import numpy as np import matplotlib.pyplot as plt import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torch.utils.data import Dataset,DataLoader import h5py import glob import os import json from tqdm import tqdm import sys import open3d as o3d
Written in the front, the directory structure of my pointnet code

Introduction to ShapeNet dataset
- First download the shapenet dataset: https://shapenet.cs.stanford.edu/ericyi/shapenetcore_partanno_segmentation_benchmark_v0.zip
- After downloading, synsetoffset2category Txt file, indicating which folder each point cloud class is in
- The point cloud data is in txt file, some contents are as follows:

- shapenet has 16 categories, and each category has some subclasses. There are 16 major categories and 50 sub categories.
'Earphone': [16, 17, 18], 'Motorbike': [30, 31, 32, 33, 34, 35], 'Rocket': [41, 42, 43], 'Car': [8, 9, 10, 11], 'Laptop': [28, 29], 'Cap': [6, 7], 'Skateboard': [44, 45, 46], 'Mug': [36, 37], 'Guitar': [19, 20, 21], 'Bag': [4, 5], 'Lamp': [24, 25, 26, 27], 'Table': [47, 48, 49], 'Airplane': [0, 1, 2, 3], 'Pistol': [38, 39, 40], 'Chair': [12, 13, 14, 15], 'Knife': [22, 23]
Define ShapeNet_DataSet
class ShapeNetDataSet(Dataset):
def __init__(self, root="./data/ShapeNet", npoints=2500, split="train", class_choice=None, normal_use=False):
'''
root: str type, dataset root directory. default: "./data/ShapeNet"
npoint: int type, sampling number of point. default: 2500
split: str type, segmentation of dataset. eg.(train, val, test). default: "train"
class_choice: list type, select to keep class. default: None
normal_use: boolean type, normal(normal) information whether to use. default: False
'''
self.root = root # Dataset path
self.npoints = npoints # Sampling points
self.normal_use = normal_use # Whether to use normal information
self.category = {} # Folder corresponding to category
# shapenet has 16 categories, and each category has some components,
# For example, the aircraft 'Airplane': [0, 1, 2, 3] in which the four sub categories labeled 0, 1, 2, 3 belong to the category of aircraft
self.seg_classes = {'Earphone': [16, 17, 18], 'Motorbike': [30, 31, 32, 33, 34, 35], 'Rocket': [41, 42, 43],
'Car': [8, 9, 10, 11], 'Laptop': [28, 29], 'Cap': [6, 7], 'Skateboard': [44, 45, 46],
'Mug': [36, 37], 'Guitar': [19, 20, 21], 'Bag': [4, 5], 'Lamp': [24, 25, 26, 27],
'Table': [47, 48, 49], 'Airplane': [0, 1, 2, 3], 'Pistol': [38, 39, 40],
'Chair': [12, 13, 14, 15], 'Knife': [22, 23]}
# Read the folder information corresponding to the category, that is, the file synsetoffset2category txt
with open(self.root+"/synsetoffset2category.txt") as f:
for line in f.readlines():
cate,file = line.strip().split()
self.category[cate] = file
# print(self.category) # {'Airplane': '02691156', 'Bag': '02773838', 'Cap': '02954340', 'Car': '02958343', 'Chair': '03001627', 'Earphone': '03261776', 'Guitar': '03467517', 'Knife': '03624134', 'Lamp': '03636649', 'Laptop': '03642806', 'Motorbike': '03790512', 'Mug': '03797390', 'Pistol': '03948459', 'Rocket': '04099429', 'Skateboard': '04225987', 'Table': '04379243'}
# Corresponding a category string to a number
self.category2id = {}
i = 0
for item in self.category:
self.category2id[item] = i
i = i + 1
# class_ Select category
if class_choice: # class_choice is a list type
for item in self.category:
if item not in class_choice: # If the category is not in class_ In choice, delete
self.category.pop(item)
# Store the point cloud data file corresponding to the category
self.datapath = [] # Storage form: [(category, data path), (category, data path),...]
# Traverse the point cloud file for storage
for item in self.category:
filesName = [f[:-4] for f in os.listdir(self.root+"/"+self.category[item])] # Traverse all the files under the category folder, and then judge them (belonging to training set, verification set, test set,)
# Capture some data (training set, verification set, test set)
if split=="train":
with open(self.root+"/"+"train_test_split"+"/"+"shuffled_train_file_list.json") as f:
filename = [f.split("/")[-1] for f in json.load(f)]
for file in filesName:
if file in filename: # If the data in this category is stored in the training set
self.datapath.append((item, self.root+"/"+self.category[item]+"/"+file+".txt"))
elif split=="val":
with open(self.root+"/"+"train_test_split"+"/"+"shuffled_val_file_list.json") as f:
filename = [f.split("/")[-1] for f in json.load(f)]
for file in filesName:
if file in filename: # If the data in the category folder is in the validation set, it is stored
self.datapath.append((item, self.root+"/"+self.category[item]+"/"+file+".txt"))
elif split=="test":
with open(self.root+"/"+"train_test_split"+"/"+"shuffled_test_file_list.json") as f:
filename = [f.split("/")[-1] for f in json.load(f)]
for file in filesName:
if file in filename: # If the data in the category folder is in the test set, it is stored
self.datapath.append((item, self.root+"/"+self.category[item]+"/"+file+".txt"))
def __getitem__(self, index):
'''
:return: Point cloud data, Large category, Semantics of each point (small category in large category)
'''
cls = self.datapath[index][0] # Category string
cls_index = self.category2id[cls] # Class is the number corresponding to the string
path = self.datapath[index][1] # Path of point cloud data storage
data = np.loadtxt(path) # Point cloud data
point_data = None
if self.normal_use: # Whether to use normal information
point_data = data[:, 0:-1]
else:
point_data = data[:, 0:3]
seg = data[:, -1] # semantic information
# Resampling data
choice = np.random.choice(len(seg), self.npoints)
point_data = point_data[choice, :]
seg = seg[choice]
return point_data, cls_index, seg
def __len__(self):
return len(self.datapath)
- Test whether the ShapeNetDataSet class is successfully defined
dataset = ShapeNetDataSet(normal_use=True) dataset
Output:
<__main__.ShapeNetDataSet at 0x1449258b5e0>
dataset[1]
Output:
(array([[ 0.04032, -0.04601, -0.2194 , 0.8508 , 0.5099 , 0.1266 ],
[ 0.28303, -0.01156, 0.01564, 0.1708 , 0.8002 , 0.5749 ],
[ 0.28908, -0.02916, 0.0262 , 0.04791, 0.09224, 0.9946 ],
...,
[ 0.12313, -0.06889, -0.12327, 0.6052 , -0.3931 , -0.6923 ],
[-0.17983, -0.04519, -0.02602, -0.07472, -0.4551 , -0.8873 ],
[ 0.03092, -0.05983, 0.05344, 0.7298 , -0.669 , -0.1407 ]]),
0,
array([3., 0., 0., ..., 3., 0., 1.]))
Introduction to S3DIS dataset
-
S3DIS dataset Download:
- txt format: https://docs.google.com/forms/d/e/1FAIpQLScDimvNMCGhy_rmBA2gHfDu3naktRm6A8BPwAWWDv-Uhm6Shw/viewform?c=0&w=1
- (recommended, super fast loading speed) hdf5 format: https://shapenet.cs.stanford.edu/media/indoor3d_sem_seg_hdf5_data.zip
-
txt format file introduction:
- After downloading, there are 6 folders (Area_1,..., Area_6)
- The introduction is as follows:
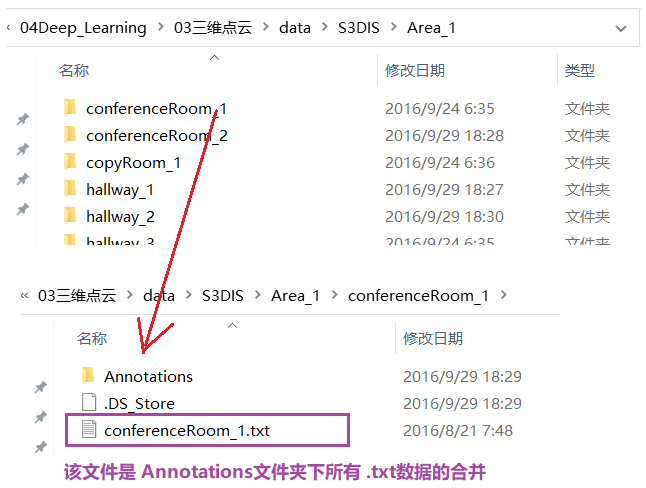
-
There are several problems in the dataset:
- Stanford3dDataset_ v1. Version 2, Area_5\office_19\Annotations\ceiling_1.txt line 323474
- Stanford3dDataset_v1.2_Aligned_Version, Area_5\hallway_6\Annotations\ceiling_1.txt line 180389
-
Introduction to hdf5 format file:
- There are 0-23 numbers h5 files (24 files in total)

- There are 0-23 numbers h5 files (24 files in total)
-
One h5 file has data key and label key
- 0-22 Document No.: data shape = (1000, 4096, 9),label.shape = (1000, 4096)
- 23 Document No.: data shape = (585, 4096, 9),label.shape = (585, 4096)
- The last dimension of data is 9, which means: XYZRGBX 'Y' Z '(X': normalized coordinates of points in the room)
- Add up to 23585 rows of data, which exactly corresponds to room_ filelist. Number of lines in TXT file
- Then, data[i,:,:] corresponds to room_filelist.txt, that is: (drawing display)
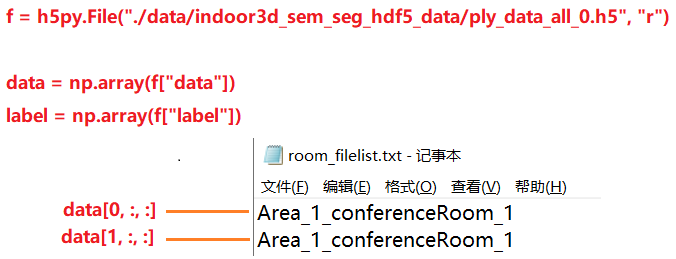
be careful
- During training, use S3DISDataSetTxt or S3DISDataSetH5 class to declare train_dataset, because during training, some scenes in a room are used for training.
- When testing, use the S3DISWholeSceneDataSet class to declare test_dataset, because when testing, a room is used for testing, and the scene is no longer divided.
DATA_PATH = './Pointnet_Pointnet2_pytorch-master/data/s3dis/Stanford3dDataset_v1.2_Aligned_Version' # Directory of dataset BASE_DIR = "./Pointnet_Pointnet2_pytorch-master/data_utils" ROOT_DIR = os.path.dirname(BASE_DIR) # "./Pointnet_Pointnet2_pytorch-master"
classes = [i.strip() for i in open(BASE_DIR+"/meta/class_names.txt")] # ['ceiling', 'floor', 'wall', 'beam', 'column', 'window', 'door', 'table', 'chair', 'sofa', 'bookcase', 'board', 'clutter']
classes2label = {classes[i]:i for i in range(len(classes))} # {'ceiling': 0, 'floor': 1, 'wall': 2, 'beam': 3, 'column': 4, 'window': 5, 'door': 6, 'table': 7, 'chair': 8, 'sofa': 9, 'bookcase': 10, 'board': 11, 'clutter': 12}
classes2color = {'ceiling':[0,255,0],'floor':[0,0,255],'wall':[0,255,255],'beam':[255,255,0],
'column':[255,0,255],'window':[100,100,255],'door':[200,200,100],'table':[170,120,200],
'chair':[255,0,0],'sofa':[200,100,100],'bookcase':[10,200,100],'board':[200,200,200],'clutter':[50,50,50]}
easy_view_labels = [7,8,9,10,11,1] # Categories that are easy to observe when visualizing point clouds
label2color = { classes2label[cls]:classes2color[cls] for cls in classes } # {0: [0, 255, 0],1: [0, 0, 255],2: [0, 255, 255],3: [255, 255, 0]4: [255, 0, 255],5: [100, 100, 255],6: [200, 200, 100],7: [170, 120, 200],8: [255, 0, 0],9: [200, 100, 100],10: [10, 200, 100],11: [200, 200, 200],12: [50, 50, 50]}
txt format
- Before defining the DataSet, it is necessary to label the S3DIS data, because when downloading the original data, there is only XYZRGB value and no label value
# label the original data
def collect_point_label(anno_path, out_filename, file_format=".txt"):
'''
Convert the original data set to data_label File (per line): XYZRGBL,L: label)
anno_path: annotations The path of the. For example: Area_1/office_2/Annotations/
out_filename: Save file( data_label)Path of
file_format: There are only two formats for saving files:.txt or .npy
return: None
github The comments in the source code are as follows:
Note: the points are shifted before save, the most negative point is now at origin.
Note: these points were moved before saving, and now the most negative point is at the origin.
'''
points_list = []
anno_files = [anno_path+"/"+i for i in os.listdir(anno_path) if i.endswith(".txt")] # Put the Annotations folder in order to txt file
for file in anno_files:
# print(file) # ./Pointnet_Pointnet2_pytorch-master/data/s3dis/Stanford3dDataset_v1.2_Aligned_Version/Area_1/conferenceRoom_1/Annotations/beam_1.txt
cls = os.path.basename(file).split("_")[0] # beam
if cls == "stairs": # Under some annotations folders, there are stars categories, such as Area_1/hallway_8/Annotations
cls = "clutter"
points = np.loadtxt(file, encoding="utf8") # Load point cloud data (XYZRGB)
labels = np.ones([points.shape[0], 1])*classes2label[cls] # L: label
points_list.append(np.concatenate([points, labels], 1)) # np.concatenate((a1, a2, ...), axis). Axis: 0 connects lines A1 and A2; 1 connect A1 and A2 columns
data_label = np.concatenate(points_list, 0) # Set points_ All the data in the list are row connected
xyz_min = np.min(data_label[:,0:3], axis=0) # Why do things turn out like this? In the definition of this method, there is an explanation
data_label[:, 0:3] = data_label[:, 0:3] - xyz_min
# Save data_label (PS: I personally prefer to save in. txt format, because. npy format has not been used)
if file_format==".txt":
with open(out_filename, "w") as f:
for i in data_label: # Traversal data_label each line
f.write("%f %f %f %d %d %d %d\n" % (i[0], i[1], i[2], i[3], i[4], i[5], i[6]))
elif file_format==".npy":
np.save(out_filename, data_label)
else:
print('ERROR!! Unknown file format: %s, please use .txt or .npy.' % (file_format) )
exit()
# Traversing the point cloud data in the Annotations folder (txt format), and then calling collect_point_label() method
anno_paths = []
with open(BASE_DIR+"/meta/anno_paths.txt") as f:
lines = f.readlines()
for line in lines:
l = line.strip()
anno_paths.append(l) # ['Area_1/conferenceRoom_1/Annotations']
anno_paths = [os.path.join(DATA_PATH, p) for p in anno_paths] # ['./Pointnet_Pointnet2_pytorch-master/data/s3dis/Stanford3dDataset_v1.2_Aligned_Version\\Area_1/conferenceRoom_1/Annotations']
output_folder = os.path.join(ROOT_DIR, 'data/s3dis/alter_s3dis_my') # The folder where the original data is saved after modification/ Pointnet_Pointnet2_pytorch-master\data/s3dis/alter_s3dis_my'
if not os.path.exists(output_folder): # If not/ Pointnet_Pointnet2_pytorch-master\data/stanford_indoor3d 'folder, create
os.mkdir(output_folder)
for anno_path in anno_paths:
'''
windows Next, need .replace("\\", "/"),Otherwise use anno_path.split("/") After, it will produce ['.', 'Pointnet_Pointnet2_pytorch-master', 'data', 's3dis', 'Stanford3dDataset_v1.2_Aligned_Version\\Area_1', 'conferenceRoom_1', 'Annotations']
'''
anno_path = anno_path.replace("\\", "/")
print(anno_path) # ./Pointnet_Pointnet2_pytorch-master/data/s3dis/Stanford3dDataset_v1.2_Aligned_Version/Area_1/conferenceRoom_1/Annotations
elements = anno_path.split("/") # ['.', 'Pointnet_Pointnet2_pytorch-master', 'data', 's3dis', 'Stanford3dDataset_v1.2_Aligned_Version', 'Area_1', 'conferenceRoom_1', 'Annotations']
out_filename = elements[-3]+"_"+elements[-2]+".txt" # Saved file, Area_1_hallway_1.txt
out_filename = output_folder + "/" + out_filename # Save the full path of the file/ Pointnet_Pointnet2_pytorch-master\data/s3dis/alter_s3dis_my/Area_1_hallway_1.txt
collect_point_label(anno_path, out_filename, ".txt")
- DataSet: read txt format
# txt form
class S3DISDataSetTxt(Dataset):
def __init__(self, root="./Pointnet_Pointnet2_pytorch-master/data/s3dis/alter_s3dis_my", split="train",
num_point=4096, test_area=5, block_size=1.0, sample_rate=1.0, transform=None):
'''
root: Data set path
split: Training set or test set("train","test")
num_point: Sampling points
test_area: Test set Area_5. Other numbers can also be taken. In the paper, 5 is taken
block_size: Change the sampling room to block_size * block_size Size of, unit: m
sample_rate: Sampling rate, 1 indicates full sampling
transform: I don't know at present. Follow up
'''
self.num_point = num_point # Sampling points
self.block_size = block_size # Change the sampling room to block_size * block_size, unit: m
self.transform = transform
self.room_points, self.room_labels = [], [] # Point cloud data, label value (refers to: in a point cloud file, label is added to each line of data)
self.room_coord_min, self.room_coord_max = [], [] # Minimum value and maximum value of each dimension (X, Y, Z) of each room (point cloud file)
num_point_all = [] # Total number of points in each room
labelweights = np.zeros(13) # array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
rooms = sorted(os.listdir(root)) # Dataset file, ['area_1_wc_1. TXT ',' area_1_conferenceroom_1. TXT ',...,'area_6_pantry_1. TXT']
rooms = [room for room in rooms if "Area_" in room]
# Data set segmentation
# room.split("_")[1] : Area_1_WC_1.txt'.split("_")[1]
if split=="train":
rooms_split = [room for room in rooms if int(room.split("_")[1]) != test_area]
else:
rooms_split = [room for room in rooms if int(room.split("_")[1]) == test_area]
for room_name in tqdm(rooms_split, total=len(rooms_split)):
room_path = os.path.join(root, room_name) # Get dataset file/ Pointnet_Pointnet2_pytorch-master/data/s3dis/alter_s3dis_my\Area_1_WC_1.txt
room_data = np.loadtxt(room_path) # Load dataset, XYZRGBL, N*7
points, labels = room_data[:, 0:6], room_data[:, 6]
tmp,_ = np.histogram(labels, range(14))
labelweights = labelweights + tmp # Count the number of point categories in all room s
coord_min, coord_max = np.min(points, 0)[:3], np.max(points, 0)[:3]
self.room_points.append(points), self.room_labels.append(labels)
self.room_coord_min.append(coord_min), self.room_coord_max.append(coord_max)
num_point_all.append(labels.size)
labelweights = labelweights.astype(np.float32)
labelweights = labelweights / np.sum(labelweights) # Proportion of all kinds of points in the total points
# Maximum value / labelweights, function: give more weight to those with the least number of categories
# Third power: in order to flatten the weights, they are not easy to change
self.labelweights = np.power(np.max(labelweights)/labelweights, 1/3.0)
sample_prob = num_point_all / np.sum(num_point_all) # Proportion of point clouds per room to total point clouds
num_iter = int( sample_rate * np.sum(num_point_all) / num_point ) # sample_rate * total points / sampling points of all rooms. A total of num iterations are required_ ITER times to sample all rooms
room_idxs = []
for index in range(len(rooms_split)):
# sample_prob[index]: the proportion of the number of point clouds corresponding to room in the total number of point clouds; num_iter: total iterations
room_idxs.extend([index] * int(round(sample_prob[index] * num_iter))) # sample_prob[index] * num_iter: the number of times needed to sample the index room
self.room_idxs = np.array(room_idxs)
print("Totally {} samples in {} set.".format(len(self.room_idxs), split))
def __getitem__(self, index):
room_idx = self.room_idxs[index]
points = self.room_points[room_idx] # N × 6
labels = self.room_labels[room_idx] # N × 1
N = points.shape[0] # Number of points
while(True):
center = points[np.random.choice(N), :3] # Randomly assign a point as the center of the block
# 1m × 1m range
block_min = center - [self.block_size/2.0, self.block_size/2.0, 0]
block_max = center + [self.block_size/2.0, self.block_size/2.0, 0]
'''
np.where(condition, a, b): satisfy condition,fill a,Otherwise fill b
If not a,b,only np.where(condition),Returns:(array1, array2),array1 Rows that meet the criteria, array2: Qualified columns
'''
# The index of the selected point within the range of the block
point_index = np.where((points[:, 0] >= block_min[0]) & (points[:, 0] <= block_max[0]) & (points[:, 1] >= block_min[1]) & (points[:, 1] <= block_max[1]))[0]
if point_index.shape[0]>1024:
break
# sampling
if point_index.shape[0] >= self.num_point:
sample_point_index = np.random.choice(point_index, self.num_point, replace=False)
else:
sample_point_index = np.random.choice(point_index, self.num_point, replace=True)
sample_points = points[sample_point_index, :] # num_point × 6
# normalization
current_points = np.zeros([self.num_point, 9]) # num_point × 9. XYZRGBX'Y'Z ', X': coordinates after X normalization
current_points[:, 6] = sample_points[:, 0] / self.room_coord_max[room_idx][0]
current_points[:, 7] = sample_points[:, 1] / self.room_coord_max[room_idx][1]
current_points[:, 8] = sample_points[:, 2] / self.room_coord_max[room_idx][2]
sample_points[:, 0] = sample_points[:, 0] - center[0]
sample_points[:, 1] = sample_points[:, 1] - center[1]
sample_points[:, 3:6] = sample_points[:, 3:6] / 255
current_points[:, 0:6] = sample_points
current_labels = labels[sample_point_index]
if self.transform:
current_points, current_labels = self.transform(current_points, current_labels)
return current_points, current_labels
def __len__(self):
return len(self.room_idxs)
hdf5 format
-
Due to the official hdf5 data, I won't use it.
-
Therefore, I converted the txt file with label label on each line in the official TXT format file (I have written the conversion code and comments in the above code) into hdf5 format
-
The path of the official txt file with label on each line: D:\AnacondaCodeDeep_Learning 3D point cloud \ Pointnet_Pointnet2_pytorch-master\data\s3dis\alter_s3dis_my
-
Convert the files in the above directory into hdf5 format, put in: D:\AnacondaCodeDeep_Learning 3D point cloud \ data
-
Convert to hdf5 format
def convert_txt_to_h5(source = r"D:\AnacondaCode\04Deep_Learning\03 3D point cloud\Pointnet_Pointnet2_pytorch-master\data\s3dis\alter_s3dis_my",
target = r"D:\AnacondaCode\04Deep_Learning\03 3D point cloud\data\S3DIS_hdf5"):
for file in glob.glob(source+"/*.txt"):
name = file.replace('\\', '/').split("/")[-1][:-4]
data = np.loadtxt(file)
points = data[:, :6]
labels = data[:, 6]
f = h5py.File(target+"/"+name+".h5", "w")
f.create_dataset("data", data=points)
f.create_dataset("label", data=labels)
f.close()
convert_txt_to_h5()
- DataSet: read hdf5 format
# hdf5 form
class S3DISDataSetH5(Dataset):
def __init__(self, root="./data/S3DIS_hdf5", split="train",
num_point=4096, test_area=5, block_size=1.0, sample_rate=1.0, transform=None):
'''
root: Data set path
split: Training set or test set("train","test")
num_point: Sampling points
test_area: Test set Area_5. Other numbers can also be taken. In the paper, 5 is taken
block_size: Change the sampling room to block_size * block_size Size of, unit: m
sample_rate: Sampling rate, 1 indicates full sampling
transform: I don't know at present. Follow up
'''
self.num_point = num_point # Sampling points
self.block_size = block_size # Change the sampling room to block_size * block_size, unit: m
self.transform = transform
self.room_points, self.room_labels = [], [] # Point cloud data, label value (refers to: in a point cloud file, label is added to each line of data)
self.room_coord_min, self.room_coord_max = [], [] # Minimum value and maximum value of each dimension (X, Y, Z) of each room (point cloud file)
num_point_all = [] # Total number of points in each room
labelweights = np.zeros(13) # array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
rooms = [os.path.basename(file) for file in glob.glob(root+"/*.h5")] # Dataset file, ['area_1_conferenceroom_1. H5 ','area_1_conferenceroom_2. H5',...,'area_6_pantry_1. H5 ']
rooms = [room for room in rooms if "Area_" in room]
# Data set segmentation
# room.split("_")[1] : Area_1_WC_1.h5'.split("_")[1]
if split=="train":
rooms_split = [room for room in rooms if int(room.split("_")[1]) != test_area]
else:
rooms_split = [room for room in rooms if int(room.split("_")[1]) == test_area]
for room_name in tqdm(rooms_split, total=len(rooms_split)):
room_path = os.path.join(root, room_name) # Get dataset file/ data/S3DIS_hdf5\Area_1_WC_1.h5
# Read h5 file
f = h5py.File(room_path)
points = np.array(f["data"]) # [N, 6] XYZRGB
labels = np.array(f["label"]) # [N,] L
f.close()
tmp,_ = np.histogram(labels, range(14))
labelweights = labelweights + tmp # Count the number of point categories in all room s
coord_min, coord_max = np.min(points, 0)[:3], np.max(points, 0)[:3]
self.room_points.append(points), self.room_labels.append(labels)
self.room_coord_min.append(coord_min), self.room_coord_max.append(coord_max)
num_point_all.append(labels.size)
labelweights = labelweights.astype(np.float32)
labelweights = labelweights / np.sum(labelweights) # Proportion of all kinds of points in the total points
# Maximum value / labelweights, function: give more weight to those with the least number of categories
# Third power: in order to flatten the weights, they are not easy to change
self.labelweights = np.power(np.max(labelweights)/labelweights, 1/3.0)
sample_prob = num_point_all / np.sum(num_point_all) # Proportion of point cloud number of each room to total point cloud number
num_iter = int( sample_rate * np.sum(num_point_all) / num_point ) # sample_rate * total points / sampling points of all rooms. A total of num iterations are required_ ITER times to sample all rooms
room_idxs = []
for index in range(len(rooms_split)):
# sample_prob[index]: the proportion of the number of point clouds corresponding to room in the total number of point clouds; num_iter: total iterations
room_idxs.extend([index] * int(round(sample_prob[index] * num_iter))) # sample_prob[index] * num_iter: the number of times needed to sample the index room
self.room_idxs = np.array(room_idxs)
print("Totally {} samples in {} set.".format(len(self.room_idxs), split)) # len(self.room_idxs): 47576
# len(room_idxs) == num_iter
def __getitem__(self, index):
room_idx = self.room_idxs[index]
points = self.room_points[room_idx] # N × 6
labels = self.room_labels[room_idx] # N × 1
N = points.shape[0] # Number of points
while(True):
center = points[np.random.choice(N), :3] # Randomly assign a point as the center of the block
# 1m × 1m range
block_min = center - [self.block_size/2.0, self.block_size/2.0, 0]
block_max = center + [self.block_size/2.0, self.block_size/2.0, 0]
'''
np.where(condition, a, b): satisfy condition,fill a,Otherwise fill b
If not a,b,only np.where(condition),Returns:(array1, array2),array1 Rows that meet the criteria, array2: Qualified columns
'''
# The index of the selected point within the range of the block
point_index = np.where((points[:, 0] >= block_min[0]) & (points[:, 0] <= block_max[0]) & (points[:, 1] >= block_min[1]) & (points[:, 1] <= block_max[1]))[0]
if point_index.shape[0]>1024:
break
# sampling
if point_index.shape[0] >= self.num_point:
sample_point_index = np.random.choice(point_index, self.num_point, replace=False)
else:
sample_point_index = np.random.choice(point_index, self.num_point, replace=True)
sample_points = points[sample_point_index, :] # num_point × 6
# normalization
current_points = np.zeros([self.num_point, 9]) # num_point × 9. XYZRGBX'Y'Z ', X': coordinates after X normalization
current_points[:, 6] = sample_points[:, 0] / self.room_coord_max[room_idx][0]
current_points[:, 7] = sample_points[:, 1] / self.room_coord_max[room_idx][1]
current_points[:, 8] = sample_points[:, 2] / self.room_coord_max[room_idx][2]
sample_points[:, 0] = sample_points[:, 0] - center[0]
sample_points[:, 1] = sample_points[:, 1] - center[1]
sample_points[:, 3:6] = sample_points[:, 3:6] / 255
current_points[:, 0:6] = sample_points
current_labels = labels[sample_point_index]
if self.transform:
current_points, current_labels = self.transform(current_points, current_labels)
return current_points, current_labels
def __len__(self):
return len(self.room_idxs)
- Use the entire scene
- The following code draws lessons from the source code and has great changes with the source code
class S3DISWholeSceneDataSetH5(Dataset):
def __init__(self, root="./data/S3DIS_hdf5", block_points=4096, split='test', test_area=5, block_size=1.0, padding=0.005):
self.root = root # Dataset path
self.block_points = block_points # The number of points sampled in the part of the room to be segmented
self.block_size = block_size # Size of split part: block_size × block_size
self.padding = padding # Each divided part overlaps with the adjacent divided part
self.room_points_num = [] # Points per room
self.room_points = [] # Data for each point in each room (XYZRGB)
self.room_labels = [] # L abel of each point in each room
self.room_coord_min, self.room_coord_max = [], [] # Minimum and maximum XYZ coordinates in each room
assert split in ["train", "test"] # assert True: execute the program normally. assert False: trigger an exception, that is, an error is reported
rooms = [os.path.basename(f) for f in glob.glob(root+"/*.h5")] # ['Area_1_conferenceRoom_1.h5', 'Area_1_conferenceRoom_2.h5', ...]
if split == "train":
self.rooms = [room for room in rooms if int(room.split("_")[1]) != test_area]
else:
self.rooms = [room for room in rooms if int(room.split("_")[1]) == test_area]
labelweights = np.zeros(13) # Label value weight
for room in tqdm(self.rooms, total=len(self.rooms)):
f = h5py.File(root+"/"+room)
points = np.array(f["data"]) # [N, 6] XYZRGB
labels = np.array(f["label"]) # [N, ] L
f.close()
temp, _ = np.histogram(labels, range(14)) # Number of occurrences of each tag value
labelweights = labelweights + temp
self.room_points.append(points)
self.room_labels.append(labels)
coord_min, coord_max = np.min(points, axis=0)[0:3], np.max(points, axis=0)[0:3]
self.room_coord_min.append(coord_min), self.room_coord_max.append(coord_max)
self.room_points_num.append(labels.shape[0])
labelweights = labelweights / np.sum(labelweights)
self.labelweights = np.power( np.max(labelweights) / labelweights, 1/3.0 )
def __getitem__(self, index):
points = self.room_points[index] # Data of each point of the index room (XYZRGB)
labels = self.room_labels[index].astype(np.int64) # L abel of each point of the index room
coord_min, coord_max = self.room_coord_min[index], self.room_coord_max[index]
# points_room: point data (XYZRGBX'Y'Z ') labels of each grid in a room_ Room: point label of each grid in a room
points_room, labels_room = [], []
# The XY axis is regarded as a plane, which is similar to the YOLOv1 algorithm. The plane is divided, but each grid overlaps with its adjacent grid
# The normal size of each grid is 1m × 1m, but there needs to be overlap, so the scope of the grid needs to be appropriately expanded
grid_x = int(np.ceil((coord_max[0] - coord_min[0]) / self.block_size)) # The x-axis is divided into grid_x grids
grid_y = int(np.ceil((coord_max[1] - coord_min[1]) / self.block_size)) # The Y axis is divided into grid_x grids
for row in range(grid_y): # that 's ok
for col in range(grid_x): # column
x_min = col - self.padding
y_min = row - self.padding
x_max = (col + 1) + self.padding
y_max = (row + 1) + self.padding
points_index = np.where( (points[:,0]>x_min) & (points[:,0]<x_max) & (points[:,1]>y_min) & (points[:,1]<y_max) )[0]
if points_index.shape[0] == 0:
continue
# The number of points sampled must be block_ Multiple of points, otherwise reshape cannot be performed later
# If the number of points in a grid is < block_ Points, repeat the sampling of the missing points
multiple = int(np.ceil(points_index.shape[0] / self.block_points))
if points_index.shape[0] < self.block_points:
points_index_repeat = np.random.choice(points_index, self.block_points - points_index.shape[0], replace=True)
else:
points_index_repeat = np.random.choice(points_index, multiple * self.block_points - points_index.shape[0], replace=False)
points_index = np.concatenate([points_index, points_index_repeat], axis=0)
np.random.shuffle(points_index)
# Point cloud data and point cloud labels in a grid
points_grid = points[points_index]
labels_grid = labels[points_index]
# XYZ coordinate normalization
# In the source code: the XY coordinates in a grid are subtracted from the center point of the grid
# In my code, there is no need to subtract (I have experimented with subtraction and non subtraction) the central point, and the conclusion that it can not be subtracted is obtained
# The reasons are as follows;
# If the XY coordinate of each grid subtracts the center point of the grid, although the relative position of the points in the grid remains the same
# However, the positions of the points of this grid and the points of adjacent grids will change
norm_xyz = np.zeros((points_index.shape[0], 3))
norm_xyz[:, 0] = points_grid[:, 0] / coord_max[0]
norm_xyz[:, 1] = points_grid[:, 1] / coord_max[1]
norm_xyz[:, 2] = points_grid[:, 2] / coord_max[2]
points_grid[:, 3:6] = points_grid[:, 3:6] / 255
points_grid = np.concatenate([points_grid, norm_xyz], axis=1) # [N, 9]
points_room.append(points_grid)
labels_room.append(labels_grid)
points_room = np.concatenate(points_room)
labels_room = np.concatenate(labels_room)
points_room = points_room.reshape(-1, self.block_points, points_room.shape[1]) # [B, N, 9]
labels_room = labels_room.reshape(-1, self.block_points) # [B, N]
return points_room, labels_room
def __len__(self):
return len(self.room_points_num)
Define T-Net
class STN3d(nn.Module):
def __init__(self, channel):
super().__init__()
self.conv1 = nn.Conv1d(channel, 64, 1)
self.conv2 = nn.Conv1d(64, 128, 1)
self.conv3 = nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 9)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
def forward(self, x):
batch_size = x.shape[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x))) # x.shape: [32, 1024, 2500]
x = torch.max(x,-1, keepdim=True)[0] # x.shape: [32, 1024, 1], keepdim=True, keep the dimension after output the same as the input dimension, for example: if input is three-dimensional, then output is also three-dimensional
x = x.view(-1,1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
# I don't know why I wrote this
iden = torch.eye(3).view(1, 9).repeat(batch_size, 1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, 3, 3)
return x
class STNkd(nn.Module):
def __init__(self, channel=64):
super().__init__()
self.conv1 = nn.Conv1d(channel, 64, 1)
self.conv2 = nn.Conv1d(64, 128, 1)
self.conv3 = nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, channel*channel)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
self.channel = channel
def forward(self, x):
batch_size = x.shape[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x))) # x.shape: [32, 1024, 2500]
x = torch.max(x,-1, keepdim=True)[0] # x.shape: [32, 1024, 1], keepdim=True, keep the dimension after output the same as the input dimension, for example: if input is three-dimensional, then output is also three-dimensional
x = x.view(-1,1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
# I don't know why I wrote this
iden = torch.eye(self.channel).view(1, self.channel * self.channel).repeat(batch_size, 1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, self.channel, self.channel)
return x
Define PointNet body part
class PointNetEncoder(nn.Module):
def __init__(self, global_feature=True, feature_transform=False, channel=3):
'''
global_feature: True,Then classify
feature_transform: True,Then split
'''
super().__init__()
self.stn = STN3d(channel) # Spatial transformation network
self.conv1 = nn.Conv1d(channel, 64, 1)
self.conv2 = nn.Conv1d(64, 128, 1)
self.conv3 = nn.Conv1d(128, 1024, 1)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.global_feature = global_feature # Global features
self.feature_transform = feature_transform # Whether to calibrate high-dimensional features by rotation transformation
if self.feature_transform:
self.fstn = STNkd(64)
def forward(self, x): # x.shape: [32, 3, 2500]
B, D, N = x.shape # B: batch_size, D: dimension, N: number
stn3 = self.stn(x) # stn3.shape: [32, 3, 3]
x = x.transpose(2,1) # x.shape: [32, 2500, 3]
if D>3: # If dimension > 3
feature = x[:, :, 3:]
x = x[:, :, :3]
x = torch.bmm(x, stn3) # x.shape: [32, 2500, 3] stn3: [32, 3, 3]. Use torch BMM (t1,t2), T1 and T2 must all be three-dimensional, and the first dimension must be the same. The other two dimensions are multiplied according to the matrix
if D>3:
x = torch.cat([x, feature], dim=2)
x = x.transpose(2,1) # x.shape: [32, 3, 2500]
x = F.relu(self.bn1(self.conv1(x))) # x.shape: [32, 64, 2500]
if self.feature_transform: # Whether to rotate high-dimensional features
stn64 = self.fstn(x)
x = x.transpose(2,1) # x.shape: [32, 2500, 64]
x = torch.bmm(x, stn64)
x = x.transpose(2,1) # x.shape: [32, 64, 2500]
else:
stn64 = None
point_feature = x # Rotated feature, point_feature.shape: [32, 64, 2500]
x = F.relu(self.bn2(self.conv2(x))) # x.shape: [32, 128, 2500]
x = self.bn3(self.conv3(x)) # x.shape: [32, 1024, 2500]
x = torch.max(x, dim=2)[0] # x.shape: [32, 1024]
x = x.view(-1, 1024) # x.shape: [32, 1024]
if self.global_feature:
return x, stn3, stn64 # Return: global feature, input transform, feature transform
else:
x = x.view(-1, 1024, 1).repeat(1, 1, N) # x.shape: [32, 1024, 2500]
compoud = torch.cat([point_feature, x], dim=1) # compoud.shape: [32, 1088, 2500]
return compoud, stn3, stn64 # Corresponding point cloud segmentation algorithm
def feature_transform_reguliarzer(trans):
d = trans.shape[1]
I = torch.eye(d)[None, :, :] # [None,:,:]: None is to add a dimension. Torch can also be used eye(d). unsqeeze(0)
if trans.is_cuda:
I = I.cuda()
loss = torch.mean(torch.norm(torch.bmm(trans, trans.transpose(2, 1)), dim=(1,2)))
return loss
Semantic segmentation
class Semantic_Segmentation(nn.Module):
def __init__(self, num_class): # num_ Number of classes. S3DIS has 13 categories
super().__init__()
self.num_class = num_class
self.point_encoder = PointNetEncoder(False, True, 9)
self.conv1 = nn.Conv1d(1088, 512, 1)
self.conv2 = nn.Conv1d(512, 256, 1)
self.conv3 = nn.Conv1d(256, 128, 1)
self.conv4 = nn.Conv1d(128, self.num_class, 1)
self.bn1 = nn.BatchNorm1d(512)
self.bn2 = nn.BatchNorm1d(256)
self.bn3 = nn.BatchNorm1d(128)
def forward(self, x):
batch_size = x.shape[0] # x.shape: [32, 9, 2500]
N = x.shape[2]
x, stn3, stn64 = self.point_encoder(x)
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = self.conv4(x) # x.shape: [32, 13, 2500]
x = x.transpose(2,1).contiguous() # contiguous(): change the tensor address to continuous, otherwise x.view() will report an error. x.shape: [32, 2500, 13]
x = F.log_softmax(x.view(-1, self.num_class), -1) # x.view(-1, self.num_class): [80000, 13]
x = x.view(batch_size, N, self.num_class)
return x, stn64
class Semantic_Segmentation_Loss(nn.Module):
def __init__(self, mat_diff_loss_scale=0.001):
super().__init__()
self.mat_diff_loss_scale = mat_diff_loss_scale
def forward(self, pred, target, stn64, weight):
loss = F.nll_loss(pred, target, weight)
mat_diff_loss = feature_transform_reguliarzer(stn64)
total_loss = loss + mat_diff_loss * self.mat_diff_loss_scale
return total_loss
Semantic segmentation training and verification
Note: verification and testing are two different tasks, specific Baidu
train_dataset = S3DISDataSetH5(split="train") val_dataset = S3DISDataSetH5(split="test") train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=0, drop_last=True) val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=True, num_workers=0, drop_last=True)
- PS: Here's an episode. I run the above four lines of code on the 13G memory of the cloud platform. There is not enough memory, so I can only run train code. I think the memory should be greater than 15G, which can run the above four lines of code perfectly
lr = 0.01
EPOCH = 60
weights = torch.tensor(train_dataset.labelweights, dtype=torch.float64) # Weight of each category
model = Semantic_Segmentation(13).double() # 13: Total number of semantic segmentation categories
optimizer = optim.Adam(model.parameters(), lr) # optimizer
criterion = Semantic_Segmentation_Loss() # loss function
if torch.cuda.is_available():
model = model.cuda()
weights = weights.cuda()
for epoch in range(EPOCH):
# train
num_batch = len(train_dataloader) # Batch quantity, not batch_size
total_correct = 0 # Predict the correct quantity. From the 0th cycle to this cycle, predict the sum of the correct quantity
total_point_number = 0 # The number of points traversed under the current loop (including the loop between). That is, count the total number of points traversed from the 0th cycle to this cycle
loss_sum = 0 # Total loss in a batch
model = model.train() # Set to training mode
for points, labels in train_dataloader: # points.shape: [32, N, C] for example: [32, 4096, 9] labels: [32, n] for example: [32, 4096]
if torch.cuda.is_available():
points = points.cuda()
labels = labels.cuda()
optimizer.zero_grad()
points = points.transpose(2,1) # points.shape: [32, C, N]
sem_pre, stn64 = model(points) # sem_pre.shape: [32, N, NUM_CLASS]
sem_pre = sem_pre.contiguous().view(-1, 13)
labels = labels.view(-1, 1)[:, 0]
loss = criterion(sem_pre, labels.long(), stn64, weights) # Loss in a batch
loss.backward()
optimizer.step()
loss_sum = loss_sum + loss.item() # Total loss in a batch
pre_class = sem_pre.max(1)[1] # Category of each point forecast
correct = torch.sum(pre_class == labels) # Accuracy per batch
total_correct = total_correct + correct.item()
total_point_number = total_point_number + points.shape[0] * points.shape[2] # points.shape[0]: 32,batch_size is 32; points.shape[2]: 4096. The number of points in each batch element is 4096.
print("The first"+str(epoch+1)+"Wheel, loss:"+str(loss_sum/32)+",Accuracy:"+str(total_correct/total_point_number))
torch.save(model.state_dict(), "./model/model_state_dict_"+str(epoch+1)+".pkl")
# verification
with torch.no_grad():
num_batch = len(val_dataloader)
total_correct = 0
total_point_number = 0
loss_sum = 0
labelweights = np.zeros(13)
total_correct_class = [0] * 13 # Each category predicts the correct total number and is also the molecule of IOU
tota1_point_number_class = [0] * 13 # Total points of each category
total_iou_deno_class = [0] * 13 # Denominator of IOU
model = model.eval()
for points, labels in val_dataloader:
points = points.type(torch.float64) # points.shape: [32, 4096, 9]
labels = labels.type(torch.long) # labels.shape: [32, 4096]
points = points.transpose(2, 1)
labels = labels.reshape(-1) # [32×4096]
sem_pre, stn64 = model(points) # sem_pre: [B, N, 13]
sem_pre = sem_pre.reshape(-1, 13) # [B×N, 13]
loss = criterion(sem_pre, labels, stn64, weights)
loss_sum = loss_sum + loss.item()
pre_class = sem_pre.max(-1)[1]
correct = torch.sum(pre_class == labels)
total_correct = total_correct + correct
total_point_number = total_point_number + points.shape[0] * points.shape[2]
temp,_ = np.histogram(labels, range(14))
labelweights = labelweights + temp
for i in range(13):
tota1_point_number_class[i] = tota1_point_number_class[i] + torch.sum( labels == i ).item()
total_correct_class[i] = total_correct_class[i] + torch.sum( (pre_class == i) & (labels == i) ).item()
total_iou_deno_class[i] = total_iou_deno_class[i] + torch.sum( (pre_class == i) | (labels == i) ).item()
labelweights = labelweights / np.sum(labelweights)
mIOU = np.mean( np.array(total_correct_class) / ( np.array(total_iou_deno_class)+1e-10 ) )
print("Average loss of verification set:%s,Avg mIOU: %s,Accuracy:%s,Avg Accuracy:%s" % (str(loss_sum/num_batch),str(mIOU),
str(total_correct/total_point_number),
str(np.mean(np.array(total_correct_class)/np.array(tota1_point_number_class)))))
test
- In the process of analyzing the source code, I don't understand this part. Let's build the test code according to my own understanding
test_dataset = S3DISWholeSceneDataSetH5()
- Code Description:
points, labels, weights, grid_points_index = test_dataset[room_index] # room_index: room_ It's a room
points.shape: [272, 4096, 9]
Because the model cannot run Such large data, so it needs to be separated run.
272 Divide n 32 sizes; If 272 cannot be divided into 32, the part that cannot be divided into run Part of.
For example:
272 / 32 = 8.5 # Can not be eliminated
272 % 32 = 16 # The remaining 16
Then:
8 individual [32, 4096, 9]
1 individual [16, 4096, 9]
batch_size = 32
# Load model parameters
model = Semantic_Segmentation(13).double() # 13: Total number of semantic segmentation categories
model.load_state_dict(torch.load("./model/pointnet_state_dict_18.pkl", map_location='cpu'))
model.eval()
with torch.no_grad():
room_id = test_dataset.rooms
room_size = len(test_dataset) # 272 there are 272 room files
idx = 0
# test
for room_index in tqdm(range(room_size), total=room_size):
print("start [%d/%d] %s ..." % (room_index, room_size, room_id[room_index]))
tota1_point_number_class = [0] * 13
total_correct_class = [0] * 13
total_iou_deno_class = [0] * 13
points, labels, weights, grid_points_index = test_dataset[room_index]
points = torch.tensor(points)
labels = torch.tensor(labels)
room_pre_class = []
room_labels = []
batch_points = torch.zeros(batch_size, points.shape[1], points.shape[2])
batch_labels = torch.zeros(batch_size, points.shape[1])
sum_batch_size = 0
while points.shape[0] % batch_size != 0:
whether = int(points.shape[0] / batch_size) # Integer, 32 batch data in each batch
final_start_batch = points.shape[0] % batch_size
if idx == whether:
batch_points = points[-final_start_batch:, :, :] # [final_start_batch, N, 9]
batch_labels = labels[-final_start_batch:, :] # [final_start_batch, N]
else:
batch_points = points[idx*batch_size:(idx+1)*batch_size, :, :] # [32, N, 9]
batch_labels = labels[idx*batch_size:(idx+1)*batch_size, :] # [32, N]
batch_points = batch_points.transpose(2, 1) # [B, 9, N]
sem_pre, _ = model(batch_points) # [B, N, 13]
pre_class = torch.max(sem_pre, dim=-1)[1] # [B, N] category of prediction point
room_pre_class.append(pre_class)
room_labels.append(batch_labels)
idx = idx + 1
sum_batch_size = sum_batch_size + batch_points.shape[0]
if sum_batch_size == points.shape[0]:
break
room_pre_class = torch.cat(room_pre_class).reshape(-1) # [N_all]
room_labels = torch.cat(room_labels).reshape(-1) # [N_all]
for i in range(13):
tota1_point_number_class[i] = tota1_point_number_class[i] + torch.sum( room_labels == i ).item()
total_correct_class[i] = total_correct_class[i] + torch.sum( (room_pre_class == i) & (room_labels == i) ).item()
total_iou_deno_class[i] = total_iou_deno_class[i] + torch.sum( (room_pre_class == i) | (room_labels == i) ).item()
mIOU = np.mean( np.array(total_correct_class) / ( np.array(total_iou_deno_class)+1e-10 ) )
print("Avg mIOU: %s,Accuracy:%s" % (str(mIOU),str(sum(total_correct_class)/sum(tota1_point_number_class))))
show_point_cloud = torch.cat([points.reshape(-1,9), room_labels.reshape(-1,1), room_pre_class.reshape(-1,1)], dim=1)
f = h5py.File("./predition/"+room_id[room_index], "w")
f.create_dataset("data", data=show_point_cloud)
f.close()
Show point cloud
- Learning link: https://zhuanlan.zhihu.com/p/338845304
- Show the effect on area_ 5_ conferenceRoom_ 1. Prediction results of H5.
- Because of the cloud platform, each training can last up to 13 hours, with a total of about 40 hours a week. I trained twice in a row, with a total of about 26 hours and 18 epochs.
- In the area_ 5_ conferenceRoom_ 1. In the test of H5, Avg mIOU is 0.03925852346625844, and the accuracy is 0.2383061986770073.
# Display forecast
path = "./predition/Area_5_conferenceRoom_1.h5"
f = h5py.File(path, "r")
data = f["data"][:, :6]
pre_labels = f["data"][:, 10]
points = data[:, :3]
# Convert the label value to the corresponding RGB value
colors = np.zeros((pre_labels.shape[0],3), dtype=np.float) # shape: [N, 3]
# Change the label value to corresponding RGB
for i in range(13):
index = np.where(pre_labels == i)[0]
colors[index] = np.array(label2color[i]) / 255
pcd = o3d.geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(points)
pcd.colors = o3d.utility.Vector3dVector(colors) # RRB range: 0-1
o3d.visualization.draw_geometries([pcd])

- Display original data (RGB and color of corresponding category)
# Color of corresponding category
path = "./data/S3DIS_hdf5/Area_5_conferenceRoom_1.h5"
f = h5py.File(path, "r")
data = np.array(f["data"])
labels = np.array(f["label"])
points = np.array(data[:, :3])
# Convert the label value to the corresponding RGB value
colors = np.zeros((labels.shape[0],3), dtype=np.float) # shape: [N, 3]
# Change the label value to corresponding RGB
for i in range(13):
index = np.where(labels == i)[0]
colors[index] = np.array(label2color[i]) / 255
pcd = o3d.geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(points)
pcd.colors = o3d.utility.Vector3dVector(colors) # RRB range: 0-1
o3d.visualization.draw_geometries([pcd])

# RGB path = "./data/S3DIS_hdf5/Area_5_conferenceRoom_1.h5" f = h5py.File(path, "r") data = np.array(f["data"]) # labels = np.array(f["label"]) points = np.array(data[:, :3]) colors = np.array(data[:, 3:6]) / 255 # # Convert the label value to the corresponding RGB value # colors = np.zeros((labels.shape[0],3), dtype=np.float) # shape: [N, 3] # # Change the label value to corresponding RGB # for i in range(13): # index = np.where(labels == i)[0] # colors[index] = np.array(label2color[i]) / 255 pcd = o3d.geometry.PointCloud() pcd.points = o3d.utility.Vector3dVector(points) pcd.colors = o3d.utility.Vector3dVector(colors) # RRB range: 0-1 o3d.visualization.draw_geometries([pcd])

Reference
[1] Qi C R, Su H, Mo K, et al. Pointnet: Deep learning on point sets for 3d classification and segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 652-660.
[2] https://github.com/yanx27/Pointnet_Pointnet2_pytorch