Due to an introductory course in Python next semester
So I've been groping for myself during the winter vacation. After all, I can't drop out at that time. It's also a water credit
On a whim recently, I plan to try climbing Baidu translation
After a day's work, the liver finally came out
Don't talk too much and start it directly (the environment is Python 3.8 PyCharm Community Edition 2021.3.1)
Basic steps
Baidu translator will recognize crawlers, so you have to hide them with headers
Take chorme browser as an example
Right click on Baidu translation page and select "check" (or directly F12)
The following interface is displayed
Select network fetch / XHR headers
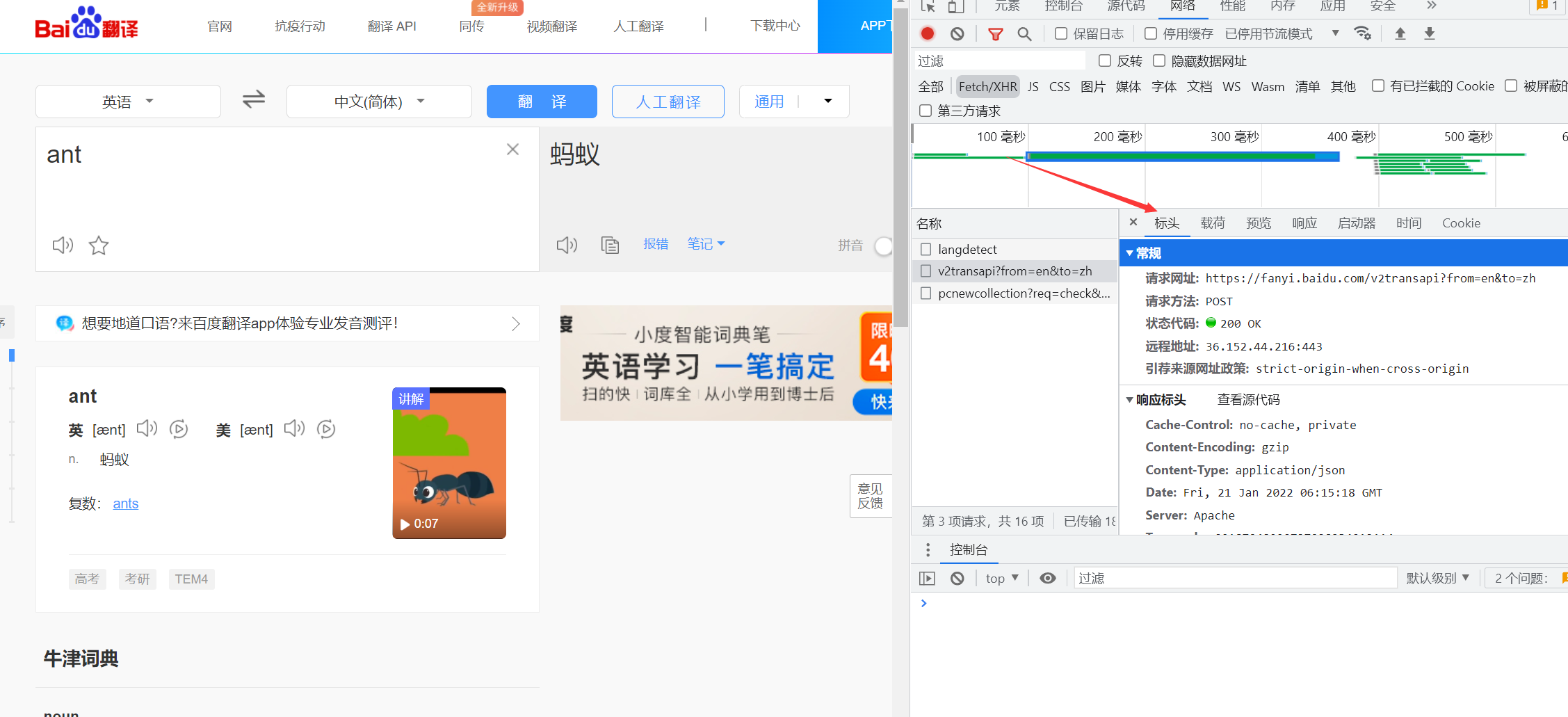
Then we can see the header we need
What we need are cookies and user agent, which are used to indicate that a specific user opens this website through a browser
That is, camouflage reptiles
Then we can copy it into pychar
1 headers = {"User-Agent": Your User-Agent, "Cookie": Your Cookie} 2 # Fill in the information you obtained later User-Agent and Cookie that will do
Submit Form
After the camouflage, you need to prepare the crawler to submit the form to the website
But before we submit, we need to see what data we want to submit
Continue viewing the website
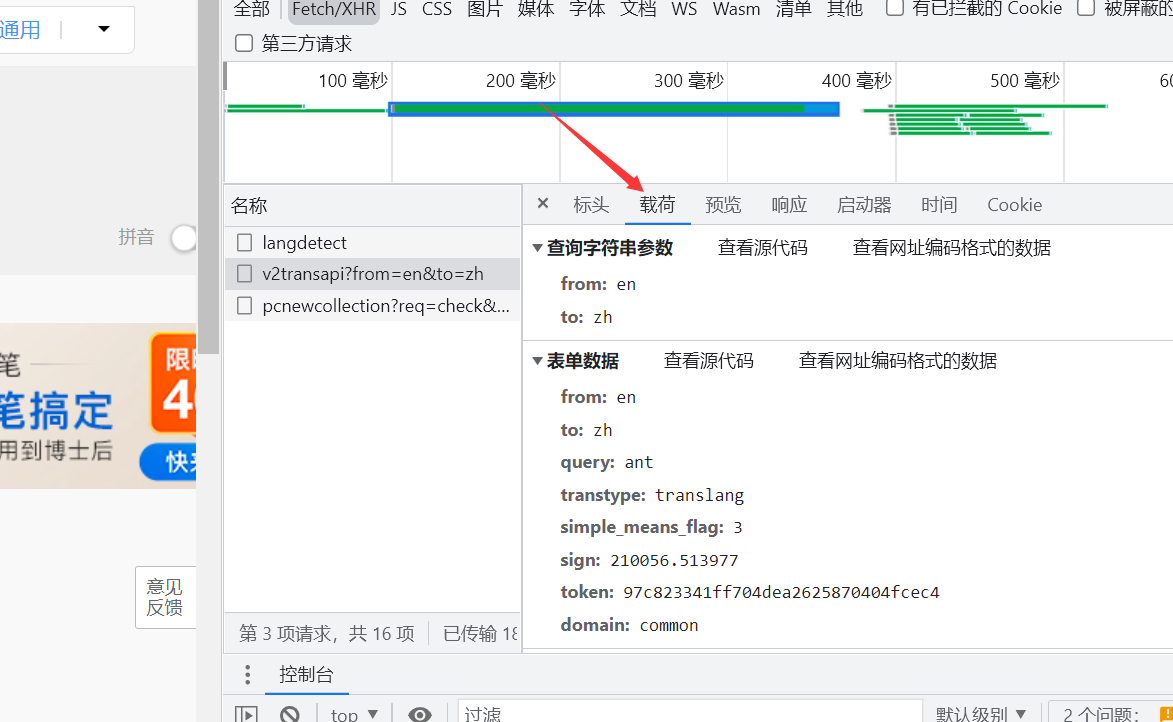
We can see that there is a form data
from: en to: zh # From English to Chinese query: ant # search ant word transtype: realtime # May it mean real-time query? simple_means_flag: 3 sign: 210056.513977 token: 97c823341ff704dea2625870404fcec4 # Baidu translation key information for identification sign and token domain: common
This is the data we want to submit
But the form we submit is dynamic, so we need to rewrite the data
that is
data = { "from": "en", "to": "zh", "query": custom_input, "transtype": "translang", "simple_means_flag": "3", "token": '97c823341ff704dea2625870404fcec4' }
Get responses and process results
We consider that after submitting the data, we need to receive feedback from the website
So continue to see where the returned translation is
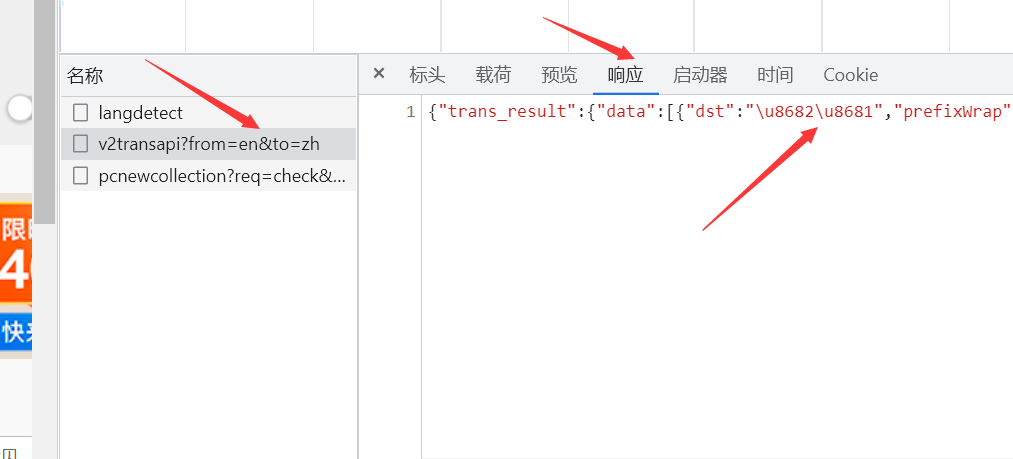
We will find that there seems to be some difference between what we want and what we actually want
