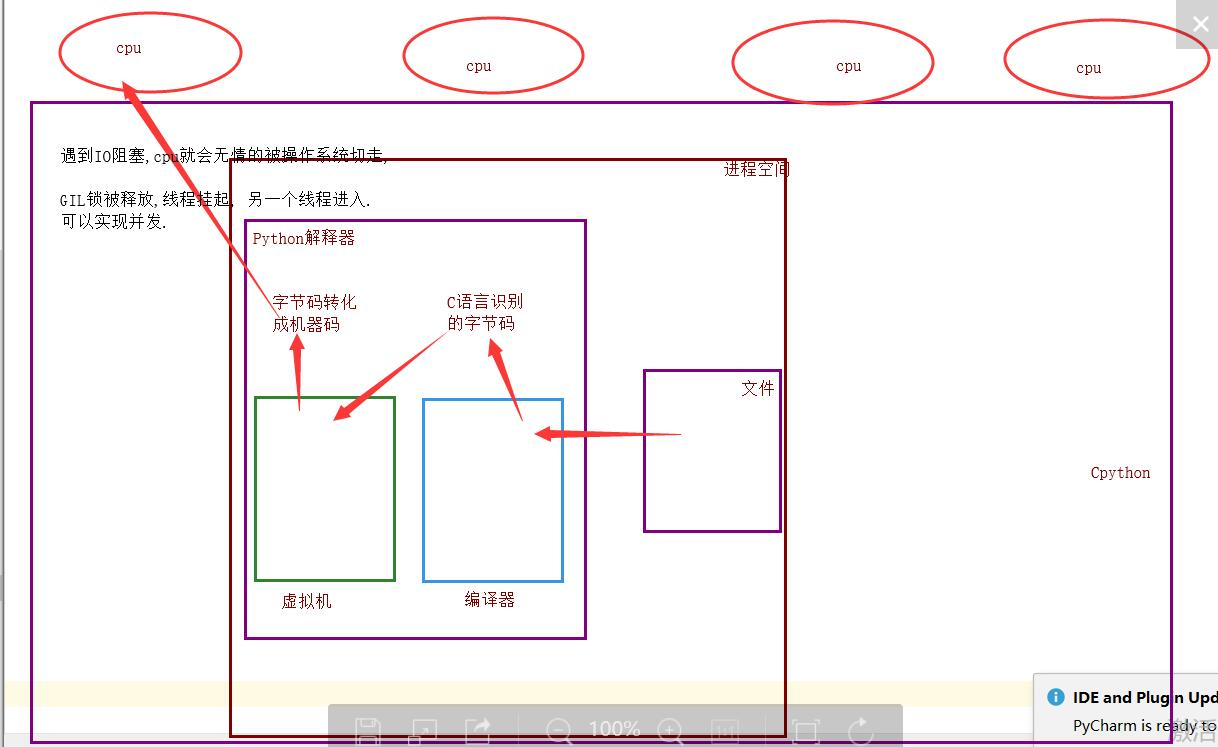
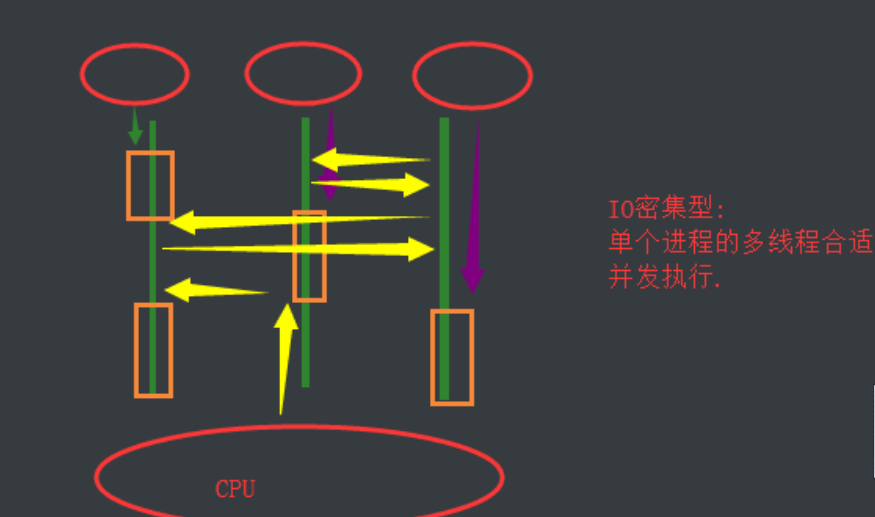
Multi-threading of a single process can be concurrent, but it can't take advantage of multi-core and can't be parallel.
Multiple processes can be concurrent and parallel.
IO-intensive
Computing intensive
11. The Difference between GIL and lock Locks
Similarity: All locks are identical, mutually exclusive.
Difference:
GIL locks global interpreter locks to protect the security of resource data within the interpreter.
GIL locks and releases without manual operation.
The mutex defined in your code protects the security of resource data in the process.
Self-defined mutexes must be manually locked and unlocked.
Detailed contact
Because the Python interpreter helps you reclaim memory automatically and regularly, you can understand that there is a separate thread in the python interpreter. Every time it wakes up to do a global poll to see which memory data can be emptied. At this time, the threads in your own program and the threads of the py interpreter itself are concurrent. Running, assuming that your thread deletes a variable, the clearing time of the garbage collection thread of the py interpreter in the process of clearing this variable may be that another thread just reassigns the memory space that has not yet been cleared, and the result may be that the newly assigned data is deleted, in order to solve the problem. Similarly, the Python interpreter simply and crudely locks a thread when it runs and nobody else can move, which solves the above problem, which can be said to be a legacy of earlier versions of Python.
12. Verify the efficiency of compute-intensive IO-intensive
io-intensive:
from threading import Thread
from multiprocessing import Process
import time
import random
def task():
count = 0
time.sleep(random.randint(1,3))
count += 1
if __name__ == '__main__':
#Multi-process concurrency and parallelism
start_time = time.time()
l1 = []
for i in range(50):
p = Process(target=task,)
l1.append(p)
p.start()
for p in l1:
p.join()
print(f'Executive efficiency:{time.time()- start_time}') # 4.41826057434082
#Multithread concurrency
start_time = time.time()
l1 = []
for i in range(50):
p = Thread(target=task,)
l1.append(p)
p.start()
for p in l1:
p.join()
print(f'Executive efficiency:{time.time()- start_time}') # 3.0294392108917236
# For IO-intensive: multi-threaded concurrency of a single process is efficient.Computing intensive:
from threading import Thread
from multiprocessing import Process
import time
def task():
count = 0
for i in range(10000000):
count += 1
if __name__ == '__main__':
#Multi-process concurrency and parallelism
start_time = time.time()
l1 = []
for i in range(4):
p = Process(target=task,)
l1.append(p)
p.start()
for p in l1:
p.join()
print(f'Executive efficiency:{time.time()- start_time}') # 1.1186981201171875
#Multithread concurrency
start_time = time.time()
l1 = []
for i in range(4):
p = Thread(target=task,)
l1.append(p)
p.start()
for p in l1:
p.join()
print(f'Executive efficiency:{time.time()- start_time}') # 2.729006767272949
# Summary: Computing intensive: multi-process concurrent and parallel efficiency.13. Multithread socket Communication
Whether it is multi-threaded or multi-process, if according to a client request, I will open a thread, a request to open a thread.
It should be like this: within your computer's permission, the more threads you open, the better.
