preface
- I suddenly want to crawl CSDN's columns and save them locally. In order to have less impact, I specially select the front page of CSDN for display.
- Comprehensive information Where was this test point found? Click the hot article in the figure below, and then jump to the specific article
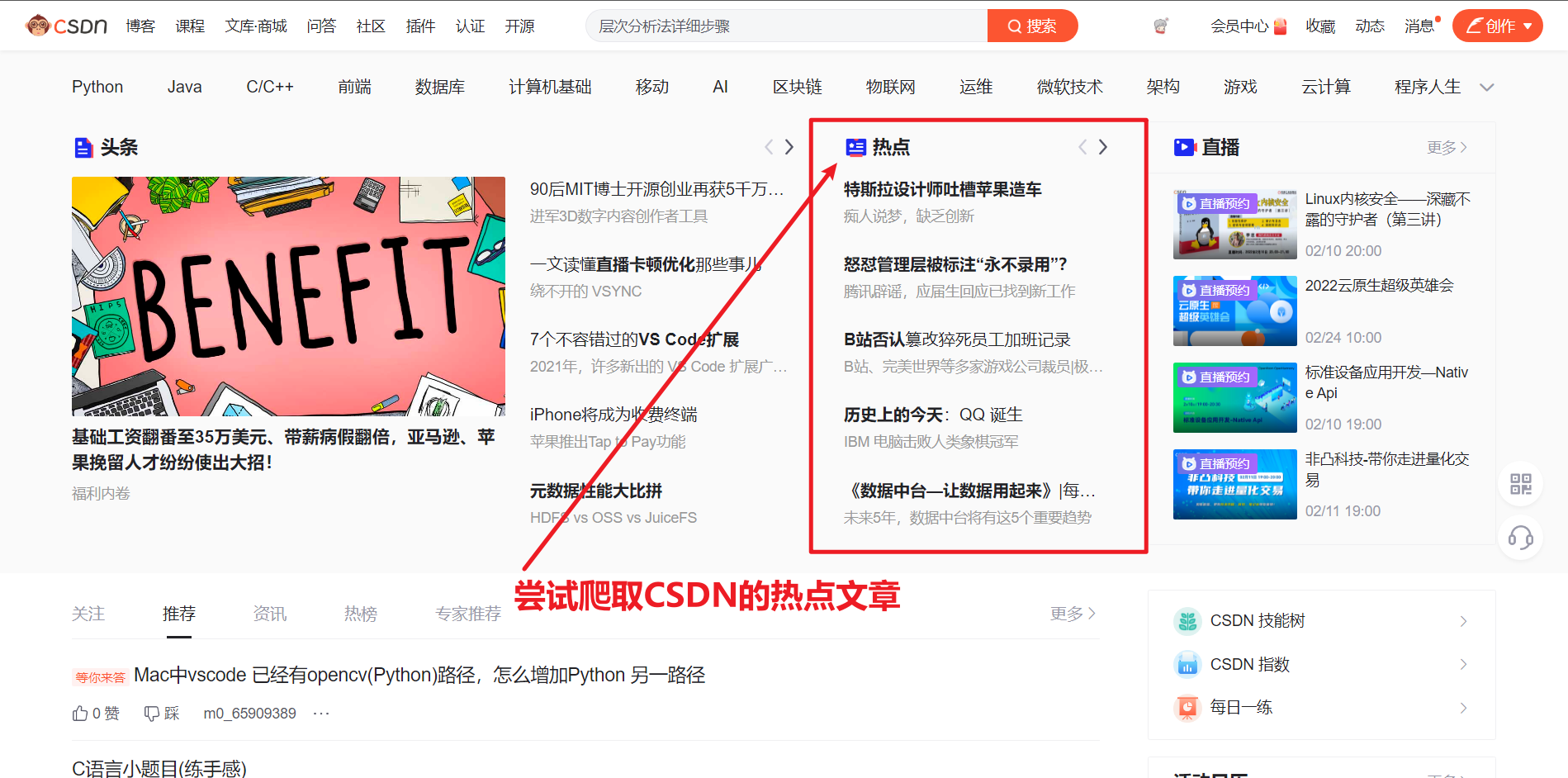