The result is yes, but it's not Chinese, it's Unicode
There are always ways
response = requests.post(url='https://fanyi.baidu.com/v2transapi', headers=headers, timeout=1, data=data) response.encoding = 'utf-8' print(response.status_code) # Get status code print(re.search("[\\u4e00-\\u9fa5]+", response.content.decode('unicode_escape'), flags=re.S)[0]) # Regular expression to find Chinese characters
In this way, what is printed out is Chinese~
It was a surprise
Almost ready to submit!
Then I excitedly submitted the data
Baidu translation gave me a big mouth and profound lesson
Please enter the translation mode to select [1]Chinese English translation [2]Chinese English translation 1 Please enter the English to be translated apple 200 unknown error The process has ended,Exit code 0
What's going on? Apple's translation should be apple, not an unknown error
Then I found that the previous data missed a sign
sign is calculated differently for different words, but it is fixed relative to words
Fortunately, many online giants found the sign algorithm
https://blog.csdn.net/qq_38534107/article/details/90440403?utm_source=app&app_version=5.0.0&code=app_1562916241&uLinkId=usr1mkqgl919blen
If you are interested, you can see the acquisition of sign algorithm
Finally, paste the sign, and it's successful!
Eliminate warning
But there will be a Warning
Please enter the translation mode to select [1]Chinese English translation [2]Chinese English translation 1 Please enter the English to be translated apple 200 Apple F:/Python/New/main.py:40: DeprecationWarning: invalid escape sequence '\/' print(re.search("[\\u4e00-\\u9fa5]+", response.content.decode('unicode_escape'), flags=re.S)[0]) The process has ended,Exit code 0
There is a warning under the translation result, which is not good-looking
So I found a way to join this
import warnings warnings.filterwarnings("ignore", category=Warning) # Close discard error
There will be no mistakes~
So far, the functions in English translation are almost done
Chinese English translation is basically the same, but there are many things returned, which can be filtered through this statement
print(re.findall(pattern='[a-zA-Z]+', string=response.content.decode('unicode_escape'), flags=re.S)[4])
That's about it~
