Recently, a domestic developer opened a crawler toolbox with many data sources on GitHub - InfoSpider, which became popular accidentally!!!
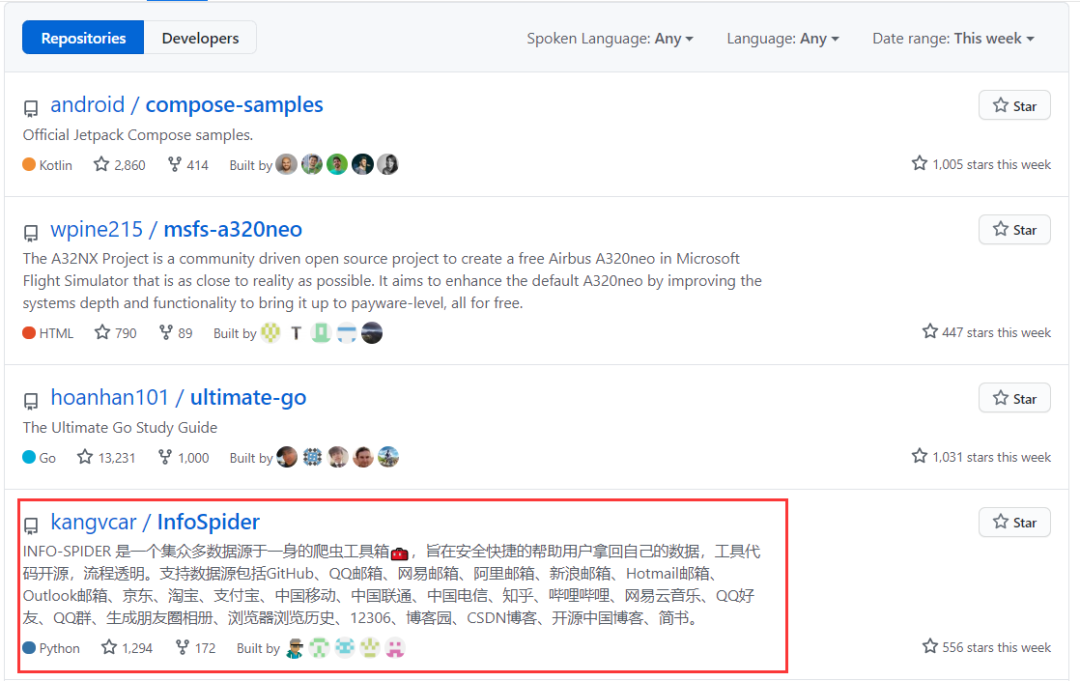
How hot is it? Within a few days, open source ranked fourth in GitHub's weekly list, with a standard star of 1.3K and a total of 172 branches. At the same time, the author has opened all the project codes and use documents, and there are video explanations on station B.
Project code: https://github.com/kangvcar/InfoSpider Project documents: https://infospider.vercel.app Project video presentation: https://www.bilibili.com/video/BV14f4y1R7oF/
In such an era of information explosion, everyone has many accounts. When there are many accounts, there will be such a situation: personal data is scattered among various companies, which will form a data island, and multidimensional data cannot be integrated. This project can help you integrate multidimensional data and analyze personal data, so that you can be more intuitive Learn more about yourself.
InfoSpider is a crawler toolbox that integrates many data sources. It aims to help users get back their data safely and quickly. The tool code is open-source and the process is transparent. It also provides data analysis function and generates chart files based on user data, so that users can have a more intuitive and in-depth understanding of their own information.

At present, it supports data sources including GitHub, QQ mailbox, NetEase mail box, Ali mailbox, Sina mailbox, Hotmail mailbox, Outlook mailbox, Jingdong, Taobao, Alipay, China Mobile, China Unicom, China Telecom, know, beep, Hotmail, QQ, group of friends, album of friends, browser history, 12306, blog, CSDN blog, Open source Chinese blogs and simple books.
According to the creator, InfoSpider has the following features:
- Safe and reliable: this project is an open source project. The code is simple, all source codes can be seen, local operation, safe and reliable.
- Easy to use: provide GUI interface, just click the data source to be obtained and operate according to the prompt.
- Clear structure: all data sources of the project are independent of each other and have high portability. All crawler scripts are under the Spiders file of the project.
- Rich data sources: the project currently supports up to 24 + data sources, which are continuously updated.
- Unified data format: all data crawled will be stored in json format to facilitate later data analysis.
