1.Netfilter structure diagram
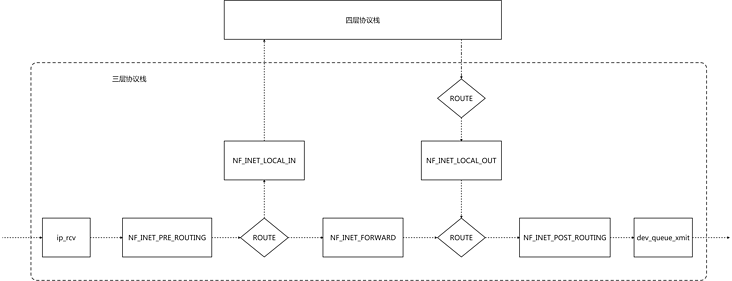
The core of Netfilter framework is five hook points. You can filter and modify packets by registering functions at the hook points
IPTABLES and IPVS realize their main functions by registering hook functions
ip_rcv is the entry function of the three-layer protocol stack
dev_queue_xmit will finally call the network device driver to send packets
2. Netfilter & contrack & iptables NAT structure diagram
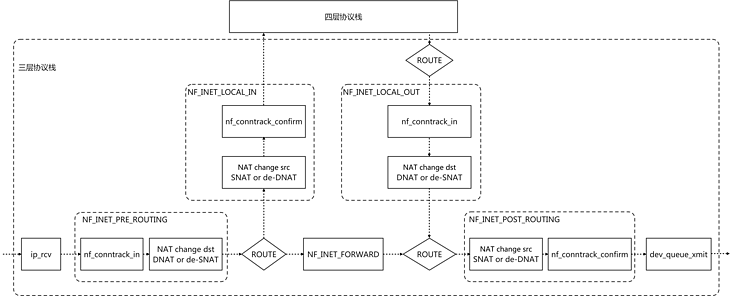
2.1 the hook function of each hook point of Netfilter has different priority
/* hook Function default priority setting. The smaller the value, the higher the priority */
enum nf_ip_hook_priorities {
NF_IP_PRI_FIRST = INT_MIN, /* Highest priority */
NF_IP_PRI_RAW_BEFORE_DEFRAG = -450, /* RAW involving IP fragment reorganization */
NF_IP_PRI_CONNTRACK_DEFRAG = -400, /* Connection tracking involving IP fragment reorganization */
NF_IP_PRI_RAW = -300, /* RAW Table for canceling connection tracking */
NF_IP_PRI_SELINUX_FIRST = -225,
NF_IP_PRI_CONNTRACK = -200, /* Connection tracking start */
NF_IP_PRI_MANGLE = -150,
NF_IP_PRI_NAT_DST = -100, /* NAT Change destination address, DNAT or de SNAT */
NF_IP_PRI_FILTER = 0, /* IPTABLES Packet filtering for */
NF_IP_PRI_SECURITY = 50,
NF_IP_PRI_NAT_SRC = 100, /* NAT Change source address, SNAT or de DNAT */
NF_IP_PRI_SELINUX_LAST = 225,
NF_IP_PRI_CONNTRACK_HELPER = 300,
NF_IP_PRI_CONNTRACK_CONFIRM = INT_MAX, /* Connection confirmation */
NF_IP_PRI_LAST = INT_MAX, /* Lowest priority */
};
priority CONNTRACK > DNAT > FILTER > SNAT > CONNTRACK_CONFIRM3.CONNTRACK
3.1 conntrack registered hook
static const struct nf_hook_ops ipv4_conntrack_ops[] = {
{
.hook = ipv4_conntrack_in, /* return nf_conntrack_in */
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_CONNTRACK,
},
{
.hook = ipv4_conntrack_local, /* return nf_conntrack_in */
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_CONNTRACK,
},
{
.hook = ipv4_confirm, /* Call nf_conntrack_confirm */
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_CONNTRACK_CONFIRM,
},
{
.hook = ipv4_confirm, /* Call nf_conntrack_confirm */
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_CONNTRACK_CONFIRM,
},
};3.2 nf_conntrack_in
nf_conntrack_in is the core function of conntrack. Its main functions are:
- Get the connection corresponding to the packet. If not, create a new connection record
- After obtaining a connection or creating a new connection, update the connection status and set SKB - >_ The NFCT field holds the connection pointer to which the packet belongs and the status of the connection
All packets not labeled UNC ntrack are in nf_conntrack_in, the connection will be obtained to provide a basis for subsequent NAT
3.2.1 nf_conntrack_in source code analysis:
unsigned int
nf_conntrack_in(struct sk_buff *skb, const struct nf_hook_state *state)
{
enum ip_conntrack_info ctinfo;
struct nf_conn *ct, *tmpl;
u_int8_t protonum;
int dataoff, ret;
/* First try to get from SKB - >_ The NFCT field gets the connection pointer and connection status
* skb->_nfct It is an unsigned long type. The last three bits store the connection status, and the remaining bits store the pointer of the connection record
* The kernel often uses this operation to save memory */
tmpl = nf_ct_get(skb, &ctinfo);
/* If the pointer and status of the connection are obtained successfully, or the packet label cancels the connection tracking */
if (tmpl || ctinfo == IP_CT_UNTRACKED) {
/* Previously seen (loopback or untracked)? Ignore. */
/* Three kinds of bags will come here
* 1.The skb of the connection has been obtained
* 2.skb without connection tracking
* 3.Set skb for template connection */
if ((tmpl && !nf_ct_is_template(tmpl)) ||
ctinfo == IP_CT_UNTRACKED) {
/* Skbs that have obtained connections and do not perform connection tracking return ACCEPT after increasing the namespace ignore count */
NF_CT_STAT_INC_ATOMIC(state->net, ignore);
return NF_ACCEPT;
}
/* The template connected skb will come here, skb_ The nfct field is reset
* However, tmpl has obtained the template connection and connection status information */
skb->_nfct = 0;
}
/* skb without connection and skb with template connection will continue */
/* rcu_read_lock()ed by nf_hook_thresh */
/* Get skb layer 4 protocol header offset */
dataoff = get_l4proto(skb, skb_network_offset(skb), state->pf, &protonum);
if (dataoff <= 0) {
pr_debug("not prepared to track yet or error occurred\n");
NF_CT_STAT_INC_ATOMIC(state->net, error);
NF_CT_STAT_INC_ATOMIC(state->net, invalid);
ret = NF_ACCEPT;
goto out;
}
/* ICMP The agreement is relevant. I won't see it for the time being */
if (protonum == IPPROTO_ICMP || protonum == IPPROTO_ICMPV6) {
ret = nf_conntrack_handle_icmp(tmpl, skb, dataoff,
protonum, state);
if (ret <= 0) {
ret = -ret;
goto out;
}
/* ICMP[v6] protocol trackers may assign one conntrack. */
if (skb->_nfct)
goto out;
}
repeat:
/* nf_conntrack_in The core function of is as follows
* 1.Match the connection in the global hash table according to the five tuples of skb
* 2.If there is no matching connection, a new connection will be created
* 3.Update the connection status after matching or establishing a connection
* 4.Save the connection pointer and connection status to SKB - >_ NFCT field */
ret = resolve_normal_ct(tmpl, skb, dataoff,
protonum, state);
if (ret < 0) {
/* Too stressed to deal. */
NF_CT_STAT_INC_ATOMIC(state->net, drop);
ret = NF_DROP;
goto out;
}
/* Here, the connection of skb has been confirmed. Retrieve the connection pointer and connection status */
ct = nf_ct_get(skb, &ctinfo);
if (!ct) {
/* Not valid part of a connection */
NF_CT_STAT_INC_ATOMIC(state->net, invalid);
ret = NF_ACCEPT;
goto out;
}
/* Four layer protocol connection tracking, such as the change of tcp connection status */
ret = nf_conntrack_handle_packet(ct, skb, dataoff, ctinfo, state);
if (ret <= 0) {
/* Invalid: inverse of the return code tells
* the netfilter core what to do */
pr_debug("nf_conntrack_in: Can't track with proto module\n");
nf_conntrack_put(&ct->ct_general);
skb->_nfct = 0;
NF_CT_STAT_INC_ATOMIC(state->net, invalid);
if (ret == -NF_DROP)
NF_CT_STAT_INC_ATOMIC(state->net, drop);
/* Special case: TCP tracker reports an attempt to reopen a
* closed/aborted connection. We have to go back and create a
* fresh conntrack.
*/
if (ret == -NF_REPEAT)
goto repeat;
ret = -ret;
goto out;
}
if (ctinfo == IP_CT_ESTABLISHED_REPLY &&
!test_and_set_bit(IPS_SEEN_REPLY_BIT, &ct->status))
nf_conntrack_event_cache(IPCT_REPLY, ct);
out:
if (tmpl)
nf_ct_put(tmpl);
return ret;
}3.2.2 init_conntrack is a function for conntrack to create a new connection. Source code analysis:
/* Allocate a new conntrack: we return -ENOMEM if classification
failed due to stress. Otherwise it really is unclassifiable. */
static noinline struct nf_conntrack_tuple_hash *
init_conntrack(struct net *net, struct nf_conn *tmpl,
const struct nf_conntrack_tuple *tuple,
struct sk_buff *skb,
unsigned int dataoff, u32 hash)
{
struct nf_conn *ct;
struct nf_conn_help *help;
struct nf_conntrack_tuple repl_tuple;
struct nf_conntrack_ecache *ecache;
struct nf_conntrack_expect *exp = NULL;
const struct nf_conntrack_zone *zone;
struct nf_conn_timeout *timeout_ext;
struct nf_conntrack_zone tmp;
/* Flip the quintuple of the packet to get the quintuple of the packet back */
if (!nf_ct_invert_tuple(&repl_tuple, tuple)) {
pr_debug("Can't invert tuple.\n");
return NULL;
}
/* zone of template connection settings */
zone = nf_ct_zone_tmpl(tmpl, skb, &tmp);
/* Create a new connection ct based on the namespace, zone, original quintuple and backhaul quintuple */
ct = __nf_conntrack_alloc(net, zone, tuple, &repl_tuple, GFP_ATOMIC,
hash);
if (IS_ERR(ct))
return (struct nf_conntrack_tuple_hash *)ct;
/* synproxy relevant */
if (!nf_ct_add_synproxy(ct, tmpl)) {
nf_conntrack_free(ct);
return ERR_PTR(-ENOMEM);
}
timeout_ext = tmpl ? nf_ct_timeout_find(tmpl) : NULL;
if (timeout_ext)
nf_ct_timeout_ext_add(ct, rcu_dereference(timeout_ext->timeout),
GFP_ATOMIC);
nf_ct_acct_ext_add(ct, GFP_ATOMIC);
nf_ct_tstamp_ext_add(ct, GFP_ATOMIC);
nf_ct_labels_ext_add(ct);
ecache = tmpl ? nf_ct_ecache_find(tmpl) : NULL;
nf_ct_ecache_ext_add(ct, ecache ? ecache->ctmask : 0,
ecache ? ecache->expmask : 0,
GFP_ATOMIC);
/* It is expected that there will be few protocols (such as ftp protocol) for sub connections */
local_bh_disable();
if (net->ct.expect_count) {
spin_lock(&nf_conntrack_expect_lock);
exp = nf_ct_find_expectation(net, zone, tuple);
if (exp) {
pr_debug("expectation arrives ct=%p exp=%p\n",
ct, exp);
/* Welcome, Mr. Bond. We've been expecting you... */
__set_bit(IPS_EXPECTED_BIT, &ct->status);
/* exp->master safe, refcnt bumped in nf_ct_find_expectation */
ct->master = exp->master;
if (exp->helper) {
help = nf_ct_helper_ext_add(ct, GFP_ATOMIC);
if (help)
rcu_assign_pointer(help->helper, exp->helper);
}
#ifdef CONFIG_NF_CONNTRACK_MARK
ct->mark = exp->master->mark;
#endif
#ifdef CONFIG_NF_CONNTRACK_SECMARK
ct->secmark = exp->master->secmark;
#endif
NF_CT_STAT_INC(net, expect_new);
}
spin_unlock(&nf_conntrack_expect_lock);
}
if (!exp)
__nf_ct_try_assign_helper(ct, tmpl, GFP_ATOMIC);
/* Now it is inserted into the unconfirmed list, bump refcount */
/* Count, and then insert the connected original quintuple into the unacknowledged linked list of the cpu */
nf_conntrack_get(&ct->ct_general);
nf_ct_add_to_unconfirmed_list(ct);
local_bh_enable();
if (exp) {
if (exp->expectfn)
exp->expectfn(ct, exp);
nf_ct_expect_put(exp);
}
return &ct->tuplehash[IP_CT_DIR_ORIGINAL];
}3.2.3 the connection record of contrack has two quintuples
- The first is the quintuple of the initial direction
- The second is the quintuple of the expected packet return
These two quintuples are in nf_conntrack_confirm will be inserted into the same global hash table, nf_conntrack_in, the connection to which the packet belongs is confirmed by looking up the global hash table
nf_conntrack_in the new connection, the two quintuples will not be added to the global hash table immediately, but the initial direction quintuples will be inserted into the unacknowledged linked list first
nf_conntrack_in new connection via NF_ conntrack_ After confirm, its two quintuples will be inserted into the global hash table
The reason for this establishment before confirmation mechanism is that packets may be discarded by the kernel on the way to Netfilter (such as filter table)
Connection tracking is at the entry position of layer 3 protocol stack PRE_ROUTING and LOCAL_OUT registered call nf_conntrack_in hook function to ensure that all data packet connections can be recorded
The connection trace is posted at the exit of the layer 3 protocol stack_ Routing and LOCAL_IN registered the call nf_conntrack_confirm hook function to ensure that the new connection can be confirmed
3.3 nf_conntrack_confirm
3.3.1 nf_conntrack_confirm source code analysis:
/* Confirm a connection: returns NF_DROP if packet must be dropped. */
static inline int nf_conntrack_confirm(struct sk_buff *skb)
{
/* Get from skb_ nfct field gets the pointer of the connection to which the packet belongs */
struct nf_conn *ct = (struct nf_conn *)skb_nfct(skb);
int ret = NF_ACCEPT;
/* Obtained the connection to which the packet belongs */
if (ct) {
/* Confirm for connections that are not confirmed */
if (!nf_ct_is_confirmed(ct))
ret = __nf_conntrack_confirm(skb);
if (likely(ret == NF_ACCEPT))
nf_ct_deliver_cached_events(ct);
}
/* The skb package with no connection directly returns ACCEPT */
return ret;
}
/* Confirm a connection given skb; places it in hash table */
int
__nf_conntrack_confirm(struct sk_buff *skb)
{
const struct nf_conntrack_zone *zone;
unsigned int hash, reply_hash;
struct nf_conntrack_tuple_hash *h;
struct nf_conn *ct;
struct nf_conn_help *help;
struct nf_conn_tstamp *tstamp;
struct hlist_nulls_node *n;
enum ip_conntrack_info ctinfo;
struct net *net;
unsigned int sequence;
int ret = NF_DROP;
/* Get connection pointer and connection status from skb */
ct = nf_ct_get(skb, &ctinfo);
net = nf_ct_net(ct);
/* ipt_REJECT uses nf_conntrack_attach to attach related
ICMP/TCP RST packets in other direction. Actual packet
which created connection will be IP_CT_NEW or for an
expected connection, IP_CT_RELATED. */
if (CTINFO2DIR(ctinfo) != IP_CT_DIR_ORIGINAL)
return NF_ACCEPT;
/* Get packet zone*/
zone = nf_ct_zone(ct);
local_bh_disable();
/* Get the hash of the original quintuple and the packet back quintuple */
do {
sequence = read_seqcount_begin(&nf_conntrack_generation);
/* reuse the hash saved before */
hash = *(unsigned long *)&ct->tuplehash[IP_CT_DIR_REPLY].hnnode.pprev;
hash = scale_hash(hash);
reply_hash = hash_conntrack(net,
&ct->tuplehash[IP_CT_DIR_REPLY].tuple);
} while (nf_conntrack_double_lock(net, hash, reply_hash, sequence));
/* We're not in hash table, and we refuse to set up related
* connections for unconfirmed conns. But packet copies and
* REJECT will give spurious warnings here.
*/
/* Another skb with the same unconfirmed conntrack may
* win the race. This may happen for bridge(br_flood)
* or broadcast/multicast packets do skb_clone with
* unconfirmed conntrack.
*/
if (unlikely(nf_ct_is_confirmed(ct))) {
WARN_ON_ONCE(1);
nf_conntrack_double_unlock(hash, reply_hash);
local_bh_enable();
return NF_DROP;
}
pr_debug("Confirming conntrack %p\n", ct);
/* We have to check the DYING flag after unlink to prevent
* a race against nf_ct_get_next_corpse() possibly called from
* user context, else we insert an already 'dead' hash, blocking
* further use of that particular connection -JM.
*/
nf_ct_del_from_dying_or_unconfirmed_list(ct);
if (unlikely(nf_ct_is_dying(ct))) {
nf_ct_add_to_dying_list(ct);
goto dying;
}
/* See if there's one in the list already, including reverse:
NAT could have grabbed it without realizing, since we're
not in the hash. If there is, we lost race. */
hlist_nulls_for_each_entry(h, n, &nf_conntrack_hash[hash], hnnode)
if (nf_ct_key_equal(h, &ct->tuplehash[IP_CT_DIR_ORIGINAL].tuple,
zone, net))
goto out;
hlist_nulls_for_each_entry(h, n, &nf_conntrack_hash[reply_hash], hnnode)
if (nf_ct_key_equal(h, &ct->tuplehash[IP_CT_DIR_REPLY].tuple,
zone, net))
goto out;
/* Timer relative to confirmation time, not original
setting time, otherwise we'd get timer wrap in
weird delay cases. */
ct->timeout += nfct_time_stamp;
atomic_inc(&ct->ct_general.use);
/* Identity connection determined */
ct->status |= IPS_CONFIRMED;
/* set conntrack timestamp, if enabled. */
tstamp = nf_conn_tstamp_find(ct);
if (tstamp)
tstamp->start = ktime_get_real_ns();
/* Since the lookup is lockless, hash insertion must be done after
* starting the timer and setting the CONFIRMED bit. The RCU barriers
* guarantee that no other CPU can find the conntrack before the above
* stores are visible.
*/
/* Insert the connected original quintuple and backhaul quintuple into the global hash table */
__nf_conntrack_hash_insert(ct, hash, reply_hash);
nf_conntrack_double_unlock(hash, reply_hash);
local_bh_enable();
help = nfct_help(ct);
if (help && help->helper)
nf_conntrack_event_cache(IPCT_HELPER, ct);
nf_conntrack_event_cache(master_ct(ct) ?
IPCT_RELATED : IPCT_NEW, ct);
return NF_ACCEPT;
out:
nf_ct_add_to_dying_list(ct);
ret = nf_ct_resolve_clash(net, skb, ctinfo, h);
dying:
nf_conntrack_double_unlock(hash, reply_hash);
NF_CT_STAT_INC(net, insert_failed);
local_bh_enable();
return ret;
}4.IPTABLES NAT
Nat of IPTABLES depends on connection tracking. Packets without connection tracking will not be NAT processed
4.1 hook for NAT registration
static const struct nf_hook_ops nf_nat_ipv4_ops[] = {
/* At the entrance of the layer 3 protocol stack, modify the destination address (DNAT or de SNAT) before packet filtering */
{
.hook = nf_nat_ipv4_in, /* Call NF first_ nat_ ipv4_ fn */
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_NAT_DST,
},
/* The exit location of the layer 3 protocol stack. After packet filtering, modify the source address (SNAT or de DNAT) */
{
.hook = nf_nat_ipv4_out, /* Call NF first_ nat_ ipv4_ fn */
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_NAT_SRC,
},
/* At the entrance of the layer 3 protocol stack, modify the destination address (DNAT or de SNAT) before packet filtering */
{
.hook = nf_nat_ipv4_local_fn, /* Call NF first_ nat_ ipv4_ fn */
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_NAT_DST,
},
/* The exit location of the layer 3 protocol stack. After packet filtering, modify the source address (SNAT or de DNAT) */
{
.hook = nf_nat_ipv4_fn, /* nf_nat_ipv4_fn */
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_NAT_SRC,
},
};4.2 nf_nat_ipv4_fn
Hook functions registered with NAT will call NF first_ nat_ ipv4_ fn
Function nf_nat_ipv4_fn will first obtain the conntrack connection pointer and connection status of the packet. Without conntrack connection, NAT will not be performed
4.2.1 nf_nat_ipv4_fn source code analysis:
static unsigned int
nf_nat_ipv4_fn(void *priv, struct sk_buff *skb,
const struct nf_hook_state *state)
{
struct nf_conn *ct;
enum ip_conntrack_info ctinfo;
/* Start with skb's_ The nfct field obtains the connection pointer and connection status. If not, it will be returned directly without NAT processing */
ct = nf_ct_get(skb, &ctinfo);
if (!ct)
return NF_ACCEPT;
/* ICMP Agreement related */
if (ctinfo == IP_CT_RELATED || ctinfo == IP_CT_RELATED_REPLY) {
if (ip_hdr(skb)->protocol == IPPROTO_ICMP) {
if (!nf_nat_icmp_reply_translation(skb, ct, ctinfo,
state->hook))
return NF_DROP;
else
return NF_ACCEPT;
}
}
/* Call core function nf_nat_inet_fn */
return nf_nat_inet_fn(priv, skb, state);
}
unsigned int
nf_nat_inet_fn(void *priv, struct sk_buff *skb,
const struct nf_hook_state *state)
{
struct nf_conn *ct;
enum ip_conntrack_info ctinfo;
struct nf_conn_nat *nat;
/* maniptype == SRC for postrouting. */
enum nf_nat_manip_type maniptype = HOOK2MANIP(state->hook);
/* Get the connection pointer and connection status of skb package again */
ct = nf_ct_get(skb, &ctinfo);
/* Can't track? It's not due to stress, or conntrack would
* have dropped it. Hence it's the user's responsibilty to
* packet filter it out, or implement conntrack/NAT for that
* protocol. 8) --RR
*/
if (!ct)
return NF_ACCEPT;
/* Get Natwork Namespace */
nat = nfct_nat(ct);
/* Do different processing according to the connection status */
switch (ctinfo) {
case IP_CT_RELATED:
case IP_CT_RELATED_REPLY:
/* Only ICMPs can be IP_CT_IS_REPLY. Fallthrough */
case IP_CT_NEW:
/* Seen it before? This can happen for loopback, retrans,
* or local packets.
*/
if (!nf_nat_initialized(ct, maniptype)) {
struct nf_nat_lookup_hook_priv *lpriv = priv;
/* Get the hook function entry saved by NAT table */
struct nf_hook_entries *e = rcu_dereference(lpriv->entries);
unsigned int ret;
int i;
if (!e)
goto null_bind;
/* Execute all hook functions saved by the entry, and the hook function of nat table will traverse the rules in sequence */
for (i = 0; i < e->num_hook_entries; i++) {
ret = e->hooks[i].hook(e->hooks[i].priv, skb,
state);
if (ret != NF_ACCEPT)
return ret;
if (nf_nat_initialized(ct, maniptype))
goto do_nat;
}
null_bind:
ret = nf_nat_alloc_null_binding(ct, state->hook);
if (ret != NF_ACCEPT)
return ret;
} else {
pr_debug("Already setup manip %s for ct %p (status bits 0x%lx)\n",
maniptype == NF_NAT_MANIP_SRC ? "SRC" : "DST",
ct, ct->status);
if (nf_nat_oif_changed(state->hook, ctinfo, nat,
state->out))
goto oif_changed;
}
break;
default:
/* ESTABLISHED */
WARN_ON(ctinfo != IP_CT_ESTABLISHED &&
ctinfo != IP_CT_ESTABLISHED_REPLY);
if (nf_nat_oif_changed(state->hook, ctinfo, nat, state->out))
goto oif_changed;
}
do_nat:
/* nat processing of data packets according to connection records */
return nf_nat_packet(ct, ctinfo, state->hook, skb);
oif_changed:
nf_ct_kill_acct(ct, ctinfo, skb);
return NF_DROP;
}
/* Do packet manipulations according to nf_nat_setup_info. */
unsigned int nf_nat_packet(struct nf_conn *ct,
enum ip_conntrack_info ctinfo,
unsigned int hooknum,
struct sk_buff *skb)
{
enum nf_nat_manip_type mtype = HOOK2MANIP(hooknum);
enum ip_conntrack_dir dir = CTINFO2DIR(ctinfo);
unsigned int verdict = NF_ACCEPT;
unsigned long statusbit;
if (mtype == NF_NAT_MANIP_SRC)
statusbit = IPS_SRC_NAT;1
else
statusbit = IPS_DST_NAT;10
/* Wrap back XOR inversion */
/* Invert if this is reply dir. */
if (dir == IP_CT_DIR_REPLY)
statusbit ^= IPS_NAT_MASK;11
/* Non-atomic: these bits don't change. */
if (ct->status & statusbit)
/* NAT Modify packet */
verdict = nf_nat_manip_pkt(skb, ct, mtype, dir);
return verdict;
}
unsigned int nf_nat_manip_pkt(struct sk_buff *skb, struct nf_conn *ct,
enum nf_nat_manip_type mtype,
enum ip_conntrack_dir dir)
{
struct nf_conntrack_tuple target;
/* We are aiming to look like inverse of other direction. */
/* The original packet is based on the reply quintuple NAT, and the return packet is based on the original quintuple de NAT */
nf_ct_invert_tuple(&target, &ct->tuplehash[!dir].tuple);
switch (target.src.l3num) {
case NFPROTO_IPV6:
if (nf_nat_ipv6_manip_pkt(skb, 0, &target, mtype))
return NF_ACCEPT;
break;
case NFPROTO_IPV4:
if (nf_nat_ipv4_manip_pkt(skb, 0, &target, mtype))
return NF_ACCEPT;
break;
default:
WARN_ON_ONCE(1);
break;
}
return NF_DROP;
}
static bool nf_nat_ipv4_manip_pkt(struct sk_buff *skb,
unsigned int iphdroff,
const struct nf_conntrack_tuple *target,
enum nf_nat_manip_type maniptype)
{
struct iphdr *iph;
unsigned int hdroff;
/* skb Writable */
if (skb_ensure_writable(skb, iphdroff + sizeof(*iph)))
return false;
/* IP head */
iph = (void *)skb->data + iphdroff;
hdroff = iphdroff + iph->ihl * 4;
/* Layer 4 port modification */
if (!l4proto_manip_pkt(skb, iphdroff, hdroff, target, maniptype))
return false;
iph = (void *)skb->data + iphdroff;
/* NAT */
if (maniptype == NF_NAT_MANIP_SRC) {
csum_replace4(&iph->check, iph->saddr, target->src.u3.ip);
iph->saddr = target->src.u3.ip;
} else {
csum_replace4(&iph->check, iph->daddr, target->dst.u3.ip);
iph->daddr = target->dst.u3.ip;
}
return true;
}