Understanding of using distributed locks
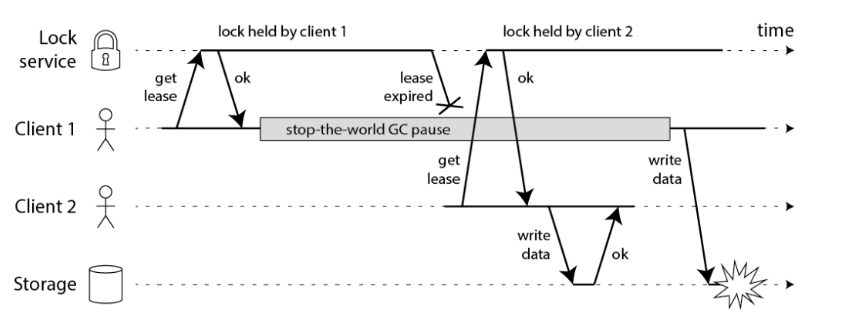
Each distributed lock has its advantages and disadvantages. In extreme cases, such as NPC, there may be wrong results and it is unsafe, as shown in the figure below (both clients think they have obtained the lock),
NPC refers to Network Delay; Process Pause, Process Pause (GC) [such as JAVA GC]; Clock Drift) is one of the three mountains that distributed systems will encounter
When using distributed locks, the following two ideas need to be combined, which can meet the requirements for most business scenarios
1. The distributed lock is used to achieve the purpose of "mutual exclusion" at the upper layer. Although the lock will fail in extreme cases, it can block concurrent requests at the top layer to the greatest extent and reduce the pressure on the operating resource layer.
2. However, for businesses that require absolutely correct data, it is necessary to "reveal the bottom" in the resource layer. For example, using the pessimistic lock of the database, the design idea can learn from the scheme of fecing token.
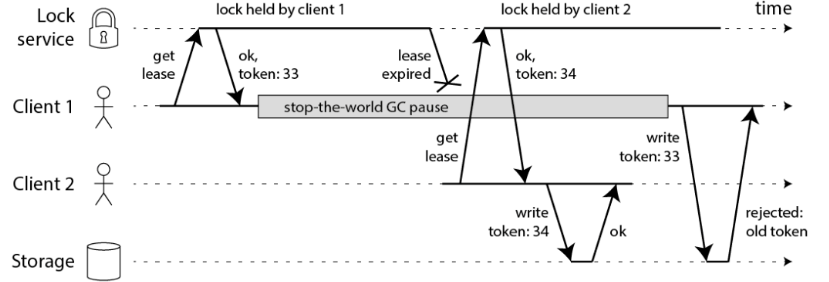
Locking token scheme
Martin proposed a scheme called fecing token to ensure the correctness of distributed locks. This scheme is similar to the implementation scheme of database optimistic lock.
The process of this model is as follows. In this way, the security of distributed locks can be guaranteed no matter what kind of exception occurs in NPC, because it is based on the "asynchronous model".
-
When a client obtains a lock, the lock service can provide an "incremental" token
-
The client takes this token to operate the shared resources
-
Shared resources can reject the "latecomer" request according to the token
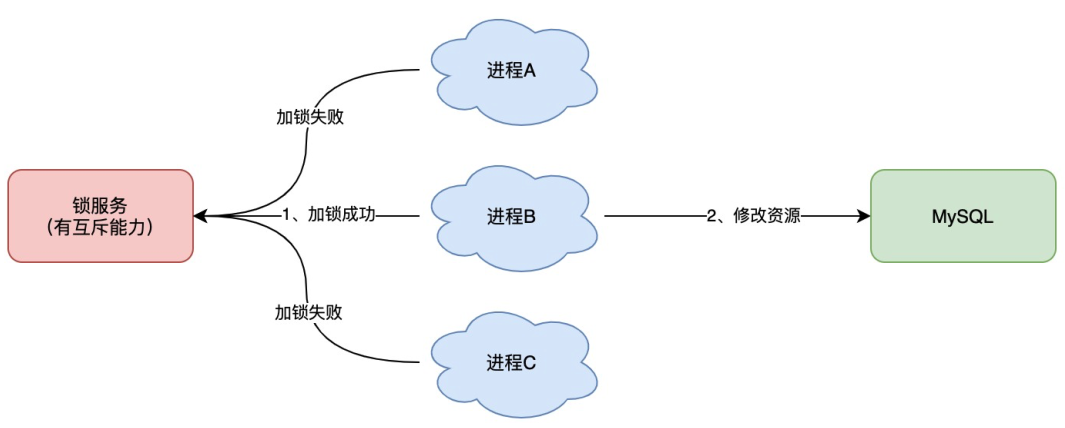
1. Distributed lock
1.1. Causes
In a single application, all applications run in a JAVA process. Based on various locks provided by JAVA, we can deal with the problem of multithreading concurrent processing.