, and then click the column to enter
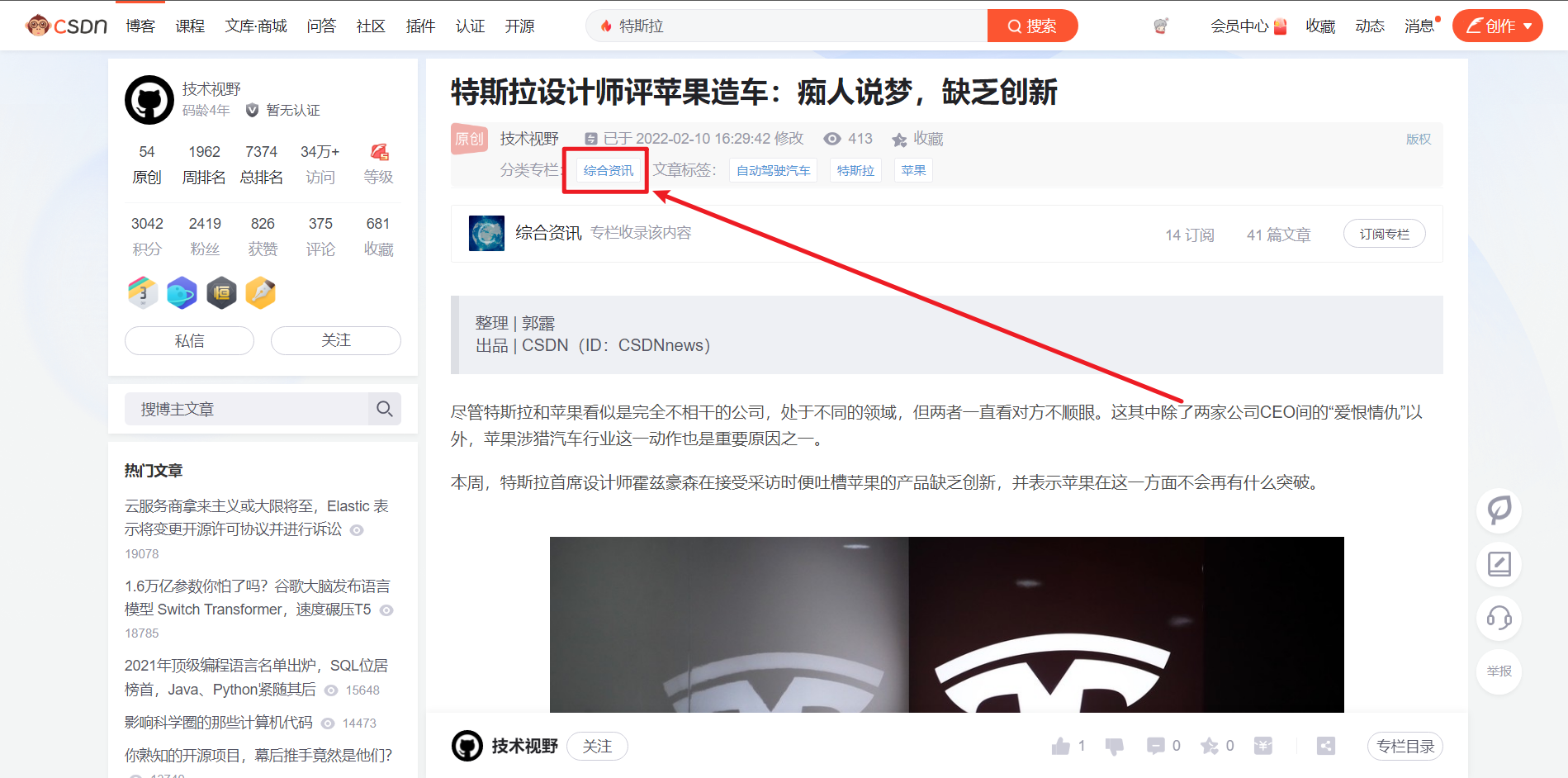
Cut the crap and go straight to the code
-
The code is realized with object-oriented thinking
-
The code idea is put in the code comments
-
Mainstream interfaces such as requests and bs4 are used
-
The rest is, I hope you can continue to develop and improve based on this, ha ha ha!!!
