1, Foreword
The first two days in WeChat saw Dong Fuguo's official account, "python cabin", sent a push. "Learning Python+numpy array operation and matrix operation, just look at this 254 page PPT" . Mr. Dong put all the 254 pages of PPT pictures in his courseware in this push.
I am learning machine learning recently and try to re implement the code implemented in Matlab in teacher Wu Enda's Deep Learning course in Python. I want to master the usage of matrix operation in Python as soon as possible, so I want to use this PPT library very efficiently. However, there are requirements to obtain this PPT:

But, 36 likes are a little difficult for me. There are few friends on wechat... But I really want this PPT. What should I do? It seems that we can only try to write a script to climb down these pictures and automatically import them into PPT. I apologize to Mr. Dong here. White whoring is helpless. I hope you can forgive me~
Final results:
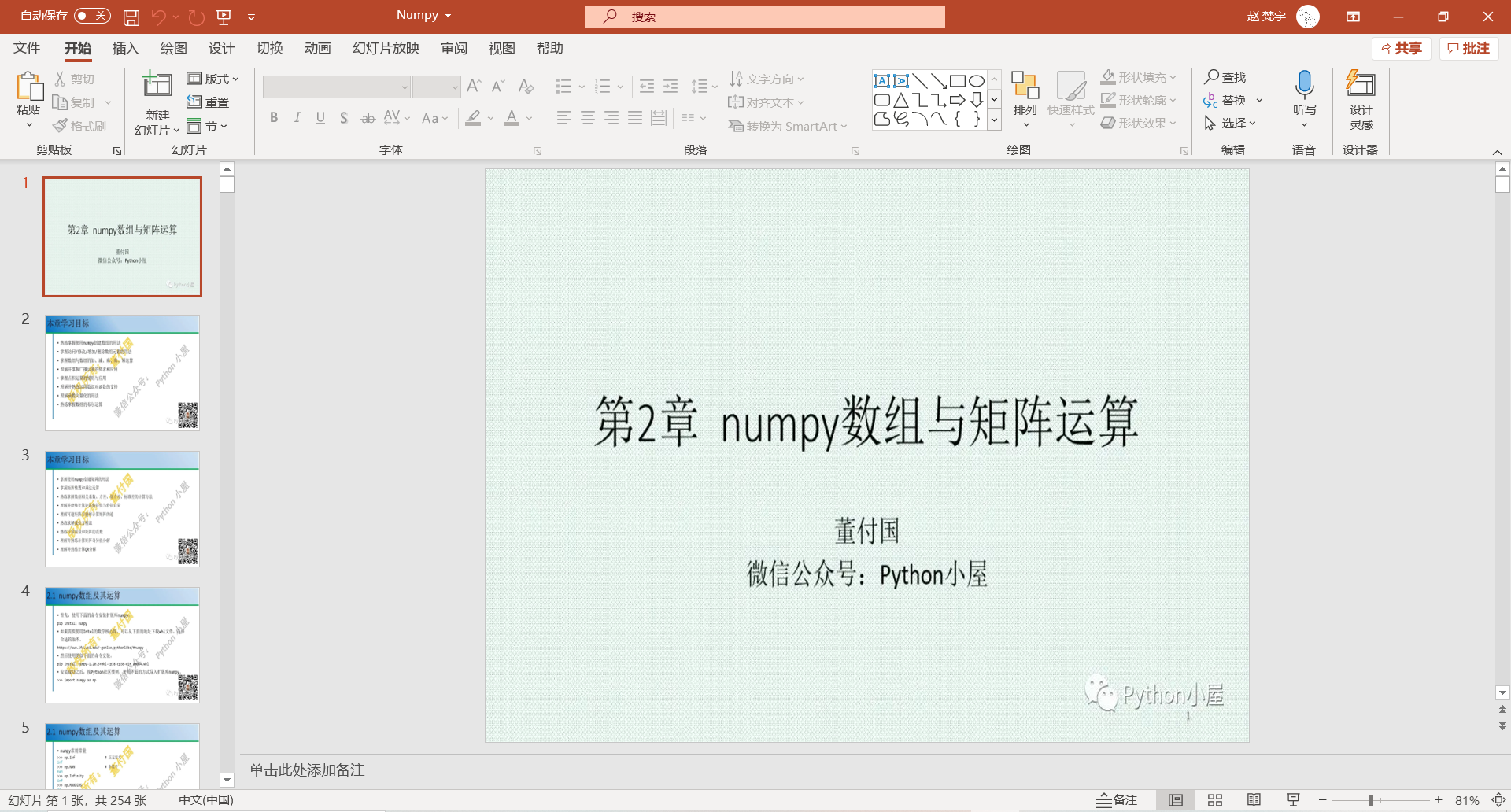
2, Start
(1) Get push URL link
If you want to crawl a web page, you naturally have to get its URL link first. Since opening a push WeChat directly will generate a random link, I still get the URL of the target pushing in the background of WeChat official account. See my other article for details Crawling the official account with python . Finally, get the target push link:
https://mp.weixin.qq.com/s?__biz=MzI4MzM2MDgyMQ==&mid=2247493780&idx=1&sn=efde5d4ec9a5c04383b709ace1222518&chksm=eb8943cedcfecad84ffb4794d19cce4c7ae3344ffa0c361f646d10689717af33dab5da93332f#rd
(2) Crawl the web page and extract the picture to save
1. Define the PictureSpider class used to crawl and push pictures
This time, I choose to implement the crawler in an object-oriented way.
First, define a class that is specifically used to crawl the pictures in the official account, named PictureSpider, and then introduce the push link start_ to be crawled when initialized. URL, and set the headers parameter of the crawler (here I save the Cookie and user agent in the "wechat.yaml" file, which will be read automatically during initialization):