Server
import socket
from threading import Thread
def communicate(conn,addr):
while 1:
try:
from_client_data = conn.recv(1024)
print(f'From the client{addr[1]}News: {from_client_data.decode("utf-8")}')
to_client_data = input('>>>').strip()
conn.send(to_client_data.encode('utf-8'))
except Exception:
break
conn.close()
def _accept():
server = socket.socket()
server.bind(('127.0.0.1', 8848))
server.listen(5)
while 1:
conn, addr = server.accept()
t = Thread(target=communicate,args=(conn,addr))
t.start()
if __name__ == '__main__':
_accept()Client
import socket
client = socket.socket()
client.connect(('127.0.0.1',8848))
while 1:
try:
to_server_data = input('>>>').strip()
client.send(to_server_data.encode('utf-8'))
from_server_data = client.recv(1024)
print(f'Messages from the server: {from_server_data.decode("utf-8")}')
except Exception:
break
client.close()
14. process pool, thread pool
Why put the process pool and thread pool together in order to unify the use of threadPollExecutor and ProcessPollExecutor in the same way, and as long as you import through this concurrent.futures, you can use both of them directly
Thread pool: A container that limits the number of threads you open, such as four
For the first time, it must be able to handle only four tasks concurrently. As long as a task is completed, the thread will take over the next task immediately.
Time for space.
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
import os
import time
import random
def task(n):
print(f'{os.getpid()} Receive visitors')
time.sleep(random.randint(1,3))
if __name__ == '__main__':
# Open the process pool (parallel (parallel + concurrent)
p = ProcessPoolExecutor() # By default, the number of processes in the process pool is equal to the number of CPUs
for i in range(20): #Publish 20 tasks, process processing of the number of CPUs
p.submit(task,i)from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
import os
import time
import random
def task(n):
print(f'{os.getpid()} Receive visitors')
time.sleep(random.randint(1,3))
if __name__ == '__main__':
# Open the process pool (parallel (parallel + concurrent)
p = ProcessPoolExecutor() # By default, the number of processes in the process pool is equal to the number of CPUs
for i in range(20): #Publish 20 tasks, process processing of the number of CPUs
p.submit(task,i)
15. Blocking, non-blocking, synchronous, asynchronous
Perspective of implementation
Blocking: When the program runs, it encounters IO and the program hangs CPU is cut off. Non-blocking: The program does not encounter IO, the program encounters IO, but through some means, let the cpu run my program forcibly.
Task submission Perspective
Synchronization: Submit a task, from the start of the task until the end of the task (possibly IO), after returning a return value, I submit the next task. Asynchronism: Submit multiple tasks at once, and then I execute the next line of code directly.
16. Synchronized call, asynchronous call
Asynchronous call
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import time
import random
import os
def task(i):
print(f'{os.getpid()}Start the Mission')
time.sleep(random.randint(1,3))
print(f'{os.getpid()}End of Mission')
return i
if __name__ == '__main__':
# Asynchronous call
pool = ProcessPoolExecutor()
for i in range(10):
pool.submit(task,i)
pool.shutdown(wait=True)
# shutdown: Let my main process wait for all the subprocesses in the process pool to finish their tasks and execute. It's a bit like join.
# shutdown: New tasks are not allowed until all tasks have been completed in the last process pool.
# A task is accomplished by a function whose return value is the return value of the function.
print('===main')Synchronized invocation
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import time
import random
import os
def task(i):
print(f'{os.getpid()}Start the Mission')
time.sleep(random.randint(1,3))
print(f'{os.getpid()}End of Mission')
return i
if __name__ == '__main__':
# Synchronized invocation
pool = ProcessPoolExecutor()
for i in range(10):
obj = pool.submit(task,i)
# An obj is a dynamic object that returns the state of the current object, which may be running, ready to block, or terminated.
# obj.result() must wait until the task is completed and the result is returned to perform the next task.
print(f'Task results:{obj.result()}')
pool.shutdown(wait=True)
print('===main') 17. Asynchronous call + callback function
The browser works by sending a request to the server, which verifies your request and returns a file to your browser if it is correct.
The browser receives the file and renders the code inside the file as beautiful and beautiful as you can see.
What is a reptile?
- Using code to simulate a browser, the browser's workflow is carried out to get a pile of source code.
- Clean the source code to get the data I want.
pip install requests
import requests
ret = requests.get('http://www.baidu.com')
if ret.status_code == 200:
print(ret.text)Based on the asynchronous call to reclaim the results of all tasks, I want to reclaim the results in real time.
