Usages such as requests pymongo BS4
from future import print_function
Prit does not need parentheses in #python2.X, but it does in python3.X.Add this sentence at the beginning, even after
python2.X, using print requires bracketing like python3.X
import requests
Import requests without requests at https://pip.pypa.io/en/stable/**talling/
The first two sentences of this website download pip Download requests with pip x x tall requests
requests is to initiate a request to get the source code of a web page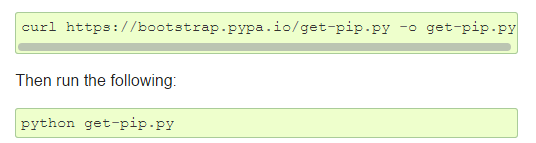
from bs4 import BeautifulSoup
pip x x tall bs4 download bs4 BeautifulSoup is one of Python's third-party libraries bs4
BeautifulSoup library, which is used to parse html code, can help you more easily locate the information you need through Tags
import pymongo
#Source installation mongodb database pip installation pymongo is python link mongodb third party library is the driver
Order, enabling Python programs to use the Mongodb database, written using python.
import json
#json is a lightweight text data exchange format.Is the syntax used to store and exchange text information.
mount this database
1. Source installation mongodb https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-3.2.5.tgz Unzip the mongodb source package and place it in/usr/local
2 mkdir -p /data/db
3.cd /usr/local/mongodb/bin
./mongod &
./mongo
exit Exit
View the contents of the database:
cd/usr/local/mongodb/bin
./mongo
show dbs
Database: iaaf
use iaaf
show collections
db.athletes.find()
Crawler processes
Step 1: Extract HTML information from your website
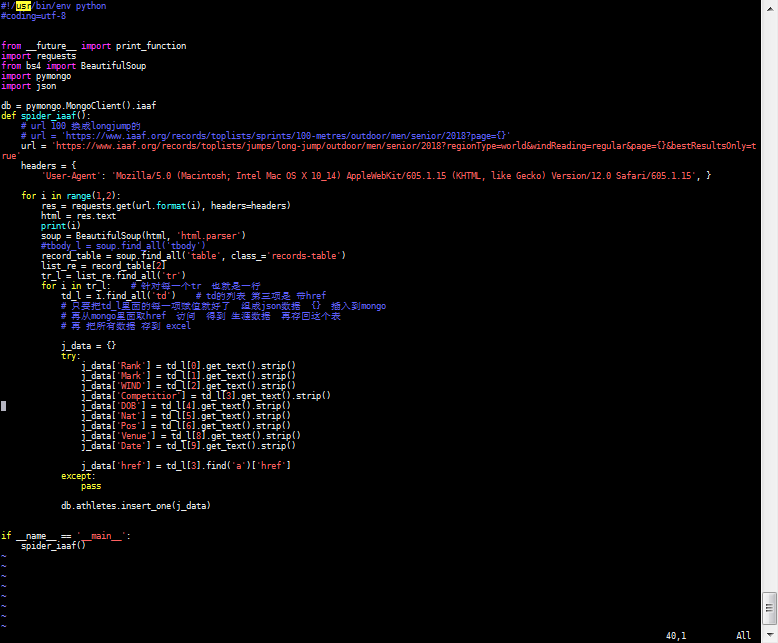
#Required web address
url = 'https://www.iaaf.org/records/toplists/jumps/long-jump/outdoor/men/senior/2018?regionType=world&windReading=regular&page={}&bestResultsOnly=true'
#Use headers to set the request header, masquerading the code as a browser
headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0 Safari/605.1.15', }
for i in range(1,23):
res = requests.get(url.format(i), headers=headers)
html = res.text
print(i)
soup = BeautifulSoup(html, 'html.parser') #Use BeautifulSoup to parse this code
#tbody_l = soup.find_all('tbody')
record_table = soup.find_all('table', class_='records-table')
list_re = record_table[2]
tr_l = list_re.find_all('tr')
for i in tr_l: # One line for each tr
td_l = i.find_all('td') # The third item in the td list is with href
# Simply insert each assignment in td_l into the mongo that makes up the json data {}
# Retake href access from mongo to get career data and save it back to this table
# Save all data to excel
j_data = {}
try:
j_data['Rank'] = td_l[0].get_text().strip()
j_data['Mark'] = td_l[1].get_text().strip()
j_data['WIND'] = td_l[2].get_text().strip()
j_data['Competitior'] = td_l[3].get_text().strip()
j_data['DOB'] = td_l[4].get_text().strip()
j_data['Nat'] = td_l[5].get_text().strip()
j_data['Pos'] = td_l[6].get_text().strip()
j_data['Venue'] = td_l[8].get_text().strip()
j_data['Date'] = td_l[9].get_text().strip()
j_data['href'] = td_l[3].find('a')['href']