All codes:
main.py
import requests from sign import sign import re import warnings warnings.filterwarnings("ignore", category=Warning) # Close discard error headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/66.0.3359.139 Safari/537.36", "Cookie": 'BIDUPSID=248487DDE4F4874C768DD664800AFB01; ' 'PSTM=1624632627; ' '__yjs_duid' '=1_9e9a49b48ccf294be969148528d703281624677345512; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; ' 'REALTIME_TRANS_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; APPGUIDE_10_0_2=1; ' 'BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID=39C416629357EBAB497629178C0541C1:FG=1; ' 'BDUSS' '=m9DMm1RUFZTTFBCNmdZUUFhY3lpeUR4Y3NNRW5SdThvb3FpTnZDNWdXNWRyeEJpSVFBQUFBJCQAAAAAAAAAAAEAAACSX1uneHp5MjAwMzIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAF0i6WFdIulhZ; BDUSS_BFESS=m9DMm1RUFZTTFBCNmdZUUFhY3lpeUR4Y3NNRW5SdThvb3FpTnZDNWdXNWRyeEJpSVFBQUFBJCQAAAAAAAAAAAEAAACSX1uneHp5MjAwMzIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAF0i6WFdIulhZ; H_PS_PSSID=35410_35105_31254_35774_34584_35490_35693_35796_35324_26350_35744; BAIDUID_BFESS=39C416629357EBAB497629178C0541C1:FG=1; BCLID=11903837222192425398; BDSFRCVID=meFOJeC627p69AjHgenlU9pUEeQF9_oTH6aoc1Pmnv6SwQ5bF3wEEG0PEM8g0Kub1VDqogKKQgOTHRCF_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF=tbFqoKI5JK03J-Fk-R6BMtCbMfQyetJyaR0tXJvvWJ5TMCoJ0-c25-InbPvwblL8-NT42-ovyJ6_ShPC-tnc3M4nKxC82Mb8Qa743qbX3l02Vhvae-t2ynLIQMFLQ-RMW23I0h7mWUoTsxA45J7cM4IseboJLfT-0bc4KKJxbnLWeIJIjjC5DTOXjH8OtTnfb5kXWnbEatD_Hn7zeUDWeM4pbt-qJqTzLNQLWqnjBpRBSDTx3fo1j4tUXxTnBT5KaKTvaCTw5l7KHq32yqKKQlKkQN3TWxuO5bRi5Roy-q3FDn3oypQJXp0n04bly5jtMgOBBJ0yQ4b4OR5JjxonDh83bG7MJPKtfJut_I05JID-bnPk5PQ_b-40Mq0X5-RLfKj-Kq7F5l8-hC3xj6rNMxksbfTQL6cjQmT-blLXXb7xOKQphP-a0-uH5Gjg-h_tKeFeLh5N3KJmsqC9bT3v5tjL34OD2-biWa6M2MbdLqOP_IoG2Mn8M4bb3qOpBtQmJeTxoUJ25DnJhbLGe4bK-TrLjHKftxK; BCLID_BFESS=11903837222192425398; BDSFRCVID_BFESS=meFOJeC627p69AjHgenlU9pUEeQF9_oTH6aoc1Pmnv6SwQ5bF3wEEG0PEM8g0Kub1VDqogKKQgOTHRCF_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF_BFESS=tbFqoKI5JK03J-Fk-R6BMtCbMfQyetJyaR0tXJvvWJ5TMCoJ0-c25-InbPvwblL8-NT42-ovyJ6_ShPC-tnc3M4nKxC82Mb8Qa743qbX3l02Vhvae-t2ynLIQMFLQ-RMW23I0h7mWUoTsxA45J7cM4IseboJLfT-0bc4KKJxbnLWeIJIjjC5DTOXjH8OtTnfb5kXWnbEatD_Hn7zeUDWeM4pbt-qJqTzLNQLWqnjBpRBSDTx3fo1j4tUXxTnBT5KaKTvaCTw5l7KHq32yqKKQlKkQN3TWxuO5bRi5Roy-q3FDn3oypQJXp0n04bly5jtMgOBBJ0yQ4b4OR5JjxonDh83bG7MJPKtfJut_I05JID-bnPk5PQ_b-40Mq0X5-RLfKj-Kq7F5l8-hC3xj6rNMxksbfTQL6cjQmT-blLXXb7xOKQphP-a0-uH5Gjg-h_tKeFeLh5N3KJmsqC9bT3v5tjL34OD2-biWa6M2MbdLqOP_IoG2Mn8M4bb3qOpBtQmJeTxoUJ25DnJhbLGe4bK-TrLjHKftxK; delPer=0; PSINO=3; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1641456854,1642661186,1642662678,1642687449; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1642688201; BA_HECTOR=248g858580ak84a0u91guirq80q; ab_sr=1.0.1_MjM4OGFjMTZiZjUyMmYxMmU5NDhjY2FkZDkzNzRkMzZkZGUxN2RmMmY1NzEwYzg5ZDlmYTk2YTIzZmM0ODBlMzJlYzAwNDMxNjllNjk3OGMxZDJmMzI1NjNiNjlhNjExNTEzYmNkZTFlZWNjYzI4ZGVmZTA4NDk3ODBjYThlYzM='} if __name__ == '__main__': print("Please enter the translation mode to select") choose = int(input("[1]Chinese English translation\n[2]Chinese English translation\n")) while choose != 1 and choose != 2: print("Wrong! Please re-enter") choose = int(input("[1]Chinese English translation\n[2]Chinese English translation\n")) data = {} if choose == 1: custom_input = input('Please enter the English to be translated\n') data = { "from": "en", "to": "zh", "query": custom_input, "transtype": "translang", "simple_means_flag": "3", "token": '97c823341ff704dea2625870404fcec4', "sign": sign(custom_input) } response = requests.post(url='https://fanyi.baidu.com/v2transapi', headers=headers, timeout=1, data=data) response.encoding = 'utf-8'print(re.search("[\\u4e00-\\u9fa5]+", response.content.decode('unicode_escape'), flags=re.S)[0]) elif choose == 2: custom_input = input('Please enter the Chinese to be translated into English\n') data = { "from": "zh", "to": "en", "query": custom_input, "transtype": "translang", "simple_means_flag": "3", "token": '97c823341ff704dea2625870404fcec4', "sign": sign(custom_input) } response = requests.post(url='https://fanyi.baidu.com/v2transapi', headers=headers, timeout=1, data=data) response.encoding = 'utf-8' print(re.findall(pattern='[a-zA-Z]+', string=response.content.decode('unicode_escape'), flags=re.S)[4])
sign.py
