catalogue
2. Finding elements in BeautifulSoup
3. Crawl the information of each movie
Analyze the broken line diagram of a film type over time
3. Analyze actors or directors
Analysis of the score of an actor's film
Crawl the content of Douban film, write it into excel and analyze the data
Methods: requests, beautiful soup, pandas
1, Crawling
The method of crawling Douban movie content is: first crawl the website of each movie on the main page (25 movies per page, a total of 10 pages), and then enter the website of each movie in turn to crawl the content.
1. Climb the main page
Before crawling, you need to find headers and URLs.
headers are mainly composed of user agent. Its function is to tell the HTTP server the name and version of the operating system and browser used by the client. You only need a user agent to crawl a general website.
url first page home site https://movie.douban.com/top250?start=0&filter= , the website on each page is the previous page, with start = followed by 25.
The next step is to use requests to start visiting the website. Requests generally have two methods: get and post. As shown in the figure below, it is determined to use get or post. Here is to use get.
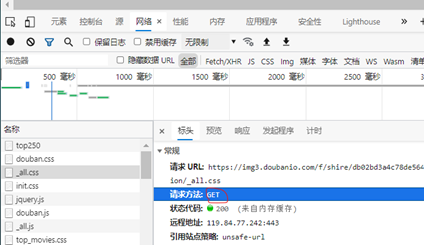
Let's start visiting the website. If the output response is 200, the access is successful. On the contrary, the error source can be found according to the error number Click to view the complete list of error codes .
response = requests.get(url=url, headers=headers)
The next step is to use beautiful soup to start parsing the web page.
soup = BeautifulSoup(response.text, 'html.parser')
HTML here Parser, one of the four parsers, is often used. The resulting soup is HTML. So we can use soup to find the attributes we need.
If you do this, you've completed half the work of the reptile.

2. Finding elements in BeautifulSoup
As the saying goes, sharpening a knife doesn't make a mistake. When we search for elements, let's first learn about the method of finding elements in beautiful soup.
Next, let's introduce the following methods of using soup. The powerful CSS selector can complete most of our functions. Let's focus on the following:

1. find_all
The format is: soup find_ All ('tag ', attrs = {attribute name': 'attribute value'}) this format can be used in most cases, focusing on memory!
For example, if you crawl the home page movie name, you can see that the tag is span, the attribute name is class, and the attribute value is title, then you can apply find_all.

list_name = soup.find_all('span',attrs={'class':'title'}) # The result is a list
for i in list_name:
print(i.get_text()) # If the type is Tag, you need to use get_text()Some results obtained are:

You can see that all the tags in a web page are span, the attribute name is class, and the attribute value is title. So find is introduced here_ All is to find all the qualified content in the web page.
2. find
find_all is to find all the contents that meet the conditions, so it can be imagined that find is to find the first one that meets the conditions.
name = soup.find('span',attrs={'class':'title'})
print(name.get_text())
print(name.string) # string and get_ Same as text()
You can also directly find or find_all string, only those that meet the conditions will be found, for example:
name = soup.find('span',attrs={'class':'title'},string='The Shawshank Redemption')
print(name.get_text())
print(name.string) # string and get_ Same as text()
3. select
select generally has two methods to crawl the content. First, copy the selector. Second, find the label.
select can directly find the content to be crawled and copy the selector, as shown below:
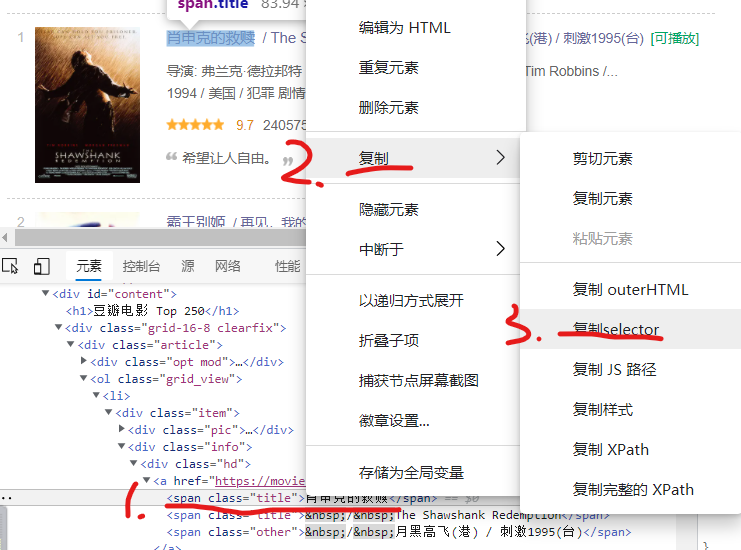
names = soup.select('#content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1)')
for name in names:
print(name.get_text())
The result is only the first name of the first part of each home page. Therefore, we need to delete the first one: nth child (1) to crawl all the information. Because the selector is used to accurately locate an element, we must delete part of the location if we want to crawl all the content.
Some results obtained after deletion are:
The second method of select is similar to find. The key point is to replace class with point (because class is a class) and id with #. However, we don't need to find the label directly. The following method is to determine the label, as shown in the figure:
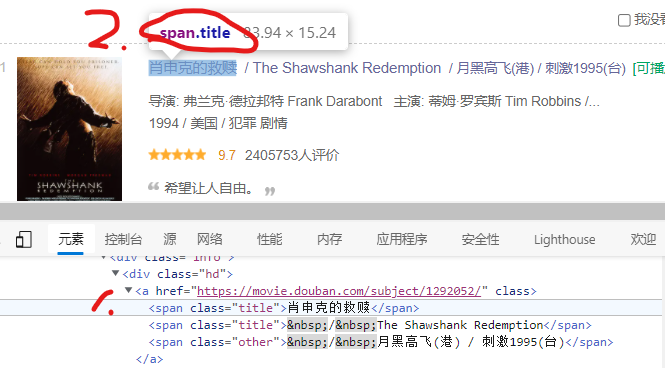
We have found the following "title" tags in the web page, so we have found all the following tags:
names = soup.select('span.title')
for name in names:
print(name.get_text())
Summary: find is mainly used to find elements in beautiful soup_ All and select are two methods to find elements. Pay attention to the tag of crawling content and the advantages and disadvantages of these two methods.
Now we officially start crawling element information:
First of all, climb down the website of each film on the main page of each page, and we can directly analyze it in each film.

Find the tag href containing the movie URL. The method used here is to copy the selector and crawl
Analysis: if find is used_ All will get a lot of and unnecessary href, which is very troublesome, so we can accurately locate it.
url_mv_list = soup.select('#content > div > div.article > ol > li > div > div.info > div.hd > a')
print(url_mv_list)
Output url_mv_list gets a list. The elements in the list are all the information of a movie, as shown in the figure below,
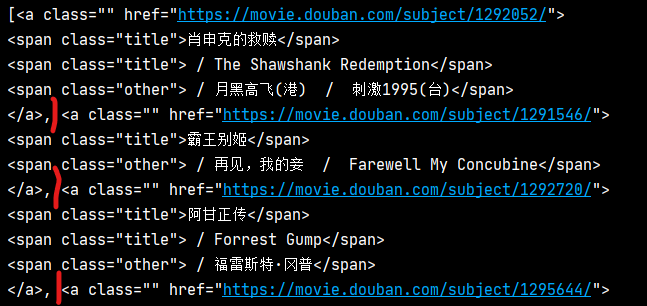
So we just need to read the href of each element
for index_url in range(len(url_mv_list)):
url_mv = url_mv_list[index_url]['href']
list_url_mv.append(url_mv)
print(url_mv)The result is the website of each film
3. Crawl each movie information
Then enter the website of each movie, analyze the web page, and then crawl the elements. The method is the same as crawling the main page. Here you can paste the code directly.
Before that, we need to consider the crawling content output format, because we finally need to input the crawling results into Excel. The method used is to change the data into dataframe and then write it into Excel. An example can well illustrate how to convert to dataframe.
a = [['a', '1', '2'], ['b', '3', '4'], ['c', '5', '6']] df = pd.DataFrame(a, columns=['pan', 'panda', 'fan']) print(df)
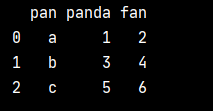
According to the results of the above example, we need to make a list of the information of each movie as the return value of the function, and then add the return value to a list, so that it can be converted into a dataframe.
# Process each film
def loading_mv(url,number):
list_mv = [] # Add crawling information of each movie to it
print('-----Processing page{}Film-----'.format(number+1))