The concurrent execution of each task only handles IO blocking, and can not add new functions.
Asynchronous call + callback function
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
import requests
def task(url):
'''The simulation is that crawling multiple source code must have IO operation'''
ret = requests.get(url)
if ret.status_code == 200:
return ret.text
def parse(obj):
'''Analog analysis of data is generally not available. IO'''
print(len(obj.result()))
if __name__ == '__main__':
# Open thread pool, concurrent and parallel execution
url_list = [
'http://www.baidu.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.taobao.com',
'https://www.cnblogs.com/jin-xin/articles/7459977.html',
'https://www.luffycity.com/',
'https://www.cnblogs.com/jin-xin/articles/9811379.html',
'https://www.cnblogs.com/jin-xin/articles/11245654.html',
'https://www.sina.com.cn/',
]
pool = ThreadPoolExecutor(4)
for url in url_list:
obj = pool.submit(task, url)
obj.add_done_callback(parse) #callback
'''
//Thread pool set up 4 threads, asynchronously initiate 10 tasks, each task is to obtain the source code through the web page, and concurrently execute.
//When a task is completed, the parse analysis code task is left to the remaining idle threads, which continue to process other tasks.
//If the process pool + callback: the callback function is executed by the main process.
//If the thread pool + callback: the return function is executed by the idle thread.
'''Is asynchronous callback the same thing?
Asynchronism stands at the point of view of publishing tasks.
From the point of view of receiving results, the callback function receives the results of each task in sequence and proceeds to the next step.
Asynchronous + callback:
IO type of asynchronous processing.
Callback processing non-IO
18. Thread queue queque
1. First in first out
import queue #FIFO q = queue.Queue(3) q.put(1) q.put(2) q.put(3) print(q.get()) print(q.get()) print(q.get()) # print(q.get(block=False))#Direct error reporting in case of blocking q.get(timeout=3) #Blocking 2 seconds without value directly reporting error
2. Last in, first out, stack
q =queue.LifoQueue(4) q.put(1) q.put(2) q.put(3) q.put(4) print(q.get()) print(q.get()) print(q.get()) print(q.get())
3. Priority queue
q = queue.PriorityQueue(4) q.put((5,"z")) q.put((0,"b")) q.put((-1,"2")) q.put((-1,"3")) #The same level does not generally exist according to accik code print(q.get()) print(q.get()) print(q.get()) print(q.get())
19. event events
Open two threads, one thread runs to a certain stage in the middle, triggering another thread to execute. The two threads increase coupling.
from threading import Thread,current_thread,Event
import time
event = Event()
def check():
print(f"{current_thread().name}Check whether the server is open")
time.sleep(3)
# print(event.is_set())#Judging whether set exists
event.set()
# print(event.is_set())#Display T after set
print('The server is on')
def connect():
print(f'{current_thread().name}Waiting for connection..')
event.wait() #After blocking knows event.set() is executed
# event.wait(1)#Blocking only 1 second, execution after 1 second
print(f"{current_thread().name}Successful connection")
t1 = Thread(target=check,)
t2 = Thread(target=connect,)
t1.start()
t2.start()20. Co-operation
COOPERATION: It is concurrent under single thread, also known as microthreading, fibre. The English name is Coroutine. One sentence explains what threads are: a coroutine is a user-mode lightweight thread, that is, the coroutine is scheduled by the user program itself.
Single cpu: 10 tasks, let you concurrently execute this 10 tasks for me:
1. Mode 1: Open multi-process concurrent execution, operating system switching + holding state. 2. Mode 2: Open multithreading and execute concurrently, and switch the operating system + keep state. 3. Mode 3: Open the concurrent execution of the program, and control the cpu to switch back and forth between the three tasks + keep state. Explain 3 in detail: The coprocess switches very fast, blinding the operating system's eyes, so that the operating system thinks that the cpu has been running your thread (coprocess.)
