1, Reptile preparation
1.1 climbing target
The target of the public comment Web crawler is the comment data of the store. The example is shown in the figure below.

1.2 web page analysis
First log in, search for bubble water by keyword, and click a store at will to view all the evaluation interfaces, as shown in the figure below.

First, check whether there is comment data in the web page source code.

Comment data found, so this is a static page.
Next, right-click to check a comment to see where the comment is stored. The div tag where the comment is stored is found, but the comment is incomplete. The font encryption appears, as shown in the figure below.

Therefore, the biggest problem of public comment Web page crawling is to solve the problem of font encryption.
2, svg font encryption solution
Right click to check a comment, click an svg encrypted font, and copy the URL in the background image in styles.
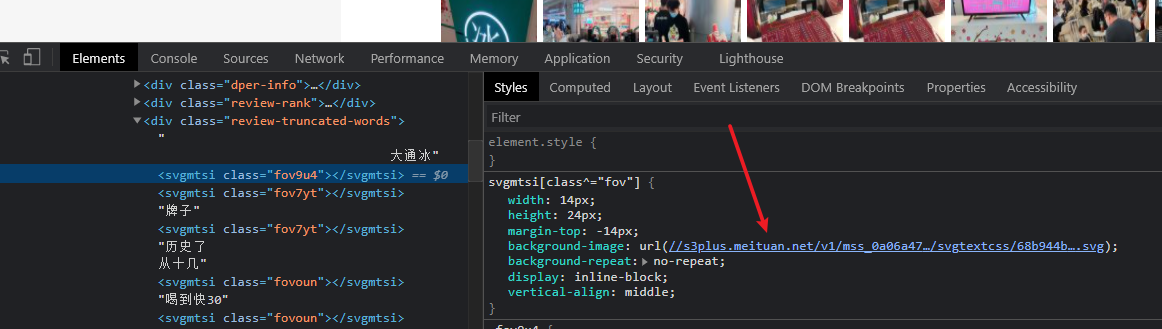
Paste it into the new page to see what it is. The display is shown in the figure below.

This svg dictionary has two main forms at present.
One is the type shown in the figure below.

Has three tags < style >, < defs >, < text >
Font size is stored in < style > label, which is 14px
The < defs > label reads as follows:
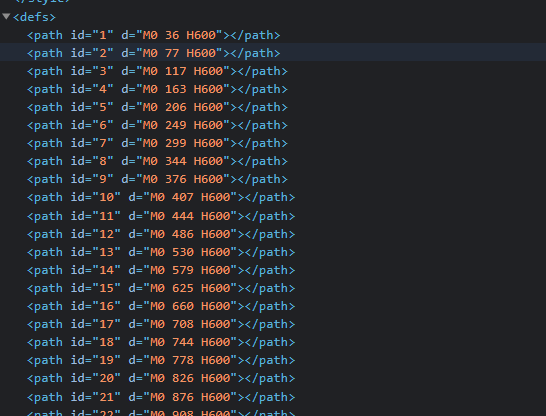
It is found that the id value is increasing, and each line d="M0 (.*?) H600 "the value in parentheses is also increasing and changing.
< text > the label reads as follows:
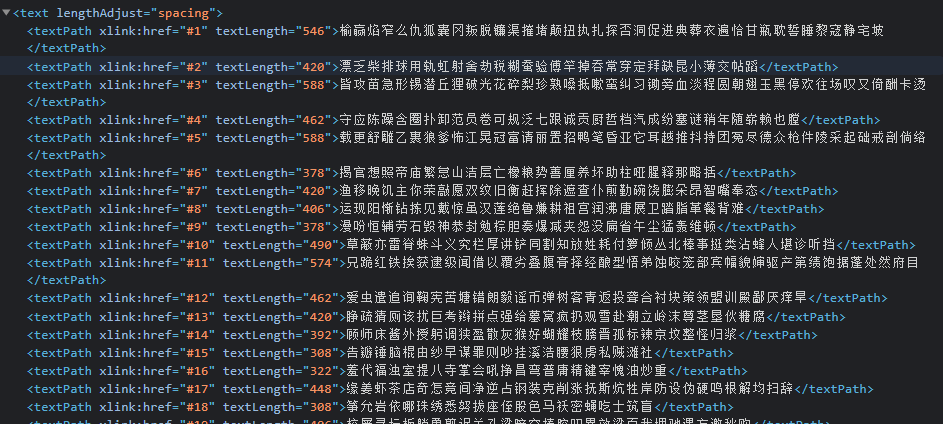
xlink:href = '#num' in < textpath > tag is the css selector, which is bound with the id of < defs > / < Path >;
The < textpath > value is a string of Chinese character strings.
The above figure should be displayed as "big" in the interface.
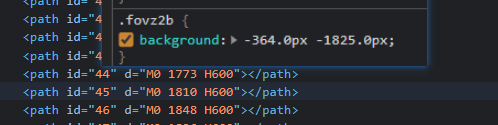
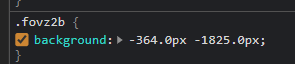
The d value in the defs tag of svg is 1848, which is greater than 1825 and closest to 1825, so the id is 46 at this time.
Next, under the text tag, first locate 46. Next, divide the x of svg font by the font size (14) to 26. It is found that 26 is exactly a large font.

Second, the form of x and y is shown in the figure below:

For this similarity, first find the Y coordinate of svg font, take the line that is greater than y and closest to it, and then use x to find the corresponding character in the same way.
3, Get svg data
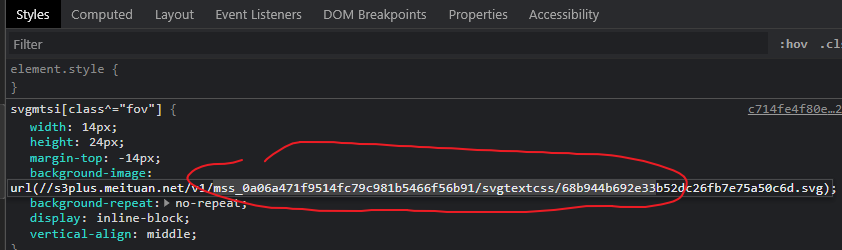
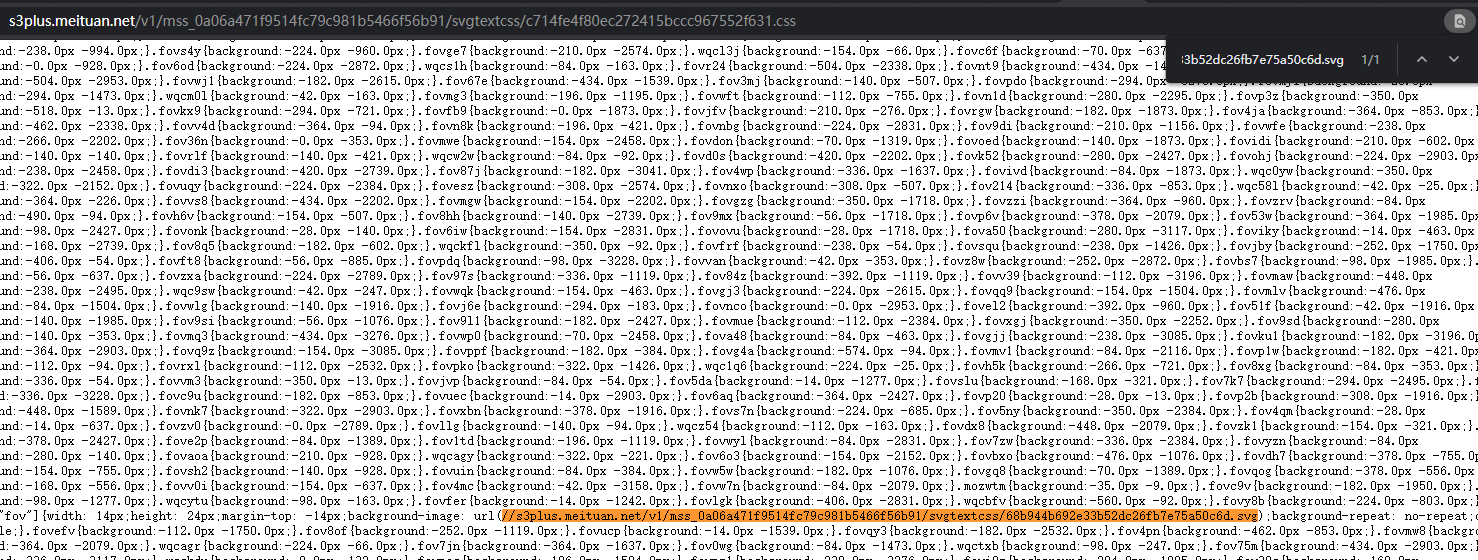
Copy the content of a svg url, search the Network for this content, and then find the url of the css we want.