However, with the needs of business development, the system of the original single application is evolved into a distributed system [composed of different JAVA processes distributed on different machines], which invalidates the concurrency control lock strategy in the case of the original single application. In order to solve this problem, a cross JVM mutual exclusion mechanism is needed to control the access to shared resources, which is the problem to be solved by the distributed lock!
At present, almost many large websites and applications are deployed distributed, and the data consistency in distributed scenarios has always been an important topic.
The distributed CAP theory tells us that "no distributed system can meet Consistency, Availability and Partition tolerance at the same time. At most, it can only meet two requirements at the same time." Therefore, many systems have to choose between these three at the beginning of design. In most scenarios in the Internet field, strong Consistency needs to be sacrificed in exchange for high Availability of the system. The system often only needs to ensure "final Consistency", as long as the final time is within the range acceptable to users
1.2. What conditions should be met
Let's first understand what conditions a distributed lock should have:
-
In the distributed system environment, a method can only be executed by one thread of one machine at the same time;
-
High availability acquisition lock and release lock;
-
High performance acquisition lock and release lock;
-
Reentrant feature;
-
Have lock failure mechanism to prevent deadlock;
-
It has the non blocking lock feature, that is, if the lock is not obtained, it will directly return to the failure of obtaining the lock.
1.3. Common implementation methods
-
Realize distributed lock based on database;
-
Implement distributed lock based on cache (Redis, etc.);
-
Implement distributed lock based on Zookeeper;
2. Implementation of distributed lock
2.1. Database implementation
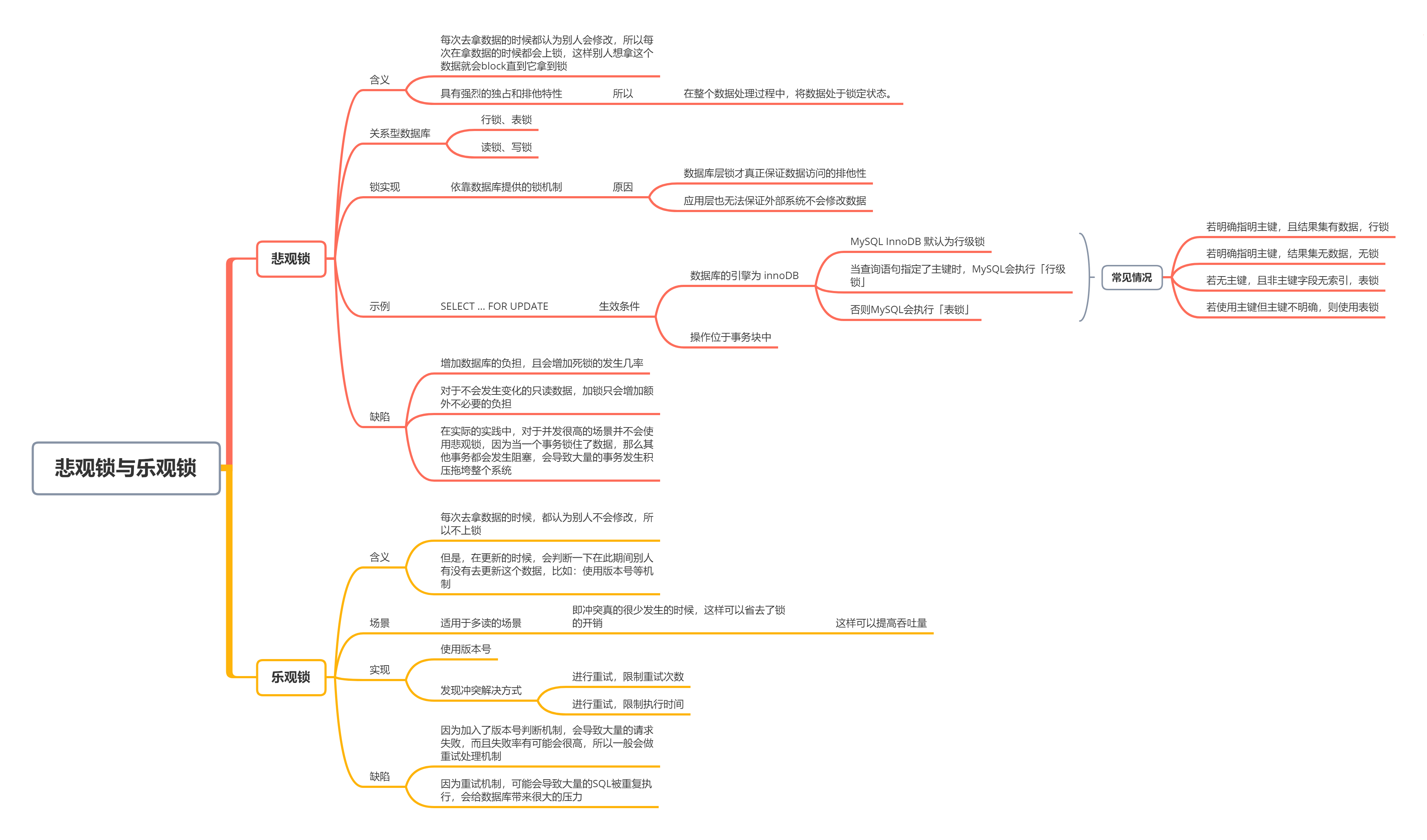
Because the implementation based on data table is too complex and does not have many characteristics of lock, it is basically not used by people. For more reading and less writing, please use optimistic lock, otherwise use pessimistic lock.
2.1.1. Implementation of pessimistic lock
