1, Code
1. Write directly from top to bottom
import os
import sys
import requests
import re
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
if __name__ == '__main__':
# Input the video number and obtain the cid by constructing the get request of bvid
video_bvid = input("video id: ")
video_api = "https://api.bilibili.com/x/player/pagelist?bvid=" + video_bvid + "&jsonp=jsonp"
header = {
# These two lines cannot be added randomly, otherwise the request module will encode according to this coding form, resulting in garbled code
# 'Accept-Encoding': 'gzip, deflate, br',
# 'Accept-Language': 'zh-CN,zh;q=0.9',
"origin": "https://www.bilibili.com",
"Referer": "https://www.bilibili.com/video/" + video_bvid,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4506.400"
}
video_json = requests.get(url=video_api, headers=header).json()
detail = video_json['data'][0]
# Get cid (and video name)
video_cid = detail['cid']
video_name = detail['part']
param = {
"cid": video_cid,
"qn": "80",
"type": "",
"otype": "json",
"bvid": video_bvid,
"fnval": "1"
}
download_url = "https://api.bilibili.com/x/player/playurl"
download_json = requests.get(url=download_url, headers=header, params=param).json()
durl = download_json["data"]["durl"][0]
video_size = durl["size"]
video_url = durl["url"]
video_length = durl["length"]
# Start downloading the annotated auxiliary functions
# size = 0
response = requests.get(url=video_url, headers=header, stream=True, verify=False)
chunk_size = 1024
content_size = int(response.headers['content-length'])
if response.status_code == 200:
# sys.stdout.write('[file size]:% 0.2f MB \ n'% (content_size / chunk_size / 1024))
filename = "D:\\python_file\\" + video_name + ".mp4"
with open(filename, 'wb') as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
# size += len(data)
# file.flush()
# sys.stdout.write('[download progress]:%. 2F%%'% float (size / content_size * 100) + '\ R')
# if size / content_size == 1:
# print('\n')
file.close()
print("Download complete")
else:
print("Download error")
2. The code is decomposed into functions and is itself a class
import requests
import os, sys
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
class Reptile():
def __init__(self):
# Video number video name download path video time definition get cid url video url get cid header get video header don't know video size
self.cid = 0
self.name = ""
self.path = "D:\\python_file\\"
self.duration = ""
self.qn = 80
self.cid_url = 'https://api.bilibili.com/x/player/pagelist?bvid={}&jsonp=jsonp'
self.video_url = 'https://api.bilibili.com/x/player/playurl?bvid={}&cid={}&qn={}&type=&otype=json&fnval=1'
self.length = ""
self.size = ""
self.cid_headers = {