#Save the data you want in a dictionaryStep 2: Extract the information we want from HTML
#!/usr/bin/env python
#encoding=utf-8
from future import print_function
import requests
from bs4 import BeautifulSoup as bs
def long_jump(url):
url = 'https://www.iaaf.org/athletes/cuba/juan-miguel-echevarria-294120'
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0 Safari/605.1.15'}
res = requests.get(url, headers=headers)
html = res.text
soup = bs(html,'html.parser')
div = soup.find('div', id='progression')
h2_l = []
if div != None:
h2_l = div.find_all('h2')
tbody_l = []
outdoor = []
indoor = []
for i in h2_l: # Get the h2 tag
text = str(i.get_text().strip())
if "Long Jump" in text and "View Graph" in text:
tbody = i.parent.parent.table.tbody
#print(tbody) # Can get the data inside
# Two for outdoor and one for indoor
tbody_l.append(tbody)
# Get two elements of tbody one for outdoor and one for indoor use try except
# Group two json data outdoor={} indoor={}
# db. * x * ert() Print first
try:
tbody_out = tbody_l[0]
tbody_in = tbody_l[1]
tr_l = tbody_out.find_all('tr')
for i in tr_l:
# print(i)
# print('+++++++++++++')
td_l = i.find_all('td')
td_dict = {}
td_dict['Year'] = str(td_l[0].get_text().strip())
td_dict['Performance'] = str(td_l[1].get_text().strip())
td_dict['Wind'] = str(td_l[2].get_text().strip())
td_dict['Place'] = str(td_l[3].get_text().strip())
td_dict['Date'] = str(td_l[4].get_text().strip())
outdoor.append(td_dict)
# print(outdoor)
# print('+++++++++++++++')
tr_lin = tbody_in.find_all('tr')
for i in tr_lin:
td_l = i.find_all('td')
td_dict = {}
td_dict['Year'] = str(td_l[0].get_text().strip())
td_dict['Performance'] = str(td_l[1].get_text().strip())
td_dict['Place'] = str(td_l[2].get_text().strip())
td_dict['Date'] = str(td_l[3].get_text().strip())
indoor.append(td_dict)
# print(indoor)
except:
pass
return outdoor, indoor
if __name__ == '__main__':
long_jump(url'https://www.iaaf.org/athletes/cuba/juan-miguel-echevarria-294120')After getting the HTML code for the whole page, we need to extract the data of the athletes'long jump from the whole page
Step 3: Store the extracted data in a database
#!/usr/bin/env python
#coding=utf-8
from future import print_function
import pymongo
import requests
from bs4 import BeautifulSoup
import json
from long_jump import *
db = pymongo.MongoClient().iaaf
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0 Safari/605.1.15'}
def get_href():
Responsible for removing href from mongo, fetching and accessing the resulting data and storing it in the original table
href_list = db.athletes.find()
# 794
count = 0
for i in href_list:
# Take id to insert crawled career data back based on id
print(count)
href = i.get('href')
outdoor = []
indoor = []
if href == None:
pass
else:
url = 'https://www.iaaf.org'+ str(href)
outdoor, indoor = long_jump(url)
db.athletes.update({'_id':i.get('_id')},{"$set":{"outdoor":outdoor,"indoor":indoor}})
count += 1def get_progression():
pass
if name == 'main':
get_href()
Step 4: Write database contents to excel according to country
