Catalog
1. Cooccurrence analysis concepts
3.4 Construct Cooccurrence Matrix
4. Importing Gephi to Make Network Diagram
4.1 Download and install Gephi
4.2 Draw a co-occurrence network diagram
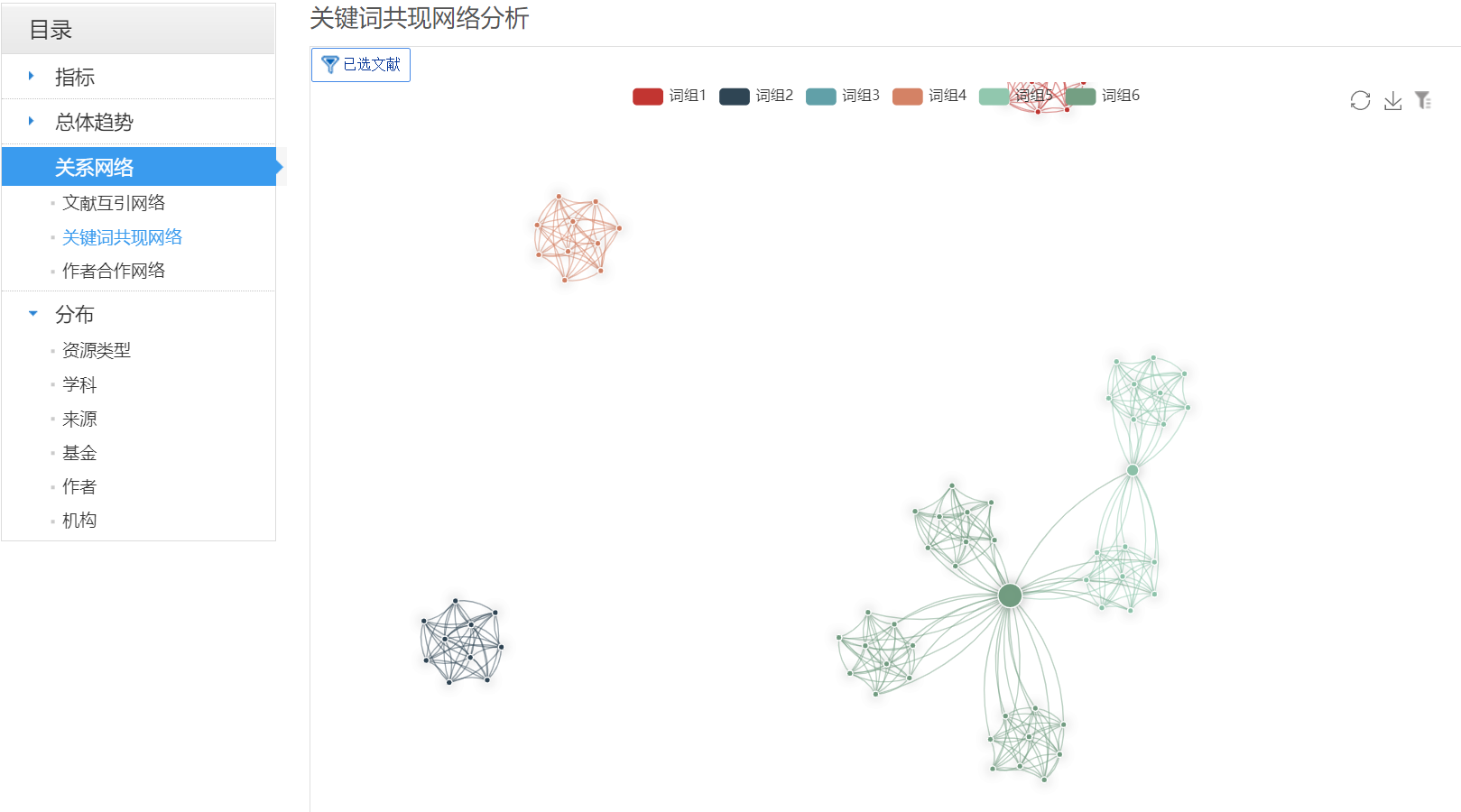
5. How to Make Key Word Cooccurrence Network Diagram with CNKI
1. Cooccurrence analysis concepts
"Cooccurrence" refers to the co-occurrence of information described by a document's feature items, which include the external and internal characteristics of the document, such as title, author, keyword, institution, etc. Cooccurrence analysis, on the other hand, is a quantitative study of co-occurrences to reveal the content relevance of information and the knowledge implied in the features.
