1. Design scheme
1. Project Name: Crawl Cat Eye Movie Box Office
2. Project Content: Crawl the box office data of cat-eye movie Changjin Lake premiered to today
3. Overview of design scheme: analyze the structure and characteristics of theme page website, collect web pages, divide data and clean them. Finally, visualize the data
2. Analysis of the Structural Characteristics of Theme Pages
1. Theme page structure and feature analysis:
Open the developer debugging tool and refresh the page to see the data requests, and by changing the date, you can access the data for a specific date.
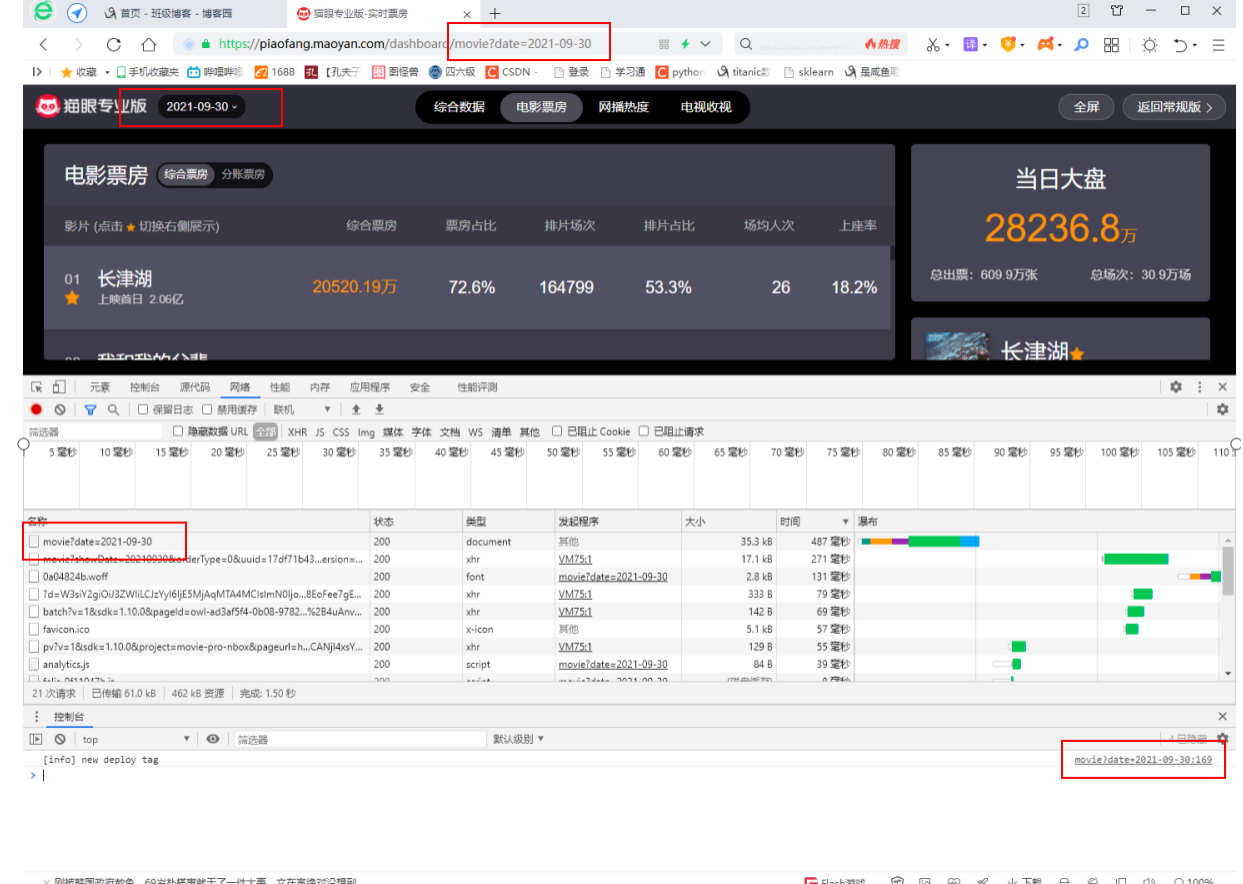
No movie related data found in static web page
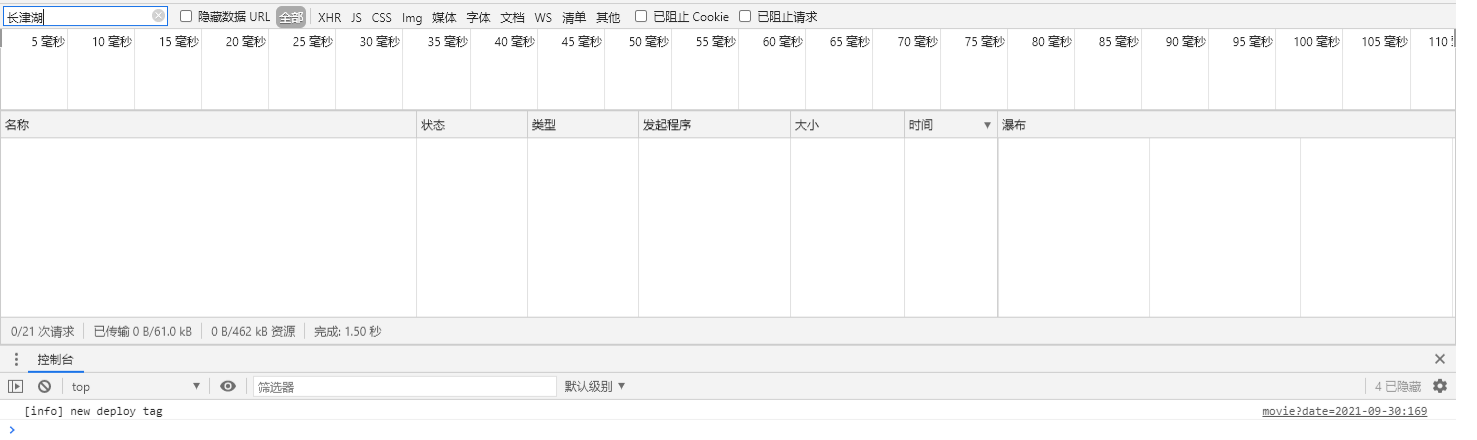
Data may be dynamically loaded, date changed, data requests viewed, and data packages stored
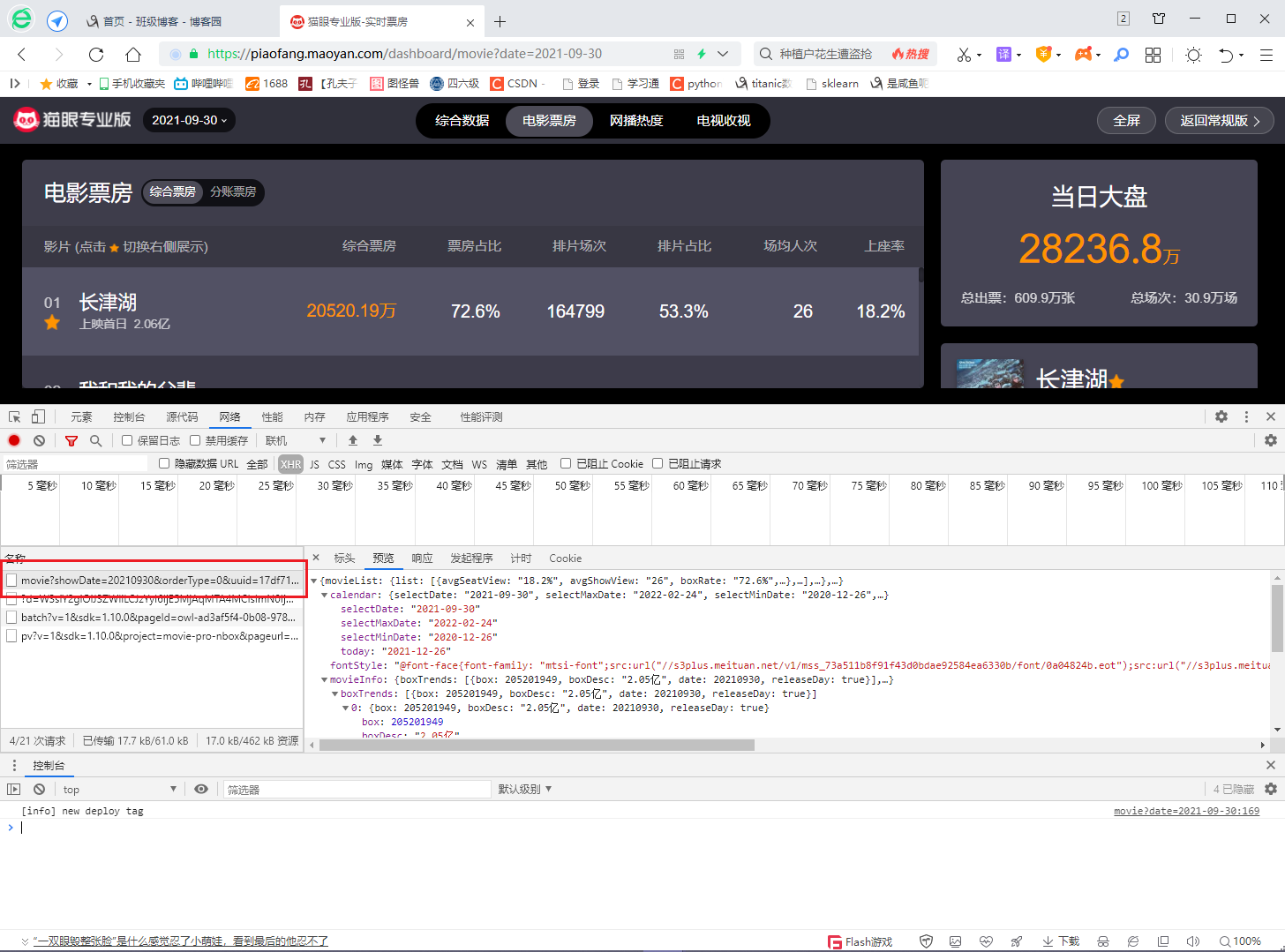
2. Page Analysis
Once the package is found, you can see that the data is stored in json format, and you can see the corresponding json data by changing the date after the url

3. Program Design of Web Crawler
1. Get all dates from premiere to today
1 def get_date(): 2 year = '2021' 3 month = '9' 4 day = '30' 5 # Premiere Date of Changjin Lake 6 7 time_arry = time.localtime(time.time()) 8 # Format timestamp 9 time_str = time.strftime('%Y%m%d', time_arry) 10 # Get the date of the day 11 12 date_list = [] 13 14 while int(month) <= 12: 15 if int(year) % 4 == 0: 16 if int(month) in [1, 3, 5, 7, 8, 10, 12]: 17 max_day = 31 18 elif int(month) in [4, 6, 9, 11]: 19 max_day = 30 20 else: 21 max_day = 29 22 else: 23 if int(month) in [1, 3, 5, 7, 8, 10, 12]: 24 max_day = 31 25 elif int(month) in [4, 6, 9, 11]: 26 max_day = 30 27 else: 28 max_day = 28 29 30 if len(str(month)) == 1: 31 month = '0' + month 32 33 while int(day) <= max_day: 34 if len(str(day)) == 1: 35 day = '0' + str(day) 36 data = str(year) + str(month) + str(day) 37 # print(data) 38 date_list.append(data) 39 if data == time_str: 40 break 41 42 day = int(day) + 1 43 44 day = '1' 45 month = int(month) + 1 46 47 return date_list 48 # Calculate all dates from premiere to today, enlarge list