The meaning of pessimistic lock is: every time you get the data, you think others will modify it, so every time you get the data, you will lock it, so that others will block the data until they get the lock. It has strong exclusive and exclusive characteristics. If a database transaction locks the data directly after it reads the data and does not allow other threads to read and write until the current database transaction is completed, the lock of the data will not be released, and the over issuance phenomenon seen before will not occur.
It is mainly realized by using the exclusive lock of select... where... for update. Note: do not lock the table and try to lock the row. It is used in the scene of writing more and reading less
2.1.2. Implementation of optimistic lock
Optimistic locking is a scheme that does not use database locks and does not block thread concurrency. Its execution process is that a thread reads the data in the existing table at the beginning, saves it, calls these data old data, and then executes certain business logic. When it needs to modify the shared data, it will compare the saved old data with the data in the current database in advance. If it is the same, it is considered that the data has not been modified and can be submitted successfully; Otherwise, the current business logic calculation is not trusted and cannot be submitted.
The common implementation method is to add a field version representing the data version in the table. Each update will be verion+1. During the update, judge whether the data version has changed. If it has changed, it cannot be updated.
Optimistic locking is based on CAS. It is not mutually exclusive and will not cause lock waiting and consume resources. It is considered that there is no concurrency conflict during the operation. It can be detected only after the update version fails. It is used in the scenario of more reads and less writes
2.1.3. Table based implementation
The core idea of the implementation method based on data table is to create a table in the database, which contains fields such as method name, and create a unique index on the method name field. If you want to execute a method, you can use this method name to insert data into the table. If you insert successfully, you will get the lock, and delete the corresponding row data after execution to release the lock.
