Introduction background of thread concept
process
We have known the concept of process in the operating system before. The program cannot run alone. Only when the program is loaded into memory, the system allocates resources for it, and this executed program is called a process. The difference between a program and a process is that a program is a collection of instructions, which is the static description text of the process; Process is an execution activity of program, which belongs to dynamic concept. In multiprogramming, we allow multiple programs to be loaded into memory at the same time, which can be executed concurrently under the scheduling of the operating system. This is such a design, which greatly improves the utilization of CPU. The emergence of process makes each user feel that they have exclusive CPU. Therefore, process is proposed to realize multi-channel programming on CPU.
Why should there be threads when there are processes
Process has many advantages. It provides multi-channel programming, which makes us feel that each of us has our own CPU and other resources, which can improve the utilization of the computer. Many people don't understand. Since the process is so excellent, why thread? In fact, after careful observation, we will find that there are still many defects in the process, which are mainly reflected in two points:
- The process can only do one thing at a time. If you want to do two or more things at the same time, the process can't do anything.
- If a process is blocked during execution, such as waiting for input, the whole process will hang. Even if some work in the process does not depend on the input data, it will not be executed.
If it is difficult to understand these two shortcomings, you may know by taking a practical example: if we regard the process of our class as a process, what we have to do is to listen to the teacher, take notes in our hands and think about problems in our brain, so as to effectively complete the task of listening to the class. If only the process mechanism is provided, the above three things cannot be executed at the same time. You can only do one thing at a time. You can't take notes or think with your brain when listening. This is one of them; If the teacher writes the calculation process on the blackboard, we begin to take notes, and the teacher suddenly can't push down one step and blocks it. He is thinking over there, and we can't do anything else. Even if you want to think about a problem you didn't understand just now, this is the second.
Now you should understand the defects of the process, and the solution is very simple. We can make the three independent processes of listening, writing and thinking work in parallel, which can obviously improve the efficiency of listening. In the actual operating system, this similar mechanism thread is also introduced.
Thread appearance
In the 1960s, the basic unit that can have resources and run independently in OS is process. However, with the development of computer technology, process has many disadvantages. First, because process is the owner of resources, there is a large space-time cost in creation, revocation and switching, so it is necessary to introduce light process; Second, due to the emergence of symmetric multiprocessor (SMP), it can meet multiple running units, and the parallel overhead of multiple processes is too large.
Therefore, in the 1980s, there appeared a basic unit that can run independently - Threads.
Note: process is the smallest unit of resource allocation, and thread is the smallest unit of CPU scheduling
There is at least one thread in each process.
Relationship between process and thread
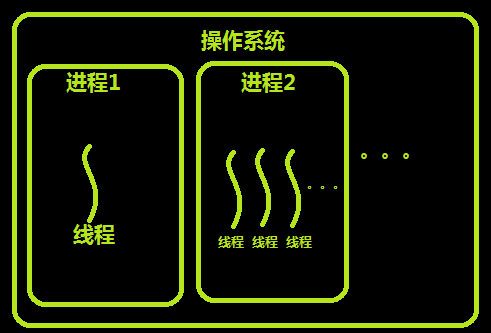
The differences between threads and processes can be summarized as follows:
1) address space and other resources (such as open files): processes are independent and shared among threads of the same process. Threads within one process are not visible to other processes.
2) communication: interprocess communication IPC. Threads can directly read and write process data segments (such as global variables) for communication - process synchronization and mutual exclusion are required to ensure data consistency.
3) scheduling and switching: thread context switching is much faster than process context switching.
4) in a multithreaded operating system, a process is not an executable entity.
* understand the thread into the city through comics
Thread characteristics
In a multithreaded operating system, it usually includes multiple threads in a process. Each thread is the basic unit of CPU utilization and the entity with the least overhead. The thread has the following properties.
1) light entity
The entities in the thread basically do not have system resources, but have some essential resources that can ensure independent operation.
Thread entities include programs, data, and TCB. Thread is a dynamic concept, and its dynamic characteristics are described by Thread Control Block (TCB).
