1. Reptile target
It is generally believed that Python crawlers are powerful, but Python has some difficulties in solving dynamic loading or landing websites. Compared with some ordinary crawlers, using R language will be more convenient.
with https://www.thepaper.cn/ For example, the httr package commonly used in dynamic web pages is mainly used to crawl the news (title, content and time) on the home page.
During the initial learning, reference is made to station B< 20 minute introduction to web crawler based on R language_ Beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping beeping >But there was an error in the code operation, so it was modified in the original code.
2. Code analysis and error correction
library(rvest)
library(stringr)
url <-"https://www.thepaper.cn/"
web <- read_html(url) #Functions for reading html web pages
news <- web %>% html_nodes('h2 a')
title <- news %>% html_text() #Get the text part
link <- news %>% html_attrs() #Get the URL corresponding to each title
link1 <- c(1:length(link))
for(i in 1:length(link1))
{
link1[i]<- link[[i]][1]
}
link2 <- paste("https://www.thepaper.cn/",link1,sep="")
##Get the full text of each news
news_content<-c(1:length(link2))
for(i in 1:length(link2))
{
web <- read_html(link2[i])
{
if(length(html_nodes(web,'div.news_txt'))==1)
news_content[i]<- html_text(html_nodes(web,'div.news_txt'))
else
news_content[i]<- trimws(str_replace_all((html_text(html_nodes(web,'div.video_txt_l p'))), "[\r\n]" , ""))
}
}
##Time to get each news
news_date <- c(1:length(link2))
for(i in 1:length(link2))
{
web <- read_html(link2[i])
{
if(length(html_nodes(web,'div.news_txt'))==1)
news_date[i]<- trimws(str_replace_all((html_text((html_nodes(web, "div p"))[2])), "[\r\n]" , ""))
else
news_date[i]<- trimws(str_replace_all((html_text(html_nodes(web,'div.video_txt_l span'))), "[\r\n]" , ""))
}
}
date <- c(1:length(link2))
time <- c(1:length(link2))
for(i in 1:length(link2))
{
date[i] <- substring(news_date[i],1,10)
time[i] <- substring(news_date[i],12,16) # is.character(news_date[i])
}
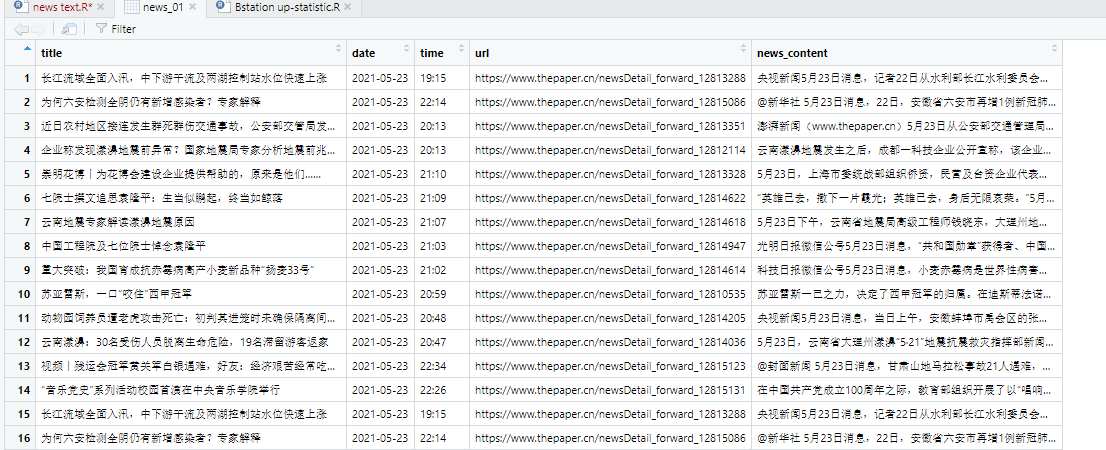
news_01 <- data.frame(title,date,time,url=link2,news_content)
save(news_01,file="news_information.Rdata")
write.csv(news_01,file=" news_information.csv")
Note1:
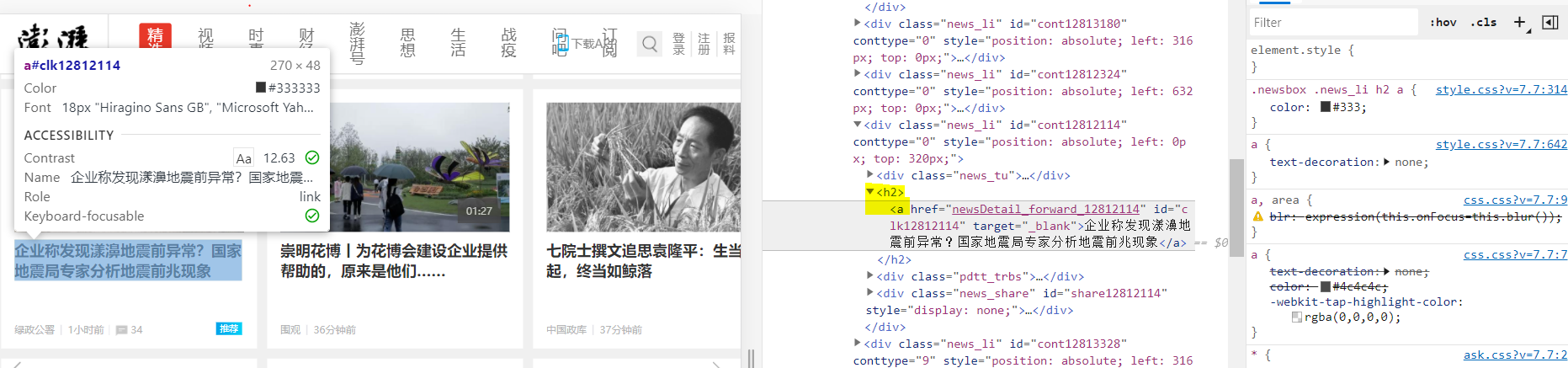