list_mv.append(number+1) # ranking
# Parsing web pages
response_mv = requests.get(url=url,headers=headers)
soup_mv = BeautifulSoup(response_mv.text,'html.parser')
# Crawling movie title
mv_name = soup_mv.find_all('span',attrs={'property':'v:itemreviewed'}) # Movie name
mv_name = mv_name[0].get_text()
list_mv.append(mv_name)
# print(mv_name)
# Crawling for the release time of the film
mv_year = soup_mv.select('span.year') # Film release time
mv_year = mv_year[0].get_text()[1:5]
list_mv.append(mv_year)
# print(mv_year)
# Crawling director information
list_mv_director = [] # director
mv_director = soup_mv.find_all('a',attrs={'rel':"v:directedBy"})
for director in mv_director:
list_mv_director.append(director.get_text())
string_director = '/'.join(list_mv_director) # Redefine format
list_mv.append(string_director)
# print(list_mv_director)
# Crawling information
list_mv_star = [] # to star
mv_star = soup_mv.find_all('span',attrs={'class':'actor'})
if mv_star == []: # There was no starring role in part 210
list_mv.append(None)
else :
mv_star = mv_star[0].get_text().strip().split('/')
mv_first_star = mv_star[0].split(':')
list_mv_star.append(mv_first_star[-1].strip())
del mv_star[0] # Remove 'starring' field
for star in mv_star:
list_mv_star.append(star.strip())
string = '/'.join(list_mv_star) # Redefine format
list_mv.append(string)
# Crawl movie type
list_mv_type = [] # Film type
mv_type = soup_mv.find_all('span',attrs={'property':'v:genre'})
for type in mv_type:
list_mv_type.append(type.get_text())
string_type = '/'.join(list_mv_type)
list_mv.append(string_type)
# print(list_mv_type)
# Crawl movie ratings
mv_score = soup_mv.select('strong.ll.rating_num') # score
mv_score = mv_score[0].get_text()
list_mv.append(mv_score)
# Number of crawling evaluators
mv_evaluation_num = soup_mv.select('a.rating_people') # Number of evaluators
mv_evaluation_num = mv_evaluation_num[0].get_text().strip()
list_mv.append(mv_evaluation_num)
# Crawling plot introduction
mv_plot = soup_mv.find_all('span',attrs={"class":"all hidden"}) # Plot introduction
if mv_plot == []:
list_mv.append(None)
else:
string_plot = mv_plot[0].get_text().strip().split()
new_string_plot = ' '.join(string_plot)
list_mv.append(new_string_plot)
# Join the movie website
list_mv.append(url)
return list_mvDefine a crawling function for each movie content, and then start calling the function:
First create a list_ all_ The MV list is used to store the return value of the calling function, that is, to store the information of each movie, as shown in the following figure,
list_all_mv = []
dict_mv_info = {}
for number in range(len(list_url_mv)):
mv_info = loading_mv(list_url_mv[number],number)
list_all_mv.append(mv_info)
print('-----End of operation-----')
pd = DataFrame(list_all_mv,columns=['Film ranking','Movie name','Release time','director','to star','Film type','Film rating','Number of evaluators','Film introduction','Movie link'])
# print(pd)
pd.to_excel(r'C:\Users\86178\Desktop\Douban film Top250.xlsx')Finally, the top 250 excel table of Douban film is obtained, as shown in the following figure:
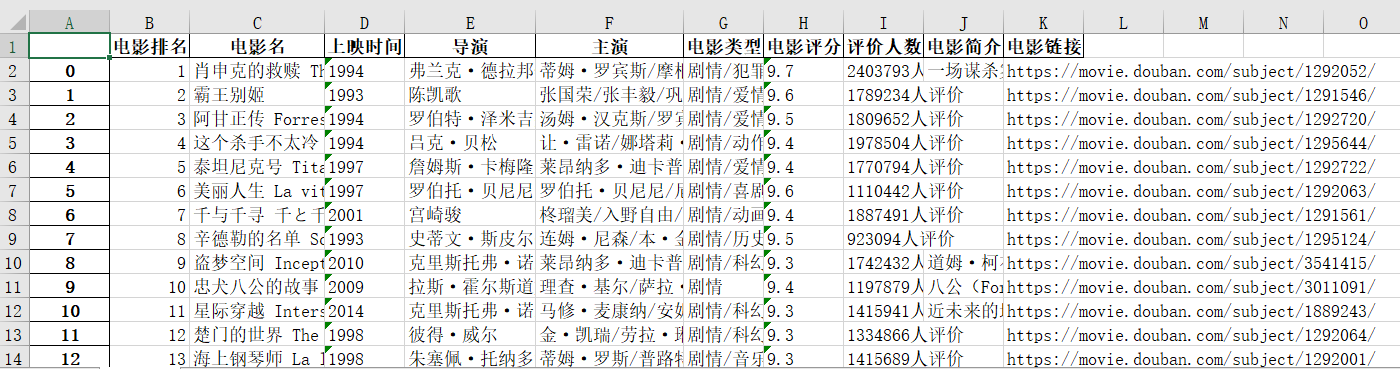
Attachment: when you use the same IP for too many visits, the website may block your IP, similar to:
HTTPSConnectionPool(host='movie.douban.com', port=443): Max retries exceeded with url: /subject/1292052/ (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x000002B3FBAB05C0>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed'))terms of settlement:
1. It can be solved by changing a WiFi, because different WiFi will have different external IP, so when our IP is blocked, just change a WiFi.
2. Build agent IP pool. The principle of proxy IP pool is to find some available IPS and add them to requests, that is, specify an IP to access the website