TCB Include the following information: (1)Thread status. (2)The field resource that is saved when the thread is not running. (3)A set of execution stacks. (4)The main memory area for storing local variables of each thread. (5)Access to main memory and other resources in the same process. A set of registers and stacks used to indicate the program counter of the executed instruction sequence, reserved local variables, a few status parameters, return addresses, etc.
2) The basic unit of independent scheduling and dispatch.
In multithreaded OS, thread is the basic unit that can run independently, so it is also the basic unit of independent scheduling and dispatching. Because threads are "light", thread switching is very fast and low overhead (in the same process).
3) share process resources.
Each thread in the same process can share the resources owned by the process. Firstly, all threads have the same process id, which means that threads can access each memory resource of the process; In addition, you can also access the open files, timers, semaphore mechanisms, etc. owned by the process. Because threads in the same process share memory and files, threads communicate with each other without calling the kernel.
4) it can be executed concurrently.
Multiple threads in a process can execute concurrently, and even all threads in a process can execute concurrently; Similarly, threads in different processes can also execute concurrently, making full use of and giving full play to the ability of the processor to work in parallel with peripheral devices.
Actual scenario using threads
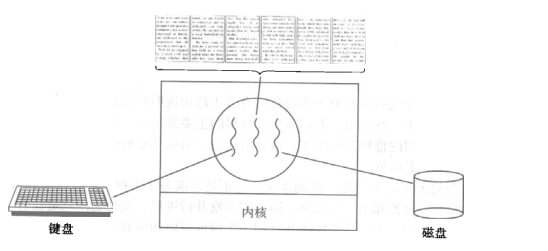
To start a word processing software process, the process must do more than one thing, such as monitoring keyboard input, processing text, and automatically saving text to the hard disk regularly. These three tasks operate on the same piece of data, so multiple processes cannot be used. Only three threads can be opened concurrently in one process. If it is a single thread, it can only be that text cannot be processed and automatically saved during keyboard input, and text cannot be input and processed during automatic saving.
Threads in memory
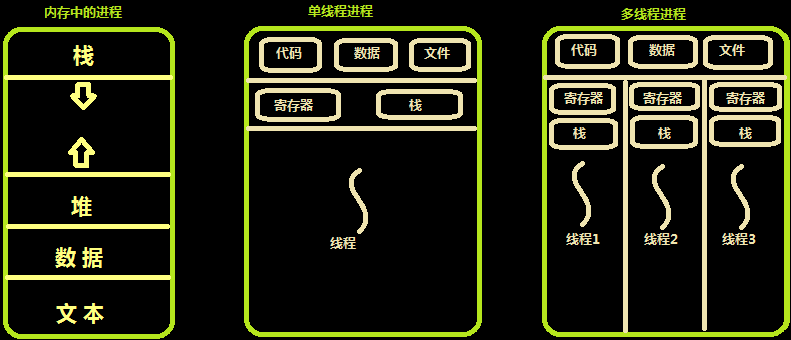
Multiple threads share resources in the address space of the same process. It is a simulation of multiple processes on a computer. Sometimes, threads are called lightweight processes.
For multiple processes on a computer, other physical resources such as physical memory, disk, printer and so on are shared. Multithreading is similar to multithreading. It is the fast switching of cpu between multiple threads.
Different processes are hostile to each other and compete for cpu. If Xunlei will grab resources with QQ. The same process is created by a programmer's program, so threads in the same process are cooperative. One thread can access the memory address of another thread, which is shared by everyone. If one thread kills the memory of another thread, it is purely a programmer's brain problem.
Similar to a process, each thread also has its own stack. Unlike a process, the thread library cannot use clock interrupts to force the thread to give up the CPU, and thread can be called_ The yield running thread automatically abandons the CPU and lets another thread run.
Thread is usually beneficial, but it brings great difficulty in small program design. The problem of thread is:
1. If the parent process has multiple threads, does the child thread need the same number of threads
2. In the same process, what if one thread closes the file and another thread is preparing to write content to the file?
Therefore, in multithreaded code, more attention is needed to design program logic and protect program data.
