From crawling one page of data to crawling all data
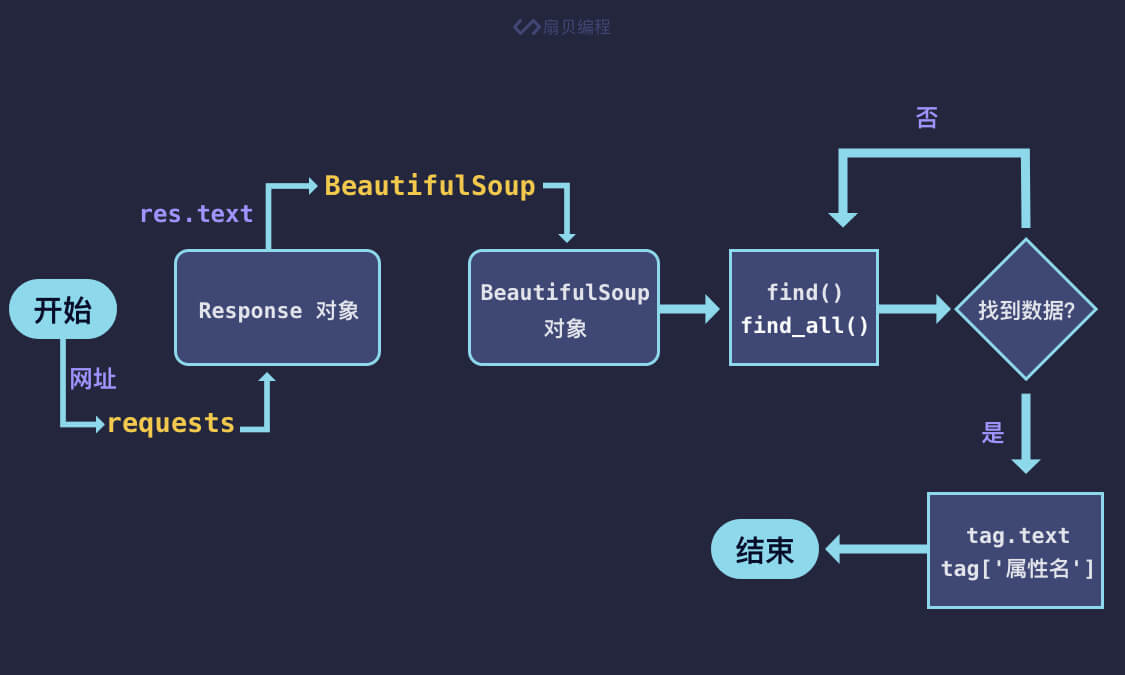
Let's talk about the general process of static web crawler first
- Data loading method
- By clicking on the second page, you can find that there are more at the back of the website? start=25 field
- This part is called "query string". The query string is transmitted to the server as a parameter for search or processed data. The format is? key1=value1&key2=value2.
- Let's turn a few more pages of Douban reading page and observe the change law of the website:
- It is not difficult to find that: the second page is "start=25", the third page is "start=50, the tenth page is" start=225 ", and the number of books per page is 25.
- Therefore, the calculation formula of start is "start = 25 * (number of pages - 1) (25 is the number displayed on each page).
- You can write a piece of code to automatically generate all the web page addresses you want to find
-
1 url = 'https://book.douban.com/top250?start={}' 2 # num Start at 0, so you don't have to -1 3 urls = [url.format(num * 25) for num in range(10)] 4 print(urls) 5 # Output: 6 # [ 7 # 'https://book.douban.com/top250?start=0', 8 # 'https://book.douban.com/top250?start=25', 9 # 'https://book.douban.com/top250?start=50', 10 # 'https://book.douban.com/top250?start=75', 11 # 'https://book.douban.com/top250?start=100', 12 # 'https://book.douban.com/top250?start=125', 13 # 'https://book.douban.com/top250?start=150', 14 # 'https://book.douban.com/top250?start=175', 15 # 'https://book.douban.com/top250?start=200', 16 # 'https://book.douban.com/top250?start=225' 17 # ]
With the links to all the pages, we can crawl the data of the whole website
1 import requests 2 import time 3 from bs4 import BeautifulSoup 4 5 # Encapsulate the code to obtain Douban reading data into a function 6 def get_douban_books(url): 7 headers = { 8 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36' 9 } 10 res = requests.get(url, headers=headers) 11 soup = BeautifulSoup(res.text, 'html.parser') 12 items = soup.find_all('div', class_='pl2') 13 for i in items: 14 tag = i.find('a') 15 name = tag['title'] 16 link = tag['href'] 17 print(name, link) 18 19 url = 'https://book.douban.com/top250?start={}' 20 urls = [url.format(num * 25) for num in range(10)] 21 for item in urls: 22 get_douban_books(item) 23 # Pause for 1 second to prevent access from being blocked too quickly 24 time.sleep(1)
Anti crawler: limit frequent and abnormal web browsing
- Whether it is a browser or a crawler, when visiting a website, it will bring some information for identification. The headers of these requests are stored in one place.
- The server will identify the visitor by the information in the request header. There are many fields in the request header. For the time being, we only need to know the user agent. User agent contains information such as operating system, browser type and version. By modifying it, we can disguise ourselves as a browser.
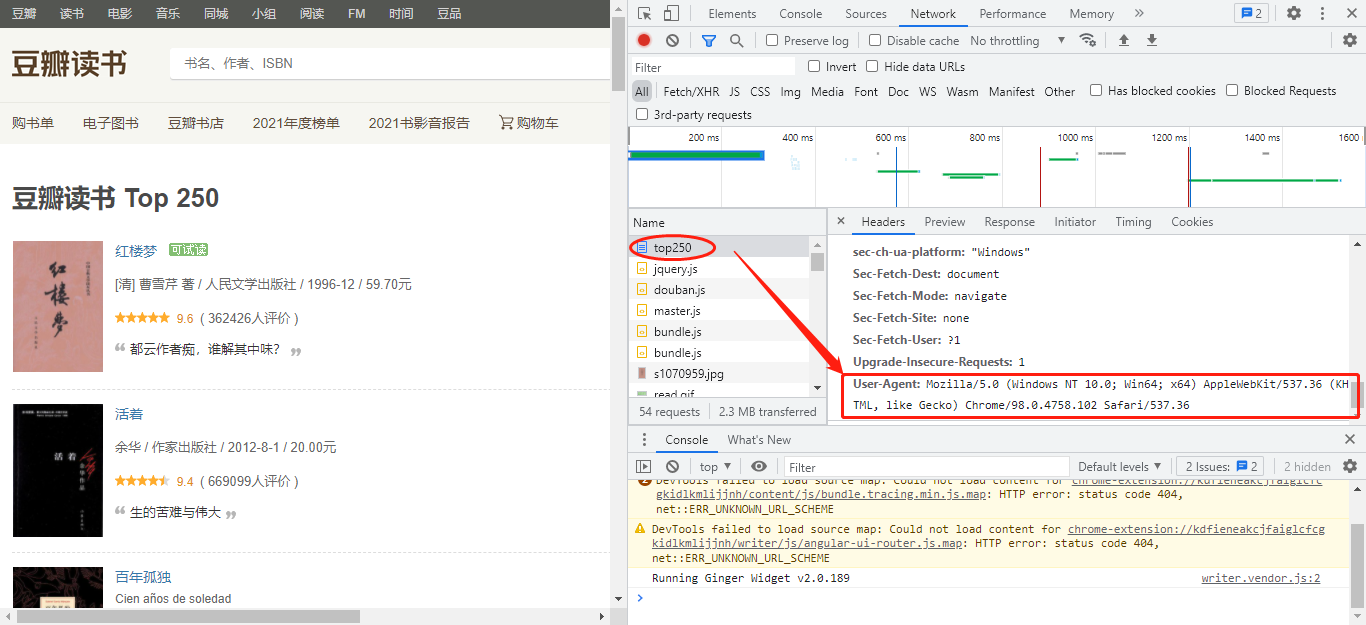 Official documents of requests( http://cn.python-requests.org/zh_CN/latest/)
Official documents of requests( http://cn.python-requests.org/zh_CN/latest/)
Identification is the simplest anti crawler method. We can also easily bypass this restriction by camouflage the crawler as a browser through one line of code. Therefore, most websites will also be subject to IP restrictions to prevent too frequent access.
