catalogue
1.1 philosophy brought by survival pressure
1.2 # buying a house & a house slave
3 climb the Guiyang house price and write it into the table
3.2 code implementation (Python)
1 Preface
1.1 philosophy brought by survival pressure
Malthus first discovered that the innate ability of organisms to proliferate highly according to geometric progression is always greater than their actual survival ability or actual survival group. In turn, it is inferred that the intraspecific competition of organisms must be extremely cruel and inevitable. For the time being, whether Malthus needs to give corresponding warnings to mankind is only a series of basic problems implied in this phenomenon. For example, what is the natural limit of biological overproduction ability? What advantages do survivors of intraspecific competition rely on to win? And how do these so-called dominant groups lead themselves to where? And so on, which is enough to cause any thoughtful person to think deeply without fear.
Later, Darwin specifically mentioned the scientific contribution and Enlightenment of Malthusian theory in the introduction of his epoch-making book the origin of species. It can be seen that ordinary people are not qualified to be the bosom friend of the old priest Ma!
1.2 # buying a house & a house slave
Now when we get married, the woman usually requires the man to have a house and a car. In fact, we can't blame other girls. In today's highly developed and turbulent society, this requirement is really not high. However, since the reform and opening up, the class has solidified, which is difficult for our generation! Let's first look at the house price in Guiyang (chain home new house): https://gy.fang.lianjia.com/)
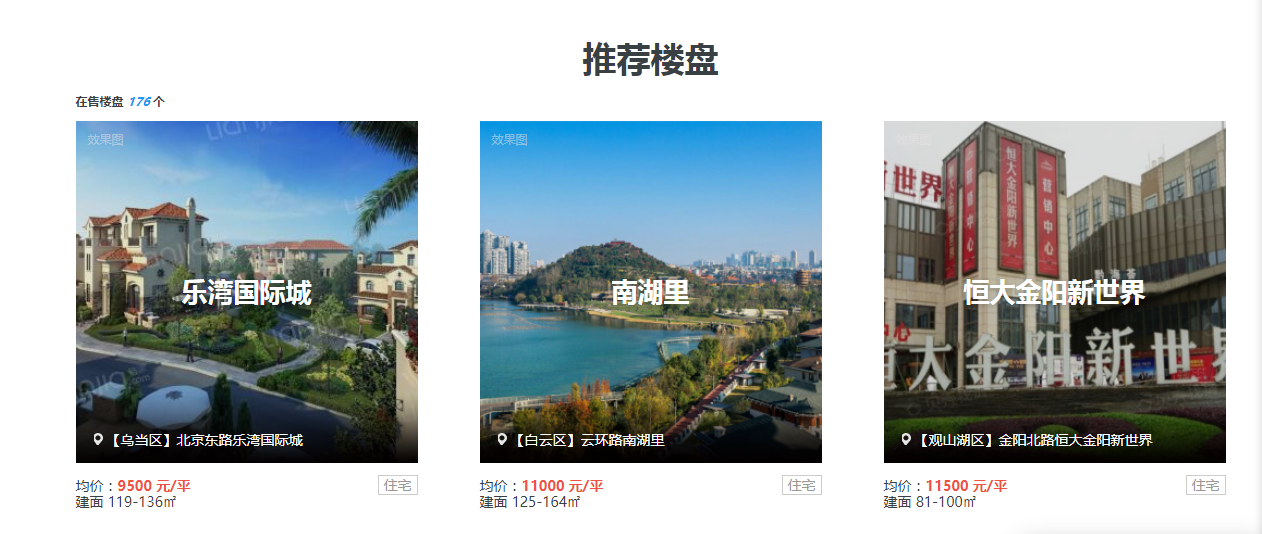
There are few big capitalists who can't be eliminated by the times and can't always sigh. Liu qiangdong is one of them. Idols belong to idols. Come back to reality. Rural children may buy a house, they may be house slaves for a lifetime. When they return to the countryside, they are worshipped by others on the surface, and only they know their pain and grievances. In view of this, I personally don't want to be a house slave and a car slave. Happiness is my own, life is my own, and living my wonderful life is not for others to see. I want to make my destiny beautiful and beautiful. What I need to do at this stage is to improve my ability and don't want to be a house slave!
With great efforts and sighs, it's time to return to today's theme. Why don't you get these data into a document table for analysis, just do it, crawl it with a crawler, and then write it into the document.
2 reptiles
2.1 basic concepts
Crawler: also known as web spider, or Robots It is a program or script that automatically captures the information of the world wide web according to certain rules. In other words, it can get the web page address automatically. If the Internet is compared to a big spider web, there are many web pages in it. Web spiders can get the content of all web pages.