- Rich personal data: this project will crawl as much personal data as possible for you, and the later data processing can be deleted as needed.
- Data analysis: this project provides visual analysis of personal data, which is only partially supported at present.
InfoSpider is also very simple to use. You only need to install Python 3 and Chrome browser and run Python 3 main Py, click the data source button in the open window, select the data saving path according to the prompt, and then enter the account password, the data will be automatically crawled, and the crawled data can be viewed according to the downloaded directory.
Of course, if you want to practice and learn crawlers by yourself, the author also open source all the crawler code, which is very suitable for actual combat.
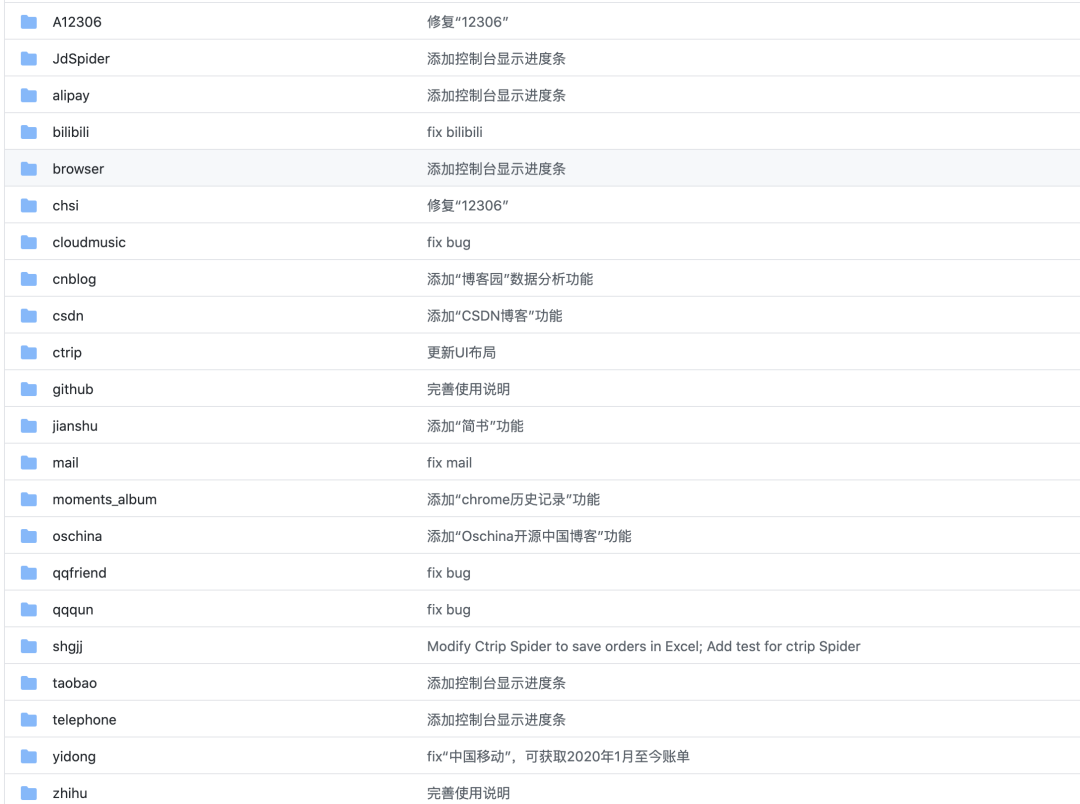
For example, climbing taobao:
import json
import random
import time
import sys
import os
import requests
import numpy as np
import math
from lxml import etree
from pyquery import PyQuery as pq
from selenium import webdriver
from selenium.webdriver import ChromeOptions
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver import ChromeOptions, ActionChains
from tkinter.filedialog import askdirectory
from tqdm import trange
def ease_out_quad(x):
return 1 - (1 - x) * (1 - x)
def ease_out_quart(x):
return 1 - pow(1 - x, 4)
def ease_out_expo(x):
if x == 1:
return 1
else:
return 1 - pow(2, -10 * x)
def get_tracks(distance, seconds, ease_func):
tracks = [0]
offsets = [0]
for t in np.arange(0.0, seconds, 0.1):
ease = globals()[ease_func]
offset = round(ease(t / seconds) * distance)
tracks.append(offset - offsets[-1])
offsets.append(offset)
return offsets, tracks
def drag_and_drop(browser, offset=26.5):
knob = browser.find_element_by_id('nc_1_n1z')
offsets, tracks = get_tracks(offset, 12, 'ease_out_expo')
ActionChains(browser).click_and_hold(knob).perform()
for x in tracks:
ActionChains(browser).move_by_offset(x, 0).perform()
ActionChains(browser).pause(0.5).release().perform()
def gen_session(cookie):
session = requests.session()
cookie_dict = {}
list = cookie.split(';')
for i in list:
try:
cookie_dict[i.split('=')[0]] = i.split('=')[1]
except IndexError:
cookie_dict[''] = i
requests.utils.add_dict_to_cookiejar(session.cookies, cookie_dict)
return session
class TaobaoSpider(object):
def __init__(self, cookies_list):
self.path = askdirectory(title='Select the information save folder')
if str(self.path) == "":
sys.exit(1)
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
}
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # Don't load pictures to speed up access
option.add_argument('--headless')
self.driver = webdriver.Chrome(options=option)
self.driver.get('https://i.taobao.com/my_taobao.htm')
for i in cookies_list:
self.driver.add_cookie(cookie_dict=i)
self.driver.get('https://i.taobao.com/my_taobao.htm')
self.wait = WebDriverWait(self.driver, 20) # The timeout duration is 10s
# Simulate sliding down browsing
def swipe_down(self, second):
for i in range(int(second / 0.1)):
# Simulate sliding up and down according to the value of i
if (i % 2 == 0):
js = "var q=document.documentElement.scrollTop=" + str(300 + 400 * i)
else:
js = "var q=document.documentElement.scrollTop=" + str(200 * i)