However, it has the following problems:
-
Because it is implemented based on the database, the availability and performance of the database will directly affect the availability and performance of the distributed lock. Therefore, the database needs dual computer deployment, data synchronization and active / standby switching;
-
There is no reentrant feature, because the row data always exists before the same thread releases the lock, and the data cannot be successfully inserted again. Therefore, a new column needs to be added in the table to record the information of the machine and thread that currently obtains the lock. When acquiring the lock again, first query whether the information of the machine and thread in the table is the same as that of the current machine and thread, If it is the same, the lock is obtained directly;
-
There is no lock invalidation mechanism, because it is possible that after successfully inserting data, the server goes down, the corresponding data is not deleted, and the lock cannot be obtained after the service is restored. Therefore, a new column needs to be added in the table to record the invalidation time, and there needs to be a regular task to clear these invalid data;
-
It does not have the blocking lock feature, and the failure is directly returned if the lock is not obtained. Therefore, it is necessary to optimize the acquisition logic and cycle for multiple times to obtain it
-
In the process of implementation, we will encounter various problems. In order to solve these problems, the implementation method will be more and more complex; Depending on the database requires a certain resource overhead, and the performance needs to be considered.
2.1.3. shortcoming
-
db operation performance is poor, and there is a risk of locking the table
-
After the non blocking operation fails, polling is required to occupy cpu resources;
-
Not commit ting or polling for a long time may consume more connection resources
2.2. redis implementation
2.2.1. Involving command explanation
The redis command is described as follows. See: https://redis.io/commands/setnx
-
setnx key val: if and only if the key does not exist, set a string whose key is val and return 1; If the key exists, do nothing and return 0.
-
expire key timeout: set a timeout for the key [timeout will be automatically deleted], and the unit is second. After this time, the lock will be automatically released to avoid deadlock.
-
delete key: deletes a key
-
watch marks the given key as monitoring the conditional execution of a transaction
2.2.2. Implementation process
The implementation process is as follows:
-
When acquiring a lock, use setnx to add a lock and use the expire command to add a timeout time for the lock. If the timeout time is exceeded, the lock will be released automatically. The value of the lock is a randomly generated UUID, which can be judged when releasing the lock=
-
When acquiring a lock, you also set a timeout time for acquiring it. If it exceeds this time, you will give up acquiring the lock.
-
When releasing a lock, judge whether it is the lock through UUID. If it is the lock, execute delete to release the lock.
2.2.3. Code example
Note: because the redis cluster does not support transactions, the distributed lock implemented by redis uses the redis stand-alone version, which needs to ensure the high availability of redis through the redis master-slave or sentinel mode.