Code Run:

2. Data collection, cleaning and storage
1 def get_data(date_list): 2 for date in date_list: 3 print('Collecting:', date, 'Movie data!!!') 4 time.sleep(1) 5 url = 'https://prowechat.maoyan.com/promovie/api/box/national.json?beginDate=' + date 6 7 headers = { 8 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 9 'Accept-Encoding': 'gzip,deflate,br', 10 'Accept-Language': 'zh-CN,zh;q=0.9', 11 'Connection': 'keep-alive', 12 'Cookie': '_lxsdk_cuid=17dd14cfc21c8-0330bbb5d574ce-978183a-1fa400-17dd14cfc21c8;_lxsdk=17dd14cfc21c8-0330bbb5d574ce-978183a-1fa400-17dd14cfc21c8;_lx_utm=utm_source%3Dbaidu%26utm_medium%3Dorganic%26utm_term%3D%25E7%258C%25AB%25E7%259C%25BC%25E7%2594%25B5%25E5%25BD%25B1;_lxsdk_s=17dd14cfc21-119-48b-757%7C%7C777', 13 'Host': 'prowechat.maoyan.com', 14 'sec-ch-ua': '"NotA;Brand";v="99","Chromium";v="96","GoogleChrome";v="96"', 15 'sec-ch-ua-mobile': '?0', 16 'sec-ch-ua-platform': '"Windows"', 17 'Sec-Fetch-Dest': 'document', 18 'Sec-Fetch-Mode': 'navigate', 19 'Sec-Fetch-Site': 'none', 20 'Sec-Fetch-User': '?1', 21 'Upgrade-Insecure-Requests': '1', 22 'User-Agent': 'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/96.0.4664.45Safari/537.36' 23 } 24 25 res = requests.get(url=url, headers=headers, verify=False) 26 27 # print(res.text) 28 29 res_json = json.loads(res.text) 30 31 data = res_json['data']['list'] 32 33 for i in data: 34 save_list = [] 35 if i['movieName'] == 'Changjin Lake': 36 # print(i) 37 moviename = i['movieName'] 38 save_list.append(moviename) 39 print('Movie Title:', moviename) 40 # Movie Title 41 42 releaseInfo = i['releaseInfo'] 43 if 'Premiere Day' == releaseInfo: 44 releaseInfo = 1 45 else: 46 releaseInfo = ''.join(re.findall('[\d]', releaseInfo)) 47 save_list.append(str(releaseInfo)) 48 print('Release Days:', releaseInfo) 49 # Release Days 50 51 sumBoxInfo = i['sumBoxInfo'] 52 save_list.append(sumBoxInfo) 53 print('Total box office:', sumBoxInfo) 54 # Total box office 55 56 boxInfo = i['boxInfo'] 57 save_list.append(boxInfo) 58 print('Comprehensive box office:', boxInfo) 59 # Comprehensive box office for the day 60 61 boxRate = i['boxRate'] 62 save_list.append(boxRate) 63 print('Composite box office percentage:', boxRate) 64 # Composite box office percentage 65 66 viewInfo = i['viewInfo'] 67 save_list.append(viewInfo) 68 print('Total number:', viewInfo) 69 # Total number 70 71 avgShowView = i['avgShowView'] 72 save_list.append(avgShowView) 73 print('Average number of persons per field:', avgShowView) 74 # Average number of persons per field 75 76 avgSeatView = i['avgSeatView'] 77 save_list.append(avgSeatView) 78 print('Attendance:', avgSeatView) 79 # Attendance 80 81 print('=============================================================') 82 83 with open(file='Changjin Lake.csv', mode='a+', encoding='utf-8_sig', newline='') as w: 84 c = csv.writer(w) 85 c.writerow(save_list) 86 87 time.sleep(3)
Code Run:



3. Data analysis and visualization
1 def see_data(): 2 with open('Changjin Lake.csv', mode='r', encoding='utf-8') as r: 3 reader = csv.reader(r) 4 data = [row for row in reader] 5 # Read by line 6 7 day = [] 8 all_pf = [] 9 zh_pf = [] 10 for i in data[1:31]: 11 # Take 30 days of movie release 12 day.append(i[1]) 13 all_pf.append(float(i[2].replace('Billions', ''))) 14 # Clean the gross box office data into the format required for visualization 15 zh_pf.append(round((float(i[3]) / 10000), 2)) 16 # Convert unit of combined box office from 10,000 to 100,000,000 yuan 17 18 x_data = day 19 20 line1 = Line() 21 22 line1.add_xaxis(xaxis_data=x_data) \ 23 .add_yaxis( 24 series_name="Total box office(Billion yuan)", 25 y_axis=all_pf, 26 label_opts=opts.LabelOpts(is_show=False) 27 ) 28 line1.extend_axis( 29 yaxis=opts.AxisOpts( 30 min_='-2', 31 axislabel_opts=opts.LabelOpts(interval=5) 32 ) 33 ) 34 