1, Retrospective dependency parsing
Many problems can be transformed into classification problems. The dependency parser based on transfer is transformed from the problem of prediction tree structure to the problem of prediction action sequence.
There is one way:
Coding end: used to calculate the hidden layer vector representation of words
Decoding end: used to decode and calculate all action scores in the current state
2, CS224n operation requirements
Neural Transition-Based Dependency Parsing (44 points)
Job: Based on neural network, transfer dependency parser
Objective: maximize UAS value (Unlabeled attachment score)
First, look at the readme file in the job to ensure that there is local_ env. All dependencies in the YML file:
# 1. Activate your old environment:
conda activate cs224n
# 2. Install docopt
conda install docopt
# 3. Install pytorch, torchvision, and tqdm
conda install pytorch torchvision -c pytorch
conda install -c anaconda tqdm
If you want to create a new virtual environment:
# 1. Create an environment with dependencies specified in local_env.yml
# (note that this can take some time depending on your laptop):
conda env create -f local_env.yml
# 2. Activate the new environment:
conda activate cs224n_a3
# To deactivate an active environment, use
conda deactivate
The dependency parser is based on dependency parsing to process sentence structures. You can refer to the previous lecture. Dependency parsers include transfer based, graph based, feature-based and so on. This job requires a dependency syntax parser based on transfer.
At every step it maintains a partial parse, which is represented as follows:
- A stack of words that are currently being processed.
- A buffer of words yet to be processed.
- A list of dependencies predicted by the parser
Initially, there is root in the stack, the dependency list (queue) is empty, and the buffer contains all words in the sentence in order. For each operation, the parser performs a conversion, and so on until the buffer queue is empty:
(1) shift: stacks the elements of the buffer queue
(2) LEFT-ARC: merge the two dependent subtrees at the top of the stack with the left arc;
(3) RIGHT-ARC: merge the two dependent subtrees at the top of the stack with the right arc;
That is, for each operation, the dependency syntax parser is used as a classifier to calculate the maximum probability of the three actions, and then the operation of the corresponding action is carried out.
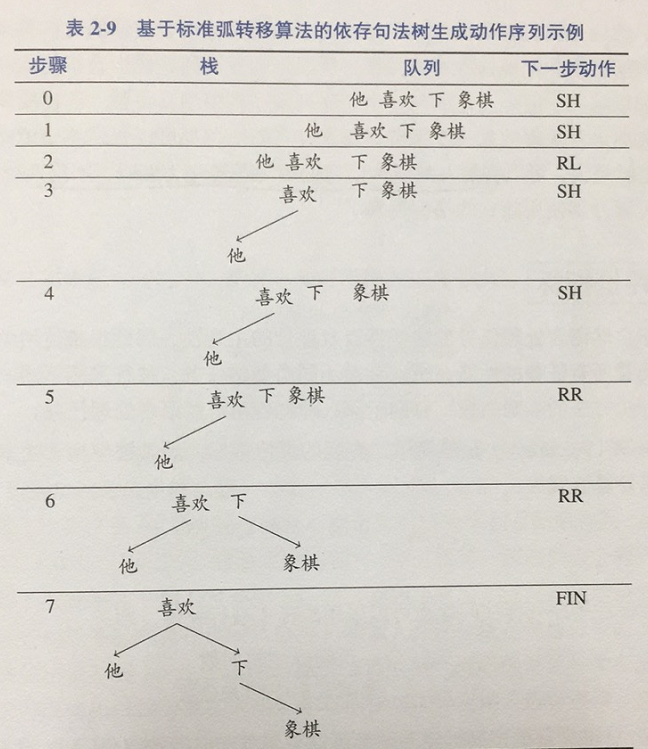
3, Specific topics
(1) (4 points) sentence: I parsed this sentence correctly
Q: what transformation was used and what new dependencies (if any) were added? The first three steps are as follows:

answer:
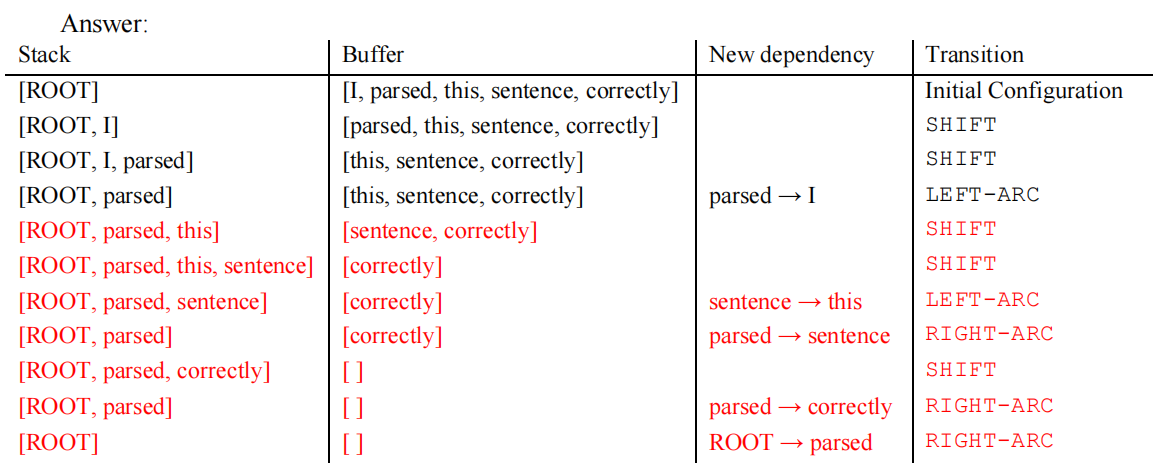
(2) (2 points) how many steps are there in a sentence with n words? Briefly explain it in 1-2 sentences.