With the url of this css, we can get the url of the svg dictionary we want through regular.
4, Crawl a store review test
4.0 import required libraries
import requests import re from lxml import etree import pandas as pd
4.1 first obtain the original web page data
headers = {
'Cookie': 'fspop=test; cy=16; cye=wuhan; _lxsdk_cuid=17916f201c4c8-035070c38d8204-d7e1739-1fa400-17916f201c4c8; _lxsdk=17916f201c4c8-035070c38d8204-d7e1739-1fa400-17916f201c4c8; _hc.v=dcde2fb0-e0f3-926e-dbae-e87bbf5ee433.1619587630; s_ViewType=10; dplet=40504813046992766625a9fefc89e41a; dper=130a3d9cd1116f55df8886ec4f9c6fef4167abbaaad42a0b3267d42bcab1635e407dc129547b3c42599c5b7bad0c280a5638000ef11d86684e1ec48f7ad140f8900fb4d510a9ffb4473cd0cae2f645ba174b382474c118fdb407f804d3356220; ll=7fd06e815b796be3df069dec7836c3df; ua=dpuser_4249164069; ctu=812925e228e979d00be7aee6bd780e9075faa40aa5bee10c149d7619df1511f1; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; Hm_lvt_602b80cf8079ae6591966cc70a3940e7=1619587630,1619587635,1619595685; Hm_lpvt_602b80cf8079ae6591966cc70a3940e7=1619595705',
'Host': 'www.dianping.com',
'Referer': 'http://www.dianping.com/shop/k1QYatFhqiMChSNu/review_all',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
response = requests.get('http://www.dianping.com/shop/k1QYatFhqiMChSNu/review_all',headers =headers)
with open('01 Web data_encryption.html',mode='w',encoding='utf-8') as f:
f.write(response.text)
4.2 get css file request svg content
css_url = 'http:' +re.findall(r'<link rel="stylesheet" type="text/css" href="(//s3plus.meituan.*?)">',response.text)[0]
css_response = requests.get(css_url)
with open('02 css style.css',mode='w',encoding='utf-8') as f:
f.write(css_response.text)
4.3 get svg mapping table
svg_url ='http:'+ re.findall(r'svgmtsi\[class\^="zz"\].*?background-image: url\((.*?)\);',css_response.text)[0]
svg_response = requests.get(svg_url)
with open('03 svg Mapping table.svg',mode='w',encoding='utf-8') as f:
f.write(svg_response.text)
4.4 obtaining svg encryption dictionary
Is to form a corresponding table to prepare for the next replacement.
import parsel
with open('03 svg Mapping table.svg',mode='r',encoding='utf-8') as f:
svg_html = f.read()
sel = parsel.Selector(svg_html)
texts = sel.css('text')
lines = []
for text in texts:
lines.append([int(text.css('text::attr(y)').get()),text.css('text::text').get()])
with open('02 css style.css',mode='r',encoding='utf-8') as f:
css_text = f.read()
class_map = re.findall(r'\.(zz\w+)\{background:-(\d+)\.0px -(\d+)\.0px;\}',css_text)
class_map = [(cls_name,int(x),int(y)) for cls_name,x,y in class_map]
d_map = {}
#Get the correspondence between class name and Chinese characters
for one_char in class_map:
try:
cls_name,x,y =one_char
for line in lines:
if line[0] < y:
pass
else:
index = int(x/14)
char = line[1][index]
# print(cls_name,char)
d_map[cls_name] = char
break
except Exception as e:
print(e)
4.5 replace svg encrypted font and restore comments
with open('01 Web data_encryption.html',mode='r',encoding='utf-8') as f:
html = f.read()
for key,value in d_map.items():
html = html.replace('<svgmtsi class="'+key+'"></svgmtsi>',value)
with open('04 Web data_decrypt.html',mode='w',encoding='utf-8') as f:
f.write(html)
Remove spaces and coexist in dataframe.
e = etree.HTML(html)
pl = e.xpath("//div[@class='review-words Hide']/text()")
dq_list =[]
for p in pl:
if p == '\n\t ' or p == '\n ':
pass
else:
dq_list.append(p)
for pp in dq_list:
cc_df = cc_df.append({'comment':pp}, ignore_index=True)
Save as csv file, and the results are as follows:

5, Summary
It mainly solves the problem of comment font encryption. The svg dictionary has been dynamically updated, so it should be crawled according to the actual situation.
This time, we mainly crawled a store comment, which solved the main problem of comment font encryption.