Consumer multithreading implementation
KafkaProducer is thread safe, but KafkaConsumer is non thread safe. An acquire() method is defined in KafkaConsumer to detect whether only one thread is currently operating. If other threads are operating, a concurrentmodificationexception will be thrown:
java.util.ConcurrentModificationException: KafkaConsumer is not safe for multi-threaded access.
Each public method in KafkaConsumer will call this acquire () method before executing the action to be executed, with the exception of wakeup() method. Please refer to section 11 for specific usage. The specific definition of acquire() method is as follows:
private final AtomicLong currentThread
= new AtomicLong(NO_CURRENT_THREAD); //Member variables in KafkaConsumer
private void acquire() {
long threadId = Thread.currentThread().getId();
if (threadId != currentThread.get() &&
!currentThread.compareAndSet(NO_CURRENT_THREAD, threadId))
throw new ConcurrentModificationException
("KafkaConsumer is not safe for multi-threaded access");
refcount.incrementAndGet();
}
The acquire() method is different from what we usually call locks (synchronized, Lock, etc.), which will not cause blocking waiting. We can regard it as a lightweight Lock. It only detects whether threads have concurrent operations by means of thread operation count marks, so as to ensure that only one thread is operating. The acquire() method and the release() method appear in pairs, indicating the corresponding locking and unlocking operations. The release() method is also very simple. The specific definitions are as follows:
private void release() {
if (refcount.decrementAndGet() == 0)
currentThread.set(NO_CURRENT_THREAD);
}
Both acquire() method and release() method are private methods, so we don't need to call them explicitly in practical application, but understanding its internal mechanism can promote us to write the corresponding program logic correctly and effectively.
KafkaConsumer's non thread safety does not mean that we can only execute in a single thread when consuming messages. If producers send messages faster than consumers process messages, more and more messages will not be consumed in time, resulting in a certain delay. In addition, due to the role of message retention mechanism in Kafka, some messages may be cleaned up before being consumed, resulting in message loss.
We can realize message consumption through multithreading. The purpose of multithreading is to improve the overall consumption ability. There are many ways to implement multithreading. The first and most common way is thread closure, that is, instantiate a KafkaConsumer object for each thread, as shown in the following figure.
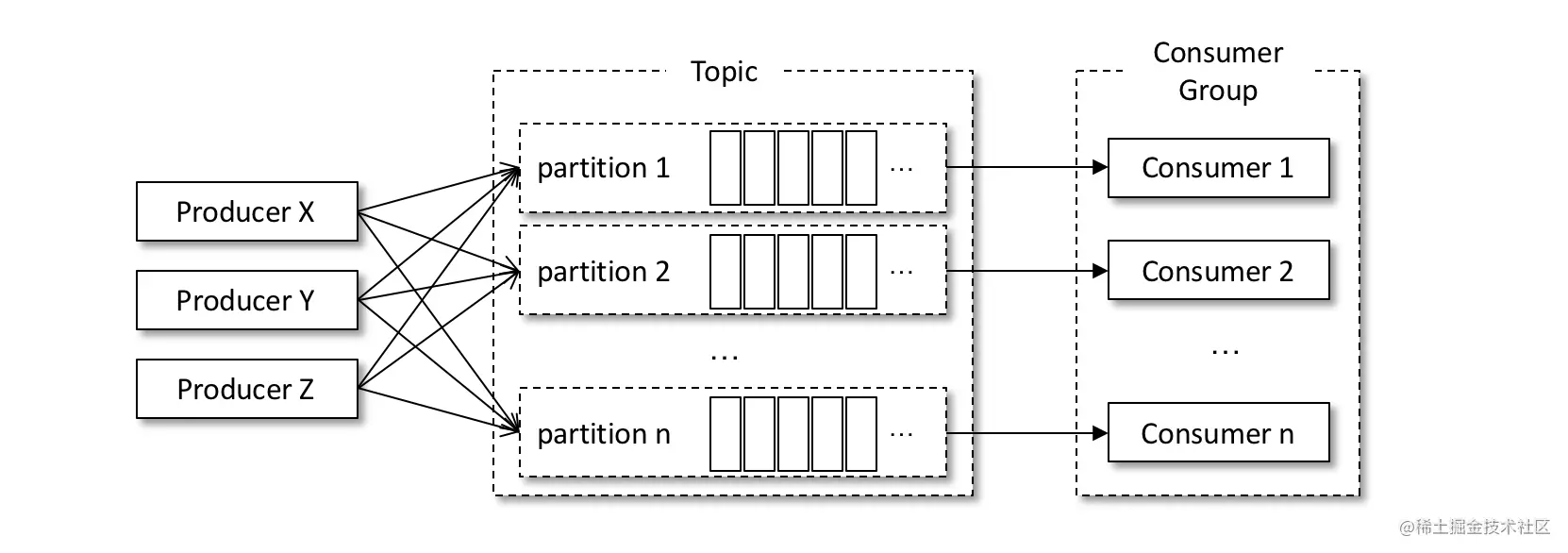
A thread corresponds to a KafkaConsumer instance, which can be called a consumption thread. A consuming thread can consume messages in one or more partitions, and all consuming threads belong to the same consuming group. The concurrency of this implementation is limited by the actual number of partitions. According to the relationship between consumers and partitions introduced in Section 7, when the number of consuming threads is greater than the number of partitions, some consuming threads are always idle.
The corresponding second method is that multiple consumption threads consume the same partition at the same time. This is realized through methods such as assign() and seek(). This can break the limit that the number of consumption threads cannot exceed the number of partitions, and further improve the consumption ability. However, the processing of displacement submission and sequence control will become very complex, which is rarely used in practical application, and the author does not recommend it. Generally speaking, partition is the smallest partition unit of consuming thread. Next, we will demonstrate the first implementation of multi-threaded consumption through actual coding. The detailed example is shown in code listing 14-1.
//Listing 14-1 shows the first implementation of multi-threaded consumption
public class FirstMultiConsumerThreadDemo {
public static final String brokerList = "localhost:9092";
public static final String topic = "topic-demo";
public static final String groupId = "group.demo";
public static Properties initConfig(){
Properties props = new Properties();
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
return props;
}
public static void main(String[] args) {
Properties props = initConfig();
int consumerThreadNum = 4;
for(int i=0;i<consumerThreadNum;i++) {
new KafkaConsumerThread(props,topic).start();
}
}
public static class KafkaConsumerThread extends Thread{
private KafkaConsumer<String, String> kafkaConsumer;
public KafkaConsumerThread(Properties props, String topic) {
this.kafkaConsumer = new KafkaConsumer<>(props);
this.kafkaConsumer.subscribe(Arrays.asList(topic));
}
@Override
public void run(){
try {
while (true) {
ConsumerRecords<String, String> records =
kafkaConsumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
//Message processing module ①
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
kafkaConsumer.close();
}
}
}
}
The internal class KafkaConsumerThread represents a consumption thread, which is wrapped with an independent KafkaConsumer instance. Start multiple consumption threads through the main() method of the external class. The number of consumption threads is specified by the consumerThreadNum variable. Generally, the number of partitions of a topic can be known in advance, and the consumerThreadNum can be set to a value not greater than the number of partitions. If the number of partitions of the topic is not known, it can also be obtained indirectly through the partitionsFor() method of KafkaConsumer class, and then set a reasonable consumerThreadNum value.
There is no essential difference between the above multi-threaded implementation and the way to start multiple consumption processes. Its advantage is that each thread can consume messages in each partition in order. The disadvantages are also obvious. Each consumer thread must maintain an independent TCP connection. If the number of partitions and the value of consumerThreadNum are large, it will cause considerable system overhead.
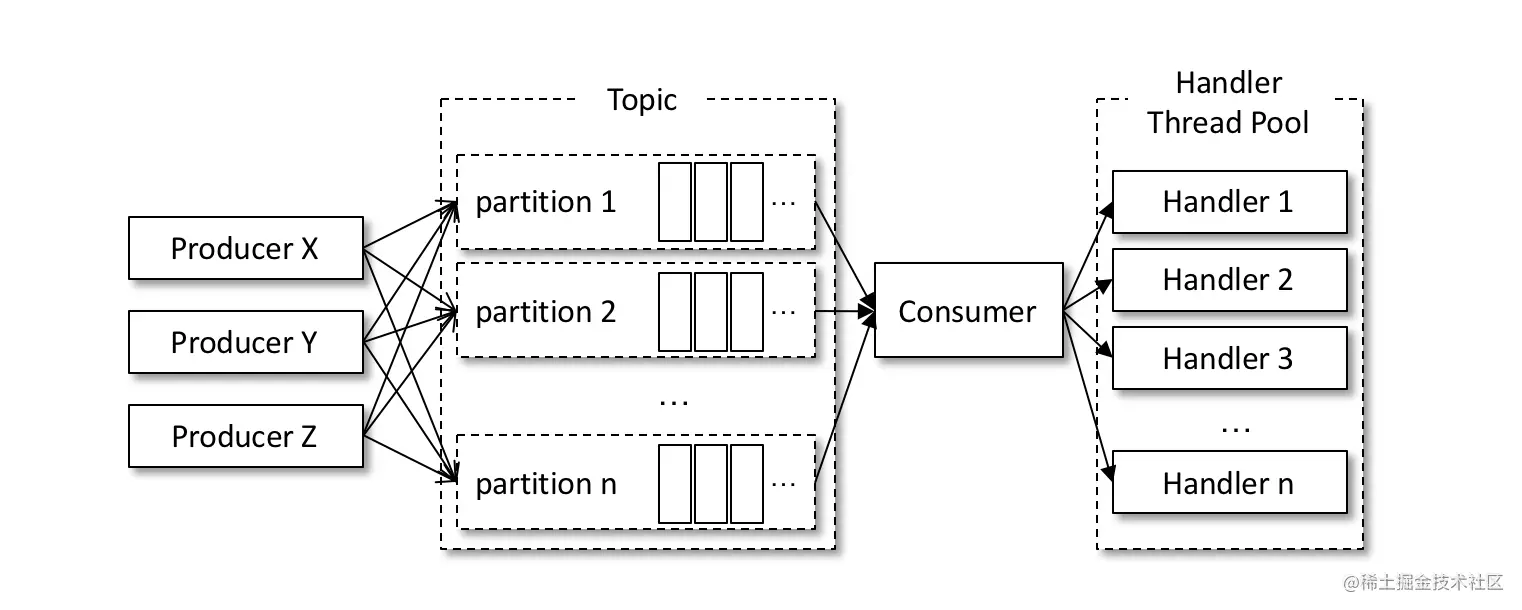
Referring to line ① in code listing 14-1, if the message processing here is very fast, the pull frequency of poll() will be higher, and the overall consumption performance will be improved; On the contrary, if the processing of messages here is slow, such as performing a transactional operation or waiting for a synchronous response from RPC, the pull frequency of poll() will also decrease, resulting in the decline of overall consumption performance. Generally speaking, the pull speed of poll() is quite fast, and the bottleneck of overall consumption is the processing of messages. If we improve this part in a certain way, we can drive the improvement of overall consumption performance.
Referring to the figure above, consider the third implementation method, and change the message processing module to multi-threaded implementation. The specific implementation is shown in code listing 14-2.
//Code listing 14-2 implementation of the third multi-threaded consumption method
public class ThirdMultiConsumerThreadDemo {
public static final String brokerList = "localhost:9092";
public static final String topic = "topic-demo";
public static final String groupId = "group.demo";
//Omit the initConfig() method. Refer to code listing 14-1 for details
public static void main(String[] args) {
Properties props = initConfig();
KafkaConsumerThread consumerThread =
new KafkaConsumerThread(props, topic,
Runtime.getRuntime().availableProcessors());
consumerThread.start();
}
public static class KafkaConsumerThread extends Thread {
private KafkaConsumer<String, String> kafkaConsumer;
private ExecutorService executorService;
private int threadNumber;
public KafkaConsumerThread(Properties props,
String topic, int threadNumber) {
kafkaConsumer = new KafkaConsumer<>(props);
kafkaConsumer.subscribe(Collections.singletonList(topic));
this.threadNumber = threadNumber;
executorService = new ThreadPoolExecutor(threadNumber, threadNumber,
0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(1000),
new ThreadPoolExecutor.CallerRunsPolicy());
}
@Override
public void run() {
try {
while (true) {
ConsumerRecords<String, String> records =
kafkaConsumer.poll(Duration.ofMillis(100));
if (!records.isEmpty()) {
executorService.submit(new RecordsHandler(records));
} ①
}
} catch (Exception e) {
e.printStackTrace();
} finally {
kafkaConsumer.close();
}
}
}
public static class RecordsHandler extends Thread{
public final ConsumerRecords<String, String> records;
public RecordsHandler(ConsumerRecords<String, String> records) {
this.records = records;
}
@Override
public void run(){
//Process records
}
}
}
The RecordHandler class in code listing 14-2 is used to process messages, while the KafkaConsumerThread class corresponds to a consumer thread, which calls the RecordHandler to process batches of messages through the thread pool. Note that the last parameter in the ThreadPoolExecutor in KafkaConsumerThread class is set to CallerRunsPolicy(), which can prevent the overall consumption capacity of the thread pool from falling behind the pull capacity of poll(), resulting in exceptions. The third implementation method can also be expanded horizontally to further improve the overall consumption capacity by opening multiple KafkaConsumerThread instances.
Compared with the first implementation, the third implementation can not only reduce the consumption of system resources by TCP connection, but also reduce the sequence processing of messages. In the initConfig() method in code listing 14-1, the author specially added a configuration:
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
The purpose of this is to explain that the displacement submission is not considered in the specific implementation. For the first implementation, if you want to make a specific displacement submission, its specific implementation is no different from the displacement submission described in section 11. It can be implemented directly in the run() method in KafkaConsumerThread. For the third implementation, a shared variable offsets is introduced to participate in submission, as shown in the following figure.
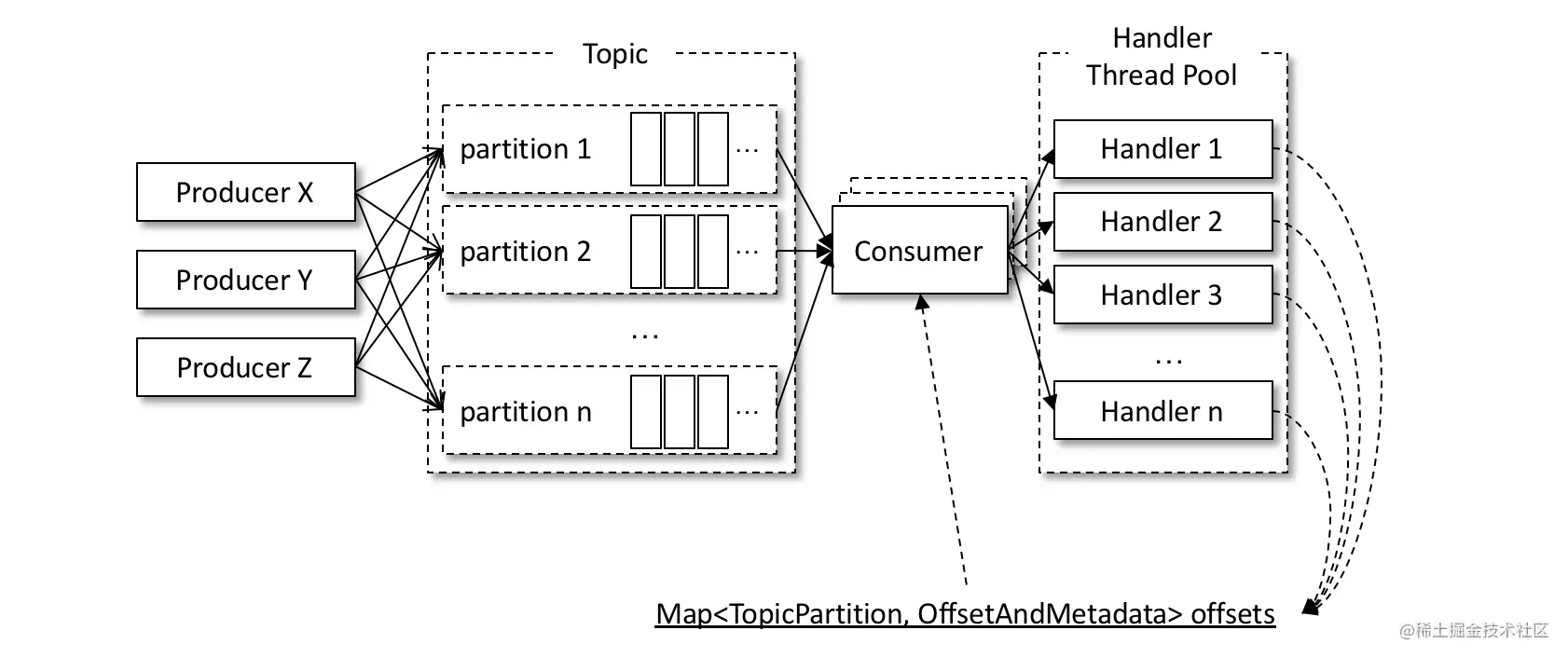
Each RecordHandler class that processes the message saves the corresponding consumption displacement to the shared variable offsets after processing the message. KafkaConsumerThread reads the contents of offsets and submits the displacement after each poll() method. Note that the offsets read / write needs to be locked during implementation to prevent concurrency problems. When writing offsets, you should pay attention to the displacement coverage. To solve this problem, you can change the implementation of the run() method in the RecordHandler class to the following (refer to code listing 11-3):
for (TopicPartition tp : records.partitions()) {
List<ConsumerRecord<String, String>> tpRecords = records.records(tp);
//Process tpRecords
long lastConsumedOffset = tpRecords.get(tpRecords.size() - 1).offset();
synchronized (offsets) {
if (!offsets.containsKey(tp)) {
offsets.put(tp, new OffsetAndMetadata(lastConsumedOffset + 1));
}else {
long position = offsets.get(tp).offset();
if (position < lastConsumedOffset + 1) {
offsets.put(tp, new OffsetAndMetadata(lastConsumedOffset + 1));
}
}
}
}
The corresponding displacement submission implementation can be added under the code in line ① of KafkaConsumerThread class in code listing 14-2. The specific implementation reference is as follows:
synchronized (offsets) {
if (!offsets.isEmpty()) {
kafkaConsumer.commitSync(offsets);
offsets.clear();
}
}
Readers can think about whether this implementation is safe? In fact, this method of displacement submission will have the risk of data loss. For messages in the same partition, suppose that one processing thread RecordHandler1 is processing messages with offset of 0 ~ 99, and the other processing thread RecordHandler2 has processed messages with offset of 100 ~ 199 and submitted displacement. At this time, if RecordHandler1 is abnormal, subsequent consumption can only start from 200 and cannot consume messages with offset of 0 ~ 99 again, This leads to the loss of messages. Although some processing has been done for displacement coverage, the problem of displacement coverage under abnormal conditions has not been solved.
For this, we need to introduce a more complex processing mechanism. Here is another solution. Refer to the figure below. The overall structure is based on sliding window. For the third implementation method, the structure it presents is to pull batches of messages through consumers and submit them to multiple threads for processing. The sliding window implementation method here is to temporarily store the pulled messages. Multiple consumer threads can pull the temporarily stored messages. The cache size used to temporarily store messages is the size of the sliding window, Generally speaking, there are not many changes. The difference is the control of consumption displacement.
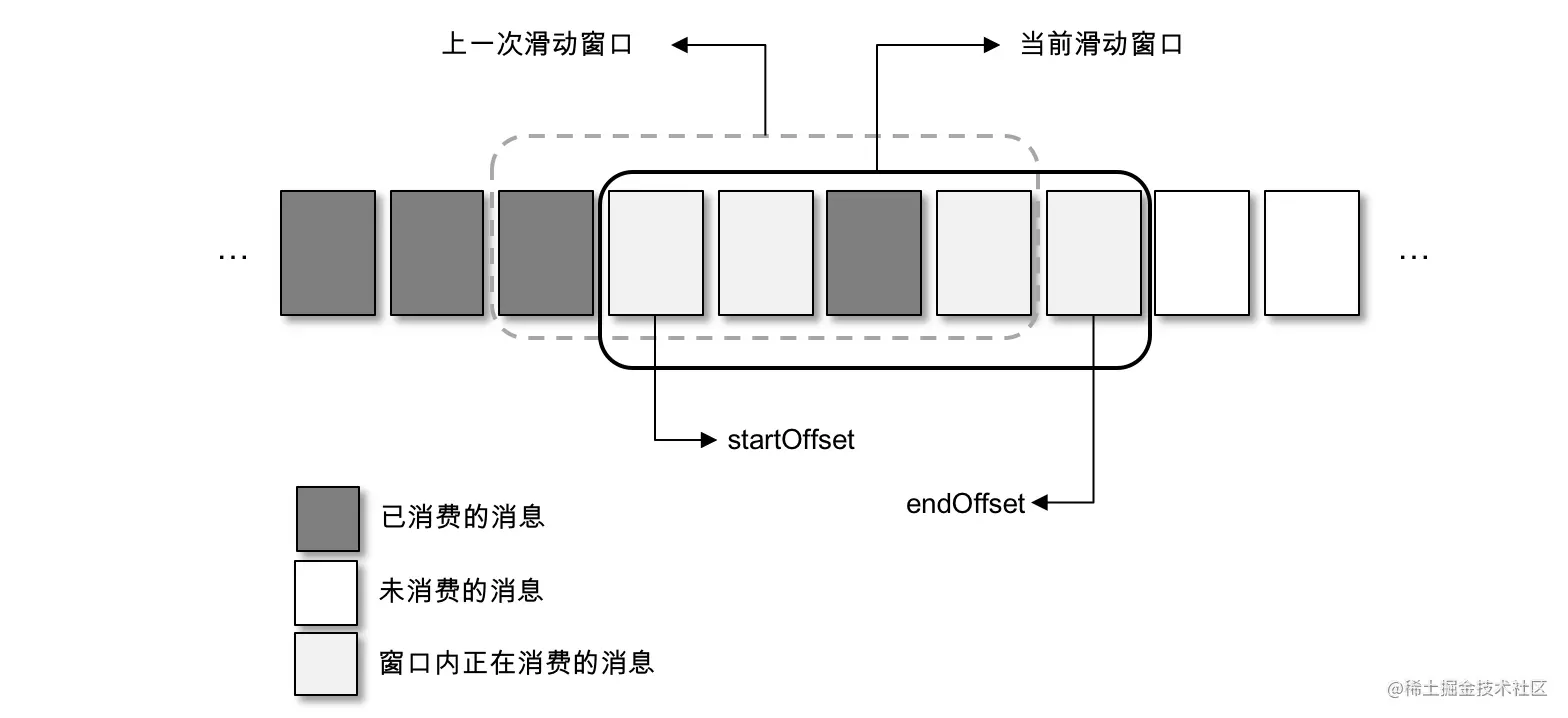
As shown in the above figure, each square represents a batch of messages. A sliding window contains several squares. startOffset indicates the start position of the current sliding window and endOffset indicates the end position. Whenever the message in the grid pointed to by startOffset is consumed, this part of the displacement can be submitted. At the same time, the window slides forward one grid, deletes the corresponding message in the grid pointed to by the original startOffset, and pulls a new message into the window. When the size of the sliding window is fixed, the corresponding cache size for temporarily storing messages is fixed, and the memory overhead is controllable.