Crawler is a program or automated script that simulates human behavior of requesting website and downloading website resources in batches.
Crawler: a way to obtain website information in batches by using any technical means. The key is batch.
Anti crawler: a way of using any technical means to prevent others from obtaining their own website information in batches. The key also lies in batch.
Accidental injury: in the process of anti crawler, ordinary users are incorrectly identified as crawlers. The anti crawler strategy with high accidental injury rate can't be used no matter how effective it is.
Block: successfully blocked crawler access. There will be the concept of interception rate. Generally speaking, the higher the interception rate, the higher the possibility of accidental injury. Therefore, a trade-off needs to be made.
Resources: the sum of machine cost and labor cost.
2.2} basic process of reptile
(1) Request page:
Send a Request to the target site through the HTTP library, that is, send a Request, which can contain additional headers, etc
Information, waiting for server response!
(2) Get the corresponding content:
If the server can respond normally, it will get a Response. The content of the Response is the page content to be obtained. The types may include HTML, Json string, binary data (such as pictures and videos).
(3) Analysis content:
The obtained content may be HTML, which can be parsed with regular expressions and web page parsing library. Maybe it's Jason. Yes
Directly convert to Json object analysis, which may be binary data, which can be saved or further processed.
(4) Store parsed data:
There are various forms of saving, which can be saved as text, saved to the database, or saved in a specific format
Test case:
Code implementation: crawl the page data of Guiyang house price
#==========Guide Package=============
import requests
#=====step_1: specify url=========
url = 'https://gy.fang.lianjia.com/ /'
#=====step_2: initiate request:======
#Use the get method to initiate a get request, which will return a response object. The parameter url represents the url corresponding to the request
response = requests . get ( url = url )
#=====step_3: get response data:===
#By calling the text attribute of the response object, the response data (page source code data) in the form of string stored in the response object is returned
page_text = response . text
#====step_4: persistent storage=======
with open ('House price in Guiyang . html ','w', encoding ='utf -8') as fp:
fp.write ( page_text )
print (' Crawling data completed !!!') 
Crawling data completed !!! Process finished with exit code 0
3 climb the Guiyang house price and write it into the table
3.1 result display
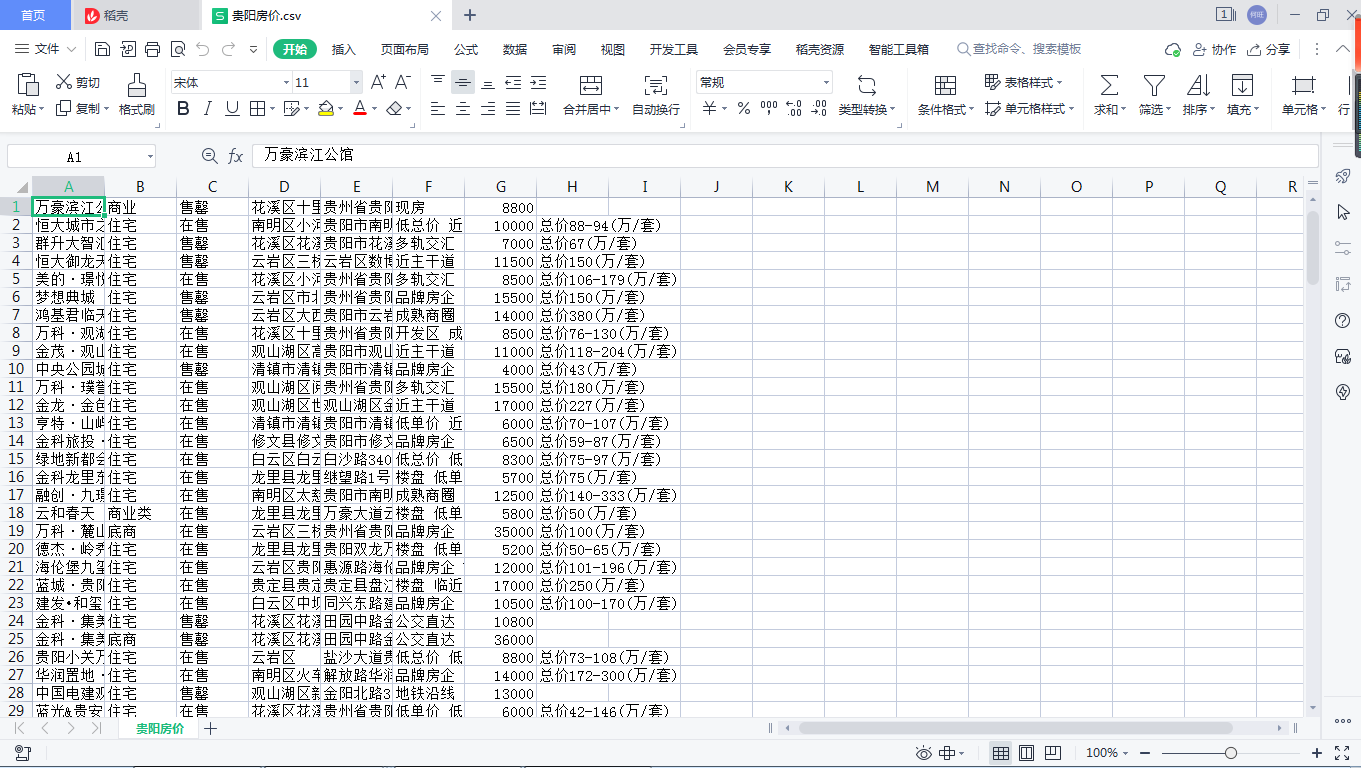

3.2 code implementation (Python)
#==================Import related Library==================================
from bs4 import BeautifulSoup
import numpy as np
import requests
from requests.exceptions import RequestException
import pandas as pd
#=============Read web page=========================================
def craw(url,page):
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36"}
html1 = requests.request("GET", url, headers=headers,timeout=10)
html1.encoding ='utf-8' # Add code, important! Convert to string encoding, and read() gets byte format
html=html1.text
return html
except RequestException:#Other issues
print('The first{0}Failed to read web page'.format(page))
return None
#==========Parse web pages and save data to tables======================
def pase_page(url,page):
html=craw(url,page)
html = str(html)
if html is not None:
soup = BeautifulSoup(html, 'lxml')
"--First determine the house information, i.e li Tag list--"
houses=soup.select('.resblock-list-wrapper li')#House list
"--Then determine the information of each house--"
for j in range(len(houses)):#Traverse every house
house=houses[j]
"name"
recommend_project=house.select('.resblock-name a.name')
recommend_project=[i.get_text()for i in recommend_project]#Name: Yinghua Tianyuan, Binxin Jiangnan imperial residence
recommend_project=' '.join(recommend_project)
#print(recommend_project)
"type"
house_type=house.select('.resblock-name span.resblock-type')
house_type=[i.get_text()for i in house_type]#Office building, ground floor
house_type=' '.join(house_type)
#print(house_type)
"Sales status"
sale_status = house.select('.resblock-name span.sale-status')
sale_status=[i.get_text()for i in sale_status]#On sale, on sale, sold out, on sale
sale_status=' '.join(sale_status)
#print(sale_status)
"Big address"
big_address=house.select('.resblock-location span')
big_address=[i.get_text()for i in big_address]#
big_address=''.join(big_address)
#print(big_address)
"Specific address"
small_address=house.select('.resblock-location a')
small_address=[i.get_text()for i in small_address]#
small_address=' '.join(small_address)
#print(small_address)
"Advantages."
advantage=house.select('.resblock-tag span')
advantage=[i.get_text()for i in advantage]#
advantage=' '.join(advantage)
#print(advantage)
"Average price: how much is 1 flat"
average_price=house.select('.resblock-price .main-price .number')
average_price=[i.get_text()for i in average_price]#1600025000, price to be determined
average_price=' '.join(average_price)
#print(average_price)
"Total price,Unit 10000"
total_price=house.select('.resblock-price .second')
total_price=[i.get_text()for i in total_price]#The total price is 4 million / set, and the total price is 1 million / set '
total_price=' '.join(total_price)
#print(total_price)
#=====================Write table=================================================
information = [recommend_project, house_type, sale_status,big_address,small_address,advantage,average_price,total_price]
information = np.array(information)
information = information.reshape(-1, 8)
information = pd.DataFrame(information, columns=['name', 'type', 'Sales status','Big address','Specific address','advantage','average price','Total price'])
information.to_csv('House price in Guiyang.csv', mode='a+', index=False, header=False) # mode='a + 'append write
print('The first{0}Page storage data succeeded'.format(page))
else:
print('Parsing failed')
#==================Dual thread=====================================
import threading
for i in range(1,100,2):#Traversing web pages 1-101
url1="https://gy.fang.lianjia.com/loupan/pg"+str(i)+"/"
url2 = "https://gy.fang.lianjia.com/loupan/pg" + str(i+1) + "/"
t1 = threading.Thread(target=pase_page, args=(url1,i))#Thread 1
t2 = threading.Thread(target=pase_page, args=(url2,i+1))#Thread 2
t1.start()
t2.start()