The IP format is: 'http':'http://IP: Port ', such as' http':'http://119.14.253.128:8088 '
response = requests.get(url=url,headers=headers,proxies=ip,timeout=3) # Request Baidu's server within 0.1 seconds
There are many ways to get IP
Free proxy IP http://ip.yqie.com/ipproxy.htm 66 free agent network http://www.66ip.cn/ 89 free agent http://www.89ip.cn/ Worry free agent http://www.data5u.com/ Cloud agent http://www.ip3366.net/ Fast agent https://www.kuaidaili.com/free/ Speed exclusive agent http://www.superfastip.com/ HTTP proxy IP https://www.xicidaili.com/wt/ Xiaoshu agent http://www.xsdaili.com Xila free proxy IP http://www.xiladaili.com/ Xiaohuan HTTP proxy https://ip.ihuan.me/ Network wide proxy IP http://www.goubanjia.com/ Feilong proxy IP http://www.feilongip.com/
Building a proxy IP pool is to crawl the IP and ports on these websites, and then make the crawled content into a standard format. In the future, I will publish a blog on building proxy IP pool.
2, Data analysis
As a saying goes, data is money. After we get the data, we need further analysis to play a greater role. Reading excel is the same as writing, and the result is dataframe.
def excel_to_dataframe(excel_path):
df = pd.read_excel(excel_path,keep_default_na=False) # keep_default_na=False results in '', not nan
return df
excel_path = r'C:\Users\86178\Desktop\Douban film Top250.xlsx'
data_mv = excel_to_dataframe(excel_path)The following will deal with the crawled content, such as release time, film type, starring or director.
1. Analysis of release time
Draw histogram
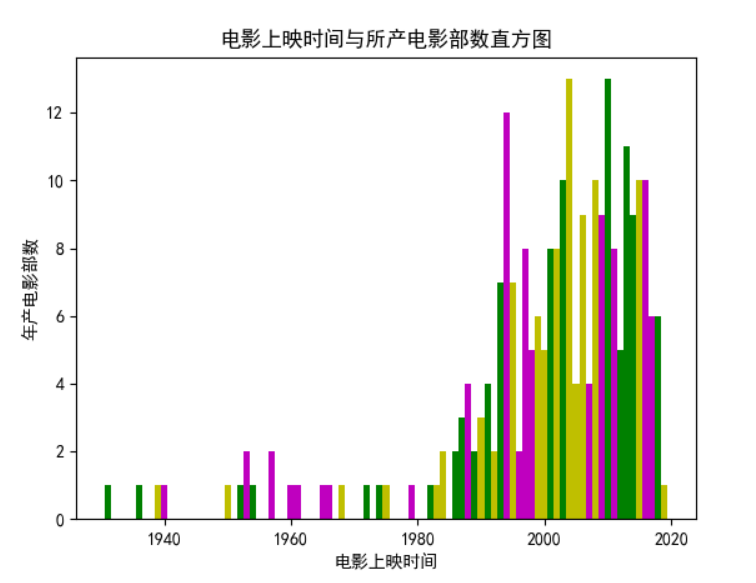
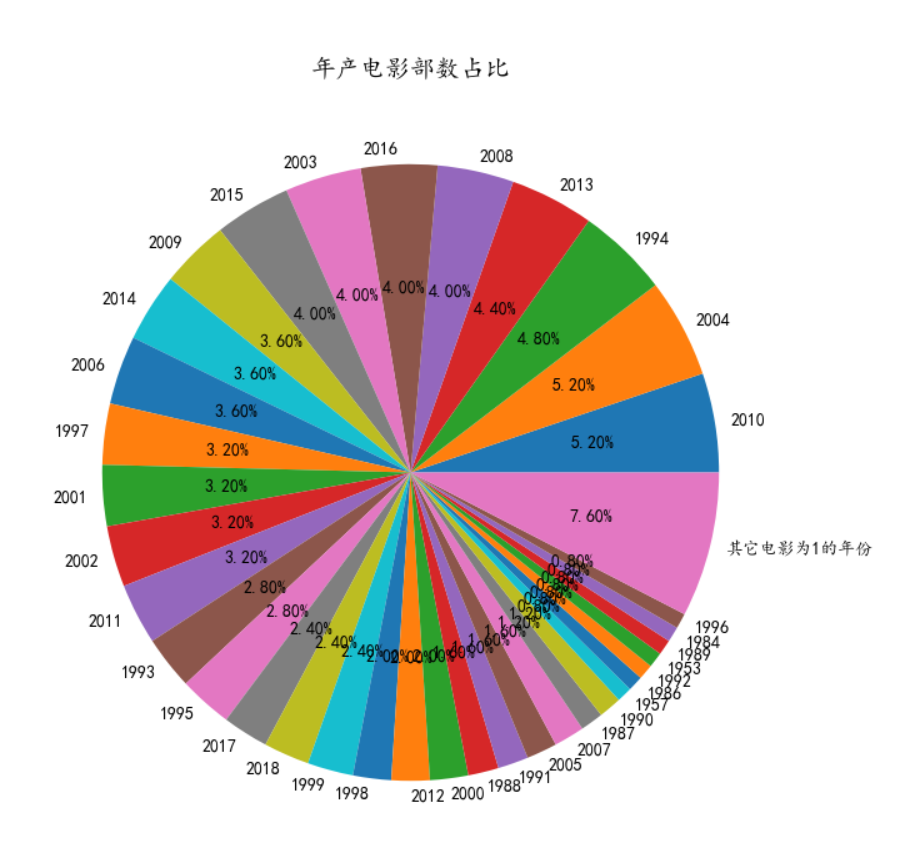
Draw pie chart
Draw a line chart
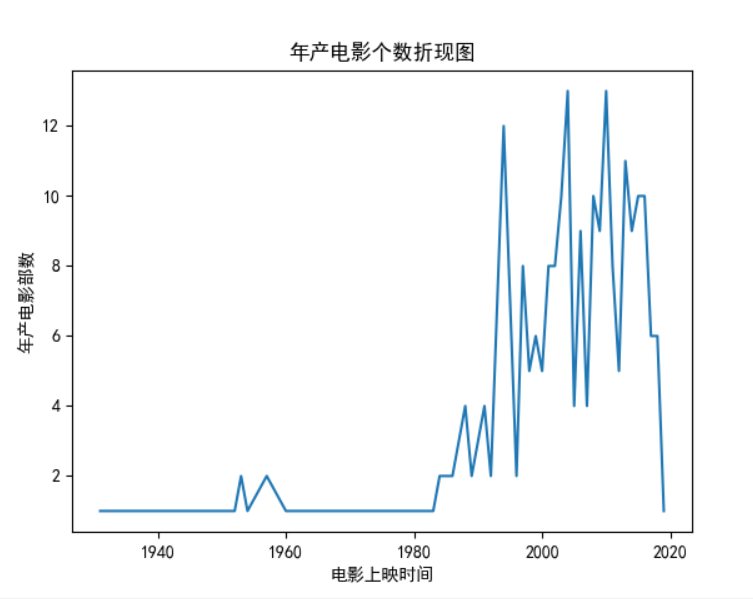
1. Based on the above three figures, the main films on the list are concentrated around 1993-2016.
2. It can be concluded that there were 12 or more films released in 1994, 2004 and 2010.
3. It can't be concluded that with the growth of time, the more films on the list.