class PictureSpider(object):
def __init__(self,start_url):
with open("wechat.yaml", "r") as file:
file_data = file.read()
self.config = yaml.safe_load(file_data)
self.headers = {
"Cookie": self.config['cookie'],
"User-Agent": self.config['user_agent']
}
self.start_url = start_url
2. Define get_url_text() method
Define get_ url_ The text () method crawls the push and returns the pushed html content:
def get_url_text(self):
"""
Return to web page html content
parameter:
url->str:website
return:
r.text->str:Web content
"""
r = requests.get(self.start_url,headers=self.headers)
if r.status_code!=200:
print("Page load failed")
else:
return r.text
3. Define search_pictures() method
Define search_ The pictures () method extracts the pictures in the push and returns a list that stores the URL links of all the pictures in the push:
def search_pictures(self,text):
"""
Search for pictures in web pages url
parameter:
text->str: Web content
return:
picture_url->list: picture URL list
"""
pictures_url = []
re_image = re.compile('<img.*?src="(.*?)".*?>',re.S)
pictures = re_image.finditer(text)
for img in pictures:
if img.group(1):
pictures_url.append(img.group(1))
return pictures_url
4. Define Download_ Pictures() method
Define Download_ The pictures () method is used for pictures_ Each URL in the URL list is traversed and crawled, that is, download the image content and call save_ The picture() method saves the picture in the specified folder:
def download_pictues(self,pictues_url,save_address):
"""
Download pictures
parameter:
pictures_url->list: Save picture url List of
save_address->str: Picture saving address
"""
i = 1
n = len(pictues_url)
for url in pictues_url:
r = requests.get(url,headers=self.headers)
if r.status_code!=200:
print(f"Image crawling failed, page{i}/{n}Zhang")
i += 1
continue
else:
self.save_picture(r,str(i),save_address)
print(f"success,{i}/{n}")
i += 1
if i%5==0:
time.sleep(1)
5. Define save_picture() method
Define save_ The picture () method writes the picture into a file in binary form and saves it:
def save_picture(self,r,name,save_address):
"""
Save picture
parameter:
r->requests.Response: picture url Request return result
name->str: Picture save name
save_adress->str: Picture saving address
"""
with open(save_address+'\\'+name+'.jpg',"wb") as f:
f.write(r.content)
6. Start crawling and results
Finally, instantiate a PictureSpider class and start crawling:
if __name__ == "__main__":
url = "https://mp.weixin.qq.com/s?__biz=MzI4MzM2MDgyMQ==&mid=2247493780&idx=1&sn=efde5d4ec9a5c04383b709ace1222518&chksm=eb8943cedcfecad84ffb4794d19cce4c7ae3344ffa0c361f646d10689717af33dab5da93332f#rd"
spider = PictureSpider(url)
text = spider.get_url_text()
pictures_address = spider.search_pictures(text)
spider.download_pictues(pictures_address,"Numpy_PPT")
After crawling, you can see that all pictures in the target push have been saved to the "Numpy_PPT" folder and named in order:
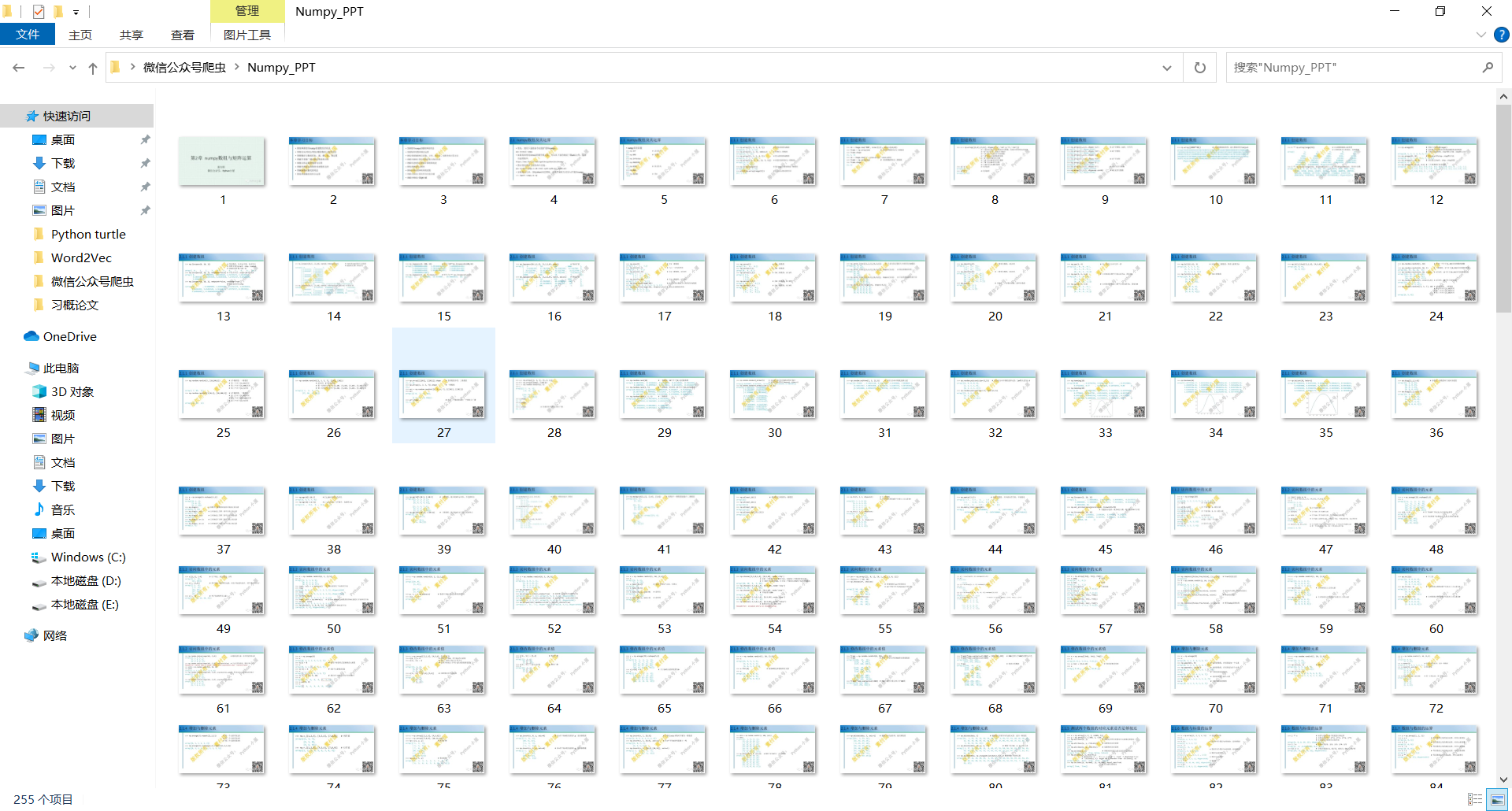
7. Complete code of crawler part
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@File : picture_spider.py
@Time : 2021/06/06 19:35:55
@Author : YuFanWenShu
@Contact : 1365240381@qq.com
'''
# here put the import lib
import requests
import yaml
import re
import os
import time
class PictureSpider(object):
def __init__(self,start_url):
with open("wechat.yaml", "r") as file:
file_data = file.read()
self.config = yaml.safe_load(file_data)
self.headers = {
"Cookie": self.config['cookie'],
"User-Agent": self.config['user_agent']
}
self.start_url = start_url
def get_url_text(self):
"""
Return to web page html content
parameter:
url->str:website
return:
r.text->str:Web content
"""
r = requests.get(self.start_url,headers=self.headers)
if r.status_code!=200:
print("Page load failed")
else:
return r.text
def search_pictures(self,text):
"""
Search for pictures in web pages url
parameter:
text->str: Web content
return:
picture_url->list: picture URL list
"""
pictures_url = []
re_image = re.compile('<img.*?src="(.*?)".*?>',re.S)
pictures = re_image.finditer(text)
for img in pictures:
if img.group(1):
pictures_url.append(img.group(1))
return pictures_url
def download_pictues(self,pictues_url,save_address):
"""
Download pictures
parameter:
pictures_url->list: Save picture url List of
save_address->str: Picture saving address
"""
i = 1
n = len(pictues_url)
for url in pictues_url:
r = requests.get(url,headers=self.headers)
if r.status_code!=200:
print(f"Image crawling failed, page{i}/{n}Zhang")
i += 1
continue
else:
self.save_picture(r,str(i),save_address)
print(f"success,{i}/{n}")
i += 1
if i%5==0:
time.sleep(1)
def save_picture(self,r,name,save_address):
"""
Save picture
parameter:
r->requests.Response: picture url Request return result
name->str: Picture save name
save_adress->str: Picture saving address
"""
with open(save_address+'\\'+name+'.jpg',"wb") as f:
f.write(r.content)
if __name__ == "__main__":
url = "https://mp.weixin.qq.com/s?__biz=MzI4MzM2MDgyMQ==&mid=2247493780&idx=1&sn=efde5d4ec9a5c04383b709ace1222518&chksm=eb8943cedcfecad84ffb4794d19cce4c7ae3344ffa0c361f646d10689717af33dab5da93332f#rd"
spider = PictureSpider(url)
text = spider.get_url_text()
pictures_address = spider.search_pictures(text)
spider.download_pictues(pictures_address,"Numpy_PPT")
(3) Batch import pictures into PPT
1. Code
This part uses the "Python pptx" library. First, set the path of the folder where the pictures are stored, enter the name of the new PPT, and then automatically write the JPG pictures under the folder into the PPT file in numbered order. Finally, save:
import os
import pptx
from pptx.util import Inches
path = os.getcwd()
os.chdir(path+'\\Numpy_PPT')
ppt_filename = input('Enter target ppt file name(No suffix required): ')
full_ppt_filename = '{}.{}'.format(ppt_filename,'pptx')
ppt_file = pptx.Presentation()
pic_files = [fn for fn in os.listdir() if fn.endswith('.jpg')]
# Import by picture number sequence
for fn in sorted(pic_files, key=lambda item:int(item[:item.rindex('.')])):
slide = ppt_file.slides.add_slide(ppt_file.slide_layouts[1])
# Set the text for the first text box in the current slide of PPTX file, which can be ignored in this code
slide.shapes.placeholders[0].text = fn[:fn.rindex('.')]
