Foreword: it is only used for learning and communication. The configuration file may be different from that in work. The software used in this experiment includes:
- hadoop-2.6.0.tar.gz
- jdk-8u161-linux-x64.tar.gz
- zookeeper-3.4.5.tar.gz
Building premise: all operations required for hadoop full distribution have been completed.
Plan:
A fully distributed hadoop cluster with one master and three slaves. Node names: Master, slave, slave2 and slave3
Select the master node and slave3 node as the Namenode node
1, Set up HA mode and modify relevant configuration files
1. Create a folder for storing HA and modify relevant configurations
(1) Create a hadoop file Ha to store high availability
[root@master ~]# mkdir /usr/local/Ha
(2) Copy fully distributed hadoop to Ha file
[root@master ~]# cp -r /usr/local/hadoop/hadoop-2.6.0/* /usr/local/Ha/
Note: - r means recursive copy. All files in the directory including subdirectories are processed together
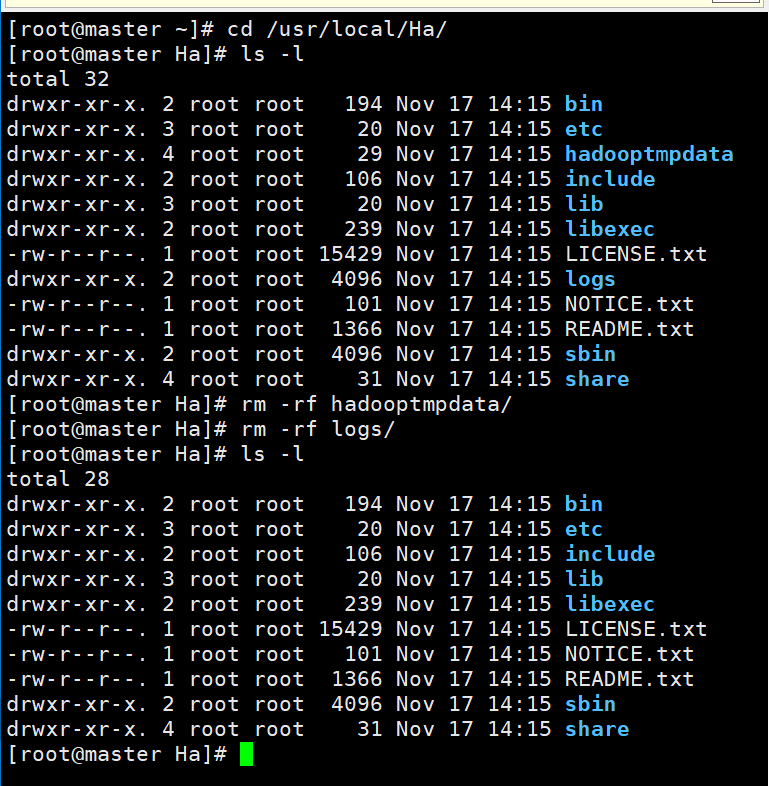
(3) Delete the Hadoop data and logs folders in the Ha file where the cluster data and logs are stored
[root@master ~]# cd /usr/local/Ha/
[root@master Ha]# ls -l
[root@master Ha]# rm -rf hadooptmpdata/
[root@master Ha]# rm -rf logs/
[root@master Ha]# ls -l
2. Modify the configuration file
(1) Modify the configuration file core-site.xml
[root@master Ha]# cd etc/hadoop/
[root@master hadoop]# vim core-site.xml
Configure hadoop fully distributed configuration items in the original file:
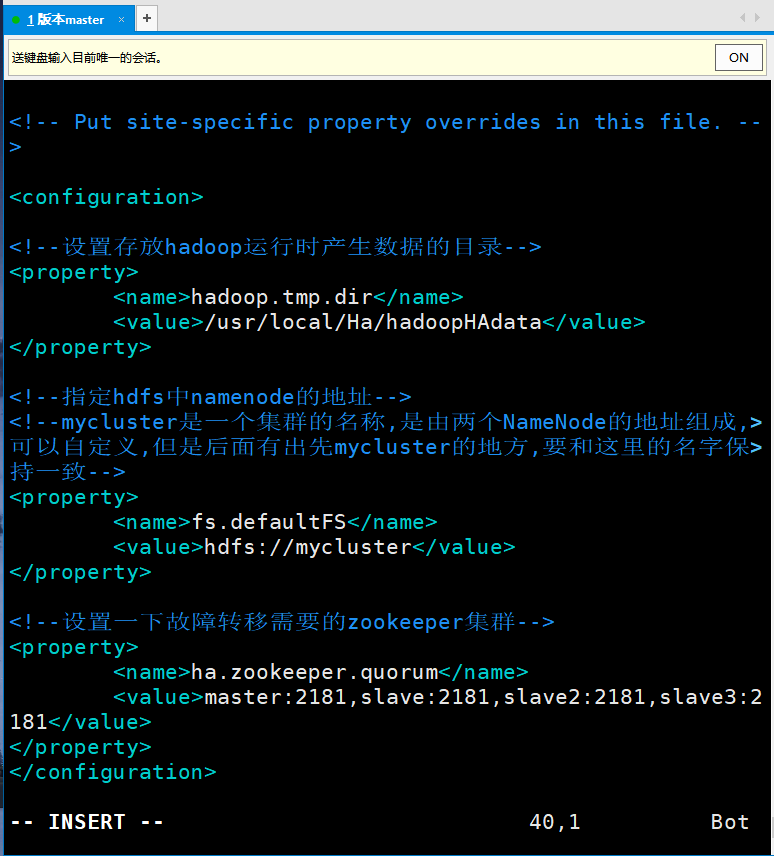
Modify and add configuration items in the file as follows:
<configuration>
<!--Set storage hadoop Directory of data generated at run time-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/Ha/hadoopHAdata</value>
</property>
<!--appoint hdfs in namenode Address of-->
<!--mycluster Is the name of a cluster,It's made up of two NameNode Address composition of,Can customize,But there's a first mover mycluster Place,Be consistent with the name here-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!--Set the required for failover zookeeper colony-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave:2181,slave2:2181,slave3:2181</value>
</property>
</configuration>
The effects are as follows:
Save and exit.
(2) Modify the configuration file hdfs-site.xml
Delete the original configuration and add the following configuration:
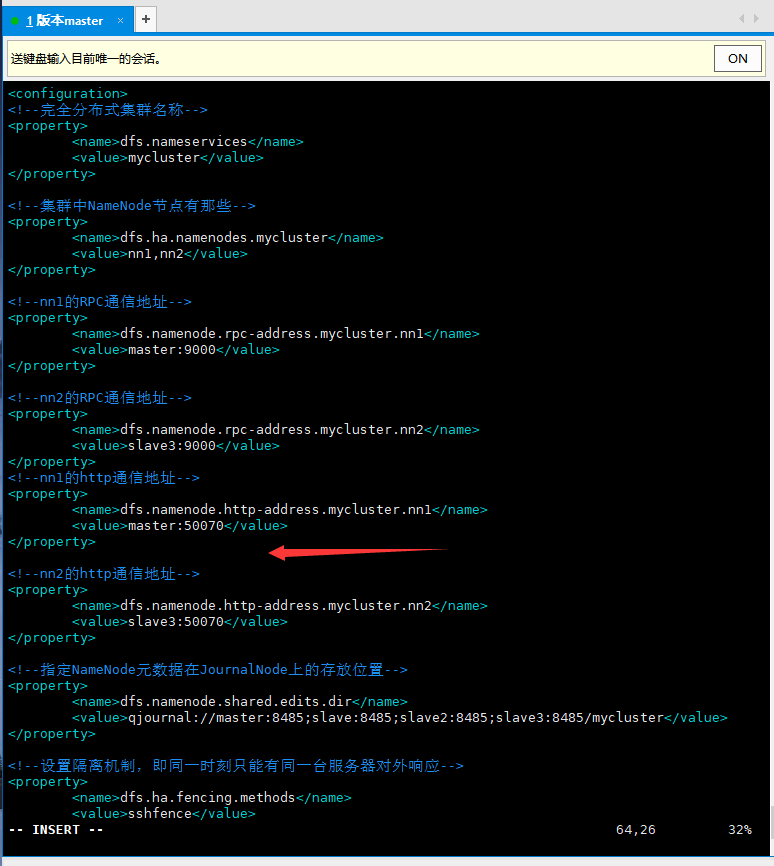
<configuration>
<!--Fully distributed cluster name-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!--In cluster NameNode What are the nodes-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!--nn1 of RPC mailing address-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>master:9000</value>
</property>
<!--nn2 of RPC mailing address-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>slave3:9000</value>
</property>
<!--nn1 of http mailing address-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>master:50070</value>
</property>
<!--nn2 of http mailing address-->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>slave3:50070</value>
</property>
<!--appoint NameNode Metadata in JournalNode Storage location on-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave:8485;slave2:8485;slave3:8485/mycluster</value>
</property>
<!--Set the isolation mechanism, that is, only one server can respond at the same time-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--Required when using isolation mechanism ssh Log in without a key. This is the private key, not the public key-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--statement journalnode Server storage directory-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/Ha/hadoopHAdata/jn</value>
</property>
<!--Start automatic failover ,Be sure to add-->
<property>
<name>dfs.ha.automatic-failover.enabled.mycluster</name>
<value>true</value>
</property>
<!--Turn off permission check-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!--Access proxy class: client,mycluster,active Configure the implementation of automatic switching-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enable</name>
<value>true</value>
</property>
</configuration>
Note the configuration item that requires ssh keyless login in the isolation mechanism. Many blogs say that this configuration item is a public key. Here should be a private key. After reading several blogs, their names and IDs are wrong_ Rsa.pub is the public key, id_rsa is the private key; In addition, you must add a configuration item to start automatic failover, otherwise an error will occur when initializing the state of HA in zookeepe on nn1 node.