It should be emphasized that:
# 1. python's threads are at the kernel level, i.e. they are scheduled under the control of the operating system (for example, if a single thread encounters io or if the execution time is too long, it will be forced to surrender the cpu execution privileges and switch other threads to run). # 2. Open a process within a single thread, once you encounter io, you will control switching from application level (rather than operating system) to improve efficiency (!!! The switching of non-io operations is independent of efficiency.
Contrasting with the switching of operating system control threads, users control the switching of the consortium within a single thread
The advantages are as follows:
# 1. The switching overhead of the protocol is less, it belongs to the program level switching, and the operating system is completely imperceptible, so it is more lightweight. # 2. The concurrent effect can be achieved within a single thread, and the maximum use of cpu can be achieved.
The shortcomings are as follows:
# 1. The essence of a coroutine is that it can't use multiple cores in a single thread. It can be a program that opens multiple processes, multiple threads in each process, and coroutines in each thread.
Summarize the characteristics of the project:
- Concurrency must be implemented in only one single thread
- Modifying shared data without locking
- The context stack of multiple control flows is saved by the user program itself
1.Greenlet
If we have 20 tasks in a single thread, it's too cumbersome to use the yield generator to switch between multiple tasks (we need to initialize the generator once, then call send...). Very cumbersome), and using the greenlet module can easily switch these 20 tasks directly
#install pip3 install greenlet
# Switching + Holding State (No Active Switching When IO Encounters)
#The real collaboration module is the handover using greenlet
from greenlet import greenlet
def eat(name):
print('%s eat 1' %name) #2
g2.switch('taibai') #3
print('%s eat 2' %name) #6
g2.switch() #7
def play(name):
print('%s play 1' %name) #4
g1.switch() #5
print('%s play 2' %name) #8
g1=greenlet(eat)
g2=greenlet(play)
g1.switch('taibai')#You can pass in parameters at the first switch, and you don't need 1 later.At work:
In general, we are process + thread + co-process to achieve concurrency in order to achieve the best concurrency effect. If it is a 4-core cpu, there are usually five processes, 20 threads in each process (5 times the number of cpus), each thread can start 500 co-processes, waiting for network latency when crawling pages on a large scale. In time, we can use the concurrency process to achieve concurrency. The number of concurrencies = 5 * 20 * 500 = 50,000 concurrencies, which is the largest number of concurrencies for a general 4 CPU machine. The maximum load-carrying capacity of nginx in load balancing is 5w
The code of these 20 tasks in a single thread usually has both computational and blocking operations. We can use blocking time to execute task 2 when we encounter blocking in task 1. Only in this way can we improve efficiency, which uses the Gevent module.
2.Gevent
#install pip3 install gevent
Gevent is a third-party library that can easily implement concurrent synchronous or asynchronous programming through gevent. The main mode used in gevent is Greenlet, which is a lightweight protocol that accesses Python in the form of C extension module. Greenlet runs entirely within the main operating system processes, but they are scheduled collaboratively.
usage
g1=gevent.spawn(func,1,2,3,x=4,y=5)Create a collaboration object g1,spawn The first parameter in parentheses is the function name, such as eat,There can be multiple parameters later, either positional or keyword arguments, which are passed to the function. eat , spawn Is an asynchronous submission task g2=gevent.spawn(func2) g1.join() #Waiting for g1 to end g2.join() #Waiting for G2 to finish someone's test will find that you can do G2 without writing a second join. Yes, the coordinator will help you switch the execution, but you will find that if the tasks in G2 take a long time to execute, but if you don't write a join, you won't finish the remaining tasks waiting for g2. #Or the two steps above: gevent.joinall([g1,g2]) g1.value#Get the return value of func1
Final version
import gevent
from gevent import monkey
monkey.patch_all() # Patch: Mark the blockages of all the tasks below
def eat(name):
print('%s eat 1' %name)
time.sleep(2)
print('%s eat 2' %name)
def play(name):
print('%s play 1' %name)
time.sleep(1)
print('%s play 2' %name)
g1 = gevent.spawn(eat,'egon')
g2 = gevent.spawn(play,name='egon')
# g1.join()
# g2.join()
gevent.joinall([g1,g2])