2. Analysis of film types
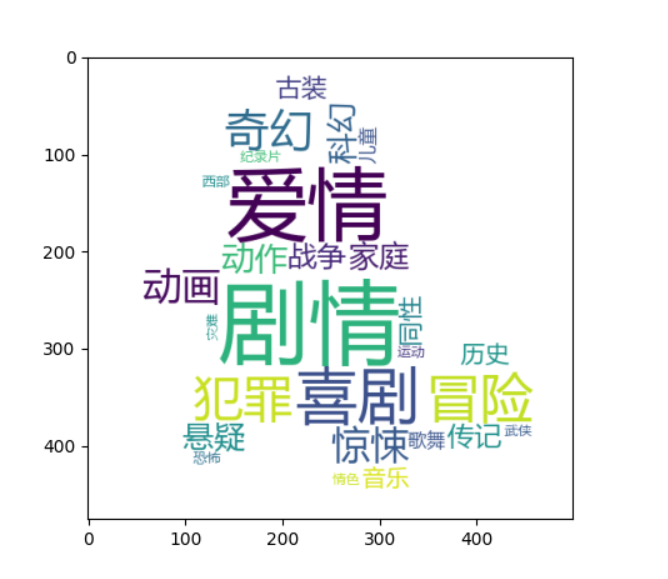
Draw word cloud
Count all movie types and draw a word cloud, as shown in the following figure
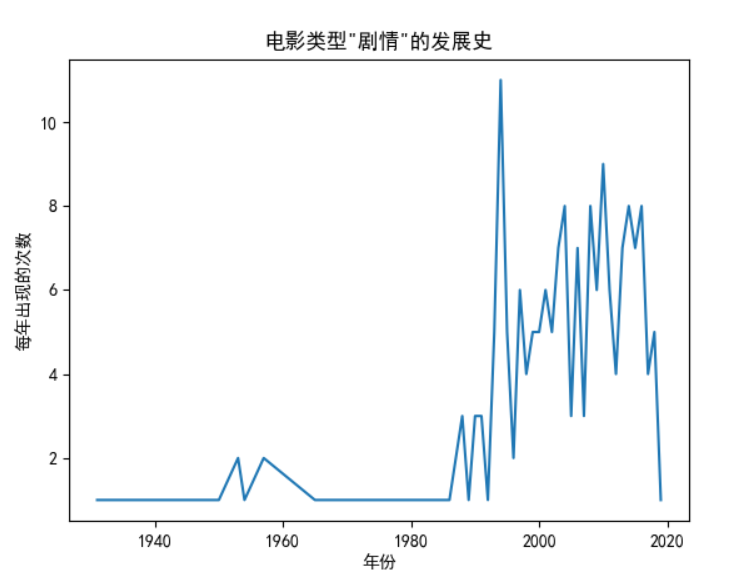
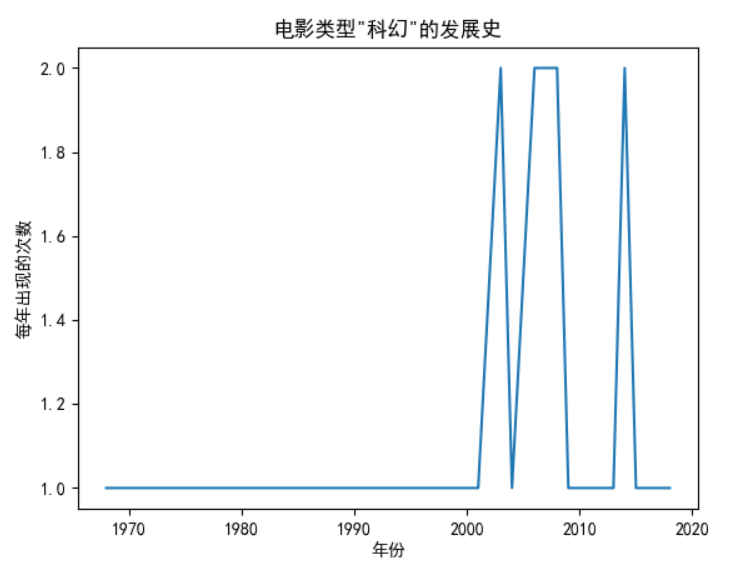
Analyze the broken line diagram of a film type over time
Analysis of "plot"
Analysis of "science fiction"
Based on the above conclusions:
1. The film type "plot" has always been loved by people, especially when the film reached the peak of 12 in 1994. Combined with the analysis of time in the previous step, it can be concluded that all the films released in 1994 are of "plot" type, and up to now, they are still classic.
2. "Science fiction" films could not achieve such good results when science and technology were not developed in the early stage. However, with the development of time and the progress of science and technology, "science and technology" films have developed.
3. Analyze actors or directors
The ranking of actors or directors is mainly based on the film score, because it is recognized by people on the top 250 list, so we roughly judge the actor ranking according to the total score.
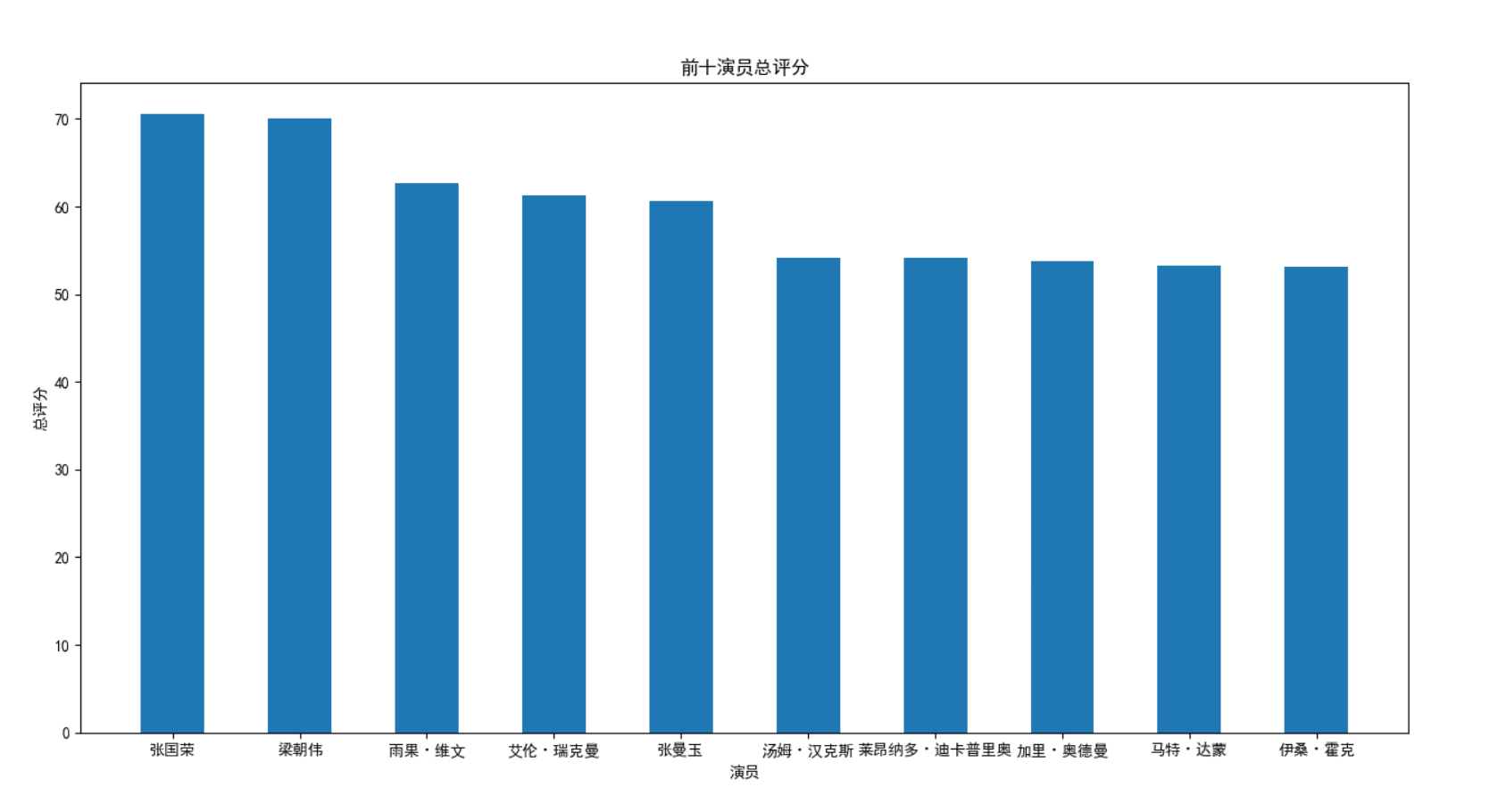
1. Top ten actors
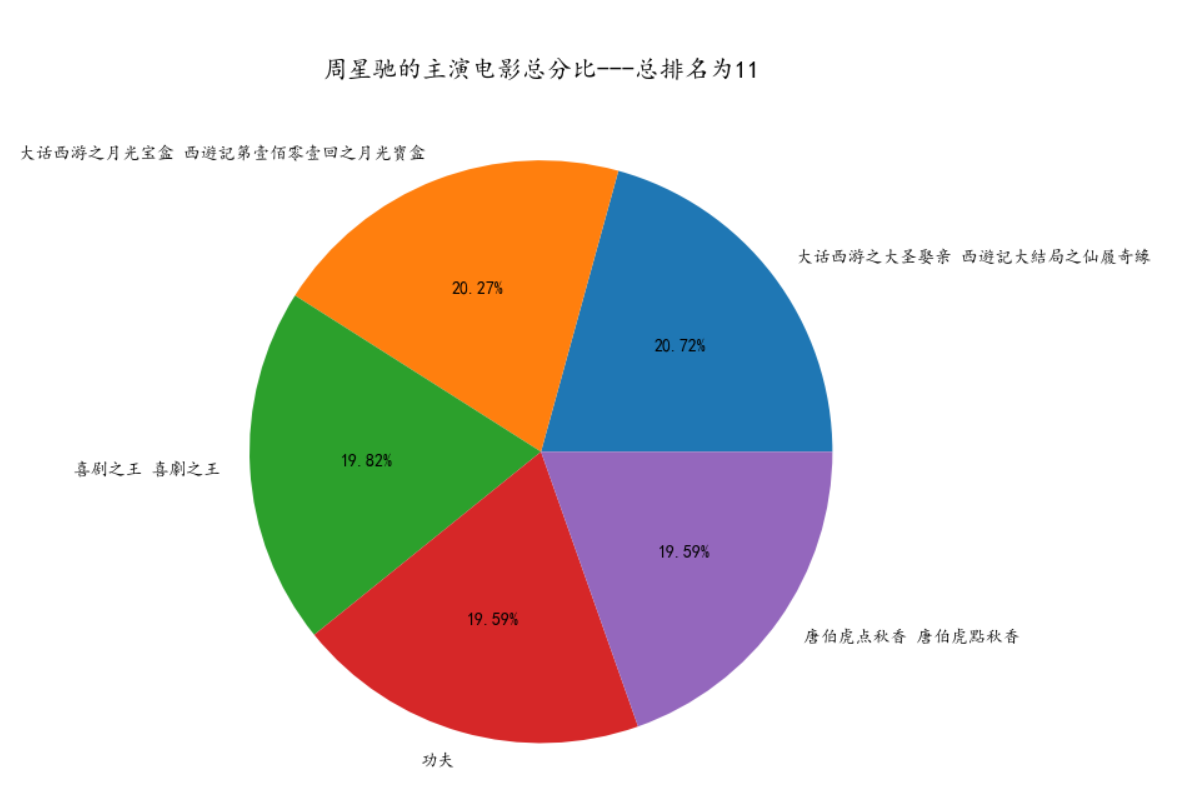
2. Analysis of the score of an actor's film
Based on the above results, it can be concluded that:
1. The top ten actors are: Zhang Guorong, Liang Chaowei
2. Analyze the movie scores of an actor
III. complete code
1. Crawl code
import requests
from bs4 import BeautifulSoup
from pandas import DataFrame
'''
Finally, it was successfully extracted
'Film ranking','Movie name','Release time','director','to star','Film type','Film rating','Number of evaluators','Movie link'
Finally, the results are output to Douban film Top250.xlsx
But there are still problems: extracting languages and producing countries/Area when there is no selector The situation.
To solve this problem, you may need to xpath
'''
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.55'}
start_num = [i for i in range(0,226,25)]
list_url_mv = [] # URL of all movies
for start in start_num:
url = 'https://movie.douban.com/top250?start={}&filter='.format(start)
print('Processing url: ',url)
response = requests.get(url=url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
url_mv_list = soup.select('#content > div > div.article > ol > li > div > div.info > div.hd > a')
# print(url_mv_list)
for index_url in range(len(url_mv_list)):
url_mv = url_mv_list[index_url]['href']
list_url_mv.append(url_mv)
# print(url_mv)
# Process each film
def loading_mv(url,number):
list_mv = []
print('-----Processing page{}Film-----'.format(number+1))
list_mv.append(number+1) # ranking
# Parsing web pages
response_mv = requests.get(url=url,headers=headers)
soup_mv = BeautifulSoup(response_mv.text,'html.parser')
# Crawling movie title
mv_name = soup_mv.find_all('span',attrs={'property':'v:itemreviewed'}) # Movie name
mv_name = mv_name[0].get_text()
list_mv.append(mv_name)
# print(mv_name)
# Crawling for the release time of the film
mv_year = soup_mv.select('span.year') # Film release time
mv_year = mv_year[0].get_text()[1:5]
list_mv.append(mv_year)
# print(mv_year)
# Crawling director information
list_mv_director = [] # director
mv_director = soup_mv.find_all('a',attrs={'rel':"v:directedBy"})
for director in mv_director:
list_mv_director.append(director.get_text())
string_director = '/'.join(list_mv_director) # Redefine format
list_mv.append(string_director)
# print(list_mv_director)
# Crawling information
list_mv_star = [] # to star
mv_star = soup_mv.find_all('span',attrs={'class':'actor'})
if mv_star == []: # There was no starring role in part 210
list_mv.append(None)
else :
mv_star = mv_star[0].get_text().strip().split('/')
mv_first_star = mv_star[0].split(':')
list_mv_star.append(mv_first_star[-1].strip())
del mv_star[0] # Remove 'starring' field
for star in mv_star:
list_mv_star.append(star.strip())
string = '/'.join(list_mv_star) # Redefine format
list_mv.append(string)
# Crawl movie type
list_mv_type = [] # Film type
mv_type = soup_mv.find_all('span',attrs={'property':'v:genre'})
for type in mv_type:
list_mv_type.append(type.get_text())
string_type = '/'.join(list_mv_type)
list_mv.append(string_type)
# print(list_mv_type)
# Crawl movie ratings
mv_score = soup_mv.select('strong.ll.rating_num') # score
mv_score = mv_score[0].get_text()
list_mv.append(mv_score)
# Number of crawling evaluators
mv_evaluation_num = soup_mv.select('a.rating_people') # Number of evaluators
mv_evaluation_num = mv_evaluation_num[0].get_text().strip()
list_mv.append(mv_evaluation_num)
# Crawling plot introduction
mv_plot = soup_mv.find_all('span',attrs={"class":"all hidden"}) # Plot introduction
if mv_plot == []:
list_mv.append(None)
else:
string_plot = mv_plot[0].get_text().strip().split()
new_string_plot = ' '.join(string_plot)
list_mv.append(new_string_plot)
# Join the movie website
list_mv.append(url)
return list_mv
# url1 = 'https://movie.douban.com/subject/1292052/'
# url2 = 'https://movie. douban. COM / subject / 26430107 / '# 210
# a = loading_mv(url1,1)
# # b = loading_mv(url2,210)
# # list_all_mv.append(a)
# # list_all_mv.append(b)
list_all_mv = []
dict_mv_info = {}
for number in range(len(list_url_mv)):
mv_info = loading_mv(list_url_mv[number],number)
list_all_mv.append(mv_info)
print('-----End of operation-----')
pd = DataFrame(list_all_mv,columns=['Film ranking','Movie name','Release time','director','to star','Film type','Film rating','Number of evaluators','Film introduction','Movie link'])
# print(pd)
pd.to_excel(r'C:\Users\86178\Desktop\Douban film Top250.xlsx')2. Data analysis code
'''
Yes, climb to the Douban film Top250 Conduct data analysis
Analysis content:
1. Time: time analysis
Draw histogram
Pie chart
Line chart - Movie
2.Pair type: movie type changes over time
Draw movie types over time
Movie type word cloud
3.For the leading actor or director: analyze the actor or director according to the film score
Top ten stars
Query actor/Director acting information
Information of all actors and directors
'''
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
import wordcloud
import imageio
# csv_path = 'Douban film Top250.csv' # It cannot be processed with csv, and errors may occur
# Read excel and convert it into dataframe for easy reading
def excel_to_dataframe(excel_path):
df = pd.read_excel(excel_path,keep_default_na=False) # keep_default_na=False results in '', not nan
return df
excel_path = r'C:\Users\86178\Desktop\Douban film Top250.xlsx'
data_mv = excel_to_dataframe(excel_path)
dict_time = {}
for time in data_mv['Release time']:
dict_time[time] = dict_time.get(time,0)+1
list_time = list(dict_time.items())
list_time.sort(key=lambda x:x[1],reverse=True)
list_year = [] # particular year
list_times = [] # Number of occurrences
for t in list_time:
list_year.append(t[0])
list_times.append(t[1])
# Draw histogram
def make_Histogram(list_x,list_y,color):
# Solve the problem of Chinese display
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.bar(list_x,list_y,width=1,color=color)
plt.title('Histogram of film release time and number of films produced')
plt.xlabel('Film release time')
plt.ylabel('Number of films per year')
plt.show()
# make_Histogram(list_year,list_times,color=['g','y','m']) # Draw a histogram of movie year occurrences
# Draw pie chart
def make_Pie(list_times,list_year):
mpl.rcParams['font.sans-serif'] = ['KaiTi', 'SimHei', 'FangSong'] # For Chinese font, regular script is preferred. If regular script cannot be found, bold script is used
mpl.rcParams['font.size'] = 12 # font size
mpl.rcParams['axes.unicode_minus'] = False # The negative sign is displayed normally
plt.figure(figsize=(10,10),dpi=100) # The size of the view
plt.pie(list_times, # Specify drawing data
labels=list_year, # Add labels outside the pie chart circle
autopct='%1.2f%%', # Format percentage
textprops={'fontsize':10}, # Set the attribute font size and color in the pie chart
labeldistance=1.05) # Set the distance between each sector label (legend) and the center of the circle
# plt.legend(fontsize=7) # Set pie chart indication
plt.title('Proportion of films per year')