# Import and add pictures for the current slide. The starting position and size can be modified
slide.shapes.add_picture(fn, Inches(0), Inches(0), Inches(10), Inches(7.5))
ppt_file.save(full_ppt_filename)
2. Results
After running the script, a PPT file is generated in the folder:
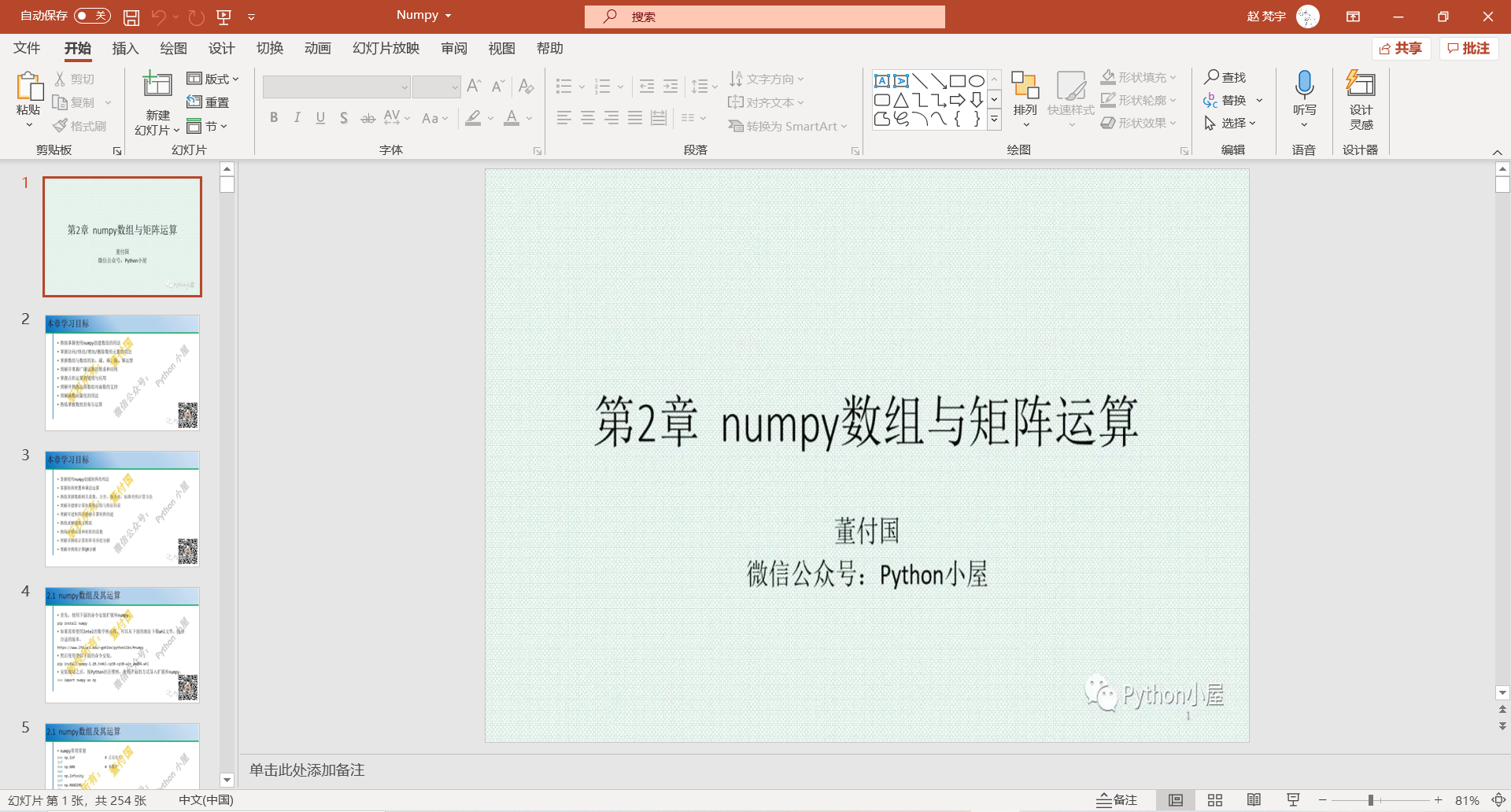
You can see that all 254 pictures have been imported in order, and the effect is very ideal.
3, Conclusion
With the experience of climbing the official account of the "post office", this code was written very smoothly, and it took more than an hour to complete all the modules. The result is very satisfactory. Say nothing, Python, yyds!
In addition, I would like to thank Mr. Dong Fuguo again. I have read several books written by Mr. Dong, and completed all the exercises in the "cabin problem brushing" system last year. It can be said that Mr. Dong and Mr. Songtian of Beihang are my guides.