#!/usr/bin/env python
#coding=utf-8
from future import print_function
import xlwt
import pymongo
def write_into_xls(cursor):
title = ['Rank','Mark','age','Competitior','DOB','Nat','country','Venue','Date','out_year','out_performance','out_wind','out_place','out_date','in_year','in_performance','in_place','in_date']
book = xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet = book.add_sheet('iaaf',cell_overwrite_ok=True)
for i in range(len(title)):
sheet.write(0, i, title[i])
# db = pymongo.MongoClient().iaaf
# cursor = db.athletes.find()
flag = 1
db = pymongo.MongoClient().iaaf
country_l = ['CUB', 'RSA', 'CHN', 'USA', 'RUS', 'AUS', 'CZE', 'URU', 'GRE', 'JAM', 'TTO', 'UKR', 'GER', 'IND', 'BRA', 'GBR', 'CAN', 'SRI', 'FRA', 'NGR', 'POL', 'SWE', 'JPN', 'INA', 'GUY', 'TKS', 'KOR', 'TPE', 'BER', 'MAR', 'ALG', 'ESP', 'SUI', 'EST', 'SRB', 'BEL', 'ITA', 'NED', 'FIN', 'CHI', 'BUL', 'CRO', 'ALB', 'KEN', 'POR', 'BAR', 'DEN', 'PER', 'ROU', 'MAS', 'CMR', 'TUR', 'PHI', 'HUN', 'VEN', 'HKG', 'PAN', 'BLR', 'MEX', 'LAT', 'GHA', 'MRI', 'IRL', 'ISV', 'BAH', 'KUW', 'NOR', 'SKN', 'UZB', 'BOT', 'AUT', 'PUR', 'DMA', 'KAZ', 'ARM', 'BEN', 'DOM', 'CIV', 'LUX', 'COL', 'ANA', 'MLT', 'SVK', 'THA', 'MNT', 'ISR', 'LTU', 'VIE', 'IRQ', 'NCA', 'ARU', 'KSA', 'ZIM', 'SLO', 'ECU', 'SYR', 'TUN', 'ARG', 'ZAM', 'SLE', 'BUR', 'NZL', 'AZE', 'GRN', 'OMA', 'CYP', 'GUA', 'ISL', 'SUR', 'TAN', 'GEO', 'BOL', 'ANG', 'QAT', 'TJK', 'MDA', 'MAC']
for i in country_l:
cursor = db.athletes.find({'Nat':i})
for i in cursor:
print(i)
count_out = len(i['outdoor'])
count_in = len(i['indoor'])
count = 1
if count_out >= count_in:
count = count_out
else:
count = count_in
if count == 0:
count = 1
# The number of rows count ed for this data
# title = ['Rank','Mark','Wind','Competitior','DOB','Nat','Pos','Venue',
# 'Date','out_year','out_performance','out_wind','out_place','out_date',
# 'in_year','in_performance','in_place','in_date']
sheet.write(flag, 0, i.get('Rank'))
sheet.write(flag, 1, i.get('Mark'))
sheet.write(flag, 2, i.get('age'))
sheet.write(flag, 3, i.get('Competitior'))
sheet.write(flag, 4, i.get('DOB'))
sheet.write(flag, 5, i.get('Nat'))
sheet.write(flag, 6, i.get('country'))
sheet.write(flag, 7, i.get('Venue'))
sheet.write(flag, 8, i.get('Date'))
if count_out > 0:
for j in range(count_out):
sheet.write(flag+j, 9, i['outdoor'][j]['Year'])
sheet.write(flag+j, 10, i['outdoor'][j]['Performance'])
sheet.write(flag+j, 11, i['outdoor'][j]['Wind'])
sheet.write(flag+j, 12, i['outdoor'][j]['Place'])
sheet.write(flag+j, 13, i['outdoor'][j]['Date'])
if count_in > 0:
for k in range(count_in):
sheet.write(flag+k, 14, i['indoor'][k]['Year'])
sheet.write(flag+k, 15, i['indoor'][k]['Performance'])
sheet.write(flag+k, 16, i['indoor'][k]['Place'])
sheet.write(flag+k, 17, i['indoor'][k]['Date'])
flag = flag + count
book.save(r'iaaf.xls')
# Start fetching data from the database from the first row if name == 'main':
write_into_xls(cursor=None)
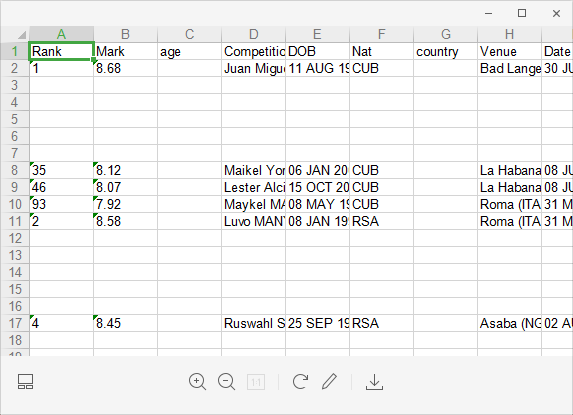
After running the above code, what we get is