plt.show()
pie_other = len([i for i in list_time if i[1]==1]) # Classify films with a year of 1 into other categories
list_pie_year = []
list_pie_times = []
for i in list_time:
if i[1] == 1:
break
else :
list_pie_year.append(i[0])
list_pie_times.append(i[1])
list_pie_year.append('Other films are 1 years')
list_pie_times.append(pie_other)
#
# make_Pie(list_pie_times,list_pie_year)
# make_Pie(list_times,list_year)
# Draw discount chart
def make_Plot(list_year,list_times):
# Solve the problem of Chinese display
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.title('Discount chart of number of films per year')
plt.xlabel('Film release time')
plt.ylabel('Number of films per year')
plt.plot(list_year, list_times)
plt.show()
list_plot_year = []
list_plot_times = []
list_time.sort(key=lambda x:int(x[0]))
for t in list_time:
list_plot_year.append(t[0])
list_plot_times.append(t[1])
# make_Plot(list_plot_year,list_plot_times)
mv_type = data_mv['Film type']
dict_type = {}
for type in mv_type:
line = type.split('/')
for t in line:
dict_type[t] = dict_type.get(t,0) + 1
list_type = list(dict_type.items())
list_type.sort(key=lambda x:x[1],reverse=True)
# Draw word cloud
def c_wordcloud(ls):
# string1 = ' '.join(ls)
gpc=[]
for i in ls:
gpc.append(i[0])
string1=" ".join('%s' % i for i in gpc)
color_mask=imageio.imread(r"logo.jpg")
wc = wordcloud.WordCloud(random_state=30,
width=600,
height=600,
max_words=30,
background_color='white',
font_path=r'msyh.ttc',
mask=color_mask
)
wc.generate(string1)
plt.imshow(wc)
plt.show()
# wc.to_file(path)
# c_wordcloud(list_type)
# [year, movie type]
list_time_type = []
for i in range(250):
line = data_mv['Film type'][i].split('/')
for j in line:
time_type = []
time_type.append(data_mv['Release time'][i])
time_type.append(j)
list_time_type.append(time_type)
dict_time_type = {}
for i in list_time_type:
dict_time_type[tuple(i)] = dict_time_type.get(tuple(i),0) + 1
list_num_time_type = list(dict_time_type.items())
list_num_time_type.sort(key=lambda x:x[1],reverse=True)
# The development history of making a film type (in terms of film type)
def mv_time_type(type_name):
list_mv_type = []
for num in list_num_time_type:
if num[0][1] == type_name:
list_mv_type.append(num)
list_mv_type.sort(key=lambda x:x[0][0],reverse=False)
list_year = []
list_times = []
for t in list_mv_type:
list_year.append(t[0][0])
list_times.append(t[1])
# Solve the problem of Chinese display
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.title('Film type"{}"Development history of'.format(type_name))
plt.xlabel('particular year')
plt.ylabel('Number of occurrences per year')
plt.plot(list_year,list_times)
plt.show()
# mv_time_type('plot ')
# mv_time_type('science fiction') # Mainly after 2000
# Calculate the score and total score of each work directed and starring
def people_score(peo_dir_star):
list = []
for num in range(250):
if data_mv[peo_dir_star][num] == '':
continue
else:
peoples = data_mv[peo_dir_star][num].split('/')
for people in peoples:
list_p_s = []
list_p_s.append(people)
list_p_s.append(data_mv['Film rating'][num])
list_p_s.append(data_mv['Film ranking'][num])
list_p_s.append(data_mv['Movie name'][num])
list.append(list_p_s)
return list
list_director = people_score('director')
list_star = people_score('to star')
# Best director or actor - based on the total score
def best_people(list_people):
dict_people = {}
for i in list_people:
dict_people[i[0]] = dict_people.get(i[0],[]) + [(i[1],i[2],i[3])]
for i in dict_people.items():
i[1].append(float('{:.2f}'.format(sum([j[0] for j in i[1]]))))
# ('Gong Li', [(9.6, 2, 'Farewell My Concubine'), (9.3, 30, 'alive'), (8.7, 109, 'Tang Bohu points Qiuxiang'),'27.60 '])
list_new_people = list(dict_people.items())
list_new_people.sort(key=lambda x:x[1][-1],reverse=True)
print('The search is over, please start your operation (enter a number)!\n---Enter 1 Top 10 stars---\n---Enter 2 to search for the actor's performance---\n---Input 3 output all actors---')
print('-----input enter sign out-----')
select_number = input('Start input operation:')
while select_number != '':
if select_number == '1':
print('Performance information of top ten actors:')
list_all_score = [] # Total score
list_prople_name = []
for i in list_new_people[0:10]:
print(i)
list_prople_name.append(i[0])
list_all_score.append(i[1][-1])
# Solve the problem of Chinese display
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# plt.figure(figsize=(10, 10), dpi=100) # The size of the view
plt.title('Total score of top ten actors')
plt.xlabel('performer')
plt.ylabel('Total score')
plt.bar(list_prople_name,list_all_score,width=0.5)
plt.show()
elif select_number == '2':
# star_name = input('enter the actor name you want to know: ')
star_name = ' '
while star_name != '':
star_name = input('Enter the actor name you want to know:')
list_mv_name = [] # Movie name
list_mv_score = [] # Film rating
for number,i in enumerate(list_new_people):
if star_name == i[0]:
all_score = i[1][-1] # Total score
del i[1][-1]
for j in i[1]:
list_mv_name.append(j[2])
list_mv_score.append(j[0])
print('{} Starring in Douban film Top250 Medium ranking{}Yes<{}>The score is {}'.format(star_name,j[1],j[2],j[0]))
print("{}Co starring{}The total score of the film is{},Ranked third among all actors{}".format(star_name,len(i[1]),all_score,number+1))
print('End of query!')
# Calculation pie chart
def pie_mv_score():
mpl.rcParams['font.sans-serif'] = ['KaiTi', 'SimHei','FangSong'] # For Chinese font, regular script is preferred. If regular script cannot be found, bold script is used
mpl.rcParams['font.size'] = 12 # font size
mpl.rcParams['axes.unicode_minus'] = False # The negative sign is displayed normally
plt.figure(figsize=(10,10))
plt.pie(list_mv_score,
labels=list_mv_name,
autopct='%1.2f%%', # Calculate percentage, set and format
textprops={'fontsize': 10})
plt.title('{}Total score ratio of starring films---The total ranking is{}'.format(star_name,number+1))
plt.show()
pie_mv_score()
break
else:
print('There is no such person!')
break
elif select_number == '3':
for i in list_new_people:
print(i)
else :
print('No such operation!')
select_number = input('After the query, you can continue to enter the query serial number:')
print('-----End of query-----')
best_people(list_star)