Press F12 to enter the developer page, click a title, and the corresponding node of the title will be a under h2, as shown in the following figure:
Note2:
The original video uses the following code to obtain the text content of daily news, but there is an error: change the parameter length to zero. As follows:
> for(i in 1:length(link2))
+ {
+ news_content[i] <- read_html(link2[i]) %>% html_nodes('div.news_txt') %>% html_text()
+ }
Error in news_content[i] <- read_html(link2[i]) %>% html_nodes("div.news_txt") %>% :
The length of the replacement parameter is zeroThe reason for the error is that there is pure video content in the web page, so the parameter obtained through the "div.news_txt" node is 0. Therefore, in the code of this paper, judge the web page content first, and extract the text content from the text news and video news respectively.
Note3:
Use the following original code to extract the news content every day, but (Ben Xiaobai speculates that the network may be upgraded due to anti climbing!!!)

Therefore, Ben Xiaobai found the corresponding node again and still found it on the developer tool page. The time of the text is at the "div p" node, and the extracted string is a string containing newline characters and spaces; The time of the video page is located in "div.video_txt_l span", and there is a small tail (news source) extracted.
Note4
Most importantly, although there is Warning, it's not important, because I can't solve it. I'm very happy when the result comes out. Life's first reptile, success!
Then I thank the UP Master of station B very much. I hope it doesn't infringe on the rights and interests of others. The above!
3. Strange knowledge has increased
pacman::p_load(XML,rvest,jiebaR,dplyr,stringr) loads multiple packages at one time, including install and library
read_html(): the function of reading html documents (web pages);
html_nodes(): select and extract the part of the specified element and node in the document;
html_text(): extract the text in the tag;
html_attrs(): extract the attribute name and its content;
trimws(): remove the spaces before and after the string;
str_replace_all(): replace. In this article, spaces and line breaks are replaced \ r \ n;
is.character(): judge whether it is in string form