Hello, I'm 👉 [year of fighting]
This issue introduces you step by step how to crawl all the Q & a related data. I hope it will be helpful to you.
Target website:
https://www.zhihu.com/question/368550554
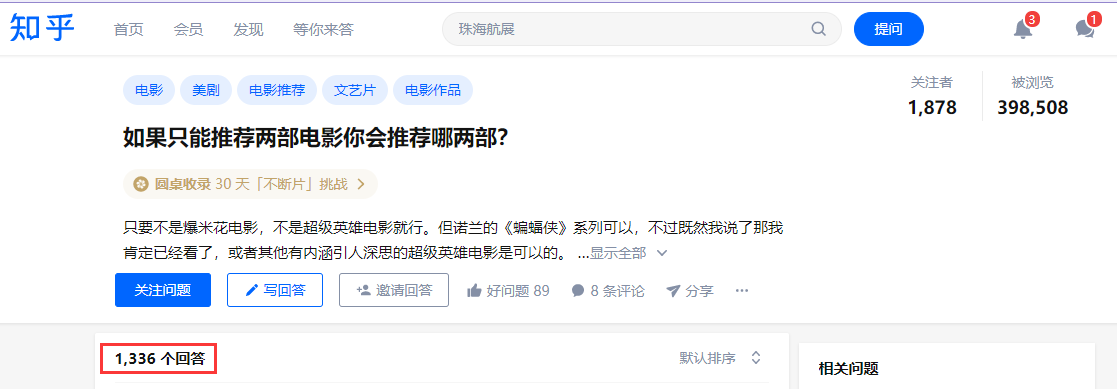
Crawl field: crawl the release time, author, approval number, content, etc. of all answers under the question (other fields can be added as needed).
1. Web page analysis
1.1 web page debugging
F12 open the browser debugging window to find the url of the loaded data. Because you know the display restrictions of the Q & a page, you need to load several more pages down to find the rules:
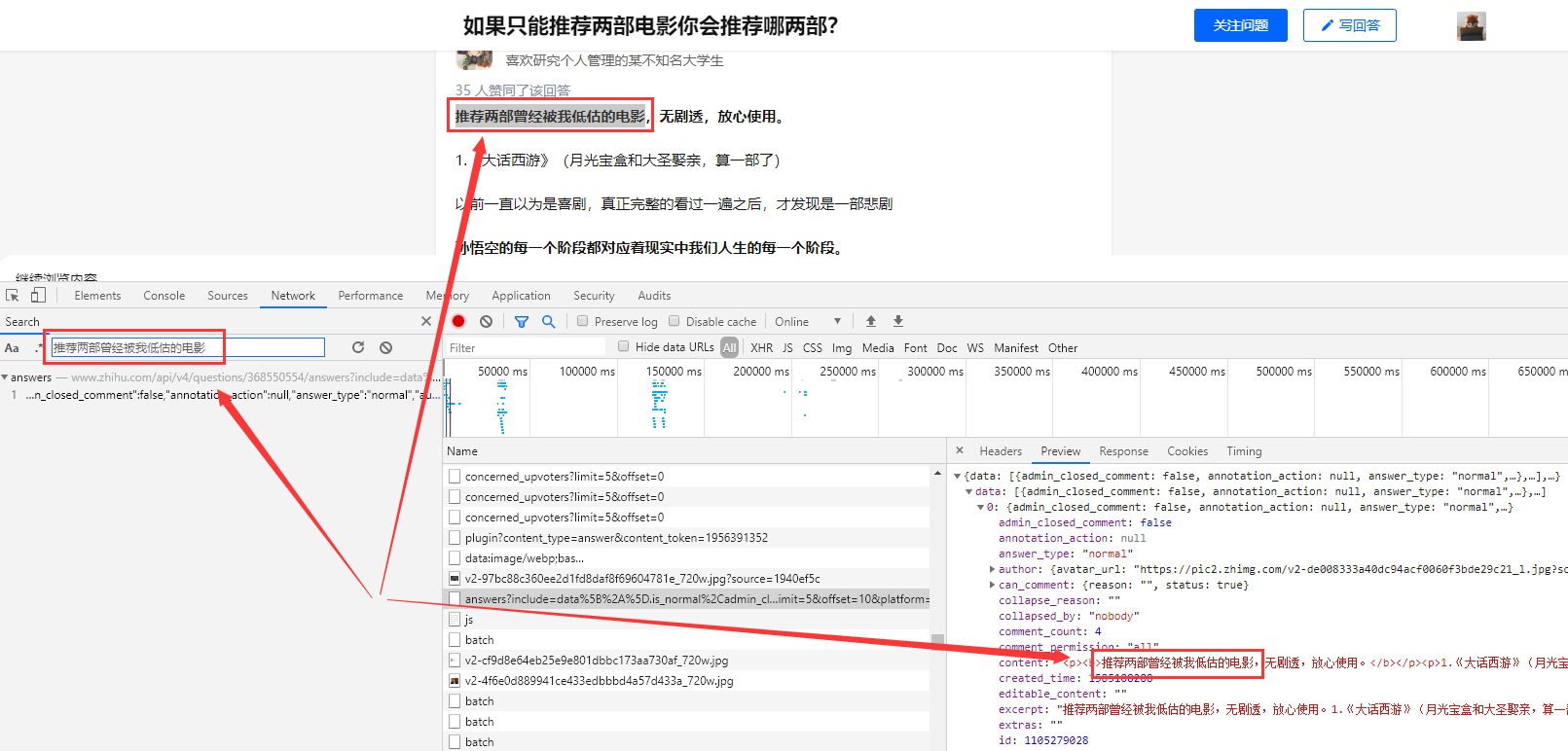
Search the web content arbitrarily. Take the sentence "recommend two movies that have been underestimated by me" as an example. As shown in the above figure, we are in answers
The answer content is found under the url of this index, and it is completely consistent.
1.2 request parameter analysis
Requested URL:
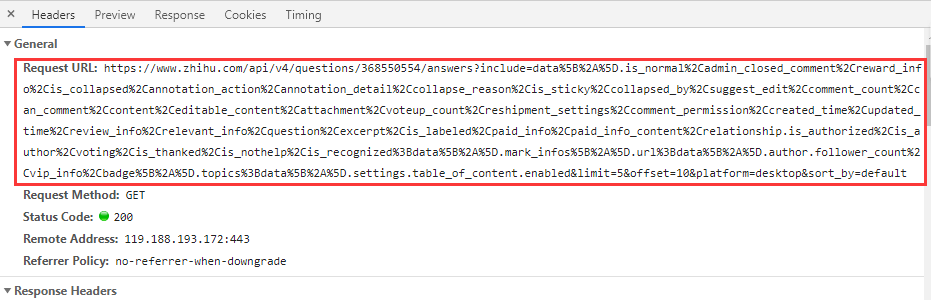
Data parameter:
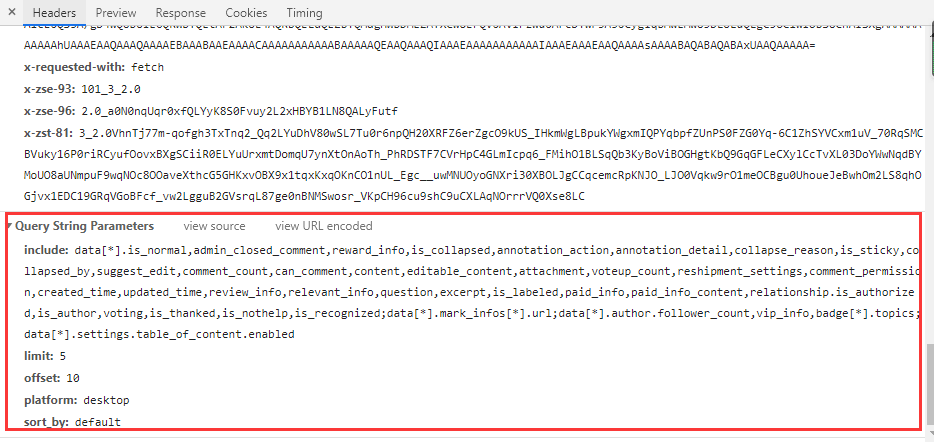
Here, focus on the limit and offset parameters. What are the functions of these two parameters? Let's search the answers link to see:
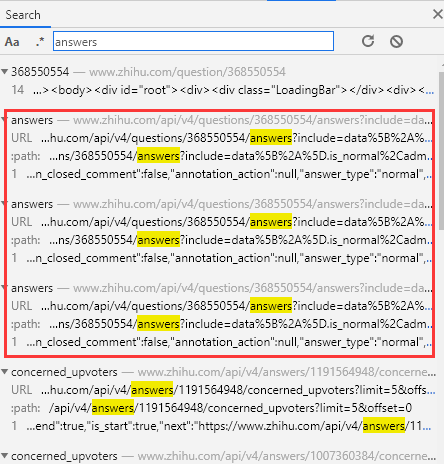
Rule: the limit is always 5, and the offset increases with 5 as the tolerance (5 / 10 / 15 / 20...)
In fact, limit means to return 5 answers per request, and offset means to start from the first few answers.
2. Data crawling
2.1 crawling test
According to the URL analyzed above, let's construct a request to test:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36',
}
for i in range(2):
url = f'https://www.zhihu.com/api/v4/questions/368550554/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset={i}&platform=desktop&sort_by=default'
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = 'utf-8'
datas = json.loads(r.text)