User level threads and kernel level threads (understand)
The implementation of threads can be divided into two categories: user level thread and kernel level thread. The latter is also called kernel supported thread or lightweight process. In multi-threaded operating systems, the implementation methods of each system are different. User level threads are implemented in some systems and kernel level threads are implemented in some systems.
User level thread
The kernel switching is controlled by the user state program itself. The kernel switching does not need kernel interference, which reduces the consumption of entering and leaving the kernel state, but it can not make good use of multi-core Cpu.
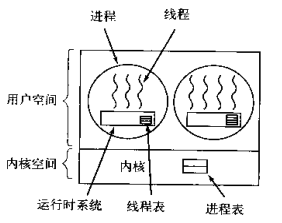
Simulate the scheduling of processes by the operating system in user space to call threads in a process. There will be a runtime system in each process to schedule threads. At this time, when the process obtains the cpu, another thread is scheduled to execute in the process, and only one thread executes at the same time.
Kernel level thread
Kernel level thread: switching is controlled by the kernel. When the thread is switched, it is transformed from user state to kernel state. After switching, return from kernel state to user state; Can make good use of smp, that is, the use of multi-core cpu. windows threads are like this.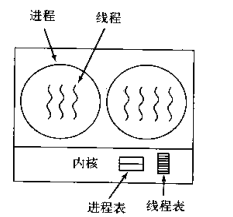
Comparison between user level and kernel level threads
The difference between user level threads and kernel level threads 1 Kernel supported threads are OS The kernel is aware, while user level threads are OS The kernel is not perceptible. 2 The creation, undo, and scheduling of user level threads do not require OS Kernel support is in languages such as Java)At this level; The kernel supports thread creation, undo and scheduling OS The kernel provides support and is roughly the same as process creation, undo, and scheduling. 3 When a user level thread executes a system call instruction, it will cause its process to be interrupted, while when the kernel supports the thread to execute a system call instruction, it will only cause the thread to be interrupted. 4 In a system with only user level threads, CPU Scheduling is also based on the process as a unit. The user program controls the rotation of multiple threads in the running process; In systems with kernel supported threads, CPU Scheduling is based on threads OS The thread scheduler is responsible for thread scheduling. 5 The program entity of user level thread is the program running in user state, while the program entity of kernel supporting thread is the program that can run in any state.
Advantages and disadvantages of kernel threads Advantages: when there are multiple processors, multiple threads of a process can execute at the same time. Disadvantages: scheduling by the kernel.
Advantages and disadvantages of user level threads advantage: Thread scheduling does not need the direct participation of the kernel, and the control is simple. It can be implemented in an operating system that does not support threads. The cost of thread management such as creating and destroying threads and thread switching is much less than that of kernel threads. Each process is allowed to customize its own scheduling algorithm, and thread management is more flexible. Threads can utilize more table space and stack space than kernel level threads. Only one thread can be running at the same time in the same process. If one thread is blocked by using system call, the whole process will be suspended. In addition, page failure can cause the same problem. Disadvantages: Resource scheduling is carried out according to the process. Under multiple processors, threads in the same process can only be reused in time sharing under the same processor
Hybrid implementation
User level and kernel level multiplexing. The kernel schedules the same kernel thread, and each kernel thread corresponds to n user threads
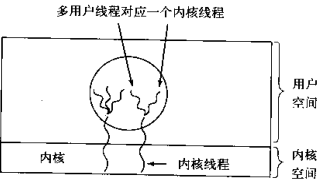
NPTL of linux operating system
history
Before kernel 2.6, the scheduling entities were all processes, and the kernel did not really support threads. It can be implemented through a system call clone(). This call creates a copy of the calling process. Unlike fork(), this process copy completely shares the address space of the calling process. Linux thread is used to provide thread support at the kernel level through this system call (many previous thread implementations are completely in the user state, and the kernel does not know the existence of threads at all). Unfortunately, this method does not follow POSIX standard in many places, especially in signal processing, scheduling, interprocess communication primitives and so on.
Obviously, in order to improve Linux thread, it must be supported by the kernel and the thread library needs to be rewritten. In order to realize this demand, there are two competing projects: the NGTP(Next Generation POSIX Threads) project launched by IBM and the NPTL of Redhat company. In the middle of 2003, IBM abandoned NGTP, that is, about that time, Redhat released the original NPTL.