'host': 'api.bilibili.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
self.video_headers = {
'host': '',
'Origin': 'https://www.bilibili.com',
'Referer': 'https://www.bilibili.com/video/{}',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
def getCid(self, url):
# Get cid
cid_json = requests.get(url=url, headers=self.cid_headers).json()
detail = cid_json['data'][0]
self.cid = detail['cid']
self.name = detail['part']
self.duration = detail['duration']
def getUrl(self, url):
# Get video url (mp4)
video_json = requests.get(url=url, headers=self.cid_headers).json()
durl = video_json['data']['durl'][0]
self.size = durl['size']
self.video_url = durl['url']
self.length = durl['length']
def download(self):
# download
size = 0
response = requests.get(self.video_url, headers=self.video_headers, stream=True, verify=False)
chunk_size = 1024
content_size = int(response.headers['content-length'])
if response.status_code == 200:
sys.stdout.write(' [file size]:%0.2f MB\n' % (content_size / chunk_size / 1024))
self.path += self.name
print(self.path)
with open(self.path, 'wb') as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
size += len(data)
file.flush()
sys.stdout.write(' [Download progress]:%.2f%%' % float(size / content_size * 100) + '\r')
if size / content_size == 1:
print('\n')
else:
print('Download error')
def start(self, bvid):
# start
self.getCid(self.cid_url.format(bvid))
self.getUrl(self.video_url.format(bvid, self.cid, self.qn))
self.video_headers['host'] = self.video_url.split('/')[2]
self.name = self.name.replace(' ', '_') + '.mp4'
print("name: {0} duration:{1}s".format(self.name, self.duration))
self.download()
if __name__ == '__main__':
bilibili = Reptile()
video_list = ["BV17E411o7ye"]
for i in video_list:
bilibili.start(bvid=i)
3. Use thread pool + function
import requests
import os, sys
from lxml import etree
from multiprocessing.dummy import Pool
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
def get_cid(video):
# Get cid
video_json = requests.get(url=video["cid_url"].format(video["bvid"]), headers=video["cid_header"]).json()
detail = video_json['data'][0]
video["cid"] = detail['cid']
video["name"] = detail['part'].replace(' ', '_') + '.mp4'
video["duration"] = detail["duration"]
def get_videourl(video):
# Get the url of the video (mp4 format)
video["video_header"]["host"] = video["video_url"].split('/')[2]
video_json = requests.get(url=video["video_url"].format(video["bvid"], video["cid"]),
headers=video["video_header"]).json()
durl = video_json['data']['durl'][0]
video["size"] = durl['size']
video["video_url"] = durl['url']
video["length"] = durl['length']
def get_download(video):
size = 0
video["video_header"]["host"] = video["video_url"].split('/')[2]
response = requests.get(url=video["video_url"], headers=video["video_header"], stream=True, verify=False)
chunk_size = 1024
content_size = int(response.headers['content-length'])
if response.status_code == 200:
sys.stdout.write(video["name"] + ' [file size]:%0.2f MB\n' % (content_size / chunk_size / 1024))
with open("D:\\python_file\\" + video["name"], 'wb') as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
size += len(data)
file.flush()
sys.stdout.write(video["name"] + ' [Download progress]:%.2f%%' % float(size / content_size * 100) + '\r')
if size / content_size == 1:
print('\n')
else:
print('Download error')
if __name__ == '__main__':
# The process pool has four sizes
pool = Pool(4)
# bvid list
bvid_list = ["BV17E411o7ye"]
videos = []
for bvid in bvid_list:
data = {
"cid": "",
"bvid": bvid,
"name": "",
"duration": "",
"length": "",
"size": "",
"cid_url": "https://api.bilibili.com/x/player/pagelist?bvid={}&jsonp=jsonp",
"video_url": "https://api.bilibili.com/x/player/playurl?bvid={}&cid={}&qn=80&type=&otype=json&fnval=1",
# The public part can be mentioned outside
"cid_header": {
"host": "api.bilibili.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4506.400"
},
"video_header": {
"host": "",
"Origin": "https://www.bilibili.com",
"Referer": "https://www.bilibili.com/video/" + bvid,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4506.400"
}
}
videos.append(data)
pool.map(get_cid, videos)
pool.map(get_videourl, videos)
for i in videos:
print("name:{0} duration:{1}s Download address: D:\\python_file\\{2}".format(i["name"], i["duration"], i["name"]))
pool.map(get_download, videos)
2, Precautions
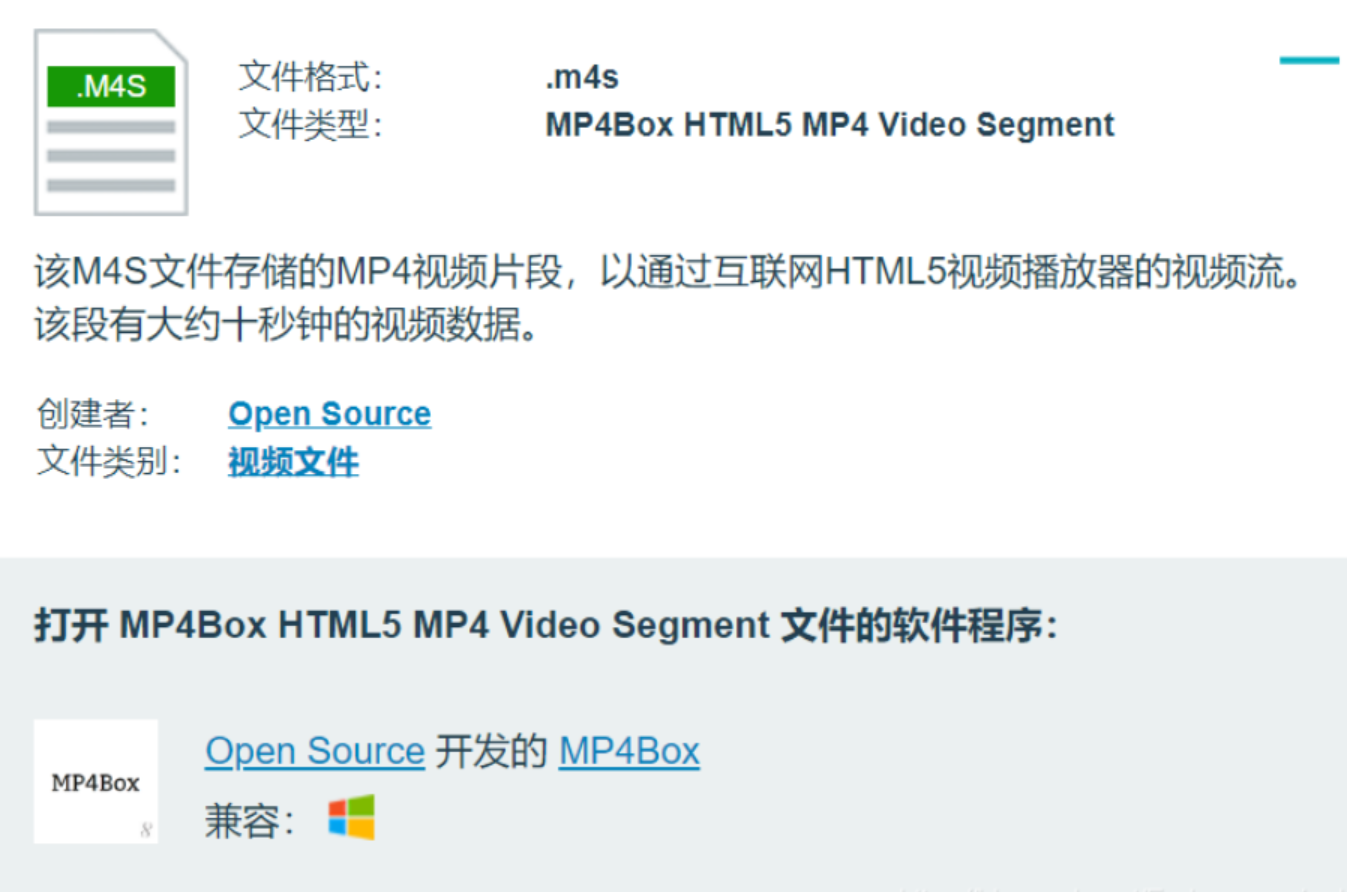
1. Video format: m4s,flv,mp4
1. m4s:
2. flv:

3. mp4
It's the serious mp4
4. General
In other words, most of the videos played on Web pages are in FLV format, and then flv is sliced into many m4s?
2. blob
Blob URL s can only be generated internally by the browser. URL.createObjectURL() A reference to a special Blob or File object will be created and can be published later URL.revokeObjectURL() . these URL s can only be used locally in a single instance of the browser and in the same session (that is, the life cycle of the page / document).
Blob URL / Object URL is a pseudo protocol that allows blob and File objects to be used as URL sources for images, downloading binary data links, etc.
At first, the database directly used Blob to store binary data objects, so we don't have to pay attention to the format of storing data. In the web field, Blob object represents a class file object of read-only original data. Although it is binary original data, it is similar to file object, so Blob object can be operated like file object.
3, Train of thought
Now look in the web page to see if you can find the video download address

After that, I found such a string of things. Then I searched the blog and found that this is a new knowledge point, and then the back website can't be used
So I chose to grab the bag
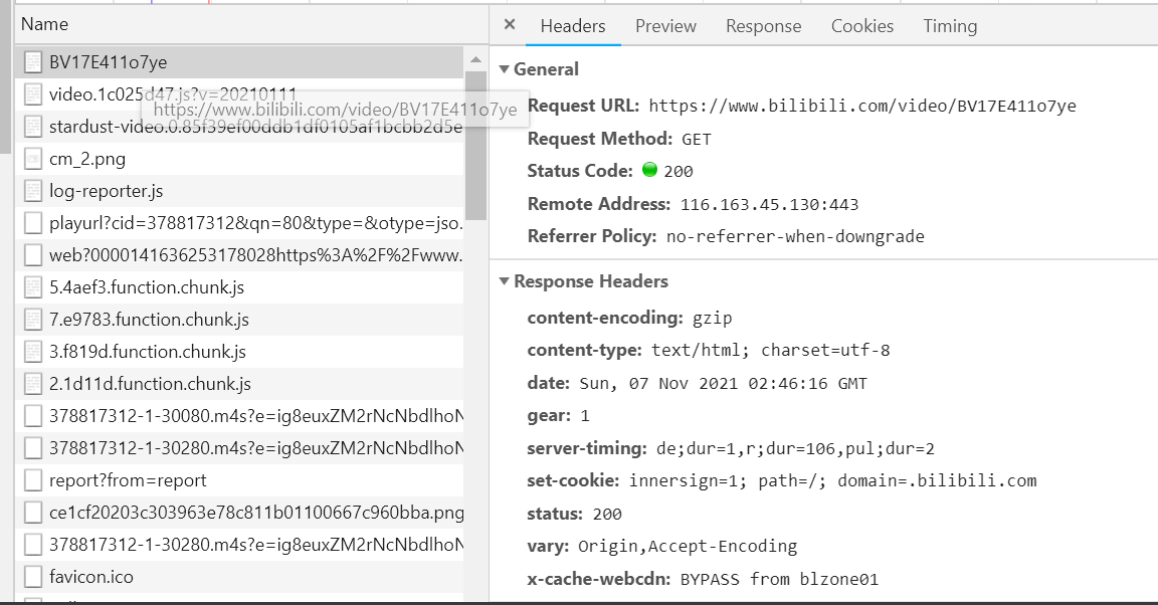
I first went to the first package and found that his response was just a page with no reference value, so I continued to look for useful information
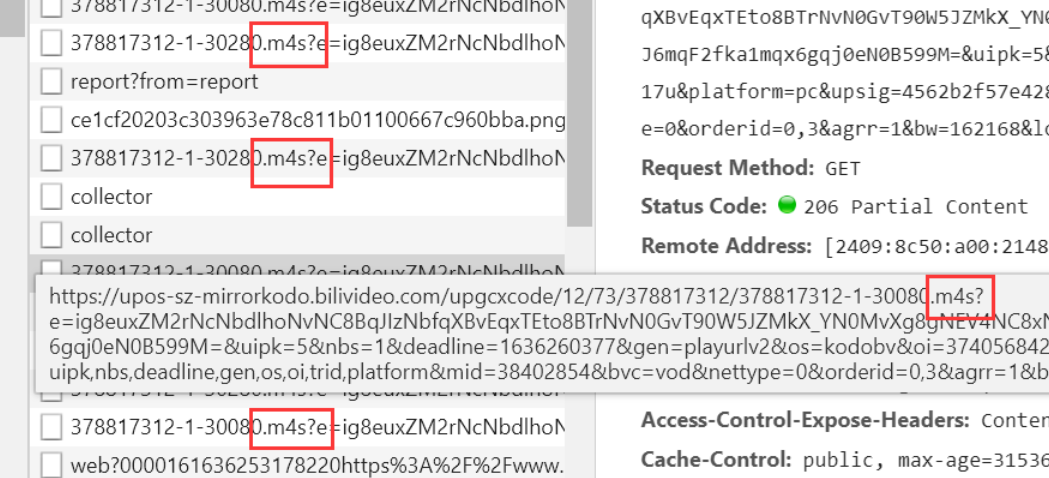
After that, I found the m4s format request, and then searched it. I found that it was a video format. I guessed boldly that this was the video I was looking for, but these requests were too scattered. I couldn't catch them at all, so I had to continue looking for other packages
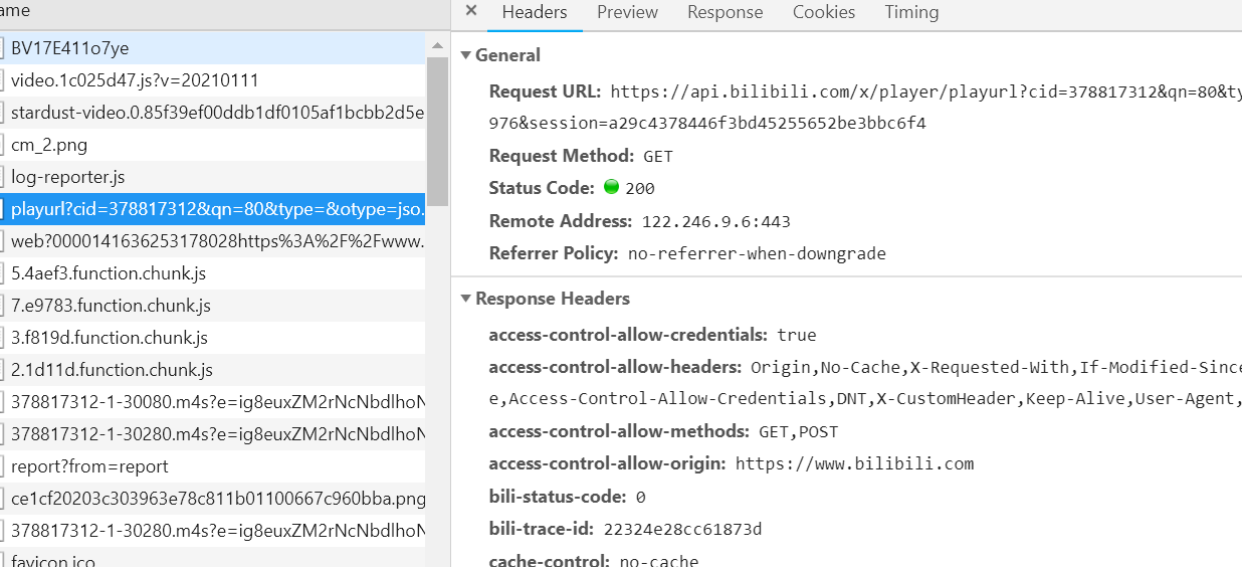
Then I found this. His response is json, which contains the URLs of many m4s files