import js2py import requests import re def sign(word): session = requests.Session() headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"} session.headers = headers response = session.get("http://fanyi.baidu.com/") gtk = re.findall(";window.gtk = ('.*?');", response.content.decode())[0] word = word context = js2py.EvalJs() js = r''' function a(r) { if (Array.isArray(r)) { for (var o = 0, t = Array(r.length); o < r.length; o++) t[o] = r[o]; return t } return Array.from(r) } function n(r, o) { for (var t = 0; t < o.length - 2; t += 3) { var a = o.charAt(t + 2); a = a >= "a" ? a.charCodeAt(0) - 87 : Number(a), a = "+" === o.charAt(t + 1) ? r >>> a : r << a, r = "+" === o.charAt(t) ? r + a & 4294967295 : r ^ a } return r } function e(r) { var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g); if (null === o) { var t = r.length; t > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(t / 2) - 5, 10) + r.substr(-10, 10)) } else { for (var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = 0, h = e.length, f = []; h > C; C++) "" !== e[C] && f.push.apply(f, a(e[C].split(""))), C !== h - 1 && f.push(o[C]); var g = f.length; g > 30 && (r = f.slice(0, 10).join("") + f.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + f.slice(-10).join("")) } var u = void 0 , l = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107); u = 'null !== i ? i : (i = window[l] || "") || ""'; for (var d = u.split("."), m = Number(d[0]) || 0, s = Number(d[1]) || 0, S = [], c = 0, v = 0; v < r.length; v++) { var A = r.charCodeAt(v); 128 > A ? S[c++] = A : (2048 > A ? S[c++] = A >> 6 | 192 : (55296 === (64512 & A) && v + 1 < r.length && 56320 === (64512 & r.charCodeAt(v + 1)) ? (A = 65536 + ((1023 & A) << 10) + (1023 & r.charCodeAt(++v)), S[c++] = A >> 18 | 240, S[c++] = A >> 12 & 63 | 128) : S[c++] = A >> 12 | 224, S[c++] = A >> 6 & 63 | 128), S[c++] = 63 & A | 128) } for (var p = m, F = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), D = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), b = 0; b < S.length; b++) p += S[b], p = n(p, F); return p = n(p, D), p ^= s, 0 > p && (p = (2147483647 & p) + 2147483648), p %= 1e6, p.toString() + "." + (p ^ m) } ''' js = js.replace('\'null !== i ? i : (i = window[l] || "") || ""\'', gtk) # implement js context.execute(js) # Call the function to get sign sign = context.e(word) return sign
Running example: