CBAM: Convolutional Block Attention Module
Channel attention module
For input characteristic diagram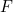 , obtained by avarage pooling and Max pooling, respectively
, obtained by avarage pooling and Max pooling, respectively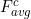 and
and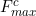 ; Then connect to the same network, which is an MLP with a hidden layer, that is, two full connection layers. In order to reduce additional parameter overhead, the size of the hidden layer is set to
; Then connect to the same network, which is an MLP with a hidden layer, that is, two full connection layers. In order to reduce additional parameter overhead, the size of the hidden layer is set to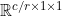 , r is the reduction ratio, and the second FC is restored; Then, the fusion is carried out by means of element wise summary; Finally, a sigmoid activation function is added to get the result of the channel branch
, r is the reduction ratio, and the second FC is restored; Then, the fusion is carried out by means of element wise summary; Finally, a sigmoid activation function is added to get the result of the channel branch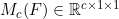 . The specific calculation method is as follows:
. The specific calculation method is as follows:
among Represents the sigmoid function. Note the of the two sub branches
Represents the sigmoid function. Note the of the two sub branches and
and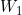 Same, andFollowed by the activation function ReLU.
Same, andFollowed by the activation function ReLU.
Spatial attention module
For input characteristic diagram, obtained by using average pooling and Max pooling along the channel direction respectively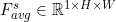 and
and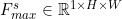 ; Then concatenate along the channel direction; Then a 7 × Convolution of 7; Finally, a sigmoid function is followed to get the result of the spatial branch
; Then concatenate along the channel direction; Then a 7 × Convolution of 7; Finally, a sigmoid function is followed to get the result of the spatial branch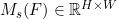 . The specific calculation method is as follows:
. The specific calculation method is as follows:
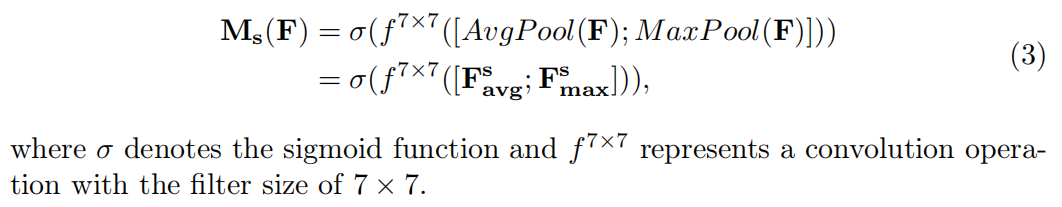
Arrangement of attention modules
Through experiments, the author determined that the effect of the two attention modules in sequential mode is better than that in parallel mode, and the effect of placing the channel attention module in front of the spatial attention module is better. Therefore, the final structure is as follows:
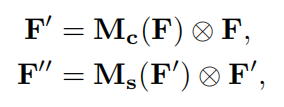
Ablation studies
Channel attention
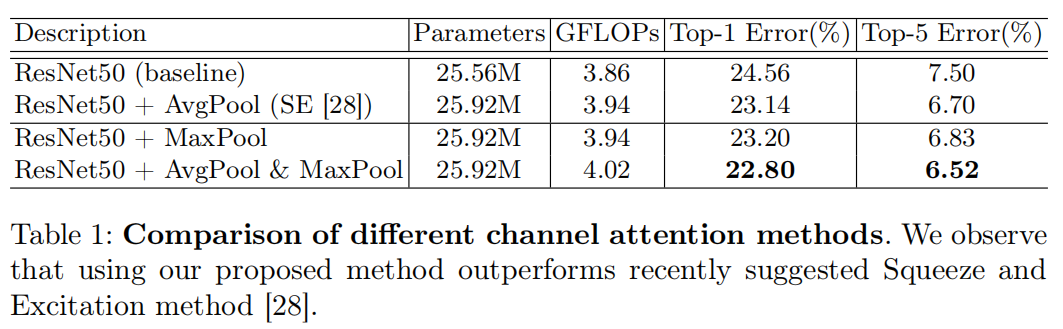
The experiment compares the differences of channel attention using AvgPool, MaxPool, AvgPool & MaxPool, and the results show that the combination of the two has the best effect. "We argue that max-pooled features which encode the degree of the most salient part can compensate the average-pooled features which encode global statistics softly."