line1.set_global_opts( 35 title_opts=opts.TitleOpts(title="Changjin Lake Cinema Box Office"), 36 tooltip_opts=opts.TooltipOpts(trigger="axis") 37 ) 38 39 line2 = Line() 40 line2.add_xaxis(xaxis_data=x_data) 41 line2.add_yaxis( 42 series_name="Comprehensive box office(Billion yuan)", 43 y_axis=zh_pf, 44 label_opts=opts.LabelOpts(is_show=True), 45 yaxis_index=1 46 ) 47 48 line1.overlap(line2) 49 line1.render('Changjin Lake Cinema Box Office.html') 50 print('Visualization completed, please note the file: Changjin Lake movie box office.html!!!')
Code Run:
4. Complete Code
1 import csv 2 import requests 3 import json 4 import urllib3 5 import re 6 import time 7 import pyecharts.options as opts 8 from pyecharts.charts import Line 9 urllib3.disable_warnings() 10 11 12 def see_data(): 13 with open('Changjin Lake.csv', mode='r', encoding='utf-8') as r: 14 reader = csv.reader(r) 15 data = [row for row in reader] 16 # Read by line 17 18 day = [] 19 all_pf = [] 20 zh_pf = [] 21 for i in data[1:31]: 22 # Take 30 days of movie release 23 day.append(i[1]) 24 all_pf.append(float(i[2].replace('Billions', ''))) 25 # Clean the gross box office data into the format required for visualization 26 zh_pf.append(round((float(i[3]) / 10000), 2)) 27 # Convert unit of combined box office from 10,000 to 100,000,000 yuan 28 29 x_data = day 30 31 line1 = Line() 32 33 line1.add_xaxis(xaxis_data=x_data) \ 34 .add_yaxis( 35 series_name="Total box office(Billion yuan)", 36 y_axis=all_pf, 37 label_opts=opts.LabelOpts(is_show=False) 38 ) 39 line1.extend_axis( 40 yaxis=opts.AxisOpts( 41 min_='-2', 42 axislabel_opts=opts.LabelOpts(interval=5) 43 ) 44 ) 45 line1.set_global_opts( 46 title_opts=opts.TitleOpts(title="Changjin Lake Cinema Box Office"), 47 tooltip_opts=opts.TooltipOpts(trigger="axis") 48 ) 49 50 line2 = Line() 51 line2.add_xaxis(xaxis_data=x_data) 52 line2.add_yaxis( 53 series_name="Comprehensive box office(Billion yuan)", 54 y_axis=zh_pf, 55 label_opts=opts.LabelOpts(is_show=True), 