2. Cooccurrence Types
(1) Types of co-occurrence analysis in the traditional environment

(2) Types of co-occurrence analysis in Network Environment
Co-word network method is widely used in knowledge network research. The most common method is to construct a Co-word matrix using the keywords and their co-occurrence relationship of the paper, and then map it to a Co-word network and visualize it, so as to reveal the research hot spots and trends, knowledge structure and evolution of a subject in a certain discipline. Citation: Structure and Evolution of Coword Networks - Conceptual and theoretical advances.
Its basic meaning: In large-scale corpus, when two words often co-occur (co-occur) in the same unit intercepted (such as a word interval/sentence/document, etc.), the two words are considered to be semantically related, and the more frequently they co-occur, the closer they are related to each other.
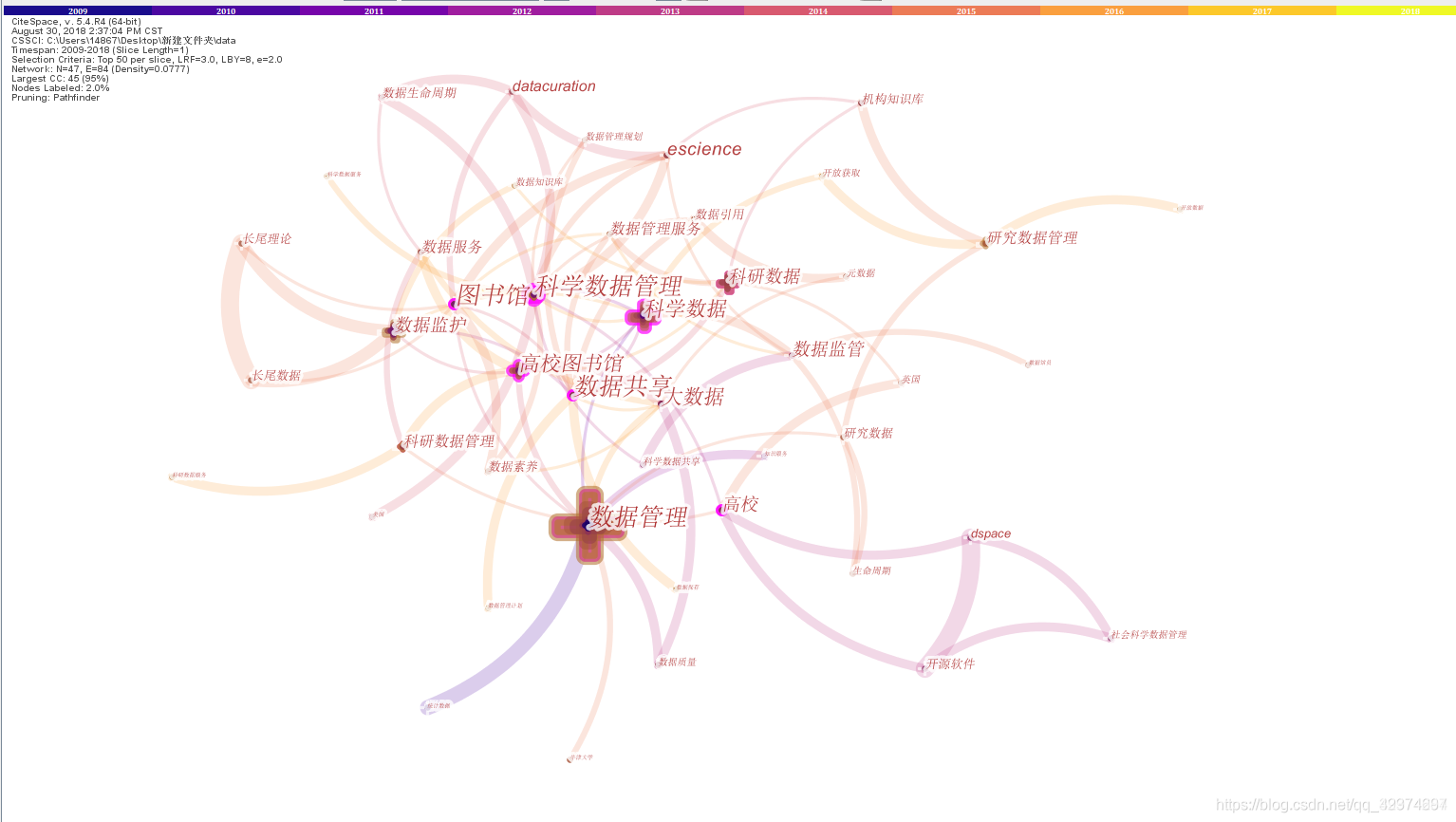 Picture from: CiteSpace keyword co-occurrence map meaning detailed analysis
Picture from: CiteSpace keyword co-occurrence map meaning detailed analysis
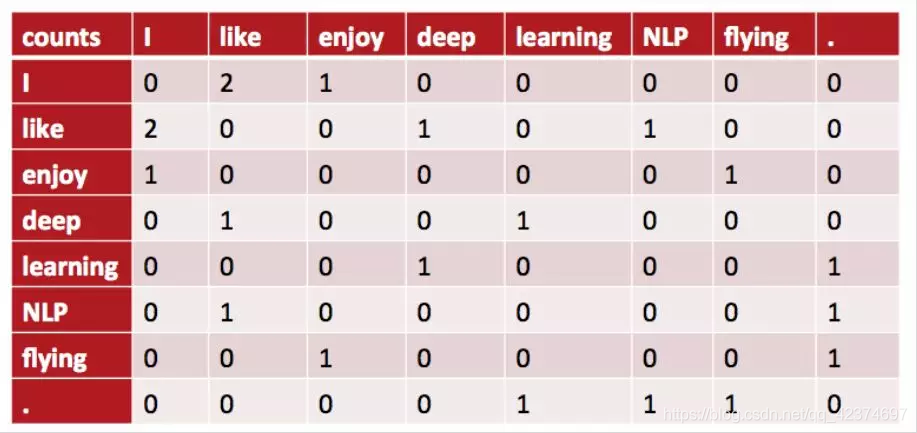
In text mining, there is the concept of a co-occurrence matrix as follows
·I like deep learning.
·I like NLP.
·I enjoy modeling.
3. Code implementation
3.1 Construct Word Separator
import pandas as pd
import numpy as np
import os
import jieba
def my_cut(text):
word_dict_file = './sport_word.dict'
# Load Custom Dictionary
jieba.load_userdict(word_dict_file)
# Load Terms
stop_words = []
with open("./stopwords.txt", encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# stop_words[:10]
return [w for w in jieba.cut(text) if w not in stop_words and len(w)>1]3.2 String Storage
def str2csv(filePath, s, x):
'''
Write string locally csv File
:param filePath: csv File Path
:param s: To Write String(Comma Separated Format)
'''
if x=='node':
with open(filePath, 'w', encoding='gbk') as f:
f.write("Label,Weight\r")
f.write(s)
print('Successful Write to File,Please'+filePath+'View in')
else:
with open(filePath, 'w', encoding='gbk') as f:
f.write("Source,Target,Weight\r")
f.write(s)
print('Successful Write to File,Please'+filePath+'View in')3.3 Build Dictionary
def sortDictValue(dict, is_reverse):
'''
Follow the dictionary value sort
:param dict: Dictionary to Sort
:param is_reverse: Is it sorted in reverse order