The effects are as follows:
Save and exit.
(3) Modify the configuration file yarn-site.xml
Delete all configurations and add the following configurations:
<configuration>
<!--mapreduce How to get data-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--Enable resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--Declare two resourcemanager Address of-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave3</value>
</property>
<!--appoint zookeeper Address of the cluster-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave:2181,slave2:2181,slave3:2181</value>
</property>
<!--Start automatic recovery-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--appoint resourcemanager The status information of is stored in zookeeper colony-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
The effects are as follows:
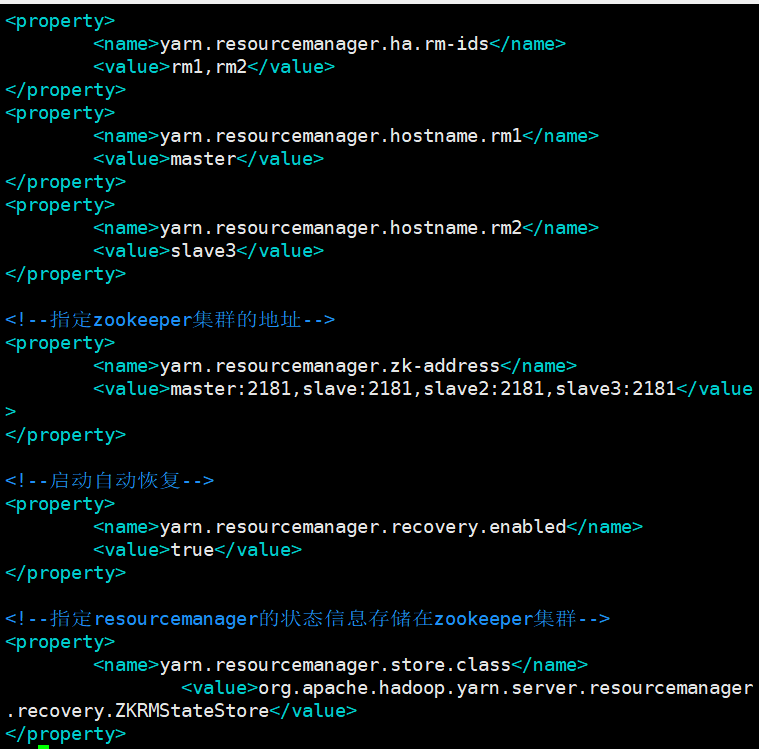
Save and exit.
(4) Modify profile slave
Add: master to this file
Reason for adding master: the slave file indicates which nodes are running the DateNode process.
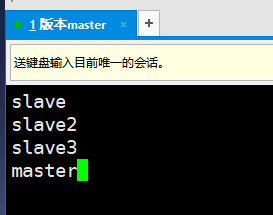
(5) Distribute the Ha file to the child nodes and place it in the / usr/local directory
[root@master ~]# scp -r /usr/local/Ha root@slave:/usr/local/
[root@master ~]# scp -r /usr/local/Ha root@slave2:/usr/local/
[root@master ~]# scp -r /usr/local/Ha root@slave3:/usr/local/
2, Start the cluster and processes
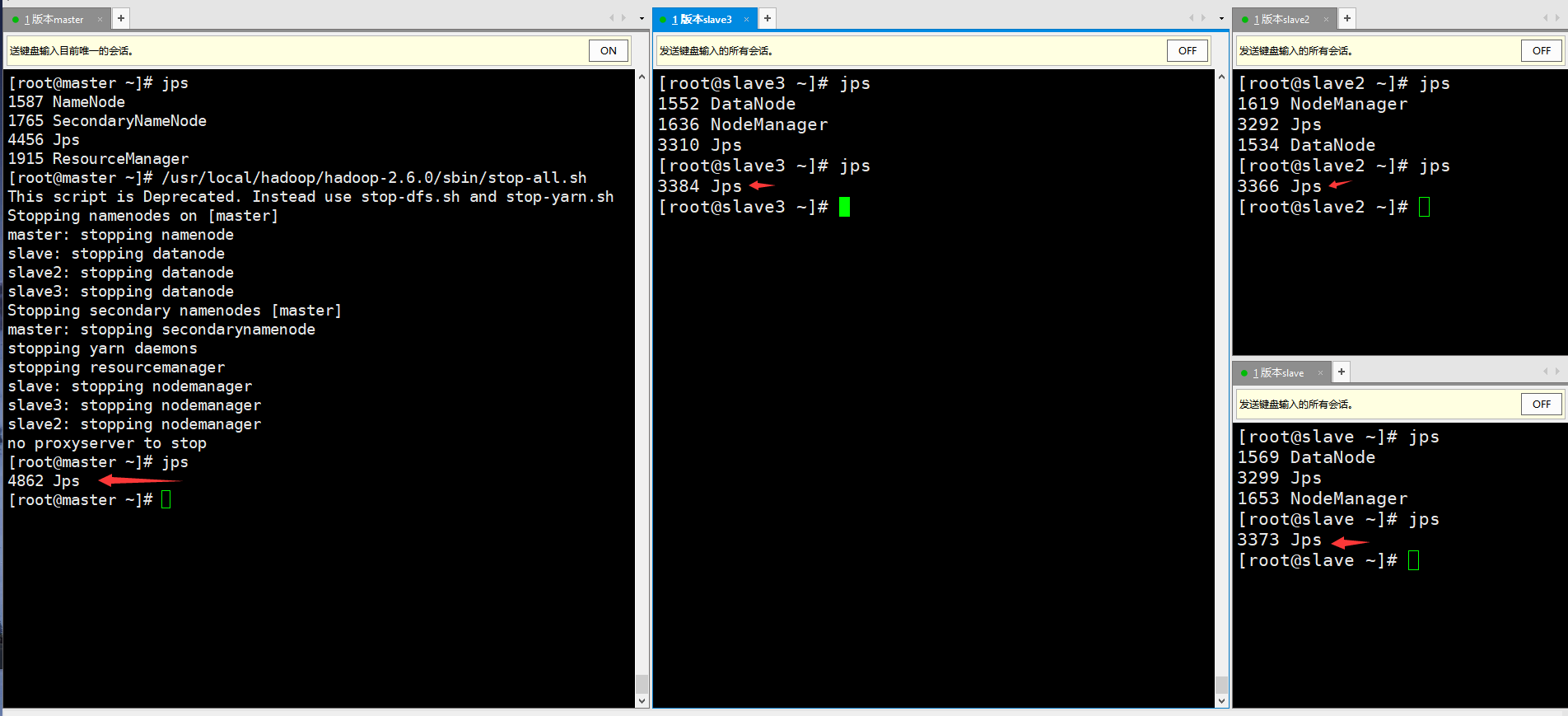
(1) Check the java process. If the fully distributed hadoop process is not closed, it needs to be closed.
