Xpath
Preparatory knowledge
HTML DOM model example
The HTML DOM defines a standard way to access and manipulate HTML documents, representing them in a tree structure.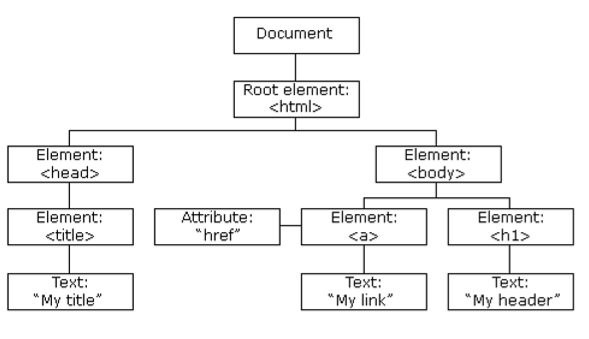
How to parse the crawler data?
1. Locate nodes in html documents
2. Extract the properties of the specified node, such as href,class, etc.
3. Get the text of the specified node, such as a, p, div,span, div, etc.
What is XPath?
XPath (XML Path Language) is a language for finding information in an XML document and can be used to traverse elements and attributes in an XML document.
XPath can first convert HTML files into XML documents, then use XPath to find HTML nodes or elements.
What is XML
Extensible Markup Language (EXtensible Markup Language), W3C's recommended standard, like HTML, tags need to be self-defined, self-descriptive, and designed to transfer data rather than display it
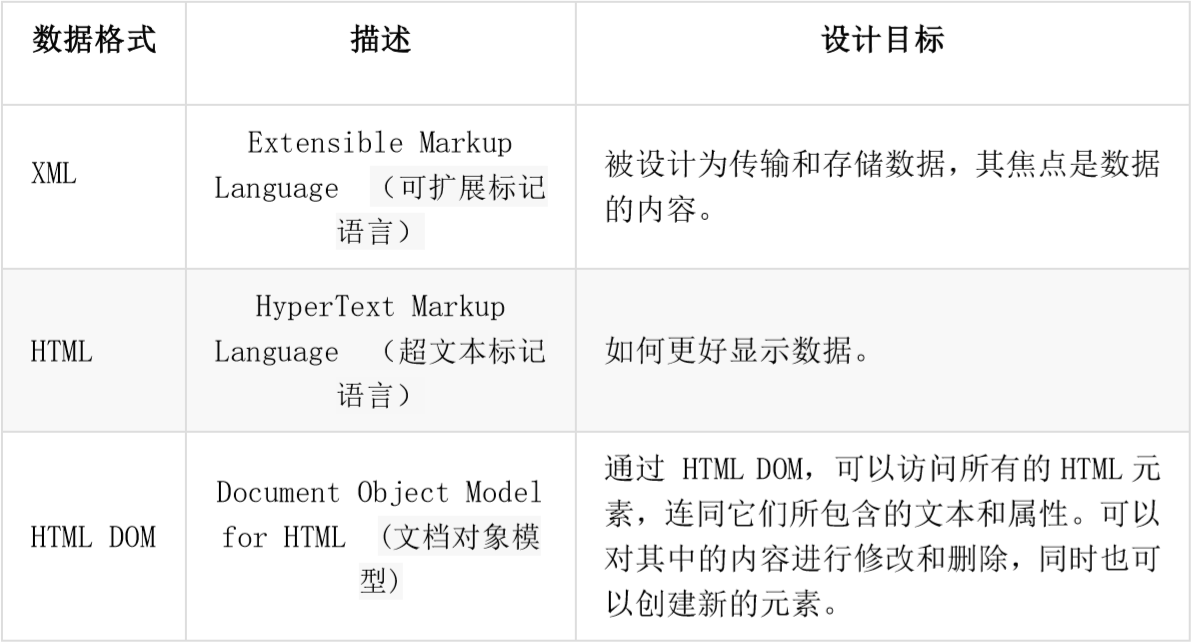
The difference between XML and HTML
XPath Syntax
Select Node
XPath uses path expressions to select nodes and or node sets in an XML document.These path expressions are very similar to those we see in regular computer file systems
The most common path expressions are listed below:
Some path expressions and the results of the expressions:
Predicates
Predicates are used to find nodes whose particular node abstainer contains a specified value and are embedded in square brackets.
