Role of a copy
1.Kafka replica function: improve data reliability.
2. The copy in Kafka is divided into Leader and Follower. Kafka producers will only send data to leaders, and then Follower will find leaders to synchronize data.
The reading and writing is completed by the leader. The follower only backs up and synchronizes data with the leader. If the leader fails, the follower goes up.
leader replica: it can be understood as a partition, except for the partition that is not a replica.
3. All replicas in the Kafka partition are collectively referred to as AR (assigned replicas).
AR = ISR + OSR
4.ISR: refers to the Follower set that keeps synchronization with the Leader. If a Follower fails to send a communication request or synchronize data to the Leader for a long time, the Follower will be kicked out of the ISR. This time threshold is determined by replica lag. time. Max.ms parameter setting, 30s by default. After the Leader fails, a new Leader will be elected from ISR.
5.OSR: indicates the replica set that timed out when the Follower and Leader replicas are synchronized.
II. Role of replica and partition
2.1 case description
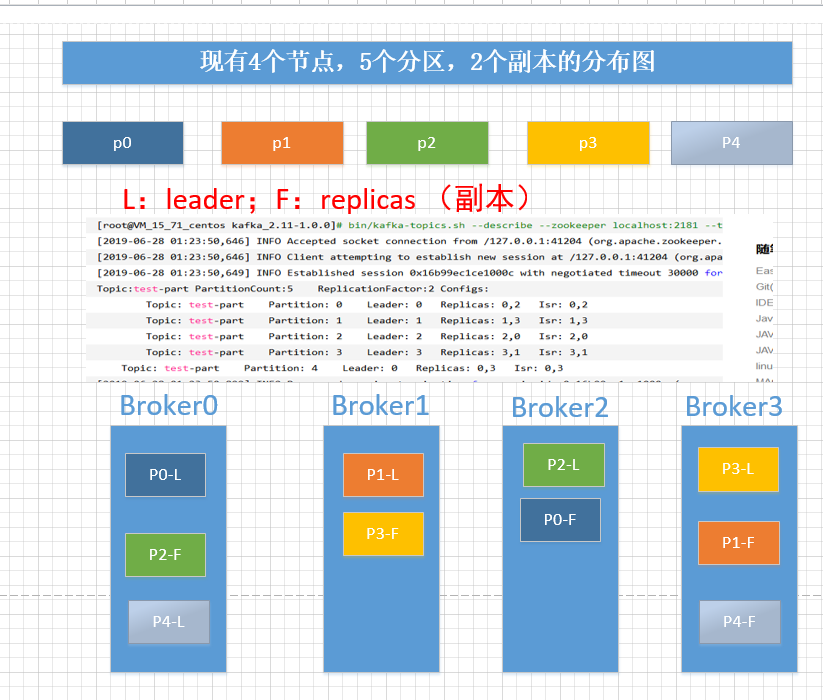
Assuming 4 nodes, 5 partitions and 2 replicas are created, the relationship between partitions and replicas is shown in the following figure:
root@VM_15_71_centos kafka_2.11-1.0.0]# bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test-part
[2019-06-28 01:23:50,646] INFO Accepted socket connection from /127.0.0.1:41204 (org.apache.zookeeper.server.NIOServerCnxnFactory)
[2019-06-28 01:23:50,646] INFO Client attempting to establish new session at /127.0.0.1:41204 (org.apache.zookeeper.server.ZooKeeperServer)
[2019-06-28 01:23:50,649] INFO Established session 0x16b99ec1ce1000c with negotiated timeout 30000 for client /127.0.0.1:41204 (org.apache.zookeeper.server.ZooKeeperServer)
Topic:test-part PartitionCount:5 ReplicationFactor:2 Configs:
Topic: test-part Partition: 0 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: test-part Partition: 1 Leader: 1 Replicas: 1,3 Isr: 1,3
Topic: test-part Partition: 2 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: test-part Partition: 3 Leader: 3 Replicas: 3,1 Isr: 3,1
Topic: test-part Partition: 4 Leader: 0 Replicas: 0,3 Isr: 0,3
[2019-06-28 01:23:50,899] INFO Processed session termination for sessionid: 0x16b99ec1ce1000c (org.apache.zookeeper.server.PrepRequestProcessor)
[2019-06-28 01:23:50,904] INFO Closed socket connection for client /127.0.0.1:41204 which had sessionid 0x16b99ec1ce1000c (org.apache.zookeeper.server.NIOServerCnxn)Sort out the storage distribution diagram:
Three kafka partition leader replica election
3.1 leader election thought
According to: on the premise of surviving in isr, according to the priority in AR, such as

2. Check the distribution of leaders
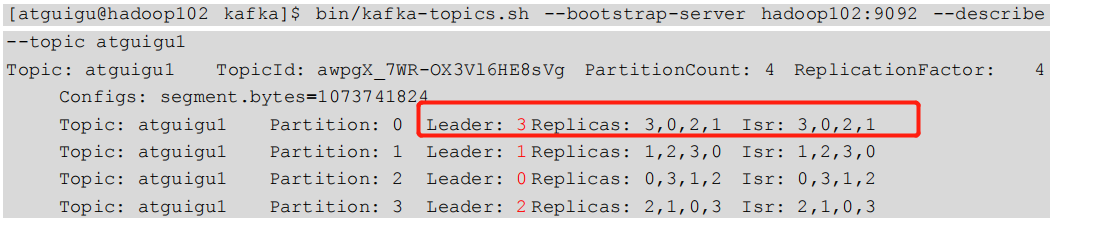 3. Stop the kafka process of Hadoop 105 and check the Leader partition
3. Stop the kafka process of Hadoop 105 and check the Leader partition


IV. troubleshooting of leader s and follower s
4.1 failure of follower
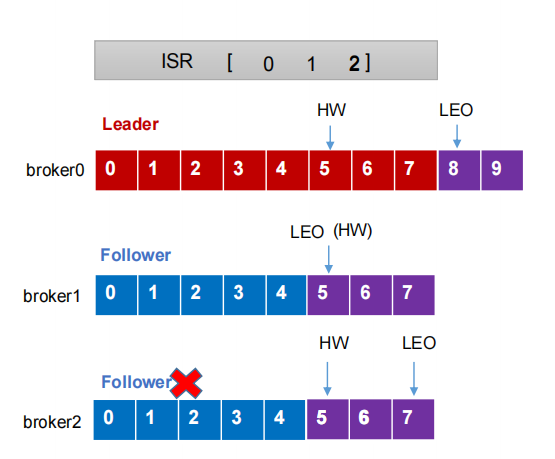
1.LEO and HW
2. Process
1.Follower will be temporarily kicked out of ISR after failure
2. During this period, the Leader and follower continue to receive data (no matter whether the follower can still receive it or not, they are still communicating and synchronizing data)
3. After the Follower is restored, the Follower will read the last HW recorded on the local disk, intercept the part of the log file higher than HW, and synchronize with the Leader from HW.
4. When the LEO of the Follower is greater than or equal to the HW of the Partition, that is, the Follower can rejoin the ISR after catching up with the Leader.
2.4 the leader fails
1.LEO and HW
2. Process

V. manually debug partition copy storage
5.1 requirements description
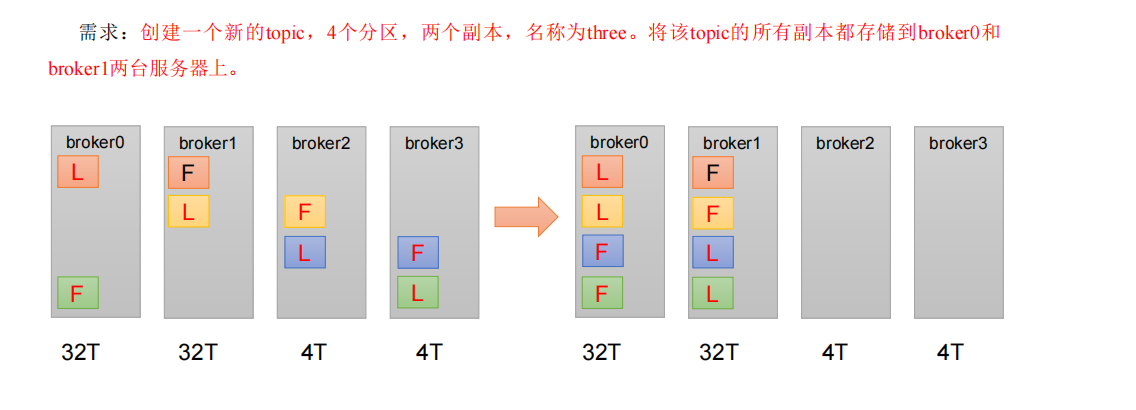
5.2} operation steps

2. Check the storage of partition replica.

3. Create a replica storage plan (all replicas are specified to be stored in broker0 and broker1).

4. Execute a replica storage plan.

5. Verify the replica storage plan.
 6. View partition replica storage
6. View partition replica storage

Vi. production experience - Leader Partition load balancing (understanding)