56 yaxis_index=1 57 ) 58 59 line1.overlap(line2) 60 line1.render('Changjin Lake Cinema Box Office.html') 61 print('Visualization completed, please note the file: Changjin Lake movie box office.html!!!') 62 63 64 def get_date(): 65 year = '2021' 66 month = '9' 67 day = '30' 68 # Premiere Date of Changjin Lake 69 70 time_arry = time.localtime(time.time()) 71 # Format timestamp 72 time_str = time.strftime('%Y%m%d', time_arry) 73 # Get the date of the day 74 75 date_list = [] 76 77 while int(month) <= 12: 78 if int(year) % 4 == 0: 79 if int(month) in [1, 3, 5, 7, 8, 10, 12]: 80 max_day = 31 81 elif int(month) in [4, 6, 9, 11]: 82 max_day = 30 83 else: 84 max_day = 29 85 else: 86 if int(month) in [1, 3, 5, 7, 8, 10, 12]: 87 max_day = 31 88 elif int(month) in [4, 6, 9, 11]: 89 max_day = 30 90 else: 91 max_day = 28 92 93 if len(str(month)) == 1: 94 month = '0' + month 95 96 while int(day) <= max_day: 97 if len(str(day)) == 1: 98 day = '0' + str(day) 99 data = str(year) + str(month) + str(day) 100 # print(data) 101 date_list.append(data) 102 if data == time_str: 103 break 104 105 day = int(day) + 1 106 107 day = '1' 108 month = int(month) + 1 109 110 return date_list 111 # Calculate all dates from premiere to today, enlarge list 112 113 114 def get_data(date_list): 115 for date in date_list: 116 print('Collecting:', date, 'Movie data!!!') 117 time.sleep(1) 118 url = 'https://prowechat.maoyan.com/promovie/api/box/national.json?beginDate=' + date 119 120 headers = { 121 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 122 'Accept-Encoding': 'gzip,deflate,br', 123 'Accept-Language': 'zh-CN,zh;q=0.9', 124 'Connection': 'keep-alive', 125 'Cookie': '_lxsdk_cuid=17dd14cfc21c8-0330bbb5d574ce-978183a-1fa400-17dd14cfc21c8;_lxsdk=17dd14cfc21c8-0330bbb5d574ce-978183a-1fa400-17dd14cfc21c8;_lx_utm=utm_source%3Dbaidu%26utm_medium%3Dorganic%26utm_term%3D%25E7%258C%25AB%25E7%259C%25BC%25E7%2594%25B5%25E5%25BD%25B1;_lxsdk_s=17dd14cfc21-119-48b-757%7C%7C777', 