The size of the grid and the size of the sliding window determine the concurrent number of consumption threads at the same time: a grid corresponds to a consumption thread. For a fixed window size, the smaller the grid, the higher the parallelism; When the grid size is fixed, the larger the window, the higher the parallelism. However, if the window is set too large, it will not only increase the memory overhead, but also cause a lot of repeated consumption in the case of exceptions (such as Crash). At the same time, considering the overhead of thread switching, it is recommended to set a reasonable value according to the actual situation. It is not appropriate to be too large or too small for either the grid or the window.
If the message in a box cannot be marked as consumption completed, it will cause the hover of startOffset. In order to enable the window to continue sliding forward, you need to set a threshold. When startOffset hovers for a certain time, you can retry and consume these messages locally. If the retry fails, you will be transferred to the retry queue. If it doesn't work, you will be transferred to the dead letter queue. In real applications, there are very few cases that cannot be consumed, which are generally caused by the processing logic of the business code. For example, the content format in the message is inconsistent with the content format of the business processing, so it is impossible to make a decision on the message. This situation can be avoided by optimizing the code logic or adopting a discard strategy. If the message needs to be highly reliable, you can also store the message that cannot carry out business logic (this kind of message can be called dead letter) in disk, database or Kafka, and then continue to consume the next message to ensure the reasonable progress of the overall consumption progress. Then you can analyze the dead letter through an additional processing task to find out the cause of the exception.