self.driver.execute_script(js)
time.sleep(0.1)
js = "var q=document.documentElement.scrollTop=100000"
self.driver.execute_script(js)
time.sleep(0.1)
# Crawl the baby product data I have bought on Taobao. pn defines how many pages of data to crawl
def crawl_good_buy_data(self, pn=3):
# Crawler the data of baby products I have bought
self.driver.get("https://buyertrade.taobao.com/trade/itemlist/list_bought_items.htm")
# Traverse all pages
for page in trange(1, pn):
data_list = []
# Wait until all the purchased baby product data on this page are loaded
good_total = self.wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#tp-bought-root > div.js-order-container')))
# Get the source code of this page
html = self.driver.page_source
# pq module parsing web page source code
doc = pq(html)
# # Store the baby data that has been bought on this page
good_items = doc('#tp-bought-root .js-order-container').items()
# Traverse all the pages
for item in good_items:
# Purchase time and order No
good_time_and_id = item.find('.bought-wrapper-mod__head-info-cell___29cDO').text().replace('\n', "").replace('\r', "")
# Merchant name
# good_merchant = item.find('.seller-mod__container___1w0Cx').text().replace('\n', "").replace('\r', "")
good_merchant = item.find('.bought-wrapper-mod__seller-container___3dAK3').text().replace('\n', "").replace('\r', "")
# Trade name
# good_name = item.find('.sol-mod__no-br___1PwLO').text().replace('\n', "").replace('\r', "")
good_name = item.find('.sol-mod__no-br___3Ev-2').text().replace('\n', "").replace('\r', "")
# commodity price
good_price = item.find('.price-mod__price___cYafX').text().replace('\n', "").replace('\r', "")
# Only the purchase time, order number, merchant name and commodity name are listed
# Please get the rest by yourself
data_list.append(good_time_and_id)
data_list.append(good_merchant)
data_list.append(good_name)
data_list.append(good_price)
#print(good_time_and_id, good_merchant, good_name)
#file_path = os.path.join(os.path.dirname(__file__) + '/user_orders.json')
# file_path = "../Spiders/taobao/user_orders.json"
json_str = json.dumps(data_list)
with open(self.path + os.sep + 'user_orders.json', 'a') as f:
f.write(json_str)
# print('\n\n')
# Most people are detected as robots because they further simulate manual operation
# Simulate manual downward browsing of goods, that is, simulate sliding operation to prevent being recognized as a robot
# Random sliding delay time
swipe_time = random.randint(1, 3)
self.swipe_down(swipe_time)
# Wait for the next page button to appear
good_total = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.pagination-next')))
good_total.click()
time.sleep(2)
# while 1:
# time.sleep(0.2)
# try:
# good_total = self.driver.find_element_by_xpath('//li[@title = "next"]')
# break
# except:
# continue
# # Click the next button
# while 1:
# time.sleep(2)
# try:
# good_total.click()
# break
# except Exception:
# pass
# How many pages do you want to collect? The default is three pages https://shoucang.taobao.com/nodejs/item_collect_chunk.htm?ifAllTag=0&tab=0&tagId=&categoryCount=0&type=0&tagName=&categoryName=&needNav=false&startRow=60
def get_choucang_item(self, page=3):
url = 'https://shoucang.taobao.com/nodejs/item_collect_chunk.htm?ifAllTag=0&tab=0&tagId=&categoryCount=0&type=0&tagName=&categoryName=&needNav=false&startRow={}'