[root@master ~]# /usr/local/hadoop/hadoop-2.6.0/sbin/stop-all.sh
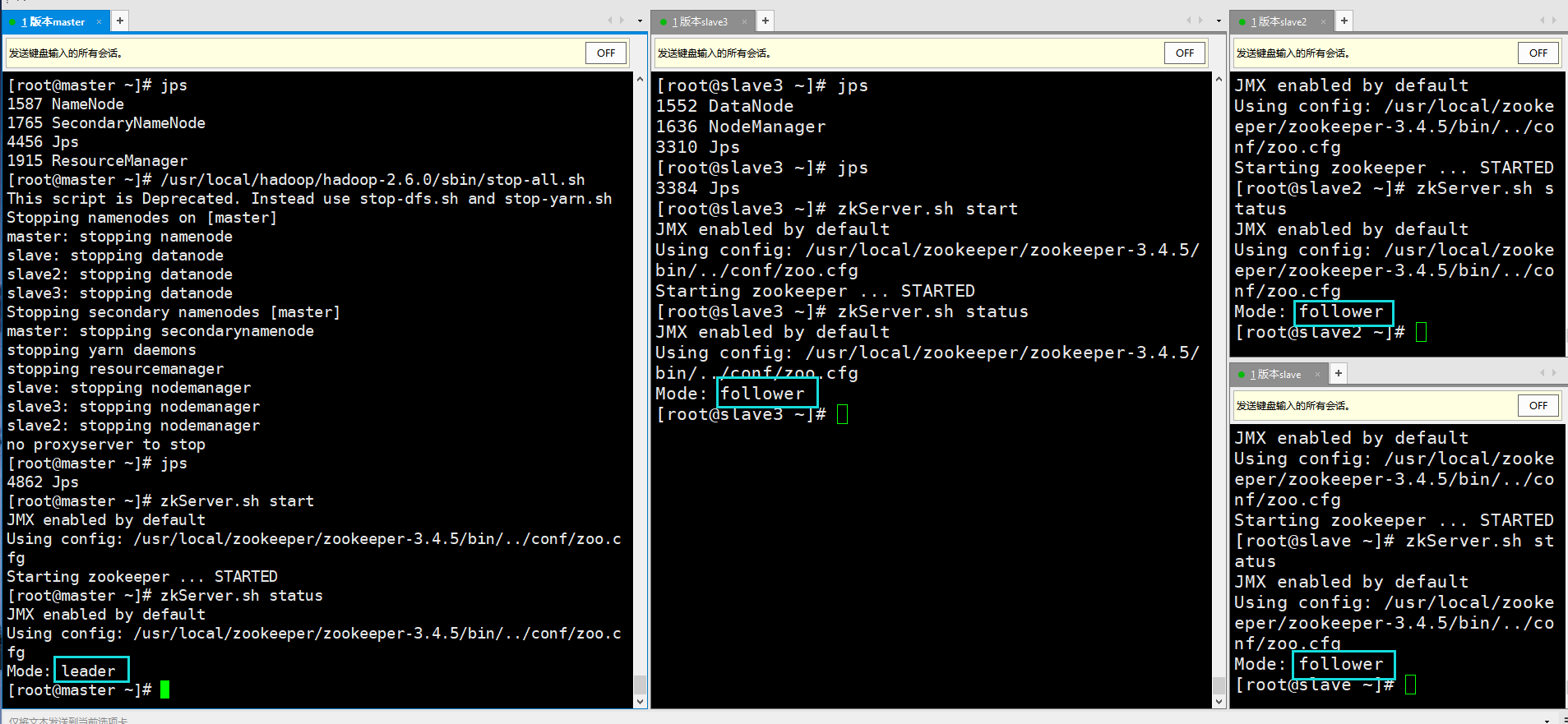
(2) Preparation: start the zookeeper service and view the service process
(3) Start each process
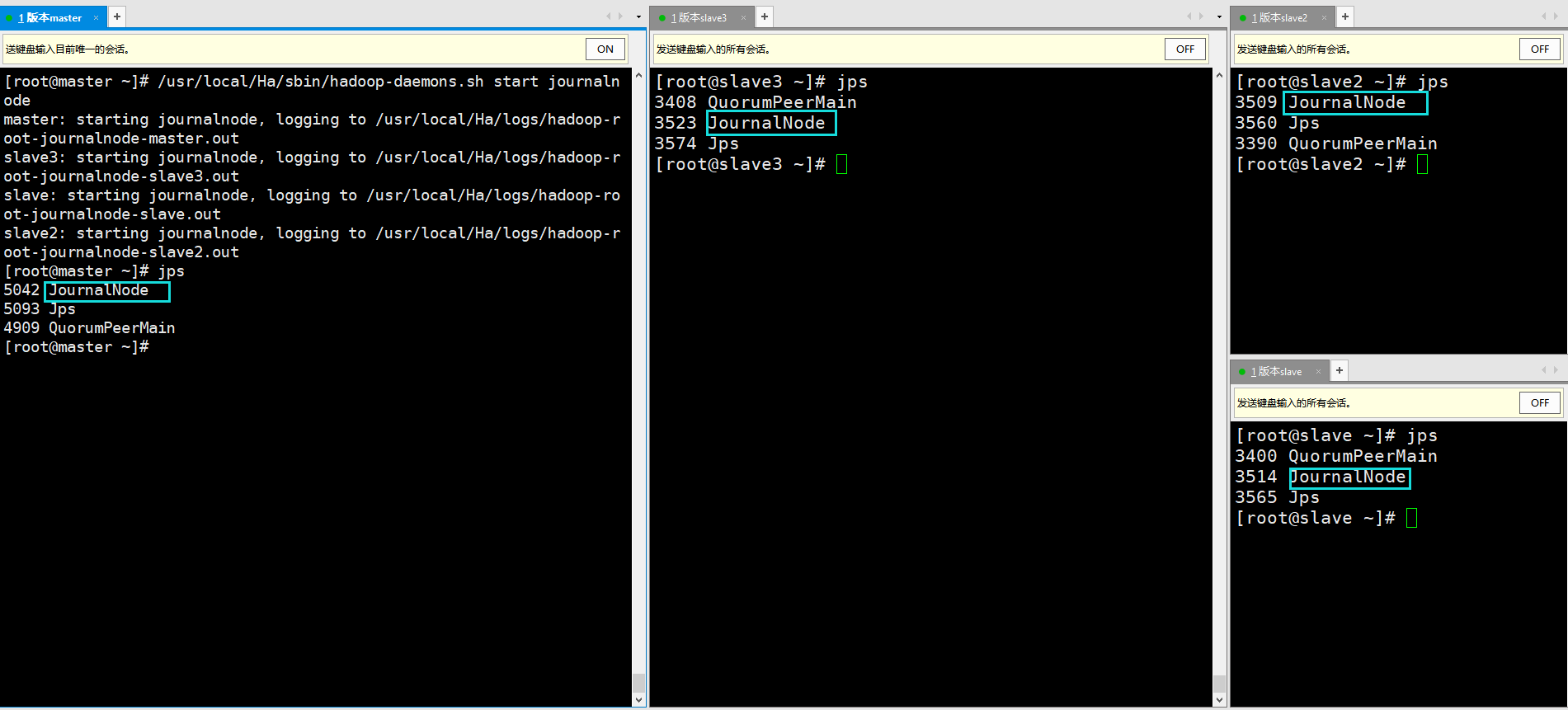
① On each node, start the journalnode service:
You can run the command: / usr/local/Ha/sbin/hadoop-daemon.sh start journalnode on each node
It can also be run on the master node: it can also be: / usr/local/Ha/sbin/hadoop-daemons.sh start journalnode
The difference between the two is that hadoop-daemons.sh can start the journalnode service for all nodes
[root@master ~]# /usr/local/Ha/sbin/hadoop-daemons.sh start journalnode
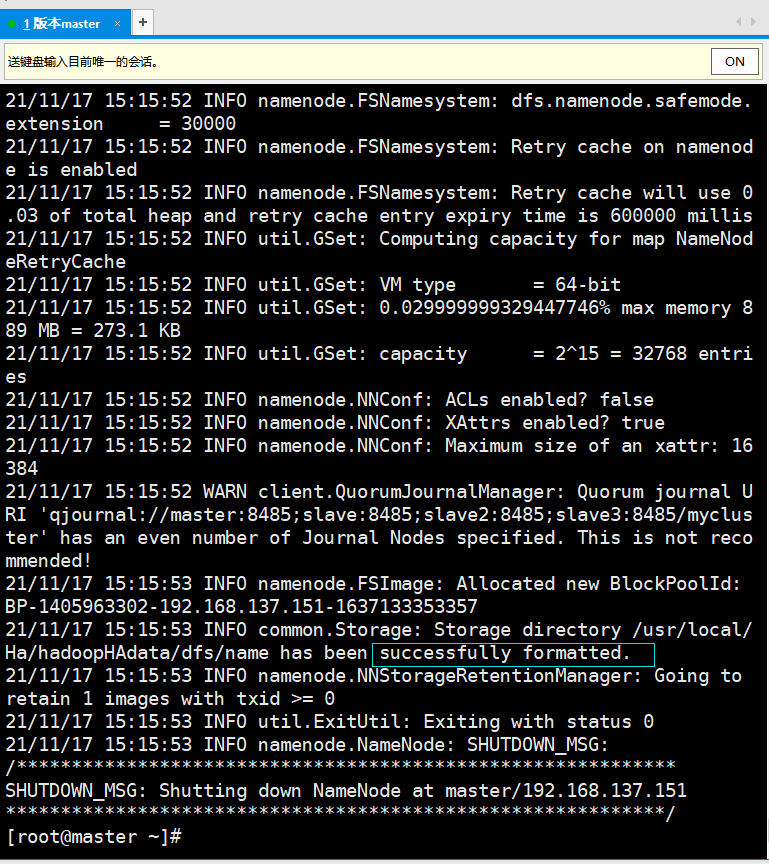
② Format the hdfs file system on the master(nn1) node
[root@master ~]# /usr/local/Ha/bin/hdfs namenode -format
Success is indicated by the following:
INFO common.Storage: Storage directory /usr/local/Ha/hadoopHAdata/dfs/name has been successfully formatted.