Answer: 2n steps.
Because each word in the sentence needs two conversions before it is deleted from the stack: SHIFT and an arc. Only one of these two transformations can be performed for one word at each step of the parsing process.
(3) (6 points) implement parser_ transitions. Constructor in PartialParse class of PY__ init__ And parse_step function, that is, the conversion mechanism of the parser. You can run python parser_transitions.py part_c to test.
1) The first is parser_ transitions. Constructor in PartialParse class of PY__ init__:
class PartialParse(object):
def __init__(self, sentence):
"""Initializes this partial parse.
@param sentence (list of str): The sentence to be parsed as a list of words.
Your code should not modify the sentence.
"""
# The sentence being parsed is kept for bookkeeping purposes. Do NOT alter it in your code.
self.sentence = sentence
### YOUR CODE HERE (3 Lines)
### Your code should initialize the following fields:
### self.stack: The current stack represented as a list with the top of the stack as the
### last element of the list.
### self.buffer: The current buffer represented as a list with the first item on the
### buffer as the first item of the list
### self.dependencies: The list of dependencies produced so far. Represented as a list of
### tuples where each tuple is of the form (head, dependent).
### Order for this list doesn't matter.
###
### Note: The root token should be represented with the string "ROOT"
### Note: If you need to use the sentence object to initialize anything, make sure to not directly
### reference the sentence object. That is, remember to NOT modify the sentence object.
self.stack = ['ROOT']
self.buffer = sentence.copy() # shallow copy
self.dependencies = []
### END YOUR CODE
2) Then parser_ transitions. Parse in PartialParse class of PY_ Step function:
def parse_step(self, transition):
"""Performs a single parse step by applying the given transition to this partial parse
@param transition (str): A string that equals "S", "LA", or "RA" representing the shift,
left-arc, and right-arc transitions. You can assume the provided
transition is a legal transition.
"""
### YOUR CODE HERE (~7-12 Lines)
### TODO:
### Implement a single parsing step, i.e. the logic for the following as
### described in the pdf handout:
### 1. Shift
### 2. Left Arc
### 3. Right Arc
if transition == 'S':
self.stack.append(self.buffer.pop(0))
elif transition == 'LA':
self.dependencies.append((self.stack[-1], self.stack.pop(-2)))
elif transition == 'RA':
self.dependencies.append((self.stack[-2], self.stack.pop(-1)))
### END YOUR CODE
(4) (8 points) of course, the classifier can predict which operation to perform each time, but in order to be more efficient, you can predict the operation to be performed multiple times at a time, that is, use the following algorithm for small batch analysis:

Implement parser_ transitions. Minibatch of Py file_ Parse function, you can use python parser_transitions.py part_d test.
(5) (12 points) model training.
The model extracts the feature vector representing the current state. We will use the feature set proposed in A Fast and Accurate Dependency Parser using Neural Networks.
In utils/parser_utils.py has implemented the function of acquiring these features. This feature vector consists of a series of tags (for example, the last word in the stack, the first word in the buffer, etc.) that can be represented as
w
=
[
w
1
,
w
2
,
...