The example is implemented based on redis 5.0.5 and jedis 3.6.1
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import redis.clients.jedis.Transaction;
import redis.clients.jedis.exceptions.JedisException;
import java.util.List;
import java.util.Random;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
/**
* Simple implementation code of distributed lock
*/
class RedisDistributedLock {
private final JedisPool jedisPool;
public RedisDistributedLock(JedisPool jedisPool) {
this.jedisPool = jedisPool;
}
/**
* Lock
* @param lockName Lock key
* @param acquireTimeout Get timeout
* @param timeout Lock timeout
* @return Lock identification
*/
public String lockWithTimeout(String lockName, long acquireTimeout, long timeout) {
Jedis conn = null;
String retIdentifier = null;
try {
// Get connection
conn = jedisPool.getResource();
// Randomly generate a value
String identifier = UUID.randomUUID().toString();
// Lock name, i.e. key value
String lockKey = "lock:" + lockName;
// Timeout. After locking, the lock will be released automatically
long lockExpire = timeout;
// The timeout period for acquiring the lock. If it exceeds this time, the acquisition of the lock will be abandoned
long end = System.currentTimeMillis() + acquireTimeout;
while (System.currentTimeMillis() < end) {
if (conn.setnx(lockKey, identifier) == 1) {
conn.pexpire(lockKey, lockExpire);
// Return value, which is used to confirm the lock release time
return identifier;
}
// If - 1 is returned, it means that the key has not set a timeout. Set a timeout for the key
if (conn.ttl(lockKey) == -1) {
conn.expire(lockKey, lockExpire);
}
try {
Thread.sleep(timeout);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
} catch (JedisException e) {
e.printStackTrace();
} finally {
if (conn != null) {
conn.close();
}
}
return retIdentifier;
}
/**
* Release lock
* @param lockName Lock key
* @param identifier Identification of release lock
* @return
*/
public boolean releaseLock(String lockName, String identifier) {
Jedis conn = null;
String lockKey = "lock:" + lockName;
boolean retFlag = false;
try {
conn = jedisPool.getResource();
while (true) {
// Monitor lock and prepare to start transaction
conn.watch(lockKey);
//It may have been deleted after timeout, so it may be null
// Judge whether it is the lock by the value value returned earlier. If it is the lock, delete it and release it
String tmp = conn.get(lockKey);
if(tmp == null){
break;
}
if (identifier.equals(tmp)) {
Transaction transaction = conn.multi();
transaction.del(lockKey);
List<Object> results = transaction.exec();
if (results == null) {
continue;
}
retFlag = true;
}
conn.unwatch();
break;
}
} catch (JedisException e) {
e.printStackTrace();
} finally {
if (conn != null) {
conn.close();
}
}
return retFlag;
}
public static void main(String[] args) {
Service service = new Service();
for (int i = 0; i < 50; i++) {
ReqThread threadA = new ReqThread(service);
threadA.start();
}
}
}
class Service {
private static JedisPool pool = null;
private static Random rand = new Random(47);
private RedisDistributedLock lock = new RedisDistributedLock(pool);
int productNum = 500;
static {
JedisPoolConfig config = new JedisPoolConfig();
// Set the maximum number of connections
config.setMaxTotal(200);
// Set maximum idle number
config.setMaxIdle(8);
// Set the maximum waiting time
config.setMaxWaitMillis(1000 * 100);
// Whether verification is required when a jedis instance is browsed. If true, all jedis instances are available
config.setTestOnBorrow(true);
pool = new JedisPool(config, "172.25.21.22", 6379, 3000);
}
/**
* Second kill business scenario
*/
public void secondKill() {
// Returns the value of the lock for judgment when releasing the lock
String identifier = lock.lockWithTimeout("productA", 5000, 2);
System.out.println(Thread.currentThread().getName() + "Got the lock");
int sleepTime = rand.nextInt(100);
try {
//Simulation request processing time
TimeUnit.MILLISECONDS.sleep(sleepTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
//Update public resources: number of products killed in seconds
System.out.println(Thread.currentThread().getName()+" productNum:"+(--productNum)+" sleep:"+sleepTime);
lock.releaseLock("productA", identifier);
}
}
class ReqThread extends Thread {
private Service service;
public ReqThread(Service service) {
this.service = service;
}
@Override
public void run() {
service.secondKill();
}
}2.2.4. shortcoming
-
Lock deletion failed. The expiration time is hard to control
-
Non blocking. After the operation fails, it needs to poll and occupy cpu resources;
2.3. zookeeper implementation
2.3.1. zk node description
-
Ordered node: if a parent node is currently / lock, zookeeper provides an optional ordering feature when creating a child node under this parent node, such as creating a child node "/ lock/node -" and indicating order, zookeeper will automatically add an integer sequence number according to the current number of child nodes when generating a child node, That is, if it is the first child node created, the generated child node is / lock/node-0000000000, the next node is / lock/node-0000000001, and so on.
-
Temporary node: the client can establish a temporary node. After the session ends or the session times out, zookeeper will automatically delete the node.