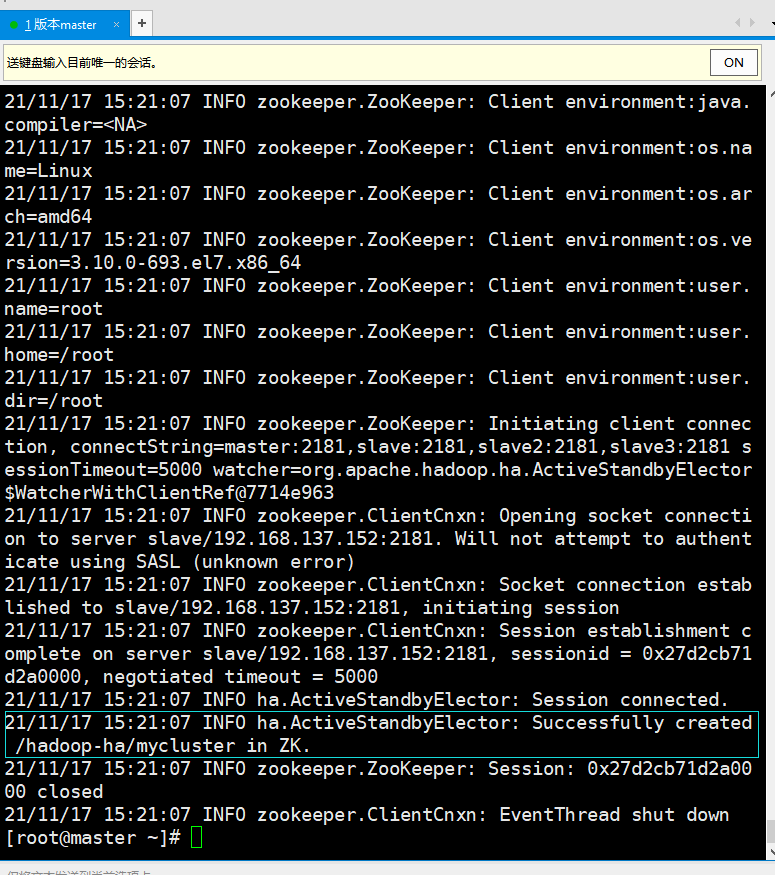
③ Initialize the HA status in Zookeeper on the master(nn1) node:
[root@master ~]# /usr/local/Ha/bin/hdfs zkfc -formatZK
The message shown in the figure below indicates success:
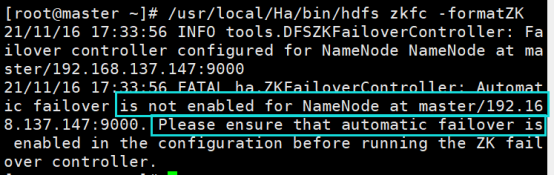
If the following error occurs, add the following configuration to the hdfs-site.xml file of each node:
<!--Start automatic failover -->
<property>
<name>dfs.ha.automatic-failover.enabled.mycluster</name>
<value>true</value>
</property>
④ Start namenode on the master(nn1) node:
[root@master ~]# /usr/local/Ha/sbin/hadoop-daemon.sh start namenode
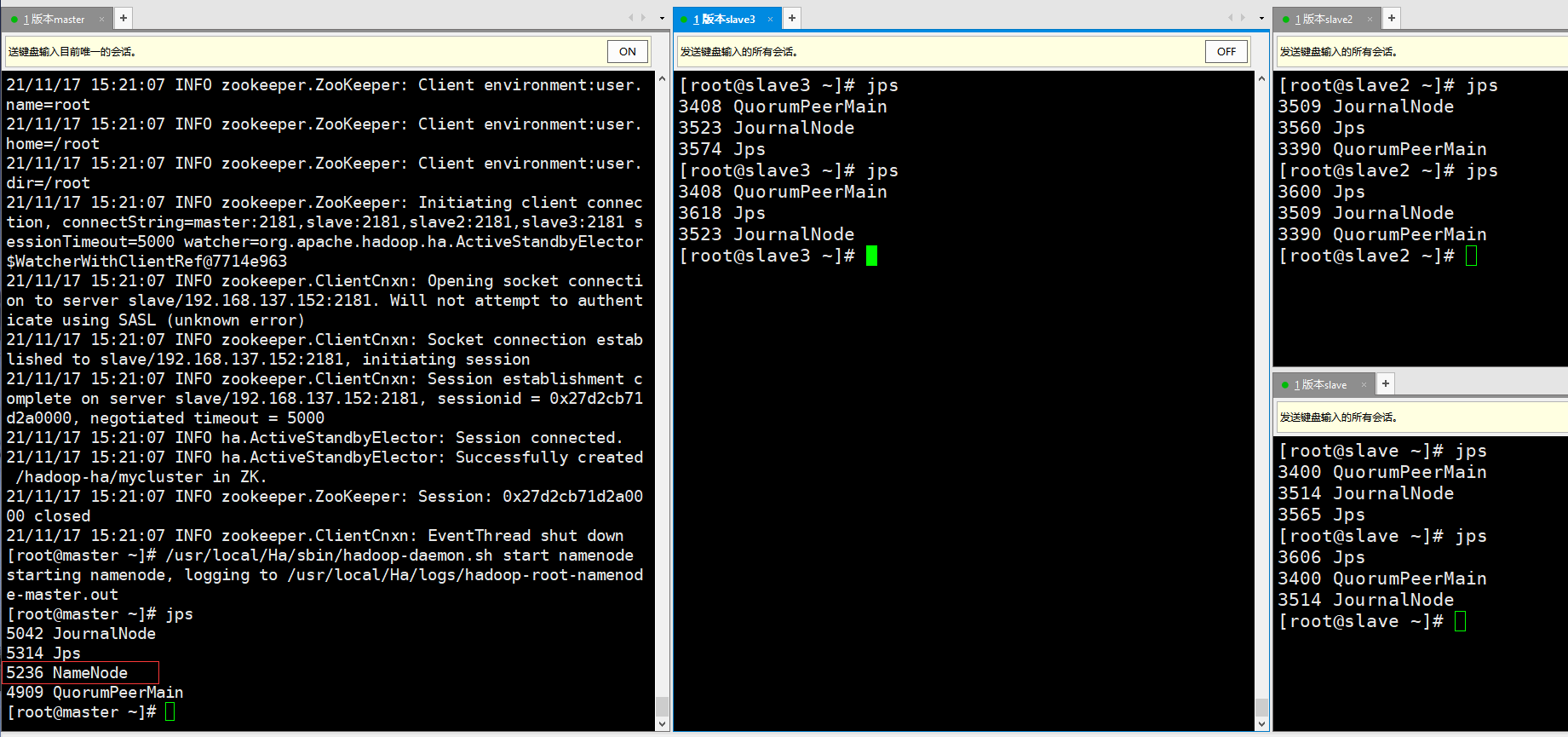
Only the master node has a NameNode process, and other nodes do not.
⑤ Synchronize the metadata information of the master(nn1) node on the slave3(nn2) node:
[root@slave3 ~]# /usr/local/Ha/bin/hdfs namenode -bootstrapStandby
The following figure shows that if the status is 0, it is successful!
