Spark operation Kudu creates a table
- Spark and KUDU integration support:
- DDL operation (create / delete)
- Local Kudu RDD
- Native Kudu data source for DataFrame integration
- Read data from kudu
- Insert / update / upsert / delete from Kudu
- Predicate push down
- Schema mapping between Kudu and Spark SQL
- So far, we have heard of several contexts, such as SparkContext, SQLContext, HiveContext and SparkSession. Now, we will use Kudu to introduce a KuduContext. This is the main serializable object that can be broadcast in Spark applications. This class represents the interaction with Kudu Java client in Spark executor.
- KuduContext provides the methods required to perform DDL operations, interfaces with the native Kudu RDD, updates / inserts / deletes data, and converts data types from Kudu to Spark.
Create table
- The table defining kudu needs to be divided into five steps:
- Provide table name
- Provide schema
- Provide primary key
- Define important options; For example: define the schema of the partition
- Call the create Table api
- Code development
package cn.it
import java.util
import cn.it.SparkKuduDemo.TABLE_NAME
import org.apache.kudu.client.CreateTableOptions
import org.apache.kudu.spark.kudu.KuduContext
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
object SparkKuduTest {
def main(args: Array[String]): Unit = {
//Building a sparkConf object
val sparkConf: SparkConf = new SparkConf().setAppName("SparkKuduTest").setMaster("local[2]")
//Building a SparkSession object
val sparkSession: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
//Get the sparkContext object
val sc: SparkContext = sparkSession.sparkContext
sc.setLogLevel("warn")
//Building KuduContext objects
val kuduContext = new KuduContext("node2:7051", sc)
//1. Create table
createTable(kuduContext)
/**
* Create table
*
* @param kuduContext
* @return
*/
def createTable(kuduContext: KuduContext) = {
//If the table does not exist, create it
if (!kuduContext.tableExists(TABLE_NAME)) {
//To build the table structure information of the created table is to define the fields and types of the table
val schema: StructType = StructType(
StructField("userId", StringType, false) ::
StructField("name", StringType, false) ::
StructField("age", IntegerType, false) ::
StructField("sex", StringType, false) :: Nil)
//Specifies the primary key field of the table
val keys = List("userId")
//Specify the related properties required to create the table
val options: CreateTableOptions = new CreateTableOptions
//Define the fields for the partition
val partitionList = new util.ArrayList[String]
partitionList.add("userId")
//Add partition as hash partition
options.addHashPartitions(partitionList, 6)
//Create table
kuduContext.createTable(TABLE_NAME, schema, keys, options)
}
}
}
}When defining a table, you should pay attention to the option value of Kudu table. You will notice that we call the "asJava" method when specifying the list of column names that make up the range partition column. This is because here, we call the Kudu Java client itself, which requires Java objects (i.e. java.util.List) instead of Scala's list objects; (to make the "asJava" method available, remember to import the JavaConverters library.) After creating the table, point the browser to http//master hostname: 8051/tables
- To view the Kudu main UI, you can find the created table. By clicking the table ID, you can see the table pattern and partition information.
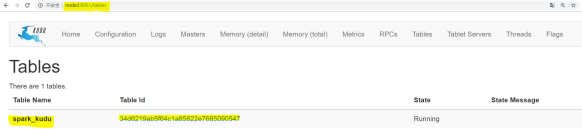
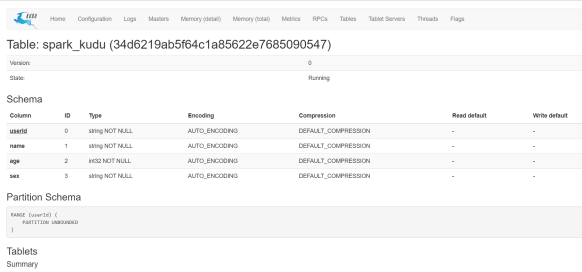
Click Table id to observe the schema and other information of the table:
- 📢 Blog home page: https://lansonli.blog.csdn.net
- 📢 Welcome to like 👍 Collection ⭐ Leaving a message. 📝 Please correct any mistakes!
- 📢 This article was originally written by Lansonli and started on CSDN blog 🙉
- 📢 Big data series articles will be updated every day. Don't forget that others are still running when you stop to have a rest. I hope you can seize the time to study and make every effort to go to a better life ✨