for info in datas['data']:
author = info['author']['name']
created_time = time.strftime("%Y/%m/%d %H:%M:%S", time.localtime(info['created_time']))
voteup_count = info['voteup_count']
text = info['excerpt']
oneinfo = [created_time,author,voteup_count,text]
print(oneinfo)
print('+++++++++++++++++++++++++++')
result:

So we can loop through all the data.
After testing, the limit can be changed to 20 at most, so that the number of cycles will be reduced to one quarter of the original.
2.2 optimization
According to the above crawling methods, we need to know how many pages of data there are in advance, and then we can determine the number of cycles.
Number of cycles = int (number of data pieces / offset)
In fact, careful friends will find that when we obtain the pilot data, we also have some page information:
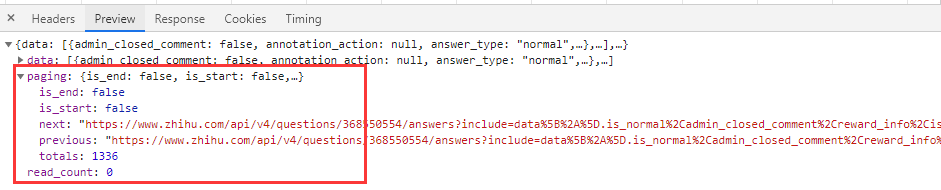
The following is given directly:
previous link
Link to next page (next)
Is it _start
Is it_end
Total
Recursive crawling:
def getinfo(url, headers):
allinfo = []
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = 'utf-8'
datas = json.loads(r.text)
for info in datas['data']:
author = info['author']['name']
created_time = time.strftime("%Y/%m/%d %H:%M:%S", time.localtime(info['created_time']))
voteup_count = info['voteup_count']
text = info['excerpt']
oneinfo = [created_time,author,voteup_count,text]
print(oneinfo)
allinfo.append(oneinfo)
next_url = datas['paging']['next']
if datas['paging']['is_end']:
print('----')
return
time.sleep(random.uniform(0.1, 20.1))
return getinfo(next_url, headers)
except:
return getinfo(next_url, headers)
3. Save data
3.1 openpyxl
Here we use openpyxl to save data to Excel. You can also try to save other files or databases:
def insert2excel(filepath,allinfo):
try:
if not os.path.exists(filepath):
tableTitle = ['Release time', 'user name', 'Approval number', 'content']
wb = Workbook()
ws = wb.active
