While listening to AI Studio courses and other online courses
-
Taking notes is too slow
-
Incomplete memory
-
Can't keep up with the teacher's lecture speed
-
Missed the teacher's lecture because of taking notes
Worry about problems? Come and create a "theft note" with paddleocr!
Your browser does not support video tags.Introduction to PaddleOCR
OCR (Optical Character Recognition) is one of the important directions of computer vision. Traditionally defined OCR is generally oriented to scanned document objects. Now we often say OCR generally refers to Scene Text Recognition (STR), which is mainly oriented to natural scenes. Although OCR is a relatively specific task, it involves many technologies, including text detection, text recognition, end-to-end text recognition, document analysis and so on.
OCR industry practice needs a set of complete and whole process solutions to speed up R & D progress and save valuable R & D time. In other words, the ultra lightweight model and its whole process solution are just needed, especially for mobile terminals and embedded devices with limited computing power and storage space.
In this context, industrial OCR development kit PaddleOCR emerge as the times require.
The construction idea of PaddleOCR starts from the user portrait and needs, relying on the core framework of the propeller, selects and replicates rich cutting-edge algorithms, develops PP characteristic models more suitable for industrial landing based on the reproduced algorithms, integrates training and promotion, and provides a variety of prediction deployment methods to meet the different demand scenarios of practical application.
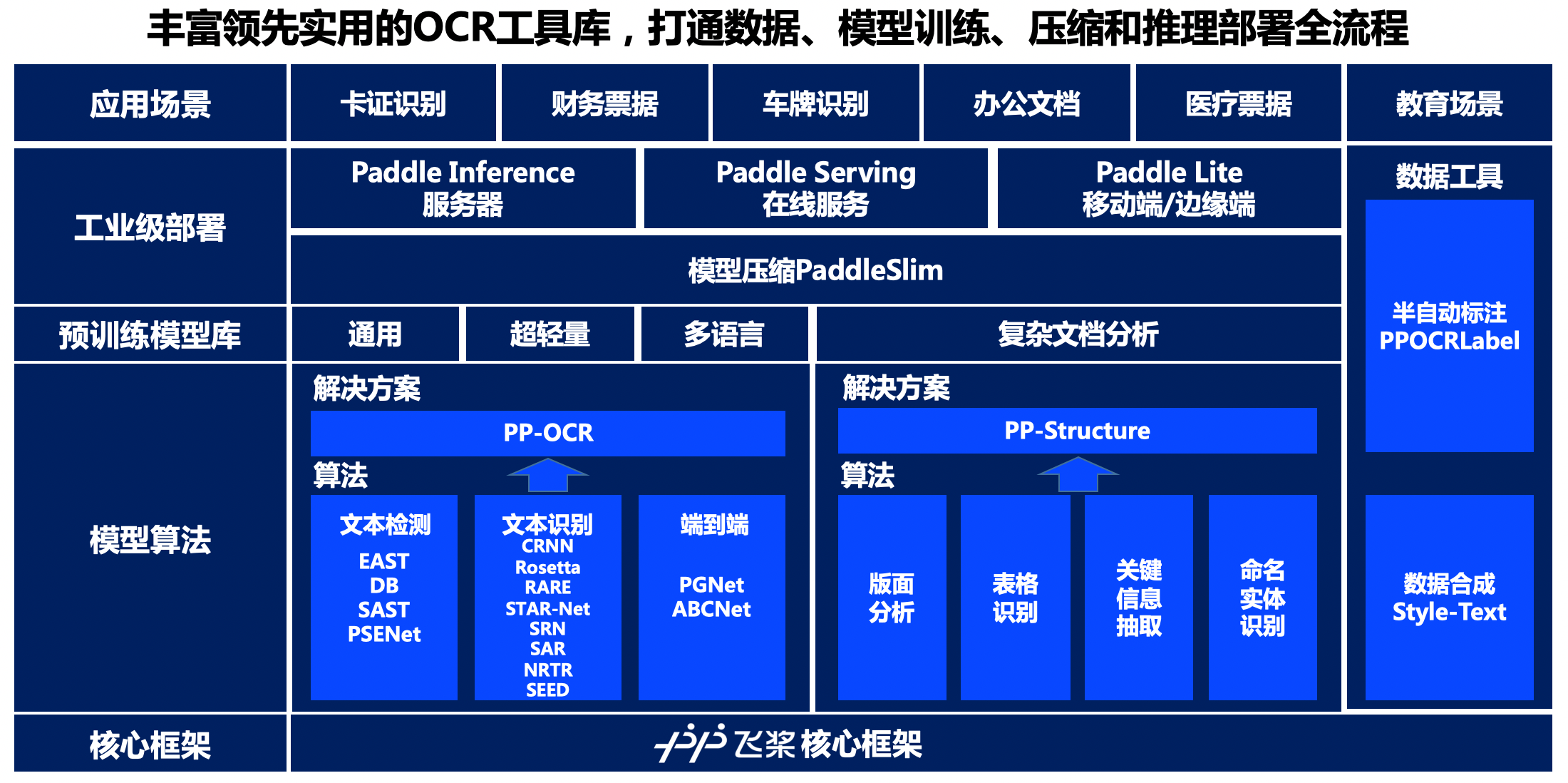
As can be seen from the panorama, PaddleOCR relies on the core framework of the propeller, provides rich solutions at the levels of model algorithm, pre training model library and industrial deployment, and provides data synthesis and semi-automatic data annotation tools to meet the data production needs of developers.