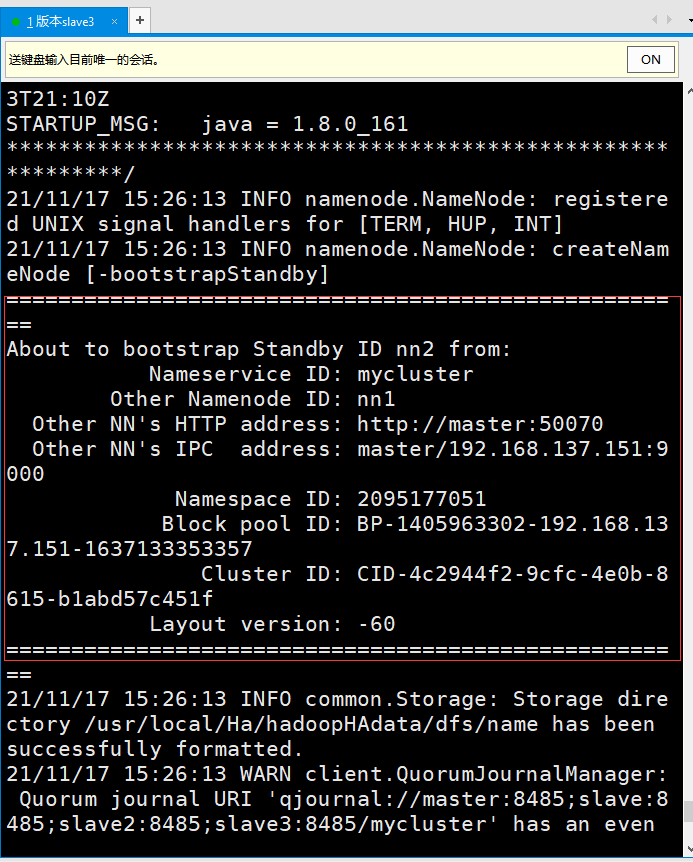
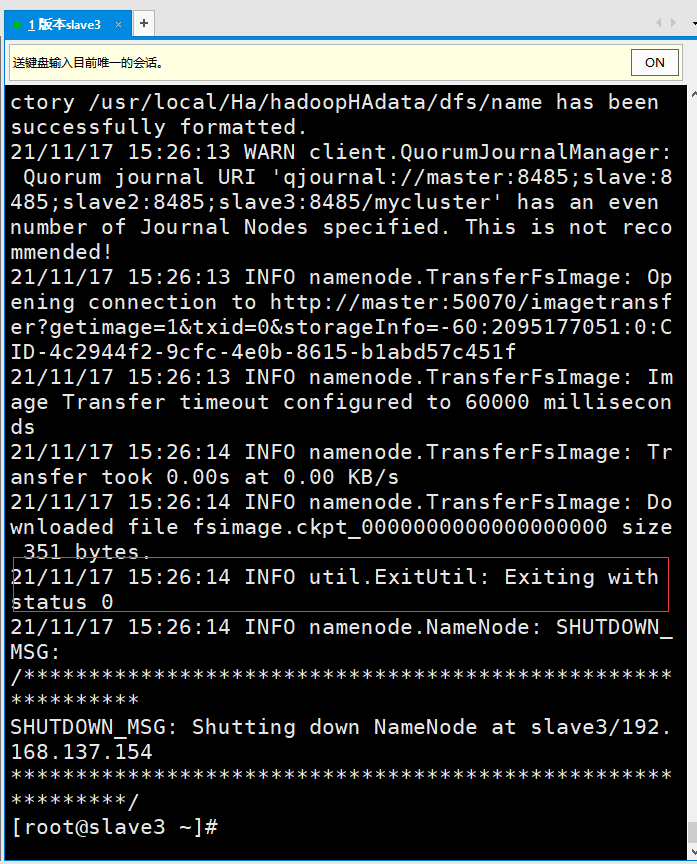
⑥ Start the namenode service on slave3(nn2)
[root@slave3 ~]# /usr/local/Ha/sbin/hadoop-daemon.sh start namenode
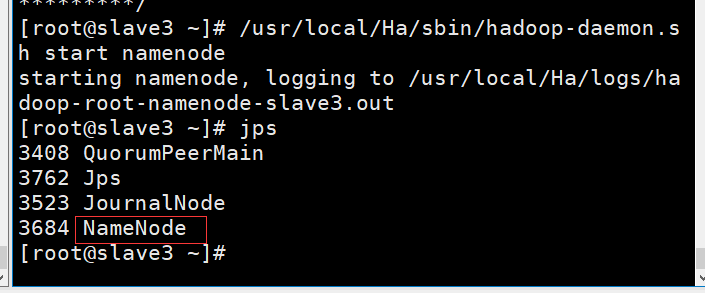
⑦ Start the DataNode process of each node at the master node, or one node at a time
Start of one node:
/usr/local/Ha/sbin/hadoop-daemon.sh start datanode
Start datanodes of all nodes on the master node:
/usr/local/Ha/sbin/hadoop-daemons.sh start datanode
Here, select the master node to start the DataNode process of all nodes:
[root@master ~]# /usr/local/Ha/sbin/hadoop-daemons.sh start datanode
jps view each node process:
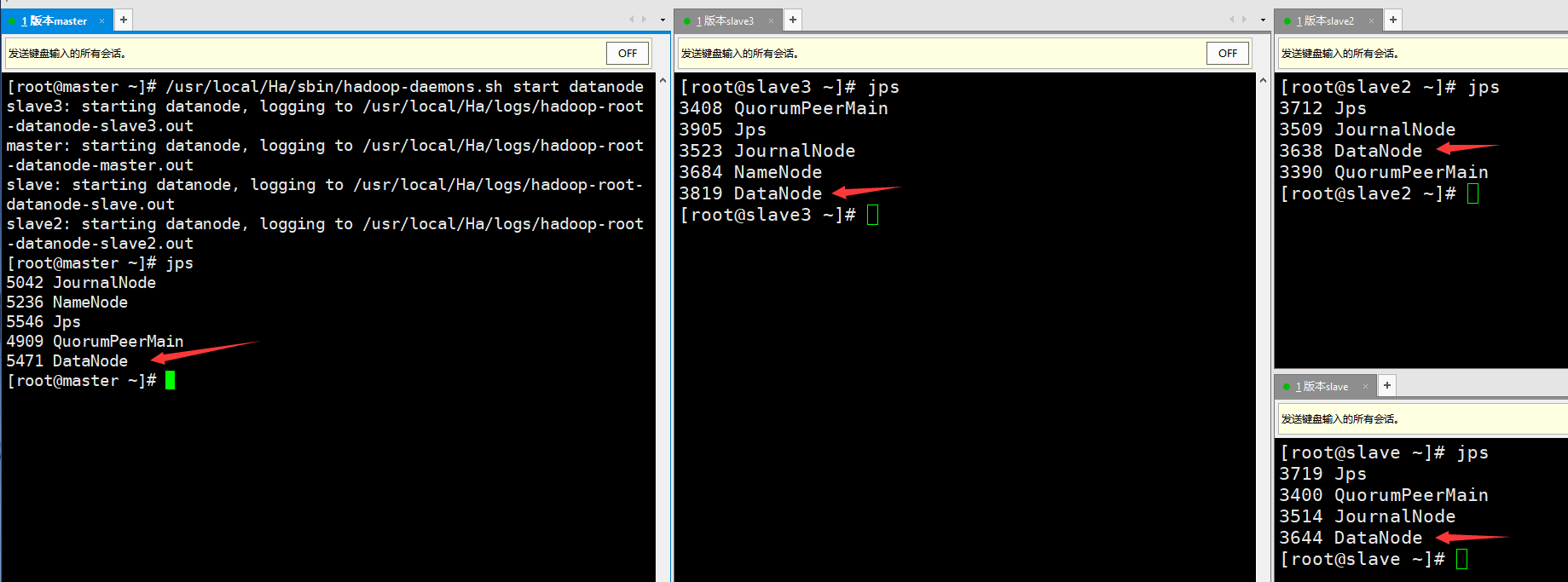
⑧ Start the DFSZK Failover Controller on one of the NameNode(master or slave3) nodes, and the NameNode state of that machine is Active NameNode.
[root@master ~]# /usr/local/Ha/sbin/hadoop-daemons.sh start zkfc
jps checks the process. It is found that only the NameNode node has DFSZKFailoverController process, and other nodes do not.
