summary
ivy is a configurable data filling framework, which mainly solves the following scenarios
1. Help you better deal with the embarrassment of no data before the development project
2. Get rid of the tedious work of manually creating databases and data tables
3. Quickly generate the simulation data required by the data background to help you write the logic development of data statistics faster
The configuration mode is adopted to make the work more efficient. Configure multiple host simulation data, as long as you match it in the file, you can achieve the effect you want.
The core idea is to liberate the labor force so that you can complete the filling task without writing or at least writing code
Code structure:
+---config // Batch operation profile directory +---ivy | +---abstracts // Interface class directory | +---functions // Function directory for generating random numbers | +---manages // Specific logic implementation management directory +---readme // directory
requirement
Python3+
Works on Linux, Windows, Mac OSX, BSD
file
Custom fill function
Write relevant code in the functions directory.
__init__.py
# -*- coding: utf-8 -*-
from ivy.functions.date import Date
from ivy.functions.default import Default
funcs = {
'range_date': Date().range,
'default': Default().default
}Then write relevant classes. Refer to default Py file
default.yml configuration file (following yaml syntax)
It mainly performs two functions:
1. Configure the database and create the data table automatically
2. Fill in data and highly support faker library
The configuration file can be written directly in the config directory, but note that it is only recognized here yml suffix configuration file oh. So just define
yml files will be executed
Chestnuts:
-
host: 127.0.0.1
port: 3306
username: root
password: root
charset: utf8mb4
dbname: faker
databases:
-
table: faker
fields:
id: INT NOT NULL AUTO_INCREMENT
name: VARCHAR(20) NOT NULL
date: timestamp NOT NULL
index:
- PRIMARY KEY (id)
other:
- ENGINE=InnoDB
- DEFAULT
- CHARSET=utf8mb4
rules:
date:
func: range_date
start: '2019-07-20'
end: '2019-08-20'
res_format: '%Y-%m-%d %H-%M-%S'
step: HOUR_TO_SECOND
name:
func: default
value: test
number: 100000
chunk: 100tips:
- This is configured in the form of arrays. Each array corresponds to a server address,
If you want to fill the databases on multiple servers, you need to configure them in an array
host: database server ip
Port: database server port
username: database user name
Password: database password
charset: encoding
dbname: name of the created database
databases: database table array
Table: data table name
Fields: data table fields
Index: data table index
other: data sheet engine
rules: content settings for database population
number: total quantity to fill
Chunk: the number of batch inserts per group to avoid memory overflow (number of inserts per time = number / chunk)
- The filling rules are defined as follows
1. The user-defined processing function should be in ivy / functions/__ init__. The function name defined in py is the func used in configuration.
rules:
date:
func: range_date
start: '2019-07-20'
end: '2019-08-20'
res_format: '%Y-%m-%d %H-%M-%S'
step: HOUR_TO_SECOND
name:
func: default
value: test2. The call of faker library should be directly prefixed with faker, and then divided with | without spaces. Then take it back
Just call the function in faker library. For example, in the above example, the function name is directly used to call. What other functions can be used to refer to faker
Library's official website
faker.readthedocs.io/en/master/loc...
- use
1. Install the required library
pip install -r requirements.txt
2. Configure padding_data.yml file, which can be configured according to yaml syntax here
3. Generate database and fill in data
python entry.py
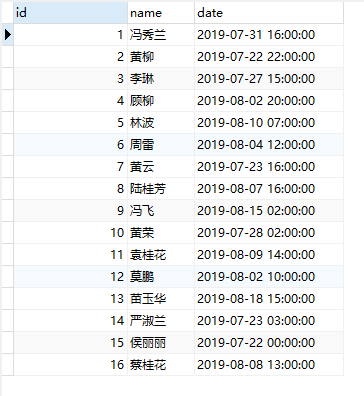
4. The effect is as follows: