In addition to the core components of producers and consumers, another core component of Kafka is the connector, which can be simply understood as the channel for data transmission between Kafka system and other systems. Through Kafka's connector, a large amount of data can be moved into and out of Kafka's system. The details are as follows:
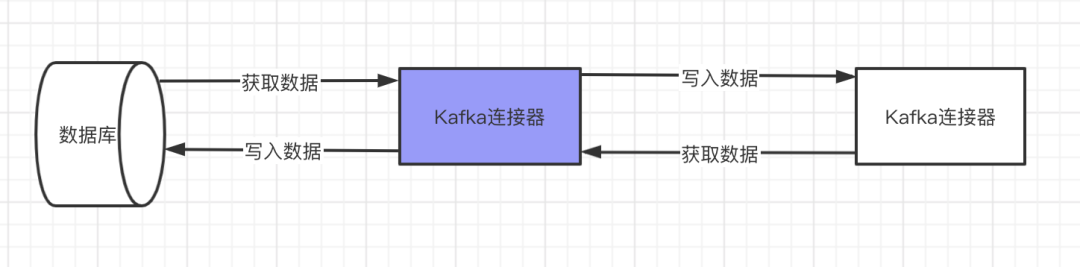
According to the above, Kafka's connector completes the pipeline of input and output data transmission. It is well understood that we obtain a large amount of real-time streaming data from a third party, write it to Kafka's system through the mode of producers and consumers, and finally store the data to the target storable database through the connector, such as Hbase, etc. Based on the above, Kafka's connector usage scenarios can be summarized as follows:
1. As a connecting pipeline, Kafka writes the target data into Kafka's system, and then moves the data out to the target database through Kafka's connector
2. Kafka, as the intermediate medium of data transmission, is only a pipeline or intermediate medium of data transmission. For example, after the information of log files is transferred to Kafka's system, these data will