In the following table, we list some path expressions with predicates and the results of the expressions: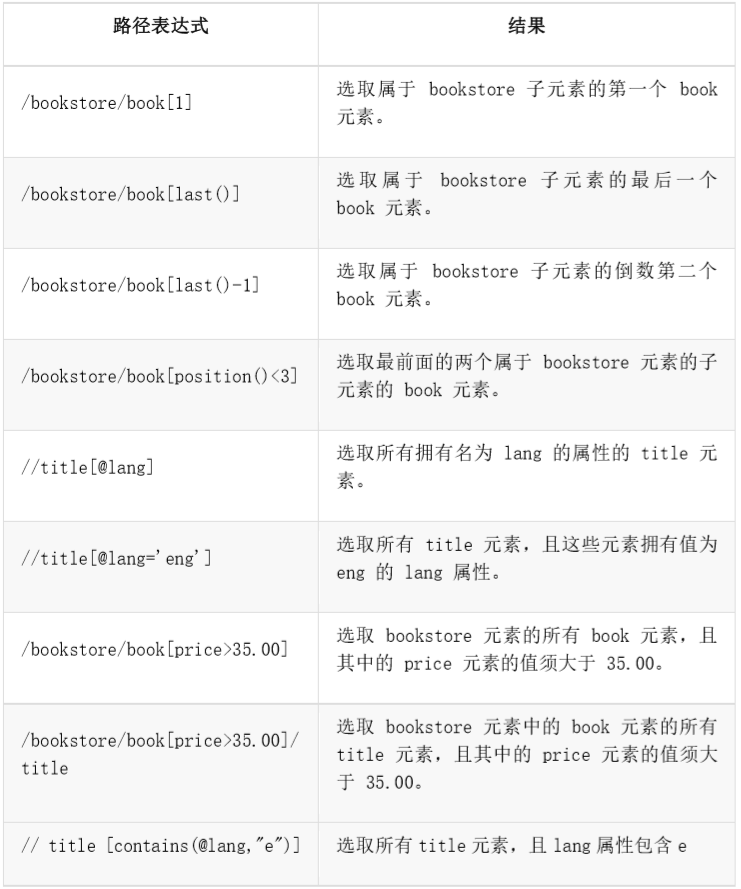
Select Unknown Node
XPath wildcards can be used to select unknown XML elements
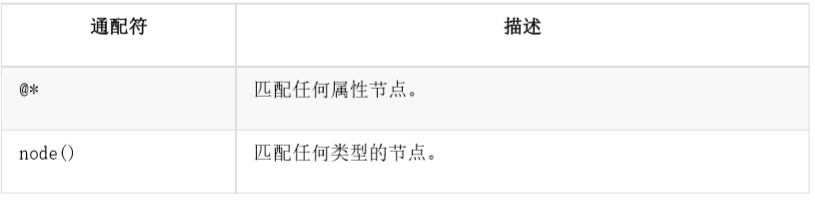
The following table lists some path expressions and the results of these expressions:
Xpath axis
Axis can define a node set relative to the current node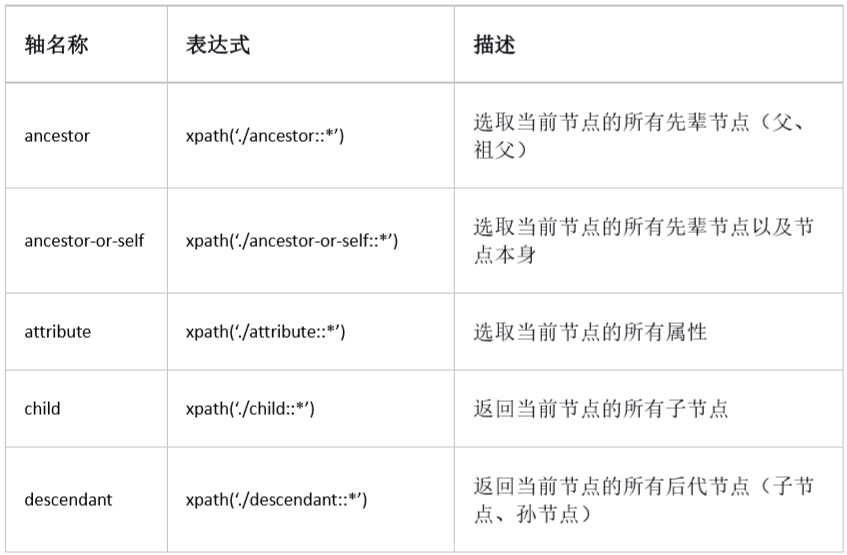
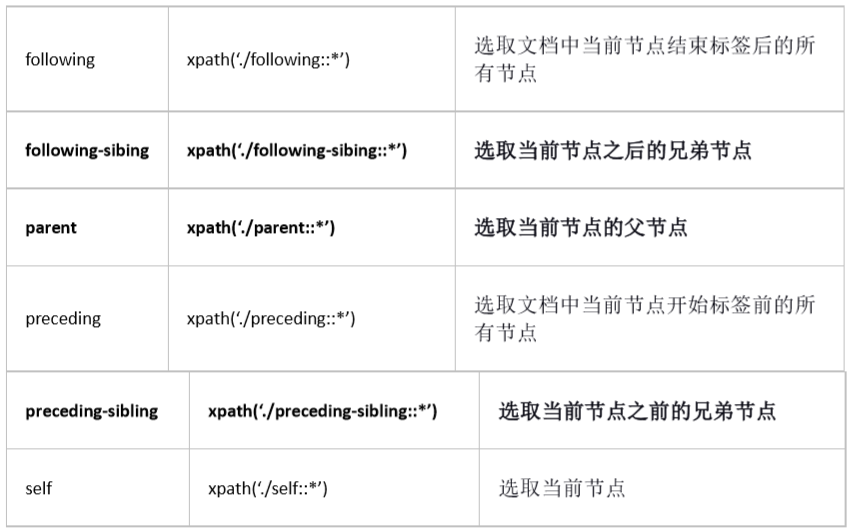
Select several paths
Several paths can be selected by using the'|'operator in the path expression.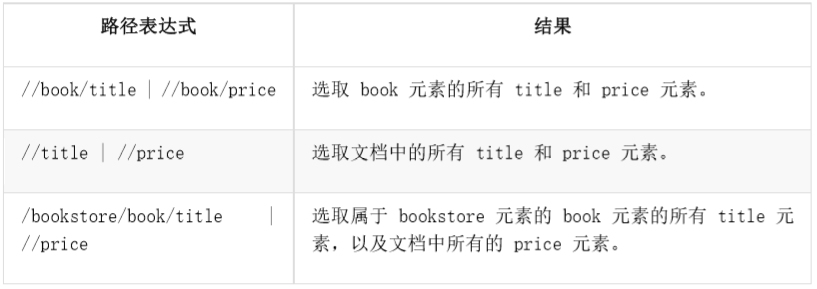
Operator for XPath
The following lists the operators that can be used in XPath expressions: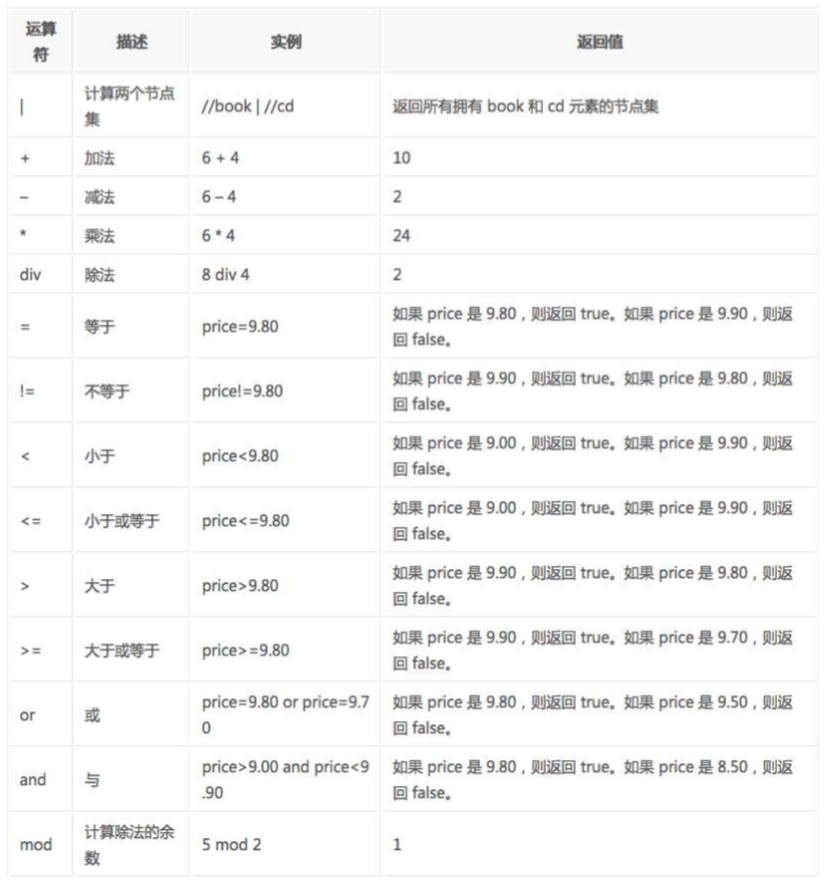
lxml Library
Lxml is a high performance Python HTML/XML parser implemented in C. The main function is to parse and extract HTML/XML data using XPath syntax to quickly locate specific elements and node information.Official lxml python document: http://lxml.de/index.html
install
pip install lxml
Parse HTML code
# etree library using lxml from lxml import etree text = ''' <div> <ul> <li class="item-0"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> # Note that a </li>closed tag is missing here </ul> </div> ''' #Using