-
This code and implementation content have been packaged and uploaded to Gitee only, You can click to view
"""
@Author:survive
@Blog (personal blog address): https://blog.csdn.net/haojie_duan@File:csdn.py.py
@Time:2022/2/10 8:49@Motto: I don't know where I'm going, but I'm already on my way—— Hayao Miyazaki's "Chihiro"
Code idea:
1. Determine the target requirements: save the content of csdn articles in html, PDF and md formats
-1.1 first save it in html format: get all the article ur1 addresses in the list page, and request the article ur1 address to get the article content we need
-1.2 through wkhtmitopdf Exe converts html files into PDF files
-1.3 through wkhtmitopdf Exe converts html file into md file2. Request ur1 to obtain the source code of the web page
3. Analyze the data and extract the content you want
4. Save data
Convert PDF data type to md
"""html_str = """
Document {article} """import requests
import parsel
import pdfkit # is used to convert html to pdf
import re
import os
import urllib.parse
from bs4 import BeautifulSoup
import html2text # is used to convert HTML to md
import randomuser_agent Library: one user is randomly selected for each access_ Agent to prevent too frequent access from being prohibited
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36"
]class CSDNSpider():
def init(self):
self.url = 'https://blog.csdn.net/csdndevelopers/category_10594816.html'
self.headers = {
'user-agent':random.choice(USER_AGENT_LIST)
}def send_request(self, url): response = requests.get(url=url, headers=self.headers) response.encoding = "utf-8" if response.status_code == 200: return response def parse_content(self, reponse): html = reponse.text selector = parsel.Selector(html) href = selector.css('.column_article_list a::attr(href)').getall() name = 00 for link in href: print(link) name = name + 1 # Send a request to the url address of the article response = self.send_request(link) if response: self.parse_detail(response, name) def parse_detail(self, response, name): html = response.text # print(html) selector = parsel.Selector(html) title = selector.css('#articleContentId::text').get() # content = selector.css('#content_views').get() # Since the web page file obtained by parsel is used here, it will automatically jump to the csdn home page and cannot be converted to pdf. I want to use soup here soup = BeautifulSoup(html, 'lxml') content = soup.find('div',id="content_views",class_=["markdown_views prism-atom-one-light" , "htmledit_views"]) #class_="htmledit_views" # print(content) # print(title, content) html = html_str.format(article=content) self.write_content(html, title) def write_content(self, content, name): html_path = "HTML/" + str(self.change_title(name)) + ".html" pdf_path ="PDF/" + str(self.change_title(name))+ ".pdf" md_path = "MD/" + str(self.change_title(name)) + ".md" # Save content as html file with open(html_path, 'w',encoding="utf-8") as f: f.write(content) print("Saving", name, ".html") # Convert html files to PDF files config = pdfkit.configuration(wkhtmltopdf=r'G:Devwkhtmltopdfinwkhtmltopdf.exe') pdfkit.from_file(html_path, pdf_path, configuration=config) print("Saving", name, ".pdf") # os.remove(html_path) # Convert html files to md format html_text = open(html_path, 'r', encoding='utf-8').read() markdown = html2text.html2text(html_text) with open(md_path, 'w', encoding='utf-8') as file: file.write(markdown) print("Saving", name, ".md") def change_title(self, title): mode = re.compile(r'[\/:?*"<>|!]') new_title = re.sub(mode,'_', title) return new_title def start(self): response = self.send_request(self.url) if response: self.parse_content(response)if name == 'main':
csdn = CSDNSpider()
csdn.start()
The effect is as follows:
- From left to right, there are html, pdf and md formats respectively

- Check the format of an article from left to pdf, and check the format of an article from left to right
Postscript
Reference article:
- Python crawler: requests + beautiful soup4 crawl CSDN personal blog home page information (blogger information, article title, article link) crawl the information (access, collection) of each blogger's article, and legally brush the number of visits?
- Sort out the most complete python markdown and HTML conversion modules