,
w
m
]
\mathbf{w}=\left[w_{1}, w_{2}, \ldots, w_{m}\right]
w=[w1, w2,..., wm], where m is the number of features, and
0
≤
w
i
<
∣
V
∣
0 \leq w_{i}<|V|
0≤wi<∣V∣,
∣
V
∣
|V|
∣ V ∣ is the size of the vocabulary. Then our network finds the embedding of each word and connects them to an input vector:
x
=
[
E
w
1
,
...
,
E
w
m
]
∈
R
d
m
\mathbf{x}=\left[\mathbf{E}_{w_{1}}, \ldots, \mathbf{E}_{w_{m}}\right] \in \mathbb{R}^{d m}
x=[Ew1,...,Ewm]∈Rdm
E
∈
R
∣
V
∣
×
d
\mathbf{E} \in \mathbb{R}^{|V| \times d}
E∈R∣V∣ × d is the embedding matrix, where each column vector
E
w
\mathbf{E}_{w}
Ew is a word
w
w
embedding of w.
Network:
h
=
ReLU
(
x
W
+
b
1
)
l
=
h
U
+
b
2
y
^
=
softmax
(
l
)
\begin{aligned} \mathbf{h} &=\operatorname{ReLU}\left(\mathbf{x} \mathbf{W}+\mathbf{b}_{1}\right) \\ \mathbf{l} &=\mathbf{h U}+\mathbf{b}_{2} \\ \hat{\mathbf{y}} &=\operatorname{softmax}(l) \end{aligned}
hly^=ReLU(xW+b1)=hU+b2=softmax(l)
Minimize cross entropy:
J
(
θ
)
=
C
E
(
y
,
y
^
)
=
−
∑
i
=
1
3
y
i
log
y
^
i
J(\theta)=C E(\mathbf{y}, \hat{\mathbf{y}})=-\sum_{i=1}^{3} y_{i} \log \hat{y}_{i}
J( θ)= CE(y,y ^) = − i=1 Σ 3 yi log ^ i. UAS is used as the evaluation index of the model.
The baseframe model can be found in the parser_model.py file to realize the network. You need to complete _init_, embedding_lookup and forward functions, and then complete the train_for_epoch and train functions in the run.py file. Finally, execute the python run.py training model and calculate the prediction effect in the test set (Penn Tree Library, marked with Universal Dependencies).
be careful:
(1) In this job, you need to implement linear layer and embedding layer, so do not directly use torch.nn.Linear and torch.nn.Embedding.
def minibatch_parse(sentences, model, batch_size):
"""Parses a list of sentences in minibatches using a model.
@param sentences (list of list of str): A list of sentences to be parsed
(each sentence is a list of words and each word is of type string)
@param model (ParserModel): The model that makes parsing decisions. It is assumed to have a function
model.predict(partial_parses) that takes in a list of PartialParses as input and
returns a list of transitions predicted for each parse. That is, after calling
transitions = model.predict(partial_parses)
transitions[i] will be the next transition to apply to partial_parses[i].
@param batch_size (int): The number of PartialParses to include in each minibatch
@return dependencies (list of dependency lists): A list where each element is the dependencies
list for a parsed sentence. Ordering should be the
same as in sentences (i.e., dependencies[i] should
contain the parse for sentences[i]).
"""
dependencies = []
### YOUR CODE HERE (~8-10 Lines)
### TODO:
### Implement the minibatch parse algorithm. Note that the pseudocode for this algorithm is given in the pdf handout.
###
### Note: A shallow copy (as denoted in the PDF) can be made with the "=" sign in python, e.g.
### unfinished_parses = partial_parses[:].
### Here `unfinished_parses` is a shallow copy of `partial_parses`.
### In Python, a shallow copied list like `unfinished_parses` does not contain new instances
### of the object stored in `partial_parses`. Rather both lists refer to the same objects.
### In our case, `partial_parses` contains a list of partial parses. `unfinished_parses`
### contains references to the same objects. Thus, you should NOT use the `del` operator
### to remove objects from the `unfinished_parses` list. This will free the underlying memory that
### is being accessed by `partial_parses` and may cause your code to crash.
partial_parses = [PartialParse(sentence) for sentence in sentences]
unfinished_parses = partial_parses[:] # shallow copy
while len(unfinished_parses) > 0:
# Take the parses of the first batch size from the unfinished parses
minibatch_partial_parses = unfinished_parses[:batch_size]
# The model predicts the next transformation step for each partial parser in minibatch
minibatch_transitions = model.predict(minibatch_partial_parses)
# According to the prediction results, perform local analysis in minibatch and perform the analysis steps
for transition, partial_parse in zip(minibatch_transitions, minibatch_partial_parses):
partial_parse.parse_step(transition)