NPTL was first released in redhat linux 9. Now NPTL is supported from RHEL3 to kernel 2.6, and has completely become a part of GNU C library.
introduce Design NPTL Used with LinuxThread In the same way, the thread is still regarded as a process in the kernel and is still used clone()system call(stay NPTL Library call). But, NPTL Special kernel level support is required, such as thread synchronization primitives that need to suspend and then wake up threads futex. NPTL It's also a 1*1 The thread library, that is, when you use pthread_create()After calling to create a thread, a scheduling entity is created in the kernel linux Is a new process. This method simplifies the implementation of threads as much as possible. except NPTL Of 1*1 There is another one outside the model m*n Model, usually the number of user threads in this model will be more than the scheduling entity of the kernel. In this implementation, the thread library itself must handle the possible scheduling, so the context switching within the thread library is usually quite fast, because it avoids the system call from turning to the kernel state. However, this model increases the complexity of thread implementation,In addition, how to coordinate the user state scheduling with the kernel state scheduling is also difficult to satisfy people.
Threads and python
Theoretical knowledge
Global interpreter lock GIL
The execution of Python code is controlled by the python virtual machine (also known as the interpreter main loop). Python was designed to have only one thread executing in the main loop at the same time. Although multiple threads can be "run" in the Python interpreter, only one thread runs in the interpreter at any time.
Access to the Python virtual machine is controlled by the global interpreter lock (GIL), which ensures that only one thread is running at the same time.
In a multithreaded environment, the Python virtual machine executes as follows:
a. Set GIL;
b. Switch to a thread to run;
c. Run a specified number of bytecode instructions or the thread actively gives up control (you can call time.sleep(0));
d. Set the thread to sleep state;
e. Unlock GIL;
d. Repeat all the above steps again.
When calling external code (such as C/C + + extension function), the GIL will be locked until the end of the function (since there is no Python bytecode running during this period, there will be no thread switching). Programmers writing extensions can actively unlock the GIL.
features: 1.GIL yes Cpython Characteristics of interpreter 2.python Multiple threads in the same process cannot take advantage of multi-core(Cannot be parallel but can be concurrent) 3.If multiple threads in the same process want to run, they must be robbed first GIL lock 4.Almost all interpretative languages can't run multiple threads in the same process at the same time
Selection of python thread module
Python provides several modules for multithreading programming, including thread, threading and Queue. The thread and threading modules allow programmers to create and manage threads. Thread module provides basic thread and lock support, and threading provides higher-level and more powerful thread management functions. The Queue module allows users to create a Queue data structure that can be used to share data between multiple threads.
Avoid using the thread module, because the higher-level threading module is more advanced and has better support for threads, and using the attributes in the thread module may conflict with threading; Secondly, the low-level thread module has few synchronization primitives (actually only one), while the threading module has many; Moreover, in the thread module, when the main thread ends, all threads will be forced to end, and there will be no normal clearing without warning. At least the threading module can ensure that the process exits only after the important sub threads exit.
The thread module does not support daemon threads. When the main thread exits, all child threads will be forcibly exited, whether they are still working or not. The threading module supports daemon threads. A daemon thread is generally a server waiting for a customer's request. If no customer requests, it will wait there. If a thread is set as a daemon thread, it means that the thread is unimportant. When the process exits, you don't have to wait for the thread to exit.