:return s: accord with csv A comma-separated string
'''
# The values of a dictionary are sorted in reverse order, items() converts each key-value pair of the dictionary into a tuple, keys enter a function, items [1] represent the second element of the tuple, and reverses represent the reverse order
tups = sorted(dict.items(), key=lambda item: item[1], reverse=is_reverse)
s = ''
for tup in tups: # Comma-separated format required to merge into csv
s = s + tup[0] + ',' + str(tup[1]) + '\n'
return s3.4 Construct Cooccurrence Matrix
def build_matrix(co_authors_list, is_reverse):
'''
According to common list,Construct Cooccurrence Matrix(Store in dictionary),And sort the dictionary by weight
:param co_authors_list: Common List
:param is_reverse: Is Sort Reversed
:return node_str: Node string in triple form(And accord with csv Comma Separated Format)
:return edge_str: Triple Edge String(And accord with csv Comma Separated Format)
'''
node_dict = {} # Node dictionary containing node name + node weight (frequency)
edge_dict = {} # Edge dictionary, containing start + target + edge weights (frequency)
# Layer 1 loop, iterating through each row of information in the entire table
for row_authors in co_authors_list:
row_authors_list = row_authors.split(' ') # Split each line by','and store it in a list
# Layer 2 Cycle
for index, pre_au in enumerate(row_authors_list): # Use enumerate() to get index of traversal times
# Count the frequency of individual words
if pre_au not in node_dict:
node_dict[pre_au] = 1
else:
node_dict[pre_au] += 1
# If you traverse to the first reciprocal element, you don't need to record the relationship; you end the loop
if pre_au == row_authors_list[-1]:
break
connect_list = row_authors_list[index+1:]
# Layer 3 loops through all the words that follow the current line to count how often two words occur
for next_au in connect_list:
A, B = pre_au, next_au
# Fixed order of two words
# Compute only the upper half of the matrix
if A==B:
continue
if A > B:
A, B = B, A
key = A+','+B # Formatted as comma separated A,B, as the key to the dictionary
# If the relationship is not in the dictionary, it is initialized to 1, indicating the number of times the words occur together
if key not in edge_dict:
edge_dict[key] = 1
else:
edge_dict[key] += 1
# Sort the resulting dictionaries by value
node_str = sortDictValue(node_dict, is_reverse) # node
edge_str = sortDictValue(edge_dict, is_reverse) # edge
return node_str, edge_str3.5 Principal function
if __name__ == '__main__':
os.chdir(r'.\')#The os.chdir() method is used to change the current working directory to the specified path
filePath1 = r'.\node.csv'
filePath2 = r'.\edge.csv'
# Read csv file to get data and store it in list
df = pd.read_csv('./AI 11706.csv',encoding='utf-8')
df_ = [w for w in df['abstract'] if len(w)>20]
co_ist = [ " ".join(my_cut(w)) for w in df_]
# Build a co-occurrence matrix (stored in a dictionary) based on a list of common words and sort the dictionary by weight
node_str, edge_str = build_matrix(co_ist, is_reverse=True)
#print(edge_str)
# Write string to local csv file
str2csv(filePath1,node_str,'node')
str2csv(filePath2,edge_str,'edge')Generated edge.csv file Preview Generated node.csv file Preview
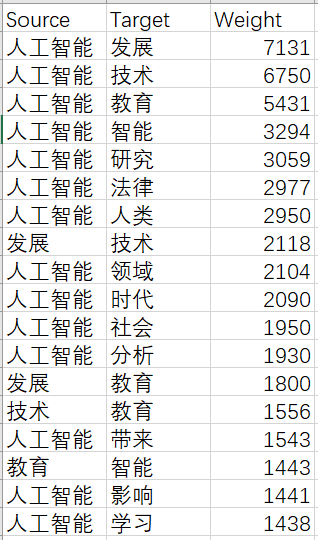
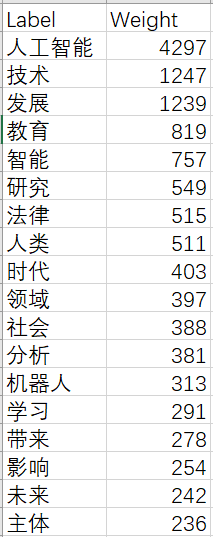
3.6 Weight greater than 300
Because there are more than 1,000 articles (more than 1 week in the data market, but no results have been obtained after a day of training, so we use the first 1,000 articles to test. Because the data set is small, the results are not very accurate, here we mainly talk about the method). Summarize the training results, weights greater than 300 are very large. To ensure the degree of visualization, we intercept words weights greater than 300.
import pandas as pd
edge_str = pd.read_csv('./edge.csv',encoding='utf-8')
edge_str.shape
edge_str1 = edge_str[edge_str['Weight']>300]
edge_str1.shape
Source = edge_str1['Source'].tolist()
Target = edge_str1['Target'].tolist()
co = Source + Target
co =list(set(co))
node_str = pd.read_csv('./node.csv',encoding='utf-8')
#node_str
node_str=node_str[node_str['Label'].isin(co)]
node_str['id']=node_str['Label']
node_str = node_str[['id','Label','Weight']] # Adjust Column Order
#node_str
node_str.to_csv(path_or_buf="node300.txt", index=False) # Write to csv file
edge_str1.to_csv(path_or_buf="edge300.txt", index=False) # Write to csv file
4. Importing Gephi to Make Network Diagram
4.1 Download and install Gephi
Major processes are available for reference Getting started with Gephi _ Step in Time, A Thousands of Miles - CSDN Blog and
Important: I downloaded Gephi-0.9.1 for normal use because I used an earlier, older version of JDK for java that did not match the latest Gephi-0.9.2 installation.