126 'Host': 'prowechat.maoyan.com', 127 'sec-ch-ua': '"NotA;Brand";v="99","Chromium";v="96","GoogleChrome";v="96"', 128 'sec-ch-ua-mobile': '?0', 129 'sec-ch-ua-platform': '"Windows"', 130 'Sec-Fetch-Dest': 'document', 131 'Sec-Fetch-Mode': 'navigate', 132 'Sec-Fetch-Site': 'none', 133 'Sec-Fetch-User': '?1', 134 'Upgrade-Insecure-Requests': '1', 135 'User-Agent': 'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/96.0.4664.45Safari/537.36' 136 } 137 138 res = requests.get(url=url, headers=headers, verify=False) 139 140 # print(res.text) 141 142 res_json = json.loads(res.text) 143 144 data = res_json['data']['list'] 145 146 for i in data: 147 save_list = [] 148 if i['movieName'] == 'Changjin Lake': 149 # print(i) 150 moviename = i['movieName'] 151 save_list.append(moviename) 152 print('Movie Title:', moviename) 153 # Movie Title 154 155 releaseInfo = i['releaseInfo'] 156 if 'Premiere Day' == releaseInfo: 157 releaseInfo = 1 158 else: 159 releaseInfo = ''.join(re.findall('[\d]', releaseInfo)) 160 save_list.append(str(releaseInfo)) 161 print('Release Days:', releaseInfo) 162 # Release Days 163 164 sumBoxInfo = i['sumBoxInfo'] 165 save_list.append(sumBoxInfo) 166 print('Total box office:', sumBoxInfo) 167 # Total box office 168 169 boxInfo = i['boxInfo'] 170 save_list.append(boxInfo) 171 print('Comprehensive box office:', boxInfo) 172 # Comprehensive box office for the day 173 174 boxRate = i['boxRate'] 175 save_list.append(boxRate) 176 print('Composite box office percentage:', boxRate) 177 # Composite box office percentage 178 179 viewInfo = i['viewInfo'] 180 save_list.append(viewInfo) 181 print('Total number:', viewInfo) 182 # Total number 183 184 avgShowView = i['avgShowView'] 185 save_list.append(avgShowView) 186 print('Average number of persons per field:', avgShowView) 187 # Average number of persons per field 188 189 avgSeatView = i['avgSeatView'] 190 save_list.append(avgSeatView) 191 print('Attendance:', avgSeatView) 192 # Attendance 