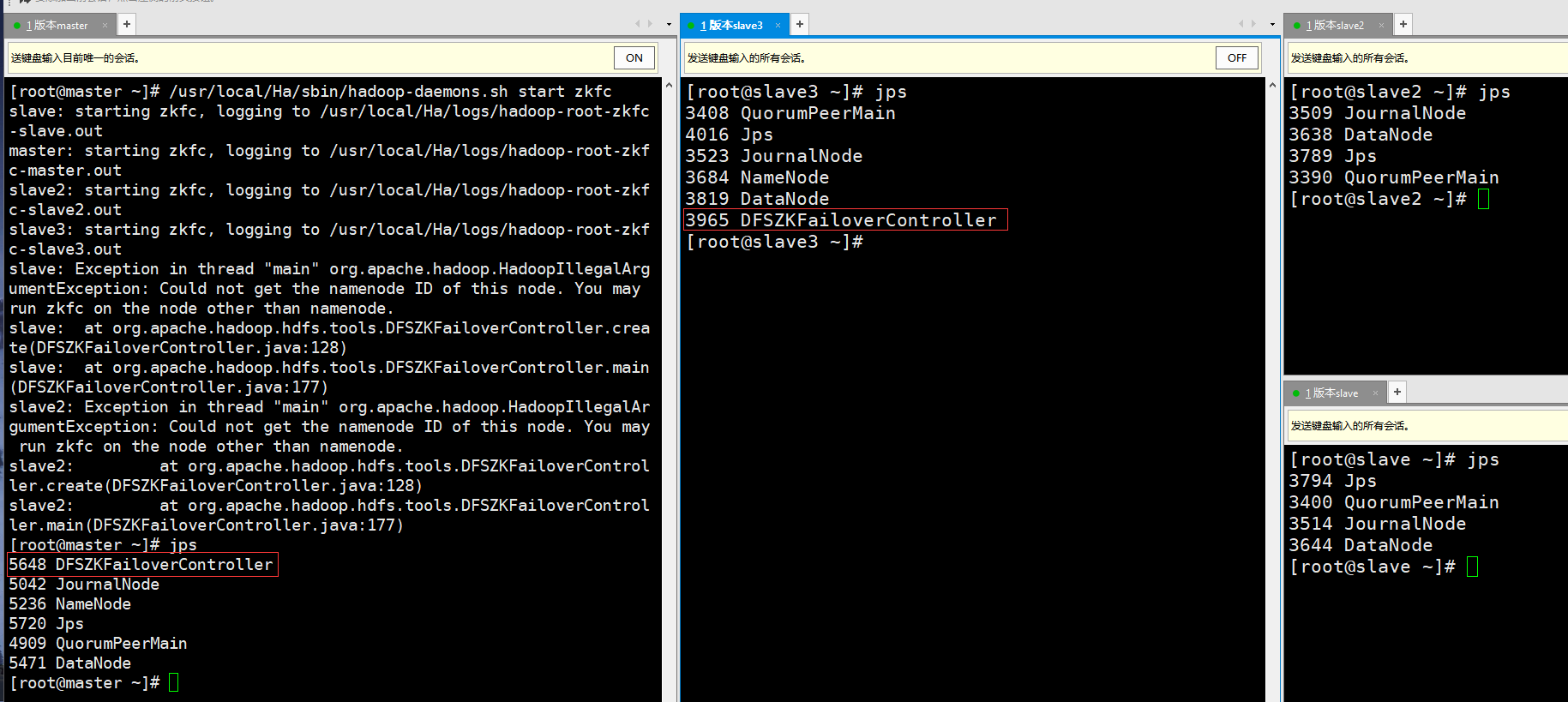
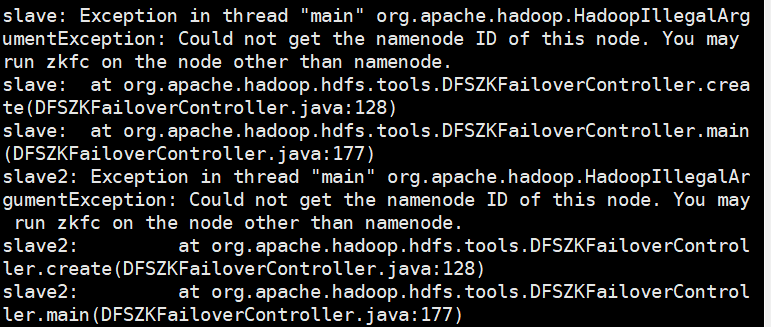
The following information may mean that the port configuration in your configuration file related to zookeeper is wrong, or because other nodes are not NameNode nodes, they will not be found.
In the first case, there will only be one DFSZKFailoverController process in the two namenodes.
In the second case, it is normal when the port is not incorrectly configured.
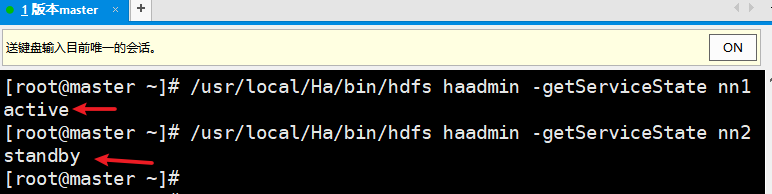
⑨ View NameNode status
- View the status of NameNode nodes (master and slave3) through the browser
Visit: master:50070 and slave3:50070. You can see that since I started zkfc on the master node, the NameNode status of the master node is active and slave3 is standby.
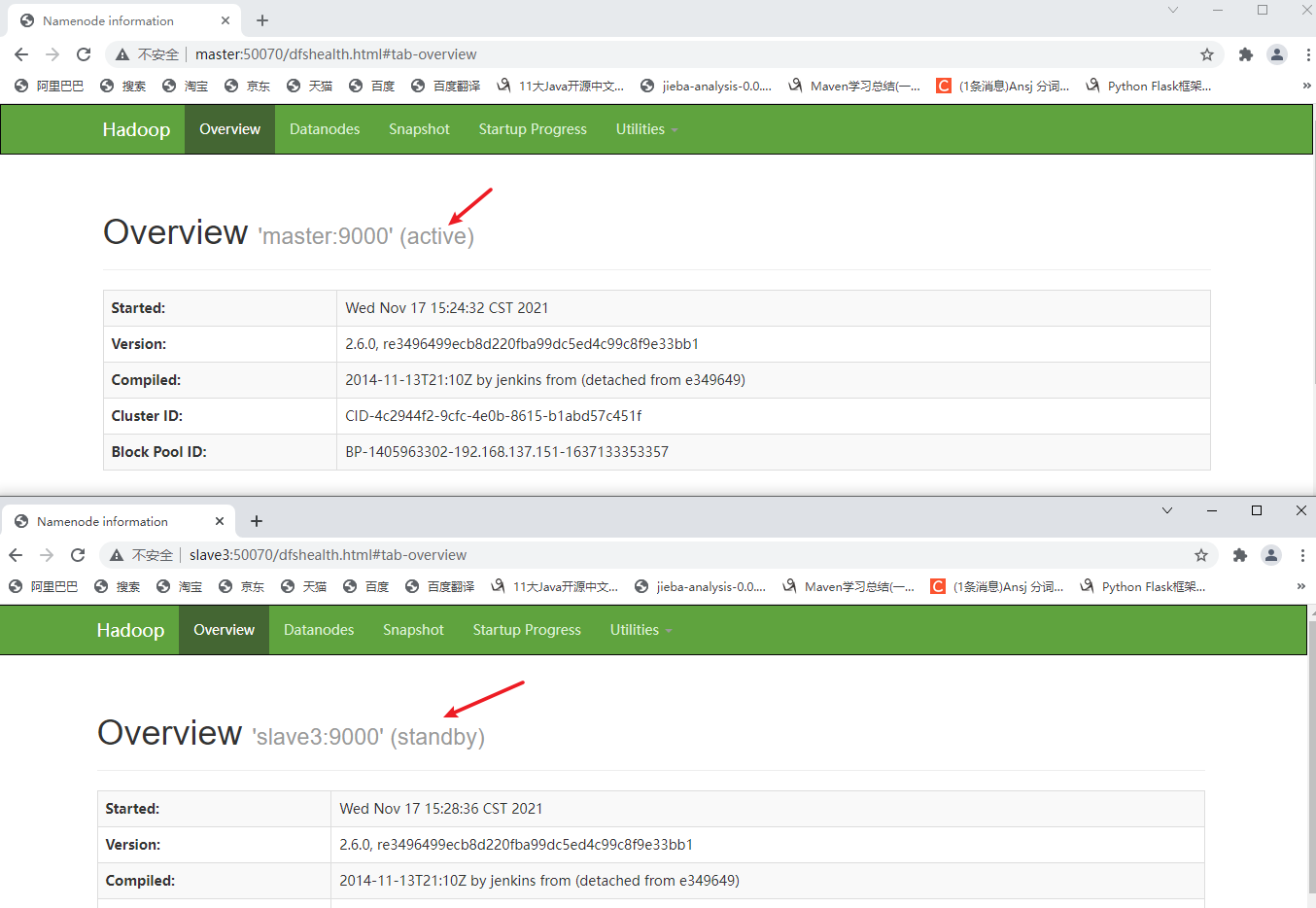
- View status through command:
On the master node:
[root@master ~]# /usr/local/Ha/bin/hdfs haadmin -getServiceState nn1
[root@master ~]# /usr/local/Ha/bin/hdfs haadmin -getServiceState nn2
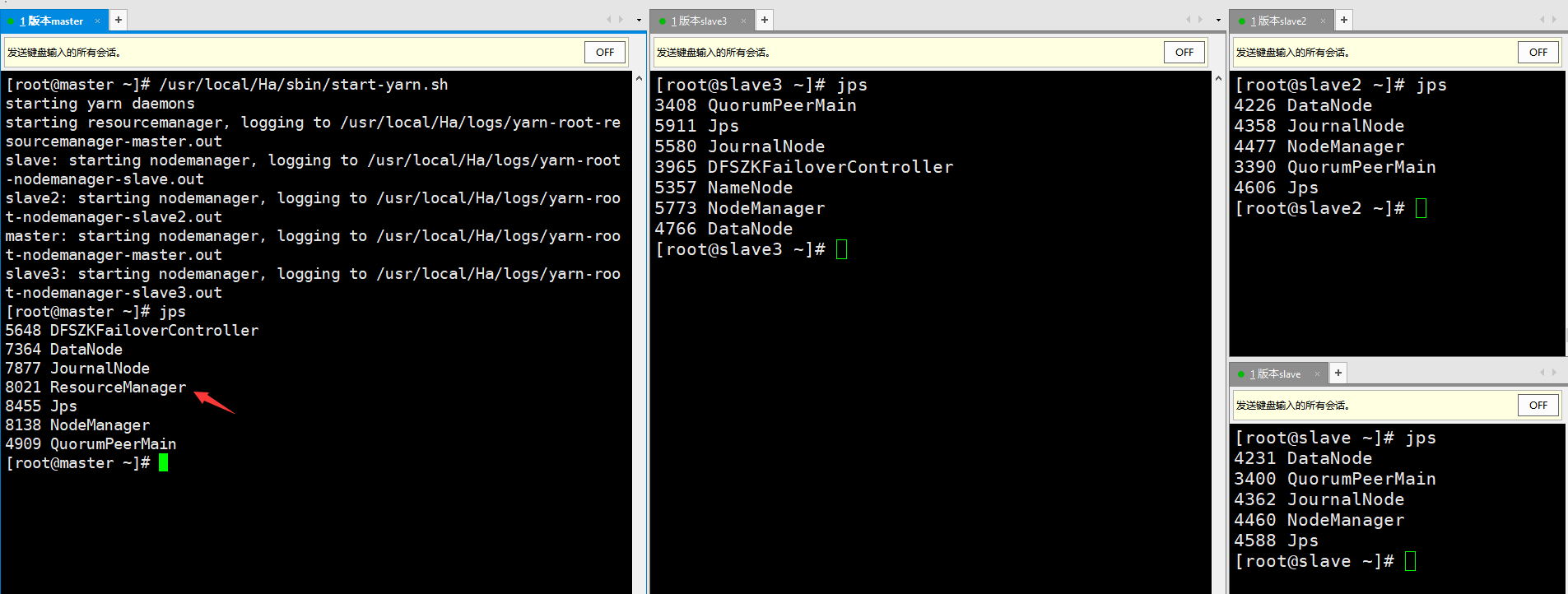
⑩ Start Yarn, terminate NameNode processes whose NameNode node is active, and close all processes
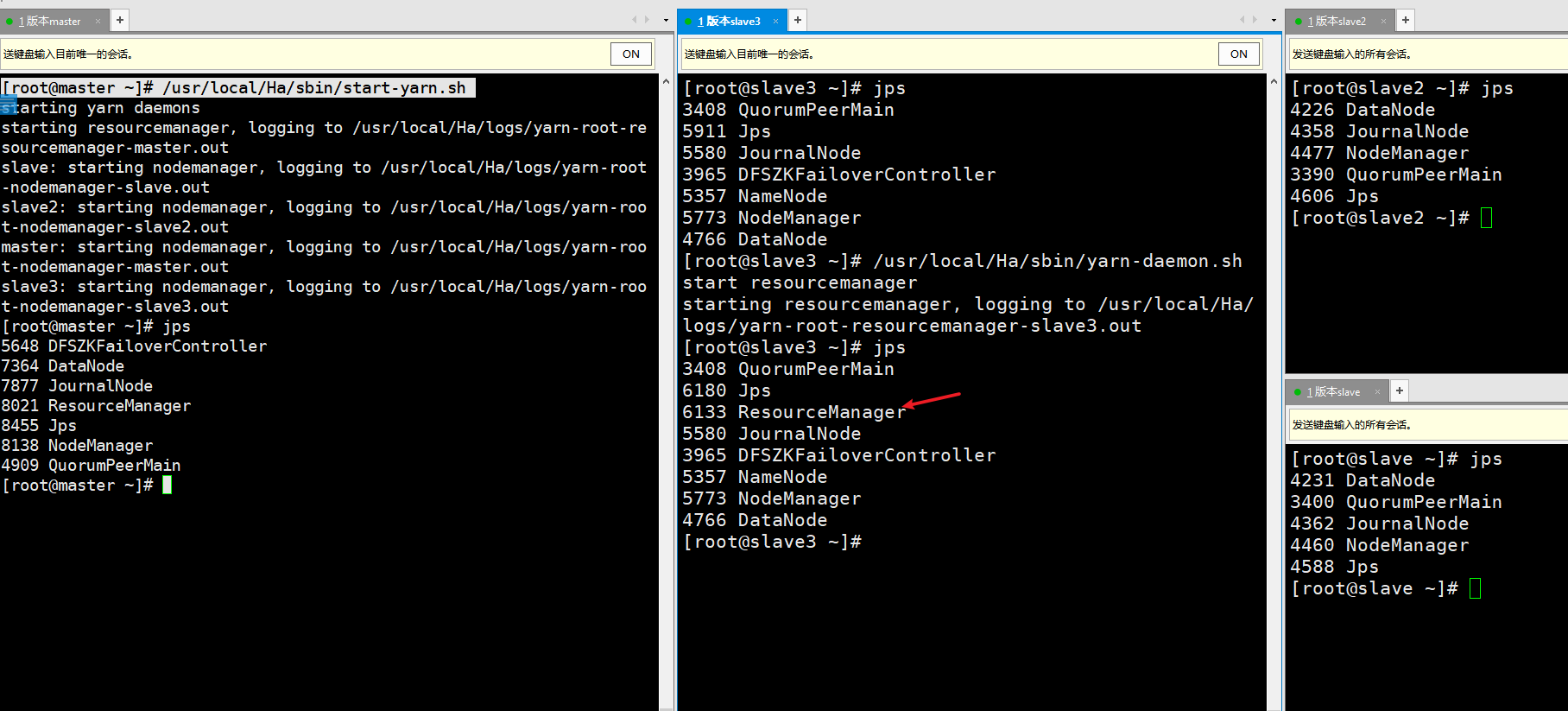