-
Event monitoring: when reading data, you can set event monitoring for the node at the same time. When the node data or structure changes, zookeeper will notify the client. Currently, zookeeper has the following four events: 1) node creation; 2) Node deletion; 3) Node data modification; 4) Child node changes.
2.3.2. Implementation of ZK distributed lock
-
The client connects to zookeeper and creates temporary ordered child nodes under / lock. The child node corresponding to the first client is / lock/lock-0000000000, the second is / lock/lock-0000000001, and so on.
-
The client obtains the list of child nodes under / lock and determines whether the child node created by itself is the child node with the lowest sequence number in the current child node list. If so, it is considered to have obtained the lock. Otherwise, it listens to the child node change message of / lock and repeats this step after obtaining the child node change notice until the lock is obtained;
-
Execute business code;
-
After the business process is completed, delete the corresponding child node and release the lock. For more information, see www apache. curator. framework. recipes. locks. Interprocessmutex source code
2.2.3. Code example
The example code is based on zookeeper 3.4.14 and cursor recipes # 4.3.0. The temporary ordered child nodes generated are similar to this:_ c_44b6308c-ed7e-4727-9ace-2fcc870da955-lock-0000000089, _c_1c7b1fed-8011-4dc7-827f-60cec1859b3b-lock-0000000091
import lombok.extern.slf4j.Slf4j;
import org.apache.curator.ensemble.EnsembleProvider;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.framework.state.ConnectionState;
import org.apache.curator.retry.ExponentialBackoffRetry;
import redis.clients.jedis.JedisPool;
import java.io.IOException;
import java.util.Random;
import java.util.concurrent.TimeUnit;
@Slf4j
class ZooKeeperLock {
private CuratorFramework zkClient;
private InterProcessMutex mutex = null;
public ZooKeeperLock(String zkStr) {
init(zkStr);
mutex = new InterProcessMutex(getZkClient(), "/secondKill/productA/locks");
}
public void getLock(long time, TimeUnit unit) {
try {
mutex.acquire(time, unit);
} catch (Exception e) {
e.printStackTrace();
}
}
public void releaseLock() {
try {
//If a timeout is specified when acquiring a lock, you need to determine whether the lock is owned by the current thread or process when releasing it
if (mutex.isOwnedByCurrentThread() && mutex.isAcquiredInThisProcess())
mutex.release();
} catch (Exception e) {
e.printStackTrace();
}
}
public void init(String zkStr) {
this.zkClient = buildClient(zkStr);
initStateLister();
}
public void initStateLister() {
checkNotNull(zkClient);
zkClient.getConnectionStateListenable().addListener((client, newState) -> {
if (newState == ConnectionState.LOST) {
log.error("connection lost from zookeeper");
} else if (newState == ConnectionState.RECONNECTED) {
log.info("reconnected to zookeeper");
} else if (newState == ConnectionState.SUSPENDED) {
log.warn("connection SUSPENDED to zookeeper");
}
});
}
public CuratorFramework getZkClient() {
return zkClient;
}
private CuratorFramework buildClient(String zkStr) {
CuratorFrameworkFactory.Builder builder = CuratorFrameworkFactory.builder()
.ensembleProvider(new DefaultEnsembleProvider(zkStr))
.namespace("web")
.retryPolicy(new ExponentialBackoffRetry(100, 1030000));
builder.sessionTimeoutMs(60000);
builder.connectionTimeoutMs(30000);
zkClient = builder.build();
zkClient.start();
try {
zkClient.blockUntilConnected();
} catch (final Exception ex) {
throw new RuntimeException(ex);
}
return zkClient;
}
public static <T> T checkNotNull(T obj) {
if (obj == null) {
throw new NullPointerException();
}
return obj;
}
public static void main(String[] args) {