193 194 print('=============================================================') 195 196 with open(file='Changjin Lake.csv', mode='a+', encoding='utf-8_sig', newline='') as w: 197 c = csv.writer(w) 198 c.writerow(save_list) 199 200 time.sleep(3) 201 202 203 if __name__ == '__main__': 204 while True: 205 print('==================================================================') 206 print('Please select program code:\n1,Data Acquisition Box Office Data for Cat Eye Movie Changjin Lake\n2,Data Visualization Chart\nbreak:Sign out!') 207 print('==================================================================') 208 key = input('Please select:') 209 if key == '1': 210 print('1,Get a list of the dates from the premiere of Changjin Lake to today!') 211 date_list = get_date() 212 print(date_list) 213 214 print('2,Traverse through the list of dates, adding data URL Format, collect daily movie data') 215 get_data(date_list=date_list) 216 elif key == '2': 217 see_data() 218 elif key == 'break': 219 break 220 else: 221 print('Please choose again!!!')
V. Summary
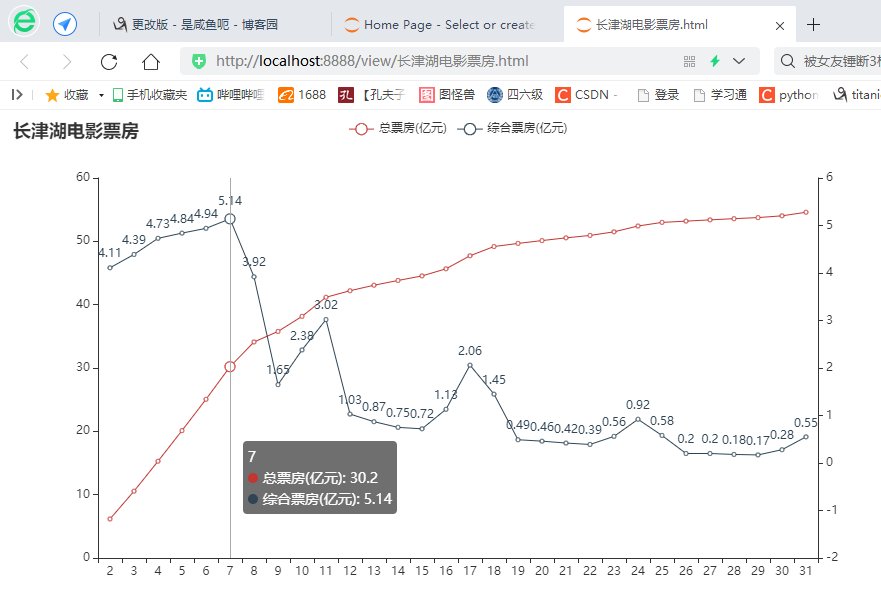
1. After cleaning, analyzing and visualizing the data, you can see from the line chart that the total box office of the movie has been on the rise substantially on the 7th day before the show. As time goes on, the heat of the movie decreases. The total box office of the day shows a downward trend compared with before, and the total box office increases slightly. After the 23rd day of the show, the total box office shows a steady trend. Taken together, Changjin Lake has been on the rise with a total box office of over 3 billion after 7 days of release.
2. Through the process of data collection and analysis, I have learned the use of many third-party libraries, plus a simple learning to use the tool pyecharts, many of the functions encountered problems, through the function documentation, Baidu and other methods to solve. Let me experience the power of python.