Spatial attention
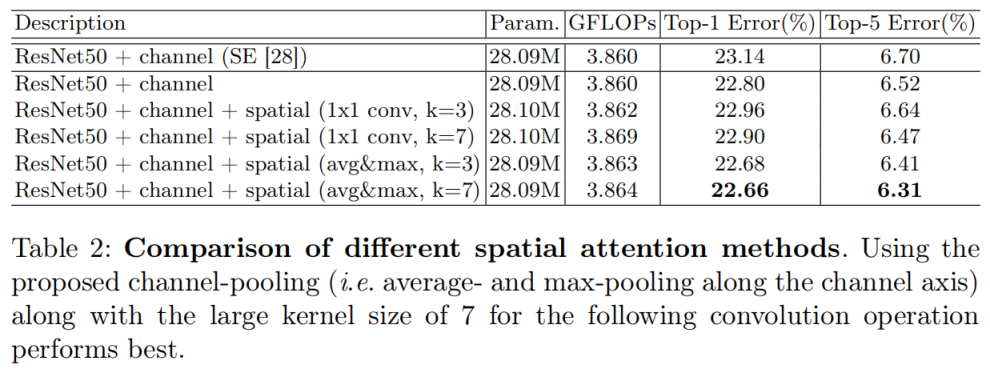
The authors did two ablation experiments on spatial attention, one is the way to compress the channel, and the other is the kernel size of the posterior convolution layer. The experimental results show that in the compression channel mode, the channel pooling proposed by the author, that is, AVG pooling and Max pooling along the channel respectively, and then concatenate, is better than 1 × 1. Convolution learning weight has a good effect on dimension reduction along the channel; In terms of convolution kernel size, kernel_size=7 than kernel_ It implies that a broad view (i.e. large receptive Fifield) is needed for determining spatially important regions
Arrangement of the channel and spatial attention
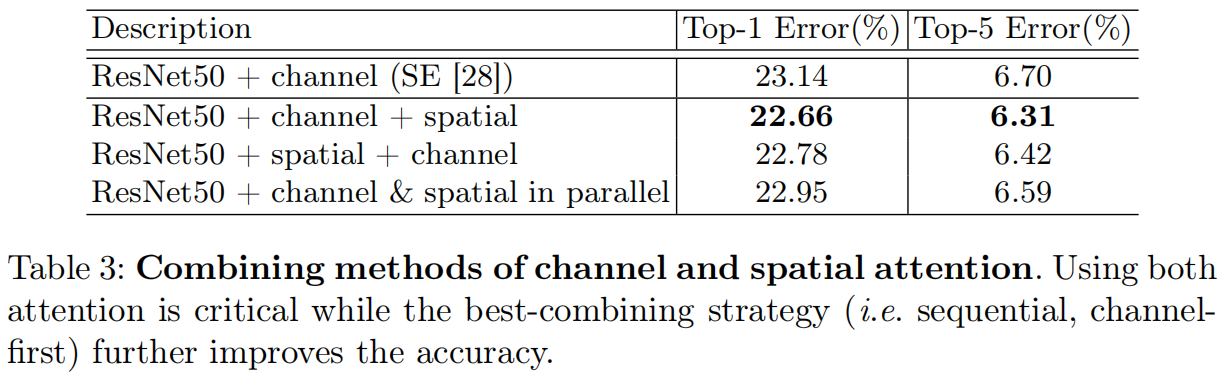
In this part, the author compares three different channel and spatial branch fusion methods, sequential channel spatial, sequential spatial channel and parallel. The experimental results show that sequential channel spatial has the best effect.
Official code
import torch
import math
import torch.nn as nn
import torch.nn.functional as F
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True,
bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding,
dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes, eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn:
x = self.bn(x)
if self.relu:
x = self.relu(x)
return x
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.size(0), -1)
class ChannelGate(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max']):
super(ChannelGate, self).__init__()
self.gate_channels = gate_channels
self.mlp = nn.Sequential(
Flatten(),
nn.Linear(gate_channels, gate_channels // reduction_ratio),
nn.ReLU(),
nn.Linear(gate_channels // reduction_ratio, gate_channels)
)
self.pool_types = pool_types
def forward(self, x):
channel_att_sum = None
for pool_type in self.pool_types:
if pool_type == 'avg':
avg_pool = F.avg_pool2d(x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp(avg_pool)
elif pool_type == 'max':
max_pool = F.max_pool2d(x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp(max_pool)
if channel_att_sum is None:
channel_att_sum = channel_att_raw
else:
channel_att_sum = channel_att_sum + channel_att_raw
scale = F.sigmoid(channel_att_sum).unsqueeze(2).unsqueeze(3).expand_as(x)
return x * scale
class ChannelPool(nn.Module):
def forward(self, x):
return torch.cat((torch.max(x, 1)[0].unsqueeze(1), torch.mean(x, 1).unsqueeze(1)), dim=1)
class SpatialGate(nn.Module):
def __init__(self):
super(SpatialGate, self).__init__()
kernel_size = 7
self.compress = ChannelPool()
self.spatial = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size - 1) // 2, relu=False)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.spatial(x_compress)
scale = F.sigmoid(x_out) # broadcasting
return x * scale
class CBAM(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max'], no_spatial=False):
super(CBAM, self).__init__()
self.ChannelGate = ChannelGate(gate_channels, reduction_ratio, pool_types)
self.no_spatial = no_spatial
if not no_spatial:
self.SpatialGate = SpatialGate()
def forward(self, x):
x_out = self.ChannelGate(x)
if not self.no_spatial:
x_out = self.SpatialGate(x_out)
return x_out
Difference between and BAM
- The channel and spatial modes of BAM are parallel mode, and CBAM is sequence mode
- In channel attention, BAM only uses avg pool, while CBAM uses avg pool and max pool