You will use Gensim and Wikipedia to get your first batch of Chinese word vectors and experience the basic process of word vector training.
For a detailed explanation of the principle of word vector, please refer to: https://blog.csdn.net/weixin_40547993/article/details/88779922
Word vector training practice refers to: https://blog.csdn.net/weixin_40547993/article/details/88782251
Operating environment:
IDE: Pycharm2019
python version: 3.6.3
Computer Configuration: Windows 7, i7, 16G Memory
Step-01: Using Wikipedia to Download Chinese Corpus
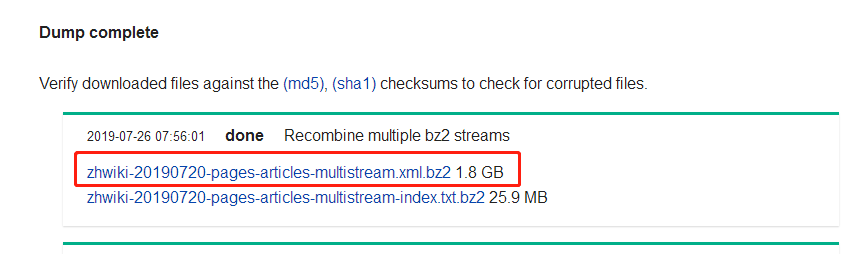
Corpus: https://dumps.wikimedia.org/zhwiki/20190720/
Step-02: Using python wikipedia extractor to extract Wikipedia content
The content of Wikipedia is extracted from the compressed package in xml format of the downloaded corpus, and the traditional characters in it are translated into simplified characters (because many of the Wikipedia pages are traditional Chinese). In addition, before training word vectors in corpus, Chinese sentences need to be segmented. Here, Jieba Chinese word segmentation tool is used to segment sentences. The specific ways of realization are as follows:
# -*- coding: utf-8 -*-
from gensim.corpora import WikiCorpus
import jieba
from langconv import *
def my_function():
space = ' '
i = 0
l = []
zhwiki_name = './data/zhwiki-20190720-pages-articles-multistream.xml.bz2'
f = open('./data/reduce_zhiwiki.txt', 'w',encoding='utf-8')
wiki = WikiCorpus(zhwiki_name, lemmatize=False, dictionary={}) #Read training corpus from xml file
for text in wiki.get_texts():
for temp_sentence in text:
temp_sentence = Converter('zh-hans').convert(temp_sentence) #Conversion of Traditional Chinese to Simplified Chinese
seg_list = list(jieba.cut(temp_sentence)) #participle
for temp_term in seg_list:
l.append(temp_term)
f.write(space.join(l) + '\n')
l = []
i = i + 1
if (i %200 == 0):
print('Saved ' + str(i) + ' articles')
f.close()
if __name__ == '__main__':
my_function()
The program runs as follows. There are nearly 340,000 Wikipedia articles in total. The length of extracting content is about 1-2 hours.
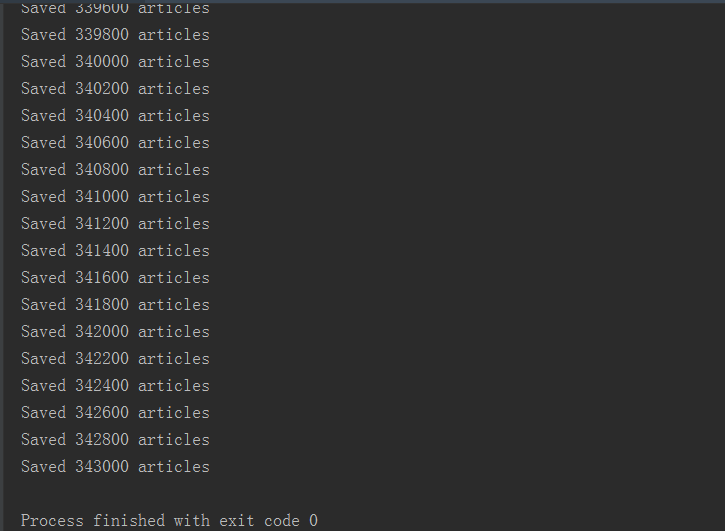
The processed corpus is shown in the figure. The reduced_zhiwiki.txt document stored after the segmentation is completed has 1.24G:

When you see the participle file, in the general NLP processing, you will need to stop the word processing. Because word2vec's algorithm depends on context, the context may be a stop word. So for word2vec, you don't have to stop.
Another way of implementation can also be referred to: https://github.com/attardi/wikiextractor
Step-03: Word vector training using Gensim
Reference:
- https://blog.csdn.net/weixin_40547993/article/details/88782251
- https://radimrehurek.com/gensim/models/word2vec.html
Refer to Gensim's document and Kaggle's reference document to get the word vector. Note that you need to use the Jieba participle to split Wikipedia content into one word and then save it in a new file. Then, you need to use Gensim's LineSentence class to read files. Then train the word vector Model.
Before training, you need to know the parameters in Gensim:
Detailed parameters in gensim toolkit:
In gensim, word2vec-related API s are in the package gensim.models.word2vec. The parameters related to the algorithm are in the class gensim.models.word2vec.Word2Vec.
The parameters that need to be noticed in the algorithm are:
Sentences: The corpus we want to analyze can be a list or read through a file.
Size: The dimension of the word vector, the default value is 100. The value of this dimension is generally related to the size of our corpus. If it is a small corpus, such as a text corpus less than 100M, the default value is generally enough. If it is a large corpus, it is suggested to increase the dimension.
3) window: that is, the maximum distance of the context of a word vector. This parameter is marked in our algorithmic principle chapter as follows: the larger the window is, the more distant a word will have a context relationship. The default value is 5. In actual use, the size of the window can be dynamically adjusted according to the actual needs. If it is a small corpus, the value can be set smaller. For general corpus, this value is recommended between [5,10].
4) sg: that is, the choice of our two word2vec models. If it is 0, it is CBOW model, Skip-Gram model and CBOW model by default.
5) hs: That is, the choice of two solutions of word2vec is Negative Sampling if 0, Negative Sampling if 1, and the number of negative samples is greater than 0, Hierarchical Softmax. The default is 0, or Negative Sampling.
6) negative: The default is 5, even when Negative Sampling is used. Recommended between [3,10]. This parameter is marked as neg in our algorithmic principle chapter.
Cbow_mean: When CBOW is used only for projection, it is 0, then the algorithm is the sum of the word vectors of the context and the average value of the word vectors of the context is 1. In our Principle Paper, it is described according to the average value of word vector. Individuals prefer to use the average to express, the default value is also 1, do not recommend modifying the default value.
8) min_count: The minimum word frequency of the word vector needs to be calculated. This value can remove some very obscure low-frequency words, the default is 5. If it is a small corpus, it can be lowered.
9) iter: The maximum number of iterations in the stochastic gradient descent method is 5 by default. For large corpus, this value can be increased.
10) alpha: Initial iteration length in the stochastic gradient descent method. The principle of the algorithm is marked as 0.025 by default.
11) min_alpha: Since the algorithm supports the gradual reduction of step size in the iteration process, min_alpha gives the minimum iteration step size. The iteration step size of each round in random gradient descent can be obtained by iter, alpha and min_alpha. This part is not the core content of word2vec algorithm, so we did not mention it in the principle chapter. For large corpus, alpha, min_alpha and ITER need to be tuned together to select the appropriate three values.
12)worker: The number of threads used for training word vectors by default is 3.
After understanding the parameters in gensim toolkit, the specific code of word vector training is as follows:
# -*- coding: utf-8 -*-
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
def my_function():
wiki_news = open('./data/reduce_zhiwiki.txt', 'r',encoding='utf-8')
model = Word2Vec(LineSentence(wiki_news), sg=0,size=200, window=5, min_count=5, workers=6)
model.save('./model/zhiwiki_news.word2vec')
if __name__ == '__main__':
my_function()
The LineSentence class provided by word2vec is used to read the file, and then the word2vec module is applied. The parameters can be adjusted according to their own needs.
A total of 17 minutes were spent in the training process:
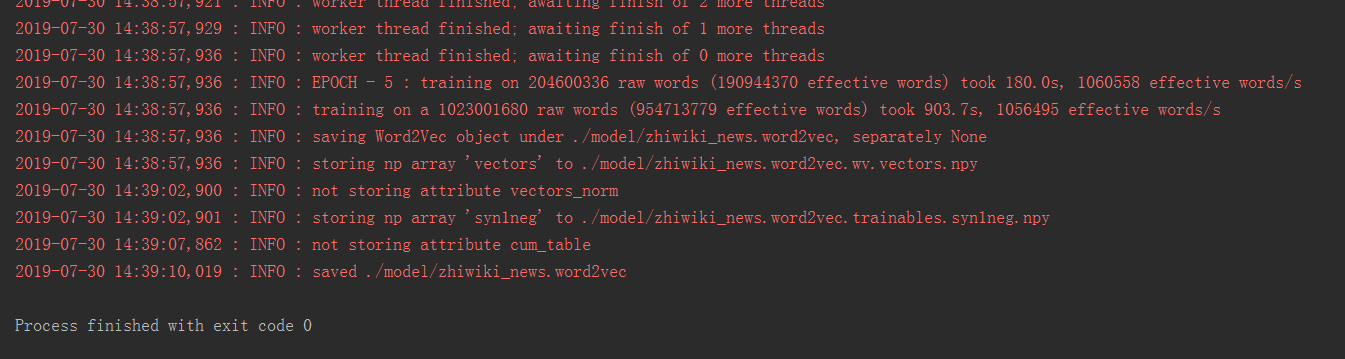
The training generates three files under the model folder, as shown in the following figure:
Step-04: Test synonyms, find a few words, see the effect
Test synonyms, find a few words to test
Testing the effect of model training, we can judge the effect of training according to the similarity of words.
#coding=utf-8
import gensim
import pandas as pd
def my_function():
model = gensim.models.Word2Vec.load('./model/zhiwiki_news.word2vec')
print(model.similarity('Tomatoes','tomato')) #The similarity is 0.60256344.
print(model.similarity('Tomatoes','Banana')) #The similarity is 0.49495476.
# print(model.similarity('artificial intelligence','Big data')
# print(model.similarity('drop','shared bicycle')
result = pd.Series(model.most_similar(u'Alibaba')) #Search for synonyms
print(result)
result1 = pd.Series(model.most_similar(u'The Imperial Palace'))
print(result1)
print(model.wv['China']) #View the Word Vector of China
if __name__ == '__main__':
my_function()
The results are as follows:
0.60256344 0.49495476 0 (Jack Ma, 0.7043435573577881) 1 (pony, 0.6246073842048645) 2 (TaoBao, 0.613457977771759) 3 (Qihoo, 0.6117738485336304) 4 (Legend Group, 0.605375349521637) 5 (Ctrip, 0.5971101522445679) 6 (Stake in, 0.5965164303779602) 7 (Unfamiliar Street, 0.5919643640518188) 8 (private placement, 0.5906440019607544) 9 (Ninth City, 0.5895131230354309) dtype: object 0 (South court, 0.6943957805633545) 1 (Beijing Forbidden City, 0.6514502763748169) 2 (The Palace Museum, 0.6480587720870972) 3 (Summer Palace, 0.6093741655349731) 4 (Dazhong Temple, 0.5974366664886475) 5 (Capital Museum, 0.5919761657714844) 6 (Baoyun Building, 0.5763161182403564) 7 (The Forbidden City, 0.5700971484184265) 8 (Old Summer Palace, 0.5676841735839844) 9 (Beijing Palace Museum, 0.5617257952690125) dtype: object [ 1.0179822 1.3085549 -0.15886988 2.2728844 0.30418944 -0.72818166 1.5713037 0.70873463 0.7049206 -0.27503544 -2.8415916 0.15120901 0.55266213 -0.97635883 1.1382341 0.13891749 -0.6220569 0.48901322 -2.3380036 -0.31055793 3.24562 -4.0859027 -0.579222 1.2372123 2.3155959 0.96481997 -3.6676245 -1.4969295 0.7837823 1.0870318 -0.6050227 0.8325408 1.328006 0.29150656 -2.5328329 -0.52930063 1.1638371 0.5451628 0.2401217 0.17821422 1.1282797 -0.6255923 -1.2899324 0.36619583 -0.46521342 2.7240493 -0.41811445 -1.3177891 0.32050967 -0.27907917 -0.02102979 2.1176116 1.4659307 -0.74454963 -1.3754915 0.26172 0.72916746 -0.78215885 0.9422904 -0.15639538 -1.9578679 -2.2291532 -1.604257 1.1513225 1.4394927 1.3663961 -0.23186158 2.1691236 0.70041925 4.0671997 0.6687622 2.2806919 1.1733083 0.8087675 1.143711 0.15101416 0.67609495 -0.37344953 -0.48123422 0.24116552 0.35969564 1.8687915 1.2080493 1.0876881 -1.8691303 -0.15507829 1.6328797 -2.5513241 -2.0818036 0.8529579 1.790232 0.9209289 2.8360684 0.46996912 -1.2465436 -1.7189977 0.30184388 1.5090418 -1.7590709 -0.6130559 -0.89942425 -0.16365221 -2.7557333 1.2682099 0.72216785 1.4142591 -0.12338407 2.2521818 2.242584 -1.2266986 1.5790528 -0.6049989 -1.2251376 0.04529851 1.2588772 1.4443516 1.9425458 -1.770078 -0.28633627 0.22818221 -1.1054004 0.05947445 0.6791499 0.8320315 0.07090905 -2.4605787 -2.8967953 1.5300242 2.3271239 -1.447048 -1.2444358 -0.82585806 0.20273234 0.6779695 0.03622686 -0.77907175 -1.756927 -0.5452485 1.0174141 2.8124187 -0.6510111 0.88718116 -4.1239104 -0.99753165 0.05194774 0.8445294 -1.0886959 -1.6984457 1.4602119 0.93301445 -1.0705873 0.5754465 -1.5405533 1.9362085 -0.98967594 0.5295451 1.589188 -0.5120375 3.1153758 1.200571 -0.9682008 1.0395331 -0.40270805 0.85788846 -1.1856868 -1.1182163 0.27180263 -2.3870842 0.30561337 -3.086804 0.6730606 -0.55788547 -1.8496476 1.1778438 -3.252681 1.1772966 -4.2397146 0.26227665 -1.1796527 -0.11905587 -1.6812707 -0.80028236 0.21924041 -0.6131642 0.50535196 0.02423297 -0.6145355 -1.2522593 0.19663902 1.4207224 0.18940918 -0.17578137 0.7356166 1.4127327 2.4649005 1.1953328 1.2943949 -0.30904412 -2.6319313 3.3482287 ] Process finished with exit code 0
It can be seen that the results of word vector training are still good. This can be seen as a word 2vec synonym, related words, can also be seen as the use of word 2vec clustering.
Attachment: An online testing website seems to be made by a professor of Tsinghua. http://cikuapi.com/index.php
Here we calculate the similarity between the words "big data" and "artificial intelligence", "drip drops" and "shared sheep cart", and we will report errors:
KeyError: word'Big data'not in vocabulary or KeyError: word'shared bicycle' not in vocabulary
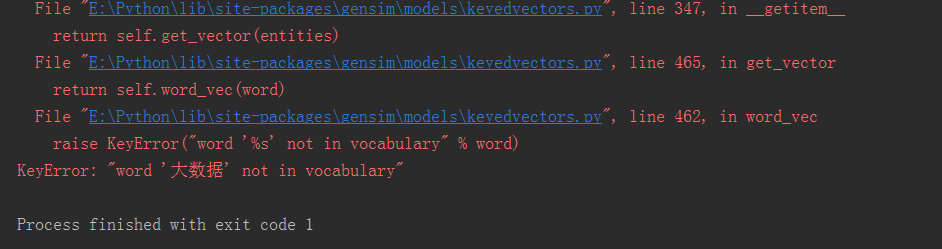
Why? Because the words "big data" and "shared bicycle" are not in the training vectors.
Why not, such a large Wikipedia corpus?
1. It is possible that when we train word vectors, the minimum word frequency of min_count is 5 by default, that is, words with word frequency less than 5 in the segmented corpus will not be trained. Here you can set the word frequency a little bit smaller, for example: min_count=2. The smaller the corpus is, the lower the frequency of words should be set, but the longer the time spent in training, you can set up a try. This is also my above set min_count=5, which takes only 17 minutes to complete the training.
2. Maybe there is no such word in the corpus, so the possibility of such a large corpus is very small, and this is the latest Wikipedia corpus.
3. It is possible that the traditional characters are not converted into simplified ones.
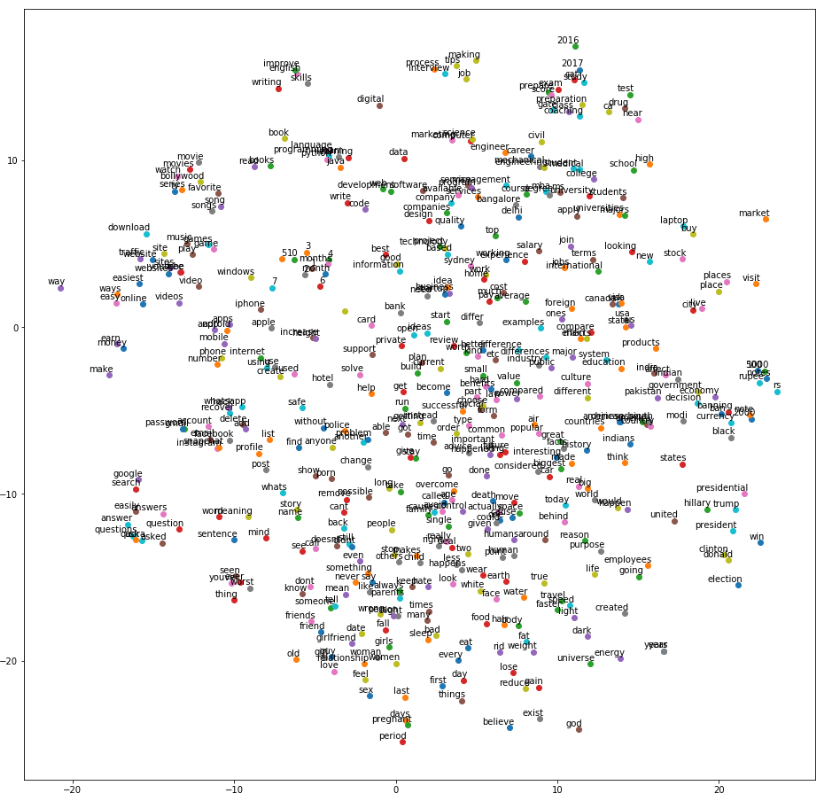
Step-05: Visualization of Word Vectors Using T-SEN given by Kaggle
Visual Reference Links: https://www.kaggle.com/jeffd23/visualizing-word-vectors-with-t-sne
To be written...