etree.HTML, parse strings into HTML documents html = etree.HTML(text) # Serialize HTML documents by string result = etree.tostring(html).decode() print(result)
lxml can automatically correct html code, in the example not only completes the li tag, but also adds the body, html tag.
html file parsing
The hello.html file:
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
# lxml_parse.py
from lxml import etree
# Read the external file hello.html
html = etree.parse('./hello.html')
result = etree.tostring(html, pretty_print=True).decode()
print(result)
XPath Instance Test
1. Get all of
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
print(type(html)) # Show etree.parse() return type
result = html.xpath('//li')
print(result) # Print element collection for <li>label
print(len(result))
print(type(result))
print(type(result[0]))
2. Get
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
#result = html.xpath('//li/span')
#Note that this is incorrect:
#Because/is used to get child elements, and <span>is not <li>child elements, use a double slash
result = html.xpath('//li//span')
print(result)
3. Get
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html'
result = html.xpath('//li/a[@href="link1.html"]')
print(result)
4. Get
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/@class')
print(result)
Run Results
[<Element a at 0x10ffaae18>]
5. Getting
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/a//@class')
print(result)
7. Get the contents of the second last element
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li[last()-1]/a')
# text method can get element content
print(result[0].text)
8. Get a label signature whose class value is bold
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//*[@class="bold"]')
# Tag method can get tag name
print(result[0].tag)
A little thought
1. Differences between single quotation marks, double quotation marks, three single quotation marks and three double quotation marks in Python
When you define a string with a single quotation mark'', it assumes that the double quotation mark''inside your string is a normal character and does not need to be escaped.Conversely, when you define a string with double quotation marks, you will think that the single quotation marks inside your string are normal characters and need not be escaped.3 Quotes for Multiline Output Effect
2. Differences between/and//in xpath
/for acquiring child elements, //for acquiring descendants
3. How to get node content?
Select text content with text
** 4. How do I get node properties?**
Use @ to select attributes.
Play a compliment with your hands!!!