ws.title = 'sheet1'
ws.append(tableTitle)
wb.save(filepath)
time.sleep(3)
wb = load_workbook(filepath)
ws = wb.active
ws.title = 'sheet1'
for info in allinfo:
ws.append(info)
wb.save(filepath)
print('File updated')
except:
print('File update failed')
effect:

3.2 complete code
The following is all the code, which can be run directly locally. There are many places that can be optimized, which can be modified by the partners themselves:
import os
import json
import time
import math
import random
import requests
from openpyxl import load_workbook, Workbook
# data acquisition
def getinfo(url, headers):
allinfo = []
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = 'utf-8'
datas = json.loads(r.text)
for info in datas['data']:
author = info['author']['name']
created_time = time.strftime("%Y/%m/%d %H:%M:%S", time.localtime(info['created_time']))
voteup_count = info['voteup_count']
text = info['excerpt']
oneinfo = [created_time,author,voteup_count,text]
print(oneinfo)
allinfo.append(oneinfo)
next_url = datas['paging']['next']
insert2excel(filepath,allinfo)
if datas['paging']['is_end']:
print('----')
return
time.sleep(random.uniform(5.1, 20.1))
return getinfo(next_url, headers)
except:
return getinfo(next_url, headers)
# Data saving
def insert2excel(filepath,allinfo):
try:
if not os.path.exists(filepath):
tableTitle = ['Release time', 'user name', 'Approval number', 'content']
wb = Workbook()
ws = wb.active
ws.title = 'sheet1'
ws.append(tableTitle)
wb.save(filepath)
time.sleep(3)
wb = load_workbook(filepath)
ws = wb.active
ws.title = 'sheet1'
for info in allinfo:
ws.append(info)
wb.save(filepath)
print('File updated')
except:
print('File update failed')
url = 'https://www.zhihu.com/api/v4/questions/368550554/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=20&offset=0&platform=desktop&sort_by=default'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36',
}
filepath = '368550554.xlsx'