At the model algorithm level, PaddleOCR provides solutions for word detection and recognition and document structural analysis. In terms of text detection and recognition, PaddleOCR reproduces or opens source four text detection algorithms, eight text recognition algorithms and one end-to-end text recognition algorithm. On this basis, it has developed PP-OCR series general text detection and recognition solutions; In the aspect of document structure analysis, PaddleOCR provides algorithms such as layout analysis, table recognition, key information extraction and named entity recognition, and puts forward the PP structure document analysis solution. Rich selection algorithms can meet the needs of developers in different business scenarios. The unification of code framework also facilitates developers to optimize and compare the performance of different algorithms.
At the level of pre training model library, based on PP-OCR and PP structure solutions, PaddleOCR developed and opened source PP series characteristic models suitable for industrial practice, including general, ultra lightweight and multilingual text detection and recognition models and complex document analysis models. PP series characteristic models are deeply optimized on the original algorithm, so that their effect and performance can reach the industrial practical level. Developers can not only directly apply to business scenarios, but also use business data to make simple finetune, so as to easily develop a "practical model" suitable for their own business needs.
At the industrial deployment level, PaddleOCR provides a server-side prediction scheme based on Paddle Inference, a service-oriented deployment scheme based on Paddle Serving, and an end-side deployment scheme based on paddle Lite to meet the deployment requirements in different hardware environments. At the same time, it provides a model compression scheme based on PaddleSlim, which can further compress the model size. The above deployment methods have completed the whole process of training and promotion, so as to ensure that developers can deploy efficiently, stably and reliably.
At the data tool level, PaddleOCR provides a semi-automatic data annotation tool PPOCRLabel and a data synthesis tool style text to help developers more conveniently train the data sets and annotation information required for production model. As the first open source semi-automatic OCR data annotation tool in the industry, PPOCRLabel has built-in PP-OCR model to realize the annotation mode of pre annotation + manual verification, which can greatly improve the annotation efficiency and save labor cost. The data synthesis tool style text mainly solves the problem that the real data of the actual scene is seriously insufficient, and the traditional synthesis algorithm can not synthesize the text style (font, color, spacing and background). Only a few target scene images are needed, and a large number of text images similar to the style of the target scene can be synthesized in batches.
Technical scheme
study Hands on OCR · Lecture 10 After class, I found it very useful, especially that OCR can solve the problem of taking notes, so I came up with the idea of taking notes with PaddleOCR, which not only records the text, but also restores the text position, so as to "steal" the screen content.
-
Interface selection: tkinter is selected because the interface is simple.
-
Screenshot implementation: originally, I wanted to directly select the screenshot area with the mouse like wechat, but due to the limited level, I chose to use keyboard and pyautogui to cooperate with the mouse to locate the video area, and then use pyautogui to take screenshots.
-
OCR implementation: PaddleOCR is so easy to use. Of course, PaddleOCR is used. It can not only recognize text, but also get text position.
-
Note taking: the text recognized by PaddleOCR can be restored to the ppt file according to the text position. This is basically realized, but the positioning and restoration of the position of pictures and lines can not be realized, which needs to be further improved.
code implementation
1. Realization of graphic interface with tkinter
root = tk.Tk()
root.geometry("200x100+200+50")
root.attributes("-topmost", True)
root.mainloop()
2. Using keyboard and pyautogui with mouse to locate video region
def pos(self):
print('Please ctrl+1 Determine the position of the upper left corner:')
while True:
hotkey = keyboard.read_hotkey()
if 'ctrl' in hotkey and '1' in hotkey:
x1, y1 = pg.position()
print('Upper left corner position:',[x1,y1])
keyboard._pressed_events={}
break
print('\n Please ctrl+2 Determine the position of the lower right corner:')
while True:
hotkey2 = keyboard.read_hotkey()
if '2' in hotkey2 and 'ctrl' in hotkey2:
x2, y2 = pg.position()
print('Bottom right position:',[x2,y2])
keyboard._pressed_events={}
break
self.size=[x1,y1,x2-x1,y2-y1]
return self.size
3. Text and position recognition with PaddleOCR
Use the PaddleOCR whl package through Python script. The whl package will automatically download the ppocr lightweight model as the default model.
- Whole process of detection + direction Classifier + recognition
# The multilingual languages currently supported by Paddleocr can be switched by modifying the lang parameter # For example, 'Ch', 'en', 'fr', 'German', 'Korean', 'Japan'` ocr = PaddleOCR(use_angle_cls=True, lang="ch")
def ocr(self,*event):
im=pg.screenshot(region=self.size)
img=cv2.cvtColor(np.asarray(im),cv2.COLOR_BGR2RGB)
cv2.imwrite('img.jpg',img)
img_path = 'img.jpg'
result = ocr.ocr(img_path, cls=True)
f = "biji.txt"
with open(f,"a") as file:
for line in result:
file.write(line[1][0] +"\n")
print(line[1][0])
file.write("\n")
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
4. Restore the text and position recognized by PaddleOCR to ppt with pptx
def ppt(size,boxes,txts):
# Instantiate ppt document object
try:
prs = Presentation('test.pptx')
except:
prs = Presentation()
# Insert slide
blank_slide = prs.slide_layouts[6]
slide_1 = prs.slides.add_slide(blank_slide)
for i in range(len(boxes)):
# Preset position and size
left =Cm(boxes[i][0][0]/size[2]*25.4) # left and top are relative positions
top = Cm(boxes[i][0][1]/size[3]*19.05*0.9)
width = Cm((boxes[i][1][0]-boxes[i][0][0])/size[2]*25.4) # width and height are the size of the text box
height = Cm((boxes[i][3][1]-boxes[i][0][1])/size[3]*19.05)
# Adds a text box at the specified location
textbox = slide_1.shapes.add_textbox(left, top, width, height)
tf = textbox.text_frame
tf.margin_left=0
tf.margin_right=0
tf.margin_top=0
tf.margin_bottom=0
# Write text in the text box
para = tf.add_paragraph() # New paragraph
para.text = txts[i] # Write text to paragraph
para.alignment = PP_ALIGN.LEFT # Center
para.line_spacing = 0.0 # 0.0 times line spacing
### Set font
font = para.font
font.name = 'Microsoft YaHei ' # Font type
#font.name = 'Calibri' # Font type
font.bold = False # Bold
font.size = Pt(int((boxes[i][2][1]-boxes[i][0][1])*0.75)) # size
# Save ppt
prs.save('test.pptx')
Software
The source code is placed in dmbj. Com in the / home/aistudio/work directory In the PY file
function
python dmbj.py #It needs to be on the local computer dmbj Py directory running
Screenshot and UI interface
Implementation based on paddleocr and tkinter

usage method
1. Click the screenshot area setting button, move the mouse to the upper left corner of the video, and set the upper left corner with "ctrl+1"
2. Move the mouse to the lower right corner of the video and set the lower right corner with "ctrl+2"
3. Click the "note taking" button to start "stealing note" in the screenshot area and record it in the pptx document (see the effect picture).
Note:
1. To avoid repetition, click the "note taking" button with the mouse after the video screen is switched, and the notes will be automatically added to the pptx document, with 1 page of pptx document for each screen.
2. At the same time, save a text note in a txt file.
Note effect






I got diamond level in AI Studio and lit 10 badges to turn on each other~
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/335435