Service service = new Service();
for (int i = 0; i < 50; i++) {
ReqThread threadA = new ReqThread(service);
threadA.start();
}
}
}
class Service {
private static JedisPool pool = null;
private static Random rand = new Random(47);
private ZooKeeperLock lock = new ZooKeeperLock("172.25.21.18:2181");
int productNum = 500;
/**
* Second kill business scenario
*/
public void secondKill() {
// Returns the value of the lock for judgment when releasing the lock
lock.getLock(500, TimeUnit.MILLISECONDS);
System.out.println(Thread.currentThread().getName() + "Got the lock");
int sleepTime = rand.nextInt(30);
try {
//Simulation request processing time
TimeUnit.MILLISECONDS.sleep(sleepTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
//Update public resources: number of products killed in seconds
System.out.println(Thread.currentThread().getName() + " productNum:" + (--productNum) + " sleep:" + sleepTime);
lock.releaseLock();
}
}
class ReqThread extends Thread {
private Service service;
public ReqThread(Service service) {
this.service = service;
}
@Override
public void run() {
service.secondKill();
}
}
class DefaultEnsembleProvider implements EnsembleProvider {
private final String serverList;
public DefaultEnsembleProvider(String serverList) {
this.serverList = serverList;
}
@Override
public void start() throws Exception {
//NOP
}
@Override
public String getConnectionString() {
return serverList;
}
@Override
public void close() throws IOException {
//NOP
}
@Override
public void setConnectionString(String connectionString) {
//NOP
}
@Override
public boolean updateServerListEnabled() {
return false;
}
}2.3.4. shortcoming
The performance is not as good as that of redis implementation. The main reason is that all write operations (obtaining and releasing locks) need to be performed on the Leader and then synchronized to the follower. But the reliability is high.
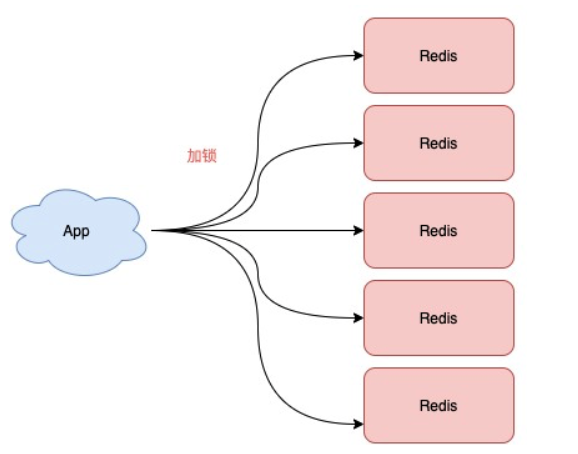
2.4. Redis # Redlock (red lock)
2.4.1. Implementation process
Redlock's scheme is based on two premises:
-
It is no longer necessary to deploy the slave database and sentinel instance, but only the master database
-
However, the main database needs to deploy multiple instances, and at least 5 instances are officially recommended
The overall process is as follows, which is divided into five steps:
-
The client obtains the "current timestamp T1" first
-
The client sends locking requests to these five Redis instances in turn (using the SET command mentioned earlier), and each request will SET a timeout (in milliseconds, which is far less than the effective time of the lock). If an instance fails to lock (including various exceptions such as network timeout and lock being held by others), it will immediately apply for locking to the next Redis instance
-
If the client successfully locks more than three (most) Redis instances from > = 3, then obtain the "current timestamp T2" again. If T2 - T1 < the expiration time of the lock, the client is considered to have succeeded in locking, otherwise it is considered to have failed
-
After locking successfully, operate the shared resources (for example, modify a line in MySQL or initiate an API request)
-
If locking fails, send a lock release request to "all nodes" (you can use Lua script to release the lock to ensure the atomicity of multi-step operation)
2.4.2. shortcoming
Redlock is heavy
If NPC occurs in steps 1-3, it can be detected in step 3 t2-t1. If the expiration time of lock setting is exceeded, it is considered that locking will fail, and then release the locks of all nodes. Otherwise, there will be problems, but the Redis author believes that all locks have similar problems
reference resources
https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html