torchvision:
torchvision is a computer vision toolkit in pytorch
Three main modules:
1) transforms module: provide common image preprocessing methods
2) datasets: datasets that provide commonly used public datasets
3) model: Provides a large number of commonly used pre-training models

transforms
Pictures are enhanced to improve model generalization

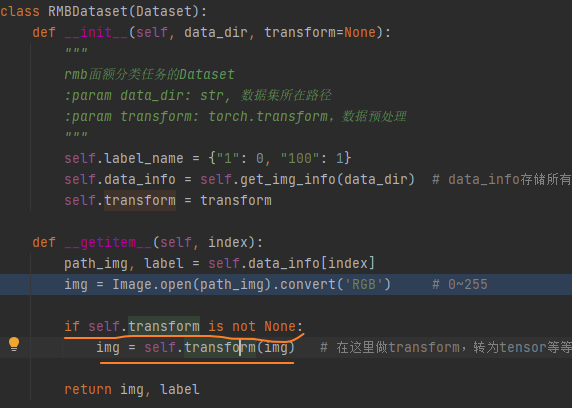
transforms are u in the dataset getitem_u Called in
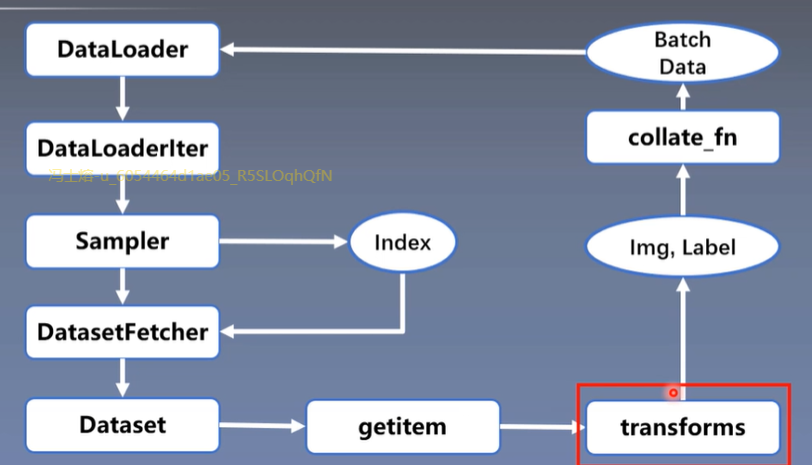
transforms.Normalize: Compare common preprocessing methods
Standardize images channel by channel
Normalize in transforms actually uses normalize in function
Reason: Standardizing data can speed up model convergence
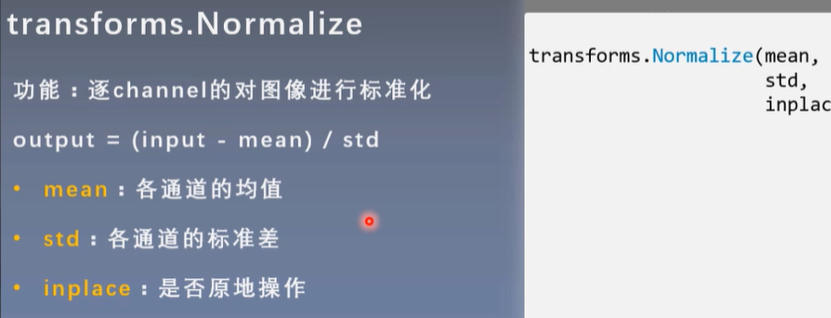
Standardizing the data accelerates the convergence of the model, normalizing the data to a mean of 0 and a standard deviation of 1.
When the data distribution is nearly zero mean, the model can converge quickly to a very low loss value.
When the data mean is not near 0 and the model initialization is all 0 mean, the boundary plane is found slowly and the iteration update process is slow.
Data Enhancement:
Data enhancement, also known as data augmentation, data augmentation, transforms the training set to enrich it, thereby improving the generalization ability of the model
Crop
1.transforms. CenterCrop (clipped from the center of the image)

Transform_ The invert function is an inverse operation of transformation, which allows us to see what the data entered by the model is like (because after data is transformed, it is converted into a tensor, which may be floating-point data, and cannot be visualized, so transform_invert is required to reverse the transformation and convert the data of the tensor to PILimage, so we can visualize it)
def transform_invert(img_, transform_train):
"""
take data Reverse transfrom operation
:param img_: tensor
:param transform_train: torchvision.transforms
:return: PIL image
"""
if 'Normalize' in str(transform_train):
norm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize), transform_train.transforms))
mean = torch.tensor(norm_transform[0].mean, dtype=img_.dtype, device=img_.device)
std = torch.tensor(norm_transform[0].std, dtype=img_.dtype, device=img_.device)
img_.mul_(std[:, None, None]).add_(mean[:, None, None])
img_ = img_.transpose(0, 2).transpose(0, 1) # C*H*W --> H*W*C
if 'ToTensor' in str(transform_train) or img_.max() < 1:
img_ = img_.detach().numpy() * 255
if img_.shape[2] == 3:
img_ = Image.fromarray(img_.astype('uint8')).convert('RGB')
elif img_.shape[2] == 1:
img_ = Image.fromarray(img_.astype('uint8').squeeze())
else:
raise Exception("Invalid img shape, expected 1 or 3 in axis 2, but got {}!".format(img_.shape[2]) )
return img_
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader):
inputs, labels = data # B C H W
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform) # transform_invert is used to reverse transform so that we can see what the input data for the model looks like
plt.imshow(img)
plt.show()
plt.pause(0.5)
plt.close()
2.transforms. RandomCrop (Random Clipping)
The random position of the random values here is not necessarily clipped from the center, upper left, lower right, but from the random position