pn = 0
json_list = []
for i in trange(page):
self.driver.get(url.format(pn))
pn += 30
html_str = self.driver.page_source
if html_str == '':
break
if 'Sign in' in html_str:
raise Exception('Sign in')
obj_list = etree.HTML(html_str).xpath('//li')
for obj in obj_list:
item = {}
item['title'] = ''.join([i.strip() for i in obj.xpath('./div[@class="img-item-title"]//text()')])
item['url'] = ''.join([i.strip() for i in obj.xpath('./div[@class="img-item-title"]/a/@href')])
item['price'] = ''.join([i.strip() for i in obj.xpath('./div[@class="price-container"]//text()')])
if item['price'] == '':
item['price'] = 'invalid'
json_list.append(item)
# file_path = os.path.join(os.path.dirname(__file__) + '/shoucang_item.json')
json_str = json.dumps(json_list)
with open(self.path + os.sep + 'shoucang_item.json', 'w') as f:
f.write(json_str)
# How many pages do you want to browse? The default is three pages https://shoucang.taobao.com/nodejs/item_collect_chunk.htm?ifAllTag=0&tab=0&tagId=&categoryCount=0&type=0&tagName=&categoryName=&needNav=false&startRow=60
def get_footmark_item(self, page=3):
url = 'https://www.taobao.com/markets/footmark/tbfoot'
self.driver.get(url)
pn = 0
item_num = 0
json_list = []
for i in trange(page):
html_str = self.driver.page_source
obj_list = etree.HTML(html_str).xpath('//div[@class="item-list J_redsList"]/div')[item_num:]
for obj in obj_list:
item_num += 1
item = {}
item['date'] = ''.join([i.strip() for i in obj.xpath('./@data-date')])
item['url'] = ''.join([i.strip() for i in obj.xpath('./a/@href')])
item['name'] = ''.join([i.strip() for i in obj.xpath('.//div[@class="title"]//text()')])
item['price'] = ''.join([i.strip() for i in obj.xpath('.//div[@class="price-box"]//text()')])
json_list.append(item)
self.driver.execute_script('window.scrollTo(0,1000000)')
# file_path = os.path.join(os.path.dirname(__file__) + '/footmark_item.json')
json_str = json.dumps(json_list)
with open(self.path + os.sep + 'footmark_item.json', 'w') as f:
f.write(json_str)
# address
def get_addr(self):
url = 'https://member1.taobao.com/member/fresh/deliver_address.htm'
self.driver.get(url)
html_str = self.driver.page_source
obj_list = etree.HTML(html_str).xpath('//tbody[@class="next-table-body"]/tr')
data_list = []
for obj in obj_list:
item = {}
item['name'] = obj.xpath('.//td[1]//text()')
item['area'] = obj.xpath('.//td[2]//text()')
item['detail_area'] = obj.xpath('.//td[3]//text()')
item['youbian'] = obj.xpath('.//td[4]//text()')
item['mobile'] = obj.xpath('.//td[5]//text()')
data_list.append(item)
# file_path = os.path.join(os.path.dirname(__file__) + '/addr.json')
json_str = json.dumps(data_list)
with open(self.path + os.sep + 'address.json', 'w') as f:
f.write(json_str)
if __name__ == '__main__':
# pass
cookie_list = json.loads(open('taobao_cookies.json', 'r').read())
t = TaobaoSpider(cookie_list)
t.get_orders()
# t.crawl_good_buy_data()
# t.get_addr()
# t.get_choucang_item()
# t.get_footmark_item()
Github address:
https://github.com/kangvcar/InfoSpider
Explanation at station b:
https://www.bilibili.com/video/BV14f4y1R7oF/
Interested students can download to learn~
PS: if you think my sharing is good, you are welcome to like it and watch it.
END