- Start Yarn
master node: / usr/local/Ha/sbin/start-yarn.sh
slave3 node: / usr/local/Ha/sbin/yarn-daemon.sh start resourcemanager
View service status:
[root@master ~]# /usr/local/Ha/bin/yarn rmadmin -getServiceState rm1
[root@master ~]# /usr/local/Ha/bin/yarn rmadmin -getServiceState rm2

- Terminate the NameNode process whose NameNode node is active
Original status:
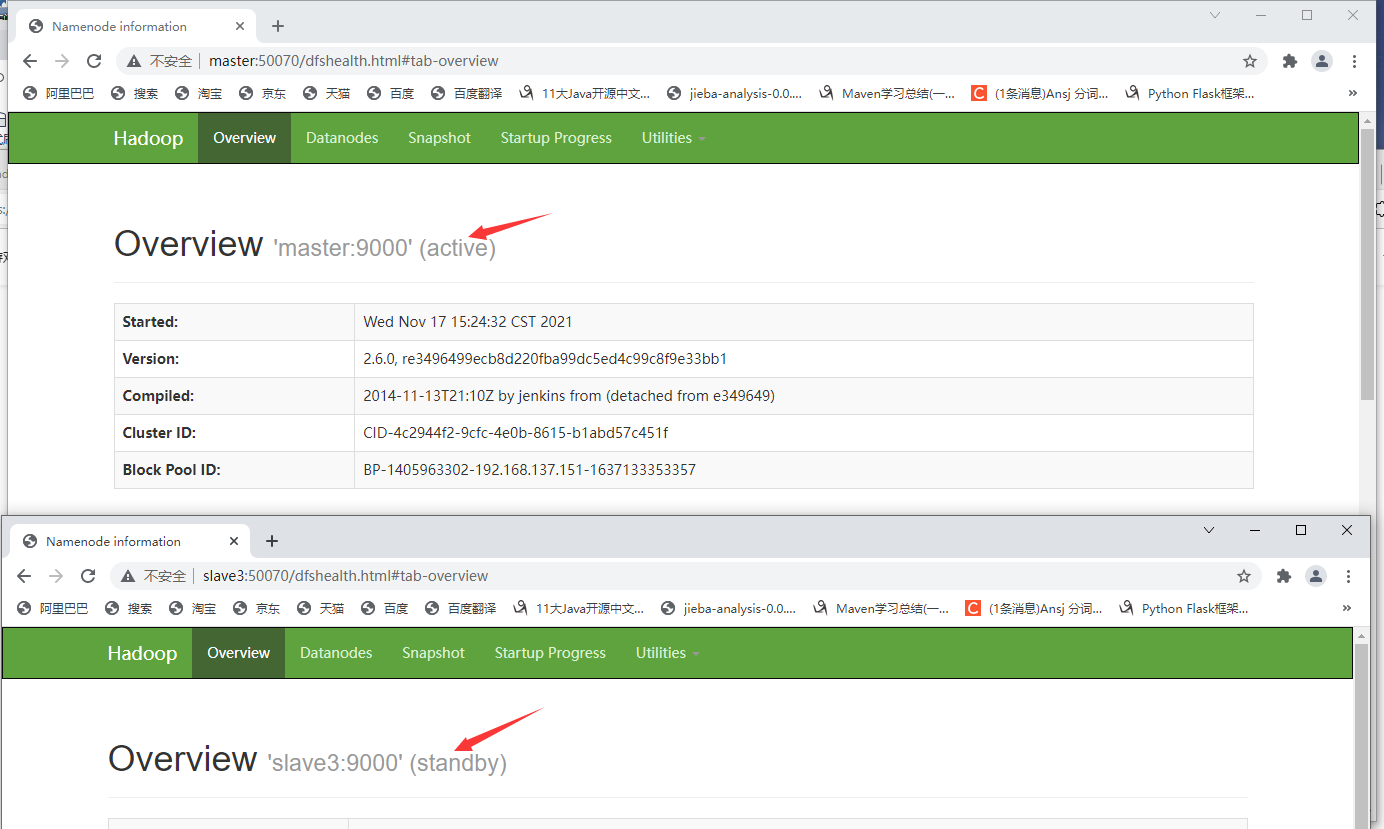
Execute the following command at the node corresponding to the NameNode in the active state (I'm the master node here):
[root@master ~]# jps
[root@master ~]# kill -9 9163
[root@master ~]# jps
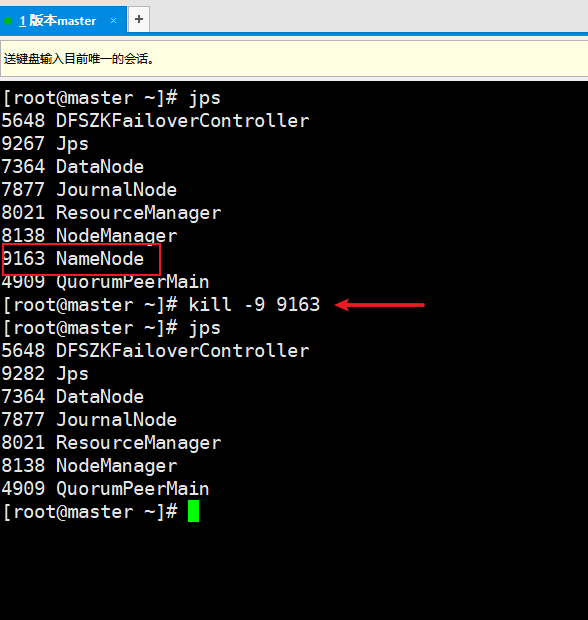
Refresh page:
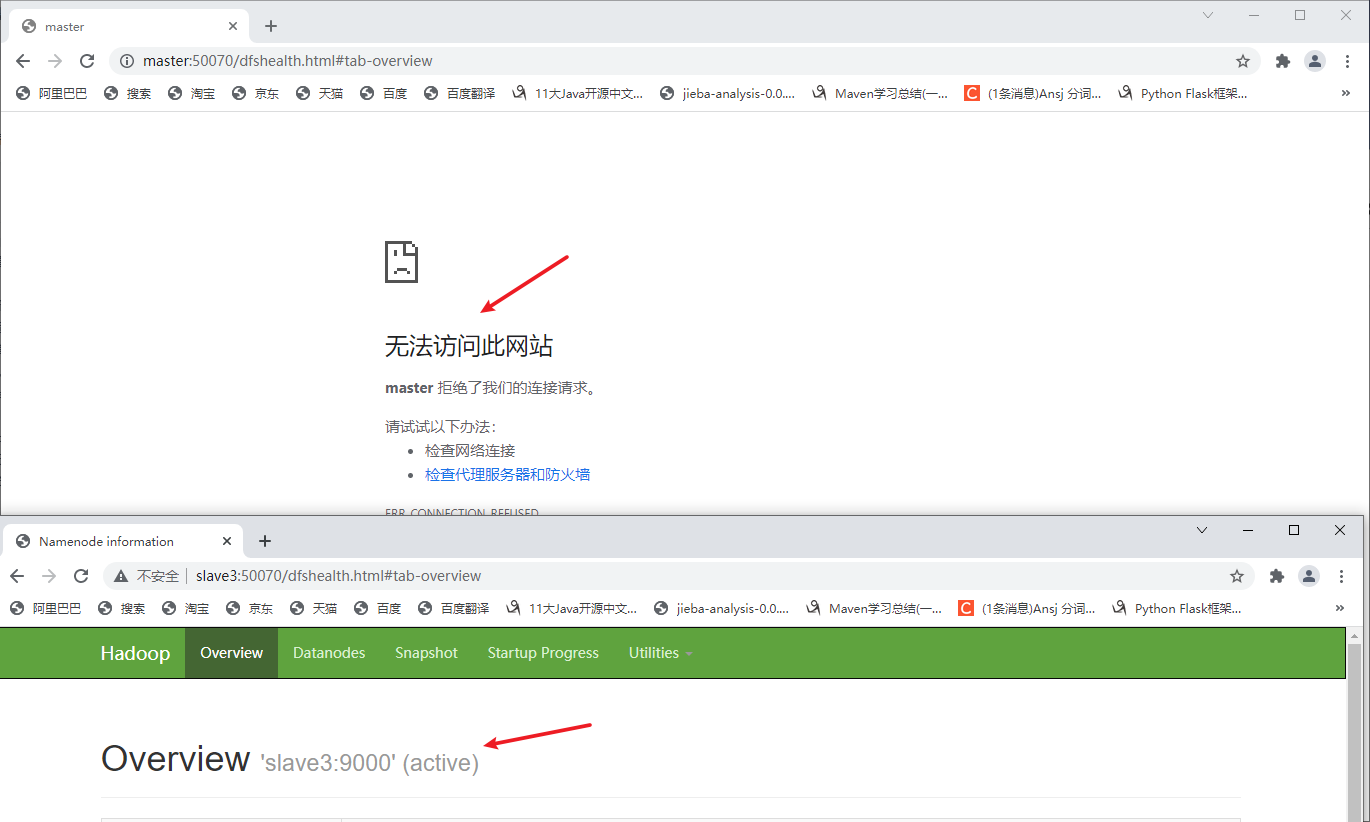
It is found that the NameNode status of slave3 changes to active and the master node crashes. This indicates that the highly available hadoop is successfully built!
- Close all processes:
On the master node:
[root@master ~]# /usr/local/Ha/sbin/stop-dfs.sh
[root@master ~]# /usr/local/Ha/sbin/stop-yarn.sh
[root@master ~]# zkServer.sh stop
(4) Start HA cluster
[root@master ~]# /usr/local/Ha/sbin/start-all.sh
3, Prompt error resolution
(1) Prompt: automatic failover is not enabled
Solution: add the following configuration items in the configuration file hdfs-site.xml:
<!--Start automatic failover -->
<property>
<name>dfs.ha.automatic-failover.enabled.mycluster</name>
<value>true</value>
</property>
(2)slave: Exception in thread "main" org.apache.hadoop.HadoopIllegalArgumentException: Could not get the namenode ID of this node. You may run zkfc on the node other than namenode.slave:atorg.apache.hadoop.hdfs.tools.DFSZKFailoverController.create(DFSZKFailoverController.java:128)
Under normal circumstances: the following information means that other nodes are not NameNode nodes, so they will not be found.
When something goes wrong: the following information may mean that the port configuration in the configuration item related to zookeeper in your configuration file is incorrect.
In the first case, there will only be one DFSZKFailoverController process in the two namenodes.
In the second case, it is normal when there is no port configuration error.
If you think the author's article is helpful to you, you can like it and pay attention to the following Oh ~, thank you!