# Delete completed parsing (empty buffer and stack size 1) from unfinished parsing.
unfinished_parses = [
partial_parse for partial_parse in unfinished_parses
if not (len(partial_parse.buffer) == 0 and len(partial_parse.stack) == 1)
]
for partial_parse in partial_parses:
dependencies.append(partial_parse.dependencies)
### END YOUR CODE
return dependencies
Run code result:
dev UAS: 88.60
test UAS: 89.08
(6) Test model effect
4, Experimental process and results
The progress bar here is implemented through the tqdm toolkit.
SyntaxWarning: "is" with a literal. Did you mean "=="?
return [("RA" if pp.stack[1] is "right" else "LA") if len(pp.buffer) == 0 else "S"
================================================================================
INITIALIZING
================================================================================
Loading data...
took 2.58 seconds
Building parser...
took 1.66 seconds
Loading pretrained embeddings...
took 8.80 seconds
Vectorizing data...
took 1.95 seconds
Preprocessing training data...
took 65.94 seconds
took 0.18 seconds
================================================================================
TRAINING
================================================================================
Epoch 1 out of 10
100%|██████████| 1848/1848 [02:07<00:00, 14.54it/s]
Average Train Loss: 0.1781648173605725
Evaluating on dev set
1445850it [00:00, 28400918.10it/s]
- dev UAS: 84.76
New best dev UAS! Saving model.
Epoch 2 out of 10
100%|██████████| 1848/1848 [02:21<00:00, 13.09it/s]
Average Train Loss: 0.11059159756480873
Evaluating on dev set
1445850it [00:00, 21319509.36it/s]
- dev UAS: 86.57
New best dev UAS! Saving model.
Epoch 3 out of 10
100%|██████████| 1848/1848 [02:29<00:00, 12.35it/s]
Average Train Loss: 0.09602350440255297
Evaluating on dev set
1445850it [00:00, 21010828.57it/s]
- dev UAS: 87.23
New best dev UAS! Saving model.
Epoch 4 out of 10
100%|██████████| 1848/1848 [02:24<00:00, 12.78it/s]
Average Train Loss: 0.08655059076765012
Evaluating on dev set
1445850it [00:00, 18410020.64it/s]
- dev UAS: 88.03
New best dev UAS! Saving model.
Epoch 5 out of 10
100%|██████████| 1848/1848 [02:29<00:00, 12.32it/s]
Average Train Loss: 0.07943204295664251
Evaluating on dev set
1445850it [00:00, 24345468.35it/s]
- dev UAS: 88.25
New best dev UAS! Saving model.
Epoch 6 out of 10
100%|██████████| 1848/1848 [02:28<00:00, 12.42it/s]
Average Train Loss: 0.07376304407124266
Evaluating on dev set
1445850it [00:00, 23765859.77it/s]
- dev UAS: 88.06
Epoch 7 out of 10
100%|██████████| 1848/1848 [02:11<00:00, 14.08it/s]
Average Train Loss: 0.06907538355638583
Evaluating on dev set
1445850it [00:00, 16358657.93it/s]
- dev UAS: 88.15
Epoch 8 out of 10
100%|██████████| 1848/1848 [02:12<00:00, 13.92it/s]
Average Train Loss: 0.06480039135468277
Evaluating on dev set
1445850it [00:00, 20698658.75it/s]
- dev UAS: 88.45
New best dev UAS! Saving model.
Epoch 9 out of 10
100%|██████████| 1848/1848 [02:31<00:00, 12.22it/s]
Average Train Loss: 0.061141976250085606
Evaluating on dev set
1445850it [00:00, 22635715.12it/s]
- dev UAS: 88.41
Epoch 10 out of 10
100%|██████████| 1848/1848 [02:18<00:00, 13.36it/s]
Average Train Loss: 0.05778654704870277
Evaluating on dev set
1445850it [00:00, 30163164.76it/s]
- dev UAS: 88.60
New best dev UAS! Saving model.
================================================================================
TESTING
================================================================================
Restoring the best model weights found on the dev set
Final evaluation on test set
2919736it [00:00, 31476695.98it/s]
- test UAS: 89.08
Done!
Reference
(1)Explain transition based dependency parser in detail
(2) Stanford CS224N course assignment