getinfo(url, headers)
The above is all the content sorted out for you in this issue. Practice quickly. It's not easy to be original. Friends who like can praise, collect or share (indicate the source) to let more people know.
Recommended reading
Climb to 20000 + film review data analysis visualization of white snake 2: green snake robbery
Visual | Python analysis of mid autumn moon cakes, these flavors are yyds!!!
123 Pandas common basic instructions, really fragrant!
Crawler + visualization | dynamic display of the world distribution of medals in 2020 Tokyo Olympic Games
Pandas+Pyecharts | second hand housing data analysis + visualization on a platform in Beijing
Pandas+Pyecharts | 2021 comprehensive ranking analysis of Chinese universities + visualization
Visual | Python drawing geographic track map of high color typhoon
Visualization | analyze nearly 5000 tourist attractions in Python and tell you where to go during the holiday
Visual | Python exquisite map dynamic display of GDP of provinces and cities in China in recent 20 years
Visualization | Python accompany you 520: by your side, by your side
Reptile Python gives you a full set of skin on the official website of King glory
Crawlers use python to build their own IP proxy pool. They don't worry about insufficient IP anymore!
Tips | 20 most practical and efficient shortcut keys of pychar (dynamic display)
Tips | 5000 words super full parsing Python three formatting output modes [% / format / f-string]
Tips | python sends mail regularly (automatically adds attachments)
Reptile Python gives you a full set of skin on the official website of King glory
Crawlers use python to build their own IP proxy pool. They don't worry about insufficient IP anymore!
The article starts with WeChat official account "Python when the year of the fight", every day there are python programming skills push, hope you can love it.