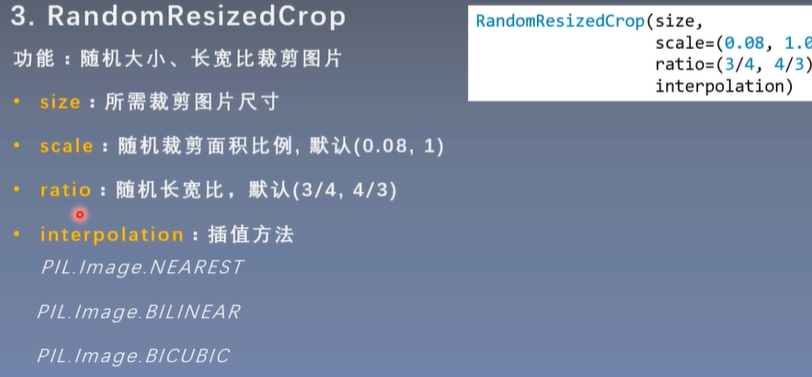
3.RandomResizedCrop
Interpolation method: (Interpolation is required because the clipped image may be smaller than the desired picture size)
NEAREST (nearest neighbor interpolation)
BILINEAR (bilinear interpolation)
BICUBIC (bicubic interpolation)
4.FiveCrop (cut 5 pictures from top left, bottom left, top right, bottom right and center)
5.TenCrop (10 pictures from 5 images just clipped mirrored horizontally or vertically)

Flip

rotation

Image transformation
1.Pad

2.ColorJitter
Usually used in image enhancement methods, especially natural images, may have some color bias

3.Grayscale
4.RandomGrayscale (adjustment of gray scale)
Grayscale is a special case of RandomGrayscale with a probability of 1

5.RadomAffine
Spatial geometric transformation of images


6. Obscure

7.transforms.Lambda
Since TenCrop returns a tuple, the input and output of transform are usually in the form of PILimage or tensor
crops is the output of TenCrop with a length of 10 tuple s, and each element is PILimage
transforms.Lambda returns a 4-dimensional tensor

Transform Operation
Selection operation on transform

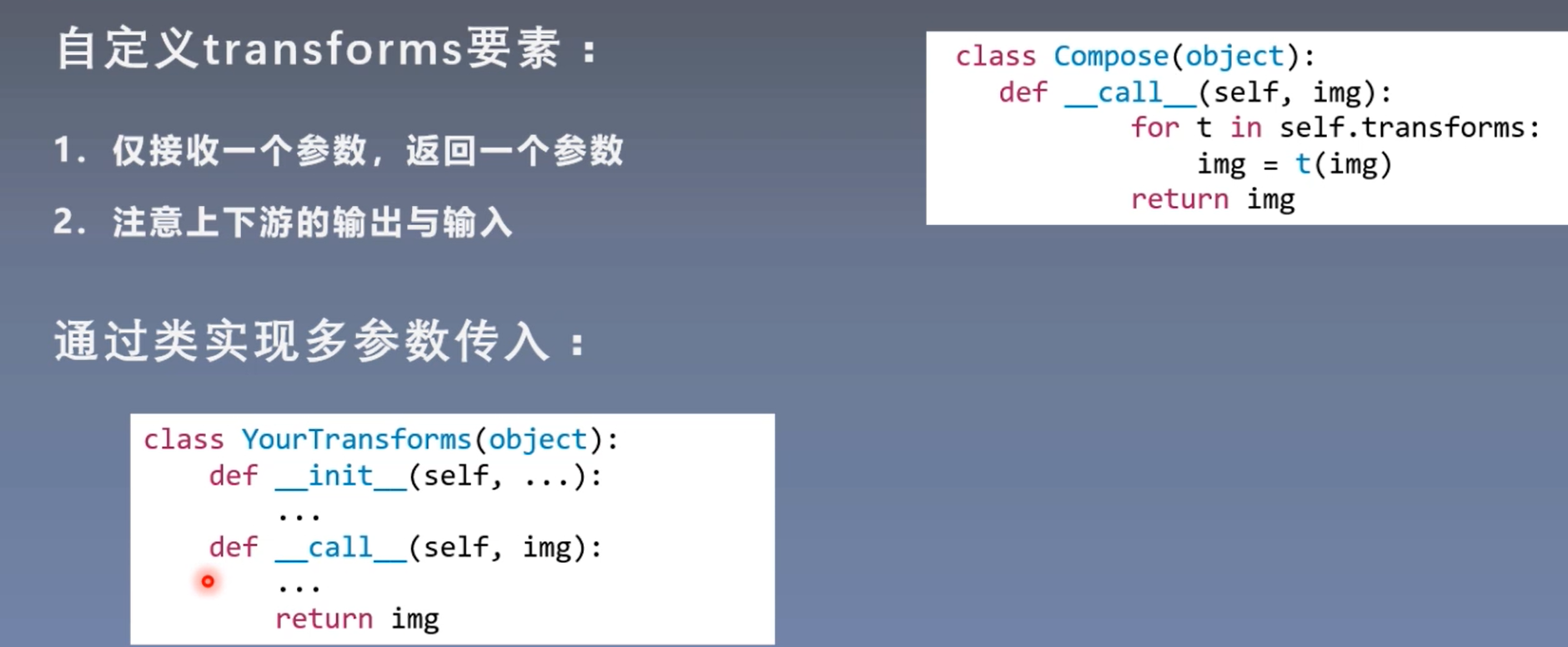
Custom transform method
call function: an instance of a class can be called


summary

