1, Content summary
This paper mainly focuses on the ThreadPoolExecutor in JDK. Firstly, it describes the construction process of ThreadPoolExecutor and the mechanism of internal state management. Then, it uses a lot of space to explore the process of ThreadPoolExecutor thread allocation, task processing, rejection policy, start and stop, and focuses on the analysis of Worker's built-in classes, The content not only includes its working principle, but also analyzes its design idea. The article not only includes the source code process analysis, but also has the design idea discussion and secondary development practice.
2, Construct ThreadPoolExecutor
2.1} thread pool parameter list
You can create a thread pool through the following construction methods (in fact, there are other constructors. You can go deep into the source code, but in the end, you call the following constructors to create a thread pool);
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
...
}The functions of the structural parameters are as follows:
- corePoolSize: number of core threads. When submitting a task, when the number of threads in the thread pool is less than corePoolSize, a new core thread will be created to execute the task. When the number of threads is equal to corePoolSize, the task is added to the task queue.
- maximumPoolSize: maximum number of threads. When submitting a task, when the task queue is full and the number of bus processes in the thread pool is not greater than maximumPoolSize, the thread pool will make non core threads execute the submitted task. When it is greater than maximumPoolSize, the reject policy is executed.
- keepAliveTime: the lifetime of a non core thread when it is idle.
- Unit: the unit of keepAliveTime.
- workQueue: task queue (blocking queue).
- threadFactory: thread factory. The factory class used by the thread pool to create new threads.
- handler: reject policy. When the thread pool encounters a situation that cannot be handled, it will execute the reject policy and choose to abandon or ignore the task.
2.2 overview of execution process
From the function of construction parameters, we can see that the thread pool consists of several important components: core thread pool, idle (non core) thread pool , and , blocking queue. Here, we first give the core execution flow chart of the thread pool. We will have an impression of it first, and then it will be easier to analyze the source code.
Here are some notes in the flowchart: cap indicates the capacity of the pool, and size indicates the number of running threads in the pool. For a blocked queue, cap represents the queue capacity and size represents the number of tasks that have been queued. CPS < CPC indicates that the number of running core threads is less than the number of core threads set by the thread pool.
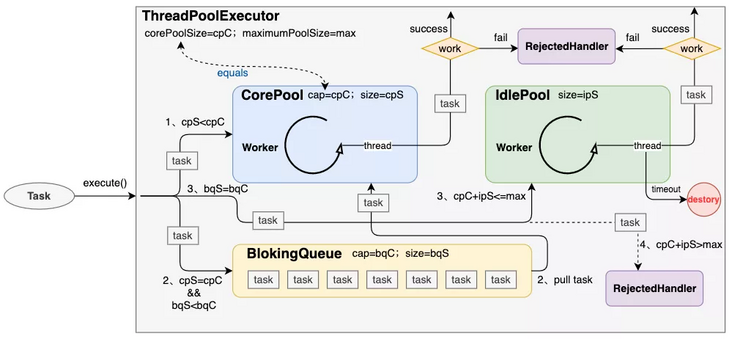
1) When the core thread pool is not "full", a new core thread will be created to execute the submitted task. The "full" here means that the number (size) in the core thread pool is less than the capacity (cap). In this case, a new thread will be created through the thread factory to execute the submission task.
2) When the core thread pool is "full", the submitted task will be push ed into the task queue, waiting for the release of the core thread. Once the core thread is released, it will pull the task from the task queue to continue execution. Because the blocking queue is used, the core threads that have been released will also be blocked in the process of obtaining tasks.
3) When the task queue is also full (full here means that it is really full. Of course, unbounded queue is not considered temporarily), threads will continue to be created from the idle thread pool to execute the submitted tasks. However, the threads in the idle thread pool have survival time (keepAliveTime). After a thread executes a task, it can only survive keepAliveTime for a long time. Once the time passes, the thread must be destroyed.
4) When the number of threads in the idle thread pool continues to increase until the number of bus processes in ThreadPoolExecutor is greater than maximumPoolSize, the task will be rejected and the submitted task will be handed over to RejectedExecutionHandler for subsequent processing.
The above-mentioned core thread pool and idle thread pool are only abstract concepts. We will analyze their specific contents later.
2.3 common thread pool
Before entering the source code analysis of ThreadPoolExecutor, let's first introduce the commonly used thread pools (actually not commonly used, but brought with JDK). These thread pools can be created by the tool class Executors (or thread pool factory).
2.3.1 FixedThreadPool
The creation method of fixed thread pool is as follows: the number of core threads and the maximum number of threads are fixed and equal, and the unbounded blocking queue with linked list as the underlying structure is adopted.
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}characteristic:
- The number of core threads is equal to the maximum number of threads, so no idle threads will be created. It doesn't matter whether keepAliveTime is set or not.
- With unbounded queues, tasks are added indefinitely until memory overflow (OOM).
- Since the unbounded queue cannot be full, the task cannot be rejected before execution (provided that the thread pool is always running).
Application scenario:
- It is suitable for scenarios with a fixed number of threads
- Suitable for servers with heavy load
2.3.2 SingleThreadExecutor
The creation method of single thread pool is as follows: the number of core threads and the maximum number of threads are 1, and the unbounded blocking queue with linked list as the underlying structure is adopted.
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}characteristic
- It is similar to FixedThreadPool, except that the number of threads is 1.
Application scenario
- It is suitable for single threaded scenarios.
- It is applicable to scenarios that require sequential processing of submitted tasks.
2.3.3 CachedThreadPool
The creation method of buffer thread pool is as follows: the number of core threads is 0, and the maximum number of threads is integer MAX_ Value (can be understood as infinity). Synchronous blocking queue is adopted.
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}characteristic:
- If the number of core threads is 0, an idle thread will be created initially, and the idle thread can only wait for 60s. If no task is submitted within 60s, the idle thread will be destroyed.
- The maximum number of threads is infinite, which will cause a large number of threads to run at the same time, and the CPU load is too high, resulting in application crash.
- Synchronous blocking queue is adopted, that is, the queue does not store tasks. Submit one and consume one. Since the maximum number of threads is infinite, the task will be consumed as long as it is submitted (before the application crashes).
Application scenario:
- It is suitable for small programs that are time-consuming and asynchronous.
- Suitable for servers with light load.
3, Thread pool status and number of active threads
ThreadPoolExecutor has two very important parameters: thread pool status (rs) and number of {active threads (wc). The former is used to identify the status of the current thread pool and control what the thread pool should do according to the state quantity; the latter is used to identify the number of active threads and control whether threads should be created in the core thread pool or idle thread pool according to the quantity.
ThreadPoolExecutor uses an Integer variable (ctl) to set these two parameters. We know that under different operating systems, the Integer variable in Java is 32 bits. ThreadPoolExecutor uses the first 3 bits (31 ~ 29) to represent the thread pool status and the last 29 bits (28 ~ 0) to represent the number of active threads.

What is the purpose of this setting?
We know that the cost of maintaining two variables at the same time in a concurrent scenario is very high. Locking is often required to ensure that the changes of the two variables are atomic. When two parameters are maintained with one variable, only one statement is needed to ensure the atomicity of the two variables. This method greatly reduces the concurrency problem in the use process.
With the above concepts in mind, let's take a look at several states of ThreadPoolExecutor from the source code level, and how ThreadPoolExecutor operates on two parameters: the state and the number of active threads at the same time.
The source code of ThreadPoolExecutor about state initialization is as follows:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); private static final int COUNT_BITS = Integer.SIZE - 3; private static final int CAPACITY = (1 << COUNT_BITS) - 1; private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS; private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS;
ThreadPoolExecutor defines ctl variables using atomic integers. ctl wraps the number of active threads and thread pool runtime state in an int. To achieve this, The number of threads in ThreadPoolExecutor is limited to 2 ^ 29-1 (about 500 million) instead of 2 ^ 31-1 (2 billion), because the first three bits are used to identify the status of ThreadPoolExecutor. If the number of threads in ThreadPoolExecutor is insufficient in the future, you can set ctl to the original sub long type and adjust the corresponding mask.
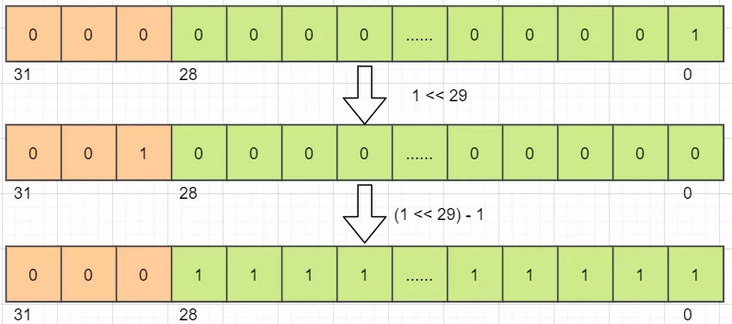
COUNT_BITS is conceptually used to represent the boundary value between status bits and thread bits. It is actually used for shift operations such as status variables. Here is integer sixze-3=32-3=29.
Capability indicates the maximum CAPACITY of ThreadPoolExecutor. As can be seen from the figure below, after the shift operation, the last 29 bits of an int value reach the maximum value: all are 1. These 29 bits represent the number of active threads. When all are 1, it indicates that the maximum number of threads that the ThreadPoolExecutor can accommodate is reached. The first three bits are 0, which means that the variable is only related to the number of active threads and has nothing to do with the status. This is also to facilitate subsequent bit operations.
RUNNING, SHUTDOWN, STOP, TIDYING and TERMINATED represent the five states of ThreadPoolExecutor. The executable operations corresponding to these five states are as follows:
RUNNING: it can receive new tasks and continuously handle the tasks in the blocking queue.
SHUTDOWN: cannot receive new tasks, but can continue to process tasks in the blocking queue.
STOP: no new tasks can be received. Interrupt and block all tasks in the queue.
TIDYING: all tasks are terminated directly and all threads are cleared.
TERMINATED: thread pool is closed.
The calculation process of these five states is shown in the figure below. After shift calculation, the last 29 bits of the value are all 0, and the first 3 bits represent different states respectively.

After the above variable definition, the ThreadPoolExecutor separates the state from the number of threads and sets them on different consecutive bits of an int value, which also brings great convenience to the following operations.
Next, let's take a look at how the ThreadPoolExecutor obtains the state and the number of threads.
3.1. runStateOf(c) method
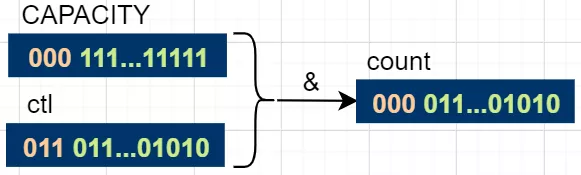
private static int runStateOf(int c) {
return c & ~CAPACITY;
}The runstateof () method is used to get the thread pool state. The formal parameter c is generally a ctl variable, including the state and the number of threads. The runStateOf() shift calculation process is shown in the following figure.

After the capability is reversed, the upper three positions are 1 and the lower 29 positions are 0. The inverse value and ctl are used for 'and' operation. Since any value 'and' 1 is equal to the original value, 'and' 0 is equal to 0. Therefore, after the 'and' operation, the upper 3 bits of ctl retain the original value and the lower 29 position is 0. This separates the state values from the ctl.
3.2 workerCountOf(c) method
private static int workerCountOf(int c) {
return c & CAPACITY;
}The analysis idea of workerCountOf(c) method is similar to the above, that is, separating the last 29 bits from ctl to obtain the number of active threads. As shown in the figure below, it will not be repeated here.
3.3. ctlOf(rs, wc) method
private static int ctlOf(int rs, int wc) {
return rs | wc;
}ctlOf(rs, wc) calculates the ctl value through the status value and thread value. rs is the abbreviation of runState and wc is the abbreviation of workerCount. The last 29 bits of rs and the first three bits of wc are 0. The final values calculated by the or operation retain the first 3 bits of rs and the last 29 bits of wc, i.e. ctl value.
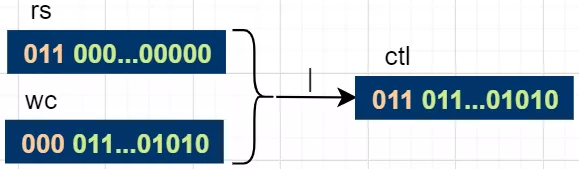
There are other ctl operation methods in ThreadPoolExecutor. The analysis ideas are similar to those above. If you are interested, you can have a look for yourself.
At the end of this summary, let's take a look at the way of state transition of ThreadPoolExecutor, which can also be understood as life cycle.
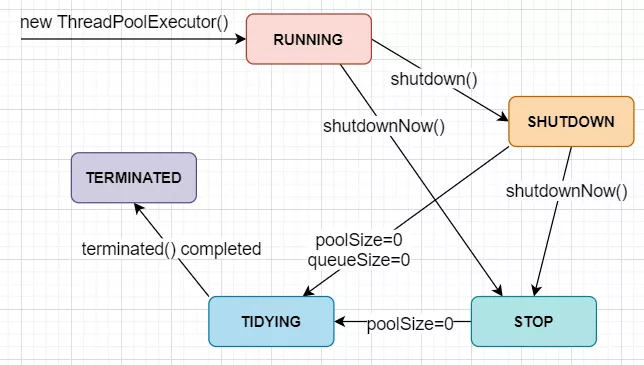
4, execute() execution process
4.1 execute method
The source code of execute() is as follows:
public void execute(Runnable command) {
// If the task to be executed is null, a null pointer exception is returned directly. If there are no tasks, the following steps are not necessary.
if (command == null) throw new NullPointerException();
// Get the value of ctl, ctl = (runState + workerCount)
int c = ctl.get();
// If workercount < number of core threads
if (workerCountOf(c) < corePoolSize) {
// Execute the addWorker method. The addWorker() method will be analyzed in detail below, which can be simply understood as adding a worker thread to process a task. true here means adding worker threads when the number is less than the number of core threads, that is, adding core threads.
if (addWorker(command, true))
// If it is added successfully, it will be returned directly
return;
// Failed to add. Retrieve the ctl value to prevent the state from changing when adding a worker
c = ctl.get();
}
// Running here indicates that the number of core threads is full, so the second parameter in addWorker below is false. Judge whether the thread pool is running. If so, try to add the task to the task queue
if (isRunning(c) && workQueue.offer(command)) {
// Get the ctl value again and perform double check
int recheck = ctl.get();
// If the thread pool is not running, an attempt is made to remove the task from the task queue
if (! isRunning(recheck) && remove(command))
// Execute reject policy after successful removal
reject(command);
// If the thread pool is running, or the removal task fails
else if (workerCountOf(recheck) == 0)
// Execute the addWorker method. At this time, non core threads are added (idle threads with survival time)
addWorker(null, false);
}
// If the thread pool is not running, or the task queue fails to add a task, try the addWorker() method again
else if (!addWorker(command, false))
// addWorker() failed, execute reject policy
reject(command);
}For source code analysis, just look at the comments directly. There are comments in each line. It is often gray and often detailed.
It can be seen from the source code that the execute() method mainly encapsulates the judgment logic of ThreadPoolExecutor to create threads, the creation timing of core threads and idle threads, and the execution timing of rejection policy. Here, the above source code is summarized through the following flow chart.
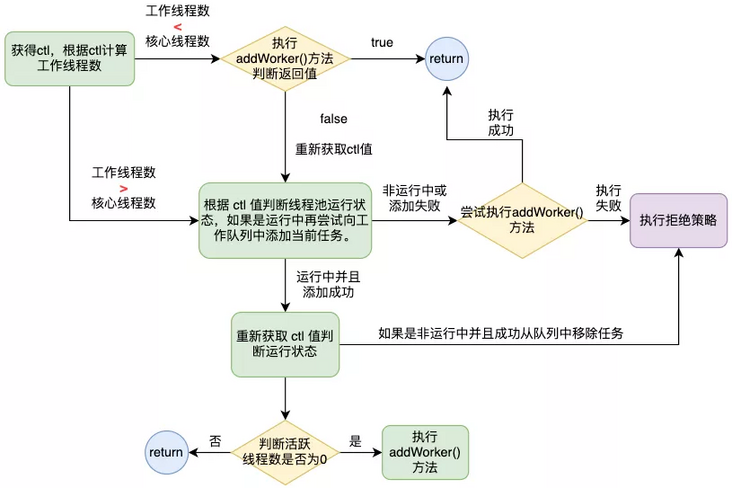
By creating a thread to execute the submitted task, the logic is encapsulated in the addWorker() method. In the next section, we will analyze the specific logic of executing the submitted task. There are several other methods in the execute() method, which are described here.
3.1.1 workerCountOf()
Getting the number of active threads from ctl is described in the second section.
3.1.2 isRunning()
private static boolean isRunning(int c) {
return c < SHUTDOWN;
}Judge whether the ThreadPoolExecutor is running according to the ctl value. Directly judge whether ctl < shutdown is true in the source code, because the highest bit of ctl in the running state is 1, which must be negative; The highest bit of other states is 0, which must be a positive number. Therefore, judging the size of ctl can judge whether it is in running state.
3.1.3 reject()
final void reject(Runnable command) {
handler.rejectedExecution(command, this);
}Directly call the rejectedExecution() method of the RejectedExecutionHandler interface during initialization. This is also the use of a typical policy pattern. The real reject operation is encapsulated in an implementation class that implements the RejectedExecutionHandler interface. There is no expansion here.
4.2 addWorker method
The source code of addWorker() is analyzed as follows:
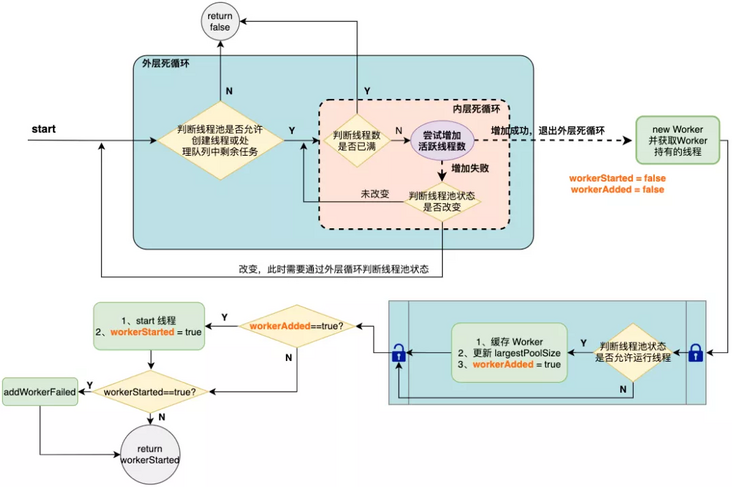
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
// Loop execution logic. Ensure that the loop exits under the expected conditions in a multithreaded environment.
for (;;) {
// Get the ctl value and extract the thread pool running state from it
int c = ctl.get();
int rs = runStateOf(c);
// If RS > shutdown, it is not allowed to receive new tasks or execute tasks in the work queue. Return to fasle directly.
// If rs == SHUTDOWN, the task is null and the work queue is not empty, then follow the logic of 'executing tasks in the work queue' below.
// The reason for setting firstTask == null here is that when the thread pool is in SHUTDOWN state, new tasks are not allowed to be added, and only the remaining tasks in the work queue are allowed to be executed.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
// Gets the number of active threads
int wc = workerCountOf(c);
// If the number of active threads > = capacity, new tasks are not allowed to be added
// If core is true, it means that a core thread is created. If the number of active threads > the number of core threads, it is not allowed to create threads
// If the core is false, idle threads are created. If the number of active threads > the maximum number of threads, threads are not allowed to be created
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// Try to increase the number of core threads. If successful, directly interrupt the outermost loop and start creating worker threads
// If the increase fails, the in loop logic will continue to be executed
if (compareAndIncrementWorkerCount(c))
break retry;
// Obtain the ctl value and judge whether the running state has changed
c = ctl.get();
// If the running state has changed, re execute the outer loop from
// If the running state does not change, continue to execute the inner loop
if (runStateOf(c) != rs)
continue retry;
}
}
// Used to record the status of worker threads
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// New a new worker thread. Each worker holds the thread that actually executes the task.
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
// Lock to ensure the atomicity of workerAdded state change
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Get thread pool status
int rs = runStateOf(ctl.get());
// If it is running, a worker thread is created
// If it is in SHUTDOWN state and firstTask == null, a thread will be created to execute the task in the task queue.
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
// Throw an exception if the thread has already run before it is started
if (t.isAlive())
throw new IllegalThreadStateException();
// Locally cached worker thread
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
// The worker thread was added successfully and changed to true
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// Start the worker thread after changing the status successfully
if (workerAdded) {
// Start worker thread
t.start();
// Change startup status
workerStarted = true;
}
}
} finally {
// If the worker thread state does not change, the processing fails
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}addWorker() judges the running status of ThreadPoolExecutor through internal and external dead loops, and successfully updates the number of active threads through CAS. This is to ensure that multiple threads in the thread pool can exit the loop according to the expected conditions in a concurrent environment.
The method then creates a new Worker and starts the Worker's built-in Worker thread. Here, judge whether the Worker has been successfully cached and started through the two states of workerAdded and workerStarted.
Modifying the workerAdded process will use the mainlock lock lock of ThreadPoolExecutor to ensure atomicity and prevent unexpected situations in the two processes of adding data to workers and obtaining the number of workers in a multi-threaded concurrent environment.
addWorker() starts the worker thread by first creating a new worker object, then obtaining the worker thread from it, and then starting. Therefore, the real thread startup process is still in the worker object.
Here is a flowchart to summarize addWorker:
addWorker also has several methods to analyze here:
4.2.1 runStateOf()
Get the ThreadPoolExecutor status from ctl. See Chapter 2 for detailed analysis.
4.2.2 workerCountOf()
Get the number of active threads of ThreadPoolExecutor from ctl. See Chapter 2 for detailed analysis.
4.2.3 compareAndIncrementWorkerCount()
int c = ctl.get();
if (compareAndIncrementWorkerCount(c)) {...}
private boolean compareAndIncrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect + 1);
}Make the number of active threads in ctl + 1 through CAS. Here, why can you change the number of threads just by making the ctl value + 1? Because the value of ctl threads is stored in the last 29 bits, without overflow, + 1 will only affect the value of the last 29 bits and only make the number of threads + 1. It does not affect the thread pool state.
4.2.4 addWorkerFailed()
private void addWorkerFailed(Worker w) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (w != null)
// Remove worker
workers.remove(w);
// Number of active threads - 1
decrementWorkerCount();
// Attempt to stop thread pool
tryTerminate();
} finally {
mainLock.unlock();
}
}
private void decrementWorkerCount() {
do {} while (! compareAndDecrementWorkerCount(ctl.get()));
}This method is executed after the worker thread fails to start. Under what circumstances will this problem occur? After successfully increasing the number of active threads and successfully new Worker, the thread pool status changes to > shutdown, which can neither accept new tasks nor execute the remaining tasks in the task queue. At this time, the thread pool should be stopped directly.
This method is in this case:
- Remove the newly created Worker from the workers cache pool;
- Ensure that the number of active threads is reduced by 1 through dead loop + CAS;
- Execute the tryTerminate() method to try to stop the thread pool.
After the tryTerminate() method is executed, the thread pool will enter the {TERMINATED state.
4.2.5 tryTerminate()
final void tryTerminate() {
for (;;) {
int c = ctl.get();
// If the current thread pool state is one of the following, it cannot directly enter the TERMINATED state. A direct return of false indicates that the attempt failed
if (isRunning(c) || runStateAtLeast(c, TIDYING) ||
(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))
return;
// If the number of active threads is not 0, all Worker threads will be interrupted. This will be explained in detail below. This will be related to the reason why the Worker inherits the AQS but does not use the CLH inside.
if (workerCountOf(c) != 0) {
interruptIdleWorkers(ONLY_ONE);
return;
}
// Add global lock
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// First, change ctl to (rs=TIDYING, wc=0) through CAS, because the above judgment ensures that the current thread pool can reach this state.
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
// Hook function, users can implement customized methods by inheriting ThreadPoolExecutor.
terminated();
} finally {
// Change ctl to (rs=TERMINATED, wc=0), and the thread pool will be closed.
ctl.set(ctlOf(TERMINATED, 0));
// Wake up other threads. In fact, it is useless to wake up. After other threads wake up, they will exit after judging that the thread pool is TERMINATED.
termination.signalAll();
}
return;
}
} finally {
// Release global lock
mainLock.unlock();
}
}
}5, Worker built-in class analysis
5.1 Worker object analysis
Source code analysis of Worker object:
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
// Worker thread
final Thread thread;
// Pending tasks submitted
Runnable firstTask;
// Number of tasks completed
volatile long completedTasks;
Worker(Runnable firstTask) {
// Initialization status
setState(-1);
this.firstTask = firstTask;
// Creating threads through a thread factory
this.thread = getThreadFactory().newThread(this);
}
// The method for executing the task submission. The specific execution logic is encapsulated in runWorker(). After t.start() in addWorker(), the method will be executed
public void run() {
runWorker(this);
}
// Some methods of implementing AQS
protected boolean isHeldExclusively() { ... }
protected boolean tryAcquire(int unused) { ... }
protected boolean tryRelease(int unused) { ... }
public void lock() { ... }
public boolean tryLock() { ... }
public void unlock() { ... }
public boolean isLocked() { ... }
// Interrupt held thread
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try { t.interrupt(); }
catch (SecurityException ignore) {}
}
}
}From the above source code, we can see that the worker implements the Runnable interface, which shows that the worker is a task; Worker also inherits AQS, which indicates that worker has the nature of lock at the same time, but worker does not use CLH function like ReentrantLock and other locking tools, because there is no scenario where multiple threads access the same worker in the thread pool. Here, only the function of state maintenance in AQS is used, which will be described in detail below.
Each Worker object will hold a Worker thread. When the Worker is initialized, it will create the Worker thread through the thread factory and pass itself into the Worker thread as a task. Therefore, the running of tasks in the thread pool does not directly execute the run() method of submitting tasks, but executes the run() method in the Worker, and then executes the run() method of submitting tasks in this method.
The run() method in Worker is delegated to runWorker() in ThreadPoolExecutor to execute specific logic.
Here is a diagram to summarize:
- The Worker itself is a task and holds the tasks and Worker threads submitted by the user.
- The task held by the worker thread is this itself, so calling the start() method of the worker thread is actually executing the run() method of this itself.
- The run() of this itself delegates the global runWorker() method to execute specific logic.
- The run() method in the runWorker() method executes the task submitted by the user and executes the user's specific logic.
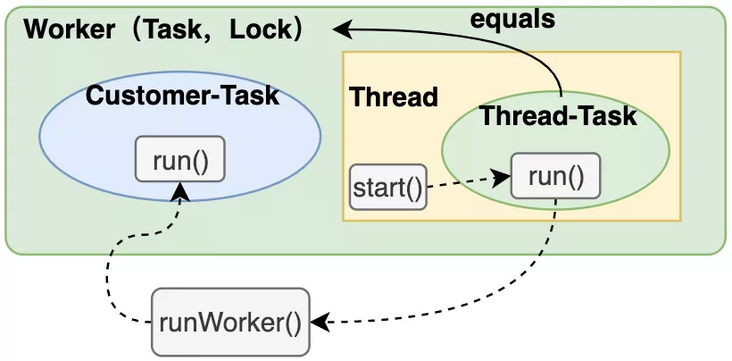
5.2 runWorker method
The source code of runWorker() is as follows:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
// Copy the submitted task and set the firstTask in the Worker to null for the next reassignment.
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock();
boolean completedAbruptly = true;
try {
// After the holding task is executed, the task is continuously obtained from the task queue through getTask()
while (task != null || (task = getTask()) != null) {
w.lock();
try {
// The hook function of ThreadPoolExecutor. Users can implement ThreadPoolExecutor and override beforeExecute() method to complete user-defined operation logic before task execution.
beforeExecute(wt, task);
Throwable thrown = null;
try {
// Execute the run() method of the submitted task
task.run();
} catch (RuntimeException x) {
...
} finally {
// The hook function of ThreadPoolExecutor is the same as beforeExecute, but it is executed after the task is executed.
afterExecute(task, thrown);
}
} finally {
// Easy task recovery
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
// This indicates that there are no tasks in the task queue or the thread pool is closed. In this case, the worker needs to be flushed from the cache
processWorkerExit(w, completedAbruptly);
}
}runWorker() is the method that actually performs the submitted task, but it does not pass thread The start () method executes the task, but the run() method that executes the task directly.
runWorker() will continuously get the task from the task queue and execute it.
runWorker() provides two hook functions. If the ThreadPoolExecutor of jdk cannot meet the needs of developers, developers can inherit the ThreadPoolExecutor and override the beforeExecute() and afterExecute() methods to customize the logic to be executed before task execution. For example, set some monitoring indicators or print logs.
5.2.1 getTask()
private Runnable getTask() {
boolean timedOut = false;
// The dead loop ensures that the task is obtained
for (;;) {
...
try {
// Get task from task queue
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}5.2.2 processWorkerExit()
private void processWorkerExit(Worker w, boolean completedAbruptly) {
...
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
// Remove worker from cache
workers.remove(w);
} finally {
mainLock.unlock();
}
// Attempt to stop thread pool
tryTerminate();
...
}6, shutdown() execution process
Thread pool has two active shutdown methods;
shutdown(): close all idle Worker threads in the thread pool and change the thread pool status to SHUTDOWN;
Shutdown now(): close all Worker threads in the thread pool, change the thread pool status to STOP, and return a list of all tasks waiting to be processed.
Why should Worker threads be divided into idle and non idle?
From the above runWorker() method, we know that the worker thread will ideally continuously obtain and execute tasks from the task queue in the while loop. At this time, the worker thread is not idle; Worker threads that are not executing tasks are idle. Because the SHUTDOWN state of the thread pool does not allow new tasks to be received and only the remaining tasks in the task queue are allowed to be executed, all idle worker threads need to be interrupted, and non idle threads continue to execute the tasks in the task queue until the queue is empty. The STOP state of the thread pool does not allow new tasks to be accepted or the remaining tasks to be executed. Therefore, it is necessary to close all worker threads, including those running.
6.1 shutdown()
The source code of shutdown() is as follows:
public void shutdown() {
// Global lock on
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Check whether there are permissions related to the closed thread pool. Here, mainly check the "modifyThread" permissions of the current thread and each Worker thread through the SecurityManager
checkShutdownAccess();
// Modify thread pool status
advanceRunState(SHUTDOWN);
// Close all idle threads
interruptIdleWorkers();
// Hook function. Users can inherit ThreadPoolExecutor and implement custom hooks. ScheduledThreadPoolExecutor implements its own hook function
onShutdown();
} finally {
mainLock.unlock();
}
// Attempt to close thread pool
tryTerminate();
}shutdown() encapsulates the closing steps of ThreadPoolExecutor in several methods, and ensures that only one thread can actively close ThreadPoolExecutor through global lock. ThreadPoolExecutor also provides a hook function onShutdown() to allow developers to customize the shutdown process. For example, the ScheduledThreadPoolExecutor cleans up the task queue when it is closed.
The methods are analyzed below.
checkShutdownAccess()
private static final RuntimePermission shutdownPerm = new RuntimePermission("modifyThread");
private void checkShutdownAccess() {
SecurityManager security = System.getSecurityManager();
if (security != null) {
// Verify the permissions of the current thread. Shutdown perm is a RuntimePermission object with modifyThread parameter.
security.checkPermission(shutdownPerm);
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers)
// Verify that all worker threads have modifyThread permission
security.checkAccess(w.thread);
} finally {
mainLock.unlock();
}
}
}advanceRunState()
// targetState = SHUTDOWN
private void advanceRunState(int targetState) {
for (;;) {
int c = ctl.get();
// Judge whether the current thread pool state > = shutdown is true. If not, modify it through CAS
if (runStateAtLeast(c, targetState) ||
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))))
break;
}
}
private static boolean runStateAtLeast(int c, int s) {
return c >= s;
}In this method, the skill of front-line process pool state definition is also used to judge whether the line current process pool state > = shutdown is true. For other states that are not in operation, they are positive numbers, and the upper three digits are different, TERMINATED (011) > tidying (010) > stop (001) > shutdown (000), and the size of the upper three bits depends on the size of the whole number. Therefore, for different states, regardless of the number of active threads, the state of the thread pool always determines the size of the ctl value. That is, the ctl value in TERMINATED state > the ctl value in tidying state is always true.
interruptIdleWorkers()
private void interruptIdleWorkers() {
interruptIdleWorkers(false);
}
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers) {
Thread t = w.thread;
// Judge whether the worker thread has been marked as interrupted. If not, try to obtain the lock of the worker thread
if (!t.isInterrupted() && w.tryLock()) {
try {
// Interrupt thread
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
// If onlyOne is true, at most one thread can be interrupted
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}The just method will try to obtain the Worker's lock, and the thread will be interrupted only if the acquisition is successful. This is also related to the fact that although the Worker inherits AQS but does not use CLH, it will be analyzed later.
The tryTerminate() method has been analyzed earlier, but it is not described here.
6.2 shutdownNow()
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Verify the permission to close the thread pool
checkShutdownAccess();
// Modify the thread pool status to STOP
advanceRunState(STOP);
// Interrupt all threads
interruptWorkers();
// Gets the list of all tasks waiting to be processed in the queue
tasks = drainQueue();
} finally {
mainLock.unlock();
}
// Attempt to close thread pool
tryTerminate();
// Return to task list
return tasks;
}This method is similar to shutdown(). The core steps are encapsulated in several methods, among which checkshutdown access () and advanceRunState() are the same. Different methods are described below
interruptWorkers()
private void interruptWorkers() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Traverse all workers and interrupt them as soon as they are started
for (Worker w : workers)
w.interruptIfStarted();
} finally {
mainLock.unlock();
}
}
void interruptIfStarted() {
Thread t;
// State > = 0 means that the worker has been started. If the worker starts and the holding thread is not null and the holding thread is not marked as interrupted, the thread will be interrupted
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}This method does not attempt to obtain the Worker's lock, but directly interrupts the thread. Because the thread pool in the STOP state does not allow processing of tasks waiting in the task queue.
drainQueue()
// Add the tasks in the task queue to the list and return. Usually, drainTo() is used. However, if the queue is a delay queue or other tasks cannot be transferred through the drainTo() method, the transfer can be carried out through circular traversal
private List<Runnable> drainQueue() {
...
}7, Why workers inherit AQS
First, let's talk about the conclusion - Worker inherits AQS to use the function of state management, and does not use the nature of CLH in AQS like ReentrantLock.
Let's take a look at the AQS related methods in Worker:
// The parameter is unused. You can also know from the naming that the parameter is not used
protected boolean tryAcquire(int unused) {
// Change the status from 0 to 1 through CAS change
if (compareAndSetState(0, 1)) {
// Set current thread exclusive
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
// This method is only used in runWorker()
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }tryAcquire in Worker only changes the state to 1, but the parameter is not used. Therefore, we can conclude that the state in Worker may take the value of (0, 1). Initialization state - 1 is not considered here to avoid confusion.
Look at the lock() method. The only place where the lock() method is called is before the Worker thread is started in runWorker(). runWorker() is called through run() in the Worker. As a task, the Worker is only passed to the Worker thread held by itself. Therefore, the run() method in the Worker can only be called by the Worker thread held by itself through start(). Therefore, runWorker() will only be called by the Worker thread held by the Worker itself, and the lock() method will only be called by a single thread. There is no case that multiple threads compete for the same lock, That is, there is no case that only one thread can obtain a lock in a multithreaded environment, resulting in other waiting threads being added to the CLH queue. Therefore, the Worker does not use the function of CLH.
This is a good indication that the tryAcquire() method does not use the passed parameters, because there are only two states for the Worker, either locked (non idle, state=1) or unlocked (idle, state=0). There is no need to set other states by passing parameters.
final void runWorker(Worker w) {
...
try {
while (task != null || (task = getTask()) != null) {
// The only place called
w.lock();
...
}
}
}The above analysis shows that the Worker does not use the CLH function of AQS. So how does Worker use the function of state management?
In the shutdown() method that closes the thread pool, one step is to interrupt all idle Worker threads. Before interrupting all Worker threads, it will judge whether the Worker thread can obtain the lock. It will judge whether the Worker's state is 0 through trylock() - > tryacquire(). Only the Worker who can obtain the lock will be interrupted, and the Worker who can obtain the lock is an idle Worker (state=0). The Worker table name that cannot obtain the lock has executed the lock() method, At this time, the Worker keeps getting the task execution of the blocking queue in the While loop, which cannot be interrupted in the shutdown() method.
private void interruptIdleWorkers(boolean onlyOne) {
...
try {
for (Worker w : workers) {
Thread t = w.thread;
if (!t.isInterrupted() && w.tryLock()) { ... }
}
}
}Therefore, the status management of a Worker actually determines whether the Worker is idle through the value of state (0 or 1). If it is idle, it can be interrupted when the process pool is closed. Otherwise, it has to obtain and execute the tasks in the blocking queue in the while loop until the tasks in the queue are empty. As shown in the following figure:
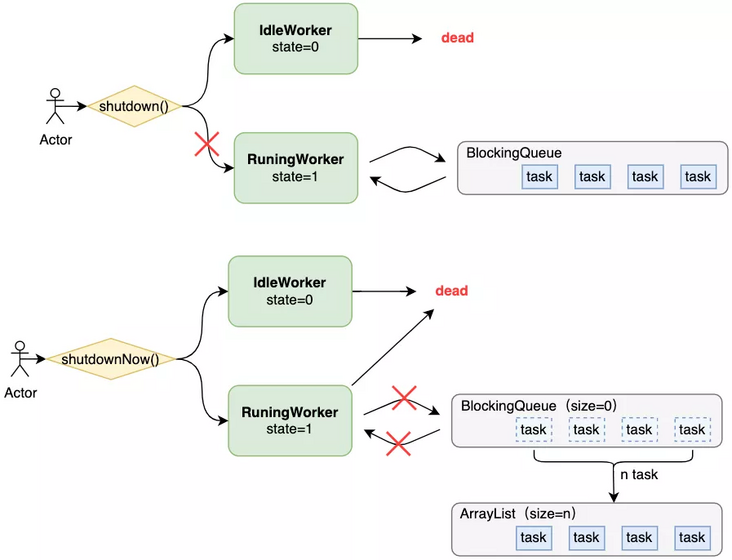
8, Reject policy
This chapter only discusses the four rejection policy handler s built into ThreadPoolExecutor.
8.1 CallerRunsPolicy
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
// If the thread pool is not closed, execute the task directly in the current thread
if (!e.isShutdown()) {
r.run();
}
}
}Execute the rejected task directly in the calling thread. As long as the thread pool is RUNNING, the task is still executed. If it is in the non RUNNING state, the task will be directly ignored, which is also in line with the behavior of the thread pool state.
8.2 AbortPolicy
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
// Throw reject exception
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}After the task is rejected, a reject exception is thrown directly.
8.3 DiscardPolicy
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() { }
// Empty method, nothing is executed
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}Abandon the task. If the reject method is empty, it means that nothing will be executed, which is equivalent to discarding the task.
8.4 DiscardOldestPolicy
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
// Get (remove) the task of the queue head from the blocking queue,
e.getQueue().poll();
// Try to execute the current task again
e.execute(r);
}
}
}Remove the earliest task in the blocking queue (queue head), and then try to execute() method again to queue the current task. This is a typical strategy of liking the new and hating the old.
9, Secondary development practice of ThreadPoolExecutor
After introducing the core principle of ThreadPoolExecutor, let's take a look at how vivo's self-developed NexTask concurrency framework plays with the thread pool and improves the development speed and code execution speed of business personnel.
NexTask abstracts common business patterns, algorithms and scenarios and implements them in the form of components. It provides a fast, lightweight, easy-to-use and shielding the underlying technical details, which can enable developers to write concurrent programs quickly and enable development to a greater extent.
Firstly, the NexTask architecture diagram is given, and then we analyze in detail where ThreadPoolExecutor is used in the architecture diagram.
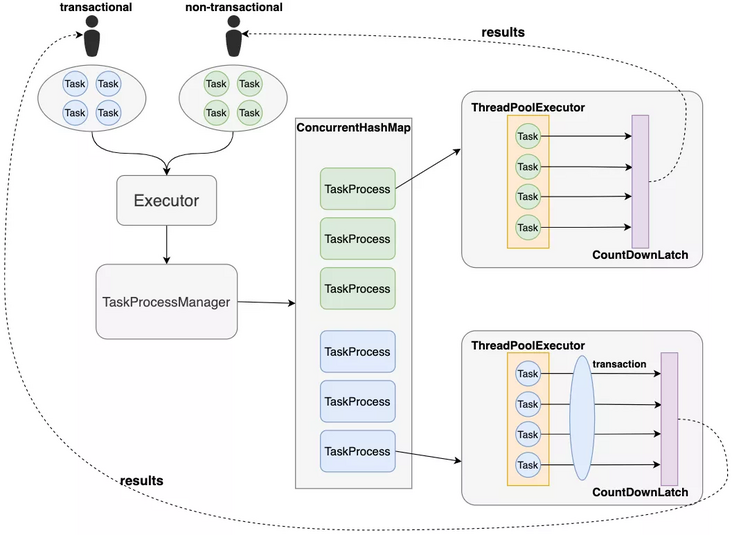
// Executor part code:
public class Executor {
...
private static DefaultTaskProcessFactory taskProcessFactory =
new DefaultTaskProcessFactory();
// The API provided externally enables users to quickly create task processors
public static TaskProcess getCommonTaskProcess(String name) {
return TaskProcessManager.getTaskProcess(name, taskProcessFactory);
}
public static TaskProcess getTransactionalTaskProcess(String name) {
return TaskProcessManager.getTaskProcessTransactional(name, taskProcessFactory);
}
...
}Executor is an external interface. Developers can use its simple and easy-to-use API to quickly create task processor TaskProcess through task manager TaskProcessManager.
// TaskProcessManager part code:
public class TaskProcessManager {
// Cache map, < service name, task processor for the service >
private static Map<String, TaskProcess> taskProcessContainer =
new ConcurrentHashMap<String, TaskProcess>();
...
}TaskProcessManager # holds a task processor locally cached in ConcurrentHashMap, and each task processor is mapped one by one with a specific business name. When obtaining the task processor, the specific business name is obtained from the cache, which can not only ensure the isolation of task processing between businesses, but also prevent resource loss caused by multiple creation and destruction of thread pools.
// TaskProcess part code:
public class TaskProcess {
// Thread pool
private ExecutorService executor;
// Thread pool initialization
private void createThreadPool() {
executor = new ThreadPoolExecutor(coreSize, poolSize, 60, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(2048), new DefaultThreadFactory(domain),
new ThreadPoolExecutor.AbortPolicy());
}
// Multithreading submits tasks for processing
public <T> List<T> executeTask(List<TaskAction<T>> tasks) {
int size = tasks.size();
// Create a CountDownLatch with the same number of tasks to ensure that all tasks are processed and the results are returned together
final CountDownLatch latch = new CountDownLatch(size);
// Return result initialization
List<Future<T>> futures = new ArrayList<Future<T>>(size);
List<T> resultList = new ArrayList<T>(size);
// Traverse all tasks and submit to the thread pool
for (final TaskAction<T> runnable : tasks) {
Future<T> future = executor.submit(new Callable<T>() {
@Override
public T call() throws Exception {
// Handling specific task logic
try { return runnable.doInAction(); }
// After processing, CountDownLatch - 1
finally { latch.countDown(); }
}
});
futures.add(future);
}
try {
// Wait until all tasks are processed
latch.await(50, TimeUnit.SECONDS);
} catch (Exception e) {
log.info("Executing Task is interrupt.");
}
// Encapsulate the result and return
for (Future<T> future : futures) {
try {
T result = future.get();// wait
if (result != null) {
resultList.add(result);
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
return resultList;
}
...
}Each TaskProcess holds a thread pool. As can be seen from the initialization process of the thread pool, the TaskProcess adopts a bounded blocking queue, which stores up to 2048 tasks. Once this number is exceeded, it will directly refuse to receive tasks and throw a rejection exception.
TaskProcess will traverse the task list submitted by the user and submit it to the thread pool for processing through the submit() method. The underlying layer of submit() is actually the called ThreadPoolExecutor#execute() method, but it will encapsulate the task into RunnableFuture before calling. Here is the content of the FutureTask framework and will not be expanded.
TaskProcess will create a CountDownLatch every time a task is processed, and execute CountDownLatch after the task is completed Countdown(), which can ensure that all tasks block the current thread after execution until all tasks are processed, and the results are obtained and returned uniformly.
10, Summary
Although JDK provides developers with Executors tool classes and a variety of built-in thread pools, the use of those thread pools is very limited and can not meet increasingly complex business scenarios. Alibaba's official programming protocol also recommends that developers do not directly use the thread pool provided by JDK, but create thread pools through ThreadPoolExecutor according to their own business scenarios. Therefore, understanding the internal principle of ThreadPoolExecutor is also very important to skillfully use thread pool in daily development.
This paper mainly explores the internal core principle of ThreadPoolExecutor, introduces its construction method and the detailed significance of each construction parameter, as well as the transformation method of thread pool core ctl parameters. Then I spent a lot of time on the source code of ThreadPoolExecutor, introducing the startup and shutdown process of thread pool, the core built-in class Worker, etc. ThreadPoolExecutor has other methods, which are not introduced in this article. Readers can read other source codes on the basis of reading this article. I believe it will be helpful.
Author: vivo Internet server team Xu Weiteng