-
IP (Internet Protocol) is the full name of internet protocol address, which means the digital label assigned to the internet protocol device used by users. You can understand the IP address as the house number. As long as I know your house number, I can find your home.
- When we crawl a large amount of data, if we visit the target website without restraint, the website will be overloaded. Some small personal websites have no anti crawler measures and may be paralyzed. Large websites generally limit your access frequency, because normal people will not visit websites dozens or even hundreds of times within 1s.
- Often use {time Sleep () to reduce the frequency of access
- Agents can also be used to solve the problem of IP restrictions, that is, accessing websites through other IPS
- Official documents - https://cn.python-requests.org/zh_CN/latest/user/advanced.html#proxies
-
1 import requests 2 3 proxies = { 4 "http": "http://10.10.1.10:3128", 5 "https": "http://10.10.1.10:1080", 6 } 7 8 requests.get("http://example.org", proxies=proxies)
When crawling a large amount of data, we need a lot of IP for switching. Therefore, we need to establish an IP proxy pool (list) and randomly select one parameter to pass to # proxies # every time.
Let's look at how to achieve:
1 import requests 2 import random 3 from bs4 import BeautifulSoup 4 5 def get_douban_books(url, proxies): 6 headers = { 7 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36' 8 } 9 # Crawling data using proxy 10 res = requests.get(url, proxies=proxies, headers=headers) 11 soup = BeautifulSoup(res.text, 'html.parser') 12 items = soup.find_all('div', class_='pl2') 13 for i in items: 14 tag = i.find('a') 15 name = tag['title'] 16 link = tag['href'] 17 print(name, link) 18 19 url = 'https://book.douban.com/top250?start={}' 20 urls = [url.format(num * 25) for num in range(10)] 21 # IP Proxy pool (nonsense is useless) 22 proxies_list = [ 23 { 24 "http": "http://10.10.1.10:3128", 25 "https": "http://10.10.1.10:1080", 26 }, 27 { 28 "http": "http://10.10.1.11:3128", 29 "https": "http://10.10.1.11:1080", 30 }, 31 { 32 "http": "http://10.10.1.12:3128", 33 "https": "http://10.10.1.12:1080", 34 } 35 ] 36 for i in urls: 37 # from IP Randomly select one from the agent pool 38 proxies = random.choice(proxies_list) 39 get_douban_books(i, proxies)
Gentleman's agreement in crawler -- robots txt
robots.txt is a text file stored in the root directory of the website, which is used to tell the crawler what content in the website should not be crawled and what can be crawled.
We just need to add / robots after the domain name of the website Txt to view,
For example, Douban's {robots Txt address is: https://book.douban.com/robots.txt . The contents after opening it are as follows:
1 User-agent: * 2 Disallow: /subject_search 3 Disallow: /search 4 Disallow: /new_subject 5 Disallow: /service/iframe 6 Disallow: /j/ 7 8 User-agent: Wandoujia Spider 9 Disallow: /
User agent: * refers to all crawlers (* is a wildcard), followed by the rules to be followed by crawlers that meet the user agent. For example, Disallow: /search means that crawling to / search is prohibited. The same is true for others.