threading module
The multiprocess module completely imitates the interface of the threading module. They are very similar in use, so they will not be introduced in detail (official link)
Thread creation Thread class
Thread creation
How to create a thread 1
from threading import Thread
import time
def sayhi(name):
time.sleep(2)
print('%s say hello' %name)
if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.start()
print('Main thread')
How to create a thread 2
from threading import Thread
import time
class Sayhi(Thread):
def __init__(self,name):
super().__init__()
self.name=name
def run(self):
time.sleep(2)
print('%s say hello' % self.name)
if __name__ == '__main__':
t = Sayhi('egon')
t.start()
print('Main thread')
Multithreading and multiprocessing
pid Comparison of
from threading import Thread
from multiprocessing import Process
import os
def work():
print('hello',os.getpid())
if __name__ == '__main__':
#part1: start multiple threads under the main process, and each thread is the same as the pid of the main process
t1=Thread(target=work)
t2=Thread(target=work)
t1.start()
t2.start()
print('Main thread/Main process pid',os.getpid())
#part2: open multiple processes, and each process has a different pid
p1=Process(target=work)
p2=Process(target=work)
p1.start()
p2.start()
print('Main thread/Main process pid',os.getpid())
Contest of opening efficiency
from threading import Thread
from multiprocessing import Process
import os
def work():
print('hello')
if __name__ == '__main__':
#Start thread under main process
t=Thread(target=work)
t.start()
print('Main thread/Main process')
'''
Print results:
hello
Main thread/Main process
'''
#Start the child process under the main process
t=Process(target=work)
t.start()
print('Main thread/Main process')
'''
Print results:
Main thread/Main process
hello
'''
Memory data sharing problem
from threading import Thread
from multiprocessing import Process
import os
def work():
global n
n=0
if __name__ == '__main__':
# n=100
# p=Process(target=work)
# p.start()
# p.join()
# print('main',n) #There is no doubt that the child process p has changed its global n to 0, but only its own. Check that the parent process's n is still 100
n=1
t=Thread(target=work)
t.start()
t.join()
print('main',n) #The view result is 0 because the data in the same process is shared between threads in the same process
Do threads in the same process share data from that process?
Exercise: multithreading socket
server
#_*_coding:utf-8_*_
#!/usr/bin/env python
import multiprocessing
import threading
import socket
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.bind(('127.0.0.1',8080))
s.listen(5)
def action(conn):
while True:
data=conn.recv(1024)
print(data)
conn.send(data.upper())
if __name__ == '__main__':
while True:
conn,addr=s.accept()
p=threading.Thread(target=action,args=(conn,))
p.start()
client
#_*_coding:utf-8_*_
#!/usr/bin/env python
import socket
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.connect(('127.0.0.1',8080))
while True:
msg=input('>>: ').strip()
if not msg:continue
s.send(msg.encode('utf-8'))
data=s.recv(1024)
print(data)
Other methods of the Thread class
Thread Method of instance object # isAlive(): Returns whether the thread is active. # getName(): returns the thread name. # setName(): sets the thread name. threading Some methods provided by the module: # threading.currentThread(): returns the current thread variable. # threading.enumerate(): returns a list of running threads. Running refers to threads after starting and before ending, excluding threads before starting and after termination. # threading.activeCount(): returns the number of running threads, with the same result as len(threading.enumerate()).
Code example
from threading import Thread
import threading
from multiprocessing import Process
import os
def work():
import time
time.sleep(3)
print(threading.current_thread().getName())
if __name__ == '__main__':
#Start thread under main process
t=Thread(target=work)
t.start()
print(threading.current_thread().getName())
print(threading.current_thread()) #Main thread
print(threading.enumerate()) #There are two running threads, including the main thread
print(threading.active_count())
print('Main thread/Main process')
'''
Print results:
MainThread
<_MainThread(MainThread, started 140735268892672)>
[<_MainThread(MainThread, started 140735268892672)>, <Thread(Thread-1, started 123145307557888)>]
Main thread/Main process
Thread-1
'''
join method
from threading import Thread
import time
def sayhi(name):
time.sleep(2)
print('%s say hello' %name)
if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.start()
t.join()
print('Main thread')
print(t.is_alive())
'''
egon say hello
Main thread
False
'''
Daemon
Both processes and threads follow: the guard xx will wait for the main xx to be destroyed after running. It should be emphasized that the completion of operation is not the termination of operation
#1. For the main process, running completion refers to the completion of the main process code #2. For the main thread, running completion means that all non daemon threads in the process where the main thread is located have finished running, and the main thread is considered to have finished running
explicate #1. The main process is finished running after its code is finished (the daemon is recycled at this time), and then the main process will wait until the non daemon sub processes are finished running to recycle the resources of the sub processes (otherwise, a zombie process will be generated), #2. The main thread runs only after other non daemon threads run (the daemon thread is recycled at this time). Because the end of the main thread means the end of the process, the overall resources of the process will be recycled, and the process must ensure that all non daemon threads run before it can end.
Daemon case 1
from threading import Thread
import time
def sayhi(name):
time.sleep(2)
print('%s say hello' %name)
if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.setDaemon(True) #Must be set before t.start()
t.start()
print('Main thread')
print(t.is_alive())
'''
Main thread
True
'''
Daemon case 2
from threading import Thread
import time
def foo():
print(123)
time.sleep(1)
print("end123")
def bar():
print(456)
time.sleep(3)
print("end456")
t1=Thread(target=foo)
t2=Thread(target=bar)
t1.daemon=True
t1.start()
t2.start()
print("main-------")
lock
Lock and GIL
Synchronous lock
Resource preemption by multiple threads
from threading import Thread
import os,time
def work():
global n
temp=n
time.sleep(0.1)
n=temp-1
if __name__ == '__main__':
n=100
l=[]
for i in range(100):
p=Thread(target=work)
l.append(p)
p.start()
for p in l:
p.join()
print(n) #The result could be 99
import threading R=threading.Lock() R.acquire() ''' Operations on public data ''' R.release()
Synchronous lock reference
from threading import Thread,Lock
import os,time
def work():
global n
lock.acquire()
temp=n
time.sleep(0.1)
n=temp-1
lock.release()
if __name__ == '__main__':
lock=Lock()
n=100
l=[]
for i in range(100):
p=Thread(target=work)
l.append(p)
p.start()
for p in l:
p.join()
print(n) #The result must be 0, which changes from concurrent execution to serial execution, sacrificing execution efficiency and ensuring data security
Mutex and join Differences between
#No lock: concurrent execution, fast speed and unsafe data
from threading import current_thread,Thread,Lock
import os,time
def task():
global n
print('%s is running' %current_thread().getName())
temp=n
time.sleep(0.5)
n=temp-1
if __name__ == '__main__':
n=100
lock=Lock()
threads=[]
start_time=time.time()
for i in range(100):
t=Thread(target=task)
threads.append(t)
t.start()
for t in threads:
t.join()
stop_time=time.time()
print('main:%s n:%s' %(stop_time-start_time,n))
'''
Thread-1 is running
Thread-2 is running
......
Thread-100 is running
main:0.5216062068939209 n:99
'''
#No lock: the unlocked part is executed concurrently, and the locked part is executed serially, with slow speed and data security
from threading import current_thread,Thread,Lock
import os,time
def task():
#Unlocked code runs concurrently
time.sleep(3)
print('%s start to run' %current_thread().getName())
global n
#The locked code runs serially
lock.acquire()
temp=n
time.sleep(0.5)
n=temp-1
lock.release()
if __name__ == '__main__':
n=100
lock=Lock()
threads=[]
start_time=time.time()
for i in range(100):
t=Thread(target=task)
threads.append(t)
t.start()
for t in threads:
t.join()
stop_time=time.time()
print('main:%s n:%s' %(stop_time-start_time,n))
'''
Thread-1 is running
Thread-2 is running
......
Thread-100 is running
main:53.294203758239746 n:0
'''
#Some may have questions: since locking will turn the operation into serial, I use join immediately after start, so I don't need to lock. It's also the effect of serial
#Yes: using jion immediately after start will certainly turn the execution of 100 tasks into serial. There is no doubt that the final result of n must be 0, which is safe, but the problem is
#join immediately after start: all codes in the task are executed serially, and locking is only the locked part, that is, the part that modifies the shared data is serial
#In terms of data security, both can be realized, but locking is obviously more efficient
from threading import current_thread,Thread,Lock
import os,time
def task():
time.sleep(3)
print('%s start to run' %current_thread().getName())
global n
temp=n
time.sleep(0.5)
n=temp-1
if __name__ == '__main__':
n=100
lock=Lock()
start_time=time.time()
for i in range(100):
t=Thread(target=task)
t.start()
t.join()
stop_time=time.time()
print('main:%s n:%s' %(stop_time-start_time,n))
'''
Thread-1 start to run
Thread-2 start to run
......
Thread-100 start to run
main:350.6937336921692 n:0 #How time-consuming it is
'''
Deadlock and recursive lock
The process also has deadlocks and recursive locks. I forgot to say it in the process. I said everything here
Deadlock refers to the phenomenon that two or more processes or threads wait for each other due to competing for resources during execution. If there is no external force, they will not be able to move forward. At this time, it is said that the system is in a deadlock state or the system has a deadlock. These processes that are always waiting for each other are called deadlock processes. The following are deadlock processes
deadlock from threading import Lock as Lock import time mutexA=Lock() mutexA.acquire() mutexA.acquire() print(123) mutexA.release() mutexA.release()
The solution is recursive lock. In Python, in order to support multiple requests for the same resource in the same thread, python provides a reentrant lock RLock.
This RLock internally maintains a Lock and a counter variable. The counter records the number of times to acquire, so that resources can be require d multiple times. Until all acquires of one thread are release d, other threads can obtain resources. In the above example, if RLock is used instead of Lock, deadlock will not occur:
Recursive lock Plock from threading import RLock as Lock import time mutexA=Lock() mutexA.acquire() mutexA.acquire() print(123) mutexA.release() mutexA.release()
Typical problem: scientists eat noodles
Deadlock problem
import time
from threading import Thread,Lock
noodle_lock = Lock()
fork_lock = Lock()
def eat1(name):
noodle_lock.acquire()
print('%s Grabbed the noodles'%name)
fork_lock.acquire()
print('%s Grabbed the fork'%name)
print('%s Eat noodles'%name)
fork_lock.release()
noodle_lock.release()
def eat2(name):
fork_lock.acquire()
print('%s Grabbed the fork' % name)
time.sleep(1)
noodle_lock.acquire()
print('%s Grabbed the noodles' % name)
print('%s Eat noodles' % name)
noodle_lock.release()
fork_lock.release()
for name in ['nezha','egon','yuan']:
t1 = Thread(target=eat1,args=(name,))
t2 = Thread(target=eat2,args=(name,))
t1.start()
t2.start()
Recursive lock to solve deadlock problem
import time
from threading import Thread,RLock
fork_lock = noodle_lock = RLock()
def eat1(name):
noodle_lock.acquire()
print('%s Grabbed the noodles'%name)
fork_lock.acquire()
print('%s Grabbed the fork'%name)
print('%s Eat noodles'%name)
fork_lock.release()
noodle_lock.release()
def eat2(name):
fork_lock.acquire()
print('%s Grabbed the fork' % name)
time.sleep(1)
noodle_lock.acquire()
print('%s Grabbed the noodles' % name)
print('%s Eat noodles' % name)
noodle_lock.release()
fork_lock.release()
for name in ['nezha','egon','yuan']:
t1 = Thread(target=eat1,args=(name,))
t2 = Thread(target=eat2,args=(name,))
t1.start()
t2.start()
Thread queue
Queue queue: use import queue. The usage is the same as process queue
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
class queue.Queue(maxsize=0) # FIFO
fifo
import queue
q=queue.Queue()
q.put('first')
q.put('second')
q.put('third')
print(q.get())
print(q.get())
print(q.get())
'''
result(fifo):
first
second
third
'''
class queue.LifoQueue(maxsize=0) #last in fisrt out
Last in first out
import queue
q=queue.LifoQueue()
q.put('first')
q.put('second')
q.put('third')
print(q.get())
print(q.get())
print(q.get())
'''
result(Last in first out):
third
second
first
'''
class queue.PriorityQueue(maxsize=0) # a queue whose priority can be set when storing data
Priority queue import queue q=queue.PriorityQueue() #put enters a tuple. The first element of the tuple is the priority (usually a number or a comparison between non numbers). The smaller the number, the higher the priority q.put((20,'a')) q.put((10,'b')) q.put((30,'c')) print(q.get()) print(q.get()) print(q.get()) ''' result(The smaller the number, the higher the priority,Those with high priority will be out of the team first): (10, 'b') (20, 'a') (30, 'c') '''
Python standard module – concurrent futures
https://docs.python.org/dev/library/concurrent.futures.html
#1 Introduction concurrent.futures The module provides a highly encapsulated asynchronous call interface ThreadPoolExecutor: Thread pool, providing asynchronous calls ProcessPoolExecutor: Process pool, providing asynchronous calls Both implement the same interface, which is defined by the abstract Executor class. #2 basic methods #submit(fn, *args, **kwargs) Asynchronous task submission #map(func, *iterables, timeout=None, chunksize=1) replace for loop submit Operation of #shutdown(wait=True) Equivalent to process pool pool.close()+pool.join()operation wait=True,Wait until all tasks in the pool are completed and resources are recovered before continuing wait=False,Return immediately without waiting for the tasks in the pool to complete But no matter wait What is the value of the parameter? The whole program will wait until all tasks are executed submit and map Must be shutdown before #result(timeout=None) Achieve results #add_done_callback(fn) Callback function# done()Determine whether a thread is completed# Cancel() cancels a task
**ProcessPoolExecutor**
#introduce
The ProcessPoolExecutor class is an Executor subclass that uses a pool of processes to execute calls asynchronously. ProcessPoolExecutor uses the multiprocessing module, which allows it to side-step the Global Interpreter Lock but also means that only picklable objects can be executed and returned.
class concurrent.futures.ProcessPoolExecutor(max_workers=None, mp_context=None)
An Executor subclass that executes calls asynchronously using a pool of at most max_workers processes. If max_workers is None or not given, it will default to the number of processors on the machine. If max_workers is lower or equal to 0, then a ValueError will be raised.
#usage
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
import os,time,random
def task(n):
print('%s is runing' %os.getpid())
time.sleep(random.randint(1,3))
return n**2
if __name__ == '__main__':
executor=ProcessPoolExecutor(max_workers=3)
futures=[]
for i in range(11):
future=executor.submit(task,i)
futures.append(future)
executor.shutdown(True)
print('+++>')
for future in futures:
print(future.result())
**ThreadPoolExecutor** #introduce ThreadPoolExecutor is an Executor subclass that uses a pool of threads to execute calls asynchronously. class concurrent.futures.ThreadPoolExecutor(max_workers=None, thread_name_prefix='') An Executor subclass that uses a pool of at most max_workers threads to execute calls asynchronously. Changed in version 3.5: If max_workers is None or not given, it will default to the number of processors on the machine, multiplied by 5, assuming that ThreadPoolExecutor is often used to overlap I/O instead of CPU work and the number of workers should be higher than the number of workers for ProcessPoolExecutor. New in version 3.6: The thread_name_prefix argument was added to allow users to control the threading.Thread names for worker threads created by the pool for easier debugging. #usage And ProcessPoolExecutor identical
**map Usage of**
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
import os,time,random
def task(n):
print('%s is runing' %os.getpid())
time.sleep(random.randint(1,3))
return n**2
if __name__ == '__main__':
executor=ThreadPoolExecutor(max_workers=3)
# for i in range(11):
# future=executor.submit(task,i)
executor.map(task,range(1,12)) #map replaces for+submit
**Callback function**
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
from multiprocessing import Pool
import requests
import json
import os
def get_page(url):
print('<process%s> get %s' %(os.getpid(),url))
respone=requests.get(url)
if respone.status_code == 200:
return {'url':url,'text':respone.text}
def parse_page(res):
res=res.result()
print('<process%s> parse %s' %(os.getpid(),res['url']))
parse_res='url:<%s> size:[%s]\n' %(res['url'],len(res['text']))
with open('db.txt','a') as f:
f.write(parse_res)
if __name__ == '__main__':
urls=[
'https://www.baidu.com',
'https://www.python.org',
'https://www.openstack.org',
'https://help.github.com/',
'http://www.sina.com.cn/'
]
# p=Pool(3)
# for url in urls:
# p.apply_async(get_page,args=(url,),callback=pasrse_page)
# p.close()
# p.join()
p=ProcessPoolExecutor(3)
for url in urls:
p.submit(get_page,url).add_done_callback(parse_page) #parse_page gets a future object obj, which needs to be used Result() gets the result