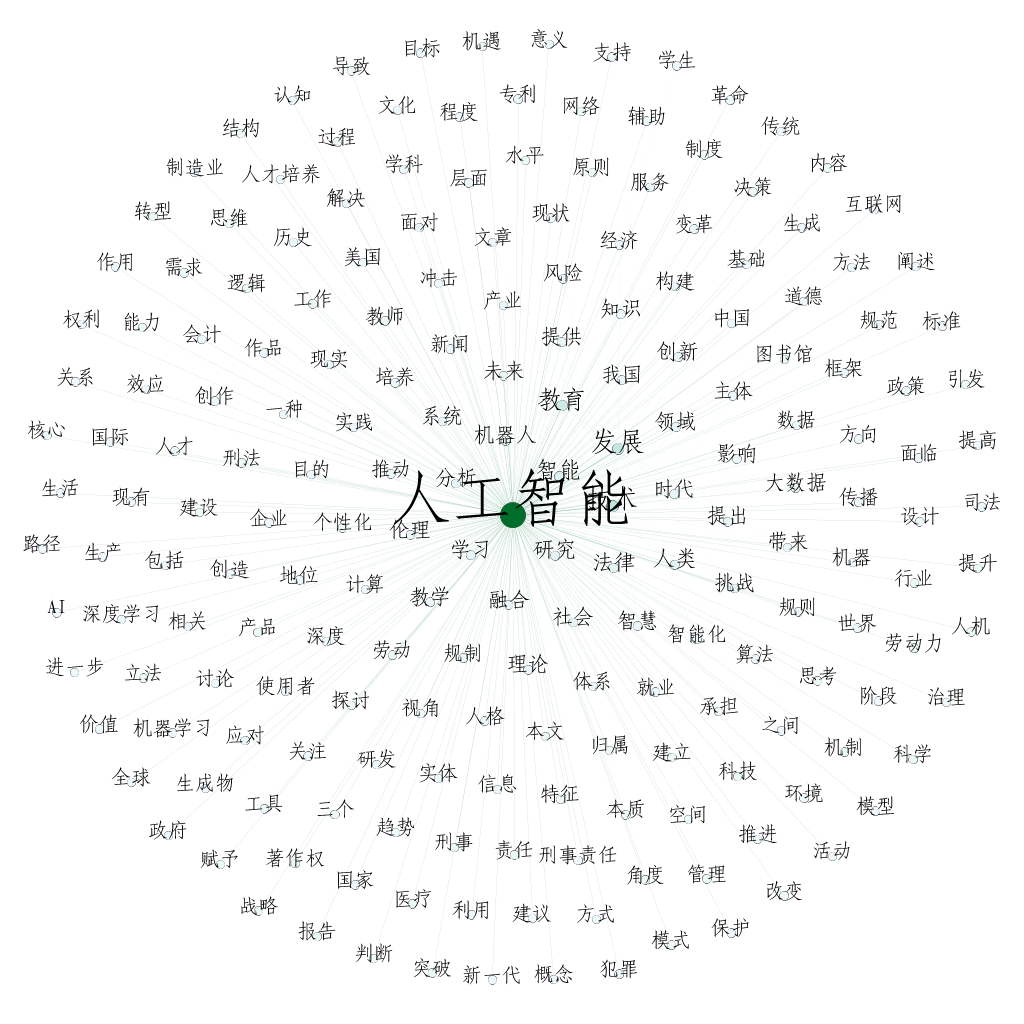
4.2 Draw a co-occurrence network diagram
Following is my first picture, and after a little groping I draw the second one, you can see that the effect has been improved. Ha-ha, because I use a smaller corpus, the following image shows the results for reference only.

5. How to Make Key Word Cooccurrence Network Diagram with CNKI
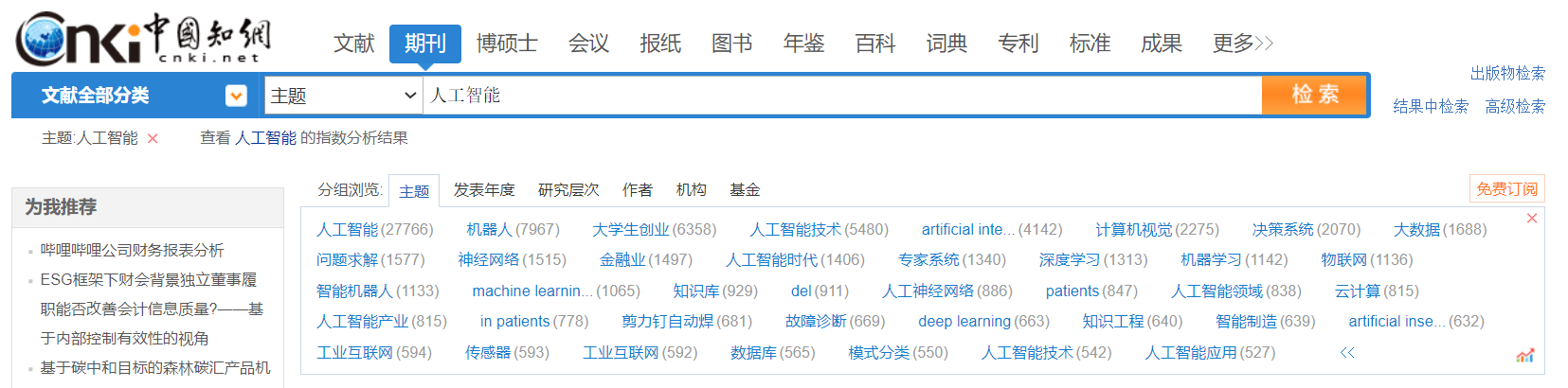
When you enter the HowNet, you can choose to jump to the old version of the interface and discover topics related to search keywords
Select some content and then measure visual analysis
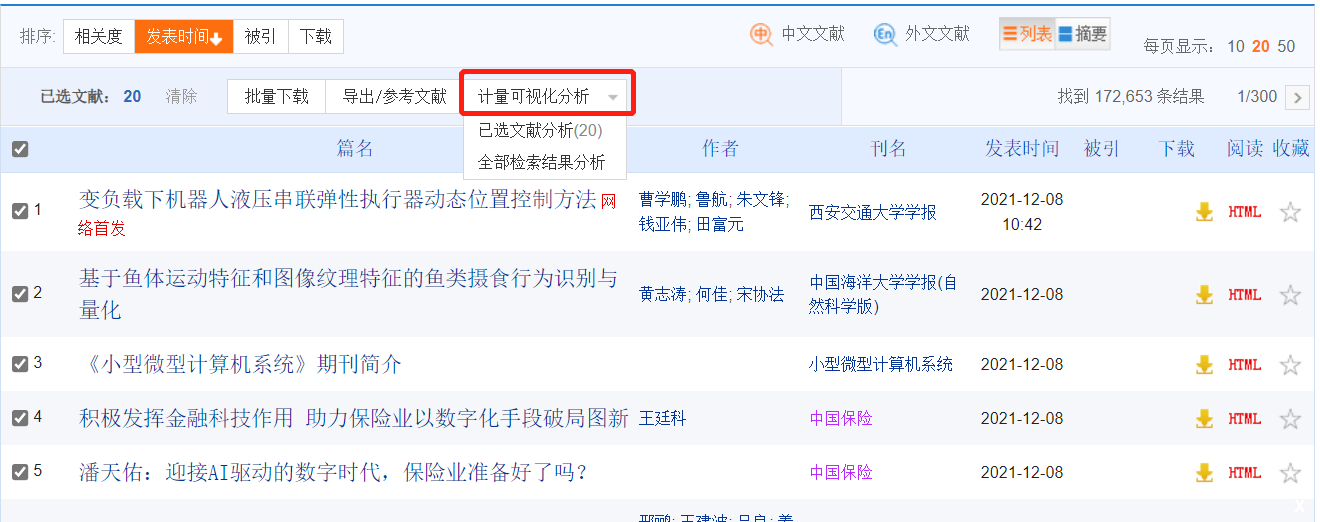 Jump to Visual Interface for Keyword Cooccurrence Analysis
Jump to Visual Interface for Keyword Cooccurrence Analysis