In fact, you can make a bold guess at this time. This is the url of those m4s format requests I found before
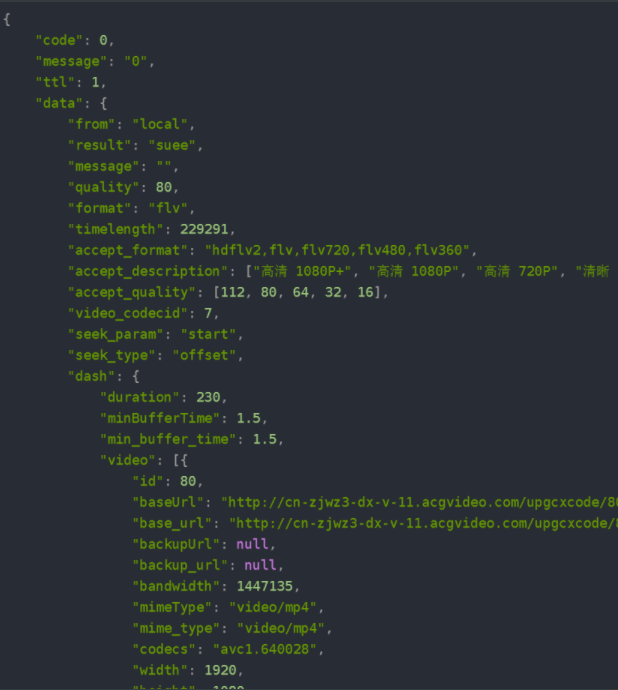
Crack it with json conversion tool, that's it

So now the question becomes how to get the url of the request header

After searching for data and previous knowledge, I probably know what these parameters mean
The next problem is to find cid, so keep looking
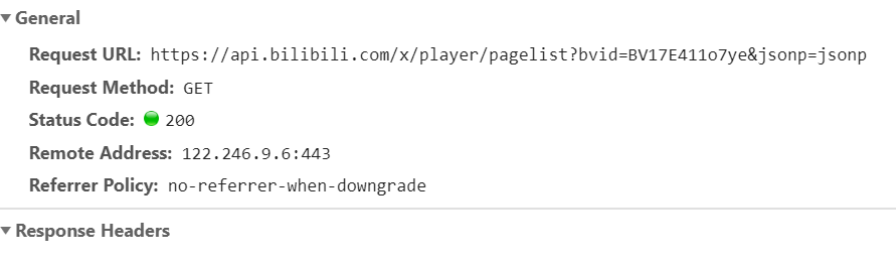
After unremitting efforts, he finally found this. His return is json, including cid

That is, I can find the cid through bvid, and then construct parameters to obtain the video url
Then there's the next question. I did get the url of the video m4s file, but I can't analyze so many m4s files (too delicious)
So I continued Baidu and found that the returned video format type can be changed through the fnval parameter. Therefore, when constructing the parameter, I let fnval=1 to directly obtain the video in mp4 format
Then there is the download operation