be removed from Kafka's system to ElasticSearch for storage and display. Through Kafka's connector, the producer mode and consumer mode of Kafka system can be effectively integrated and decoupled.
The connector of Kafka system can be started in two ways: one is single machine mode and the other is distributed mode. Here, the connector of Kafka is mainly started in single machine mode. Configure the connector information in the kafka/config directory. Its configuration file name is: connect file source Properties, the configuration contents are:
#Set connector name name=local-file-source #Specify connector class connector.class=FileStreamSource #Set maximum number of tasks tasks.max=1 #Specifies the file to read file=/tmp/source.txt #Specify topic name topic=login
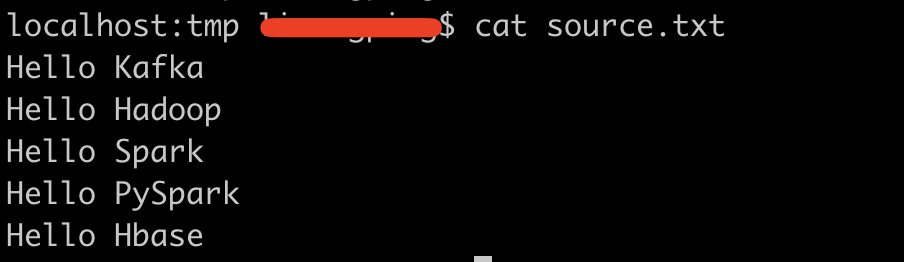
In this configuration file, we set the read file / TMP / source Txt, let's add content to this file in this directory. The specific contents are as follows:
The following program starts the connector in stand-alone mode. The start command is:
./connect-standalone.sh ../config/connect-standalone.properties ../config/connect-file-source.properties
The information output after successful startup is as follows:
#!/usr/bin/env python
#!coding:utf-8
[2021-06-07 20:43:12,715] INFO WorkerSourceTask{id=local-file-source-0} flushing 0 outstanding messages for offset commit (org.apache.kafka.connect.runtime.WorkerSourceTask:495)
[2021-06-07 20:43:12,727] INFO WorkerSourceTask{id=local-file-source-0} Finished commitOffsets successfully in 12 ms (org.apache.kafka.connect.runtime.WorkerSourceTask:574)The connector process of Kafka system is executed in the form of background service. Its default port is 8083. We can obtain relevant information through REST API, such as the instance list of active connectors. Its interface information is: GET /connectors, as follows:
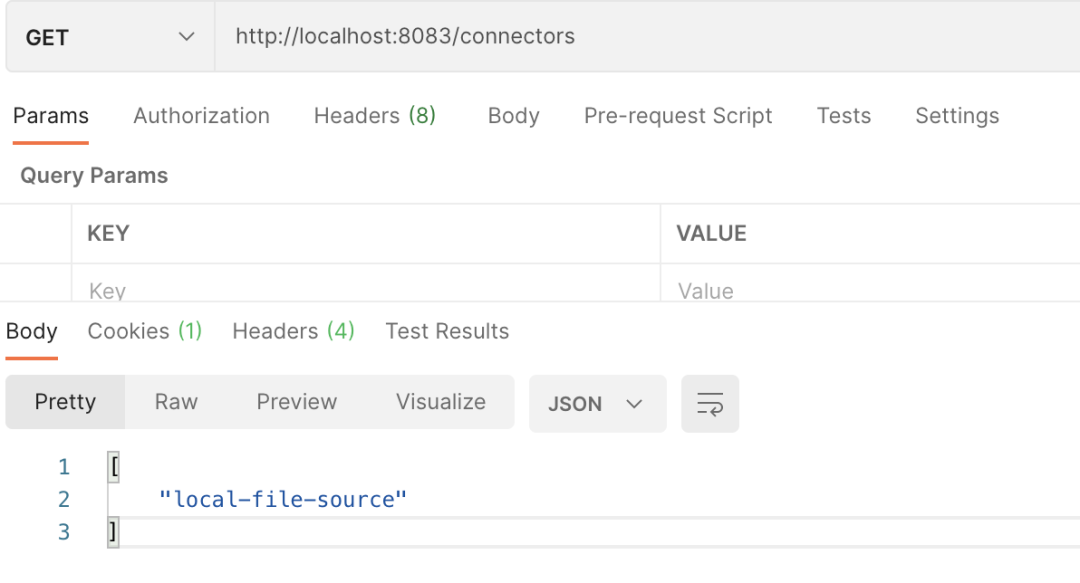
Next, we will demonstrate the instance information of the specified connector and return its details. The specific output information of PostMan is as follows:
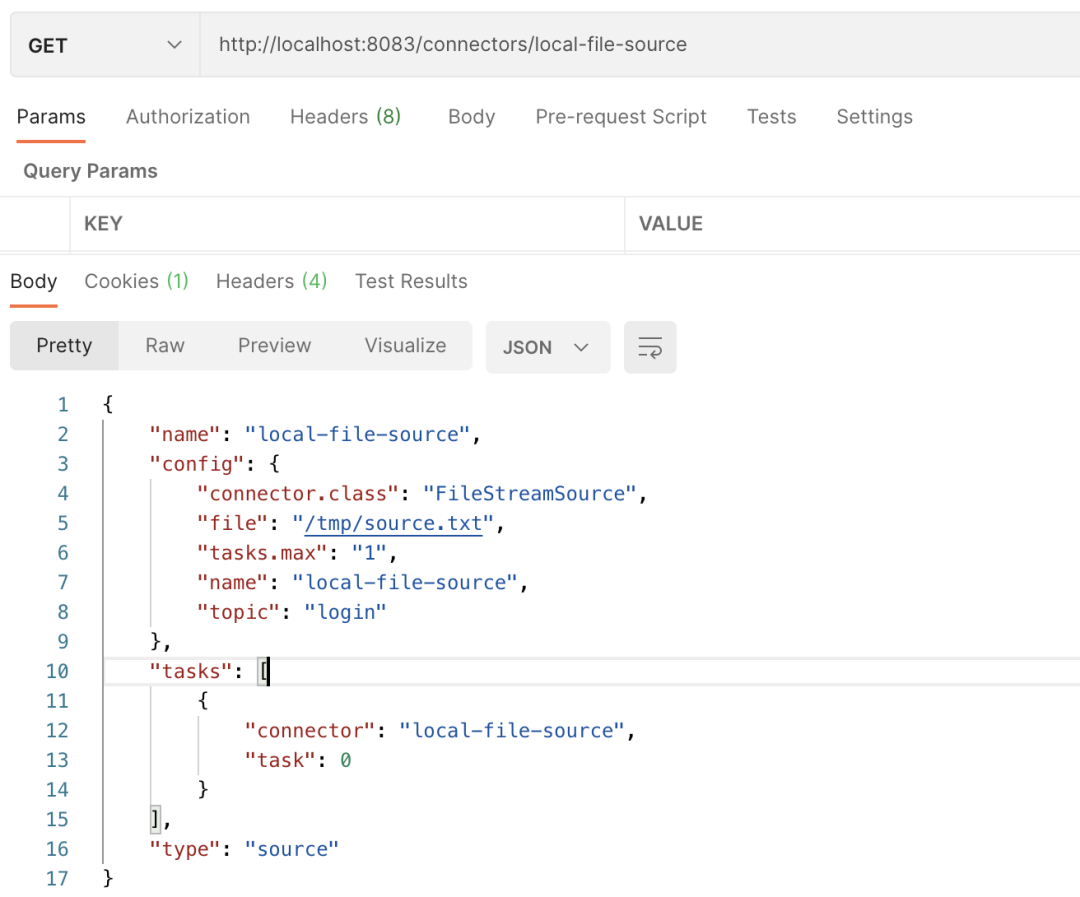
Next, let's take a look at obtaining the configuration information of the connector, that is, the config information. The specific screenshot of PostMan's request is as follows:
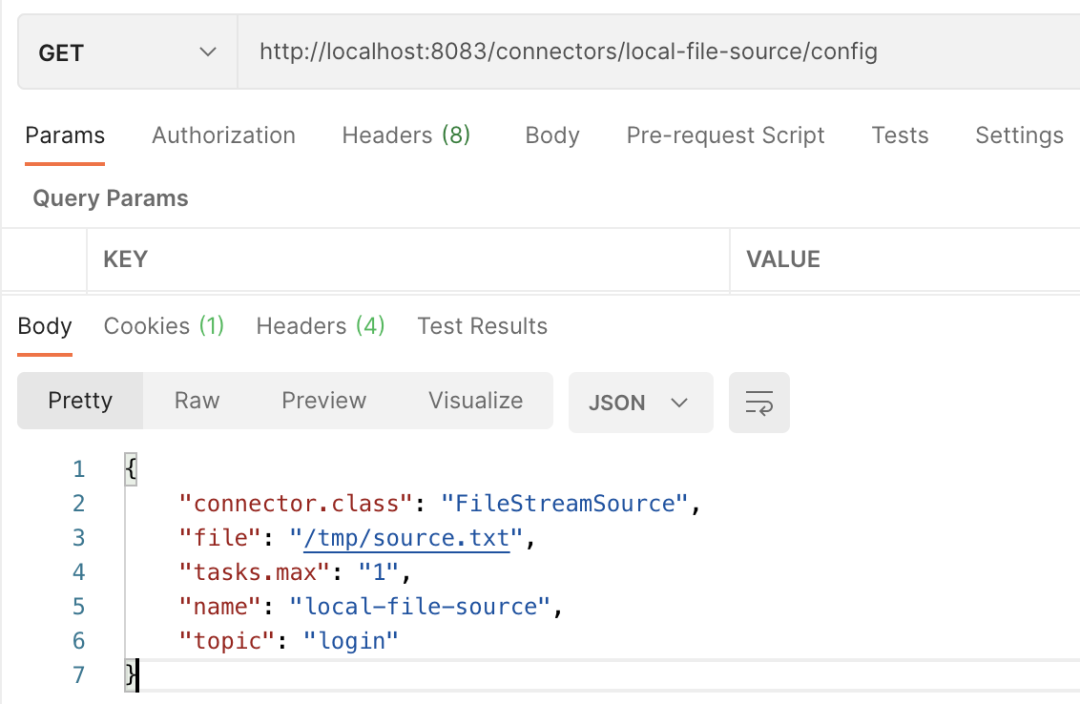
The connector provides many REST API interfaces, which will not be demonstrated one by one here.
Let's import the data into Kafka's login topic. The imported data is
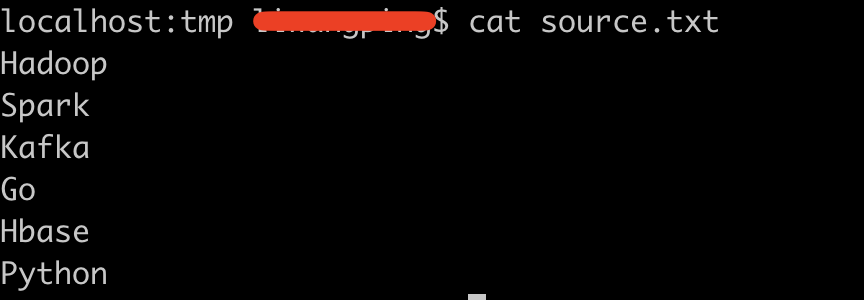
Execute command:
./connect-standalone.sh ../config/connect-standalone.properties ../config/connect-file-source.properties
After successful execution, you can see that the data is imported into the login topic in Kafka's consumer program, as shown below:
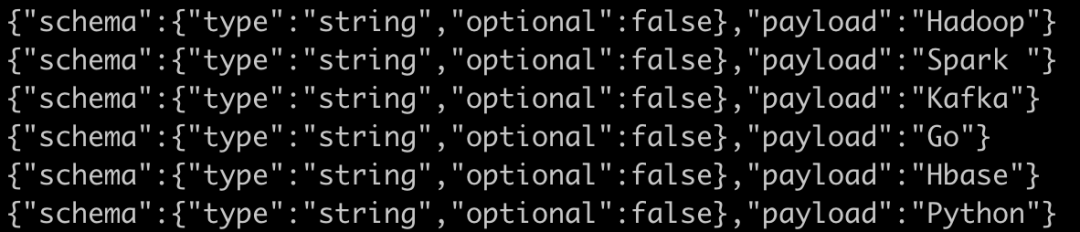
In the stand-alone mode, export the data in the Kafka topic to a local specific file in the config configuration file connect file sink The exported data specified in properties is written to the local specific file. The specific file contents are as follows:
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. name=local-file-sink connector.class=FileStreamSink tasks.max=1 file=/tmp/target.txttopics=login
Its execution sequence is as follows:
Execute the command to consume the target data into the subject of Kafka. The command is:
./connect-standalone.sh ../config/connect-standalone.properties ../config/connect-file-source.properties
Then create the file target. Under / tmp txt. Next, execute the following command to export Kafka's data to the local. The command is:
./connect-standalone.sh ../config/connect-standalone.properties ../config/connect-file-sink.properties
The log information printed on the console is:
[2021-06-08 15:37:11,766] INFO WorkerSinkTask{id=local-file-sink-0} Committing offsets asynchronously using sequence number 1: {data-1=OffsetAndMetadata{offset=5, leaderEpoch=null, metadata=''}, data-0=OffsetAndMetadata{offset=0, leaderEpoch=null, metadata=''}, data-3=OffsetAndMetadata{offset=1, leaderEpoch=null, metadata=''}, data-2=OffsetAndMetadata{offset=0, leaderEpoch=null, metadata=''}, data-5=OffsetAndMetadata{offset=0, leaderEpoch=null, metadata=''}, data-4=OffsetAndMetadata{offset=0, leaderEpoch=null, metadata=''}} (org.apache.kafka.connect.runtime.WorkerSinkTask:346)Finally, under / tmp, view the target The content of TXT file is found to be consistent with the content of the target file originally consumed.
According to the above, the target data is consumed into the subject of Kafka system through the connector, and finally exported to the local target data storage place (either database or text) through the connector. In this way, one of the purposes of connecting data pipes was realized.